构建Flask与YOLOv5集成的目标检测后端接口
Flask是一个用Python编写的轻量级Web应用框架。它易于使用,灵活且功能强大,适合快速开发应用程序。YOLOv5是一个先进的目标检测模型,以其准确性和速度被广泛应用于计算机视觉任务中。本章的目标是将YOLOv5集成到Flask应用程序中,并使其能够通过Web接口接受图像上传并返回检测结果。安装和配置Flask环境。加载预训练的YOLOv5模型。设计Web接口接收图像上传。对上传的图像进行预

简介:本教程将指导如何结合Flask和YOLOv5来搭建一个图像目标检测后端服务。首先安装Flask和YOLOv5,然后配置YOLOv5模型,接下来创建一个Flask应用来处理图像上传并使用YOLOv5进行目标检测,最后将结果以JSON格式返回。这为实现图像识别后端接口提供了一个基本框架,并可进行进一步的功能扩展。 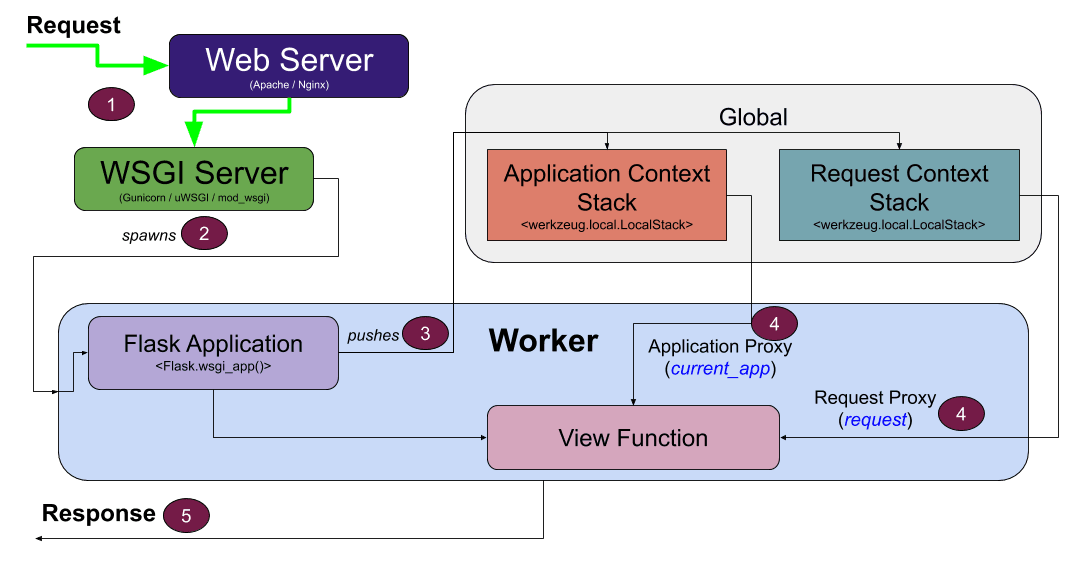
1. Flask与YOLOv5集成实现
引言
在这个章节中,我们将开始探索如何将深度学习的复杂性隐藏在后端服务的简洁性之下。通过集成流行的深度学习目标检测模型YOLOv5和灵活的Python Web框架Flask,我们可以创建一个能够识别上传图像中对象的Web应用程序。
Flask和YOLOv5简介
Flask是一个用Python编写的轻量级Web应用框架。它易于使用,灵活且功能强大,适合快速开发应用程序。YOLOv5是一个先进的目标检测模型,以其准确性和速度被广泛应用于计算机视觉任务中。本章的目标是将YOLOv5集成到Flask应用程序中,并使其能够通过Web接口接受图像上传并返回检测结果。
实现步骤概述
- 安装和配置Flask环境。
- 加载预训练的YOLOv5模型。
- 设计Web接口接收图像上传。
- 对上传的图像进行预处理。
- 使用YOLOv5模型执行目标检测。
- 将检测结果进行可视化并返回。
示例代码
以下是一个简单的Flask应用程序示例代码,展示了一个Web服务的基本框架,其中包括路由定义和视图函数的初步设置。
from flask import Flask, request, render_template, send_file
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html') # 假设我们有一个名为index.html的文件用于上传图片
@app.route('/upload', methods=['POST'])
def upload_image():
# 这里将包含处理上传的图片和调用YOLOv5模型的代码
pass
if __name__ == '__main__':
app.run(debug=True)
本章的目标是引导读者从零开始,搭建一个简单的深度学习服务。通过本章学习,读者将获得创建Web服务并集成YOLOv5模型的基础知识。在后续章节中,我们将深入探讨每一部分的具体实现,确保读者不仅能理解原理,还能在实践中应用所学。
2. Python Web应用程序开发
2.1 Web开发基础与Flask框架简介
Web开发通常围绕着客户端和服务端的交互来构建动态网站,涉及服务器、数据库和应用程序三个核心组件。对于Python开发者来说,Flask是一个轻量级的Web框架,它让开发者能够快速搭建起一个Web应用。Flask通过路由(Routing)和模板(Templates)等概念,为Web开发提供了一个简洁明了的环境。
2.1.1 Web开发核心概念
Web开发的核心在于理解HTTP协议的工作原理,即客户端如何与服务器进行通信,以及如何处理请求(Request)和响应(Response)的过程。此外,了解状态码(Status Codes)、会话管理(Session Management)和安全相关概念(如CSRF防护)也是基础中的基础。
2.1.2 Flask框架特点及安装
Flask框架的特点包括轻量级、易扩展和灵活。它有一个很大的社区和插件生态系统,开发者可以轻松地添加额外功能。使用pip安装Flask非常简单:
pip install Flask
安装完成后,开发者就可以通过创建一个简单的Web应用来开始他们的Flask之旅:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run(debug=True)
以上代码创建了一个基本的Flask Web应用,它会响应根路径的访问并返回”Hello, World!”。
2.2 Flask视图函数与请求处理
2.2.1 视图函数的定义和路由
在Flask中,视图函数(View Functions)是处理Web请求的主要手段,它们关联着一个或多个URL模式(Routes)。定义视图函数时,通常会使用@app.route装饰器来指定一个路径作为URL模式:
@app.route('/greet/<name>')
def greet(name):
return f'Hello, {name}!'
在上述代码中,当用户访问/greet/john时,服务器将返回字符串”Hello, john!”。
2.2.2 请求与响应对象的工作原理
