Faster RCNN训练自己的数据集(自用)
中,运行如下代码,生成Main文件夹中的train.txt和val.txt,切记文件存放格式和文件夹名字一定要完全一样!在代码中需要修改files_path、val_rate、train_f和eval_f。生成的Main文件夹中的两个txt文件内容是。上述代码需要修改的地方就是。图片的名字去掉.jpg后缀。相关文件地址,如下图所示。(根据个人硬件性能调整)中,xml标签文件放到。
·
参考下方链接进行学习,感谢大大。
Faster-RCNN跑自己的数据集(个人记录过程)FPN学习_faster rcnn训练自己的数据集-CSDN博客
1.标签制作
需要使用xml格式的标签文件,如果是yolo格式的,需要转成xml文件,代码如下:
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
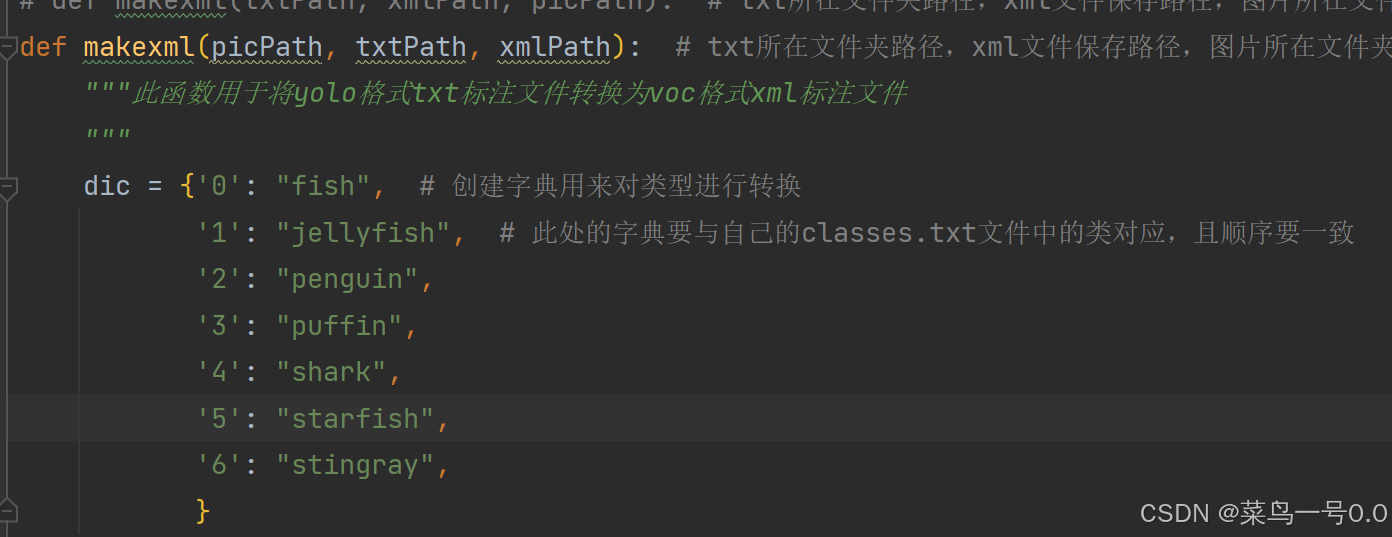
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
dic = {'0': "fish", # 创建字典用来对类型进行转换
'1': "jellyfish", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
'2': "penguin",
'3': "puffin",
'4': "shark",
'5': "starfish",
'6': "stingray",
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
aa=picPath + name[0:-4] + ".jpg"
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
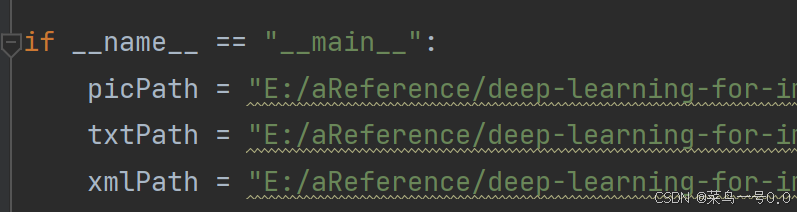
