大模型系列——论文解读:eagle/eagle2
使用 Vicuna-68M 作为草稿模型的标准推测性采样也实现了显著的加速,但与其他方法相比,其训练开销要高得多。
1、eagle
1.1 背景
自回归解码是大型语言模型(LLM)的实际标准,它按顺序生成标记,导致生成速度慢且成本高。基于推测采样的方法(Leviathan 等人,2023;Chen 等人,2023a)通过将过程分为低成本草稿阶段和对草稿标记的并行验证阶段来解决这个问题,允许在单个 LLM 传递中验证多个标记。这些方法通过每传递生成多个标记来加速生成。更重要的是,验证阶段确保文本分布与原始 LLM 的解码结果完全一致,从而保持生成内容的完整性。
应用推测性采样的关键在于找到一个与原始LLM功能相似的草稿模型,但延迟更低,通常涉及来自同一LLM系列的更低参数版本。使用7B模型作为70B模型的草稿模型是有效的,而为最小的7B变体找到合适的草稿模型则很棘手。尽管7B模型有潜力作为草稿模型,但其高开销降低了加速收益。专门为推测性采样训练一个新的、大小合适的草稿模型也不是一个理想的解决方案,因为成本太高。
在推测性采样中提高加速的关键在于减少时间开销并提高原始 LLM 对草稿的接受率(Chen 等人,2023b;Xia 等人,2023;Santilli 等人,2023)。许多方法都集中于减少草稿阶段的开销。前瞻(Fu 等人,2023)采用 n 元语法和雅可比迭代,而 Medusa(Cai 等人,2023)则利用一组 MLP,根据原始 LLM 的第二层特征预测标记。这些策略显著降低了生成草稿的延迟,从而提高了加速。然而,它们的有效性受到生成草稿准确率较低的影响,Medusa 的准确率约为 0.6,而前瞻的准确率更低。相比之下,我们的方法达到了约 0.8 的准确率。
备注:与medusa比,草稿模型更准确、速度更快
为了克服这些局限性,我们引入了 EAGLE(用于提高大型语言模型效率的推断算法),这是一种高效的推测性采样方法,它基于以下两个观察结果。
首先,在特征层面上进行自回归比在词元层面上更简单。在本文中,“特征”指的是原始LLM的倒数第二层特征,位于LM头之前。与自然语言的简单变换词元序列相比,特征序列表现出更高的规律性。在特征层面上进行自回归处理,然后使用原始LLM的LM头推导出词元,比直接自回归预测词元效果更好。如图4所示,自回归预测特征可以获得更好的性能,表现为更高的加速比。
其次,采样过程固有的不确定性极大地限制了预测下一个特征的性能。如图3所示,对不同标记(如“am”或“always”)进行采样会导致不同的特征序列,从而在特征级自回归中引入歧义。Medusa在预测间隔标记时也面临类似问题,它不确定输入FI的真实目标应该是Pam还是Palways。为了解决这个问题,EAGLE将来自提前一步的时间步的标记序列(包括采样结果)输入到草稿模型中。在图3所示的示例中,这涉及到基于FI和Talways预测Falways,以及基于FI和Tam预测Fam。如图4所示,通过解决不确定性问题,加速比从1.9倍进一步提高到2.8倍。
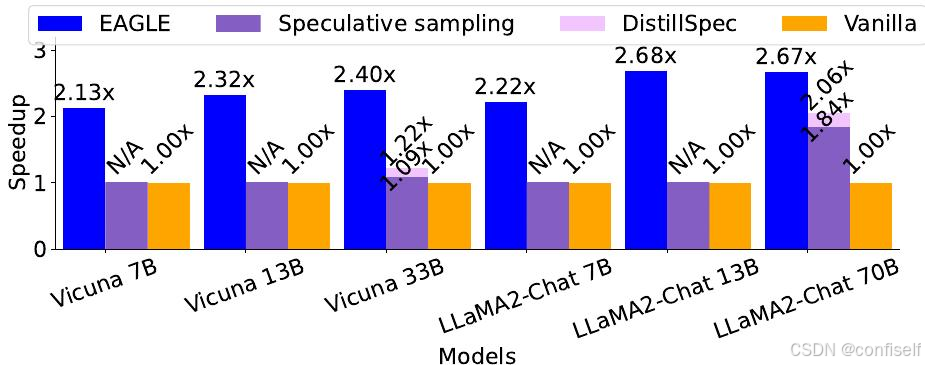
图4
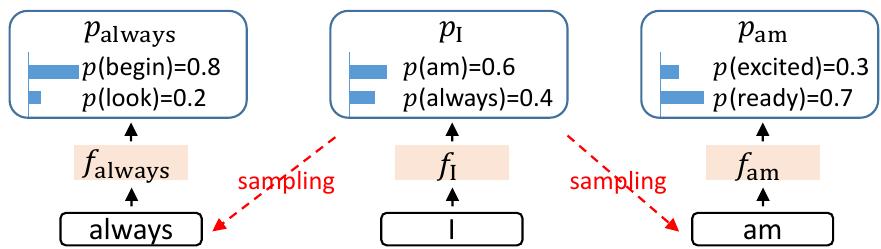
Figure 3: Uncertainty in feature sequences. The next feature following fI is contingent on the sampling outcome and cannot be determined solely based on fI , where both “always” and “am” are possible to follow the token “I” and lead to two branches.
