理解循环神经网络(RNN)
RNN(循环神经网络)是一种专门处理序列数据的神经网络,通过隐藏状态传递历史信息,实现对序列数据的记忆功能。其核心特点是每个时间步都会结合当前输入和前一步的隐藏状态生成输出,适用于连续剧理解、语言模型等时序任务。示例代码展示了PyTorch实现的简单RNN模型,包含输入层、RNN层和全连接层,演示了如何处理二维序列数据(batch_size=2, seq_len=5)并输出分类结果。该模型通过维护
一、什么是RNN
RNN (Recurrent Neural Network) 是一种专门处理序列数据的神经网络。
与普通的前馈神经网络(如 CNN、MLP)不同,RNN 在每个时间步都会“记住”前一步的信息,并将其传递到下一步,从而具备短期记忆能力。
核心公式:
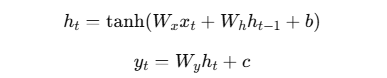
- x(t):当前输入
- h(t-1):前一时刻的隐藏状态
- h(t):当前隐藏状态
- y(t):当前输出
RNN 的核心思想:逐步接收序列输入,依靠隐藏状态在时间上传递记忆,并基于当前输入与历史信息共同生成输出。
简易理解(生活类比):
想象你在看一场连续剧(一个序列),你的大脑就像 RNN:
- 输入x(t):每一集剧情
- 隐藏状态h(t):你对剧情的记忆(会受前几集影响)
- 输出y(t):你对当前剧情的感受或预测(比如“这集可能会反转”)
看第 5 集时,你不可能只看第 5 集,还会带着前 4 集的记忆。
这就是 RNN:把记忆往前传。
二、简单示例
import torch
import torch.nn as nn
# 一个最简单的 RNN 模型
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x: [batch, seq_len, input_size]
out, hidden = self.rnn(x) # out: 所有时刻输出, hidden: 最后时刻的隐藏状态
out = self.fc(out[:, -1, :]) # 只取最后时刻的隐藏状态用于分类
return out
# 模拟输入数据
batch_size = 2
seq_len = 5
input_size = 3
hidden_size = 4
output_size = 2
model = SimpleRNN(input_size, hidden_size, output_size)
# 输入 (batch=2, 序列长度=5, 每个输入向量维度=3)
x = torch.randn(batch_size, seq_len, input_size)
y = model(x)
print("输入 shape:", x.shape) # [2, 5, 3]
print("输出 shape:", y.shape) # [2, 2]
| self.rnn = nn.RNN(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) |
nn.RNN:核心循环层- 输入
x的形状是[batch, seq_len, input_size] - 输出
out的形状是[batch, seq_len, hidden_size],包含每个时间步的隐藏状态 hidden的形状是[1, batch, hidden_size],是最后时刻的隐藏状态
- 输入
nn.Linear:全连接层,把最后时刻的隐藏状态映射到指定的output_size
| out, hidden = self.rnn(x) out = self.fc(out[:, -1, :]) # 取最后一个时间步的隐藏状态 |
out[:, -1, :]取序列最后一个时间步的输出(形状[batch, hidden_size])。fc层把它变换为[batch, output_size],得到分类结果
| x.shape = [2, 5, 3] # batch=2, 序列长度=5, 每个输入3维 y.shape = [2, 2] # batch=2, 输出是2维分类结果 |
- 模型一次可以处理两个序列(batch=2)
- 每个序列有 5 个时间步,每个时间步是一个 3 维向量
- 输出是
[2, 2],即两个样本的 2 类预测结果
三、RNN 的应用
1、自然语言处理
- 语言模型:预测下一个单词
- 机器翻译:输入英语序列,输出中文序列
- 情感分析:一句话正面还是负面
2、语音处理
- 语音识别:语音帧序列 → 文本序列
- 唤醒词检测
3、时间序列预测
- 股票价格预测
- 温度/气象预测
DeepSpeech 的核心建模单元就是 RNN,DeepSpeech(以 DeepSpeech 0.9.x Mozilla 开源版为例)的主要网络结构如下:
|

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)