【大模型】大模型量化
最后,在知道了这么多量化方法后,对于如何选择量化,关于LLAMA-3 量化相关的论文中的相关结论。1. 8bit 量化是免费午餐,无损失。2. AWQ 4bit量化对8B模型来说有2%性能损失,对70B模型只有0.05%性能损失。可以说也是免费午餐了。3. 参数越大的模型,低bit量化损失越低。AWQ 3bit 70B 也只有2.7%性能损失,完全可接受。4. 综合来说,如果追求无任何性能损失,8
前言
模型量化意味着将高精度数字转换为低精度数字,通过以更少的位数表示浮点数据。低精度实体可以减少模型尺寸,进而减少在推理时的内存消耗,并且在一些低精度运算较快的处理器上可以增加推理速度。
1.量化方法
1.1 对称量化
对称量化(Symmetric Quantization)是将浮点数映射到对称的整数区间(例如[-127,127])。公式如下:

1.2 非对称量化
非对称量化(Asymmetric Quantization),适用于数据分布不均衡的情况。公式如下:
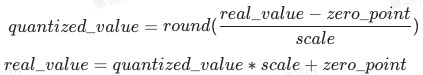
其中scale是量化因子,zero_point是偏移量,用于调整实数值。
1.3 对称量化实例
假设有25个以 FP16 格式显示的权重值,如下所示的矩阵:

我们需要对这些值进行 int8 量化。下面是具体步骤:
1. 旧范围 = FP16 格式中的最大权重值 - FP16 格式中的最小权重值 = 0.932–0.0609 = 0.871
2. 新范围 = Int8 包含从 -128 到 127 的数字。因此,范围 = 127-(-128) = 255
3. 比例 (Scale) = 新范围中的最大值 / 旧范围中的最大值 = 127 / 0.932 = 136.24724986904138
4. 量化值 = 四舍五入(比例 * 原始值)
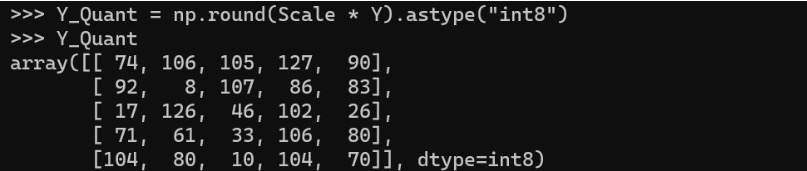
5. 反量化值 = 量化值 / 比例
 6. 四舍五入误差 — 这里需要注意的一个重要点是,当我们反量化回到 FP16 格式时,可以看到到数字似乎并不完全相同。第一个元素 0.5415 变成了 0.543。大多数元素都会出现相同的问题。这是量化 - 反量化过程的结果所导致的误差。
6. 四舍五入误差 — 这里需要注意的一个重要点是,当我们反量化回到 FP16 格式时,可以看到到数字似乎并不完全相同。第一个元素 0.5415 变成了 0.543。大多数元素都会出现相同的问题。这是量化 - 反量化过程的结果所导致的误差。
2.量化对象
模型量化的对象主要包括以下几个方面。
(1)权重(weight):weight的量化是最常规也是最常见的。量化weight可达到减少模型大小内存和占用空间。
(2)激活(activation):实际中activation往往是占内存使用的大头,因此量化activation不仅可以大大减少内存占用。更重要的是,结合weight的量化可以充分利用整数计算获得性能提升。