图 3:特征序列中的不确定性。紧随 fI 的下一个特征取决于采样结果,不能仅根据 fI 确定,其中“always”和“am”都可能跟随“I”并导致两个分支。
1.2 优势
EAGLE 拥有较低的训练成本。对于 LLaMA2-Chat 70B 模型,EAGLE 使用不超过 70k 个来自 ShareGPT 数据集的对话来训练一个参数量少于 10 亿的参数的解码器层。训练在 4x A100 (40G) GPU 上完成,耗时 1-2 天。EAGLE 在 7B、13B 和 33B 模型上的训练甚至可以在一个 RTX 3090 节点上完成,耗时 1-2 天。在实际应用中,EAGLE 仅需一次训练即可为每个查询提供加速。随着查询数量的增加,EAGLE 的摊销训练成本变得可以忽略不计。
The method adds only a lightweight plug-in (a single transformer decoder layer) to the LLM, which can be easily deployed in a production environment
该方法仅在大型语言模型中添加了一个轻量级插件(一个单一的 Transformer 解码器层),该插件可以轻松部署在生产环境中。
可靠性:EAGLE 不涉及对原始 LLM 的任何微调,并且理论上保证了 EAGLE 在贪婪和非贪婪设置下都能够保留输出分布。这与 Lookahead 和 Medusa 形成鲜明对比,它们要么只关注贪婪设置,要么不能保证在这些设置下保留分布。
1.3 方法


eagle也使用了推测采样的方法,区别点在于草稿模型和他们不一样。
EAGLE 与其他基于推测性采样的方法一致,包含草稿阶段和验证阶段。
1.3.1 起草阶段
EAGLE 与其他方法的主要区别在于草稿阶段,如图5所示。
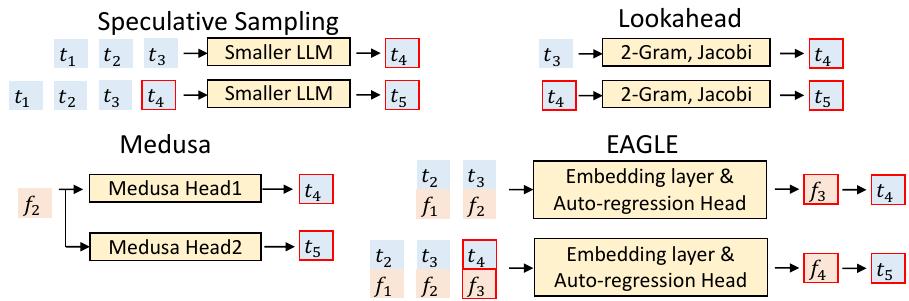
Figure 5: A comparison of the methods for drafting the fourth and fifth tokens, t4 and t5. t (represented by blue blocks) denotes tokens, and f (orange blocks) signifies the features, with subscripts indicating their positions in the sequence. The red border indicates the predictions of the draft model. For simplicity, the n in the n-gram for Lookahead, as shown in the figure, has been set to 2.
