【保姆级实操】从0到1掌握CHARLS队列数据聚类分析,终于有人讲明白了!
聚类分析的目标是根据这些变量的取值,将数据划分为不同的类别,使得同一类别内的数据具有较高的相似性,而不同类别之间的数据具有较大的差异性。因此,本文将以CHARLS 2011~2015年的TyG作为暴露,心血管疾病作为结局,探究TyG与结局之间的关联。答:不同类型的数据才需要用到标准化 比如我选择了体重和身高作为聚类,这是两种变量,那我就需要进行标准化。关于平台提取数据的操作,各位可以看教学视频,这

近日,CHARLS整理分析平台正式上线了聚类分析,今天给大家详细说明一下如何进行聚类分析。
在开始研究前,我们需要重点明确什么是聚类变量:
-
聚类变量是指在聚类分析中用于对数据进行分类的特征或指标。这些变量可以是连续变量(如身高),也可以是分类变量(如性别)。
-
聚类分析的目标是根据这些变量的取值,将数据划分为不同的类别,使得同一类别内的数据具有较高的相似性,而不同类别之间的数据具有较大的差异性。
明确完聚类变量后,接下来按照操作流程进行即可。
一.CHARLS提取平台——提取数据
1.获取宽数据
关于平台提取数据的操作,各位可以看教学视频,这里就不细说了。正常提取指标数据即可
CHARLS数据库独有的2011和2015年两个波次的血检数据,很适合做聚类分析。
因此,本文将以CHARLS 2011~2015年的TyG作为暴露,心血管疾病作为结局,探究TyG与结局之间的关联。

2.进行纳排
这里纳排标准为 保证参与者均具有最关键的变量——完整的TyG数据。
大家实际研究时,请根据自己的研究思路进一步添加纳排标准
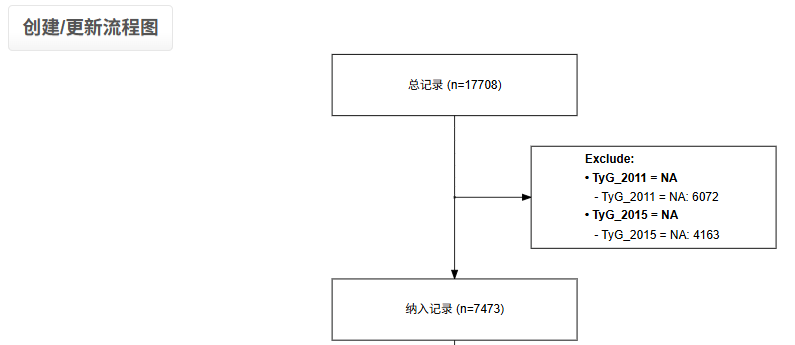
3.下载纳排后数据
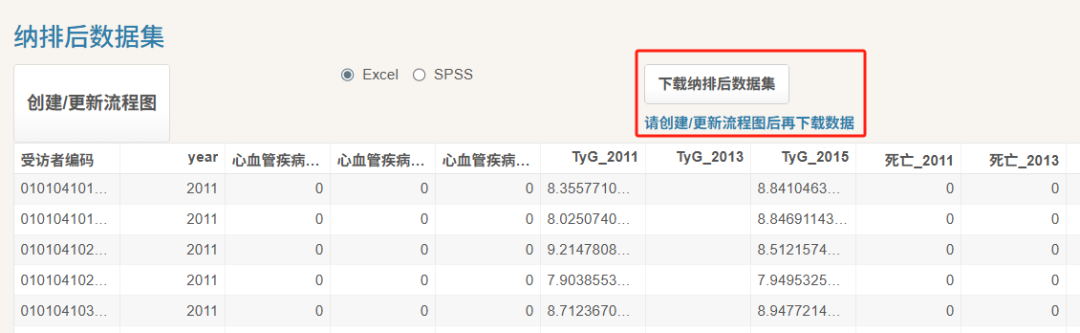
二、申请原始数据
[重点] 后续分析需要用到原始数据,所以请先申请原始数据,具体的申请标准群内都有说明哦~
请注意 申请格式须为宽数据!!!
