AI量化 - DeepLOB:用于限价订单簿的深度卷积神经网络Deep convolutional neural networks for limit order books
AI量化,cnn+lstm训练订单簿,可用于高频交易。
目录
摘要
今天,我们来看看使用AI进行量化交易。代码解析部分在另一篇文章。
DeepLOB:用于限价订单簿的深度卷积神经网络
参考资料:
DeepLOB: Deep convolutional neural networks for limit order books - Zhang Z, Zohren S, Roberts S.
https://github.com/zcakhaa/DeepLOB-Deep-Convolutional-Neural-Networks-for-Limit-Order-Books
张子豪,斯特凡·佐伦,斯蒂芬·罗伯茨 摘要
我们开发了一种大规模深度学习模型,用于从现金股权的限价订单簿(LOB)数据中预测价格变动。该架构利用卷积滤波器捕捉限价订单簿的空间结构,并结合长短期记忆(LSTM)模块捕捉较长时间的依赖关系。所提出的网络在基准LOB数据集[1]上超越了所有现有的最先进算法。在更现实的设置中,我们使用伦敦证券交易所一年的市场报价数据测试了我们的模型,该模型在多种工具上实现了非常稳定的样本外预测准确性。重要的是,我们的模型能够很好地推广到未包含在训练集中的工具,表明模型能够提取通用特征。为了更好地理解这些特征并超越“黑箱”模型,我们进行了敏感性分析,以了解模型预测背后的逻辑,并揭示限价订单簿中最相关的组成部分。模型能够提取稳健特征并很好地推广到其他工具,这一特性使其在许多其他应用中具有重要价值。
I. 引言
在当今竞争激烈的金融世界中,超过一半的市场使用电子限价订单簿(LOB)[2]来记录交易[3]。与传统的报价驱动市场不同,在报价驱动市场中,交易者只能以做市商公开的价格买卖资产,现在交易者可以直接查看交易所限价订单簿中的所有未执行限价订单1。由于限价订单根据其提交价格被分为不同级别,限价订单簿随时间演变成为一个多维问题,其元素代表买卖双方在多个级别上的众多价格和订单量/规模。 限价订单簿是一个高维度的复杂动态环境,建模复杂性使得传统方法难以应对。数学金融通常由价格序列演变模型主导。
这导致了一系列类马尔可夫模型,带有随机驱动项,例如向量自回归模型(VAR)[4]或自回归综合移动平均模型(ARIMA)[5]。这些模型为了避免过多的参数空间,通常依赖于手工设计的特征。然而,鉴于每天生成数十亿的电子市场报价,采用更现代的数据驱动机器学习技术来提取这些特征是自然的。 此外,限价订单数据与其他金融时间序列数据一样,众所周知是非平稳的,并且受随机性的主导。特别是,订单簿较深层次的订单往往因预期未来价格变动而被放置或取消,因此更容易受到噪声的影响。其他问题,例如拍卖和暗池[6],也增加了额外的困难,使环境更加不可观察。有兴趣的读者可参考[7],其中回顾了这些问题中的若干。
在本文中,我们设计了一种新颖的深度神经网络架构,结合了卷积层和长短期记忆(LSTM)单元,以预测大规模高频限价订单簿数据中的未来股价变动。我们模型相对于先前研究[8]的一个优势是,它能够通过从高度噪声数据中提取代表性特征,适应多种股票。
为了避免手工设计特征的局限性,我们使用了所谓的Inception模块[9],将卷积层和池化层包装在一起。Inception模块有助于推断不同时间范围内的局部交互。生成的特征图随后被传入LSTM单元,以捕捉动态时间行为。
我们在公开的LOB数据集FI-2010[1]上测试了我们的模型,该方法显著优于所有现有的最先进算法。然而,FI-2010数据集仅包含10个连续日的降采样预标准化数据,来自流动性较低的市场。虽然它是一个有价值的基准集,但可以说不足以完全验证算法的稳健性。为了确保模型的泛化能力,我们进一步使用伦敦证券交易所(LSE)一年的订单簿数据对五只股票进行测试。为了尽量减少对回测数据过拟合的问题,我们在单独的验证集上仔细优化任何超参数,然后再进行样本外测试。我们的模型在三个月的测试期内为多只股票提供了稳健的样本外预测准确性。 除了在时间意义上对训练集中的股票进行样本外数据测试外,我们还对未包含在训练集中的股票(在时间和数据流意义上均为样本外)进行了测试。
有趣的是,我们在整个测试期间仍然获得了良好的结果。我们认为,这一观察结果不仅表明所提出的模型能够从订单簿中提取稳健特征,还表明订单簿中存在调制股票需求和价格的通用特征。模型能够转移到新工具上,为未来的工作提供了许多可能性。
为了展示模型的实用性,我们在简单的交易模拟中使用它。我们专注于流动性充足的股票,以减少滑点和市场影响。事实上,这些股票通常比流动性较低的股票更难预测。由于我们的交易模拟主要用作模型之间的比较方法,我们假设交易以中间价格2进行,并比较扣除费用前的总利润。前者假设交易的一方可以被动进入,后者假设不同模型交易的量相似,因此会受到相似费用的影响。我们在这里的重点是使用模拟作为在交易环境中模型预测相对价值的衡量标准。在这些简化假设下,我们的模型实现了显著的正收益,风险相对较小。
尽管我们的网络表现良好,但像深度神经网络这样的复杂“黑箱”系统在金融应用中的使用受到限制,除非我们对模型预测背后的逻辑有所了解。在这里,我们利用模型无关的LIME方法[10]突出订单簿中高度相关的组成部分,以更好地理解我们的预测和模型输入之间的关系。令人放心的是,这些符合价格和订单簿中量的合理(尽管可能不寻常)的活动模式。
大纲:本文的其余部分安排如下。第II节介绍背景和相关工作。第III节描述限价订单数据及数据准备的各个阶段。第IV节介绍我们的网络架构,并说明模型每个组成部分的理由。第V节将我们的工作与一大组流行方法进行比较。第VI节总结我们的发现,并考虑扩展和未来工作。
II. 背景与相关工作
关于股票市场可预测性的研究在金融文献中有悠久的历史,例如[11, 12]。尽管对市场效率的看法各异,许多广为接受的研究表明,金融市场在某种程度上是可预测的[13, 14, 15, 16]。尝试预测金融时间序列的两大类工作大体上可以分为统计参数模型和数据驱动的机器学习方法[17]。传统统计方法通常假设研究的时序数据是从参数过程中生成的[18]。