当一个请求被发送到Flask应用时,Flask创建一个请求对象(request object),这个对象封装了客户端发送的所有信息。在视图函数内部,开发者可以使用这个对象来访问如查询参数、表单数据或JSON数据等信息:
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
username = request.form['username']
# ... 处理登录逻辑 ...
return '登录成功'
return '''
<form method="post">
<input type="text" name="username">
<input type="submit" value="登录">
</form>
'''
在这个登录示例中,根据HTTP请求方法的不同,执行不同的逻辑分支。
2.3 Flask模板与静态文件管理
2.3.1 模板引擎的使用和Jinja2语法
Flask使用Jinja2作为模板引擎来生成HTML页面。Jinja2语法允许在HTML中嵌入Python代码,同时提供了模板继承等高级功能来提高代码的复用性和可维护性。一个典型的Jinja2模板示例如下:
<!DOCTYPE html>
<html>
<head>
<title>{% block title %}My Page{% endblock %}</title>
</head>
<body>
{% block content %}
{% endblock %}
</body>
</html>
在这个模板中, {% block title %} 和 {% block content %} 表示着可以被继承模板填充的区域。
2.3.2 静态文件(CSS/JS)的部署和使用
静态文件(如CSS样式表和JavaScript文件)通常放在项目的static文件夹中。在HTML模板中,可以通过 {{ url_for('static', filename='style.css') }} 来引用这些文件,确保文件在生产环境中也能正确加载。
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
在开发过程中,静态文件被Flask自动管理,但在生产环境中,需要配置Web服务器(如Nginx)来优化静态文件的加载速度。
这为我们的第二章提供了概览,下一章我们将继续探讨如何使用Flask进行视图函数与请求处理,以及如何利用模板和静态文件来创建更加动态和完整的Web应用。
3. 目标检测模型应用
3.1 YOLOv5模型基础和架构
3.1.1 目标检测技术概述
目标检测是计算机视觉中的一项基础而重要的任务,其目的是在给定的图像或视频序列中识别和定位出物体。目标检测技术广泛应用于自动驾驶、视频监控、工业检测等多个领域。与传统的图像分类任务不同,目标检测不仅要识别出图像中的物体类别,还需要准确地定位出物体在图像中的位置。这通常通过为图像中的每个物体生成一个或多个边界框(bounding boxes)来实现。
目标检测模型的发展经历了从传统方法到深度学习方法的演变。传统的目标检测方法,如滑动窗口、基于选择性搜索的选择区域等,依赖手工设计特征,检测速度和准确性难以兼顾。随着卷积神经网络(CNN)的兴起,基于深度学习的目标检测方法,如R-CNN、Fast R-CNN、Faster R-CNN等,通过学习特征表示,大幅提升了检测性能。然而,这些方法仍然存在速度慢、难以实现实时检测等挑战。
YOLO(You Only Look Once)系列模型的出现,为实时目标检测领域带来了突破。YOLO将目标检测任务视为一个回归问题,将整个图像直接映射为边界框坐标和类别概率。YOLOv5作为该系列的最新成员,不仅速度快,而且准确率高,易于部署和使用,因此成为业界广泛采用的目标检测模型之一。
3.1.2 YOLOv5模型的特点和架构解析
YOLOv5在继承了YOLO系列速度快、准确率高等特点的基础上,进一步优化了模型的性能和易用性。YOLOv5的模型架构在保持轻量级的同时,通过一些关键的改进,如引入Focus模块、使用自适应锚框计算等技术,使得模型能够在不同的数据集和应用场景中,都能够有良好的表现。
YOLOv5模型主要由以下几个部分构成:
-
输入层 :采用Focus模块,将输入图像从416x416缩小为104x104x3的大小,这样做可以在不损失信息的前提下,提升计算速度。
-
Backbone(主干网络) :由一系列卷积层和残差块组成,用于提取特征。YOLOv5在Backbone中使用了深度可分离卷积,以减少模型的计算量和参数数量。
-
Neck(特征融合层) :在此阶段,通过多次上采样和卷积操作,将不同尺度的特征图进行融合,提升小物体的检测精度。
-
Head(输出层) :将融合后的特征图映射到最终的输出,包括边界框坐标、目标类别概率以及置信度。
YOLOv5的另一个关键改进是其锚框(anchor boxes)的自适应计算方法。锚框是指预先设定的一组不同大小和宽高比例的边界框,用于检测图像中的物体。传统的YOLO版本中,这些锚框是基于特定数据集进行统计得出的,而YOLOv5则通过聚类算法,根据训练数据自动学习锚框的大小和比例,这使得模型更加适应不同的应用场景和目标。
3.2 YOLOv5模型在Flask中的集成
