RLinf强化学习框架深入探索
原文发表在知乎,辛苦移步~《最近深入的研究了一下RLinf框架的原理,也深入了阅读了一些核心的代码,整理一些收获,记录如下。在此之前,关于RLinf框架一些的宏观的信息可参阅笔者的上一篇文章《RLinf强化学习框架试用》。RLinf支持的模型,算法,仿真环境比较多,笔者深入的研究的案例是:pi0.5模型+ppo算法+libero_10仿真,配置文件是:libero_10_ppo_openpi_pi
原文发表在知乎,辛苦移步~《RLinf强化学习框架深入探索》
最近深入的研究了一下RLinf框架的原理,也深入了阅读了一些核心的代码,整理一些收获,记录如下。在此之前,关于RLinf框架一些的宏观的信息可参阅笔者的上一篇文章《RLinf强化学习框架试用》。
RLinf支持的模型,算法,仿真环境比较多,笔者深入的研究的案例是:pi0.5模型+ppo算法+libero_10仿真,配置文件是:libero_10_ppo_openpi_pi05.yaml,官方文档:链接。笔者修改的配置项参考本文附录。
代码debug
笔者在研究这个框架遇到的最大的问题可能就是代码的debug了,我们用pycharm或vscode对python代码进行step by step的debug,可以很大的提升代码阅读的效率。但RLinf是基于ray的一个分布式框架,在代码debug上不是很方便,在主进程上可以比较方便的attach上去进行debug,但对于分布式环境下的其它进程,无法有效的进行debug。
官方工具
好在ray官方提供了一些debug工具,可查看文档。简单说就是在代码中加上breakpoint(),当代码运行到此位置后会中断并输出下面的内容。
(EmbodiedFSDPActor pid=139216) Ray debugger is listening on 192.168.1.54:37503
(EmbodiedFSDPActor pid=139216) Waiting for debugger to attach (see https://docs.ray.io/en/latest/ray-observability/ray-distributed-debugger.html)…
然后可以用vscode连接上去进行debug。官方这个debug工具简单的查看函数中的变量值,step by step的debug等基本功能是没有问题的,但问题是它需要人工指定代码在哪里,不会自动加载代码,并且当代码运行到第三方库时(例如openpi库中,想看看pi0.5的加载过程),也无法进去debug。所以整体上官方这个工具可以满足大部分需求,但也存在一些明显的问题。
其它方法
笔者在这里就直接对分布式的代码进行一些简单的修改,让其运行的主进程中,这样就可以用大家喜欢的debug工具例如pycharm进行debug。因为全量的代码肯定是需要分布式环境的,如果把它改成非分布式的,很多代码就走不到了。所以这种修改只能达到调试一些初始化阶段的代码的目标,例如训练worker或rollout worker中对模型的加载,仿真环境的初始化与交互等代码。目前来看,这种方式会比较高效,大约能调试60%左右的代码。大家可以结合上面这两种方法来使用。当然各位若有更好的debug方法,请在评论区不吝赐教!
我们知道,RLinfo框架中核心的三个模块:rollout,env,actor,这三部分可以分开进行修改代码进行debug。为了不占用正文的篇幅,笔者将修改的代码记录放在附录中,请自行参考。
env模块详解
架构
env模块负责仿真环境,策略与仿真环境进行交互,生产出训练所需要的数据或者对策略的效果进行评测。env中的各资源模块关系如下图: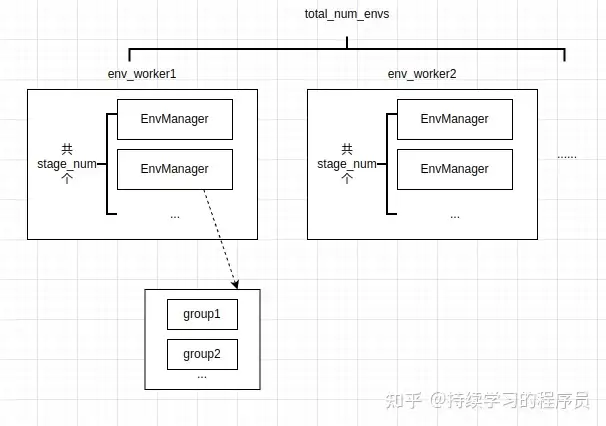
如上图所示,笔者直接举个具体的例子会更清晰一些。例如配置文件中共配置total_num_envs=64个并行的仿真环境,共配置了2个env_worker(可以理解为2个物理节点, ray中的2个节点),stage_num=2(用于rollout与env之间的pipeline并发),所以每个EnvManager管理了16个仿真环境,若group_size=8的话,这16个仿真环境又会分成16/8=2组,每组的8个仿真环境在仿真的时候会运行相同的任务,例如把抽屉打开,不同组运行的任务是随机的。
从上面可以看出,仿真环境物理上运行在一起的单元是EnvManager,虽然里面的仿真环境可能运行的任务是不同的(根据几个group来确定),但这一组仿真环境会同时进行一个step。EnvManager对不同仿真环境抽象出来的类,对外充当统一的接口。对于不同的仿真环境,例如libero, maniskill等,由各自不同的类进行管理,例如libero对应libero_env.py。
各种概念与关系
- Task (任务)