picPath = "E:/aReference/deep-learning-for-image-processing-master/deep-learning-for-image-processing-master/dataset/images/valid/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "E:/aReference/deep-learning-for-image-processing-master/deep-learning-for-image-processing-master/dataset/labels/valid/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = "E:/aReference/deep-learning-for-image-processing-master/deep-learning-for-image-processing-master/dataset/Annotations/valid/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
上述代码需要修改的地方就是目标类别和相关文件地址,如下图所示。
2.数据集存放位置和划分数据集
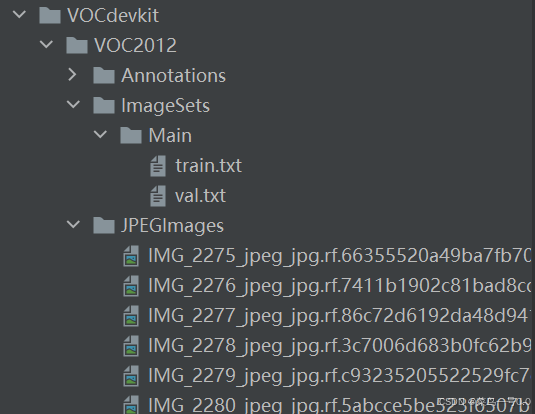
所有图像放到JPEGImages中,xml标签文件放到Annotations中,运行如下代码,生成Main文件夹中的train.txt和val.txt,切记文件存放格式和文件夹名字一定要完全一样!!!
在代码中需要修改files_path、val_rate、train_f和eval_f。
import os
import random
def main():