(3)KV cache:量化 KV 缓存对于提高长序列生成的吞吐量至关重要。
(4)梯度(Gradients):相对上面两者略微小众一些,因为主要用于训练。在训练深度学习模型时,梯度通常是浮点数,它主要作用是在分布式计算中减少通信开销,同时,也可以减少backward时的开销。
3.量化过程
量化过程可以分为以下三种方法。
3.1 量化感知训练
量化感知训练(Quantization Aware Training, QAT)。QAT 的基本思想是根据该层权重的精度将输入量化为较低的精度。QAT 还负责在下一层需要时将权重和输入相乘的输出转换回较高的精度。这个将输入量化为较低精度,然后将权重和输入的输出转换回较高精度的过程也称为“伪量化节点插入”。这种量化被称为伪量化,因为它既进行了量化,又进行了反量化,转换成了基本操作。
QAT在训练过程中模拟量化,让模型在不损失精度的情况下适应更低的位宽。与量化预训练模型的训练后量化(PTQ)不同,QAT涉及在训练过程本身中量化模型。QAT过程可以分解为以下步骤:
-
定义模型:定义一个浮点模型,就像常规模型一样。
-
定义量化模型。定义一个与原始模型结构相同但增加了量化操作(如torch.quantization.QuantStub())和反量化操作(如torch.quantization.DeQuantStub())的量化模型。
-
准备数据。准备训练数据并将其量化为适当的位宽。
在 QAT 中,主要对不会导致参数量化后精度损失过大的层进行量化。那些参数被量化时会对精度产生负面影响的层将保持不变量化。
QAT是在训练过程中,考虑量化的影响进行训练。在训练开始前,构建一个包含量化操作的模型。在训练过程中,对权重和激活值进行模拟量化(通常是通过在向前传播过程中插入量化和反量化操作)并使用量化后的值进行反向传播和参数更新。
3.2 量化感知微调
量化感知微调(Quantization-Aware Fine-tuning,QAF)。在微调过程中对LLM进行量化。主要目标是确保经过微调的LLM在量化为较低位宽后仍保持性能。通过将量化感知整合到微调中,以在模型压缩和保持性能之间取得平衡。
3.3 训练后量化
训练后量化(Post Training Quantization, PTQ)在LLM训练完成后对其参数进行量化,只需要少量校准数据,适用于追求高易用性和缺乏训练资源的场景。主要目标是减少LLM的存储和计算复杂性,而无需对LLM架构进行修改或进行重新训练。
PTQ的主要优势在于其简单性和高效性。但PTQ可能会在量化过程中引入一定程度的精度损失。
4.训练后量化
4.1 权重量化
4.1.1 GPTQ
论文:《GPTQ: ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS》。对某个 block 内的所有参数逐个量化,每个参数量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。 GPTQ 量化需要准备校准数据集。