含义:LIBERO 中的一个具体任务,例如“把杯子放到桌子上”。
获取方式:self.task_suite.get_task(task_id),每个任务有唯一的 task_id。
2. Trial (试验/初始状态)
含义:某个任务下的一个具体初始状态(init state)。一个任务可以有多个 trial,每个 trial 表示不同的初始条件(物体位置、手臂姿态等)。
获取方式:self.task_suite.get_task_init_states(task_id) 返回该任务的所有初始状态列表。
3. reset_state_id (重置状态ID)
含义:全局唯一索引,用于标识所有“任务-初始状态”组合。
计算方式:
例如:3个task,分别有5、8、4个trial
reset_state_id 范围:0-16(共17个)
Task 0: reset_state_id 0-4
Task 1: reset_state_id 5-12
Task 2: reset_state_id 13-16
作用:作为全局索引,用于采样和分配重置状态。例如,针对task1的第一个初始状态,它的state_id=5,通过这个state_id=5可以反解析出task_id和trial_id这两个id。
4. task_ids 和 trial_ids
task_ids:长度为 num_envs 的数组,每个元素是该环境当前对应的 task_id。
trial_ids:长度为 num_envs 的数组,每个元素是该环境在当前任务下的局部 trial_id(从 0 开始)。
关系:可以从 reset_state_id 反推出对应的 task_id 和 trial_id(见 _get_task_and_trial_ids_from_reset_state_ids)。
5. Group (组)
含义:将并行环境分组的概念。
相关变量:
group_size:每组包含的环境数量
num_group = num_envs // group_size:组数
用途:同一组内的多个环境共享相同的 reset_state_id,实现任务多样化。
┌─────────────────────────────────────────────────────┐
│ LIBERO Task Suite (Benchmark) │
├─────────────────────────────────────────────────────┤
│ Task 0: “把杯子放到桌子上” │
│ ├─ Trial 0 (初始状态0) │
│ ├─ Trial 1 (初始状态1) │
│ └─ Trial 2 (初始状态2) │
│ │
│ Task 1: “打开抽屉” │
│ ├─ Trial 0 (初始状态0) │
│ └─ Trial 1 (初始状态1) │
└─────────────────────────────────────────────────────┘
↓
转换为全局 reset_state_id
↓
reset_state_id 0 → (task_id=0, trial_id=0)
reset_state_id 1 → (task_id=0, trial_id=1)
reset_state_id 2 → (task_id=0, trial_id=2)
reset_state_id 3 → (task_id=1, trial_id=0)
reset_state_id 4 → (task_id=1, trial_id=1)
↓
分配给不同的环境实例
↓
env 0: reset_state_id=0 → task_ids[0]=0, trial_ids[0]=0
env 1: reset_state_id=1 → task_ids[1]=0, trial_ids[1]=1
…
env中auto_reset的作用机制
因为仿真是多任务一起并行仿真的,所以就存在某些任务已经结束,某些任务仍然还在运行的情况,auto_reset=True 时,任务完成后会自动切换成新的任务。例如针对配置:max_episode_steps=480,也就是一个episode最多允许运行480个step。针对上文中所说的EnvManager中并行的16个仿真任务来说,若其中有6个仿真任务在step=100的时候success完成了,若auto_reset=True时,这6个仿真任务会自动开始一个新的任务,剩下的10个任务仍然继续。若auto_reset=False,那么这6个仿真任务相当于一直停留在success的状态,直到完成480个step。
在libero_10_ppo_openpi_pi05.yaml配置中,在train的时候,auto_reset=False,在eval的时候,auto_reset=True,那么若打开此配置的话,在后续统计任务成功率的时候会有什么样的逻辑处理呢?
