实战 KNN 算法:从数据可视化到模型预测全流程解析
通过这三段代码,我们完整实现了 KNN 算法从数据探索→模型训练→效果评估→业务预测的全流程。数据可视化:可以帮助我们理解政务数据的分布规律,发现潜在的业务关联。标准化处理:对于多源异构的政务数据,标准化是保证算法效果的关键步骤。模型预测:可以应用于企业信用评估、办事需求预判等多种政务业务场景。KNN 算法虽然简单,但它揭示了机器学习的核心思想 ——“相似的输入会产生相似的输出”。掌握这个基础算法
在机器学习的入门算法中,K 近邻(KNN)以其原理简单、易于实现的特点,成为很多初学者的首选。本文将结合三段完整的代码实例,带大家从数据可视化、模型训练到批量预测,完整走一遍 KNN 算法的落地流程,所用的经典约会数据集也非常适合理解算法的核心逻辑。
一、KNN算法介绍
全称为k-nearest neighbors,通过寻找k个距离相近的数据,来确定当前数据值的大小或类别,是机器学习中最为简单和经典的一个算法。
KNN算法分为回归和分类
分类:核心是预测「离散的类别标签」(如苹果 / 香蕉、动作片 / 喜剧),靠 “少数服从多数” 确定结果
回归:核心是预测「连续的数值」(如房价、分数),靠 “邻居数值的平均值” 确定结果
距离计算公式
欧式距离:

曼哈顿距离:

Sklearn
sklearn(Scikit-Learn)是基于python语言的第三方机器学习库。它建立在Numpy,scipy,pandas和Matplotlib库之上
Sklearn安装
pip install scikit-learn==1.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple看到successful就安装成功了,和numpy库安装语句类似
在建模之前,我们首先要对数据的分布有直观认识。通过三维散点图,我们可以清晰看到不同类别样本在特征空间中的分布规律。
核心代码实现
import matplotlib.pyplot as plt # 用于数据可视化
import numpy as np # numpy专门处理矩阵数据
data = np.loadtxt('datingTestSet2(1).txt') # 使用numpy库读取txt文件
data_1 = data[data[:, -1] == 1] # 找出最后一行类别为1的数据
data_2 = data[data[:, -1] == 2] # 找出最后一行类别为2的数据
data_3 = data[data[:, -1] == 3] # 找出最后一行类别为3的数据
fig = plt.figure() # 创建一个图像对象,默认为2维图像
ax = plt.axes(projection="3d") # 图像轴为3维
ax.scatter(data_1[:, 0], data_1[:, 1], zs=data_1[:, 2], c="#00DDAA", marker="o") # 绘制散点图
ax.scatter(data_2[:, 0], data_2[:, 1], zs=data_2[:, 2], c="#FF5511", marker="^")
ax.scatter(data_3[:, 0], data_3[:, 1], zs=data_3[:, 2], c="#000011", marker="+")
ax.set(xlabel="Xaxes", ylabel="Yaxes", zlabel="Zaxes") # 对坐标轴的名字进行设置
plt.show() # 图像显示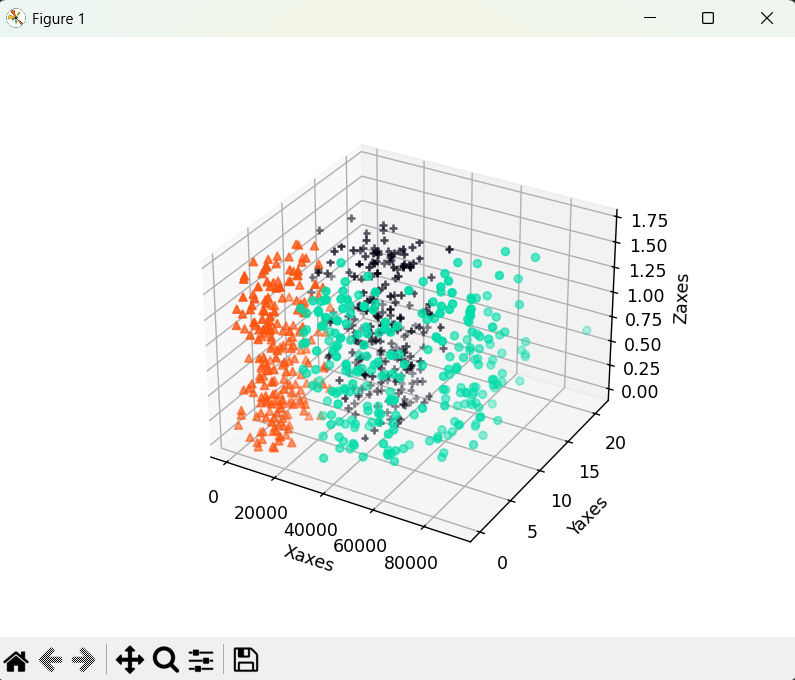
可视化的价值
- 直观认知:通过三维散点图,我们可以看到不同类别的样本在特征空间中呈现出一定的聚集性,这正是 KNN 算法能够生效的前提。
- 特征相关性:从图中可以发现,“每年飞行里程数” 和 “游戏时间占比” 对样本类别的区分度较高,而 “冰淇淋消费量” 的区分度相对较弱。
- 发现问题:如果数据存在明显的异常点或分布不均,我们可以在可视化阶段就发现,提前进行数据清洗。
