mfc ajax爬虫,另辟蹊径,爬取Ajax数据内容
通常利用python 爬取ajax数据 有两种方式:①基于selenium+phantomjs+python的动态爬虫技术②基于逆向分析但是这两种方式都不太容易。第一种利用selenium进行driver。从安装到代码书写都不容易,我也是学了很久都没有完全掌握。我从csdn上找到了前辈写的内容,有兴趣的可以看一看。第二种方法 逆向分析,这个更困难。如果没有扎实的html、js等技术,很难分析出网页

通常利用python 爬取ajax数据 有两种方式:
①基于selenium+phantomjs+python的动态爬虫技术
②基于逆向分析
但是这两种方式都不太容易。
第一种利用selenium进行driver。从安装到代码书写都不容易,我也是学了很久都没有完全掌握。我从csdn上找到了前辈写的内容,有兴趣的可以看一看。
第二种方法 逆向分析,这个更困难。如果没有扎实的html、js等技术,很难分析出网页中的数据,很多的教学视频课中 讲师很容易就从网页的开发者工具中找到了需要的数据,这看似容易,但当你亲自上手时才发现自己什么都找不到。
基于上述原因,我另辟蹊径 找其他更简单的方法爬取自己所需要的内容。
【声明:我不是专业的爬虫工作者,只是业余爱好者,偶尔爬取一些需要的内容。上述的两种方法我都不太熟悉,大神勿喷】
正式开始我的内容,以爬取西瓜视频内容为例,网上爬取西瓜视频的例子很少。
【起因】
超长的寒假在家闲来无事 我就又捡起了python学习,所以就在西瓜视频上搜索,发现一个作者上传的视频很是很不错的就想连着看。打开他的主页一看,发现他的作品有一万多个,想要直接找到自己需要的内容挺难的,就想着把他的内容都爬取下来,方便查找观看。
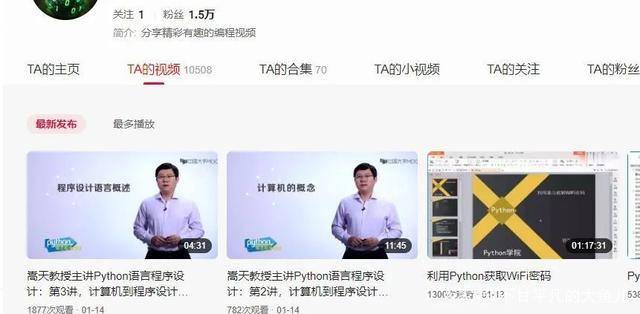
大家都知道,像头条、西瓜视频、微博等网站的数据都是利用ajax进行加载的,用普通的requests根本就爬不到数据,但逆向分析和selenium我还不会,所以,我就尝试了新的方法。
所有在网页上展现出来的数据都可以用F12开发者工具查找到。
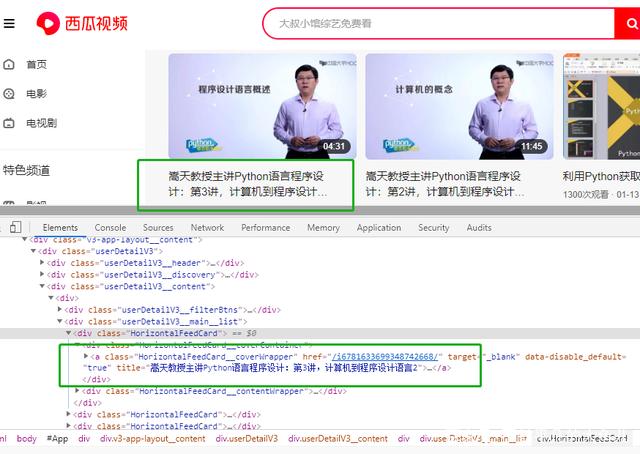
所以,需要做的就是拿到所需数据的这部分内容全部代码。通过分析,发现所有的数据都在 class="userDetailV3__content" 的div标签下。所以,目的就变成了获得这个标签下的全部代码。
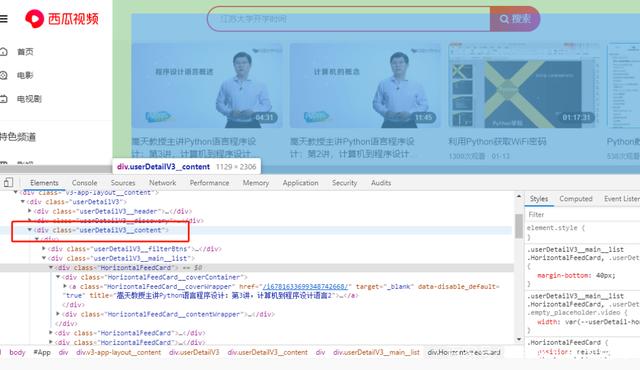
然后,我就把这个网页下拉到了最底端,然后打开开发者工具,找到这个div标签,Ctrl+C复制这部分代码到了notepad里,由于这部分代码量很大,下拉和粘贴的过程需要一些时间,大概10分钟。
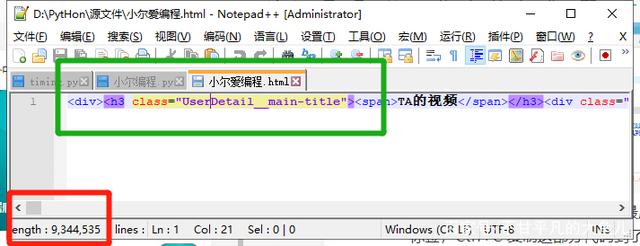
有了源代码,获得里面的内容就很简单了,熟悉爬虫一般流程的朋友几分钟就可以完成数据的获得。