三、聚类网页应用
1、打开网页
打开提供的聚类代码(和轨迹同一个代码),运行到最后一步 ,跳转到网页版的聚类分析

2、数据准备
导入原始的宽数据
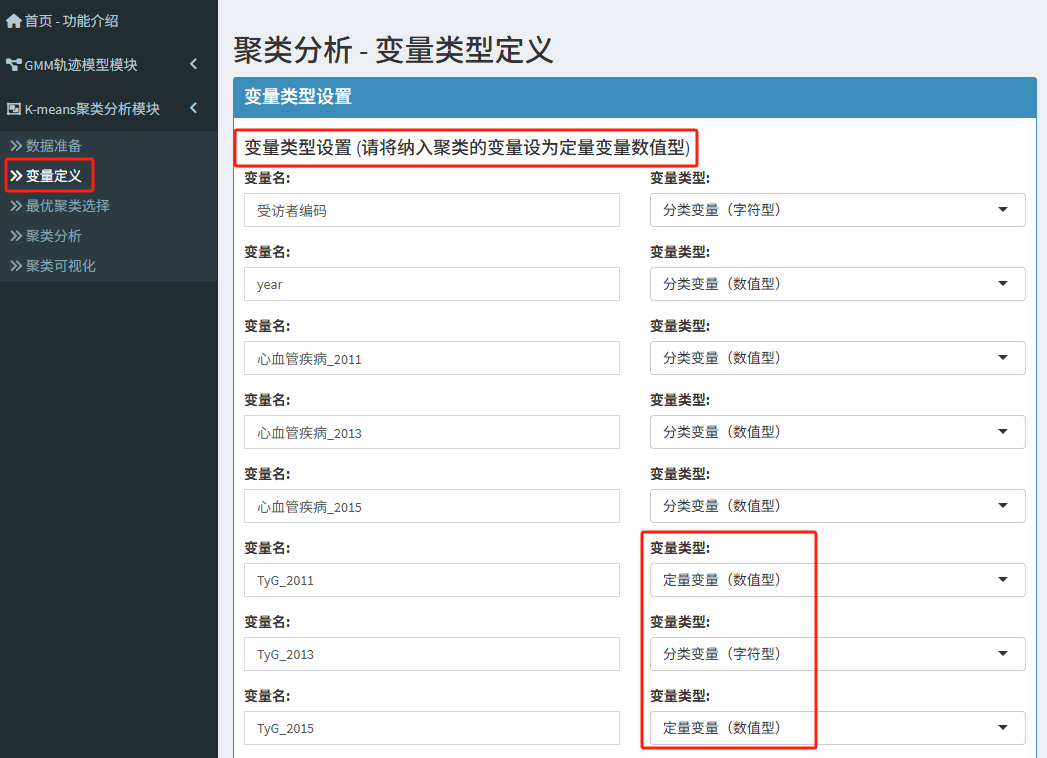
3.变量定义
需将纳入聚类的变量设为定量变量数值型
由于2013年没有TyG数据,这里的聚类变量就是TyG2011和TyG2015年。
ps:别管原数据多少,在聚类分析时我们只需要关注聚类变量即可。
4.最佳聚类选择
在该模块 我们最重要的目的是得出最佳聚类数!
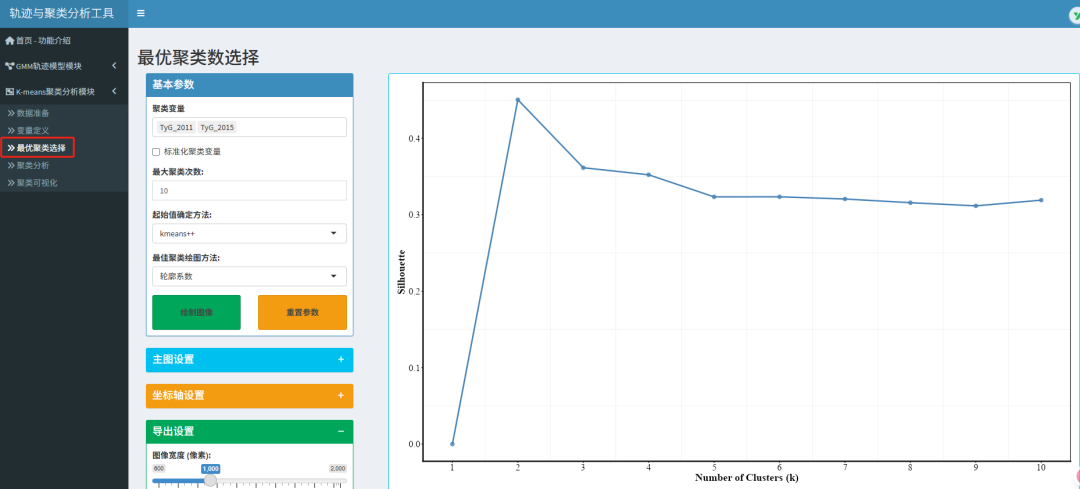
👀问题1.标准化聚类变量是否勾选?