3.2.1 模型加载和初始化
为了在Flask Web应用程序中集成YOLOv5模型,首先需要将预先训练好的模型加载到内存中。这里我们假设有一个训练好的 .pt 文件。加载模型通常涉及到使用YOLOv5官方提供的工具或者自己编写加载脚本。以下是使用Python进行模型加载和初始化的基本步骤:
import torch
from models.common import * # 导入模型中的常用组件
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='best.pt')
# 将模型移动到GPU上(如果可用)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
在上述代码中, torch.hub.load 方法用于从YOLOv5的仓库中加载指定版本的模型,并根据 path 参数加载我们自己的模型文件 best.pt 。通过设置 custom 参数,可以指定自定义模型的路径。此外,通过 device 变量来指定模型运行在CPU或GPU上。
3.2.2 图像预处理和模型推理过程
为了使模型正确处理图像数据,我们需要对输入的图像进行预处理。YOLOv5对图像大小有特定要求,例如,通常模型输入大小为640x640像素。因此,对上传的图像进行缩放是必要的,同时还需要对图像数据进行归一化处理。预处理后,我们可以使用模型进行推理并获取检测结果。
下面代码展示了如何对图像进行预处理,以及如何使用YOLOv5模型进行推理:
import torch
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='best.pt')
model.to(device)
model.eval() # 设置为评估模式
# 图像预处理函数
def preprocess_image(image_path):
img = torch.zeros((1, 3, 640, 640)) # 创建一个虚拟的图像张量
img = preprocess(img) # 使用模型自带的预处理函数
img = Image.open(image_path) # 打开实际图像
img = transforms.ToTensor()(img) # 将图像转换为张量
img = img.unsqueeze(0) # 增加批次维度
return img.to(device)
# 模型推理函数
def perform_inference(image_path):
img = preprocess_image(image_path)
with torch.no_grad():
results = model(img) # 进行推理
return results
# 模型预测
results = perform_inference('path/to/uploaded/image.jpg')
在代码中, preprocess_image 函数负责加载图像,调整大小,并将图像转换为模型所期望的格式。 perform_inference 函数则接收处理过的图像,调用模型进行推理,返回检测结果。这里的 results 包含了检测到的边界框、置信度和类别概率等信息。随后,可以将这些信息进行进一步处理,以便将结果返回给客户端。
至此,YOLOv5模型已成功集成到Flask Web应用程序中,能够接收上传的图像,并使用深度学习模型进行目标检测。通过这种方式,我们构建了一个实际可用的目标检测服务,进一步的开发可以扩展至实时视频流分析等高级应用。
4. 图像上传处理与结果返回
4.1 Flask文件上传处理机制
4.1.1 HTML文件上传表单创建
在Web应用中,用户上传文件是一个常见的需求。为了实现这一功能,首先需要创建一个HTML文件上传表单。这个表单需要设置正确的 enctype 属性,即 multipart/form-data ,这是因为只有这种类型才能处理文件数据。
<form method="post" action="/upload" enctype="multipart/form-data">
<input type="file" name="file">
<input type="submit" value="Upload">
</form>
在上述代码中, <input type="file"> 标签让用户可以选择要上传的文件。一旦用户选择了文件并提交表单,数据就会被发送到服务器上定义好的 /upload 路由。
4.1.2 Flask接收和保存上传文件
在Flask应用中,对于文件上传的接收和保存处理,需要在对应的路由视图函数中进行。在这个函数里,使用 request.files 可以访问到上传的文件对象。文件保存到服务器时,需要确保文件名是唯一的,避免覆盖已存在的文件。
from flask import request, flash, redirect, url_for, render_template
@app.route('/upload', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
# 获取上传的文件
uploaded_file = request.files['file']
