第七篇:深度学习SLAM——端到端的革命--从深度特征到神经辐射场的建图新范式
深度学习SLAM技术综述 本文系统介绍了深度学习在SLAM领域的应用进展。首先分析了传统SLAM方法的三大局限性:特征缺失环境、动态物体干扰和光照变化问题,并对比了深度学习解决方案。将深度学习SLAM分为模块增强和端到端系统两大类,详细阐述了监督与自监督学习的不同损失函数。重点介绍了SuperPoint和SuperGlue组成的深度特征提取与匹配系统,实验数据显示其匹配精度较传统方法提升30%以上
·

- 深度学习SLAM基础理论
1.1 传统SLAM的局限性
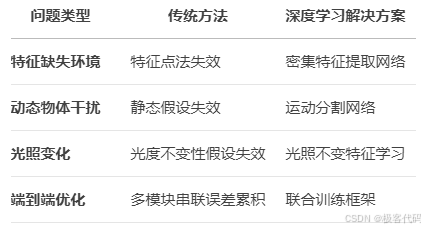
1.2 深度学习SLAM分类
1.3 监督与自监督学习
· 监督学习:![\mathcal{L} = | \hat{T} - T_{gt} |_1 + \lambda | \hat{D} - D_{gt} |_2]](https://i-blog.csdnimg.cn/direct/e004622a49224613ada417164bad4a34.png)
· 自监督学习:![\mathcal{L}_{photo} = \sum_i | I_t(p_i) - I_{t+1}(\pi(\hat{T} \cdot \pi^{-1}(p_i, \hat{d}_i))) |]](https://i-blog.csdnimg.cn/direct/e1c4b5a7f0bb450db32c6870cb69cdb3.png)
- 深度特征提取与匹配
2.1 SuperPoint 架构
class SuperPoint(nn.Module):
def __init__(self):
super().__init__()
# 共享编码器
self.encoder = nn.Sequential(
nn.Conv2d(1, 64, 3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
... # 4层下采样
)
# 特征点检测头
self.detector = nn.Conv2d(128, 256, 3, padding=1)
# 描述子提取头
self.descriptor = nn.Conv2d(128, 256, 3, padding=1)
def forward(self, x):
features = self.encoder(x) # [B, 128, H/8, W/8]
detections = self.detector(features) # [B, 256, H/8, W/8]
descriptors = self.descriptor(features) # [B, 256, H/8, W/8]
return detections, descriptors
2.2 SuperGlue 匹配机制
class SuperGlue(nn.Module):
def __init__(self):
super().__init__()
# 图神经网络层
self.gnn = nn.ModuleList([AttentionalGNN(256) for _ in range(9)])
# 匹配层
self.final_proj = nn.Conv1d(256, 256, 1)
def forward(self, desc0, desc1):
# 初始化图节点
nodes0 = desc0.permute(0,2,3,1).flatten(1,2)
nodes1 = desc1.permute(0,2,3,1).flatten(1,2)
# 多轮图传播
for layer in self.gnn:
nodes0, nodes1 = layer(nodes0, nodes1)
# 计算匹配分数
scores = torch.einsum('bdn,bdm->bnm', nodes0, nodes1)
scores = scores / 256**0.5
return scores
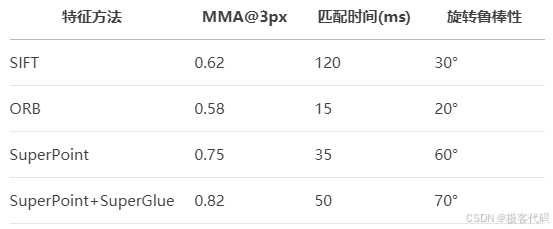
2.3 性能对比
- 端到端位姿估计
3.1 PoseNet 架构
class PoseNet(nn.Module):
def __init__(self):
super().__init__()
self.encoder = resnet34(pretrained=True)
self.pose_regressor = nn.Sequential(
nn.Linear(512, 2048),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(2048, 7) # [tx, ty, tz, qw, qx, qy, qz]
)
def forward(self, x):
features = self.encoder(x)
pose = self.pose_regressor(features)
return pose
3.2 几何一致性损失
def geometric_consistency_loss(T1, T2, points):
"""计算两组位姿对点云的几何一致性"""
# 变换点云
points1 = transform_points(points, T1)
points2 = transform_points(points, T2)
# 计算倒角距离
dist1 = pointcloud_distance(points1, points2)
dist2 = pointcloud_distance(points2, points1)
return (dist1.mean() + dist2.mean()) / 2
3.3 时空一致性训练
def train_vo(model, sequence_loader):
for images in sequence_loader: # [B, T, C, H, W]