主要分为两个阶段:
阶段1:环境层(libero_env.py)- 保存 episode 结束时的指标
在 _handle_auto_reset() 函数中(448-466行):
def _handle_auto_reset(self, dones, _final_obs, infos):
final_obs = copy.deepcopy(_final_obs)
env_idx = np.arange(0, self.num_envs)[dones]
# ⭐ 关键:在重置前,保存当前 episode 的完整信息
final_info = copy.deepcopy(infos) # 包含 success_once、return 等指标
if self.cfg.is_eval:
self.update_reset_state_ids() # 可能切换任务
# 重置环境(可能切换到新任务)
obs, infos = self.reset(...)
# ⭐ 将重置前的指标保存到新 infos 中,供下游使用
infos["final_observation"] = final_obs
infos["final_info"] = final_info # 保存重置前的指标
infos["_final_info"] = dones # 标记哪些环境完成了 episode
return obs, infos
阶段2:Worker 层(env_worker.py)- 提取已完成 episode 的指标
在 env_interact_step() 函数中(161-165行):
elif chunk_dones.any(): # 当 auto_reset=True 且有环境完成时
if “final_info” in infos:
final_info = infos[“final_info”]
for key in final_info[“episode”]:
# ⭐ 只提取完成 episode 的环境的指标(通过 chunk_dones[:, -1] 筛选)
env_info[key] = final_info[“episode”][key][chunk_dones[:, -1]].cpu()
下游统计模块(Logger/Metric Collector)的工作:
-
下游的统计模块在每次调用 env.step() 后,会检查返回的 infos 字典。
-
它会遍历每个并行环境的 info (for info in infos)。
-
它检查 if “final_info” in info:。
-
如果这个键存在,说明这个环境刚刚结束了一个回合。它就会从
info['final_info']中提取统计数据,而不是从外层的 info 中提取。
rollout/actor模块中关于模型(pi0.5)相关内容
关于pi0.5模型的相关信息大家可以阅读笔者的专栏《π (pi)系列模型与算法》,在本章节中重点讲一些pi0.5与ppo算法协作的部分。
value head
在ppo算法中,有一个value函数用于评估每个状态下的value值,此value值代表此状态开始到任务结束时,总体的期望收益。在本案例中,作者在pi0.5的VLM上添加了一个head,用于输出这个值。这种作法也是一种比较主流的方法。
head结构:
ValueHead(
(mlp): Sequential(
(0): Linear(in_features=2048, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=128, bias=True)
(5): ReLU()
(6): Linear(in_features=128, out_features=1, bias=True)
)
输入/输出/算法:
支持三种计算value的方法:mean_token/last_token/first_token,假如VLM最后一层输出的hidden state的size是(2, 712, 2048),batch size=2,256*2(img) + 200(lang)=712个token,mean就是712个token先求个平均,last/first就是取最后一个/第一个token的值。然后把token值作为上面段落中所介绍的head的输入,就可以得到一个value值。
#prefix_out_value.shape
#Out[5]: torch.Size([2, 2048])
values_vlm = self.value_head(prefix_out_value)[:, 0]
#values_vlm.shape
#Out[6]: torch.Size([2])
动作采样
在rollout模块中,需要根据当前仿真的状态,运行pi0.5的infer流程,输出一个动作,然后下发给仿真环境,仿真环境运行此动作后,会产生一个新的状态。其中pi0.5 infer出一个动作的过程,就叫动作采样。动作采样中包含了一个“采样”的字眼,说明它跟实际模型部署时infer过程是稍微有些不一样的。在动作采样时,生成的动作有一定的随机性在里面,这个随机性是强化学习与环境探索的过程所需求的。采样后输出动作的同时,也会有动作的概率,这个概率在ppo算法中会需要。
我们知道,在pi0.5模型中,动作的输出是多步去噪的过程。配置文件中默认去噪的步骤是5步,因为动作采样需要有随机性,默认情况下,每个去噪步都可以引入随机性,但这样计算代价过高,所以跟正常情况下训练pi0的方法一样,只随机抽取一个去噪步,在这个去噪步中加入随机性,抽取的去噪步如下:
batch size=2,5就去噪的步数,5个0就代表此次抽中了第一步,若所有步都被抽中的话,就是[0,1,2,3,4]
denoise_inds
tensor([[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]])
denoise_inds.shape
torch.Size([2, 5])