# 检查文件是否存在
if uploaded_file.filename == '':
flash('No file part')
return redirect(request.url)
if uploaded_file:
# 保存文件
filename = secure_filename(uploaded_file.filename)
uploaded_file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
# 调用目标检测模型进行处理
# ...
return redirect(url_for('uploaded_file', filename=filename))
return render_template('upload.html')
上述代码片段展示了如何在Flask中接收并保存上传的文件。 secure_filename 函数用于确保文件名的安全性,而 os.path.join 用于创建一个安全的路径来保存文件。
4.2 图像处理与目标检测
4.2.1 图像数据的加载和预处理
一旦图像被上传并且保存到服务器上,下一步是加载图像数据并进行必要的预处理,以确保它能被YOLOv5模型所接受。预处理通常包括缩放到模型所需的尺寸、归一化等步骤。
import cv2
from PIL import Image
# 加载图像
image_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
image = cv2.imread(image_path)
# 调整图像大小
resized_image = cv2.resize(image, (640, 640)) # 根据模型要求调整尺寸
# 转换为RGB
image_rgb = cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB)
# PIL图像对象
image_pil = Image.fromarray(image_rgb)
在处理完图像之后,需要将它们转换成YOLOv5模型所需要的格式。这通常需要将图像转换成张量,并且可能需要添加一个批次维度。
4.2.2 调用YOLOv5模型进行目标检测
加载并预处理图像之后,接下来是使用YOLOv5模型进行目标检测。这包括加载模型权重,对图像进行推理,获取检测结果。
import torch
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# 推理
results = model(image_pil)
# 检测结果可视化
results.render() # 在内存中渲染检测结果
# 获取检测结果字典
results_dict = results.xyxy[0].tolist() # 使用xyxy表示法获取边界框坐标
模型通常返回一个包含多个检测结果的字典,每个结果都有相应的类别ID、置信度等信息。这些结果之后可以用于生成可视化的图像。
4.3 检测结果的可视化与返回
4.3.1 结果数据的格式化和处理
在得到检测结果后,需要将其转换成一个容易在前端显示的格式。这通常意味着将结果字典转换成JSON对象。
import json
# 结果转换为JSON格式
results_json = json.dumps(results_dict)
将检测结果转换为JSON格式后,它们就可以被发送到客户端,并在Web页面中以图表或列表的形式展示。
4.3.2 生成可视化图像并返回客户端
最后一步是将检测结果与原始图像结合起来,并以可视化图像的形式返回给客户端。这需要将结果绘制到图像上,然后将图像转换为适合网络传输的格式。
# 将结果渲染到图像上
final_image = results.render()[0] # 获取渲染后的图像
# 将PIL图像对象转换为BytesIO对象
from io import BytesIO
import torchvision.transforms as T
final_image_bytes = BytesIO()
final_image.save(final_image_bytes, format='JPEG')
final_image_bytes.seek(0)
# 将图像数据转换为base64编码
from base64 import b64encode
image_b64 = b64encode(final_image_bytes.read()).decode('utf-8')
# 返回结果
return render_template('result.html', image_b64=image_b64)
在上述代码中,使用 BytesIO 对象来处理二进制图像数据,然后将其编码为base64字符串。这样就可以将图像数据作为字符串嵌入到HTML中,并在网页上显示。
5. 后端接口功能扩展
5.1 接口认证与权限控制
在Web应用开发中,确保接口安全性是非常关键的一步。随着应用程序的不断增长,我们需要实现一个安全的认证机制来保护接口不被未授权的访问。
5.1.1 接口认证机制的原理和类型