图 5:比较了生成第四个和第五个词元 t4 和 t5 的方法。t(蓝色块表示)表示词元,f(橙色块表示)表示特征,下标表示它们在序列中的位置。红色边框表示草稿模型的预测。为简单起见,图中所示的 Lookahead 中 n-gram 的 n 已设置为 2。
备注:可以看出基于Smaller LLM的是逐个预测t4和t5的,medusa则将f2特征预测出t3(原来的head),新的head预测出t4和t5。
(1)草稿模型结构
如图6所示,EAGLE 的草稿模型包含三个模块:嵌入层、LM 头和自回归头。嵌入层和 LM 头使用目标 LLM 的参数,不需要额外的训练。草稿模型以形状为 (bs, seq len, hidden dim) 的特征序列和形状为 (bs, seq len) 的高级标记序列作为输入。然后它将标记序列转换为形状为 (bs, seq len, hidden dim) 的标记嵌入序列,并将其连接起来形成形状为 (bs, seq len, 2×hidden dim) 的融合序列。自回归头包含一个 FC 层和一个解码器层。FC 层将融合序列的维度降低到 (bs, seq len, hidden dim),然后我们使用解码器层来预测下一个特征。LM 头根据特征计算分布,从中采样下一个标记。最后,将预测的特征和采样的标记连接到输入中,便于自回归过程的继续。EAGLE 使用树注意力创建树状结构草稿,生成深度为m、超过m个标记的草稿树,通过m次前向传递。例如,如图6所示,EAGLE 只需 3 次前向传递即可草拟一个包含 10 个标记的树。EAGLE 使用的实际树结构在附录 A.1 中详细说明。
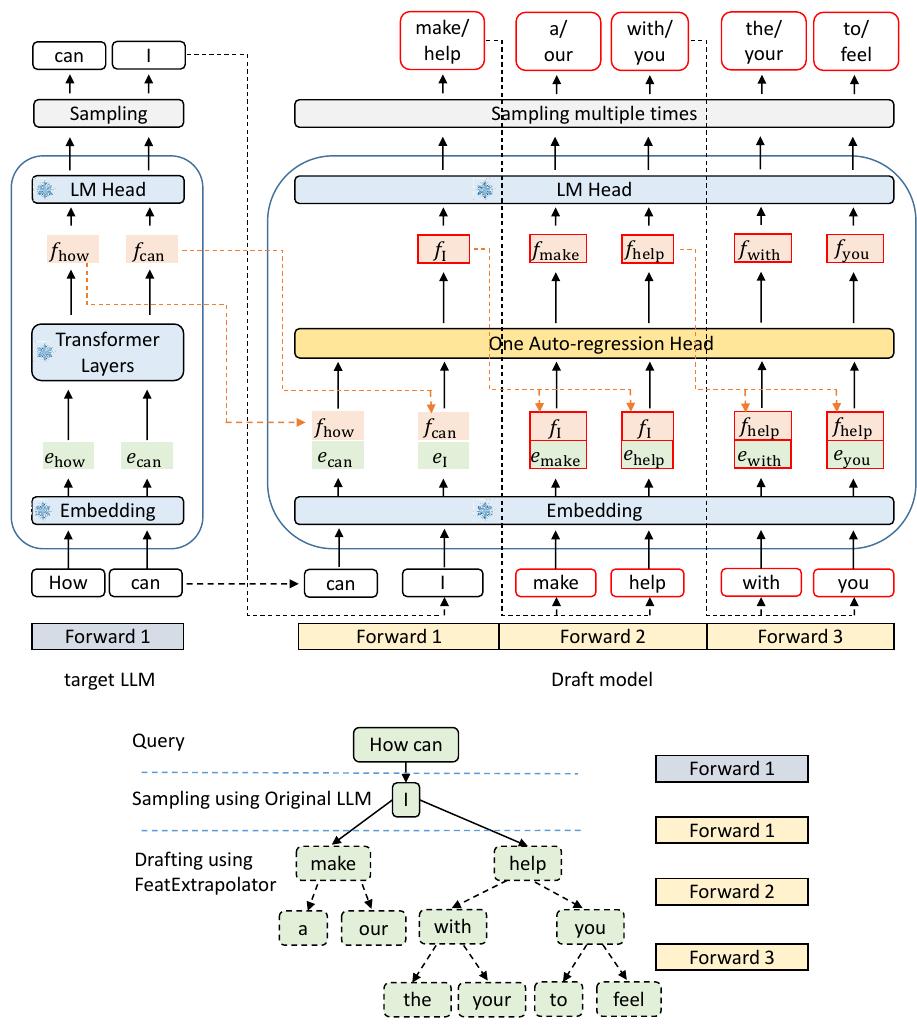
Figure 6: Pipeline of EAGLE. The upper section illustrates the computational process, while the lower section displays the corresponding generation results for each step. In the upper section, green blocks represent token embeddings, orange blocks represent features, red boxes indicate the predictions of the draft model, and blue modules with snowflake icons represent the use of target LLM parameters, which are not subject to training.
图 6:EAGLE 的管道。上半部分说明了计算过程,下半部分显示了每个步骤的相应生成结果。在上半部分,绿色块表示词元嵌入,橙色块表示特征,红色框表示草稿模型的预测,蓝色模块带有雪花图标表示目标 LLM 参数的使用,这些参数不受训练的影响。
备注:这个图说的很清晰了,经过3次预测,生成了10个标记。自回归头包含一个 FC 层和一个解码器层,这里的解码器层如何实现?