由于复制过来的html代码不规范,所以用BeautifulSoup里的prettify()方法将代码规范化,找到自己需要的内容 视频名称和视频链接。
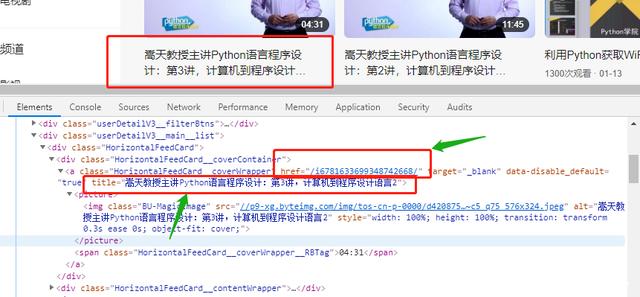
获取视频名称title和链接href,我用的re正则表达式。但这里需要小小的注意,得到的href地址是短的相对地址,想要获得完整的地址 还需要在它前面加上“https://www.ixigua.com/”。这些都是非常容易的。然后把这些内容保存到本地,就算完成了。
看一下最后的成果:
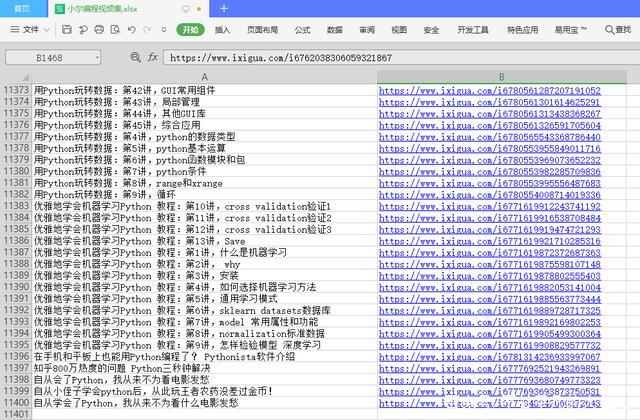
有了标题和视频地址,想看哪个,点击一下就可以了。还很方便查找。
以下是源代码,只有20来行。
#
from bs4 import BeautifulSoup
import re
path = 'd:/PytHon/源文件/小尔爱编程.html'
htmlfile = open(path,'r',encoding='utf-8')
htmlhandle = htmlfile.read()
soup = BeautifulSoup(htmlhandle,'lxml')
soup = soup.prettify()
# print(soup)
soup = soup.replace("\n","")
soup = soup.replace("\r","")
re_name = r'(.*?)'
sp_info = re.findall(re_name,soup,re.S)
print(len(sp_info))
print(sp_info[1][1])
print(sp_info[1][0])
for i in range(len(sp_info):
sp_name = sp_info[i][1]
sp_url = 'https://www.ixigua.com'+sp_info[i][0]
info = sp_name + '-' + sp_url + '\n'
print(sp_name)
with open('小尔编程.csv', 'a', encoding='utf8') as f:
f.write(info)
这就是我采用的一种方法,比起用 selenium 和 逆向分析 会简单非常多。可以节约很多分析过程的时间,也不会触发服务器限制。但是,它也有很明显的缺点,只能小规模进行。
后记:
我不是爬虫工程师,更不是程序猿,只是一个学习者。规模化的爬虫我做不到,对想要的数据随时都可以自己爬取。我认为,对于想要获得的内容不能仅局限于那一种方式,相反,我们可以多种工具混合使用,提高效率。人之所以为人 就是因为可以创造和使用工具。而python也是一种工具,它适合来做爬虫、数据分析等类似的工作,而不适合做gui等工作,我也试过,图形界面很难用。
【以上就是我的分享,感谢大神指导,不喜勿喷,谢谢各位】
举报/反馈

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)