在对数据有了直观认识后,我们就可以构建 KNN 分类器,完成训练和测试,并评估模型的准确率。
import numpy as np
train_data = np.loadtxt("datingTestSet2(1).txt")
test_data = np.loadtxt("datingTest.txt")
train_X = train_data[:, :-1]
train_Y = train_data[:, -1]
from sklearn.preprocessing import scale
data = scale(train_X)
data_1 = scale(train_X[:, :-1]) # 找出最后一行类别为1的数据
data_2 = scale(train_X[:, :-1]) # 找出最后一行类别为2的数据
data_3 = scale(train_X[:, :-1]) # 找出最后一行类别为3的数据
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(data, train_Y)
train_predicted = knn.predict(data)
score1 = knn.score(data, train_Y)
print(score1)
test_X = test_data[:, :-1]
test_Y = test_data[:, -1]
from sklearn.preprocessing import scale
data_test = scale(test_X)
a = test_X[0, 0]
data_test1 = scale(test_X[:, :-1])
data_test2 = scale(test_X[:, :-1])
data_test3 = scale(test_X[:, :-1])
test_predicted = knn.predict(test_X)
score = knn.score(data_test, test_Y)
print(score)
训练好的模型最终要用于预测。我们可以用它对单个样本进行预测,也可以批量处理多个样本。
核心代码实现
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
data = np.loadtxt('datingTestSet2(1).txt')
X = data[:, :-1]
Y = data[:, -1]
neigh = KNeighborsClassifier(n_neighbors=5)
neigh.fit(X, Y)
print(neigh.predict([[23759, 9.454321, 0.982593]]))
predict_data = [[19744, 8.456733, 2.356335],
[17642, 1.345667, 1.634425],
[34325, 6.519522, 3.248664],
[26532, 11.475155, 1.845789]]
#
print("再次多人同时预测")
print(neigh.predict(predict_data))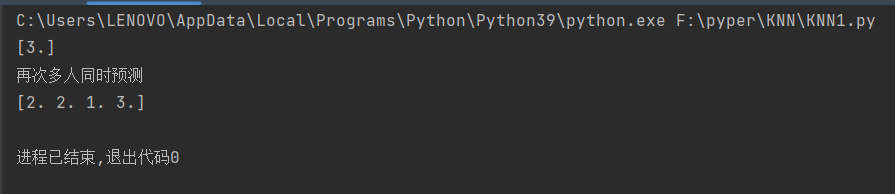
通过这三段代码,我们完整实现了 KNN 算法从数据探索→模型训练→效果评估→业务预测的全流程。在机关和政务数据场景中,这套流程同样适用:
- 数据可视化:可以帮助我们理解政务数据的分布规律,发现潜在的业务关联。
- 标准化处理:对于多源异构的政务数据,标准化是保证算法效果的关键步骤。
- 模型预测:可以应用于企业信用评估、办事需求预判等多种政务业务场景。
KNN 算法虽然简单,但它揭示了机器学习的核心思想 ——“相似的输入会产生相似的输出”。掌握这个基础算法,能为后续学习更复杂的模型打下坚实的基础。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)