卷积神经网络—感受野与特征图
一、感知器输入x(x1,x2…)->组合函数c()-> b偏差(权重w1,w1…)->激活函数a() -> 输出y多层感知器(MLP)二、卷积神经网络(CNN)两种广泛应用的DNN:CNN 和RNNCNN(卷积神经网络)—-图像识别Convolut
一、卷积神经网络(CNN)
1.1 卷积神经网络(CNN)使用场景
-
CNN(卷积神经网络)
-
图像识别,OCR等
图像分类:目标检索/定位
图像搜索
人脸识别:人脸检测/人脸分析(性别,年龄,微笑)
人脸比对(判断)、人脸搜索(数据库中搜索)
无人驾驶:定位,感知,决策,控制
拍照食物/搜索:识别花朵/拍照购物/以图搜图
物体检测和定位:图片中的物体
风格迁移:模仿大师的绘画风格
图片智能审核:色情过滤/暴力过滤/广告过滤/识别二维码 RNN(循环神经网络)
-
时间序列预测(天气、股票、等与时间序列相关的使用场景)
情感分析(正面、负面)
模拟写作:模仿作家风格写作
看图说话:自动给图片生成标题
机器翻译等
二、感受野的概念
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如图1所示。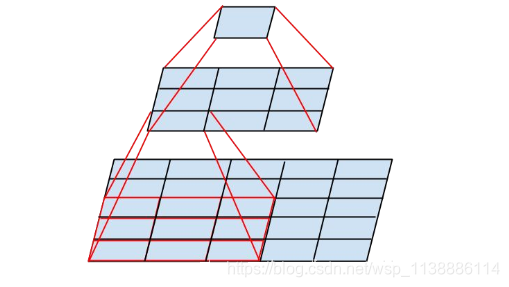
图中是个微型CNN,来自Inception-v3论文,原图是为了说明一个conv5x5可以用两个conv3x3代替,从下到上称为第1, 2, 3层:
- 第2层左下角的值,是第1层左下红框中3x3区域的值经过卷积,也就是乘加运算计算出来的,即第2层左下角位置的感受野是第1层左下红框区域
- 第3层唯一值,是第2层所有3x3区域卷积得到的,即第3层唯一位置的感受野是第2层所有3x3区域
- 第3层唯一值,是第1层所有5x5区域经过两层卷积得到的,即第3层唯一位置的感受野是第1层所有5x5区域
简而言之:某一层feature map(特性图)中某个位置的特征向量,是由前面某一层固定区域的输入计算出来的,那这个区域就是这个位置的感受野。任意两个层之间都有位置—感受野对应关系,但我们更常用的是feature map层到输入图像的感受野,如目标检测中我们需要知道feature map层每个位置的特征向量对应输入图像哪个区域,以便我们在这个区域中设置anchor,检测该区域内的目标。
感受野区域之外图像区域的像素不会影响feature map层的特征向量,一般我们不会让CNN仅依赖某个特征向量去找到其对应输入感受野之外的目标。但是考虑到图像像素之间有相关性,有时候感受野之外的目标是可以猜出来的,什么一叶知秋,管中窥豹,见微知著之类,对CNN目标检测都是有可能的,但猜出来的结果并不总是那么靠谱。
感受野作用
- 一般task要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好
- 密集预测task要求输出像素的感受野足够的大,确保做出决策时没有忽略重要信息,一般也是越深越好
- 目标检测task中设置anchor要严格对应感受野,anchor太大或偏离感受野都会严重影响检测性能
感受野的计算
我们首先介绍一种从后向前计算方法,极其简单适合人脑计算,看看网络结构就知道感受野了,之后介绍一种通用的从前往后计算方法,比较规律适合电脑计算,简单编程就可以计算出感受野大小和位置。
我们要计算感受野的大小r(长或宽)和不同区域之间的步进S,从前往后的方法以感受野中心**(x,y)**的方式确定位置,从后往前的方法以等效padding P的方式确定位置。CNN的不同卷积层,用k表示卷积核大小,s表示步进(s1表示步进是1,s2表示步进是2),下标表示层数。
从后往前的计算方式的出发点是:一个conv5x5的感受野等于堆叠两个conv3x3,反之两个堆叠的conv3x3感受野等于一个conv5x5,推广之,一个多层卷积构成的FCN感受野等于一个conv r x r,即一个卷积核很大的单层卷积,其kernelsize=r,padding=P,stride=S。
感受野计算:
f i e l d l = ( f i e l d l + 1 × S t e p ) + ( K e r n e l s i z e − S t e p ) field_l = (field_{l+1} \times Step) + (\rm Kernel_{size}-Step) fieldl=(fieldl+1×Step)+(Kernelsize−Step)
- 初始 feature map 层的感受野是1
- 每经过一个conv k x k ,s1的卷积层,感受野 r = r + (k - 1)
常用卷积核 k=3 计算倒数第二层感受野 :r = (原始感受野1 * step1) + (卷积核3-step1) = 3 - 每经过一个conv k x k, s2的卷积层或max/avg pooling层,感受野 r = (r x 2) + (k -2),
常用卷积核k=3, s=2,感受野 r = r x 2 + 1,卷积核k=7, s=2, 感受野r = r x 2 + 5 - 每经过一个maxpool2x2 s2的max/avg pooling下采样层,感受野 r = r x 2
- 特殊情况,经过conv1x1 s1不会改变感受野,经过FC层和Global Average Pooling层,感受野就是整个输入图像
- 经过多分枝的路径,按照感受野最大支路计算,shotcut也一样所以不会改变感受野
