关于前馈神经网络
前馈神经网络初始权重是随机的,后续权重更新是在前一个样本更新后的权重基础上,即每个样本更新一次权重。迭代次数=训练轮数*样本数量1.反向传播顺序:从输出层开始,逐层向后计算δ,再用前向传播时保存的 a (l)和旧权重 计算梯度。2.在线学习(随机梯度下降):每个样本更新一次权重。批量学习:所有样本前向传播后,累加每个样本的 Δw 和 Δb然后求平均(或总和)再更新。3.logsig 特性:导数可用
一、常见神经网络算法
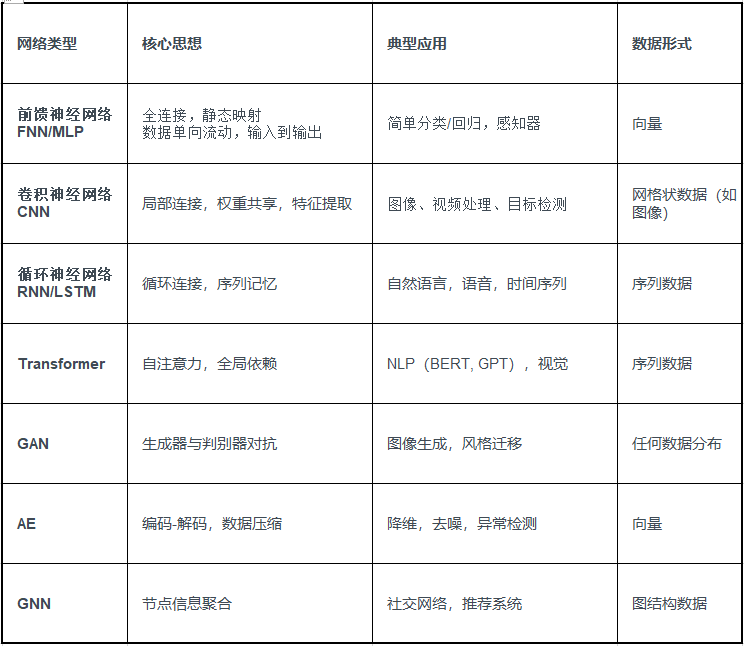
二、前馈神经网络
1、结构
1)输入层(Input Layer):接收外部输入信号。
2)隐藏层(Hidden Layer):对输入信号进行处理和特征提取,可以有多个隐藏层。
3)输出层(Output Layer):产生最终的输出结果。
2、工作原理
如下四层网络:
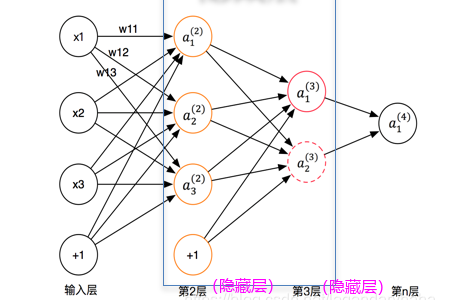
1) 前向传播:
输入数据首先进入输入层,然后通过权重和偏置传递到隐藏层,隐藏层中的节点对输入进行加权求和,并通过激活函数进行非线性转换,最后输出层接收到经过隐藏层处理的信号,并产生最终的输出。
2)激活函数:
激活函数用于在网络中引入非线性,将输入数据映射到一个特定的范围。常见的激活函数包括Sigmoid、Tanh、ReLU等。
激活函数特点:
***logsig:数值范围是0~1,多次经过变换可能会导致数据的相对比例关系发生改变,因为函数的非线性特性会使不同输入值之间的差异在映射后产生不同的变化。
***tansig:数值范围是-1~1,数据在经历了多重的Sigmoid变换后仍维持原先的比例关系。
3)权重和偏置:权重是连接输入层和隐藏层、隐藏层和输出层的连接强度,偏置是加在输入上的一个常数,用于调整激活函数的输出。
3、训练过程
1)损失函数:定义一个损失函数来衡量模型预测值与实际值之间的差异,常见的损失函数包括均方误差(MSE)、交叉熵损失等。
2)反向传播:虽然称为反向传播,但在前馈神经网络中,它实际上是在训练过程中使用的,用于计算损失函数关于权重的梯度。
3)优化算法:通过最小化损失函数来更新网络权重,常见的优化算法包括随机梯度下降(SGD)或其变体Adam、RMSProp等
