【深度学习】缺陷检测---Python调用ONNX模型
本文介绍了在Windows环境下使用Python版ONNX Runtime部署ONNX模型的方法,通过PYQT5开发可视化界面实现缺陷检测功能。文章重点阐述了推理流程:1)加载模型和配置文件;2)图像预处理;3)ONNX模型推理;4)结果后处理(NMS过滤、坐标转换);5)结果可视化与数据保存。系统分为参数设置和结果显示两个区域,支持置信度阈值调节、批量处理等功能,推理结果同时保存为图片和CSV格
前言
在Windows上利用python版本的onnxruntime部署ONNX模型,脱离原有的训练环境,让模型在生产环境能够快速运行。
以下为基于PYQT5为界面的Python调用ONNX模型实现缺陷检测的小程序。
依赖环境
import onnxruntime as rt
import numpy as np
import cv2
import yaml
import sys
from PyQt5.QtWidgets import (QApplication, QMainWindow, QLabel, QVBoxLayout,
QHBoxLayout, QPushButton, QFileDialog, QWidget,
QSpinBox, QDoubleSpinBox, QTextEdit)
from PyQt5.QtCore import Qt, QThread, pyqtSignal
from PyQt5.QtGui import QImage, QPixmap, QIcon
import time, logging
import os.path通过pip install XXX将以上的依赖库安装到项目虚拟环境即可;
界面布局
 分为两个区域:
分为两个区域:
1、【ONNX预测参数设置】加载模型、yaml文件,设置Batch大小、图片标准尺寸(我是使用yoloV11训练的,默认640*640),以及置信度阈值,设置好后即可加载图片开始检测了。
2、图片显示、放大、缩小图片以及Log显示。
界面设计的代码部分我就不在文章内多说了,大家关注的重点都在推理实现上。
推理代码
def process_static_image(self):
"""处理静态图像"""
# 加载配置文件
config_file = self.yaml_file_path
with open(config_file, "r") as config:
config = yaml.safe_load(config)
dic = config["names"] # 得到的是模型内缺陷类别字典
class_list = list(dic.values())
