Docker容器核心技术:Linux命名空间Namespaces、控制组cgroups、联合文件系统UnionFS
Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核的 cgroup,namespace,以及 OverlayFS 类的 Union FS 等技术,对进程进行封装隔离,属于 操作系统层面的虚拟化技术。由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
1.容器的本质——进程
Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核的 cgroup,namespace,以及 OverlayFS 类的 Union FS 等技术,对进程进行封装隔离,属于 操作系统层面的虚拟化技术。由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
由上可知,容器是独立于宿主和其它的隔离的进程的进程,即容器的本质是进程,而这也是容器与虚拟机的最本质区别。容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
2.Namespaces命名空间:隔离容器
2.1 Namespaces命名空间介绍
命名空间是 Linux 内核的一个强大特性,它可以将不同的进程或容器隔离开来,使它们看起来像是在独立的操作系统中运行一样。在 Docker 中,每个容器都有自己单独的命名空间,其中包括 pid、net、ipc、mnt、uts 和 user 命名空间。
- pid 命名空间:隔离不同用户的进程,每个命名空间中可以有相同的 pid。系统调用参数为CLONE_NEWPID
- net 命名空间:隔离网络端口、设备、协议栈,每个命名空间有独立的网络设备、IP 地址、路由表和 /proc/net 目录。系统调用参数为CLONE_NEWNET
- ipc 命名空间:隔离进程间通信,如信号量、消息队列和共享内存,每个 IPC 资源有一个唯一的 32 位 id。系统调用参数为CLONE_NEWIPC
- mnt 命名空间:隔离文件系统,每个命名空间中的进程所看到的文件目录被隔离开了。系统调用参数为CLONE_NEWNS
- uts 命名空间:隔离主机名和域名,使容器在网络上可以被视作一个独立的节点。系统调用参数为CLONE_NEWUTS
- user 命名空间:隔离用户和组 id,使容器内部的用户可以执行程序而非主机上的用户。系统调用参数为CLONE_NEWUSER
很多编程语言都包含了命名空间的概念,这是一种封装,它可以实现代码的隔离。
在操作系统中,命名空间提供的是系统资源的隔离,包括进程、网络、文件系统等。在同一个命名空间下的进程可以感知彼此的变化,而对其他命名空间的进程一无所知,这样就可以让容器中的进程产生一个错觉,仿佛他自己置身于一个独立的系统环境当中,以此达到独立和隔离的目的。
创建容器进程时,默认情况下,Docker会为每个容器创建一个新的命名空间,这是为了确保容器之间的隔离性和安全性。这意味着每个容器都有自己的PID、IPC、UTS、网络和挂载点命名空间,这些命名空间是相互隔离的,不会相互干扰。这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。通过命名空间的隔离,容器之间互不影响,提高了容器的安全性和可靠性。
2.2 namespace API操作
主要是三个系统调用
- clone() :实现线程的系统调用,用来创建一个新的进程,并可以通过设计参数达到隔离。
- unshare() : 使某进程脱离某个namespace
- setns() : 把某进程加入到某个namespace
2.3 Docker指定namespace
Docker run命令有几个参数与命名空间相关。以下是这些参数的简要说明:
-
--ipc:指定容器使用的IPC命名空间。IPC命名空间用于控制进程间通信(IPC)机制,如共享内存和信号量。 -
--pid:指定容器使用的PID命名空间。PID命名空间用于控制进程ID(PID)的范围,以便容器中的进程只能看到其自己的PID和其子进程的PID。 -
--userns:指定容器使用的用户命名空间。用户命名空间用于控制容器中的用户和组ID的范围,以便容器中的进程只能看到其己的用户和组ID。 -
--uts:指定容器使用的UTS命名空间。UTS命名空间用于控制主机名和域名的范围,以便容器中的进程只能看到其自己的主机名和域名。 -