poses = []
for t in range(images.shape[1]-1):
# 估计相邻帧位姿
pose_t = model(images[:, t])
pose_t1 = model(images[:, t+1])
poses.append(pose_t)
# 计算光度损失
warped = warp_image(images[:, t+1], pose_t1.inverse() @ pose_t)
loss_photo = photometric_loss(images[:, t], warped)
# 计算几何一致性损失
loss_geo = geometric_consistency_loss(pose_t, pose_t1, depth[:, t])
# 联合优化
loss = loss_photo + 0.5 * loss_geo
loss.backward()
optimizer.step()
- 神经辐射场(NeRF)建图
4.1 NeRF核心方程
· 体积渲染:![\hat{C}(r) = \sum_{i=1}^N T_i (1 - \exp(-\sigma_i \delta_i)) c_i]其中 T_i = \exp(-\sum_{j=1}^{i-1} \sigma_j \delta_j)](https://i-blog.csdnimg.cn/direct/e3e86560066044a1bde6798a8b713160.png)
4.2 Instant-NGP 实现
class InstantNGP(nn.Module):
def __init__(self):
super().__init__()
# 多分辨率哈希编码
self.embedder = HashEmbedder(
num_levels=16,
log2_hashmap_size=19,
per_level_scale=2
)
# 轻量MLP
self.mlp = TinyMLP(
input_dim=32,
output_dim=4, # RGB + density
hidden_dim=64,
num_layers=2
)
def forward(self, x, d):
# 位置编码
pos_enc = self.embedder(x)
# 方向编码
dir_enc = sh_encoder(d, degree=2)
# 网络推理
h = self.mlp(torch.cat([pos_enc, dir_enc], dim=-1))
rgb = torch.sigmoid(h[..., :3])
density = torch.relu(h[..., 3])
return rgb, density
4.3 SLAM与NeRF融合
class NeRF_SLAM:
def __init__(self):
self.nerf = InstantNGP()
self.pose_estimator = DeepVO()
self.keyframes = []
def add_frame(self, rgb, depth):
# 估计当前位姿
pose = self.pose_estimator(rgb)
# 选择关键帧
if self._is_keyframe(pose):
self.keyframes.append((rgb, depth, pose))
# 更新NeRF
self._update_nerf()
def _update_nerf(self):
# 从关键帧采样光线
rays = sample_rays_from_keyframes(self.keyframes)
# 训练NeRF
for _ in range(10): # 每帧10次迭代
rgb_pred, density_pred = self.nerf(rays.origins, rays.directions)
loss = photometric_loss(rgb_pred, rays.rgb)
loss.backward()
optimizer.step()
- 语义SLAM融合
5.1 语义建图架构
5.2 动态物体过滤
def filter_dynamic_objects(points, semantics, mask):
"""基于语义和运动信息过滤动态物体"""
# 静态物体类别
static_classes = ['wall', 'floor', 'ceiling', 'furniture']
# 创建掩码
static_mask = np.isin(semantics, static_classes)
motion_mask = mask < 0.1 # 光流运动小
# 组合掩码
valid_mask = static_mask & motion_mask
return points[valid_mask]
5.3 语义引导回环检测
def semantic_loop_detection(query, database):
"""基于语义场景图的回环检测"""
# 构建场景图
query_graph = build_scene_graph(query['objects'])
best_score = -1
best_id = -1
for i, db in enumerate(database):
# 图匹配
graph_similarity = graph_match(query_graph, db['graph'])
# 几何验证
inlier_ratio = geometric_verification(query['points'], db['points'])
# 综合分数
score = 0.7 * graph_similarity + 0.3 * inlier_ratio
if score > best_score:
best_score = score
best_id = i
return best_id, best_score
- 实例:单目深度估计与位姿联合学习