std_h, std_w = self.img_train_height, self.img_train_width # 标准输入尺寸
self.logger.info(f"开始预处理所选{self.img_name}图片!")
img = cv2.imread(self.img_path)
# 前处理 设置图片尺寸大小
self.logger.info(f"开始处理所选{self.img_name}图片!")
img_after = self.resize_image(img, (std_w, std_h), True) # (640, 640, 3)
# 将图像处理成输入的格式
data = self.img2input(img_after)
# 输入模型
self.logger.info(f"开始检测所选{self.img_name}图片!")
sess = rt.InferenceSession(self.onnx_file_path) # yolov11模型onnx格式
self.logger.info(f"模型完成检测所选{self.img_name}图片!")
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred = sess.run([label_name], {input_name: data})[0] # 输出(8400x7, 84=3cls+4reg, 8400=3种尺度的特征图叠加)
pred = self.std_output(pred)
# 置信度过滤+nms
results = self.nms(pred, self.conf_threshold, 0.4) # [x,y,w,h,conf(最大类别概率),class]
# 坐标变换
if results:
results = self.cod_trf(results, img, img_after)
image = self.draw(results, img, class_list)
# 使用transpose来改变数组的形状
lv_image = np.transpose(image, (2, 0, 1))
i = 0
results_list = []
for result in range(len(results)):
result_list = []
result_list.append([self.img_name, int(results[i][5]), np.round(results[i][4], 2), np.round(results[i][0], 2), np.round(results[i][1], 2), np.round(results[i][2], 2), np.round(results[i][3], 2)])
