大模型qwen3使用llama.cpp转换为gguf格式
为了在安卓设备上顺利运行Qwen3系列大模型,通常需要借助llama.cpp工具将原始模型转换为更适合移动端部署的GGUF格式。GGUF是一种轻量、高效的模型格式,支持在资源受限的设备上进行推理。通过这一转换流程,不仅可以减小模型体积,还能提升在手机端的加载速度与运行效率,从而实现本地化、低延迟的AI体验。
·
步骤一:合并模型
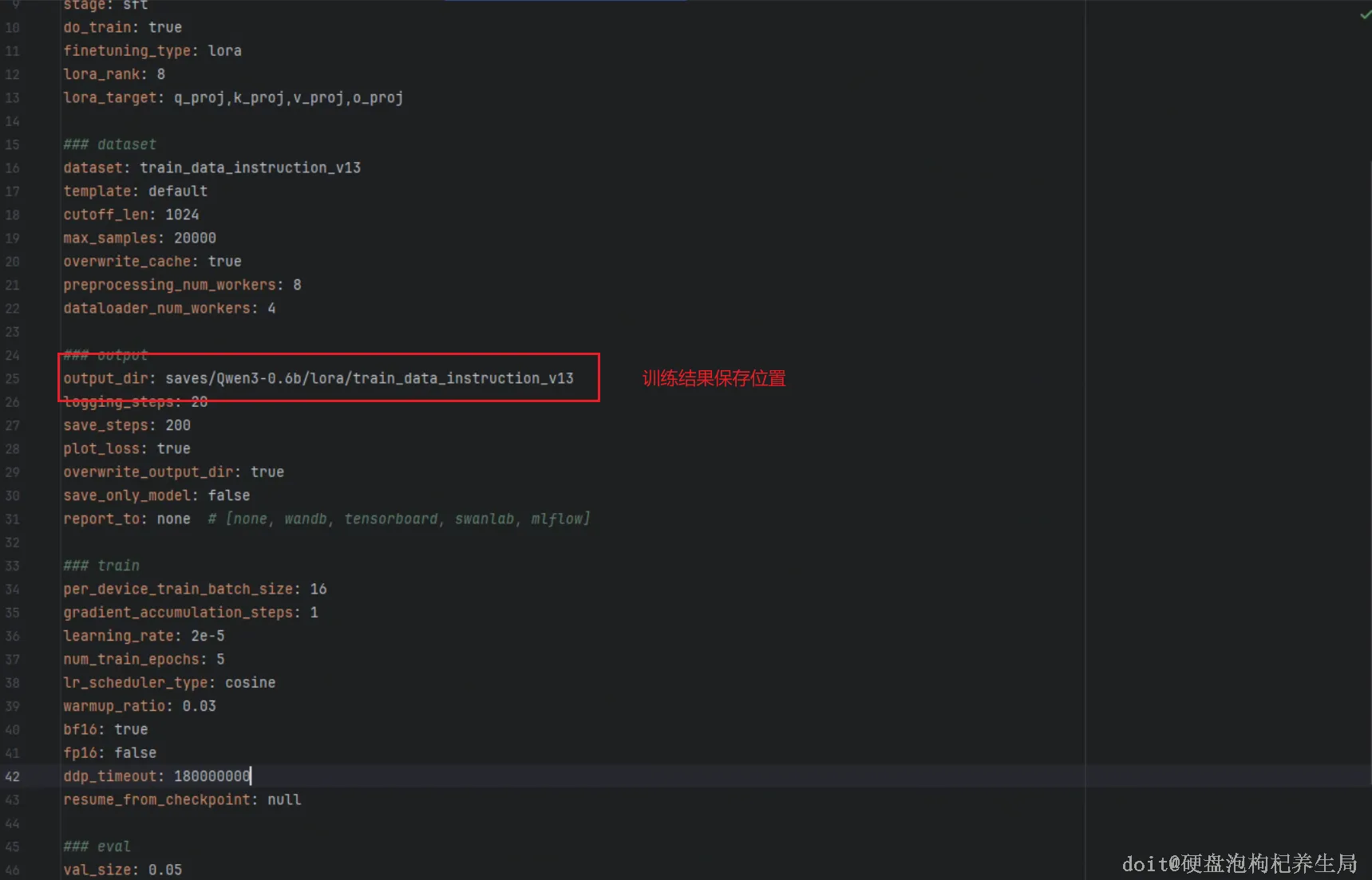
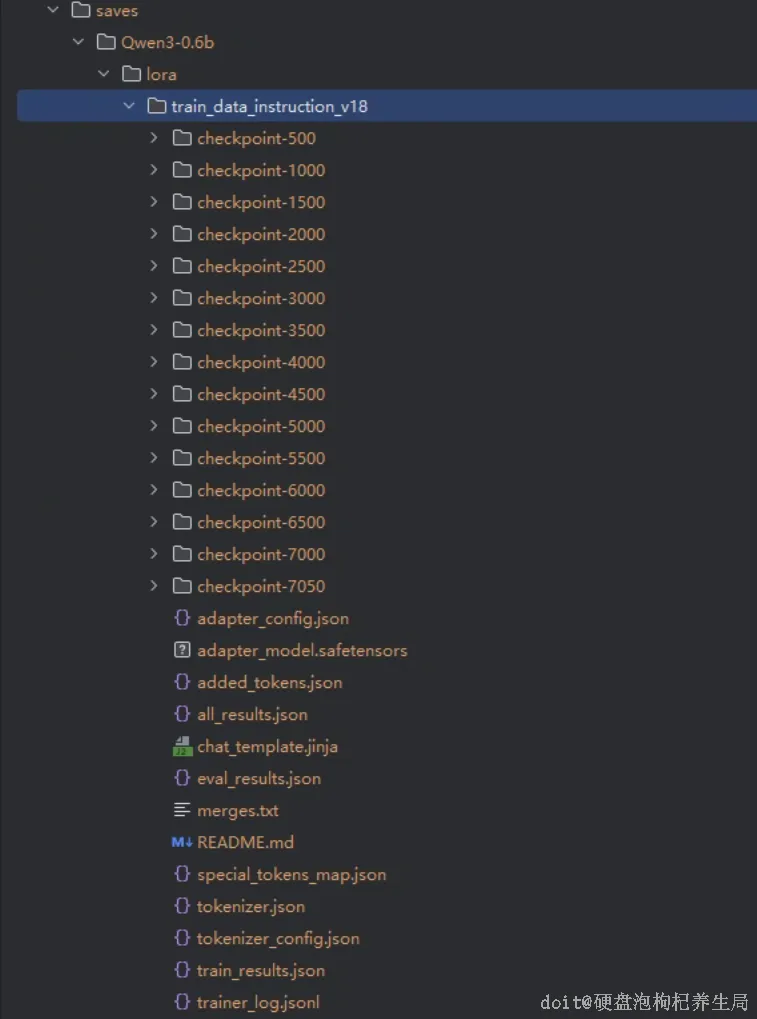

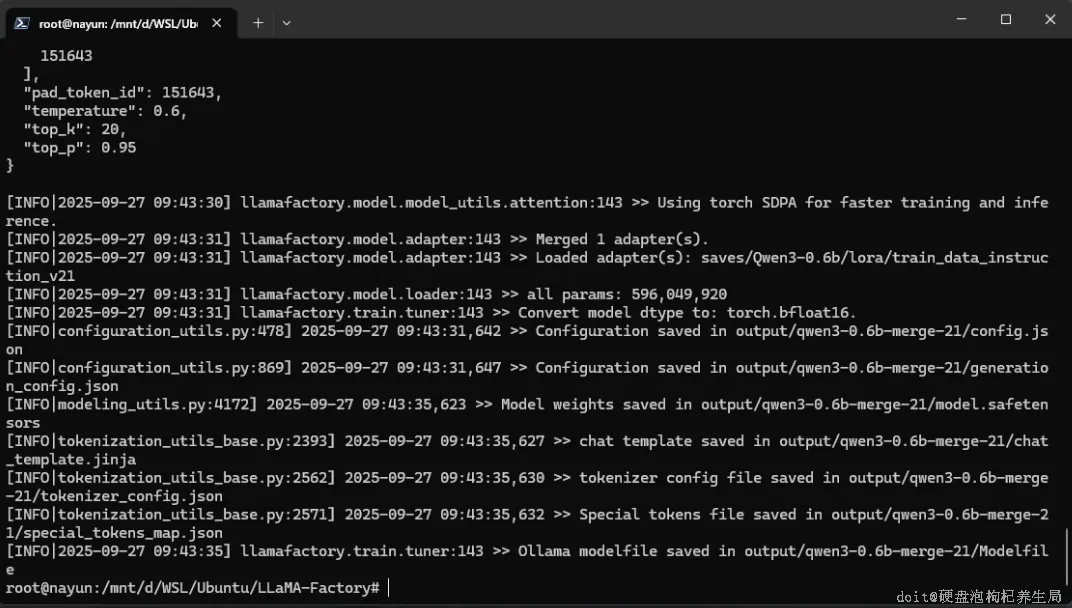
