【数据结构--哈希表】
对哈希表及相关概念的理解,用C语言实现哈希表(直接定址法)
什么是哈希表
哈希表(Hash table),又称为散列表,是一种根据关键码值(Key value)直接进行访问的数据结构。它通过将关键码值映射到表中的一个位置来访问记录,从而加快查找的速度。这个映射函数称为散列函数,存放记录的数组称为散列表;
只看概念不好理解,举个例子
现在有一个商店,商品名称和价格一 一对应
假如想知道一个商品的价格,你肯定不希望从头开始一个一个查找,知道找到这个商品,
我们希望能够根据这个商品的名字直接找到价格
我们把商品叫做key(关键字),现在有一个数组price[ ],如果可以把key作为下标,价格作为值存在对应下标里面,是不是就可以直接通过访问key来得到价格,也就是price[key]就是要找的商品key的价格。
再看一个更直观的例子
现在要通过学号查找到学生成绩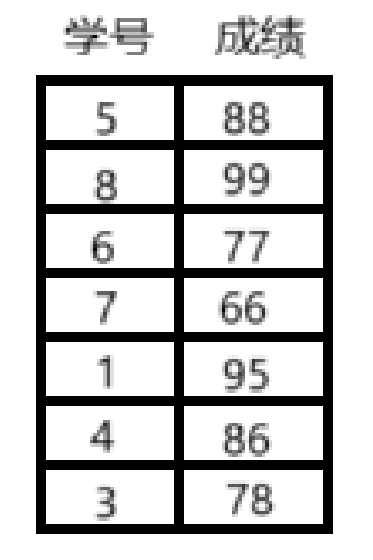
在学哈希表之前,我们是这样做的:
- 将所有学生的信息存到数组里
- 遍历数组所有元素,直到找到相应学号
也就是:

这样的时间复杂的是O(N)
换一种思路,如果将学号作为下标,将成绩学号对应的下表中,就会得到: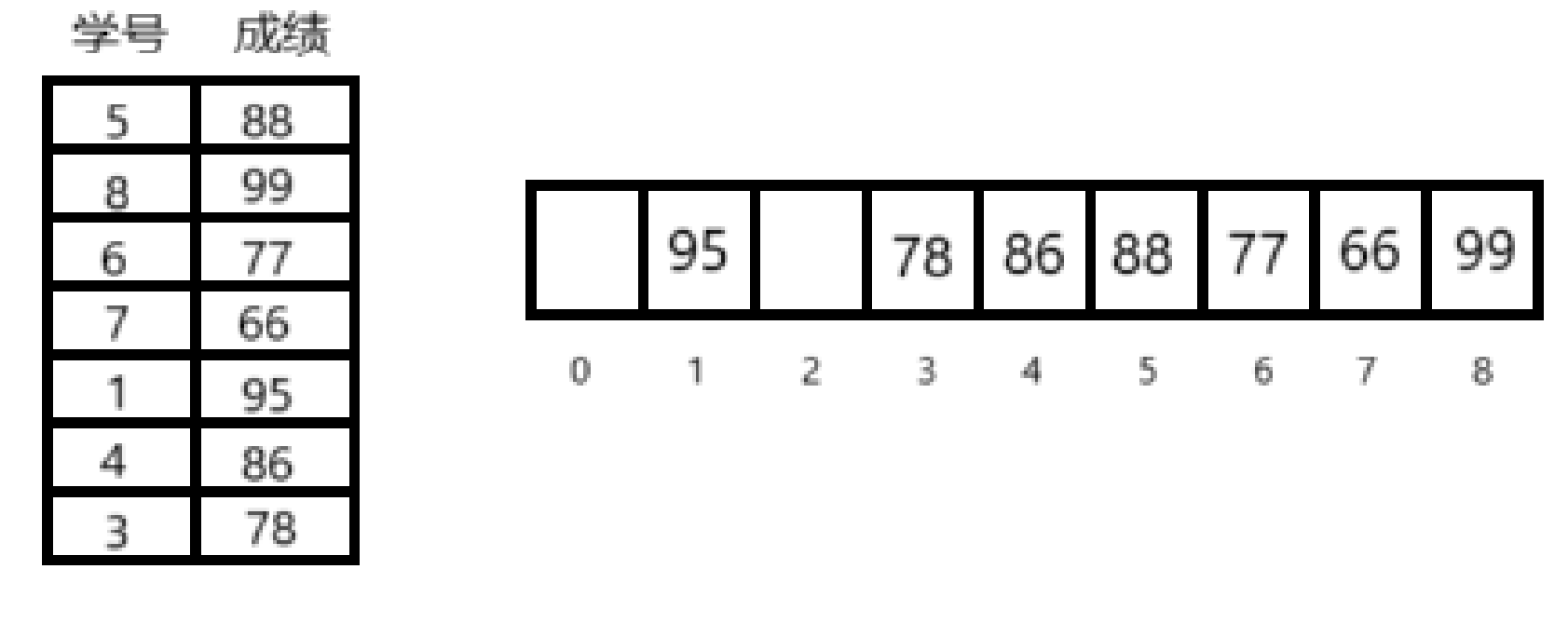
这样 如果要找学号为1的同学的成绩,直接访问下标1就可以得到数据,时间复杂度是O(1)
数组的下标与关键字的关系是散列函数H(key),上面的例子中H(key) = key,但是在很多情况下并不适用
比如下面这种情况
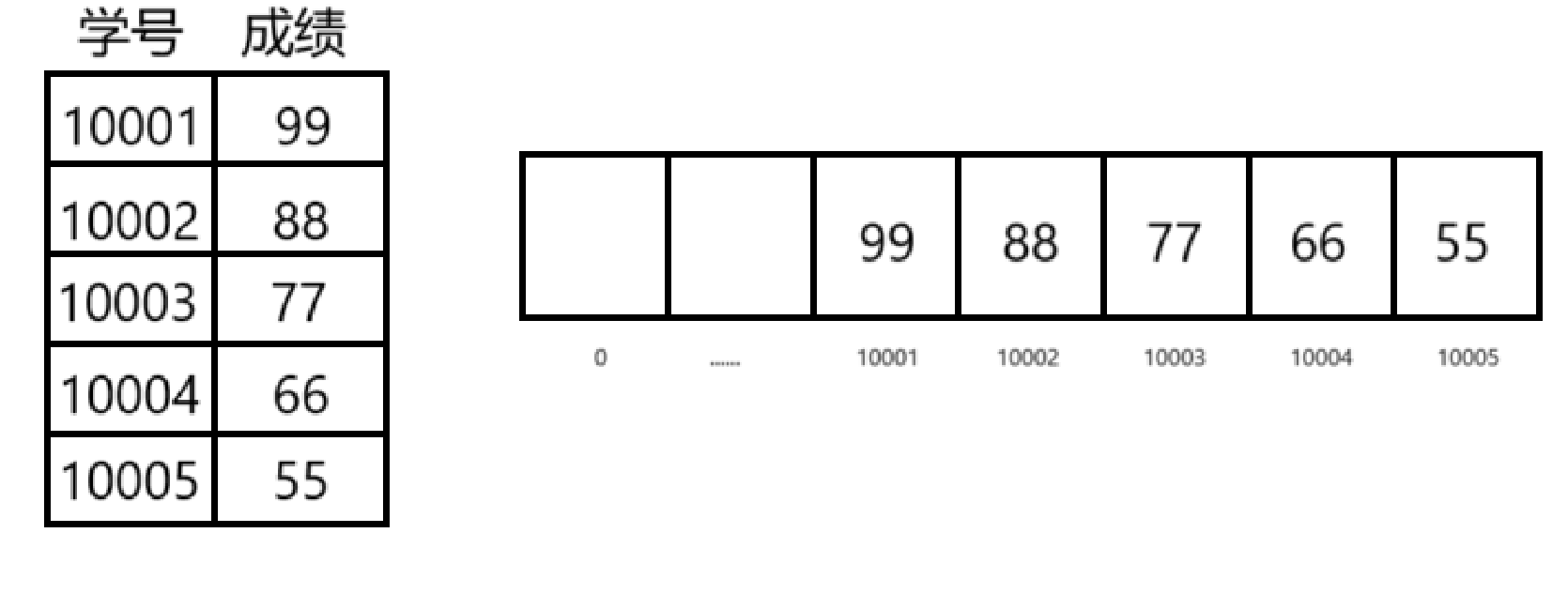