接口认证机制的原理基于验证发起请求的用户身份,确保该用户有权限访问特定资源。实现这一机制通常有几种方法,包括但不限于:
- 基于令牌的认证 (Token-based Authentication):用户登录时通过验证后,服务端生成一个令牌(如JWT - JSON Web Tokens),客户端之后的每个请求都携带此令牌进行身份验证。
- 基本认证 (Basic Authentication):通常用于HTTP协议中,客户端通过在请求头中携带Base64编码的用户名和密码进行身份验证。
- 会话认证 (Session-based Authentication):服务端会为每个会话创建一个唯一的会话ID,存储在客户端(通常为cookie),服务端通过这个ID来识别用户。
5.1.2 Flask中实现基本的权限控制
在Flask中,我们可以通过装饰器模式来实现权限控制。下面是一个简单的例子,演示了如何使用Flask的装饰器来限制对特定路由的访问。
from flask import Flask, request, abort
from functools import wraps
def require_auth(f):
@wraps(f)
def decorated(*args, **kwargs):
auth = request.authorization
if not auth or not check_auth(auth.username, auth.password):
return 'Could not verify your access level for that URL.'
return f(*args, **kwargs)
return decorated
def check_auth(username, password):
return username == 'admin' and password == 'secret'
在这个例子中, require_auth 装饰器检查请求头中的认证信息。如果认证失败,它会返回一个错误消息。实际使用中, check_auth 函数应连接到用户数据库,以验证用户的登录凭证。
5.2 批量处理与异步任务
随着应用用户数量的增加,我们需要考虑优化后端处理以应对大规模的请求。在某些情况下,处理任务可以被批量化,或者使用异步处理来提升效率。
5.2.1 接口批量处理的需求与实现
批量处理是一种将多个请求合并为一个处理单元的方法。这在处理大量数据时尤其有用,可以显著减少数据库的交互次数。
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/process/batch', methods=['POST'])
def batch_process():
data = request.json
result = []
for item in data:
# 假设这是一个处理函数
processed_data = process_item(item)
result.append(processed_data)
return jsonify(result)
def process_item(item):
# 这里是对单个数据项的处理逻辑
pass
5.2.2 异步任务处理机制和Flask应用
异步任务处理意味着将任务放在后台执行,这样可以立即响应客户端请求,而不需要等待任务完成。Flask可以通过Celery等任务队列工具实现异步处理。
from flask import Flask
from celery import Celery
app = Flask(__name__)
app.config['CELERY_BROKER_URL'] = 'redis://localhost:6379/0'
app.config['CELERY_RESULT_BACKEND'] = 'redis://localhost:6379/0'
celery = Celery(app.name, broker=app.config['CELERY_BROKER_URL'])
celery.conf.update(app.config)
@celery.task
def async_task(data):
# 异步任务逻辑
pass
@app.route('/start/async/task', methods=['GET'])
def start_async_task():
task = async_task.delay(data)
return jsonify({'task_id': task.id})
在上面的例子中, async_task 函数被设计为一个异步任务,通过Celery的 delay 方法可以在后台异步执行。客户端请求后可以得到一个任务ID,随后可以使用这个ID来查询任务状态。
在这个章节中,我们详细探讨了如何在Flask应用程序中实现接口认证和权限控制,以及如何通过批量处理和异步任务提升处理性能。这些功能是任何成熟后端系统不可或缺的一部分,也是优化用户体验和保证系统安全性的关键步骤。随着应用的成长和需求的变化,这些功能的扩展对于保持系统的可扩展性和稳定性至关重要。
6. 错误处理与性能优化
6.1 Flask中的异常处理机制