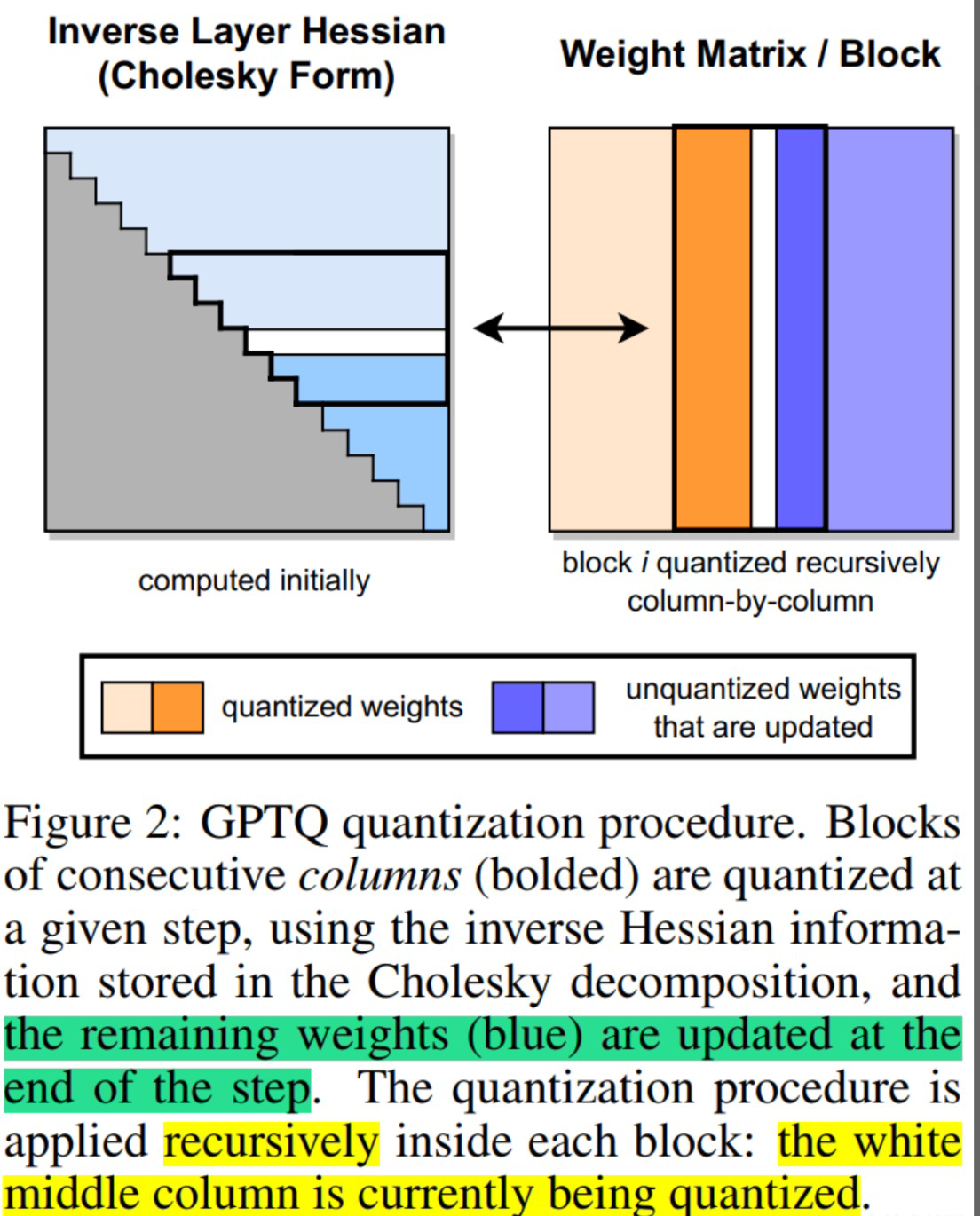
GPTQ 是一种针对4位量化的训练后量化 (PTQ) 方法,主要关注GPU推理和性能。该方法的思想是通过将所有权重压缩到4位量化中,通过最小化与该权重的均方误差来实现。在推理过程中,它将动态地将权重解量化为float16,以提高性能,同时保持内存较低。具体操作包括以下几个步骤:
缩放:将输入张量x除以缩放因子scale。这一步是为了将x的值范围调整到预期的量化范围。
四舍五入:将缩放后的结果四舍五入到最近的整数。这一步是为了将x的值离散化,即将其转换为整数。
限制范围:使用torch.clamp函数将四舍五入后的结果限制在0和maxq之间。这一步是为了确保量化后的值不会超出预期的量化范围。
反缩放:将量化后的张量减去零点zero,然后乘以缩放因子scale。这一步是为了将量化后的值恢复到原始的值范围。
4.1.2 AWQ
论文:《AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration》

AWQ是一种类似于 GPTQ 的量化方法。AWQ 和 GPTQ 之间有几个区别,但最重要的区别是 AWQ 假设并非所有权重对 LLM 的性能都同等重要,通过保留1%的显著权重可以大大减少量化误差。换句话说,在量化过程中,不会对所有权重进行量化;只会量化对于模型保持有效性不重要的权重。因此,他们的论文提到与 GPTQ 相比,它们在保持类似甚至更好性能的同时实现了显著的加速。该方法采用逐通道缩放技术来确定最佳缩放因子,从而在量化所有权重的同时最小化量化误差。
- 校准:向预训练的LLM传递样本数据,以确定权重和激活的分布。确定重要的激活和相应的权重。
- 缩放:将这些关键实体放大,同时将其余权重量化为较低精度。这样做可以将由于量化而引起的准确性损失降到最低,因为这是在放大最重要的权重,同时降低不重要权重的精度。
4.1.3 SpQR
论文:《SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression》确定并隔离了异常权重,将其存储在更高的精度中,并将所有其他权重压缩为3-4比特。
4.2 全量化
全量化包含权重和激活量化。
4.2.1 SmoothQuant
论文:《SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models》
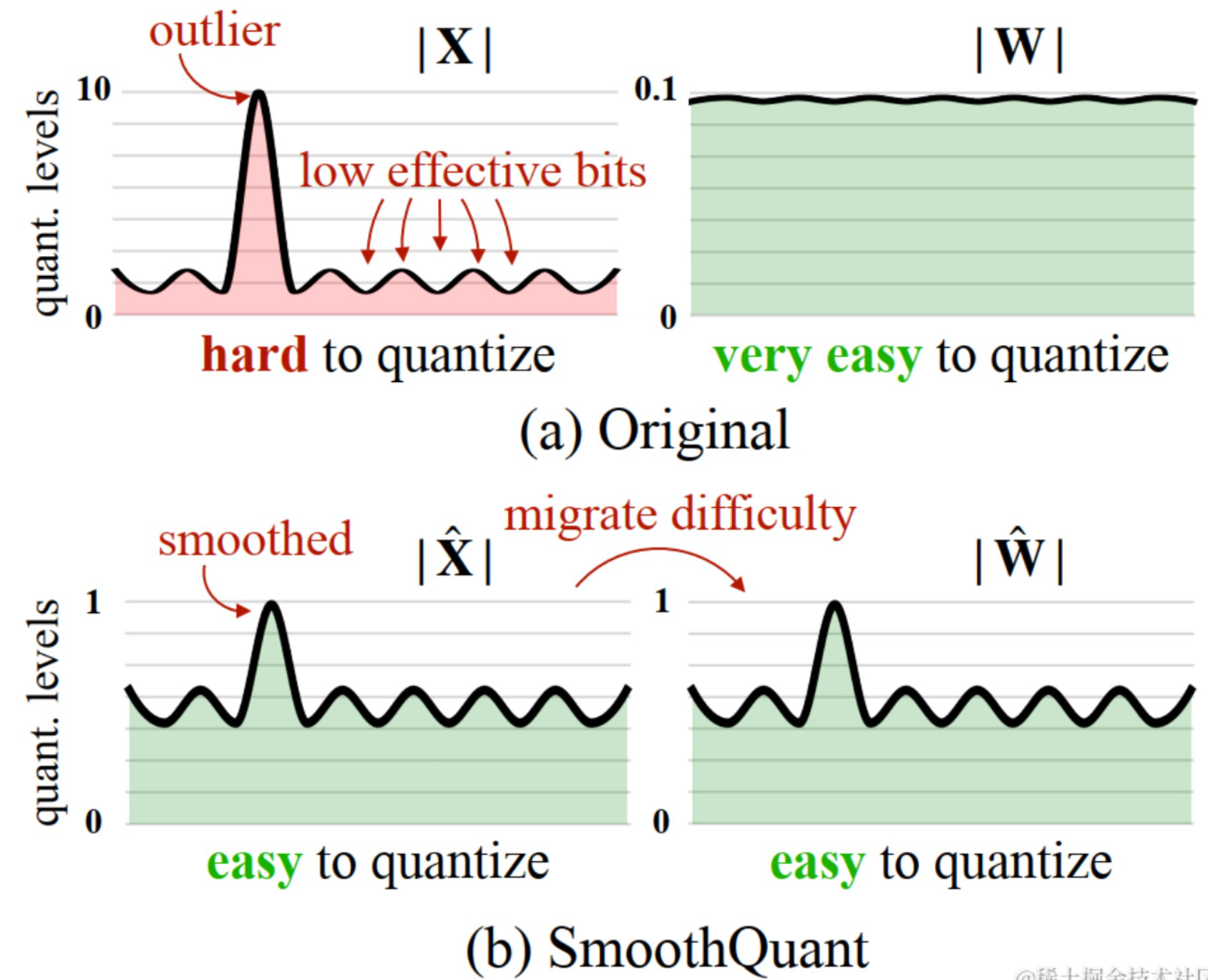
LLM中激活往往由于异常值的存在而变得更加复杂,而SmoothQuant解决了量化激活的挑战。SmoothQuant观察到不同的token在它们的通道上展示出类似的变化,引入了逐通道缩放变换,有效地平滑了幅度,使得模型更易于量化。
4.2.2 RPTQ
论文:《RPTQ: Reorder-based Post-training Quantization for Large Language Models》
