大数据特征及基本技能
整个世界将变成数据,我认为这还只是数据时代的开始。新浪潮即将来临,很多就业机会即将被夺走。有些人会赶上潮流,变得更加富有和成功。但是对于那些落后的人,未来将是痛苦的。大数据时代已经到来,它俨然成为了企业的战略资源,成为了提高竞争力的关键要素。为此,各个行业都开始用数据指导决策,从微信朋友圈、淘宝京东等电商APP的商品推荐 ,今日头条、抖音快手等媒体的新闻和视频推送,甚至到出行路线优化,...
整个世界将变成数据,我认为这还只是数据时代的开始。新浪潮即将来临,很多就业机会即将被夺走。有些人会赶上潮流,变得更加富有和成功。但是对于那些落后的人,未来将是痛苦的。
大数据时代已经到来,它俨然成为了企业的战略资源,成为了提高竞争力的关键要素。为此,各个行业都开始用数据指导决策,从微信朋友圈、淘宝京东等电商APP的商品推荐 ,今日头条、抖音快手等媒体的新闻和视频推送,甚至到出行路线优化,这背后,都严重依赖于以数据为基础的决策结果。
大数据是什么鬼?
大数据本质也是数据,但是又有了新的特征,包括数据来源广、数据格式多样化(结构化数据、非结构化数据、Excel文件、文本文件等)、数据量大(最少也是TB级别的、甚至可能是PB级别)、数据增长速度快等。
针对以上主要的4个特征我们需要考虑以下问题:
- 数据来源广,该如何采集汇总?对应出现了Sqoop,Cammel,Datax等工具。
- 数据采集之后,该如何存储?对应出现了GFS,HDFS,TFS等分布式文件存储系统。
- 由于数据增长速度快,数据存储就必须可以水平扩展。
- 数据存储之后,该如何通过运算快速转化成一致的格式,该如何快速运算出自己想要的结果?
- 对应的MapReduce这样的分布式运算框架解决了这个问题;但是写MapReduce需要Java代码量很大,所以出现了Hive,Pig等将SQL转化成MapReduce的解析引擎;
- 普通的MapReduce处理数据只能一批一批地处理,时间延迟太长,为了实现每输入一条数据就能得到结果,于是出现了Storm/JStorm这样的低时延的流式计算框架;
- 但是如果同时需要批处理和流处理,按照如上就得搭两个集群,Hadoop集群(包括HDFS+MapReduce+Yarn)和Storm集群,不易于管理,所以出现了Spark这样的一站式的计算框架,既可以进行批处理,又可以进行流处理(实质上是微批处理)。
- 而后Lambda架构,Kappa架构的出现,又提供了一种业务处理的通用架构。
- 为了提高工作效率,加快运速度,出现了一些辅助工具:
- Ozzie,azkaban:定时任务调度的工具。
- Hue,Zepplin:图形化任务执行管理,结果查看工具。
- Scala语言:编写Spark程序的最佳语言,当然也可以选择用Python。
- Python语言:编写一些脚本时会用到。
- Allluxio,Kylin等:通过对存储的数据进行预处理,加快运算速度的工具。
以上大致就把整个大数据生态里面用到的工具所解决的问题列举了一遍,知道了他们为什么而出现或者说出现是为了解决什么问题,进行学习的时候就有的放矢了。
大数据工程师的技能要求有哪些?
大数据工程师技能图谱: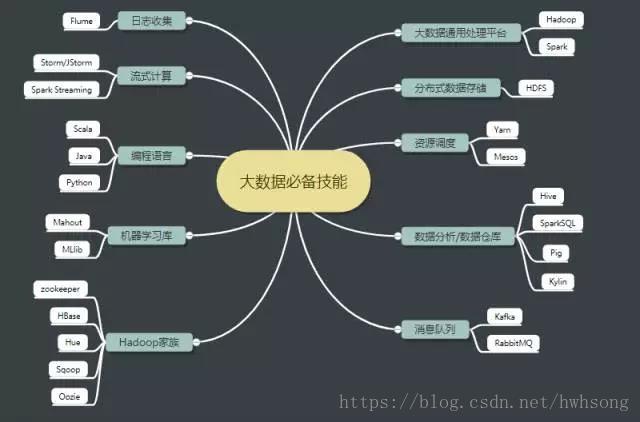
必须掌握的技能11条:
- Java高级(虚拟机、并发)
- Linux 基本操作
- Hadoop(HDFS+MapReduce+Yarn )
- HBase(JavaAPI操作+Phoenix )
- Hive(Hql基本操作和原理理解)
- Kafka
- Storm/JStorm
- Scala
- Python
- Spark(Core+sparksql+Spark streaming)
- 辅助小工具(Sqoop/Flume/Oozie/Hue等)
高阶技能:
- 机器学习算法以及mahout库加MLlib
- R语言
- Lambda 架构
- Kappa架构
- Kylin
- Alluxio

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)