然而,人们一致认为股票回报的行为更加复杂,通常表现出高度非线性[19, 20]。机器学习技术能够捕捉这种任意非线性关系,几乎不需要关于输入数据的先验知识[21]。 最近,使用机器学习算法预测限价订单簿数据引起了广泛关注[1, 22, 23, 24, 25, 26, 27, 20, 28, 29]。在众多机器学习技术中,预处理或特征提取通常是必须的,因为金融时间序列数据高度随机。
已实施的通用特征提取方法包括主成分分析(PCA)和线性判别分析(LDA),如[24]中的工作。然而,这些提取方法是静态预处理步骤,未优化以最大化观察它们的模型的总体目标。在[25, 24]的工作中,特征包(Bag-of-Features,BoF)模型被表达为神经层,模型通过反向传播算法进行端到端训练,在FI-2010数据集[1]上取得了显著更好的结果。
这些工作表明数据驱动方法在从大量数据中提取代表性特征的重要性。在我们的工作中,我们提倡端到端训练,并展示深度神经网络本身不仅能带来更好的结果,还能很好地转移到未包含在训练集中的新工具上——表明网络能够从原始数据中提取“通用”特征。 可以说,现代深度学习的关键贡献之一是将特征提取和表示作为学习模型的一部分。卷积神经网络(CNN)[30]是一个典型例子,其中信息提取以滤波器组的形式自动调整到整个网络旨在优化的效用函数。CNN已在多个应用领域成功应用,例如对象跟踪[31]、对象检测[32]和分割[33]。
然而,采用CNN分析金融微观结构数据的已发表工作较少[34, 35, 26],现有的CNN架构相当简单,缺乏深入研究。就像从“AlexNet”[36]到“VGGNet”[37]的转变一样,我们展示了精心设计的网络架构可以带来比所有现有方法更好的结果。 长短期记忆(LSTM)[38]最初被提出用于解决循环神经网络的梯度消失问题[39],并在语言建模[40]和序列到序列学习[41]等应用中广泛使用。与在金融市场中应用较少的CNN相比,LSTM近年来颇受欢迎,[42, 28, 43, 44, 45, 46, 47, 20]均利用LSTM分析金融数据。特别是,[20]使用1000只股票的限价订单数据测试了四层LSTM模型。其结果显示了跨时间的稳定样本外预测准确性,表明深度学习方法的潜在优势。
据我们所知,还没有工作将CNN与LSTM结合以预测股价变动,这是首次将嵌套CNN-LSTM模型应用于原始市场数据进行广泛研究的尝试。特别是,在此背景下使用Inception模块是新颖的,对于推断提取特征的“衰减率”至关重要。
III. 数据、标准化与标签
A. 限价订单簿
我们首先介绍限价订单簿(LOB)的一些基本定义。
关于市场微观结构的经典参考文献请见[48, 49],关于LOB的简短评论请见[7]。在此我们遵循[7]的惯例。限价订单簿有两种类型的订单:买单和卖单。
买单(卖单)是以低于(高于)指定价格购买(出售)资产的订单。买单具有价格Pb(t)和规模/量Vb(t),卖单具有价格Pa(t)和规模/量Va(t)。P(t)和V(t)都是表示资产在不同价格级别的值的向量。
图1说明了上述概念。
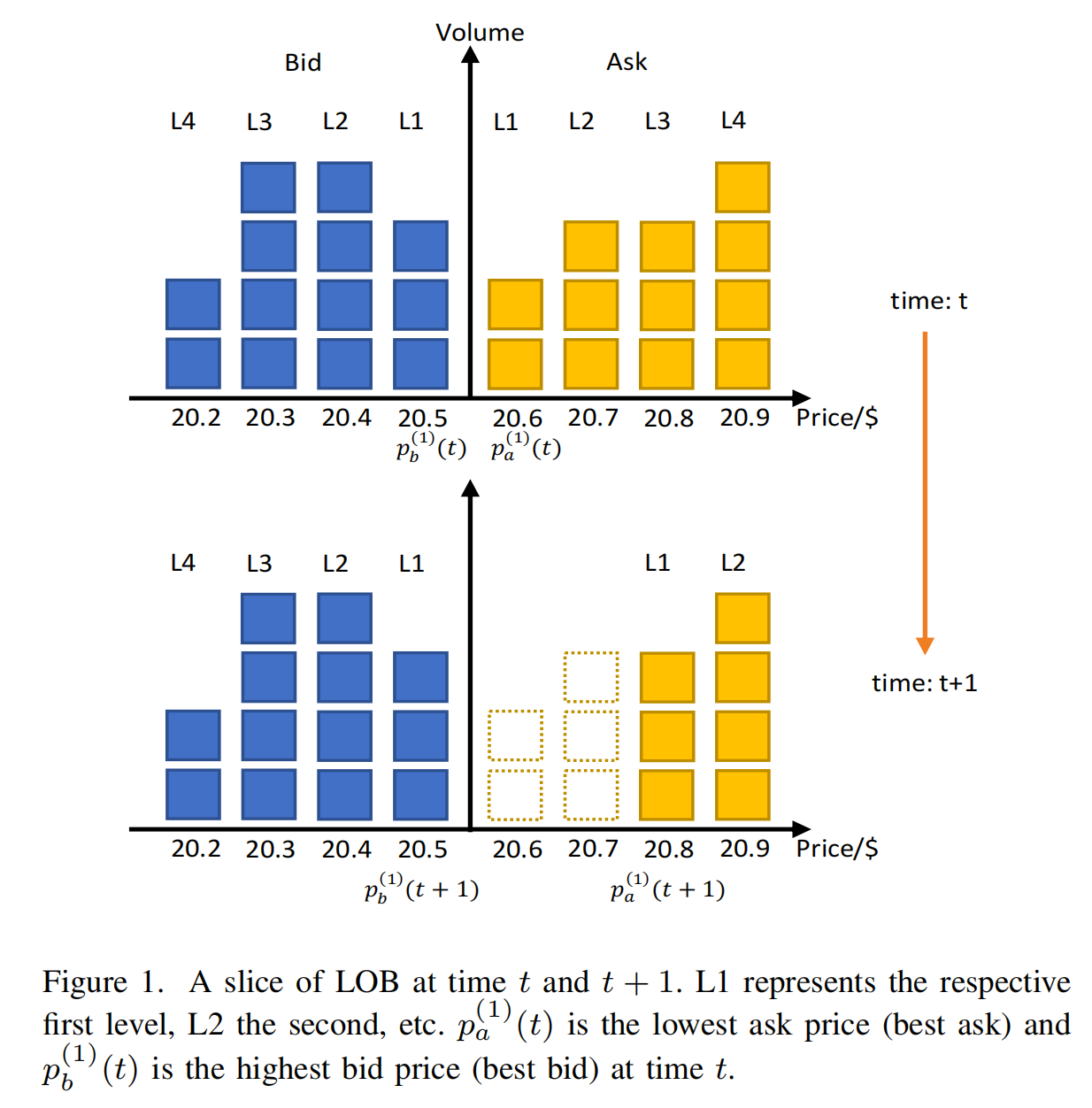
上图显示了时间t的限价订单簿的一个片段。图中的每个方块代表一个标称规模为1的订单。
为简单起见,实际中不同订单的规模可能不同。
蓝色条表示买单,黄色条表示卖单。订单根据其提交价格被分为不同级别,其中L1表示第一级,依此类推。每个级别包含两个值:价格和量。在买单方面,Pb(t)和Vb(t)在此示例中为4维向量。我们用p^(1)_b(t)表示可用的最高买单价格(第一买单级别)。
类似地,p^(1)_a(t)表示最低卖单价格(第一卖单级别)。下图显示了在时间t+1进入的购买5股的市场订单的行为。因此,第一和第二卖单级别完全针对该订单执行,p^(1)_a(t+1)从时间t的20.6移动到20.8。
B. 输入数据
我们在两个数据集上测试了我们的模型:
FI-2010数据集[1]和伦敦证券交易所(LSE)一年的限价订单簿数据。
FI-2010数据集[1]是第一个公开可用的高频限价订单数据和提取的时间序列数据的基准数据集,涵盖纳斯达克北欧股票市场五只股票连续10天的数据。许多早期算法都在该数据集上进行了测试,我们使用它来与其他算法进行公平比较。
然而,10天的数据量不足以完全测试算法的稳健性和泛化能力,因为对回测数据过拟合的问题很严重,我们通常期望信号在几个月内保持一致。 为了解决上述问题,我们在一年的限价订单簿数据上训练和测试我们的模型,数据涵盖了劳埃德银行、巴克莱银行、乐购、英国电信和沃达丰。这五只工具是伦敦证券交易所上市的流动性最高的股票之一。
通常在流动性较高的股票上训练模型更困难,但与此同时,这些工具在交易时受价格影响较小,因此用于评估性能的简单交易模拟更加现实。数据包括上述股票的所有LOB更新,涵盖了2017年1月3日至12月24日的全部交易日,我们将其限制在08:30:00至16:00:00的区间,以确保仅包含正常交易活动,不包括拍卖。LOB的每个状态包含买卖双方各10个级别,每个级别包含价格和量信息。因此,每个时间戳有40个特征。
需要注意的是,FI-2010数据集实际上是降采样的限价订单簿数据,因为作者遵循[50]通过每10个非重叠事件块创建额外特征。我们未对数据进行任何处理,仅将原始订单簿信息输入算法。
总体而言,我们的LSE数据集由12个月组成,包含超过1.34亿个样本。平均每天每只股票有150,000个事件。事件在时间上的间隔不规律,两个事件之间的时间间隔∆k,k+1可能从几分之一秒到几秒不等,数据集中平均为0.192秒。
我们将前6个月作为训练数据,接下来的3个月作为验证数据,最后3个月作为测试数据。在高频数据的背景下,3个月的测试数据对应于数百万次观察,因此为测试模型性能和估计模型准确性提供了足够的空间。
C. 数据标准化与标签
数据集:
FI-2010数据集[1]提供了三种不同的标准化方法:z分数、最小-最大标准化和十进制精度标准化。我们使用了未经任何修改的z分数标准化数据,发现使用其他两种标准化方案时差异不大。
对于LSE数据集,我们再次使用标准化(z分数)来标准化数据,但使用前5天数据的均值和标准差来标准化当天数据(对每只工具单独标准化)。
我们强调标准化的重要性,因为机器学习算法的性能通常依赖于此。由于金融时间序列通常经历制度变化,使用静态标准化方案对一年的数据集不合适。