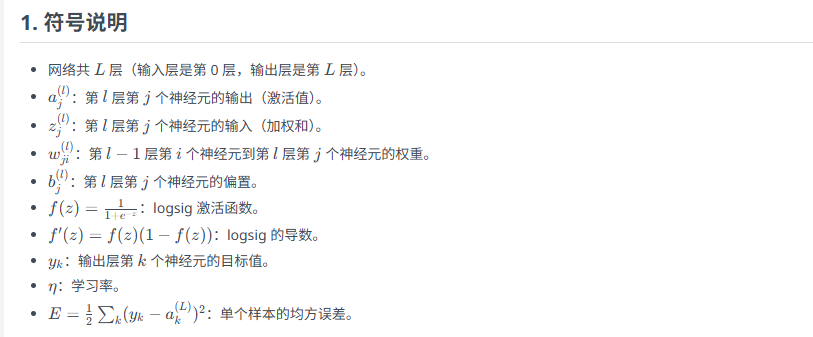
公式总结
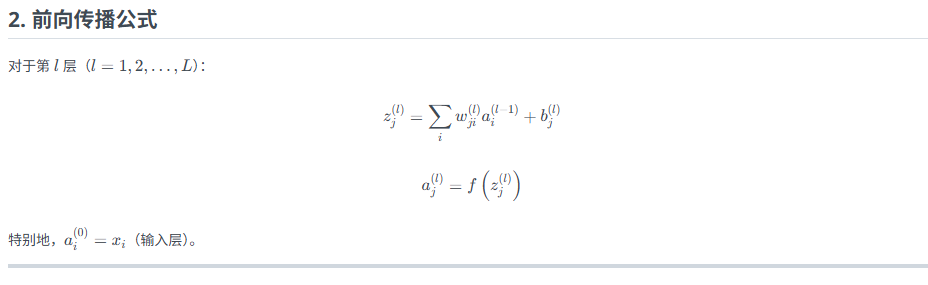

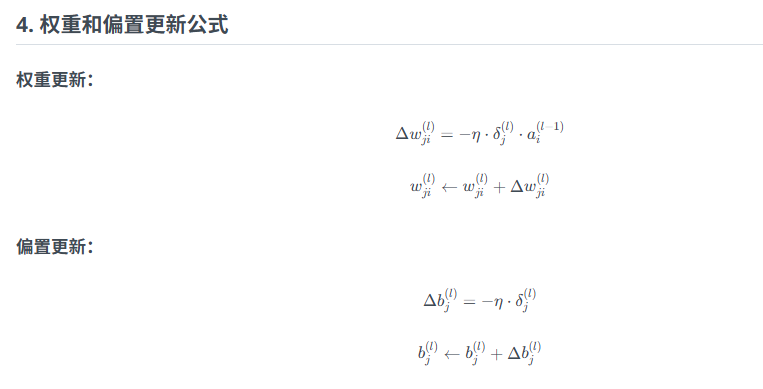
4、注意
4.1 特点
前馈神经网络初始权重是随机的,后续权重更新是在前一个样本更新后的权重基础上,
即每个样本更新一次权重。
迭代次数=训练轮数*样本数量
1.反向传播顺序:从输出层开始,逐层向后计算δ,再用前向传播时保存的 a (l)和旧权重 计算梯度。
2.在线学习(随机梯度下降):每个样本更新一次权重。
批量学习:所有样本前向传播后,累加每个样本的 Δw 和 Δb然后求平均(或总和)再更新。
3.logsig 特性:导数可用激活值直接计算,无需重新计算 z
4.2 优化
4.2.1 缺点:
(1)易形成局部极小值而得不到全局最优
(2)训练次数多,使的学习效率降低,收敛速度慢
(3)隐节点的选取缺乏理论指导
(4)训练时学习新样本有遗忘旧样本的趋势
4.2.2 优化方向:
4.2.2.1更精确的收敛:
1.降低学习率。
2.增加迭代轮数。
3.使用批量梯度下降。(多个样本的总误差一起求平均再更新)
批量梯度下降法:在更新参数时都使用所有的样本来进行更新。
优点:全局最优解,能保证每一次更新权值,都能降低损失函数;易于并行实现。
缺点:当样本数目很多时,训练过程会很慢。
4.2.2.2 提高训练效率:
1.优化学习率

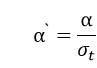
2.加入抖动因子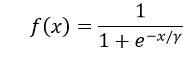
对激活函数加入抖振因子,函数平坦区,γ>1;递增区,γ=1。激活函数效果由蓝线变为黄线: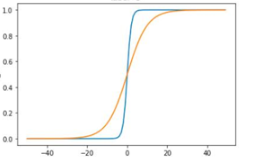
3.优化梯度
1)随机梯度下降法(SGD):
在更新参数时都使用一个样本来进行更新。每一次跟新参数都用一个样本,更新很多次。如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将参数迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次,这种方式计算复杂度太高。