print(result_list)
results_list.append([int(results[i][5]), np.round(results[i][4], 2), np.round(results[i][0], 2), np.round(results[i][1], 2), np.round(results[i][2], 2), np.round(results[i][3], 2)])
i = i + 1
# 以追加模式打开文件并写入新数据
with open(self.results_csv, 'a') as f:
np.savetxt(f, result_list, delimiter=',', fmt="%s")
self.results_img_path = os.getcwd() + '/results_img/{}/'.format(
time.strftime('%Y%m%d%H%M', time.localtime(time.time()))[:8])
self.results_img = self.results_img_path + f"{self.img_name}.jpg"
isExists = os.path.exists(self.results_img_path)
if not isExists:
os.makedirs(self.results_img_path)
# 显示图像
self.show_frame(image)
# 保存输出原始图像
cv2.imwrite(self.results_img, image)
self.statusBar().showMessage("此图片已检测完成")
self.logger.info(f"所选{self.img_name}图片检测完成!")代码内注释比较清晰,基本流程就是根据yaml文件获得模型缺陷种类字典、图片预处理、加载模型、推理、结果索引、保存结果数据与图片。
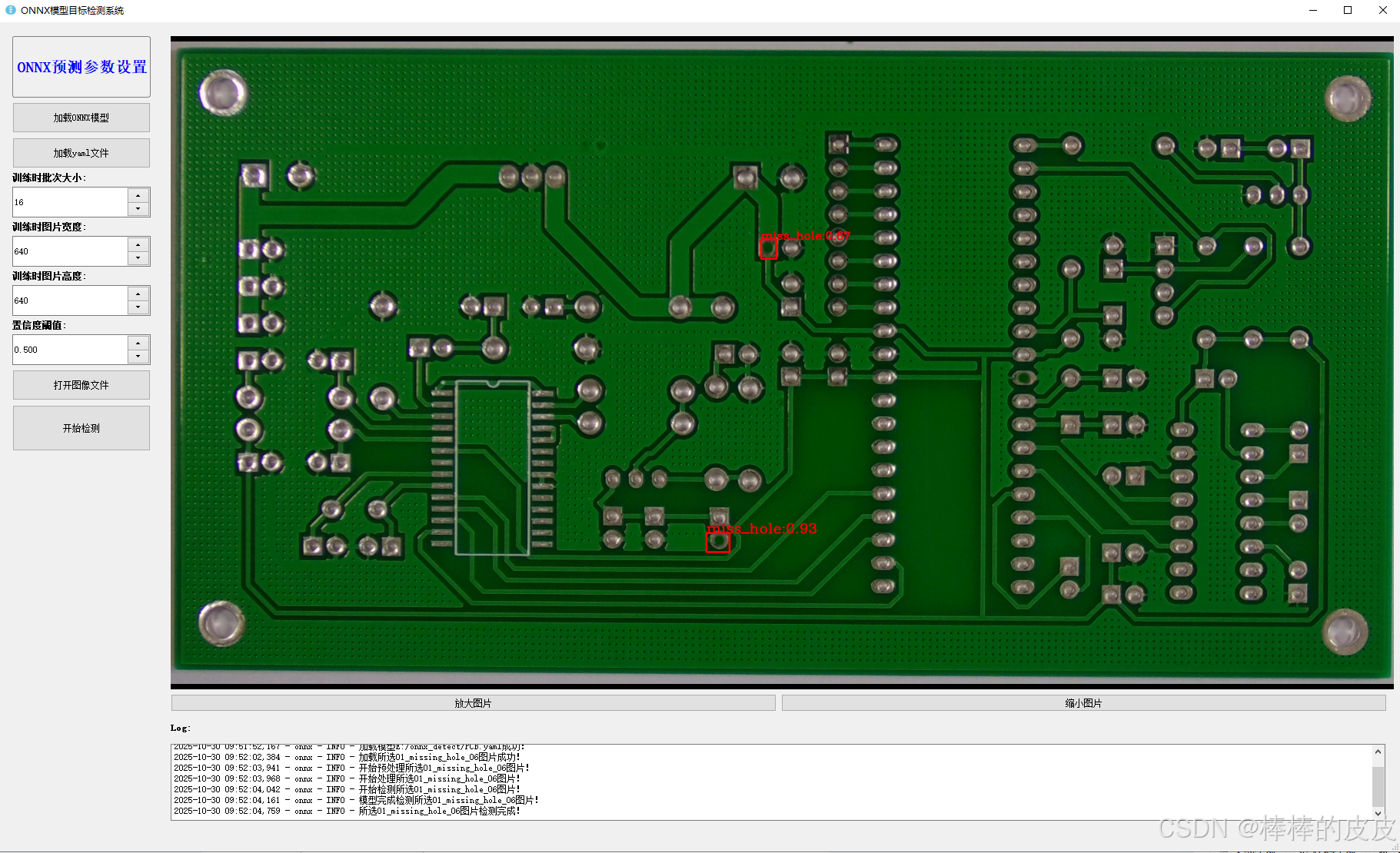
效果图
推理界面:
数据保存格式:

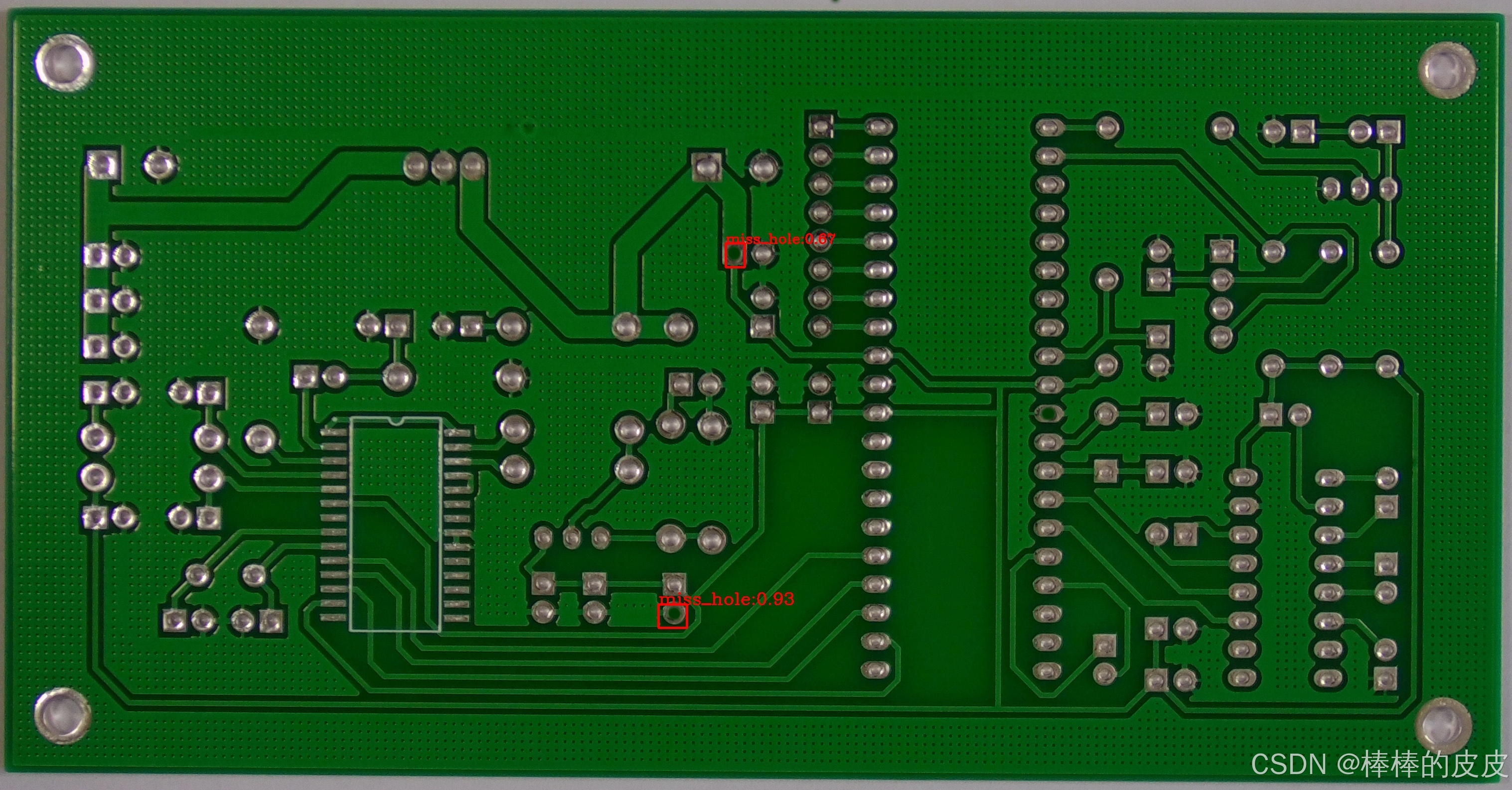
本地保存推理后图片:
总结
尽可能简单、详细的介绍Python调用ONNX模型的流程,通过可视化界面更清晰的展示推理过程;
如需要源码可私信。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)