答:不同类型的数据才需要用到标准化 比如我选择了体重和身高作为聚类,这是两种变量,那我就需要进行标准化。
但如果我选取的是体重的不同年份数据,那就不需要勾选。
以本文的TyG数据为例,则不需要勾选。
👀问题2.起始值确定方法如何选择?适用场景是什么?
1. k-means++(最常用、推荐)
绝大多数情况下的首选,尤其是k较大、数据分布不均匀时。
2. random(完全随机)
-
数据量极大,对速度极度敏感
-
数据分布非常均匀时可能还行
3. quantile_init(分位数初始化)
-
低维数据(d ≤ 3)
-
需要可重复的结果
-
数据大致呈均匀分布或已知分布
4. optimal_init(最优初始化)
-
对聚类质量要求极高
-
数据量不大,可承受更高计算成本
👀问题3.最佳聚类绘图方法如何选取?
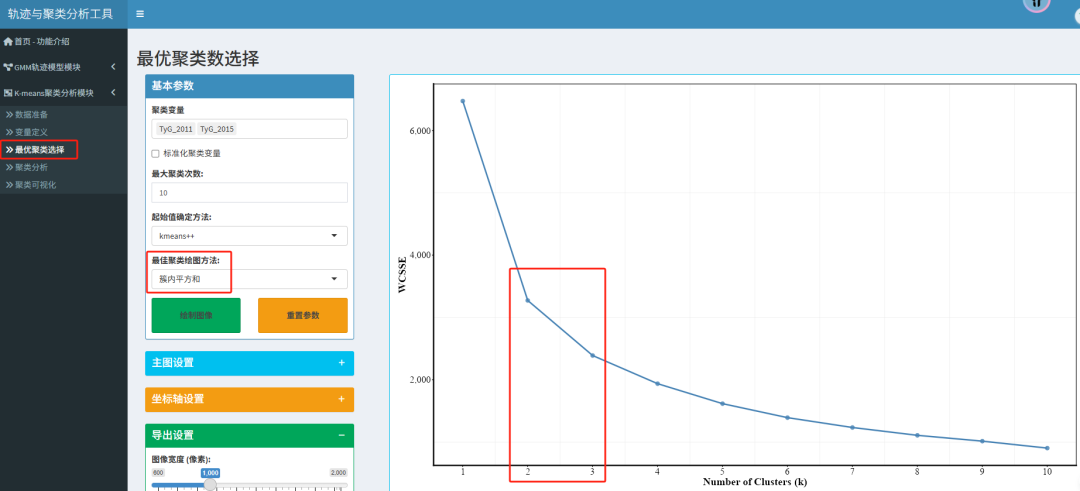
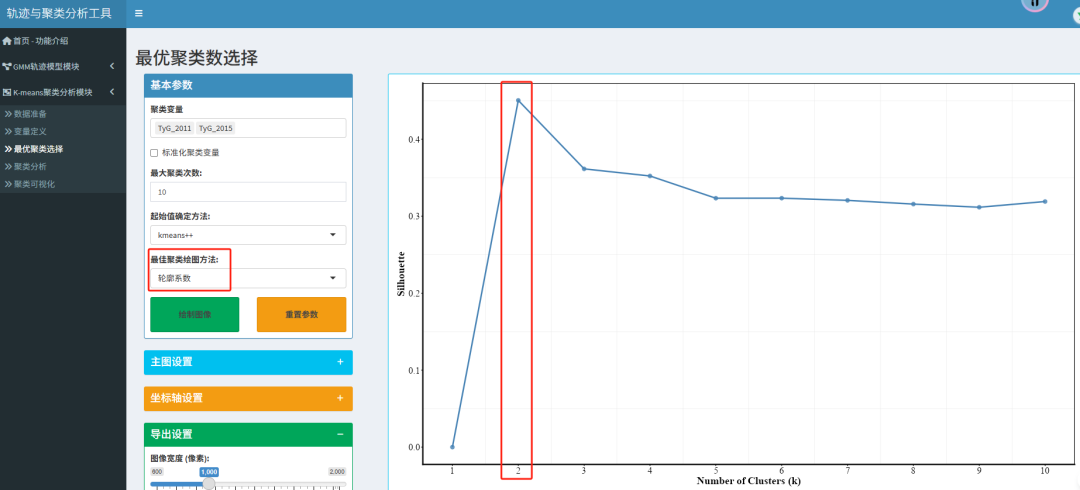
平台共提供5种绘图方法:簇内平方和、轮廓系数、AIC、BIC、调整R方
最佳聚类选择没有金标准,大家在判断时可以综合这几种方式选择。
建议至少结合簇内平方和+轮廓系数进行选择!