- ReLU, BN,dropout等元素级操作不会影响感受野
- 全局步进等于经过所有层的步进累乘: S = s 1 × s 2 × s 2 × ⋯ × s n S=s_1\times s_2\times s_2\times \cdots \times s_n S=s1×s2×s2×⋯×sn
- 经过的所有层所加padding都可以等效加在输入图像,等效值P,直接用卷积的输入输出公式 : f o u t = ( f i n − r + 2 P ) / S + 1 f_{out} = (f_{in}-r+2P)/S +1 fout=(fin−r+2P)/S+1 反推出P即可:
P = ( f o u t − 1 ) × s t r i d e − f i n + k e r n e l S i z e 2 P=\frac{(f_{out}-1)\times stride -f_{in}+ kernelSize}{2} P=2(fout−1)×stride−fin+kernelSize
更多详情【请点击】。
三、Feature Map 特征图尺寸计算
-
普通卷积
一般卷积提取特征时,我们需要计算下层特征图的大小:
假设输入 ( N , C i n , H i n , W i n ) (N,C_{in},H_{in},W_{in}) (N,Cin,Hin,Win) 卷积操作后输出 ( N , C o u t , H o u t , W o u t ) (N,C_{out},H_{out},W_{out}) (N,Cout,Hout,Wout),
计算公式为:( 计算结果向上取整)
H o u t = [ H i n + 2 × p a d d d i n g [ 0 ] − k e r n e l s i z e [ 0 ] S t r i d e [ 0 ] ] + 1 H_{out} = \left[ \frac{H_{in} +2 \times paddding[0] -kernel_{size}[0]}{Stride[0]} \right]+1 Hout=[Stride[0]Hin+2×paddding[0]−kernelsize[0]]+1
以VGG网络卷积为例:输入图片大小为:244 X 244, conv3(卷积核3 x 3), s1(步长1),padding=1:
下一层的 feature map = [ h i n + 2 P − k S ] + 1 \left[ \frac{h_{in} +2P -k}{S} \right]+1 [Shin+2P−k]+1=[(244+2-3)/1]+1 = 224
显然卷积后会保持原图大小。 -
dilation膨胀(空洞)卷积
关于dilation卷积的详情:【点击】
H o u t = [ H i n + 2 × p a d d d i n g [ 0 ] − d i l a t i o n [ 0 ] × ( k e r n e l s i z e [ 0 ] − 1 ) − 1 S t r i d e [ 0 ] ] + 1 H_{out} = \left[ \frac{H_{in} +2 \times paddding[0] - dilation[0] \times (kernel_{size}[0]-1)-1}{Stride[0]} \right]+1 Hout=[Stride[0]Hin+2×paddding[0]−dilation[0]×(kernelsize[0]−1)−1]+1
四、感受野与特征图的关系
做目标检测任务分为两个子任务:分类和边框回归。
在CNN感受野的概念中就是说:图像上的某一块区域大小影响到某个神经元的输出,这个区域大小就是这个神经元的感受野大小。根据CNN的结构特点,层数越深,对应的感受野越大,比如经典的分类网络,最后的输出神经元感受野达到了整张图像大小,需要有看到整张图像的能力才能做全局的分类。另外由于监督学习模式,越深的层得到的特征越抽象(高级),越浅的层特征越细节(低级)。深层的特征由于平移不变性(translation invariance),已经丢掉了很多位置信息。而检测既需要分类也需要回归。分类要求特征有较多的高级信息,回归(定位)要求特征包含更过的细节信息,这两种要求在同一个特征图(feature map)上很难同时兼得。因此,大的特征图由于感受野较小,同时特征包含位置信息丰富,适合检测小物体。
感受野和物体scale的关系也有很多值得研究的地方。两者不合适的匹配会造成比较大的损害,就比如物体是一只狗但感受野只有能看到躯干的大小,这样会大概率认为是只猫,这是感受野太小;在世界地图上想找到北京,这就是感受野太大;不管太大还是太小都不好。那么尽量让物体的scale和感受野保持一个合适的固定的比例是一个解决方法。这个固定的比例是多大呢,需要引出有效感受野的概念,这方面的研究也不少。前面说到浅层特征缺少抽象信息,而这些信息对分类很重要,因此说浅层特征检测小物体也有其值得提升的地方。FPN就是将高级和低级特征融合来增强浅层特征的高级特征信息。
参考与鸣谢
https://www.cnblogs.com/pprp/p/12346759.html

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 3
3 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)