--userns-remap=default|uid:gid|user:group|user|uid:指定容器的用户命名空间,默认是创建新的 UID 和 GID 映射到容器内进程。
如果您不指定这些参数,创建容器进程时,默认情况下,Docker会为每个容器创建一个新的命名空间,这是为了确保容器之间的隔离性和安全性。这意味着每个容器都有自己的PID、IPC、UTS、网络和挂载点命名空间,这些命名空间是相互隔离的,不会相互干扰。这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。通过命名空间的隔离,容器之间互不影响,提高了容器的安全性和可靠性。
3.cgroups——Control groups控制组:资源分配
3.1 cgroups介绍
虽然容器使用了 NameSpace 技术进行进程隔离,但是它们仍然与宿主机上的进处于同等级别的资源竞争关系。这就需要使用 Linux Control groups进行资源限制,它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
- 任务(Tasks):就是系统的一个进程。
- 控制组(Control Group):一组按照某种标准划分的进程,其表示了某进程组,Cgroups中的资源控制都是以控制组为单位实现,一个进程可以加入到某个控制组。而资源的限制是定义在这个组上,简单点说,cgroup的呈现就是一个目录带一系列的可配置文件。
- 层级(Hierarchy):控制组可以组织成hierarchical的形式,既一颗控制组的树(目录结构)。控制组树上的子节点继承父结点的属性。简单点说,hierarchy就是在一个或多个子系统上的cgroups目录树。
- 子系统(Subsystem):一个子系统就是一个资源控制器,比如CPU子系统就是控制CPU时间分配的一个控制器。子系统必须附加到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。Cgroup的子系统可以根据不同的需求进行配置和使用,比如限制CPU使用、限制内存使用、限制磁盘等等。每个子系统都有自己的特点和用途,可以根据具体的场景进行选择和配置,如下所示:

3.2 cgroups操作接口
Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,它以文件和目录的方式组织在 /sys/fs/cgroup 路径下,有很多诸如 cpuset、cpu、 memory 这样的子目录,即子系统。这些是可以被 Cgroups 进行限制的资源种类。例如查看PU限制目录: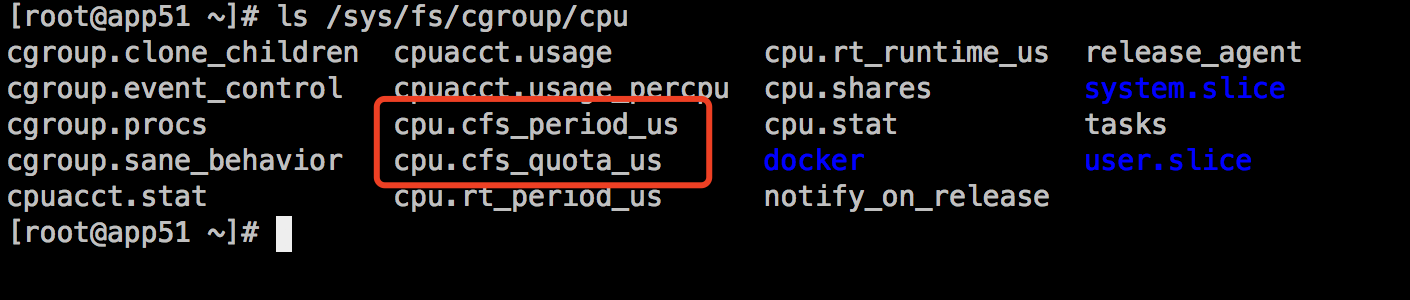
cfs_period 和 cfs_quota两个可能不会陌生,这两个参数需要组合使用,可以用来限制进程在长度为cfs_period 的一段时间内,只能被分配到总量为cfs_quota 的 CPU 时间。
cpu.cfs_quota_us值为-1代表没有任何限制,cpu.cfs_period_us 则是默认的100000us ,即100 ms。
下面将向cpu_limit_demo控制组的cpu.cfs_quota_us文件写入50ms即50000us,这表示在100ms周期内,cpu最多使用%50,同时将进程的pid号为10069写入对应的tasks文件,表示对进程进行CPU限制:
于是pid为10069的进程cpu就被限制成了%50.0,此时利用top命令在此查看cpu使用情况:
3.3 cgroups限制Docker资源
默认情况下,Docker会在需要限制的子系统下创建一个目录为docker的控制组,当容器运行后,会在这些目录生成以容器ID为目录的子目录用于限制的容器资源。
docker主要提供两种类别的资源限制:CPU和内存,通过docker run 时指定参数实现。cpu限制资源限制有多种维度,以下为限制cpu配额为25%的代码示例:
docker run -d --cpu-period=100000 --cpu-quota=250000 --name test-c1 nginx:latest
其余有关cgroups实现Docker资源限制的命令可以参考:https://www.cnblogs.com/wdliu/p/10509045.html
4.UnionFS联合文件系统:
4.1UnionFS介绍