鉴于量化LLM中激活的复杂性,RPTQ揭示了不同通道之间不均匀范围的挑战,以及异常值的存在所带来的问题。为了解决这个问题,RPTQ将通道策略性地分组为簇进行量化,有效地减轻了通道范围的差异。此外,它将通道重排集成到层归一化操作和线性层权重中,以最小化相关的开销。
4.2.3 OliVe
论文:《OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization》
进一步采用了 outlier-victim 对(OVP)量化,并在低硬件开销和高性能增益的情况下局部处理异常值,因为它发现异常值很重要,而其旁边的正常值却不重要。
4.2.4 Outlier Suppression+
论文:《Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling》
通过确认激活中的有害异常呈现出不对称分布,主要集中在特定通道中。因此,引入了一种新的策略,涉及通道级的平移和缩放操作,以纠正异常的不对称呈现,并减轻问题通道的影响,并定量分析了平移和缩放的最佳值,同时考虑了异常的不对称性以及下一层权重引起的量化误差。
4.2.5 ZeroQuant-FP
论文:《ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 Quantization Using Floating-Point Formats》
探索了浮点(FP)量化的适用性,特别关注FP8和FP4格式。研究揭示,对于LLM,FP8激活在性能上持续优于INT8,而在权重量化方面,FP4在性能上与INT4相比具有可比性,甚至更优越。为了解决由权重和激活之间的差异引起的挑战,ZeroQuant-FP要求所有缩放因子为2的幂,并将缩放因子限制在单个计算组内。值得注意的是,ZeroQuant-FP还集成了Low Rank Compensation (LoRC) 策略,以进一步增强其量化方法的有效性。
5.总结
最后,在知道了这么多量化方法后,对于如何选择量化,关于LLAMA-3 量化相关的论文中的相关结论。

1. 8bit 量化是免费午餐,无损失。
2. AWQ 4bit量化对8B模型来说有2%性能损失,对70B模型只有0.05%性能损失。可以说也是免费午餐了。
3. 参数越大的模型,低bit量化损失越低。AWQ 3bit 70B 也只有2.7%性能损失,完全可接受。
4. 综合来说,如果追求无任何性能损失,8B模型用8bit量化,70B模型用4bit量化;如果能接受2-3%损失,8B模型用4bit量化,70B模型用3bit量化。
Reference:
1.https://www.53ai.com/news/qianyanjishu/2276.html

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 28
28 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)