不难发现,0 - 10000 个空间都被浪费了 ,这空间浪费也太大了
这时候如果直接把学号当作关键字就不合适了
但是如果将(学号-10000)作为下标直接存储
那会得到
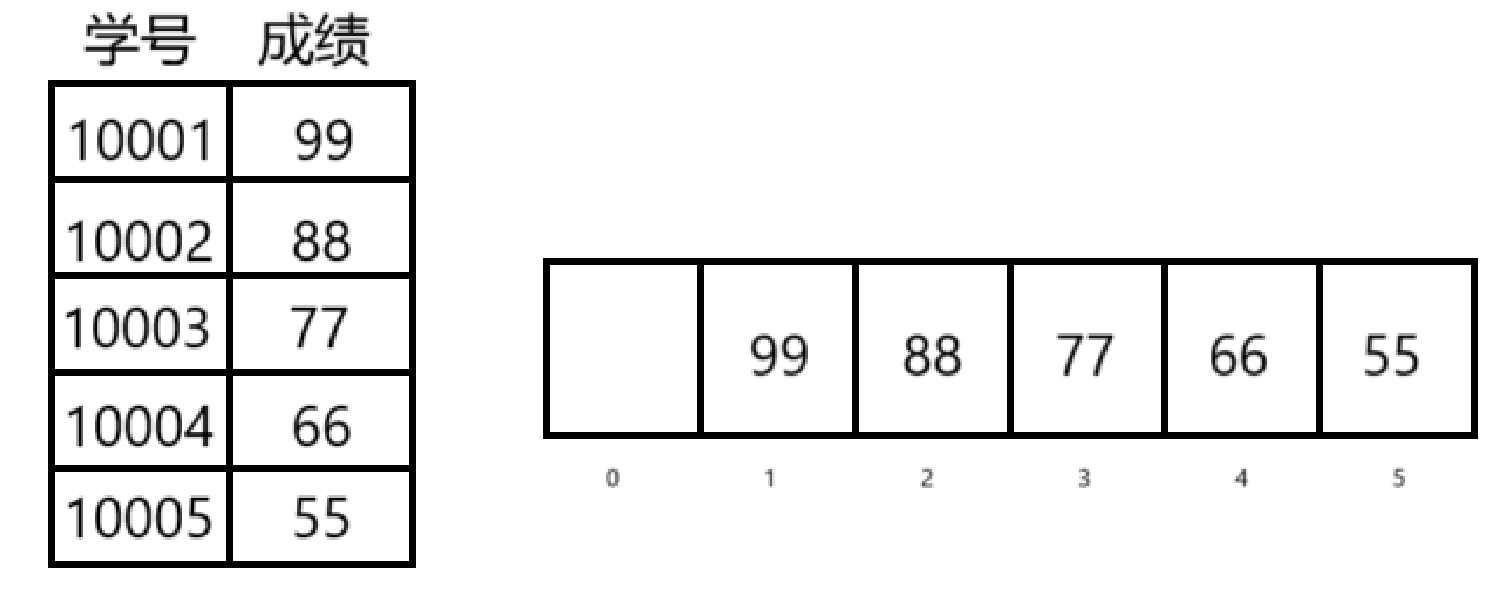
这时候如果要得到学号x的成绩,就可以通过访问下标为(x-10000)的数据得到
这样就减少了空间的浪费,此时H(key) = key - 10000
此时所用的散列函数实际上是线性函数,也就是y = ax + b 的形式,这里a=1,b=-10000
到这差不多对哈希表有了初步认识
上图提到的学号为10001的数据存到下标为1的位置,这里的10001和1就是映射
散列函数的构造方法
散列函数H(key) = ? 来表示
构造方法包括 直接定址法、除留余数法、数字分析法和平方取中法