上述方法是动态的,标准化后的数据通常落入合理范围。
我们在两个数据集中都使用最近100个LOB状态作为模型输入。具体来说,单个输入定义为X = [x1, x2, · · · , xt, · · · , x100]^T ∈ R^(100×40),其中xt = [p^(a_i)(t), va^(i)(t), p^(b_i)(t), vb^(i)(t)]^n_i=1=10。p^(i)和v^(i)表示限价订单簿第i级别的价格和量。
在对限价订单数据标准化后,我们使用中间价格
pt = (p^(1)_a(t) + p^(1)_b(t)) / 2, (1)
来创建表示价格变动方向的标签。
尽管没有订单可以精确地在中间价格成交,但它表达了资产的总体市场价值,通常用于表示资产价格的单一数字。
由于金融数据高度随机,如果我们简单比较pt和pt+k来决定价格变动,生成的标签集将会有噪声。(注释:波动太大,必须平滑处理)
在[1]和[26]的工作中,介绍了两种平滑标签方法。我们在此简要回顾这两种方法。首先,令m−表示前k个中间价格的均值,m+表示后k个中间价格的均值:
m−(t) = (1/k) Σ_(i=0)^k pt−i
m+(t) = (1/k) Σ_(i=1)^k pt+i (2)
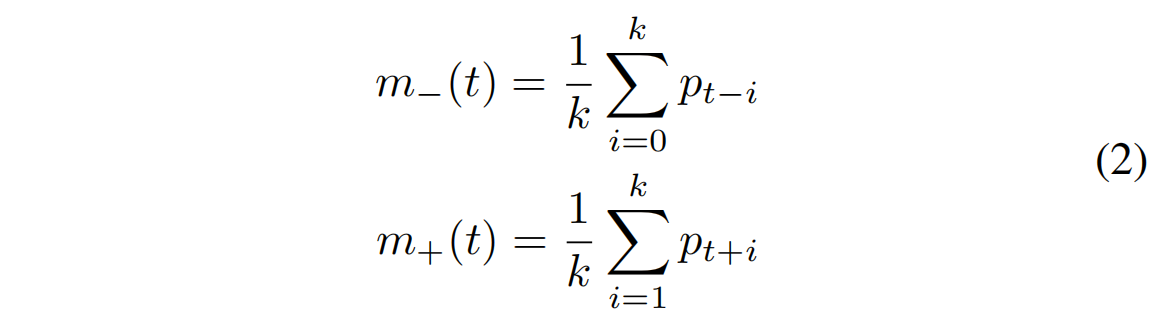
其中pt是方程(1)中定义的中间价格,k是预测 horizon。两种方法都使用中间价格的百分比变化(lt)来决定方向。
我们现在可以定义
lt = (m+(t) − pt) / pt (3)
lt = (m+(t) − m−(t)) / m−(t) (4)
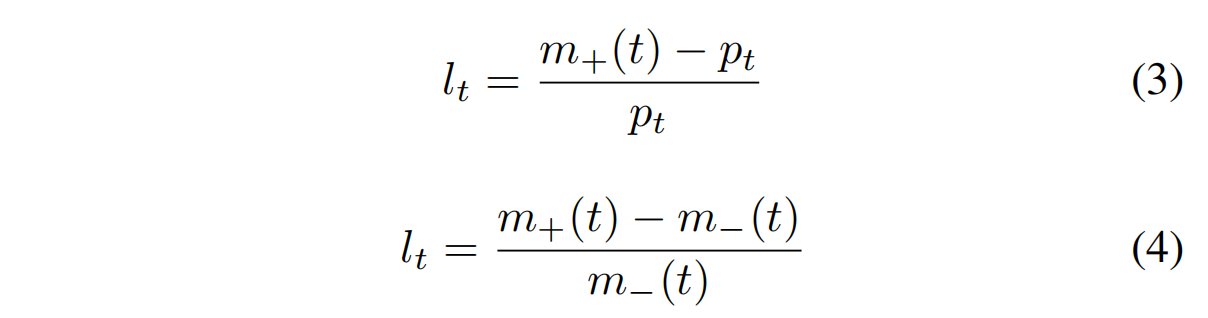
两者都是定义时间t价格变动方向的方法,前者(方程3)在[1]中使用,后者(方程4)在[26]中使用。 标签随后根据百分比变化(lt)的阈值(α)来决定。
如果lt > α或lt < −α,我们将其定义为上升(+1)或下降(−1)。
对于其他情况,我们认为是平稳(0)。
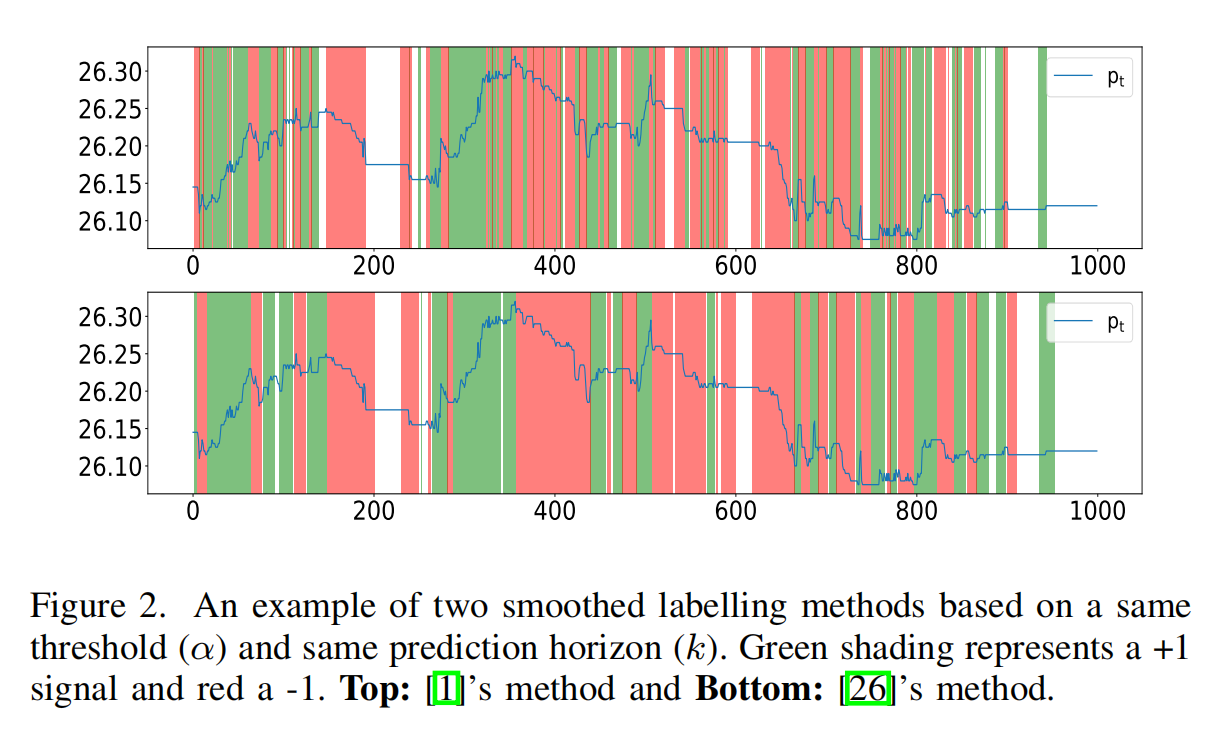
图2提供了在相同阈值(α)和相同预测horizon(k)下两种标签方法的图形说明。所有分类为下降(−1)的标签显示为红色区域,上升(+1)为绿色区域。未着色(白色)区域对应于平稳(0)标签。
FI-2010数据集[1]采用了方程3的方法,我们直接使用其标签以与其他方法进行公平比较。然而,生成的标签如图2顶部所示一致性较差,因为此方法仅对未来价格进行平滑,更贴近真实价格。这对于设计交易算法基本上是有害的,因为信号在这里不一致,导致许多冗余的交易行为,从而产生更大的交易成本。
(博主:这里的一致性,我理解为,横坐标800~900处,上图一会红一会绿来回切换,而下图则稳定不少)
此外,FI-2010数据集是在2010年收集的,与现在相比,工具的流动性较低。我们在伦敦证券交易所的数据上尝试了[1]的方法,发现生成的标签相当随机,因此我们对LSE数据集采用了方程4的方法,以产生更一致的信号。
IV. 模型架构
A. 概述
我们在此详细介绍我们的网络架构,它包括三个主要构建模块:标准卷积层、Inception模块和LSTM层,如图3所示。
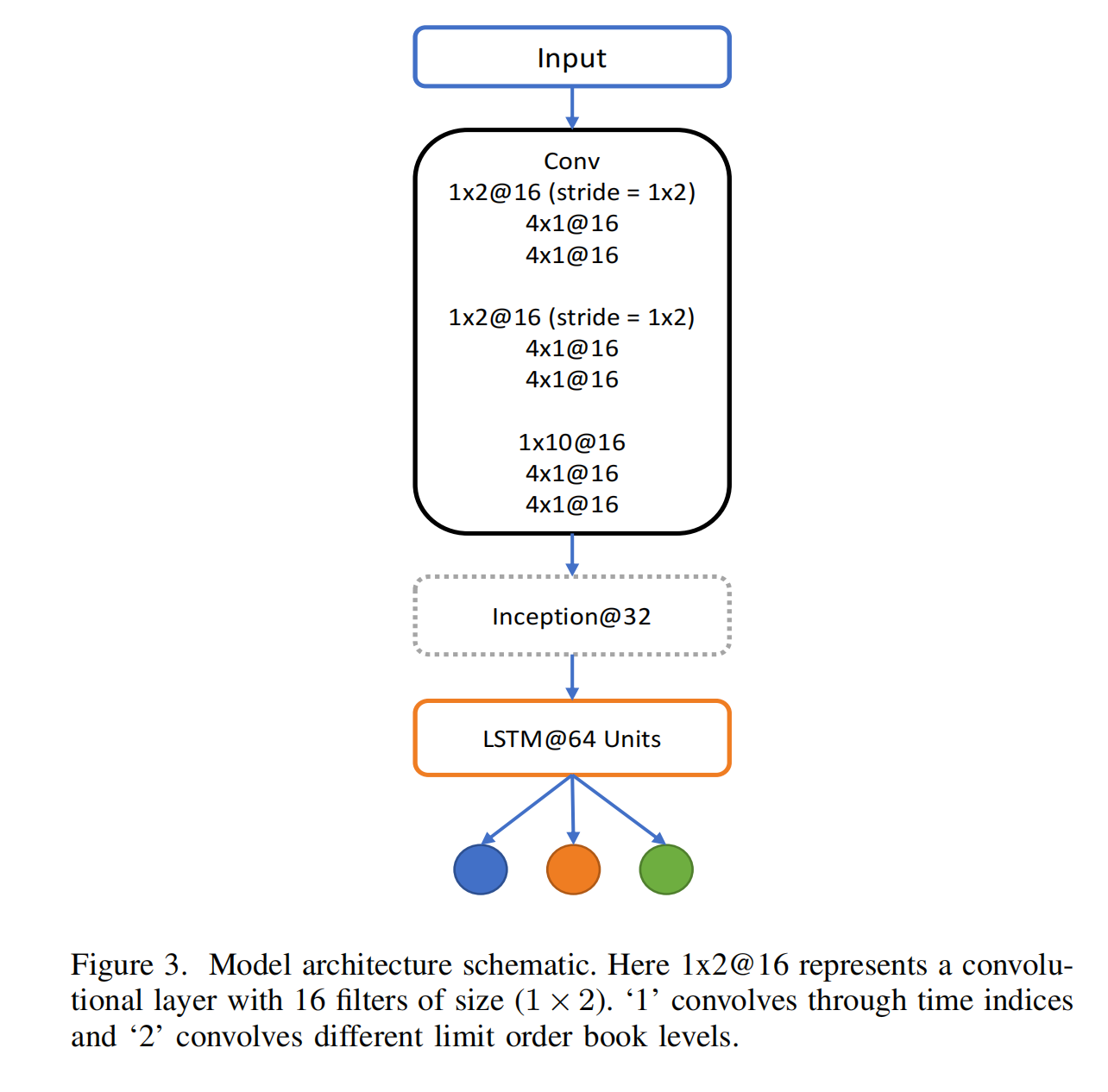
使用CNN和Inception模块的主要思想是自动化特征提取过程,因为金融数据以噪声大、信噪比低而著称。
技术指标如MACD和相对强弱指数常作为输入,预处理机制如主成分分析(PCA)[51]常用于转换原始输入。
然而,这些过程并非易事,它们带有隐含假设,并且金融数据是否能用固定参数的参数模型很好地描述尚存疑问。
在我们的工作中,我们仅需要LOB价格和规模的历史作为算法输入。
权重在推理过程中学习,从大型训练集中学习的特征是数据自适应的,消除了上述约束。然后使用LSTM层捕捉结果特征中的额外时间依赖性。我们注意到,卷积层已经捕捉了非常短的时间依赖性,因为它以LOB的“时空图像”作为输入。
B. 各组件详情
a) 卷积层
近期电子交易算法的发展常常在短时间内提交和取消大量限价订单,作为其交易策略的一部分[52]。
这些行为通常发生在订单簿的较深处,[7]指出超过90%的订单以取消而非匹配结束,因此从业者认为远离最佳买价和卖价的级别在任何LOB中用处较小。
此外,[53]的工作表明,最佳卖价和最佳买价(L1-Ask和L1-Bid)对价格发现的贡献最大,其他级别的贡献明显较小,估计仅为20%。
因此,将所有级别信息输入神经网络是多余的,因为较深层次的级别用处较小,甚至可能具有误导性。
自然地,我们可以通过汇总较深层次的信息来平滑这些信号。我们注意到,任何CNN架构中使用的卷积滤波器从信号处理的角度来看是离散卷积或有限冲激响应(FIR)滤波器[54]。
FIR滤波器是流行的去噪目标信号的平滑技术,易于实现和使用。我们可以将任何FIR滤波器写为以下形式:
y(n) = Σ_(k=0)^M bk x(n − k) (5)
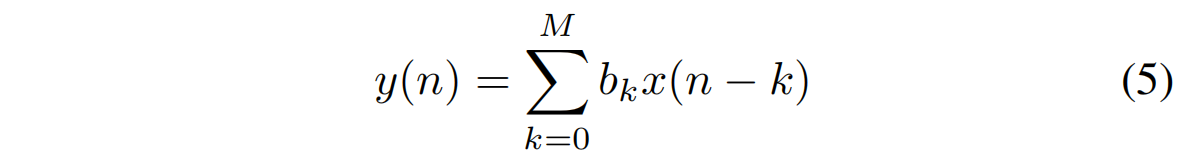
其中输出信号y(n)是输入信号x(n)过去有限值的加权和。滤波器阶数表示为M,bk是滤波器系数。
在卷积神经网络中,滤波器核的系数不是通过传统信号滤波理论的统计目标获得的,而是作为网络推断的自由度,以优化其输出值函数。 第一卷积层的细节不可避免地需要一些考虑。由于卷积层使用小核在输入数据上“扫描”,限价订单簿信息的布局至关重要。
回顾一下,我们采用最近100次订单簿更新形成单个输入,每个时间戳有40个特征,因此单个输入的大小为(100×40)。我们将40个特征组织如下:
{p^(a_i)(t), va^(i)(t), p^(b_i)(t), vb^(i)(t)}^n_i=1=10 (6)
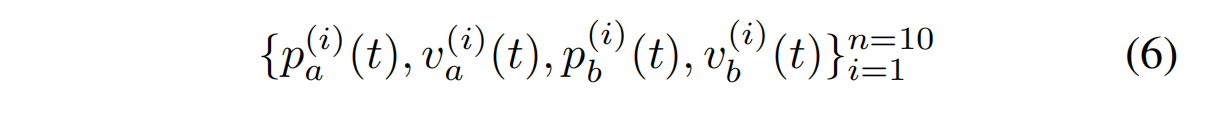
其中i表示限价订单簿的第i级别。我们第一个卷积滤波器的大小为(1×2),步幅为(1×2)。第一层实质上汇总了每个订单簿级别的价格和量信息{p^(i), v^(i)}。这里使用步幅是必要的,因为卷积层的一个重要属性是参数共享。这一属性吸引人,因为估计的参数较少,很大程度上避免了过拟合问题。