(2)训练


注意,这里的f^i+1即为才草稿模型预测出来的,fi+1为原模型lm_head的前一层状态得来的(原来前一层维度应该为batch_size, hidden_dim,如何来的2个feature?)。
EAGLE 的自回归头部最适合使用目标 LLM 自回归生成的文本进行训练,但这种方法成本很高。幸运的是,EAGLE 对训练数据表现出低敏感性(第 4.3.3 节中的消融研究)。我们使用固定数据集而不是使用目标 LLM 生成的文本,从而大幅降低了开销。在起草阶段,EAGLE 自回归地处理特征。特征中的不准确性会导致错误累积。为了缓解这个问题,我们在训练期间通过向目标 LLM 特征添加从均匀分布 U(−0.1, 0.1) 中采样的随机噪声来使用数据增强(Jain 等人,2023)。
训练。我们固定了目标LLM。EAGLE在ShareGPT数据集上进行训练,利用68,000次对话迭代,学习率设置为3e-5。我们采用AdamW优化器,β值(β1, β2)设置为(0.9, 0.95),并实施了0.5的梯度裁剪。EAGLE的7B、13B、33B和70B模型的可训练参数分别为0.24B、0.37B、0.56B和0.99B。EAGLE用于MoE模型Mixtral 8x7B的可训练参数为0.28B。EAGLE的特点是训练成本低;对于70B模型,自回归头可以在A100 40G服务器上训练1-2天内完成。
1.3.2 验证阶段
利用树形注意力机制,目标LLM通过单次前向传播计算树形结构草稿中每个词元的概率。在草稿树的每个节点上,我们递归地应用推测性采样算法来采样或调整分布(详情见附录A.2),与SpecInfer(Miao等人,2023)一致,确保输出文本的分布与目标LLM的分布一致。同时,我们将接受的词元及其特征记录下来,以便在下一个起草阶段使用。
1.4 实验
(1)Metrics
与其他基于推测性采样的方法类似,EAGLE 主要关注延迟而不是吞吐量。我们使用以下指标评估加速效果
壁时加速比:相对于普通自回归解码的实际测试加速比
平均接受长度 τ:目标 LLM 正向传递中接受的令牌平均数量
接受率 α:在起草过程中,接受的标记与生成的标记的比率,衡量草稿的准确性。对于树形草稿来说,由于每个位置采样多个标记,而只接受一个标记,因此不太适用。因此,在衡量此指标时,我们使用没有树形注意力的链式草稿,与推测性采样和 DistillSpec 一致。EAGLE 的草稿模型输入特征和标记序列。自回归特征处理会传播错误,因此我们将接受率衡量为 n-α,考虑到 n 个特征由草稿模型预测,可能存在不准确性。
EAGLE 的加速理论上保证了目标 LLMs 输出分布的保持。因此,评估 EAGLE 生成的结果的质量既不必要也不具有意义
1.5 兼容与进一步加速
EAGLE 与其他加速技术兼容。我们进行了将 EAGLE 与 gpt-fast 相结合的实验,gpt-fast 采用量化和编译进行加速。如图 4 所示,通过将 EAGLE 与 gpt-fast 集成,我们将 LLaMA2-Chat 7B 在单个 RTX 3090 上的生成速度提高到 160.4 个 token/s。
1.6 消融研究
1.6.1 树形注意力
EAGLE,类似于 SpecInfer 和 Medusa,采用树注意力机制,其中草稿的生成和验证都是树状结构的。相比之下,像推测性采样这样的方法不使用树注意力机制,导致草稿生成和验证是链状结构的。表 5 和图 7 展示了使用树注意力机制的影响的比较结果。EAGLE 中树形草稿和验证的实现导致平均接受长度大约增加了 0.6-0.8,加速比大约增加了 0.3-0.5。与链式草稿和验证相比,树形草稿和验证不会增加模型(目标 LLM 和草稿模型)中的前向传递次数,但会增加每个前向传递处理的标记数量。因此,加速比的改进不如平均接受长度的增加明显。值得注意的是,即使不采用树形草稿和验证,EAGLE 也表现出显著的加速效果,大约在 2.3x-2.7x 的范围内。
1.6.2 草稿模型的输入
与其他基于推测性采样的方法相比,EAGLE 的关键创新在于它利用了目标 LLM 计算的特征,并将采样结果纳入草稿模型的输入中以解决随机性。我们在 Vicuna 7B 上进行了消融研究,评估了具有不同输入的草稿模型。我们测试了四种类型的输入:特征和移位令牌 (EAGLE)、特征和未移位令牌、令牌和特征。特征和移位令牌 (EAGLE) 以及特征和未移位令牌都在不同级别上整合了语义信息。区别在于特征和移位令牌 (EAGLE) 输入提前一个时间步的令牌,使其能够有效地解决随机性。除了使用 FC 层来降低特征和令牌输入的维数之外,草稿模型的结构完全保持一致。图 8 展示了使用 Vicuna 7B 作为目标 LLM 在 MT-bench 上的实验结果。可以得出三个观察结果。
1.7 实现细节
Utilizing tree attention, EAGLE generates a tree-structured draft. The left side of Figure 9 illustrates the tree structure of the draft, while the right side depicts the corresponding chain-structured draft when tree attention is not used (as utilized in the ablation study detailed in Section 4.3.1). In a greedy setting, we select the top k tokens with the highest probabilities as child nodes. In a non-greedy setting, we sample k tokens. The number of child nodes, k, can be inferred from Figure 9; for instance, k = 4 at the root node. Regardless of employing a tree-structured or chain-structured draft, the draft model undergoes 5 forward passes during the draft phase. During the verification phase, each token’s probability is obtained through a single forward pass by the target LLM.