优点:训练速度快;
缺点:准确度下降,并不是全局最优;不易于并行实现。从迭代的次数上来看,随机梯度下降法迭代的次数较多,在解空间的搜索过程看起来很盲目。噪音很多,使得它并不是每次迭代都向着整体最优化方向。
2)小批量梯度下降法:
在更新每一参数时都使用一部分样本来进行更新。为了克服上面两种方法的缺点,又同时兼顾两种方法的优点。
三种方法使用的情况:如果样本量比较小,采用批量梯度下降算法。如果样本太大,使用随机梯度下降算法。在实际的一般情况下,采用小批量梯度下降算法。参考链接: https://blog.csdn.net/qq_44871101/article/details/140045473
3)引入海森矩阵
4.3 隐藏层数怎么选:
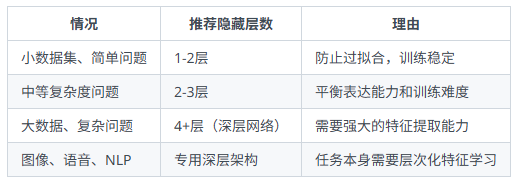
层数过多的问题:
1*梯度消失/爆炸问题
梯度我理解为权重变换量
2*过拟合风险
过拟合,即训练误差小,测试误差大
3*训练难度和计算成本
层数越多,参数越多
4*单层隐藏层已经可以拟合任何连续函数。
5.应用
链接: http://www.uml.org.cn/car/202504084.asp?artid=26779
1.数据来源:
Ux,Uy,r,ax—来源—集成导航系统,
转向角—来源—车辆控制器局域网CAN
2.记录工具:dSPACE MicroAutoBox
3.数据滤波:6Hz截止频率的二阶巴特沃斯低通滤波器
4.计算集群:Intel i7处理器和Nvidia 1080显卡
5.学习耗时:单个训练数据集约需要25分钟
6.物理模型的参数:随机高斯分布初始化
7.神经网络模型的参数:使用Xavier均匀初始化方法进行初始化
8.模型训练时,使用了Adam优化算法
9.初始条件(Ux,Uy,r),初始控制量(δ,F)。
训练目标:均方差MSE
模型预测量:(U_y ) ̂,(r ) ̂
测量目标量:U_y,r
训练样本量:N
网络的权重:θ
模型如下: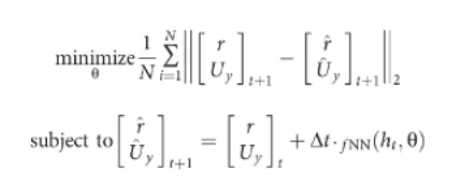

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)