然而,如果没有步幅,我们会将相同的参数应用于{p^(i), v^(i)}和{v^(i), p^(i+1)}。换句话说,p^(i)和v^(i)会共享相同的参数,因为核滤波器移动一步,这显然是错误的,因为价格和量形成不同的动态行为。
由于第一层仅在每个订单簿级别捕捉信息,我们期望通过整合多个订单簿级别的信息来提取代表性特征。我们可以通过使用另一个卷积层(滤波器大小为(1×2),步幅为(1×2))来实现这一点。
生成的特征图实际上形成了[55]定义的微观价格:
p_micro price = I p^(1)_a + (1 − I) p^(1)_b
I = vb^(1) / (va^(1) + vb^(1)) (7)
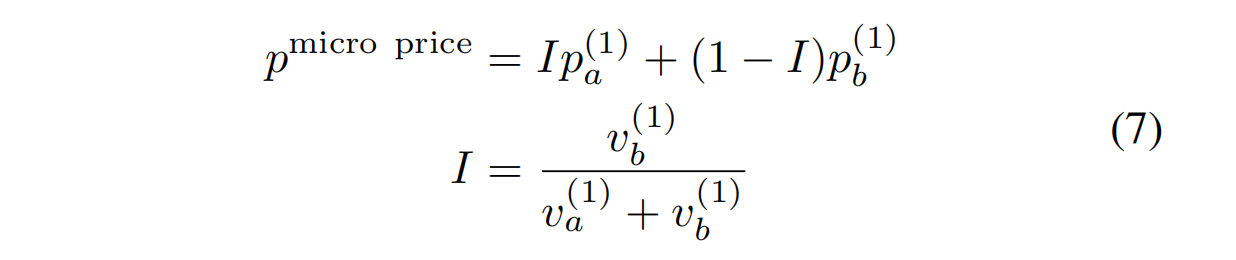
权重I称为不平衡。
微观价格是一个重要指标,因为它考虑了买卖双方的量,买卖量之间的不平衡是下一价格变动的强烈指标。这种不平衡特征已被多个研究者报道[56, 57, 58, 59, 60]。
与仅考虑第一订单簿级别的微观价格不同,我们利用卷积为所有LOB级别形成微观价格,因此在两个带步幅的层后,特征图大小为(100,10)。
最后,我们使用大小为(1×10)的大滤波器整合所有信息,在Inception模块之前,特征图的维度为(100,1)。
我们在每个卷积层应用零填充,以确保输入的时间维度不变,并使用Leaky整流线性单元(Leaky-ReLU)[61]作为激活函数。Leaky-ReLU的超参数(单位不活跃时的微小梯度)设为0.01,通过在验证集上的网格搜索评估。
卷积的另一个重要属性是平移等变性[62]。具体来说,函数f(x)对函数g等变,如果f(g(x)) = g(f(x))。
例如,假设存在一个主要分类特征m,位于图像I(x, y)的(xm, ym)。如果我们将I的每个像素向右移动一个单位,得到新图像I',其中I'(x, y) = I(x − 1, y)。我们仍然可以在I'中获得主要分类特征m',且m = m',而m'的位置将是(xm' , ym') = (xm − 1, ym)。
这对时间序列数据很重要,因为卷积可以找到对最终输出决定性的通用特征。在我们的案例中,假设在时间t获得了研究不平衡的特征。如果在输入的稍后时间t'发生相同事件,相同的特征可以在t'提取。
我们仅在Inception模块中使用池化层。尽管池化层帮助我们找到对输入平移不变的表示,但池化的平滑性质可能导致欠拟合。常见的池化层是为图像处理任务设计的,当我们只关心输入中是否存在某些特征而非它们的位置时,这些层最为强大[62]。时间序列数据与图像的特性不同,代表性特征的位置很重要。
我们的经验表明,至少在卷积层中,池化层会导致LOB数据的欠拟合问题。然而,我们认为池化很重要,应设计新的池化方法来处理时间序列数据,因为这是提取不变特征的有前景的解决方案。
b) Inception模块
我们注意到,标准卷积层的所有滤波器大小固定。例如,如果我们使用大小为(4×1)的滤波器,我们会捕捉四个时间步长内的局部交互。
然而,通过使用Inception模块将多个卷积包装在一起,我们可以捕捉多个时间尺度上的动态行为。我们发现这对结果模型的性能有所改进。
Inception模块的理念也可以视为技术分析中使用不同的移动平均。实践者通常使用不同衰减权重的移动平均来观察时间序列动能[63]。如果采用较大的衰减权重,我们会得到一个更平滑的时间序列,很好地表示长期趋势,但可能会错过高频数据中重要的小波动。在实践中,设置正确的衰减权重是一项艰巨的任务。
相反,我们可以使用Inception模块,权重随后在反向传播过程中学习。 在我们的案例中,我们通过使用1×1卷积将输入拆分为一小组较低维表示,然后通过一组滤波器(此处为3×1和5×1)转换表示,然后合并输出。
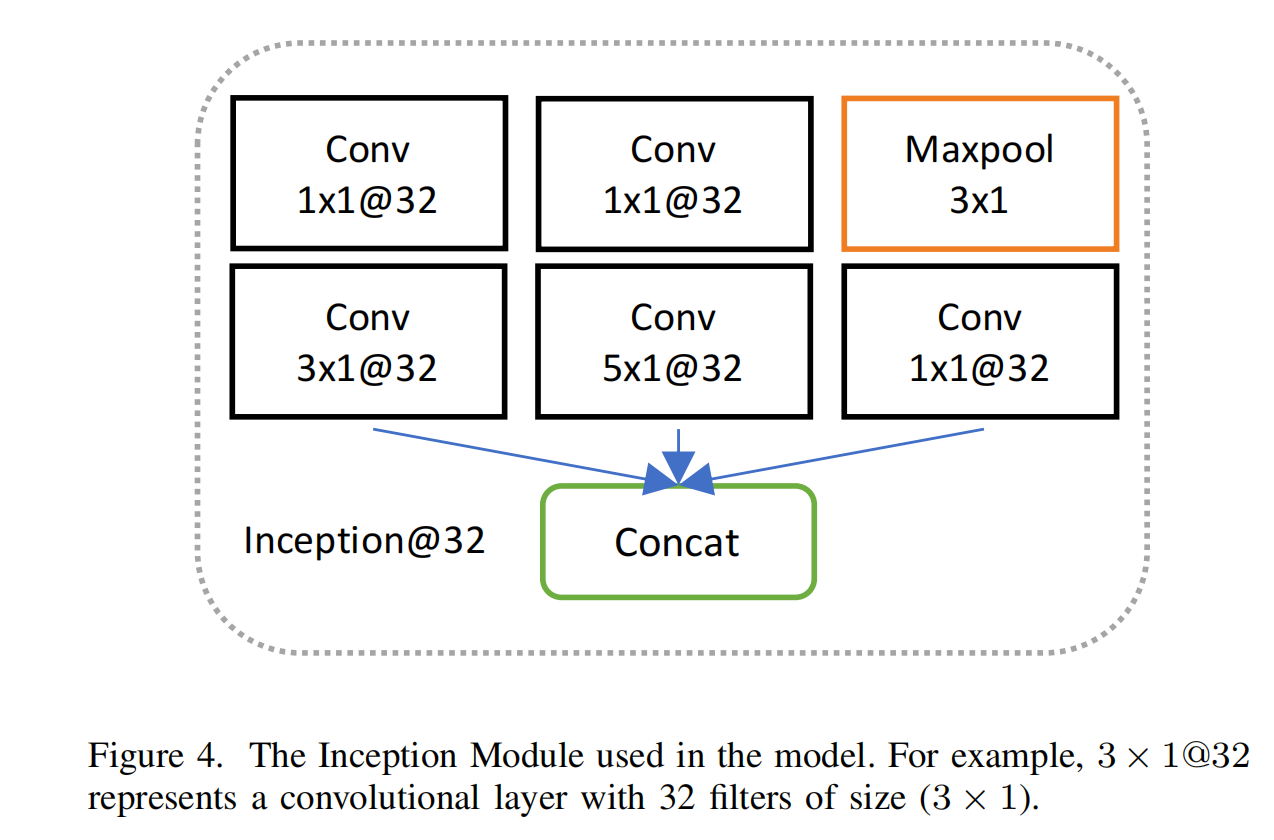
在Inception模块内部使用最大池化层,步幅为1,零填充。“Inception@32”表示一个模块,表明该模块中的所有卷积层有32个滤波器,方法如图4所示。1×1卷积形成[64]提出的网络内网络(Network-in-Network)方法。不是对数据应用简单卷积,网络内网络方法使用小型神经网络捕捉数据的非线性属性。我们发现此方法有效,且对预测准确性有改进。
c) LSTM模块与输出
通常,全连接层用于分类输入数据。
然而,除非使用多个全连接层,否则全连接层的输入被假定为彼此独立的。由于我们工作中使用了Inception模块,最终有大量特征。
如果仅使用一个64个单位的全连接层,将需要估计超过630,000个参数,更不用说多个层了。为了捕捉提取特征中存在的时间关系,我们用LSTM单元替换全连接层。LSTM单元的激活反馈给自身,过去的激活记忆通过一组单独的权重保持,因此可以建模特征的时间动态。我们在工作中使用64个LSTM单元,导致约60,000个参数,参数估计量减少了10倍。最后的输出层使用softmax激活函数,因此最终输出元素表示每个时间步长内每个价格变动类的概率。
V. 实验结果
A. 实验设置
我们在本节的所有实验中应用相同的架构,提出的模型称为DeepLOB。我们通过最小化分类交叉熵损失来学习参数。使用自适应矩估计算法(ADAM)[65],我们将参数“epsilon”设为1,学习率设为0.01。当验证准确性在20个额外轮次内没有改善时停止学习。对于FI-2010数据集大约为100个轮次,对于LSE数据集大约为40个轮次。
我们使用大小为32的迷你批次进行训练。我们选择小的迷你批次大小是由于[66]的发现,他们建议大批量方法倾向于收敛到训练函数的狭窄深层最小值,而小批量方法始终收敛到浅层宽泛最小值。所有模型使用基于TensorFlow后端的Keras[67]构建,我们使用单个NVIDIA Tesla P100 GPU进行训练。
B. FI-2010数据集实验
使用FI-2010数据集有两个实验设置。遵循[24]的惯例,我们将其称为设置1和设置2。
设置1基于每日将数据集分为9个折叠(标准锚定前向拆分)。在第i折叠中,我们在前面i天上训练模型,并在第(i+1)天上测试,其中i = 1, · · · , 9。