无论使用tree还是链式,对于k=4时,草稿模型需要经过5次前向计算,验证阶段则只需要目标LLM的一次前向计算。
Why do we use such a tree structure? The choice of the tree structure, as depicted in Figure 9, was not rigorously optimized but rather based on intuition: branches of higher-probability tokens should be deeper and wider. For this paper, all models across all experiments utilized the draft structure shown in Figure 9. However, the optimal tree structure is likely context-dependent. For instance, as batch size increases and redundant computational resources decrease, a smaller tree might be preferable. Tuning the draft structure could potentially lead to improved performance.
高概率令牌的分支应该更深入、更广泛。对于本文,所有实验中的所有模型都使用了图9所示的草稿结构。然而,最佳树结构可能取决于上下文。例如,随着批处理大小的增加和冗余计算资源的减少,较小的树可能更可取。调整草稿结构可能会提高性能。
Unlike the chain-structured draft of speculative sampling, EAGLE employs a tree-structured draft, necessitating modifications to the sampling algorithm. The sampling algorithm A of speculative sampling can be briefly described as: if a token is accepted, it returns that token; otherwise, it samples a token from the adjusted distribution. For a tree-structured draft with k candidate tokens, Multi-round speculative sampling recursively invokes algorithm A. Instead of directly sampling from the adjusted distribution after rejecting a token, Multi-round speculative sampling calls A again. If all tokens are rejected, it then directly samples from the adjusted distribution. The pseudocode for Multi-round speculative sampling is provided in Algorithm 1.