在Web应用开发过程中,错误处理是不可忽视的一个环节。Flask通过内置的错误处理功能,为开发者提供了一种方便的方式来处理可能出现的异常情况。
6.1.1 常见异常的捕获和处理
在Flask中,可以通过 @app.errorhandler 装饰器为特定的HTTP状态码注册处理函数。例如,如果我们希望为404错误提供一个自定义的错误页面,可以这样做:
@app.errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
除了HTTP状态码,也可以捕获更广泛的异常类型。下面是一个处理任何类型异常的通用处理器:
@app.errorhandler(Exception)
def handle_exception(e):
# 在这里可以添加日志记录,例如使用日志模块记录错误详情
logging.error('An exception occurred: %s' % e)
# 可以返回一个自定义的错误页面,甚至使用模板渲染错误详情
return render_template('error.html', error=e), 500
6.1.2 日志记录和错误报告
为了进行有效的错误处理和调试,日志记录是至关重要的。Flask内置了日志记录功能,并且可以通过Python标准库的 logging 模块来扩展。下面是如何在Flask应用中设置日志的基本示例:
import logging
# 创建日志记录器,设置日志级别和日志格式
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
# 现在可以使用 logging 记录日志信息
logging.info('This is an informational message')
对于生产环境,建议使用更复杂的日志系统,如使用 logging.handlers 来配置文件日志记录,或者集成第三方日志管理服务,比如ELK Stack(Elasticsearch, Logstash, Kibana)。
6.2 性能优化策略
优化Web应用性能是确保用户获得良好体验的关键。性能优化可以从代码层面和应用部署层面进行。
6.2.1 代码层面的性能优化
代码层面的优化包括减少不必要的计算,使用高效的数据结构和算法,以及优化数据库查询。例如,对于大型数据集,应该使用分页技术来减少单次查询的数据量。
使用 Flask-Caching 扩展可以缓存请求结果,减少重复的计算:
from flask_caching import Cache
cache = Cache(config={'CACHE_TYPE': 'simple'})
@cache.cached(timeout=50)
def expensive_function():
# 这个函数进行了一些复杂的操作
return result
在该示例中, expensive_function 的结果会被缓存50秒,这可以显著提高性能,特别是在有大量重复请求时。
6.2.2 应用部署层面的性能提升
应用部署层面的性能优化通常包括使用负载均衡器、使用更高效的Web服务器以及应用代码的优化。
一个简单的部署优化示例是在Flask应用前使用Nginx作为反向代理。这样做的好处包括:
- 提供静态文件服务,减轻Flask应用的负担。
- 增加一层安全性,Nginx可以作为一个防护墙。
- 改善负载均衡和反向代理,如果流量增加,可以简单地添加更多的Flask工作进程。
下面是一个基本的Nginx配置文件示例,用于将请求转发到Flask应用:
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://localhost:5000; # Flask应用运行在5000端口
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
# 配置静态文件服务
location /static {
alias /path/to/application/static; # Flask的静态文件目录
}
}
在生产环境中,还可以考虑使用Gunicorn作为WSGI服务器,并配置多个工作进程和线程来提升性能。
gunicorn -w 4 -b :5000 myapp:app
在这里, -w 4 表示使用4个工作进程,这可以根据CPU核心数进行调整,通常以核心数的两倍作为工作进程数。
在第六章中,我们学习了如何在Flask应用中进行错误处理和性能优化。第七章将深入探讨如何将Flask应用部署到生产环境,并考虑持续集成/持续部署(CI/CD)的实现。
简介:本教程将指导如何结合Flask和YOLOv5来搭建一个图像目标检测后端服务。首先安装Flask和YOLOv5,然后配置YOLOv5模型,接下来创建一个Flask应用来处理图像上传并使用YOLOv5进行目标检测,最后将结果以JSON格式返回。这为实现图像识别后端接口提供了一个基本框架,并可进行进一步的功能扩展。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 23
23 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)