random.seed(0) # 设置随机种子,保证随机结果可复现
files_path = r"E:\aReference\deep-learning-for-image-processing-master\deep-learning-for-image-processing-master\dataset\Annotations"
assert os.path.exists(files_path), "path: '{}' does not exist.".format(files_path)
val_rate = 0.2
files_name = sorted([file.split(".xml")[0] for file in os.listdir(files_path)])
files_num = len(files_name)
val_index = random.sample(range(0, files_num), k=int(files_num*val_rate))
train_files = []
val_files = []
for index, file_name in enumerate(files_name):
if index in val_index:
val_files.append(file_name)
else:
train_files.append(file_name)
try:
train_f = open(r"E:\aReference\deep-learning-for-image-processing-master\deep-learning-for-image-processing-master\pytorch_object_detection\faster_rcnn\VOCdevkit\VOC2012\ImageSets\Main\train.txt", "w")
eval_f = open(r"E:\aReference\deep-learning-for-image-processing-master\deep-learning-for-image-processing-master\pytorch_object_detection\faster_rcnn\VOCdevkit\VOC2012\ImageSets\Main\val.txt", "w")
train_f.write("\n".join(train_files))
eval_f.write("\n".join(val_files))
except FileExistsError as e:
print(e)
exit(1)
if __name__ == '__main__':
main()
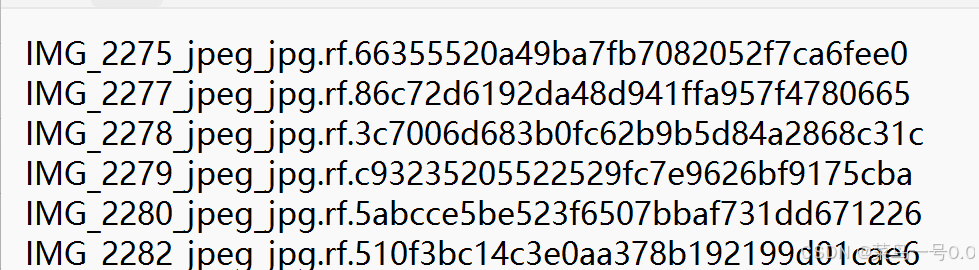
生成的Main文件夹中的两个txt文件内容是图片的名字去掉.jpg后缀,如下图:
3.修改训练参数
我选择了 train_res50_fpn.py这个文件进行训练,设置超参数如下:
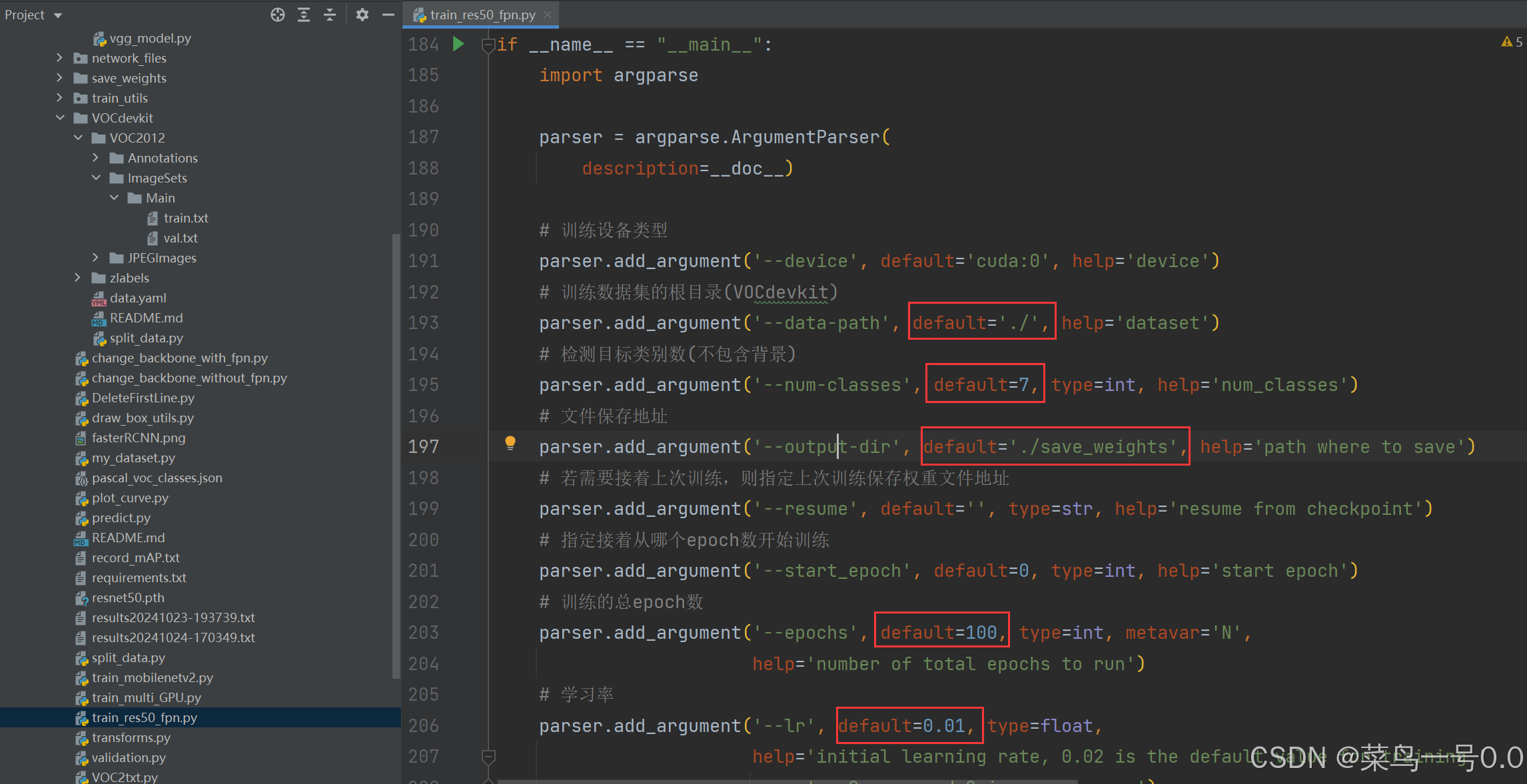
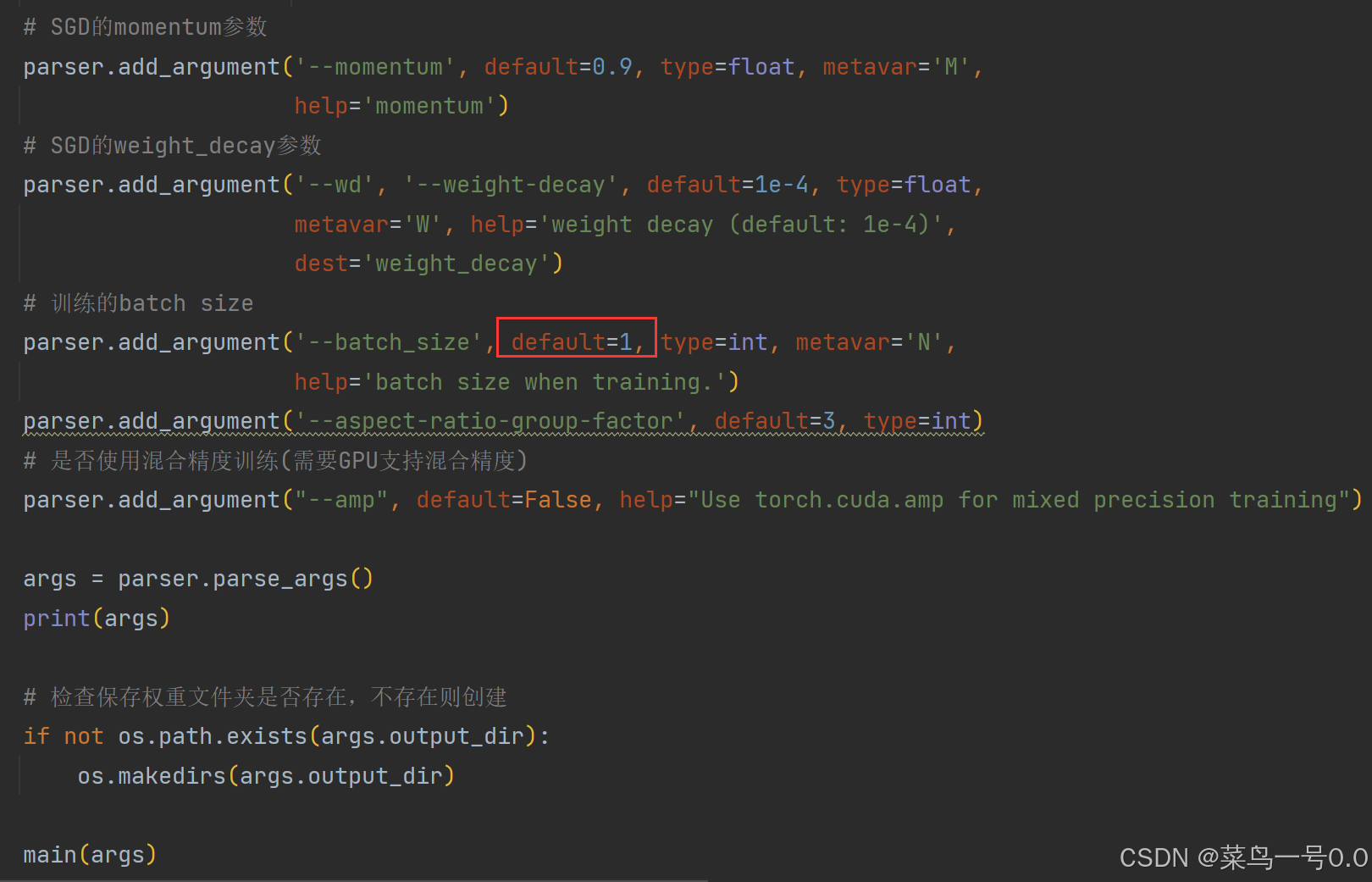
batch_size设置为1或2(根据个人硬件性能调整),设置的太大的话会出现如下问题:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 108.00 MiB (GPU 0; 4.00 GiB total capacity; 1.11 GiB already allocated; 523.75 MiB free; 1.19 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF

设置完直接训练就好

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)