第二个设置,设置2,源于[26, 28, 27, 25]的工作,其中评估了深度网络架构。由于深度学习技术通常需要大量数据来校准权重,在此设置中,前7天用作训练数据,最后3天用作测试数据。我们在此两种设置中评估我们的模型。
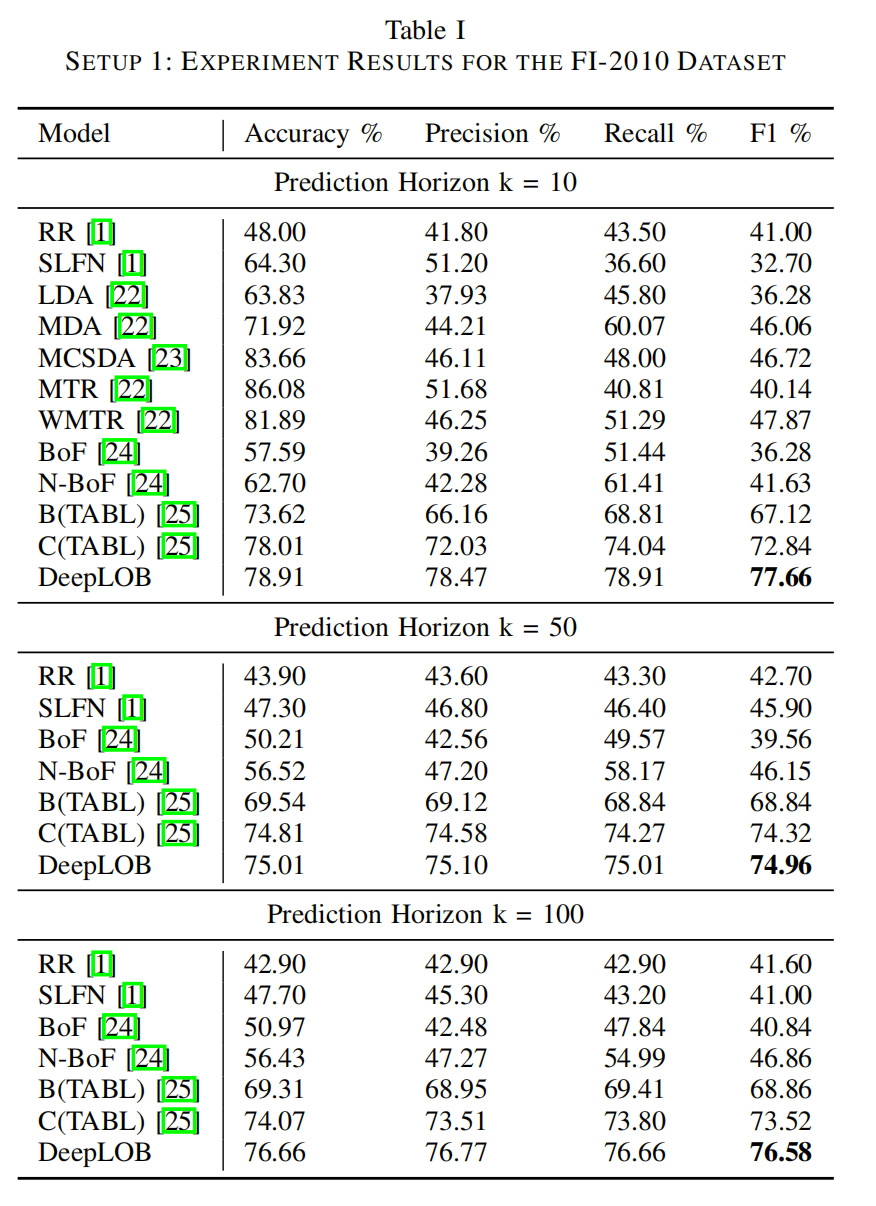
表I显示了在设置1中我们的模型与其他方法的比较结果。性能通过计算所有折叠的平均准确性、召回率、精确度和F1分数来衡量。由于FI-2010数据集不是很好平衡,[1]建议关注F1分数性能以进行公平比较。我们将模型与所有现有实验结果进行了比较,包括岭回归(RR)[1]、单层前馈网络(SLFN)[1]、线性判别分析(LDA)[22]、多线性判别分析(MDA)[22]、多线性时间序列回归(MTR)[22]、加权多线性时间序列回归(WMTR)[22]、特征包(BoF)[24]、神经特征包(N-BoF)[24]以及具有一个隐藏层(B(TABL))和两个隐藏层(C(TABL))的注意力增强双线性网络[25]。还有更多方法如PCA和自编码器(AE)在他们的工作中测试,但为简单起见,我们仅报告他们的最佳结果,我们的模型取得了更好的性能。 然而,设置1对于训练深度学习模型并非理想,如我们提到的,深度网络通常需要大量数据来校准权重。这种锚定前向设置导致前几折仅有一两天训练数据,我们观察到前几天性能较差。
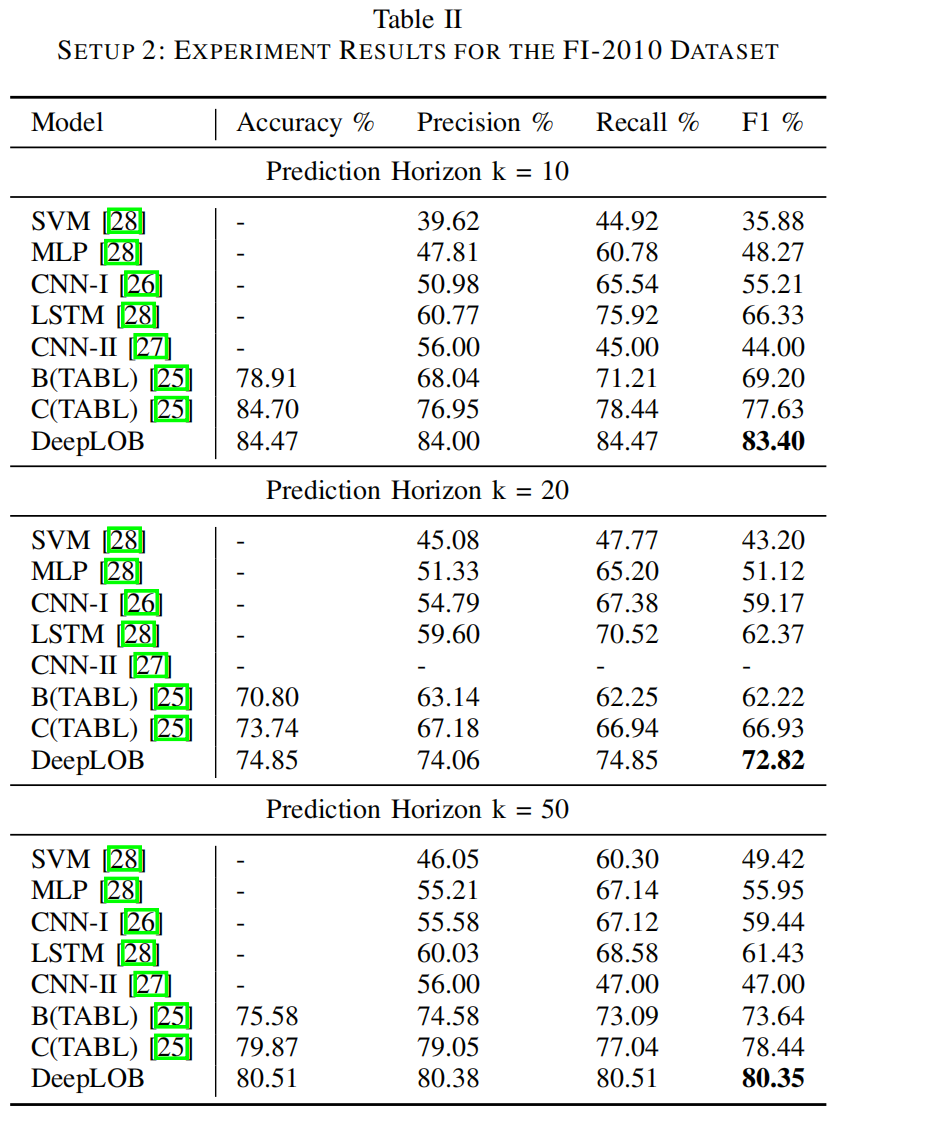
随着训练数据的增加,我们观察到显著更好的结果,如表II所示,表II显示了我们的网络在设置2中与其他方法的比较结果。特别是,我们的模型与CNN-I [26]和CNN-II [27]之间的显著差异归因于网络架构,我们在此看到性能的巨大改进。
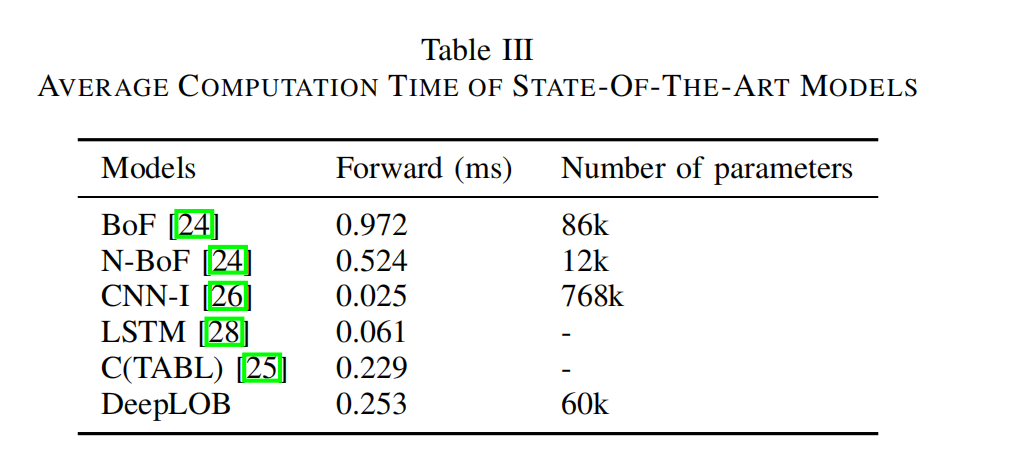
在表III中,我们比较了DeepLOB与CNN-I [26]的参数大小。尽管我们的模型有更多层,但由于使用了LSTM层而非全连接层,参数数量少得多。 我们还在表III中报告了可用算法的计算时间(前向传播),以毫秒(ms)为单位。由于GPU的发展,训练深度网络现在是可行的,预测很快,这使得高频交易成为可能。我们将在下一节进一步讨论这一点。
C. 伦敦证券交易所(LSE)实验
如我们所建议,FI-2010数据集不足以验证预测模型——它太短、降采样且来自流动性较低的市场。为了进行对现代应用有意义的评估,我们在一年的LSE股票数据上进一步测试了我们的方法,测试期为三个月。如第III节所述,我们在五只股票上训练模型:劳埃德银行(LLOY)、巴克莱银行(BARC)、乐购(TSCO)、英国电信和沃达丰(VOD)。[20]的近期工作表明,深度学习技术可以为限价订单数据提取通用特征。为了测试这种通用性,我们将模型直接应用于未包含在训练数据集中的五只股票(迁移学习)。我们选择了汇丰银行、Glencore(GLEN)、Centrica(CNA)、BP和ITV进行迁移学习,因为它们也是LSE中流动性最高的股票。测试期与之前相同,为三个月,类别大致平衡。
表IV展示了我们模型在不同预测horizon上的所有股票结果。为了更好地研究结果,我们在图5中展示了混淆矩阵,并计算了测试期间每天每只股票的准确性。我们使用图6中的箱线图展示这些信息,我们可以观察到所有股票在测试期间的性能一致且稳健,IQR较窄,出界点较少。我们的模型对未包含在训练集中的数据具有良好泛化能力,表明算法中的CNN块在从LOB提取特征时可以捕捉与价格形成机制相关的通用模式。我们认为这一观察结果非常有趣。
D. 简单交易模拟中的模型性能
设计了一个简单的交易模拟来测试我们结果的实用性。我们将每次交易的股票数量µ设为1,既为了简单,也为了尽量减少市场影响,确保订单以最佳价格执行。尽管µ可以通过优化来最大化回报,例如在[69]中使用预测概率来调整订单大小,但我们希望展示我们的算法即使在这种简单设置下也能工作。 为了减少交易数量,我们使用以下规则采取行动。在每个时间步,模型从网络输出(−1, 0, +1)生成信号,指示k步内的价格变动。信号(−1, 0, +1)对应于行动(卖、等待和买)。假设我们的模型在时间t预测为+1,我们在时间t+5购买µ股(考虑滑点),并持有直到出现−1以卖出所有µ股(如果出现0则不采取行动)。我们对卖空应用相同的规则,并在一天内重复该过程。所有头寸在一天结束时关闭,因此我们不持有股票过夜。我们确保在拍卖时间不进行交易,以免产生异常利润。 由于我们工作的重点是预测,上述简单模拟是一种展示预测原则上可货币化的方式。特别是,我们的目标不是提出一个完全开发的独立交易策略。现实的高频策略通常需要结合多种交易信号,特别是用于精确确定交易的进入和退出点。对于上述模拟,我们使用中间价格,不考虑交易成本。虽然特别是第二个假设对于独立策略来说不合理,但我们认为(i)它足以用于上述模型的相对比较,
(ii)它是一个很好的指标,表明上述预测器对更复杂的高频交易模型的相对价值。关于第一个假设,即中-中模拟,我们注意到在高频交易中,许多参与者从事做市,因为设计有利可图的完全激进策略在如此短的持有期内是困难的。如果我们假设可以被动进入交易,而激进退出,跨过点差,那么这实际上等同于中-中交易。例如,在从事客户做市的投资银行中,这种情况自然发生。关于第二个假设,仔细选择进入点以及更复杂的交易规则,例如包括头寸放大,应能产生额外利润以覆盖交易成本。无论如何,作为测试我们模型可预测性的简单度量,上述简单模拟已足够。 图7展示了不同股票和预测horizon的标准化每日利润(利润除以当天交易次数)箱线图。我们使用t检验检查利润是否在统计上大于0。t统计量本质上与夏普比率相同,但对于高频交易是更一致的评估指标。
图8展示了测试期间的累计利润。我们可以观察到所有股票在测试期间的利润和显著t值均一致。尽管我们在较长的预测horizon上获得较差的准确性,但累计利润实际上更高,因为生成了更稳健的信号。
E. 敏感性分析