基于训练完成的模型进行导出。训练时已在配置文件中通过 `output_dir` 字段指定了模型保存路径。现在,我们在 `examples/` 目录下创建一个用于模型导出的 YAML 配置文件:
vim examples/qwen3_lora_sft.yaml
写入以下内容:
# 基础模型名称或路径(此处使用 Qwen3-0.6B)
model_name_or_path: Qwen/Qwen3-0.6B
# 训练完成后 LoRA 适配器的保存路径
adapter_name_or_path: saves/Qwen3-0.6b/lora/train_data_instruction_v19
# 使用的对话模板(默认)
template: default
# 允许加载远程自定义代码(Qwen 系列模型必需)
trust_remote_code: true
# 导出合并后模型的保存目录
export_dir: output/qwen3-0.6b-merge-1
# 每个分片文件的最大大小(单位:GB)
export_size: 3
# 导出时使用的设备(可选:cpu 或 auto)
export_device: cpu
# 是否使用旧版(transformers < 4.37)的权重格式
export_legacy_format: false使用以下命令执行模型导出:
llamafactory-cli export examples/qwen3_lora_sft.yaml该命令会将 LoRA 适配器与基础模型合并,并将最终的完整模型导出至 `export_dir` 指定的目录中。
步骤二:下载llama.cpp
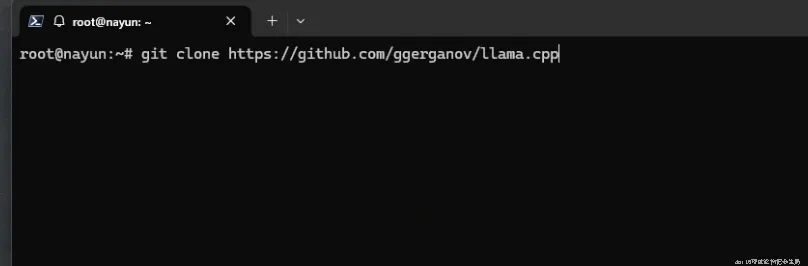