去噪过程核心的代码如下,可以看到跟《π RL(piRL)算法支持用强化学习方法训练π 0/π 0.5(pi0/pi0.5)》中分析的过程是一样的。另外,chains/log_probs/denoise_inds保存下来,后面训练过程中PPO算法需要,关于chains/denoise_inds在链接的文章中也有讲解。chains中保存了每个去噪步的输入x_t,为啥第二个维度是6呢,因为5个去噪步+一个最开始的输入,共6维。log_probs的最后一维是7,是去掉了32个维度中一些为零的维度,因为此实验环境(libero)中动作的维度是7。
for idx in range(num_steps):
x_t_mean, x_t_std, value_t = self.sample_mean_var_val(…) # 获取采样的均值与方差,使用了flow_sde算法
x_t = x_t_mean + self.sample_noise(x_t.shape, device) * x_t_std # 采样动作
log_prob = self.get_logprob_norm(x_t, x_t_mean, x_t_std) # 计算动作概率,没有被抽中的步中log_prob都是0
chains.append(x_t)
log_probs.append(log_prob)
…
return {
“actions”: x_0, # x_0.shape : torch.Size([2, 10, 32])
“chains”: chains, # chains.shape: torch.Size([2, 6, 10, 32])
“prev_logprobs”: log_probs, # log_probs.shape: torch.Size([2, 10, 7])
“prev_values”: values,
“denoise_inds”: denoise_inds,
}
reward/advantage/logprob的计算粒度
我们知道,在VLA模型的输出格式上,动作可以是单个动作(例如openvla模型),或者是多个动作(例如10)组成一个chunk。像pi0/pi0.5这种模型,它输出的动作就是一个chunk。目前主流的都是chunk模式。在这里,常规的强化学习算法中的action就升华成了actions(即chunk)。那么ppo强化学习算法里面对应的reward/advantage/logprob等数据的计算粒度是chunk级的呢?还是action级的?
直接说答案,粒度是chunk_level。有两个相关配置:reward_type: chunk_level, logprob_type: chunk_level。代码细节如下:
1,reward的聚合
因为最终与仿真环境交互的是chunk内的每个action,所以每个action会得到一个reward。每个chunk的所有action rewards被求和,得到chunk级别的总reward。后续advantage基于chunk级别reward计算
if kwargs[“reward_type”] == “chunk_level”:
# 原始形状: [n_chunk_steps, bsz, num_action_chunks]
rewards = rewards.sum(dim=-1, keepdim=True) # -> [n_chunk_steps, bsz, 1]
# 将每个chunk内所有action的rewards求和
2,chunk的概率处理
上文中讲到过,对于某一个chunk输出的概率格式:log_probs.shape: torch.Size([2, 10, 7]),其中batch size=2,10就是chunk内的action数量,7就是action的维度。在对此概率进行后处理时,代码如下,整体的效果就是一个chunk最终聚合成一个概率值。跟上面的优势的粒度是一样的。因为概率按数学意义应该是相乘的,但这里因为是概率的log值,所以相加就可以,因为log(a)+log(b)=log(a*b)。
elif logprob_type == “chunk_level”:
# 原始形状: [bsz, num_action_chunks, action_dim]
logprobs = logprobs.reshape(bsz, -1, single_action_dim).sum(dim=[1, 2]) # -> [bsz]
# 对所有chunks和所有action tokens的logprobs求和
模型加载过程中内存/显存的变化
本节与ppo算法无关,因为RLinf框架比较占用资源,所以笔者很好奇模型加载过程到底占用了多少资源。在模型的加载过程中,用top和nvidia-smi命令看了下资源的占用变化如下: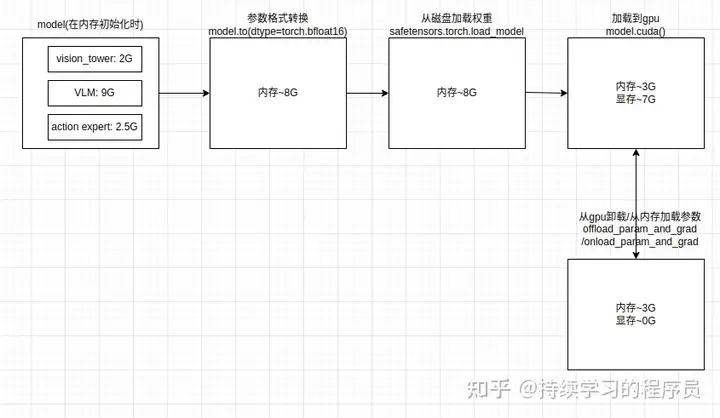
在pi0.5的对象在内存中完成初始化后,相关weight的内存已经分配完成,weight的数值是用均值为零,方差很小的正态分布进行初始化。数据格式是fp32。
将weight转为fp16后,内存使用下降较多。
此时weight仍然是随机的,需要从磁盘中加载训练好的模型。
模型从磁盘加载后,需要从内存中移动到gpu中。所以显存从0升到7G,内存下降较多。
为了节省相关资源,RLinf框架提供了一些资源onload/offload的功能。例如可以从显存中把rollout中模型卸载到内存中去,然后可以把显存腾出来用于模型训练。在这个过程中显存确实有明显变化,但内存不怎么变,估计是有缓存了吧。
笔者最开始的初衷是将模型加载的过程进行优化,以达到可以在本地3090上运行目标。后来在研究过程中发现,除了模型占用的资源外,仿真环境也占用不少资源,还有ray分布式环境本身也占用大量的资源,后面两者的资源占用不亚于模型的占用。所以要想达到本地运行RLinfo的目的,需要深入研究且优化的东西还不少。
附录:
代码debug
(rollout/actor)pi0.5模型加载部分代码:
+++ b/examples/embodiment/train_embodied_agent.py
def main(cfg) -> None:
-