信任和风险在任何金融应用中都是基本的。如果我们基于预测采取行动,了解这些预测背后的原因总是很重要的。神经网络通常被认为是缺乏可解释性的“黑箱”。然而,如果我们理解输入组成部分(例如文本中的单词、图像中的补丁)与模型预测之间的关系,我们可以将这些关系与我们的领域知识进行比较,以决定是否接受或拒绝预测。 [10]的工作提出了一种方法,称为LIME,以获得此类解释。在我们的案例中,我们使用LIME揭示对预测最重要的LOB组成部分,并了解为什么所提出的DeepLOB模型比其他网络架构(如CNN-I [26])表现更好。LIME使用可解释模型来近似复杂模型在给定输入上的预测。它局部扰动输入并观察模型预测的变化,从而提供有关输入重要性和敏感性的某种度量。 图9展示了一个示例,显示DeepLOB和CNN-I [26]对给定输入的反应。在图中,我们展示了预测类别的前10个支持(绿色)和反对(红色)区域(黄色为边界)。未着色的区域表示对预测结果影响较小或“不重要”的输入组成部分。我们注意到,CNN-I [26]的大多数输入组成部分是不活跃的。我们认为这是由于该架构中使用了两个最大池化层。因为[26]在第一卷积层中使用了大尺寸滤波器,网络深层的任何表示实际上代表了从输入的大部分信息中提取的信息。我们对许多示例应用LIME的实验表明,这一观察是一个常见特征。 VI. 结论
在本文中,我们介绍了第一个使用高频限价订单数据预测股价变动的混合深度神经网络。与传统手工设计的模型不同,我们利用CNN和Inception模块自动化特征提取,并使用LSTM单元捕捉时间依赖性。 所提出的方法在FI-2010基准数据集上与几种基线方法进行了评估,结果显示我们的模型在预测短期价格变动方面优于其他技术。我们进一步通过使用伦敦证券交易所一年的限价订单数据(测试期为三个月)测试了模型的稳健性。我们工作中的一个有趣观察是,所提出的模型对未包含在训练数据中的工具具有良好的泛化能力。这表明存在对价格形成有信息的通用特征,我们的模型似乎通过从包含多个工具的大型数据集中学习捕捉到这些特征。使用简单的交易模拟进一步测试了我们的模型,我们获得了统计上显著的良好利润。 为了超越深度学习模型常被批评的“黑箱”性质,我们使用LIME方法进行敏感性分析,以指示对预测有贡献的输入组成部分。很好地理解输入组成部分与模型预测之间的关系可以帮助我们决定是否接受预测。特别是,我们看到不同级别和horizon上的价格和量信息如何对预测有贡献,这与我们的计量经济学理解相符。 在近期对此工作的扩展中,我们修改了DeepLOB模型以使用贝叶斯神经网络[69]。这允许为网络输出提供不确定性度量,例如可用于放大头寸,如[69]所示。 在后续工作中,我们希望研究更详细的交易策略,使用基于DeepLOB特征提取的强化学习。
致谢
作者感谢牛津大学机器学习研究小组成员对本文草稿的宝贵意见。我们非常感谢牛津-曼氏量化金融研究所提供的限价订单数据和其他支持。我们工作的计算得到了牛津大学Arcus Phase B和JADE HPC以及英国Hartree国家计算设施的支持。我们也感谢英国皇家工程学院的支持。
参考文献
[1] A. Ntakaris, M. Magris, J. Kanniainen, M. Gabbouj,
和 A. Iosifidis, “Benchmark dataset for mid-price fore-
casting of limit order book data with machine learning
methods,” Journal of Forecasting, vol. 37, no. 8, pp. 852–
866, 2018.
[2] C. A. Parlour and D. J. Seppi, “Limit order markets:
A survey,” Handbook of financial intermediation and
banking, vol. 5, pp. 63–95, 2008.
[3] I. Rosu et al., “Liquidity and information in order driven
markets,” Tech. Rep., 2010.
[4] E. Zivot and J. Wang, “Vector autoregressive models for
multivariate time series,” Modeling Financial Time Series
with S-PLUS R
, pp. 385–429, 2006.
[5] A. A. Ariyo, A. O. Adewumi, and C. K. Ayo, “Stock
price prediction using the ARIMA model,” in Computer
Modelling and Simulation (UKSim), 2014 UKSim-AMSS
16th International Conference on. IEEE, 2014, pp. 106–
112.
[6] C. Carrie, “The new electronic trading regime of dark
books, mashups and algorithmic trading,” Trading, vol.
2006, no. 1, pp. 14–20, 2006.
[7] M. D. Gould, M. A. Porter, S. Williams, M. McDonald,
D. J. Fenn, and S. D. Howison, “Limit order books,”
Quantitative Finance, vol. 13, no. 11, pp. 1709–1742,
2013.
[8] W.-C. Chiang, D. Enke, T. Wu, and R. Wang, “An
adaptive stock index trading decision support system,”
Expert Systems with Applications, vol. 59, pp. 195–207,
2016.
[9] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed,
D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabi-
novich, “Going deeper with convolutions,” in Proceed-