直接定址法
上面例子提到的 H(key) = ax + b ,这样来确定下标的方法为直接定址法
但是这种方法只适合关键字基本连续的情况,否则会出现大量空间浪费
如果关键字很分散,会出现很多空位,比如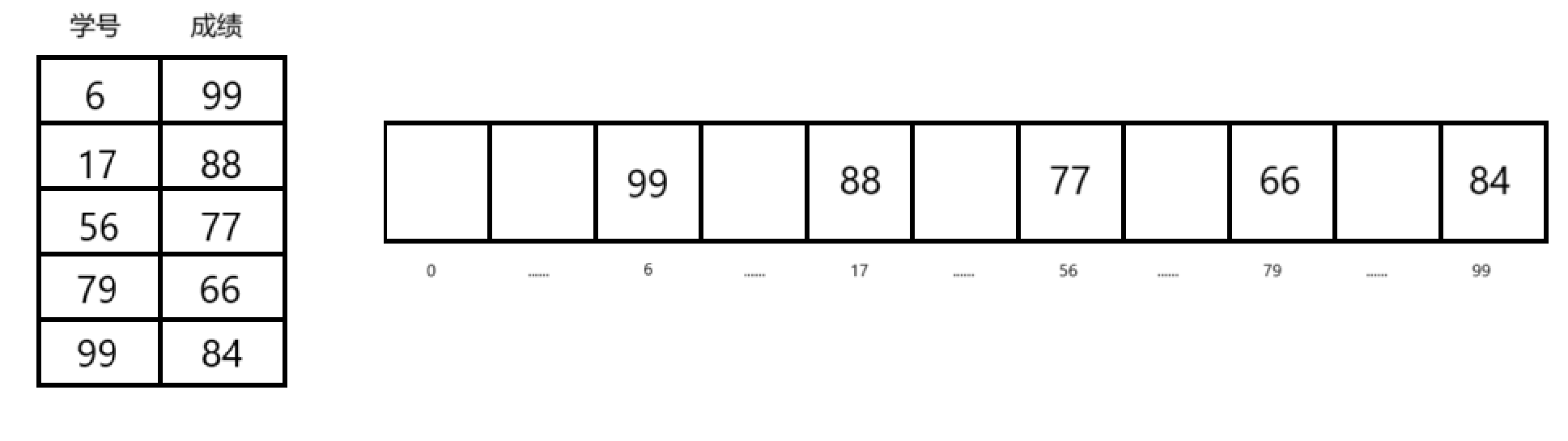
这样仍然会有大量空间浪费,所以这时候直接定址法就不适用了
除留余数法
除留余数法用的比较多,它的散列函数是 H(key) = key % p (p是整数)
现在有一个长度为6的数组,现要将下图五个数据存入数组中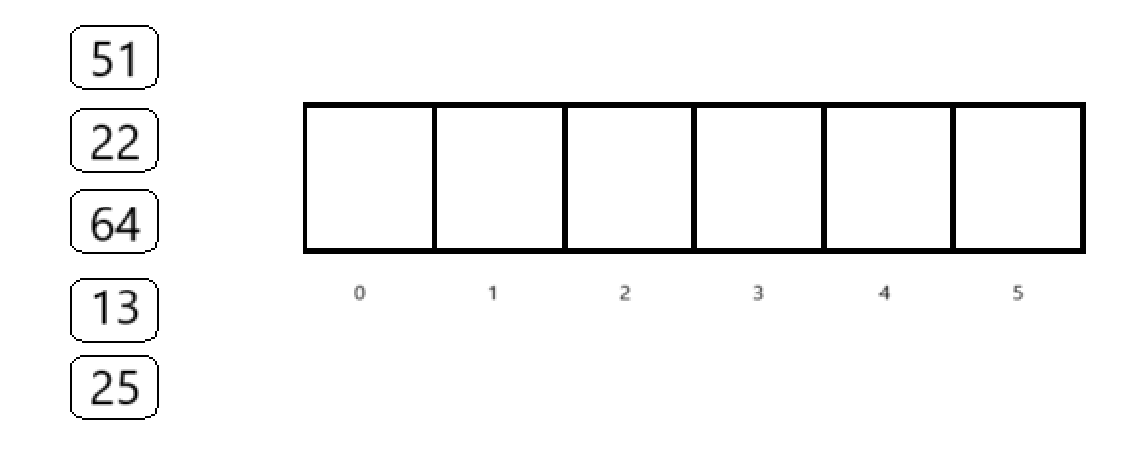
数组下标范围是0-5,如果对6求余,得到的下标的范围是0-5,是符合要求的