‼️究竟如何选择最佳聚类数?
选择最佳聚类数的 核心是 在模型的“复杂度”(聚类数K)和“拟合度/解释能力”之间找到最佳平衡点。这里对平台包含的常用方法进行解释:
1. 簇内平方和
原理:计算不同K值下的总簇内平方和。随着K增加,每个簇更小、更紧凑,SSE必然会下降。目标是找到SSE下降速度突然变缓的那个“拐点”,形如手肘。
选取原则:寻找曲线从“陡峭”变为“平缓”的转折点。该点对应的K值通常被认为是较好的选择。
2. 轮廓系数
原理:综合衡量一个样本与其所属簇的相似度(凝聚度a)和与其他最近簇的相似度(分离度b)。
选取原则:绘制不同K值对应的平均轮廓系数图,选择系数最大的K。
3. 信息准则:AIC 与 BIC
原理:在基于概率的聚类模型(如高斯混合模型GMM)中,它们衡量模型的似然拟合优度,同时对模型复杂度(参数数量,与K正相关)进行惩罚。
如果使用GMM,则计算AIC/BIC。
选取原则:拟合不同K值的模型,计算AIC和BIC,选择值最小的K。
在本文的最佳聚类选择中,簇内平方和提示2/3分类,轮廓系数法提示2更好。因此,综合选择2作为最佳聚类。
5.聚类分析⭐
-
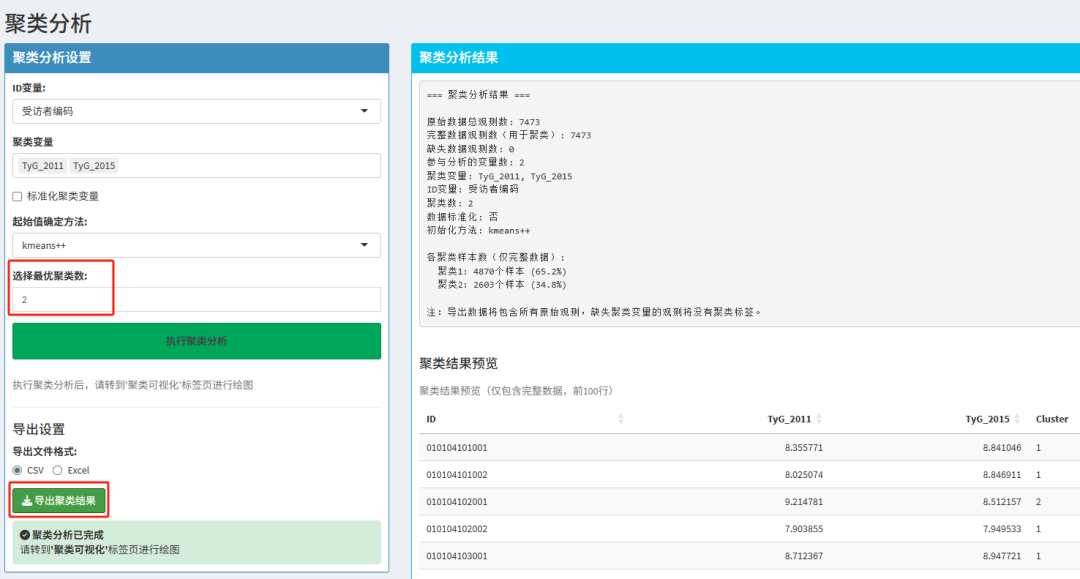
ID变量即为受访者编码
-
聚类变量、起始值确定方法与上一步中的最佳聚类选择保持一致。
-
更改最佳聚类数为刚刚确认的数值。
-
导出聚类结果:即可得到各ID的聚类分组——Cluster_Group。
6.聚类可视化⭐
为方便大家理解,我们以一篇一区Top文章(PMID: 40355933)中涉及的聚类结果图为例,进行讲解。
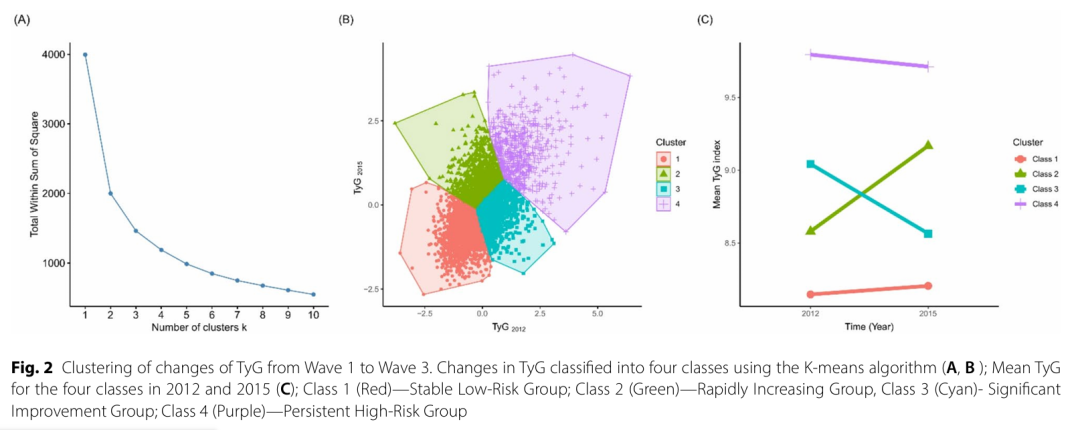
A为最佳聚类数选择结果图;B为散点图;C为均值折线图
平台包含的绘图类型共有三种:
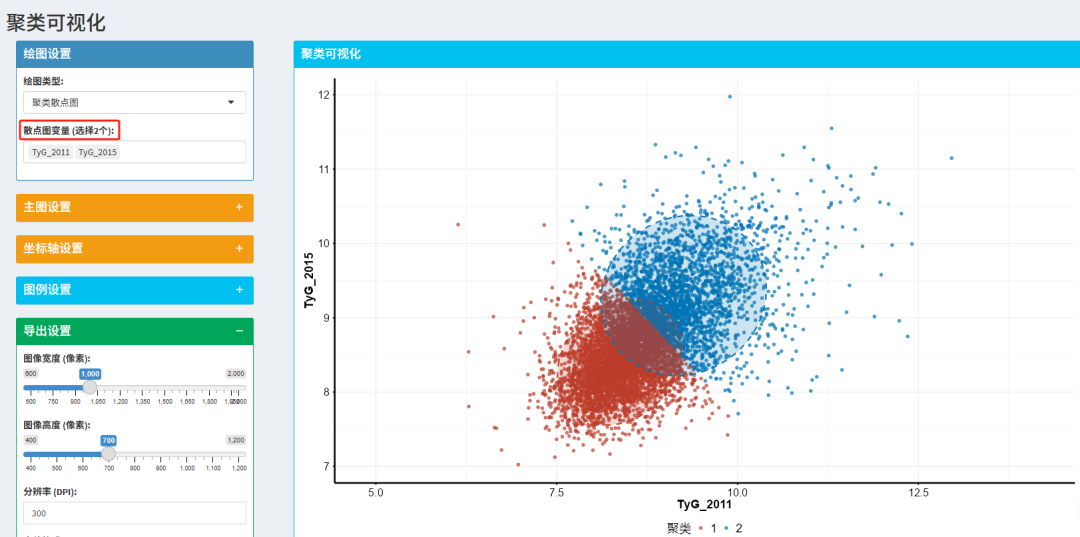
💠绘图类型1:散点图
需注意:散点图变量选择为两个!!!