ings of the IEEE conference on computer vision and
pattern recognition, 2015, pp. 1–9.
[10] M. T. Ribeiro, S. Singh, and C. Guestrin, “Why should I
trust you?: Explaining the predictions of any classifier,”
in Proceedings of the 22nd ACM SIGKDD international
conference on knowledge discovery and data mining.
ACM, 2016, pp. 1135–1144.
[11] A. Ang and G. Bekaert, “Stock return predictability: Is it
there?” The Review of Financial Studies, vol. 20, no. 3,
pp. 651–707, 2006.
[12] P. Bacchetta, E. Mertens, and E. Van Wincoop, “Pre-
dictability in financial markets: What do survey expec-
tations tell us?” Journal of International Money and
Finance, vol. 28, no. 3, pp. 406–426, 2009.
[13] T. Bollerslev, J. Marrone, L. Xu, and H. Zhou, “Stock
return predictability and variance risk premia: Statistical
inference and international evidence,” Journal of Finan-
cial and Quantitative Analysis, vol. 49, no. 3, pp. 633–
661, 2014.
[14] M. A. Ferreira and P. Santa-Clara, “Forecasting stock
market returns: The sum of the parts is more than the
whole,” Journal of Financial Economics, vol. 100, no. 3,
pp. 514–537, 2011.
[15] B. Mandelbrot and R. L. Hudson, The Misbehavior of
Markets: A fractal view of financial turbulence. Basic
books, 2007.
[16] B. B. Mandelbrot, “How Fractals Can Explain What’s
Wrong with Wall Street,” Scientific American, vol. 15,
no. 9, p. 2008, 2008.
[17] J. Agrawal, V. Chourasia, and A. Mittra, “State-of-the-
art in stock prediction techniques,” International Journal
of Advanced Research in Electrical, Electronics and
Instrumentation Engineering, vol. 2, no. 4, pp. 1360–
1366, 2013.
[18] R. C. Cavalcante, R. C. Brasileiro, V. L. Souza, J. P.
Nobrega, and A. L. Oliveira, “Computational intelligence
and financial markets: A survey and future directions,”
Expert Systems with Applications, vol. 55, pp. 194–211,
2016.
[19] Q. Cao, K. B. Leggio, and M. J. Schniederjans, “A com-
parison between Fama and French’s model and artificial
neural networks in predicting the Chinese stock market,”
Computers Operations Research, vol. 32, no. 10, pp.
2499–2512, 2005.
[20] J. Sirignano and R. Cont, “Universal features of price
formation in financial markets: perspectives from deep
learning,” arXiv preprint arXiv:1803.06917, 2018.
[21] G. S. Atsalakis and K. P. Valavanis, “Surveying stock
market forecasting techniques–Part II: Soft computing
methods,” Expert Systems with Applications, vol. 36,
no. 3, pp. 5932–5941, 2009.
[22] D. T. Tran, M. Magris, J. Kanniainen, M. Gabbouj,
and A. Iosifidis, “Tensor representation in high-frequency
financial data for price change prediction,” in Computa-
tional Intelligence (SSCI), 2017 IEEE Symposium Series
on. IEEE, 2017, pp. 1–7.