与推测采样的链式结构草稿不同,EAGLE采用树形结构草稿,需要对采样算法进行修改。推测采样的采样算法A可以简要描述为:如果接受令牌,则返回该令牌;否则,它将从调整后的分布中采样一个令牌。对于具有k个候选令牌的树结构草稿,多轮推测采样递归调用算法A。在拒绝令牌后,多轮猜测采样不再直接从调整后的分布中采样,而是再次调用A。如果所有令牌都被拒绝,则直接从调整后的分布中采样。算法1中提供了多轮推测采样的伪码。

2、eagle2
使用现代大型语言模型 (LLM) 进行推理既昂贵又耗时,而推测性采样已被证明是一种有效的解决方案。大多数推测性采样方法,例如 EAGLE,使用静态草稿树,隐式地假设草稿标记的接受率仅取决于它们的位置。有趣的是,我们发现草稿标记的接受率也与上下文相关。在本文中,基于 EAGLE,我们提出了 EAGLE-2,它在草稿建模中引入了上下文感知动态草稿树的新技术。这种改进利用了 EAGLE 的草稿模型经过良好校准的事实:来自草稿模型的置信度分数以较小的误差近似接受率。我们在三个系列的 LLM 和六项任务上进行了广泛的评估,EAGLE-2 达到了 3.05x 4.26x 的加速比,比 EAGLE-1 快 20%-40%。EAGLE-2 还确保了生成的文本分布保持不变,使其成为一种无损加速算法。
备注:和eagle比,使用动态草稿树。静态草稿树认为概率高的节点,排在前面,分支也越多。
EAGLE(Li 等人,2024b)和Medusa(Cai 等人,2024)在所有上下文中使用相同的静态草稿树结构:在草稿阶段的第 i 步,添加 k 个候选者,其中 k 是固定的。这隐含地假设了上述假设。然而,这种假设似乎与推测采样的见解相矛盾,即某些标记更简单,可以通过更小的模型预测。我们的实验(见第 3.1 节)表明,草稿标记的接受率不仅取决于位置,而且高度依赖于上下文。因此,草稿树的静态结构存在固有局限性。根据不同上下文中草稿标记的接受率动态调整草稿树结构可以产生更好的结果。
然而,获取草稿标记的接受率需要原始LLM的正向结果,这与推测性采样的目标(减少原始LLM的正向次数)相冲突。幸运的是,我们发现EAGLE是经过良好校准的:草稿模型的置信度得分(概率)很好地近似了草稿标记的接受率(参见第3.2节)。这使得使用上下文相关的动态草稿树结构成为可能。
我们提出了 EAGLE-2,它利用草稿模型的置信度得分来近似接受率。在此基础上,它动态调整草稿树结构,增加接受的标记数量。在 MT-bench 数据集上,EAGLE-2 比 Medusa 快约 2 倍,比 Lookahead 快约 2.3 倍,同时确保输出分布保持不变。
2.1 预备知识
(1) 推测采样和eagle


图3b
 备注:有人证明了这种分布的一致性
备注:有人证明了这种分布的一致性
在标准的推测性采样中,草稿是链式结构的,如果草稿令牌被拒绝,则需要丢弃所有后续令牌。EAGLE 使用树状结构的草稿,允许在草稿令牌被拒绝时尝试其他分支。图 3b 说明了这两种方法之间的区别。
(2)eagle2和eagle的区别
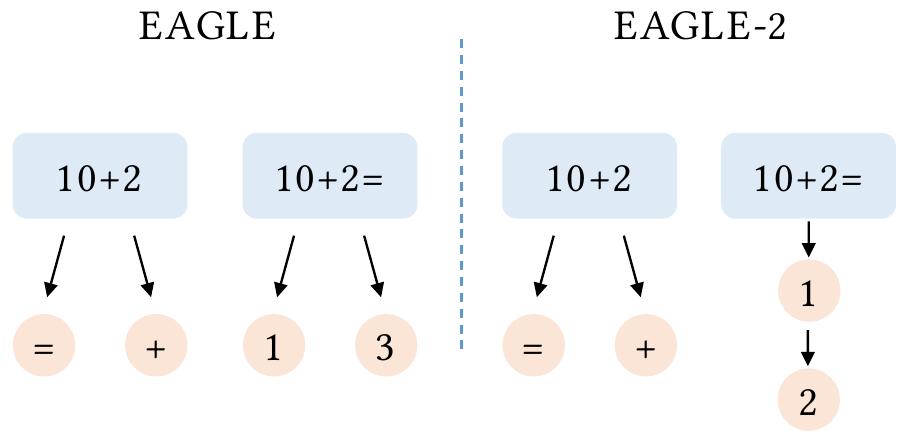
图 4:EAGLE 和 EAGLE-2 之间的差异。EAGLE 始终使用固定的草稿形状。当查询为“10+2=”时,下一个标记很可能被正确预测为“1”。然而,使用静态草稿树,EAGLE 仍然会添加两个候选者,即使另一个候选者“3”为正确的概率非常低。另一方面,EAGLE-2 根据上下文调整草稿树的形状。当查询为“10+2”时,下一个标记很难预测,因此 EAGLE-2 添加了两个候选者。对于更简单的查询“10+2=”,EAGLE-2 只添加了一个候选者“1”。
2.2 动态草稿树的必要性