不过已经有结论 对一个小于等于表长的最大质数求余,发生冲突的可能性更小(下面讲什么是冲突),效果更好 ,所以 p一般取小于等于表长的最大质数
所以此时p取5
那么就会得到: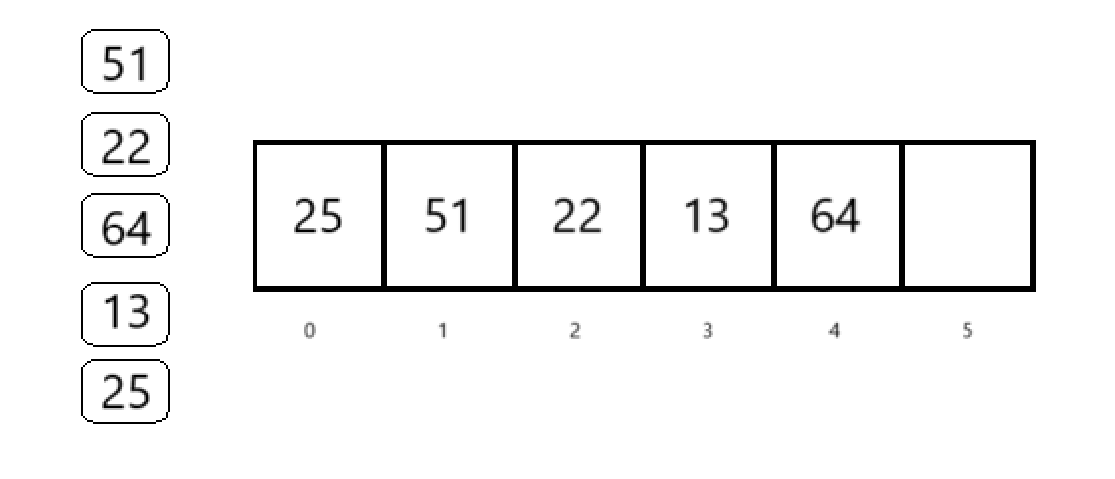 数组(arr)具体是怎么变成这样的:
数组(arr)具体是怎么变成这样的:
取p=5 , H(key) = key % 5
51:51%5=1 -> arr[1] = 51
22:22%5=2 -> arr[2] = 22
64:64%5=4 -> arr[4] = 64
13:13%5=3 -> arr[3] = 13
25:25%5=0 -> arr[0] = 25
既然key对5求余后的结果在0到4之间,那下标5是不是们没有什么用?
事实上不是的。关键字确实不能直接映射到下标5上,不过如果发生冲突,那下标5的位置就发挥作用了