// 下载llama.cpp源码
git clone https://github.com/ggerganov/llama.cpp
// 进入llama.cpp目录
cd llama.cpp步骤三:编译llama
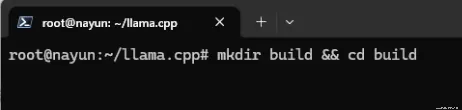
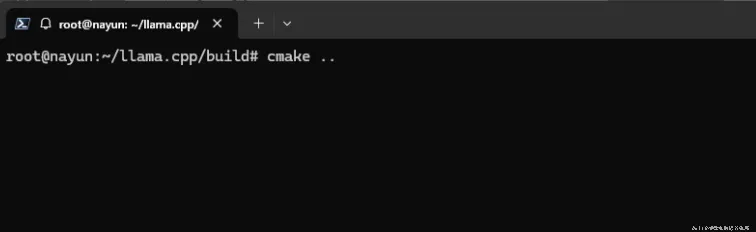
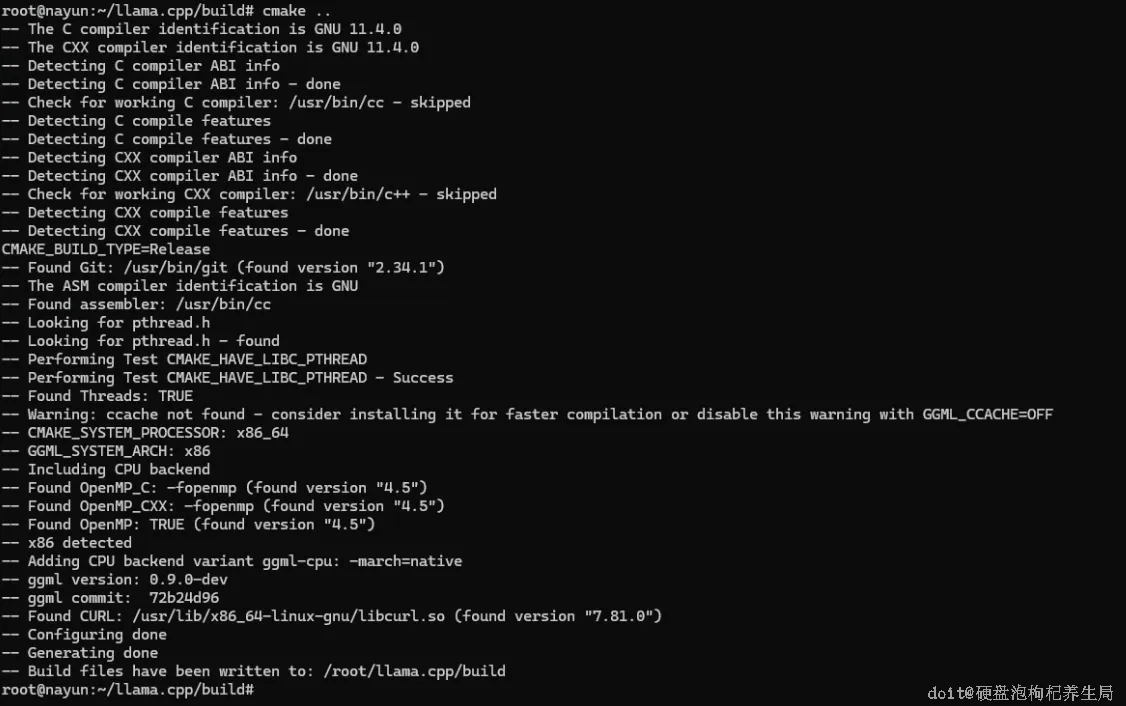
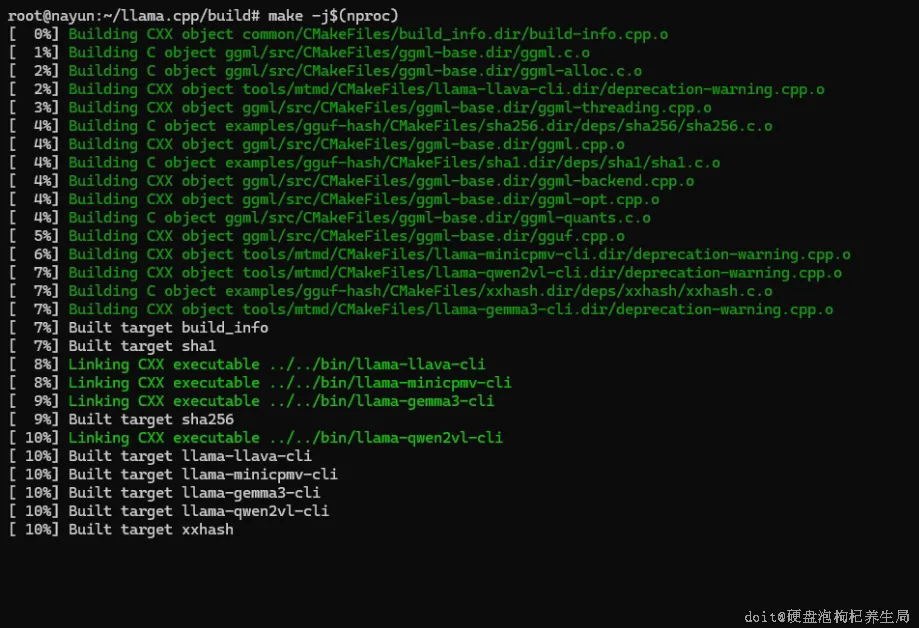
# 创建构建目录并进入
mkdir build && cd build
# 配置项目(使用 CMake)
cmake ..