model = get_model(cfg.actor.checkpoint_load_path, cfg.actor.model)
-
policy = FSDPStrategy(cfg.actor.fsdp_config, world_size=1)
-
policy.offload_param_and_grad(model, offload_grad=True)
-
policy.onload_param_and_grad(model, torch.cuda.current_device(), True)
cfg = validate_cfg(cfg)
print(json.dumps(OmegaConf.to_container(cfg, resolve=True), indent=2))
(env)仿真初始化与交互的代码:
其中有一段保存仿真observation等信息的一段代码,用于后续rollout采样动作时debug使用。这个信息包含的内容如下图:
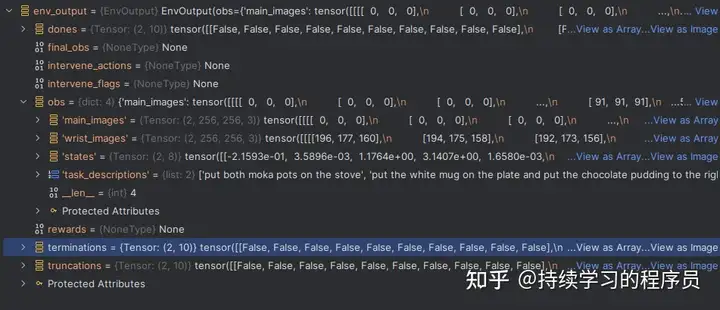
— a/examples/embodiment/train_embodied_agent.py
+++ b/examples/embodiment/train_embodied_agent.py
cfg = validate_cfg(cfg)
- env = EnvWorker(cfg)
- env.init_worker()
- env.interact()
— a/rlinf/envs/env_manager.py
+++ b/rlinf/envs/env_manager.py
-
worker_info: WorkerInfo,
-
#worker_info: WorkerInfo,
-
self.worker_info = worker_info
-
#self.worker_info = worker_info
-
self.cfg, num_envs, seed_offset, total_num_processes, worker_info
-
self.cfg, num_envs, seed_offset, total_num_processes,
— a/rlinf/envs/libero/libero_env.py
+++ b/rlinf/envs/libero/libero_env.py
class LiberoEnv(gym.Env):
- def init(self, cfg, num_envs, seed_offset, total_num_processes, worker_info):
- def init(self, cfg, num_envs, seed_offset, total_num_processes):
self.seed_offset = seed_offset
-
self.worker_info = worker_info
-
#self.worker_info = worker_info
— a/rlinf/workers/env/env_worker.py
+++ b/rlinf/workers/env/env_worker.py
-class EnvWorker(Worker):
+class EnvWorker():
def init(self, cfg: DictConfig):
-
Worker.__init__(self)
-
#Worker.__init__(self) # Env configurations -
self._world_size = 1 -
self._rank = 0
-
self.broadcast(True, list(range(self._world_size)))
-
#self.broadcast(True, list(range(self._world_size)))
-
worker_info=self.worker_info,
-
#worker_info=self.worker_info,
- def interact(self, input_channel: Channel, output_channel: Channel):
-
def interact(self):
-
with open("/workspace/RLinf/envoutput_object.pkl", "wb") as f: -
pickle.dump(env_output, f) #保存对象一次即可,在rollout模块调试时可使用 env_output_list.append(env_output)
-
self.send_env_batch(output_channel, env_output.to_dict())
-
#self.send_env_batch(output_channel, env_output.to_dict())
-
raw_chunk_actions = self.recv_chunk_actions(input_channel)
-
#raw_chunk_actions = self.recv_chunk_actions(input_channel) -
raw_chunk_actions = torch.normal( -
mean=0.0, -
std=1.0, -
size=(2, 10,7), -
dtype=torch.float32, -
device='cuda', -
)
-
self.send_env_batch(output_channel, env_output.to_dict())
-
#self.send_env_batch(output_channel, env_output.to_dict())
(rollout) 动作采样的代码:
— a/examples/embodiment/train_embodied_agent.py
+++ b/examples/embodiment/train_embodied_agent.py
def main(cfg) -> None:
cfg = validate_cfg(cfg)