6.1 网络架构
class DepthPoseNet(nn.Module):
def __init__(self):
super().__init__()
# 共享编码器
self.encoder = resnet50(pretrained=True)
# 深度解码器
self.depth_decoder = nn.Sequential(
nn.Conv2d(2048, 1024, 3, padding=1),
nn.Upsample(scale_factor=2),
... # 逐步上采样
nn.Conv2d(64, 1, 3, padding=1) # 深度图
)
# 位姿解码器
self.pose_decoder = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(2048, 7)
)
def forward(self, src, tgt):
# 提取特征
feat_src = self.encoder(src)
feat_tgt = self.encoder(tgt)
# 预测深度
depth_src = self.depth_decoder(feat_src)
# 预测位姿
pose = self.pose_decoder(torch.cat([feat_src, feat_tgt], dim=1))
return depth_src, pose
6.2 自监督损失函数
def compute_loss(src, tgt, depth, pose):
"""计算自监督损失"""
# 重建目标帧
warped_tgt = warp_image(src, depth, pose, K)
# 光度损失
loss_photo = photometric_loss(tgt, warped_tgt)
# 深度平滑损失
loss_smooth = depth_smoothness(depth, src)
# 深度一致性损失
warped_depth = warp_depth(depth, pose)
loss_consist = depth_consistency_loss(warped_depth, tgt_depth)
return loss_photo + 0.1 * loss_smooth + 0.5 * loss_consist
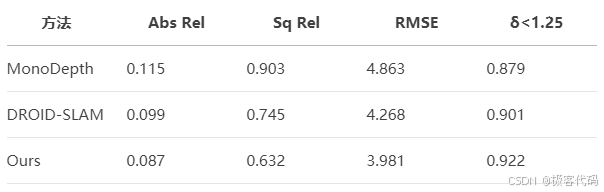
6.3 KITTI 基准测试
- 前沿进展:生成式SLAM
7.1 扩散模型建图
class DiffusionMapper(nn.Module):
def __init__(self):
super().__init__()
self.diffusion = LatentDiffusion(
unet_config,
autoencoder_config
)
self.condition_encoder = CLIPEncoder()
def update_map(self, image, pose):
# 编码观测
cond = self.condition_encoder(image)
# 扩散过程
latents = self.diffusion.sample(
cond,
timesteps=50,
guidance_scale=3.0
)
# 更新地图
self.global_map = self.diffusion.decode(latents)
7.2 语言引导导航
def language_guided_slam(instruction, scene):
"""语言引导的SLAM"""
# 编码语言指令
text_emb = text_encoder(instruction)
# 编码场景
scene_emb = scene_encoder(scene)
# 路径生成
path = path_generator(text_emb, scene_emb)
# 执行导航
for pose in path:
move_to(pose)
update_map(current_view())
7.3 多模态神经地图
class MultiModalMap(nn.Module):
def __init__(self):
super().__init__()
self.map_embedding = nn.Embedding(100000, 256) # 地图网格嵌入
self.fusion = TransformerFusion(256)
def update(self, vision, lidar, audio, pose):
# 编码多模态数据
vis_feat = vision_encoder(vision)
lidar_feat = lidar_encoder(lidar)
audio_feat = audio_encoder(audio)
# 融合特征
fused_feat = self.fusion(vis_feat, lidar_feat, audio_feat)
# 更新地图
map_idx = pose_to_index(pose)
self.map_embedding.weight[map_idx] = fused_feat
关键理论总结
- 深度特征:SuperPoint/SuperGlue超越传统特征
- 端到端位姿:PoseNet与自监督VO实现直接估计
- 神经建图:NeRF实现逼真场景重建
- 语义融合:场景理解提升SLAM鲁棒性
- 生成模型:扩散模型开启建图新范式
下篇预告:第八篇:多传感器融合SLAM——鲁棒性的终极答案
将深入讲解:
· 传感器时空标定理论
· 卡尔曼滤波与因子图融合
· 多传感器紧耦合优化
· 故障检测与容错机制

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 36
36 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)