# 并行编译(使用所有 CPU 核心)
make -j$(nproc)步骤四:转换模型

![]()

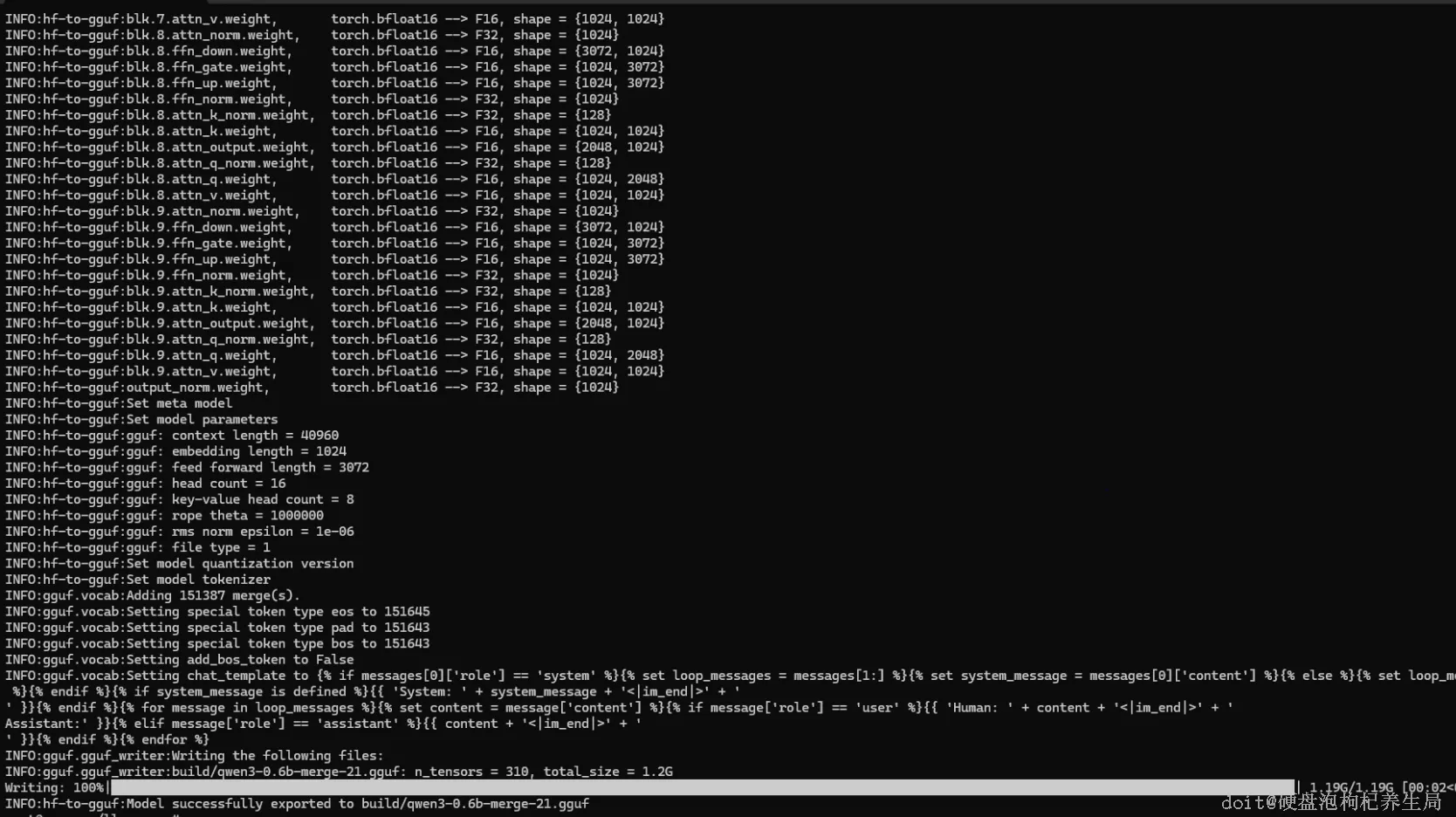
将导出的模型复制到models目录
// 创建文件夹
mkdir -p /root/models/qwen3-0.6b
// 复制文件到models目录
cp -r /mnt/d/wsl/Ubuntu/LLaMA-Factory/output/qwen3-0.6b-merge-21 /root/models/qwen3-0.6b
// 查看文件
ls /root/models/qwen3-0.6b/
// 回到llama.cpp目录
cd ..