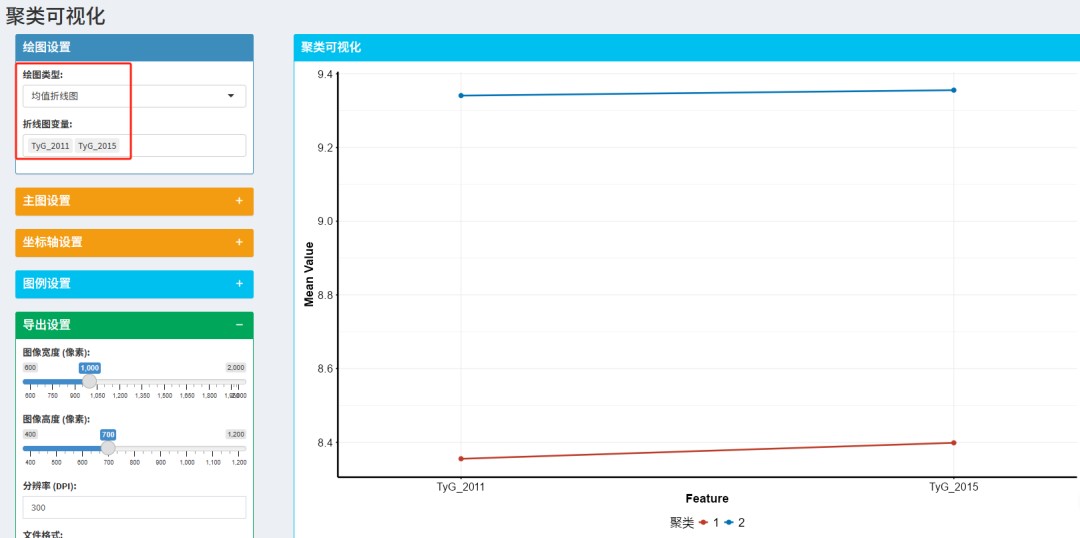
💠绘图类型2:均值折线图
ps:如果想要完全实现参考文献中 横坐标的TyG_2011改名为2011,只需在数据集中更改变量名即可实现。
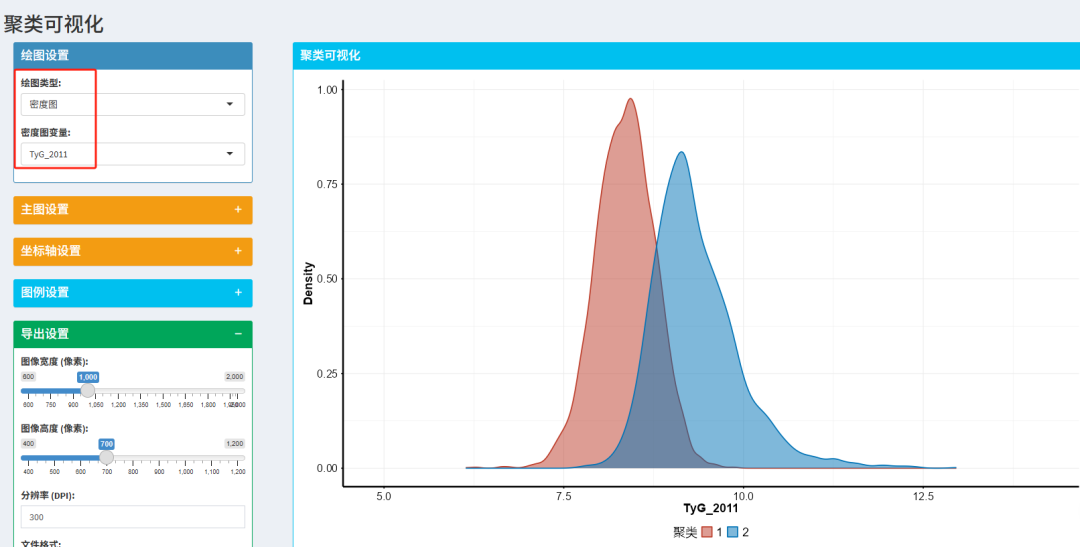
💠绘图类型3:密度图
可以查看单一数据的分布情况。
图表的各种设置,大家可以多多摸索一下,帮您做出更加精美的图形。
各种设置完成后,点击底部的“导出聚类图形”即可。
四、统计分析
将保存的宽数据在分析平台进行常规的统计分析即可。
1.导入刚刚在聚类分析步骤导出的聚类结果(此为原始宽数据 无需在平台解码)
2.统计分析
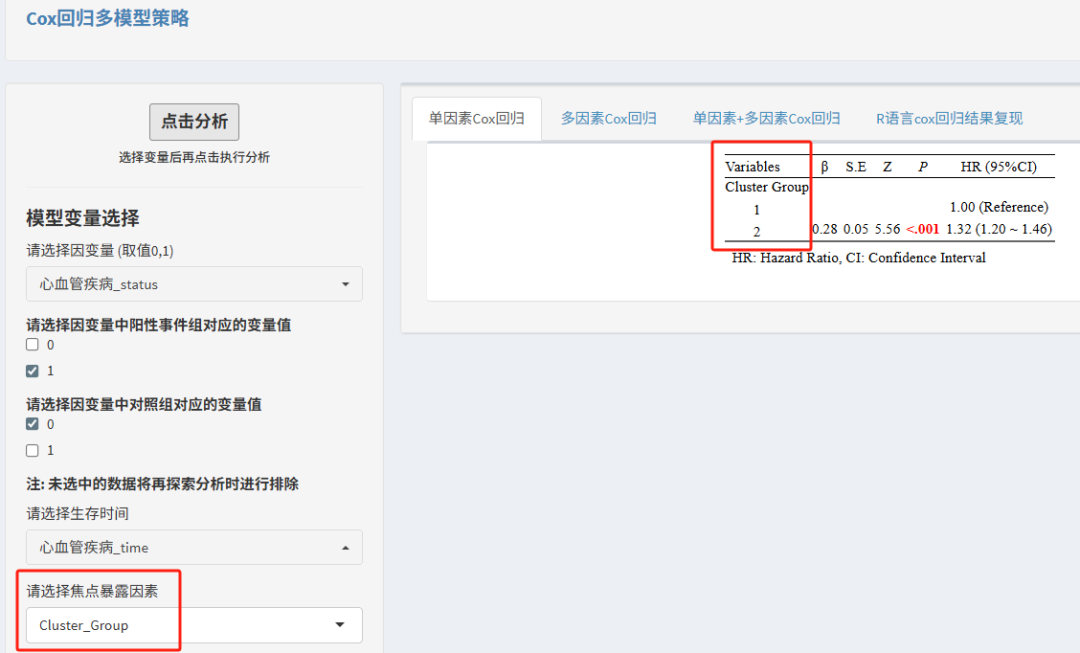
以cox回归为例,将暴露因素选为Cluster_Group,即可探究不同聚类与结局之间的关联。
其余回归分析原理相同。
以上就是对于CHARLS平台进行聚类分析的使用教程。感兴趣的朋友欢迎联系我们~
[注] 我们的CHARLS平台持续更新中,不断丰富指标与功能!有需求的朋友欢迎向我们提供建议,争取为你打造最全面且权威的一站式科研分析平台。

费用与服务
费用:
CHARLS整理分析平台:2000元/年
(有购买郑老师其他课程的学员享9折优惠)
相关服务:
✅买1年送1年,共2年的平台使用权限
✅平台后期会更新CHARLS综合性指标数据
✅提供1年期在线数据分析咨询

购买方式
-
可以添加下方助教微信咨询详情,或搜索微信号:aq566665。
-
可开技术服务费、培训费、咨询费等发票;可出具课程学习通知方便报销,可以对公转账。

助教二维码,联系咨询
✅平台后期会更新CHARLS综合性指标数据
✅提供1年期在线数据分析咨询
可以添加下方助教微信咨询详情,或搜索微信号:aq566665。
可开技术服务费、培训费、咨询费等发票;可出具课程学习通知方便报销,可以对公转账。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 19
19 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)