映射
对于上面的数组 13存在下标为3的位置而不是为1、2、13…的位置
这就是映射 也就是说关键字13和下标为3的位置有映射关系
包括51和下标为1的位置的映射关系…
映射又分为两种,一对一映射,一对多映射
一对一映射就是一个下标只和一个值有映射关系
一对多映射也就是说可能有几个值和同一个下标有映射关系,这时候这几个值就是同义词(下面会用到同义词的概念)
通过下面的内容举例子
哈希冲突
再次明确
对于上面的数组,再加入一个元素40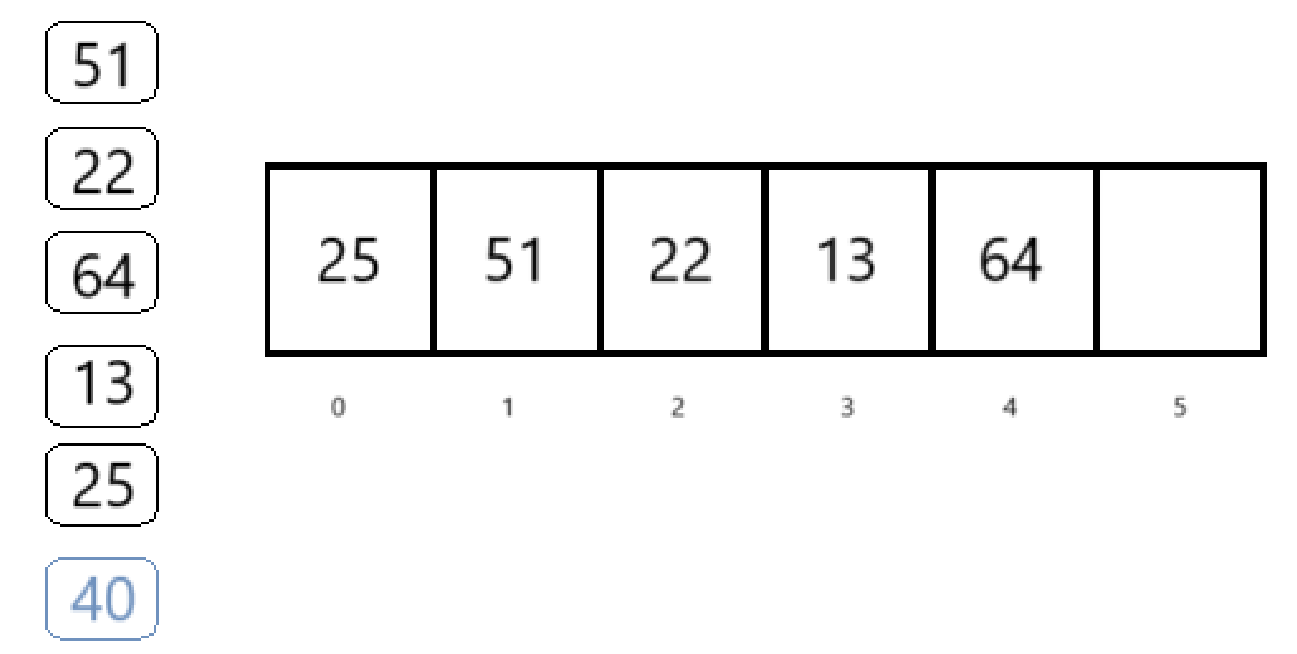
按照散列函数H(key) = key%5,40对5求余是0,应该插入下标为0的位置,但是下标0的位置已经存了关键字25了,这时候就发生了冲突(也叫碰撞)