// 进行模型转换
python convert_hf_to_gguf.py /root/models/qwen3-0.6b/qwen3-0.6b-merge-21 --outfile ./build/qwen3-0.6b-merge-21.gguf步骤五:运行gguf文件
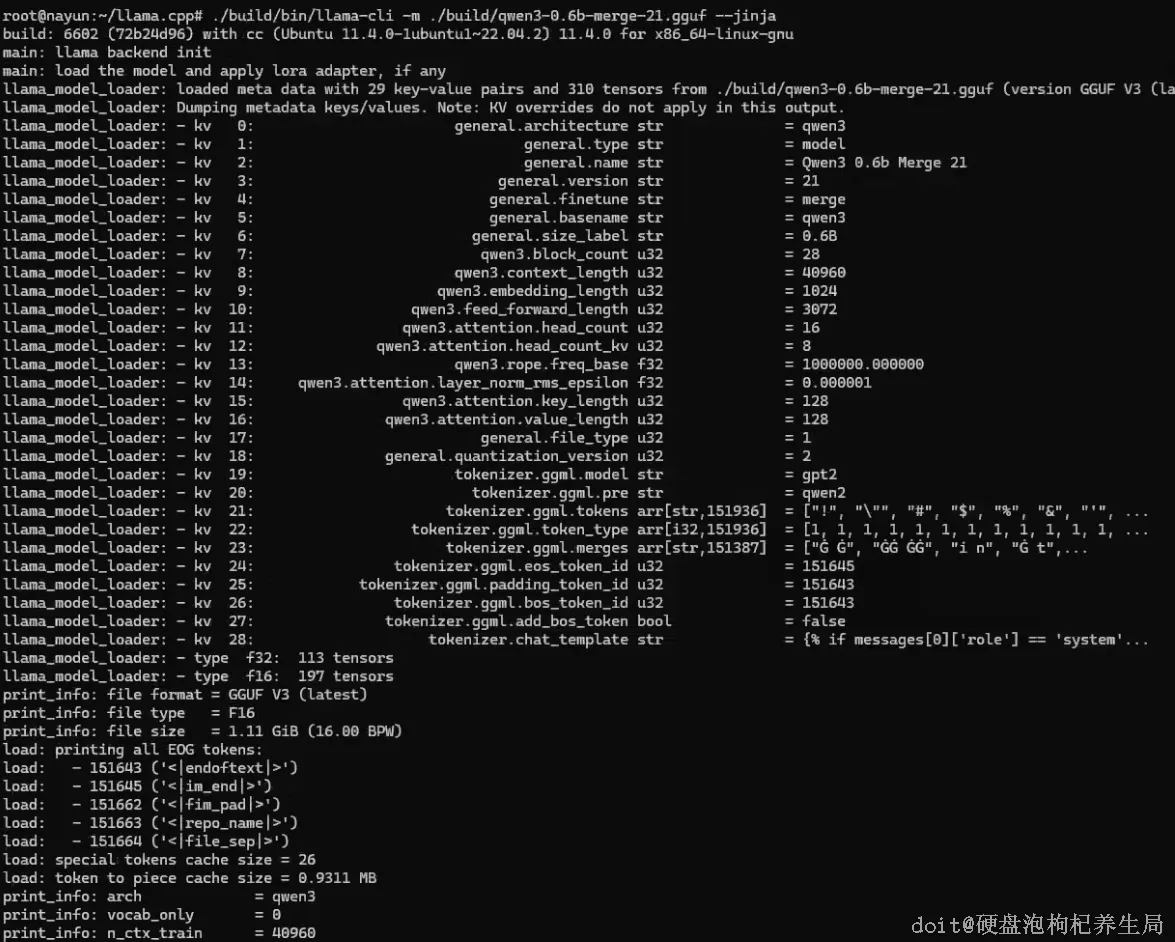
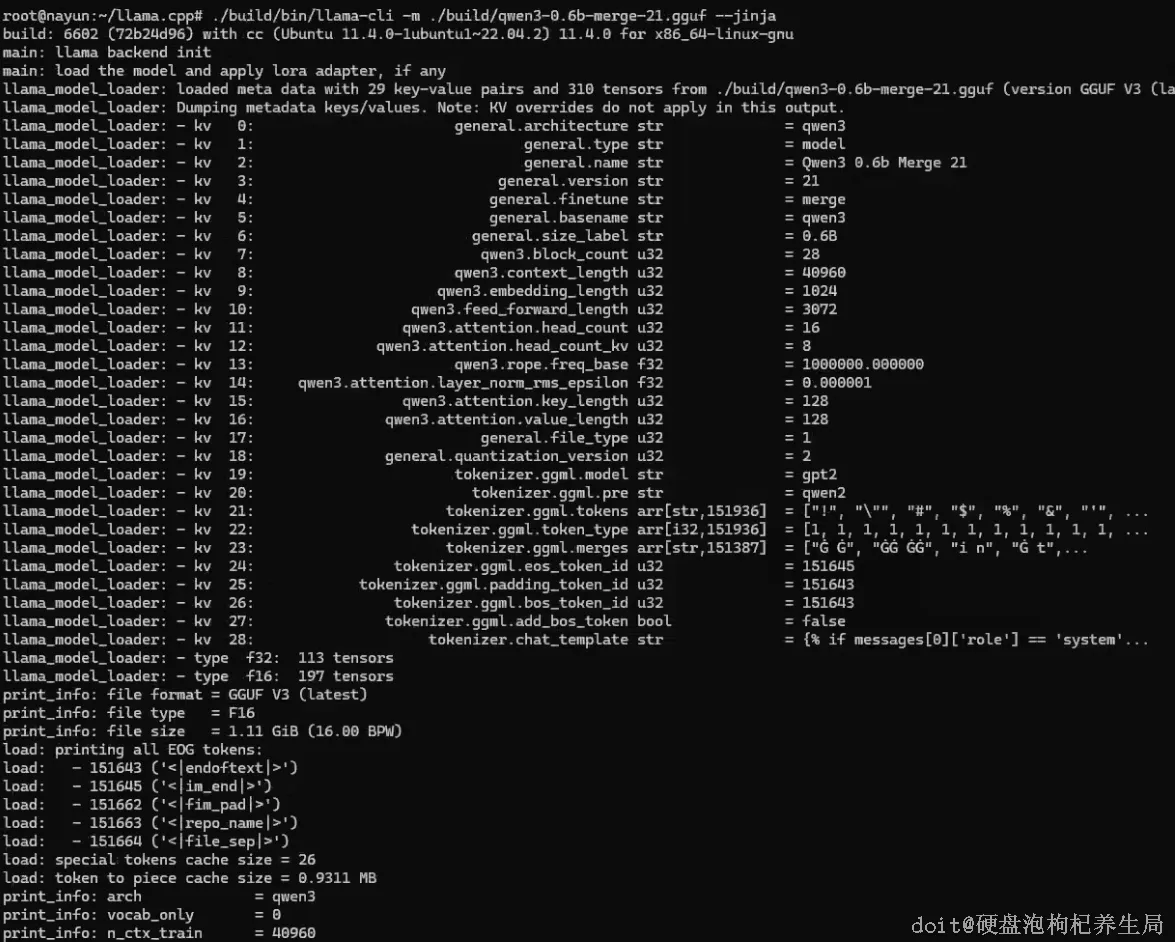
- ./build/bin/llama-cli 是 llama.cpp 编译生成的命令行工具,用于运行 GGUF 格式的模型。
- -m(或 --model)用于指定模型文件路径,例如 ./build/qwen3-0.6b-merge-21.gguf,必须是 GGUF 格式。
- --jinja 启用模型内置的 Jinja2 聊天模板,Qwen3 等现代模型必需此选项,否则会报错。
转载地址:
大模型qwen3使用llama.cpp转换为gguf格式-DOIT社区![]() https://www.doitwiki.com/article/details/180115206221824
https://www.doitwiki.com/article/details/180115206221824

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)