- rollout = MultiStepRolloutWorker(cfg)
- rollout.init_worker()
- rollout.generate()
— a/rlinf/workers/rollout/hf/huggingface_worker.py
+++ b/rlinf/workers/rollout/hf/huggingface_worker.py
+import pickle
-class MultiStepRolloutWorker(Worker):
+class MultiStepRolloutWorker():
def init(self, cfg: DictConfig):
-
Worker.__init__(self)
-
#Worker.__init__(self)
-
self.actor_weight_src_rank = self._rank % actor_world_size
-
self.actor_weight_src_rank = 0 # self._rank % actor_world_size -
self._rank = 0
-
if self.enable_offload: -
self.offload_model()
-
#if self.enable_offload: -
# self.offload_model()
- async def generate(
-
self, input_channel: Channel, output_channel: Channel, actor_channel: Channel
- def generate(
-
):-self
-
if self.enable_offload: -
self.reload_model()
-
#if self.enable_offload: -
# self.reload_model()
-
with open("/workspace/RLinf/envoutput_object.pkl", "rb") as f: -
env_output = pickle.load(f) -
env_output = env_output.__dict__
-
env_output = await self.recv_env_output(input_channel)
-
#env_output = await self.recv_env_output(input_channel)
-
if last_forward_inputs[stage_id] is not None: -
last_forward_inputs[stage_id] = self.update_intervene_actions( -
env_output, last_forward_inputs[stage_id] -
)
-
#if last_forward_inputs[stage_id] is not None: -
# last_forward_inputs[stage_id] = self.update_intervene_actions( -
# env_output, last_forward_inputs[stage_id] -
# )
-
self.send_chunk_actions(output_channel, actions)
-
#self.send_chunk_actions(output_channel, actions) for stage_id in range(self.num_pipeline_stages):
-
env_output = await self.recv_env_output(input_channel)
-
#env_output = await self.recv_env_output(input_channel)
-
with self.worker_timer(): -
actions, result = self.predict(extracted_obs)
-
#with self.worker_timer(): -
actions, result = self.predict(extracted_obs)
-
for i in range(self.num_pipeline_stages): -
self.send_rollout_batch(actor_channel, i)
-
#for i in range(self.num_pipeline_stages): -
# self.send_rollout_batch(actor_channel, i)
修改的配置
文件libero_10_ppo_openpi_pi05.yaml,笔者用了gpufree平台上的三个L40。
- actor,env,rollout: all
- actor: 0-1
- env,rollout: 2
- val_check_interval: -1
- val_check_interval: 8
- rollout_epoch: 8
- rollout_epoch: 1
- total_num_envs: 64
- total_num_envs: 20
- total_num_envs: 500
- total_num_envs: 8
- micro_batch_size: 128
- global_batch_size: 2048 # maximum : global batch size = micro batch size * actor num_processes.
- micro_batch_size: 20
- global_batch_size: 160 # maximum : global batch size = micro batch size * actor num_processe

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 29
29 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)