首先,我们评估使用动态草稿树的必要性。总体而言,草稿标记的接受率与位置相关,在位置 P1 处接受率最高,在位置 P6 处接受率最低。草稿树左上角的标记(例如位置 P1)具有更高的接受率,而右下角的标记(例如位置 P6)则具有较低的接受率。这支持了在 EAGLE 和 Medusa 等方法使用的静态草稿树中,在左上角有更多节点,而在右下角有更少节点的理由。然而,我们也观察到相同位置的接受率存在显著差异,这表明草稿标记被接受的概率不仅取决于其位置,还取决于上下文。这表明,上下文感知的动态草稿树比静态草稿树具有更大的潜力。
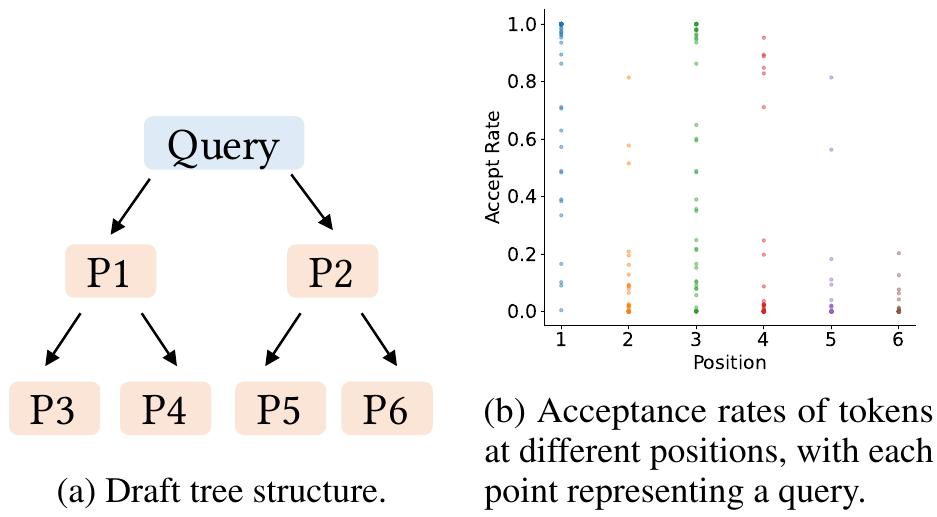
图5
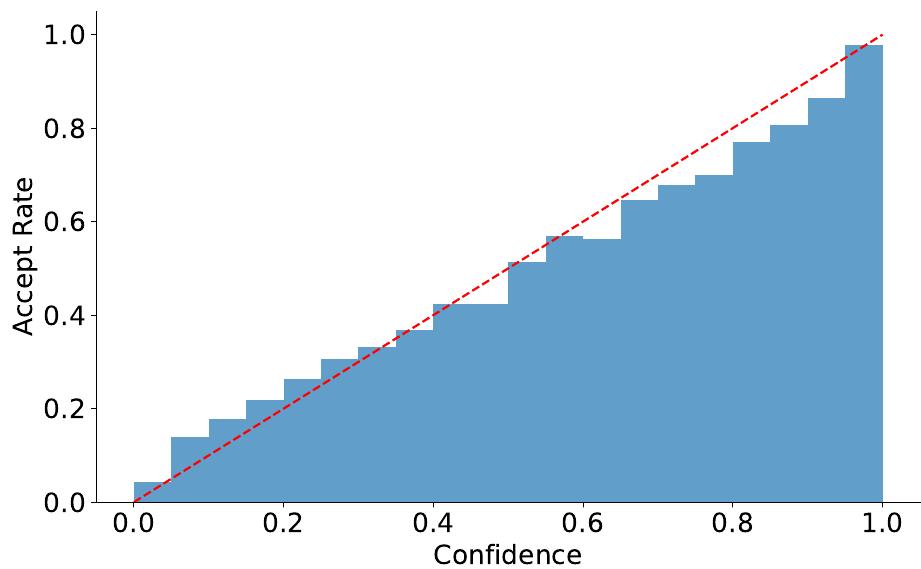
图6
如图6所示,草稿模型的置信度得分与标记的接受率之间存在很强的正相关关系。置信度得分低于0.05的草稿标记的接受率约为0.04,而置信度得分高于0.95的草稿标记的接受率约为0.98。因此,我们可以使用草稿模型的置信度得分来估计接受率,而无需额外的开销,从而实现对草稿树的动态调整。在其他方法中,例如GLIDE和CAPE(Du等人,2024),也观察到了类似的现象。
2.3 动态草稿树
基于上述观察,我们引入了 EAGLE-2,这是一种用于 LLM 推理的加速算法,它动态调整草稿树。EAGLE-2 不会改变草稿模型的训练和推理,也不会影响验证阶段。它的改进集中在两个方面:如何扩展草稿树(第 4.1 节)以及如何重新排序草稿令牌(第 4.2 节)。在扩展阶段,我们将草稿树最新层中最有希望的节点输入到草稿模型中,以形成下一层。在重新排序阶段,我们选择具有更高接受概率的令牌,以形成验证阶段原始 LLM 的输入。
2.3.1 扩展阶段
得益于树形注意力机制,草稿模型能够同时输入当前层的所有标记,并在单次前向传递中计算下一个标记的概率,从而扩展当前层的所有标记。然而,一次输入过多标记会导致草稿模型的前向传递速度变慢,并且草稿树每一层的标记数量呈指数级增长。因此,我们需要选择性地扩展草稿树。


2.3.2 重排序阶段
扩展阶段的目的是加深草稿树。由于接受率在 0 到 1 之间,更深层的令牌的值更低。一些未扩展的浅层节点可能比更深层的扩展节点具有更高的值。因此,我们不直接使用扩展阶段选择的令牌作为草稿。相反,我们重新对所有草稿令牌进行排序,并选择具有最高值的排名前 m 个令牌。节点的值始终小于或等于其父节点的值。对于具有相同值的节点,我们优先选择更浅层的节点。这确保了重新排序后选择的排名前 m 个令牌仍然形成一个连通树。
随后,我们将选定的标记扁平化为一维序列,作为验证阶段的输入。为了确保与普通自回归解码的一致性,我们还需要调整注意力掩码。在普通自回归解码中,每个标记可以看见所有前面的标记,从而形成一个下三角注意力矩阵。当使用草稿树时,来自不同分支的标记不应该互相可见。因此,注意力掩码必须根据树结构进行调整,以确保每个标记只能看见其祖先节点。图 7 底部说明了重新排序阶段。

图7
图 7:EAGLE-2 的示意图。边旁的数字代表草稿模型的置信度得分,方块内的括号数字代表节点的值。在扩展阶段,我们从当前层(橙色方块)中选择两个值最高的节点作为草稿模型的输入,并将生成的标记(绿色方块)连接到草稿树。在重新排序阶段,我们从所有节点(蓝色方块)中选择八个值最高的节点,将它们展平成一维序列,形成最终的草稿。然后,我们根据树结构构建注意力掩码,确保每个标记只能看到其祖先节点。
2.4 指标
Speedup Ratio: The actual test speedup ratio relative to vanilla autoregressive decoding.