[23] D. T. Tran, M. Gabbouj, and A. Iosifidis, “Multilinear
class-specific discriminant analysis,” Pattern Recognition
Letters, vol. 100, pp. 131–136, 2017.
[24] N. Passalis, A. Tefas, J. Kanniainen, M. Gabbouj, and
A. Iosifidis, “Temporal bag-of-features learning for pre-
dicting mid price movements using high frequency limit
order book data,” IEEE Transactions on Emerging Topics
in Computational Intelligence, 2018.
[25] D. T. Tran, A. Iosifidis, J. Kanniainen, and M. Gabbouj,
“Temporal attention-augmented bilinear network for fi-
nancial time-series data analysis,” IEEE transactions on
neural networks and learning systems, 2018.
[26] A. Tsantekidis, N. Passalis, A. Tefas, J. Kanniainen,
M. Gabbouj, and A. Iosifidis, “Forecasting stock prices
from the limit order book using convolutional neural
networks,” in Business Informatics (CBI), 2017 IEEE
19th Conference on, vol. 1. IEEE, 2017, pp. 7–12.
[27] ——, “Using Deep Learning for price prediction by
exploiting stationary limit order book features,” arXiv
preprint arXiv:1810.09965, 2018.
[28] ——, “Using deep learning to detect price change in-
dications in financial markets,” in Signal Processing
Conference (EUSIPCO), 2017 25th European. IEEE,
2017, pp. 2511–2515.
[29] M. Dixon, D. Klabjan, and J. H. Bang, “Classification-
based financial markets prediction using deep neural
networks,” Algorithmic Finance, vol. 6, no. 3-4, pp. 67–
77, 2017.
[30] Y. LeCun, Y. Bengio et al., “Convolutional networks for
images, speech, and time series,” The handbook of brain
theory and neural networks, vol. 3361, no. 10, p. 1995,
1995.
[31] N. Wang and D.-Y. Yeung, “Learning a deep compact
image representation for visual tracking,” in Advances in
neural information processing systems, 2013, pp. 809–
817.
[32] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich
feature hierarchies for accurate object detection and
semantic segmentation,” in Proceedings of the IEEE
conference on computer vision and pattern recognition,
2014, pp. 580–587.
[33] J. Long, E. Shelhamer, and T. Darrell, “Fully convolu-
tional networks for semantic segmentation,” in Proceed-
ings of the IEEE Conference on Computer Vision and
Pattern Recognition, 2015, pp. 3431–3440.
[34] J.-F. Chen, W.-L. Chen, C.-P. Huang, S.-H. Huang, and
A.-P. Chen, “Financial time-series data analysis using
deep convolutional neural networks,” in Cloud Com-
puting and Big Data (CCBD), 2016 7th International
Conference on. IEEE, 2016, pp. 87–92.
[35] J. Doering, M. Fairbank, and S. Markose, “Convolu-
tional neural networks applied to high-frequency market
microstructure forecasting,” in Computer Science and
Electronic Engineering (CEEC), 2017. IEEE, 2017, pp.
31–36.
[36] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet
classification with deep convolutional neural networks,”
in Advances in neural information processing systems,
2012, pp. 1097–1105.
[37] K. Simonyan and A. Zisserman, “Very Deep Convolu-
tional Networks for Large-Scale Image Recognition,” in
International Conference on Learning Representations,
2015.
[38] S. Hochreiter and J. Schmidhuber, “Long short-term
memory,” Neural computation, vol. 9, no. 8, pp. 1735–
1780, 1997.
[39] Y. Bengio, P. Simard, and P. Frasconi, “Learning long-
term dependencies with gradient descent is difficult,”
IEEE transactions on neural networks, vol. 5, no. 2, pp.
157–166, 1994.
[40] M. Sundermeyer, R. Schluter, and H. Ney, “LSTM neural
networks for language modeling,” in Thirteenth Annual
Conference of the International Speech Communication
Association, 2012.
[41] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to
sequence learning with neural networks,” in Advances in
neural information processing systems, 2014, pp. 3104–
3112.
[42] W. Bao, J. Yue, and Y. Rao, “A deep learning framework
for financial time series using stacked autoencoders and
long-short term memory,” PloS one, vol. 12, no. 7, p.
e0180944, 2017.
[43] S. Selvin, R. Vinayakumar, E. Gopalakrishnan, V. K.
Menon, and K. Soman, “Stock price prediction using
LSTM, RNN and CNN-sliding window model,” in Ad-
vances in Computing, Communications and Informatics
(ICACCI), 2017 International Conference on. IEEE,
2017, pp. 1643–1647.
[44] T. Fischer and C. Krauss, “Deep learning with long short-
term memory networks for financial market predictions,”
European Journal of Operational Research, vol. 270,
no. 2, pp. 654–669, 2018.
[45] L. Di Persio and O. Honchar, “Artificial neural networks
architectures for stock price prediction: Comparisons and
applications,” International Journal of Circuits, Systems
and Signal Processing, vol. 10, pp. 403–413, 2016.
[46] M. Dixon, “Sequence classification of the limit order
book using recurrent neural networks,” Journal of com-
putational science, vol. 24, pp. 277–286, 2018.
[47] D. M. Nelson, A. C. Pereira, and R. A. de Oliveira,
“Stock market’s price movement prediction with LSTM
neural networks,” in Neural Networks (IJCNN), 2017
International Joint Conference on. IEEE, 2017, pp.
1419–1426.
[48] L. Harris, Trading and exchanges: Market microstructure
for practitioners. Oxford University Press, USA, 2003.
[49] M. O’Hara, Market microstructure theory. Blackwell
Publishers Cambridge, MA, 1995, vol. 108.
[50] A. N. Kercheval and Y. Zhang, “Modelling high-
frequency limit order book dynamics with Support Vector
Machines,” Quantitative Finance, vol. 15, no. 8, pp.
1315–1329, 2015.
[51] A. Abraham, B. Nath, and P. K. Mahanti, “Hybrid intelli-
gent systems for stock market analysis,” in International
Conference on Computational Science. Springer, 2001,
pp. 337–345.
[52] T. Hendershott, C. M. Jones, and A. J. Menkveld, “Does
algorithmic trading improve liquidity?” The Journal of
Finance, vol. 66, no. 1, pp. 1–33, 2011.
[53] C. Cao, O. Hansch, and X. Wang, “The information
content of an open limit-order book,” Journal of futures
markets, vol. 29, no. 1, pp. 16–41, 2009.
[54] S. J. Orfanidis, Introduction to signal processing.
Prentice-Hall, Inc., 1995.
[55] J. Gatheral and R. C. Oomen, “Zero-intelligence realized
variance estimation,” Finance and Stochastics, vol. 14,
no. 2, pp. 249–283, 2010.
[56] Y. Nevmyvaka, Y. Feng, and M. Kearns, “Reinforcement
learning for optimized trade execution,” in Proceedings
of the 23rd international conference on Machine learn-
ing. ACM, 2006, pp. 673–680.
[57] M. Avellaneda, J. Reed, and S. Stoikov, “Forecasting
prices from Level-I quotes in the presence of hidden
liquidity,” Algorithmic Finance, vol. 1, no. 1, pp. 35–43,
2011.
[58] Y. Burlakov, M. Kamal, and M. Salvadore, “Optimal
limit order execution in a simple model for market
microstructure dynamics,” 2012.
[59] L. Harris, “Maker-taker pricing effects on market quo-
tations,” USC Marshall School of Business Work-
ing Paper. Avalable at http://bschool. huji. ac. il/.
upload/hujibusiness/Maker-taker. pdf, 2013.
[60] A. Lipton, U. Pesavento, and M. G. Sotiropoulos, “Trade
arrival dynamics and quote imbalance in a limit order
book,” arXiv preprint arXiv:1312.0514, 2013.
[61] A. L. Maas, A. Y. Hannun, and A. Y. Ng, “Rectifier
nonlinearities improve neural network acoustic models,”
in Proc. icml, vol. 30, no. 1, 2013, p. 3.
[62] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learn-
ing. MIT Press, 2016,
http://www.deeplearningbook.org.
[63] T. J. Moskowitz, Y. H. Ooi, and L. H. Pedersen, “Time
series momentum,” Journal of financial economics, vol.
104, no. 2, pp. 228–250, 2012.
[64] M. Lin, Q. Chen, and S. Yan, “Network in network,” in
International Conference on Learning Representations,
2014.
[65] D. Kingma and J. Ba, “Adam: A method for stochastic
optimization,” Proceedings of the International Confer-
ence on Learning Representations 2015, 2015.
[66] N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy,
and P. T. P. Tang, “On large-batch training for deep
learning: Generalization gap and sharp minima,” in Inter-
national Conference on Learning Representations, 2017.
[67] F. Chollet et al., “Keras,” https://keras.io, 2015.
[68] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen,
C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin,
S. Ghemawat, I. Goodfellow, A. Harp, G. Irving,
M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur,
J. Levenberg, D. Mane, R. Monga, S. Moore, D. Murray,
C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever,
K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan,
F. Viegas, O. Vinyals, P. Warden, M. Wattenberg,
M. Wicke, Y. Yu, and X. Zheng, “TensorFlow: Large-
scale machine learning on heterogeneous systems,”
2015, software available from tensorflow.org. [Online].
Available: https://www.tensorflow.org/
[69] Z. Zhang, S. Zohren, and S. Roberts, “BDLOB: Bayesian
Deep Convolutional Neural Networks for Limit Order
Books,” in Third workshop on Bayesian Deep Learning
(NeurIPS 2018), 2018.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)