UnionFS(Union File System)是一种堆叠式文件系统,它可以把多个目录内容联合挂载到同一个目录下,而目录的物位置是分开的。UnionFS应用的地方很多,比如在多个磁盘分区上合并不同文件系统的主目录,或把几张CD光盘合并成一个统一的光盘目录(归档)。以下是UnionFS的一些特点:
-
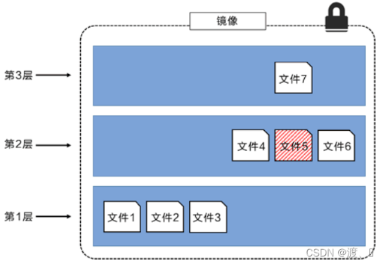
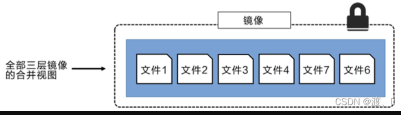
可以将不同目录挂载到同一个虚拟文件系统下,从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录。如下所示
-
支持为每一个成员目录设定 readonly、readwrite 和 whiteout-able 权限。
-
具有写时复制(copy-on-write)功能,允许只读文件系统的修改可以保存到可写文件系统当中。
-
文件系统分层,对 readonly 权限的 branch 可以逻辑上进行修改(增量地, 不影响 readonly 部分的)。
4.2 Docker镜像加载原理
容器的非运行态叫做镜像,是一种轻量级、可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码、运行时库、环境变量和配置文件。
在Docker中,UnionFS被用来实现镜像的分层存储,docker的镜像实际上由一层一层的文件系统组成。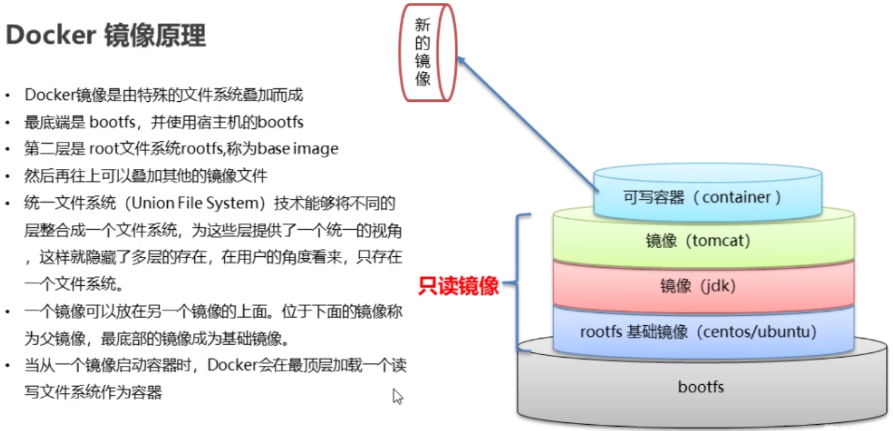
-
bootfs(boot file system) 主要包含bootloader 和 kernel,bootloader主要引导加载kernel,linux刚启动时会加载bootfs文件系统,在Docker镜像的最底层时bootfs。这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此使内存的使用权已由bootfs转交给内核,此使系统也会卸载bootfs。
-
rootfs(root file system) ,在bootfs之上。包含的就是典型Linux系统中的/dev、/proc、/bin、/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,CentOS等等
-
将中间只读的 rootfs 的集合称为 Docker 镜像,Docker 镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。UnionFS 使得镜像的复用、定制变得更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
-
当用docker run启动这个容器时,实际上在镜像的顶部添加了一个新的可写层,这个可写层也叫容器层,容器层之下的都叫镜像层。容器启动后,其内的应用所有对容器的改动,文件的增删改操作都只会发生在容器层中,对容器层下面的所有只读镜像层没有影响,Docker 镜像层都是只读的。
-
每个镜像都由多个只读层和一个可读写层组成。只读层包含了镜像的文件系统,而可读写层则包含了容器运行时的文件系统。当容器启动时,Docker会将只读层和可读写层合并成一个文件系统,这样容器就可以访问到镜像中的文件系统和容器运行时的文件系统。不同的目录在这个虚拟目录里面又可以有独立的权限,也即是将两个不同的目录,挂载到同一个目录下面,然后通过读写权限的设置,使得呈现最终的文件目录给容器(模拟成了一个完整的操作系统)。
在Docker中,OverlayFS是默认的UnionFS实现方式,它具有更好的性能和更好的稳定性。Overlay 只有两层:upper 层和 Lower 层。Lower 层代表镜像层,upper 层代表容器可写层。如下所示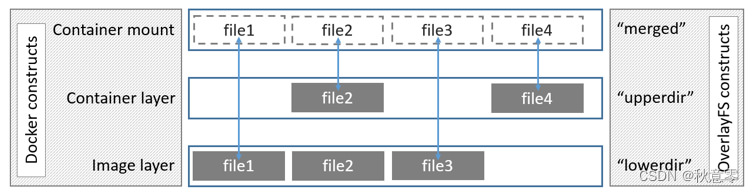
分层的优点如下:
- 分层最大的一个优点是共享资源;
- 多个镜像都从相同的base镜像构建而来,那么宿主机只需在磁盘上保存一份base镜像即可,对于已经存在的层就没有必要再次下载了,而是实现了资源的共享。如下所示:
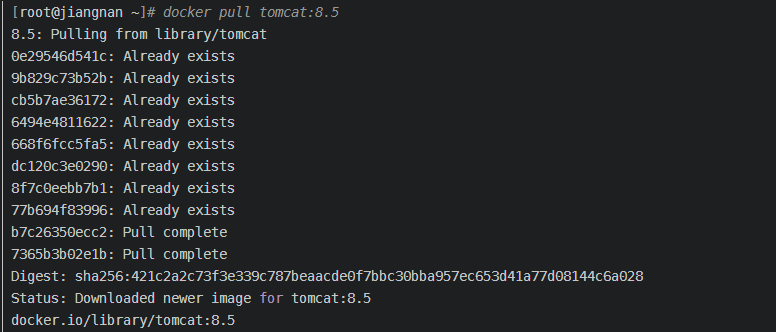
- 同时内存中也只需要加载一份base镜像,就可以为所有容器服务,而且镜像的每一层都可以被共享。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)