• 加速比:相对于普通自回归解码的实际测试加速比。
• 平均接受长度 τ:每个草稿验证循环生成的标记平均数量,对应于从草稿中接受的标记数量。平均接受长度的优点是它独立于硬件和运行时环境,而其缺点是不反映草稿模型的开销。
为什么不包含接受率?接受率只反映了草稿模型的性能。由于 EAGLE-2 不会修改草稿模型的结构,因此接受率与 EAGLE 的接受率保持一致。
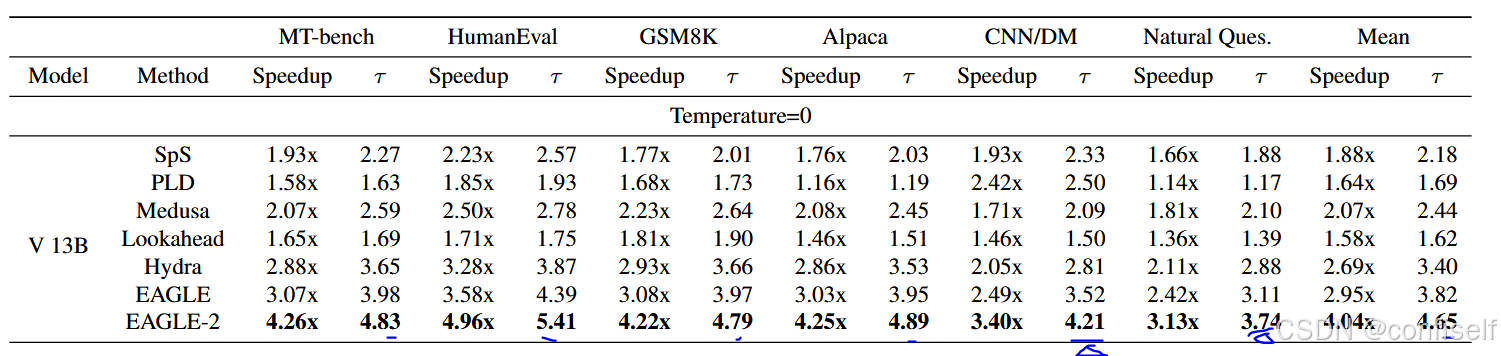
在所有我们测试的数据集和LLM中,EAGLE-2 实现了最高的加速比。大多数推测性采样方法在代码生成任务(HumanEval)上表现出最高的加速比,得益于代码中广泛使用固定模板。EAGLE 在代码生成任务上实现了高达 5 倍的加速。当使用 Vicuna 作为原始 LLM 时,PLD 在摘要任务(CNN/DM)上实现了最高的加速比,这是由于 PLD 的基于检索的草稿生成以及 Vicuna 执行摘要时上下文的高度重叠。使用 Vicuna-68M 作为草稿模型的标准推测性采样也实现了显著的加速,但与其他方法相比,其训练开销要高得多。PLD 和 Lookahead 不需要训练,而 Medusa、Hydra、EAGLE 和 EAGLE-2 使用 SFT 数据集来训练它们的草稿模型。Vicuna-68M 使用了预训练和 SFT 数据集,预训练数据集远大于 SFT 数据集。
备注:PLD这种摘要提速和Lookahead值得研究下
在我们测试的所有数据集和 LLM 中,EAGLE2 实现了最长的平均接受长度。EAGLE-2 的每个起草-验证循环大约生成 4-5.5 个 token,显著高于其他方法,大约是标准推测采样和 Medusa 的两倍。PLD 和 Lookahead 的平均接受长度较短,但由于它们要么缺乏草稿模型,要么它们的草稿模型不是神经网络,因此起草阶段的开销非常低,导致加速比非常接近它们的平均接受长度。
与其他任务相比,美杜莎、九头蛇、EAGLE 和 EAGLE-2 在问答(自然问题)和摘要(CNN/DM)任务上的平均接受长度更低,而标准推测性采样则没有出现这种下降。在加速比方面也观察到了相同的模式。这种差异可能是由于草稿模型训练数据的差异造成的。标准推测性采样的草稿模型使用预训练和 SFT 数据集,而美杜莎、九头蛇、EAGLE 和 EAGLE2 仅使用 SFT 数据集。自然问题涉及关于世界知识的问题,例如“2015 年橄榄球联盟世界杯在哪里举行?”,而世界知识主要通过预训练而不是 SFT 获得。摘要任务在 SFT 数据集中也较少。这表明扩展草稿模型训练数据的潜在益处。尽管如此,EAGLE-2 在这两个数据集上仍然优于标准推测性采样。
备注:如何提高在自然语言和摘要问答上面的效果?

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)