也就是说下标为0的位置和25、40都有映射关系,也就是上面提到的一对多映射,也就是25和40是同义词(下面会用到这个概念)
冲突的存在会影响散列表的效率,冲突越多效率越低,所以要尽可能减少冲突
对一个小于等于表长的最大质数求余,结果会更均匀
所以如果使用直接定址法构造散列函数不会发生冲突,但是只适合关键字分布连续的情况,否则会出现大量空间浪费
如果使用除留余数法,可以把关键字映射到连续的地址空间,但是可能会发生冲突
装填因子
用 α 表示装填因子
α = n/m(n是表中元素个数,m是表的长度)
实际上反映了空间利用率
α越大,表明空间利用的越多,空闲位置越少,那么插入新元素的时候发生冲突的可能性就会越大
α越小,冲突的可能性越小,但是空间利用率越低
所以α即不能太高,也不能太低,一般让α保持在0.75
总结一下,影响散列表性能的因素包括 散列函数、装填因子和处理冲突的方式(下面说)
冲突处理
开放定址法
总的来说就是发生冲突时,就占用别的位置
线性探测法
如果关键字2映射到的下标为 K, K位置上已经有了元素,此时发生冲突,那向后找,直到遇到空闲位置(表尾的下一个位置是表首),将关键字2插入数组就可以了
比如将下面几个元素存入长度为8的数组中
利用除留余数法构造散列函数,H(key) = key%p,此时p取7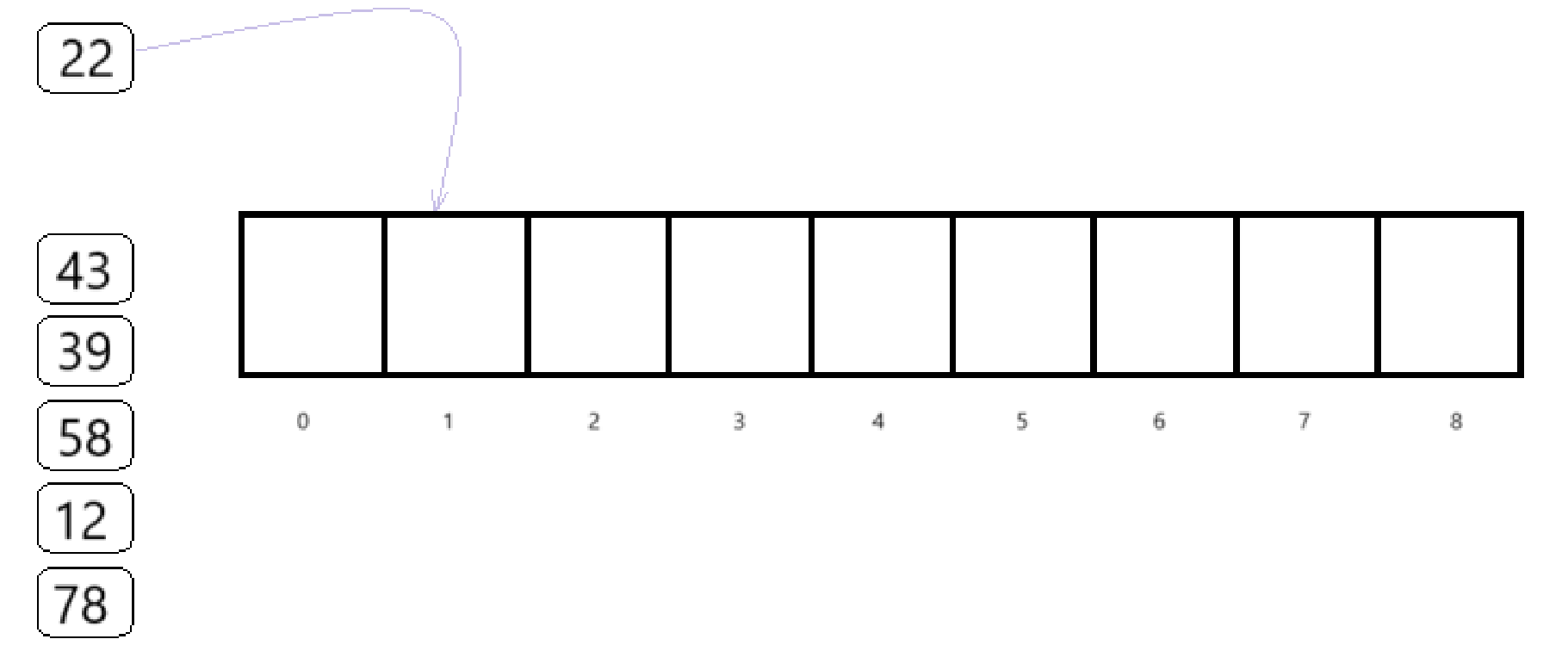
将第二个元素插入时,发生了冲突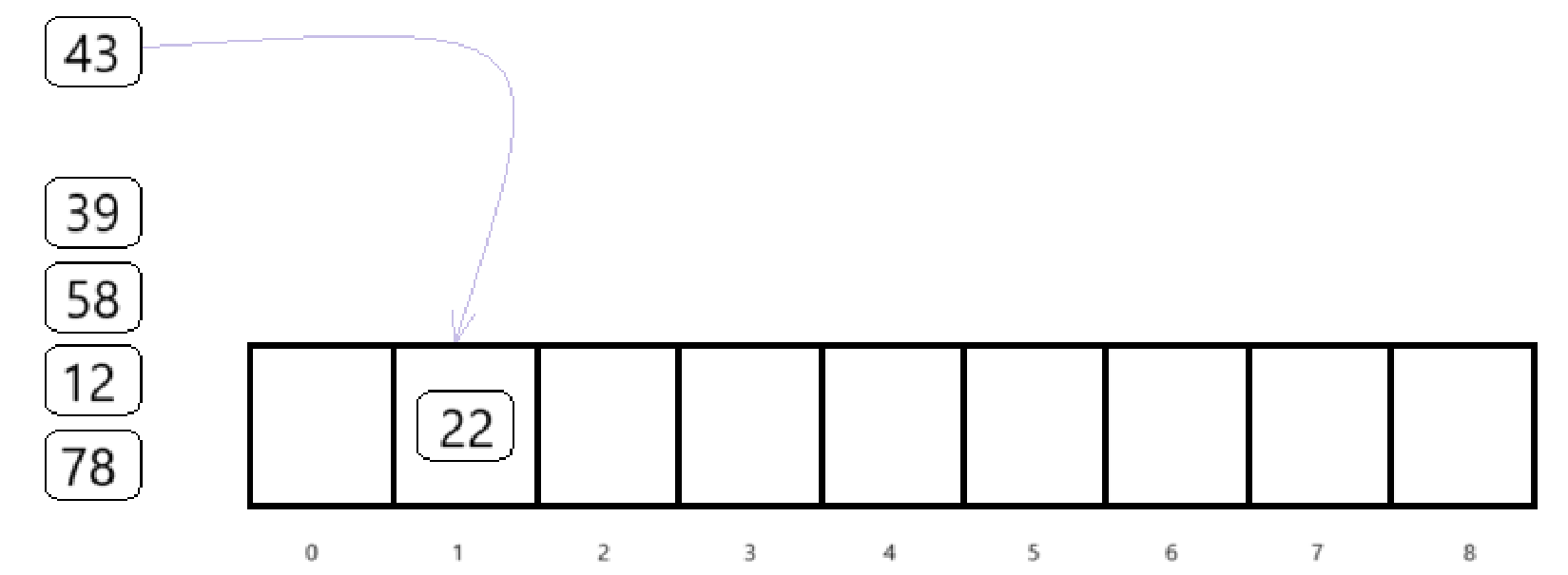
既然下标为1的位置冲突了,那就往后找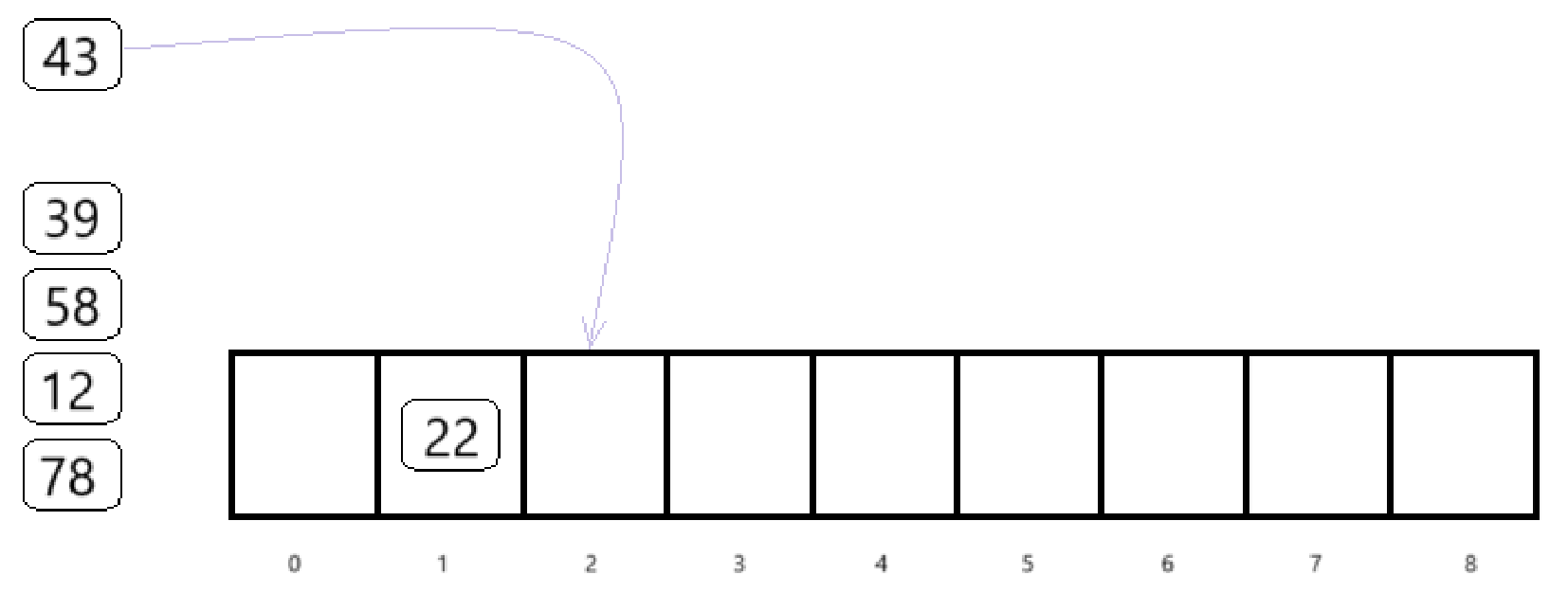
发现下标为2的位置还没有元素,所以插入下标为2的位置
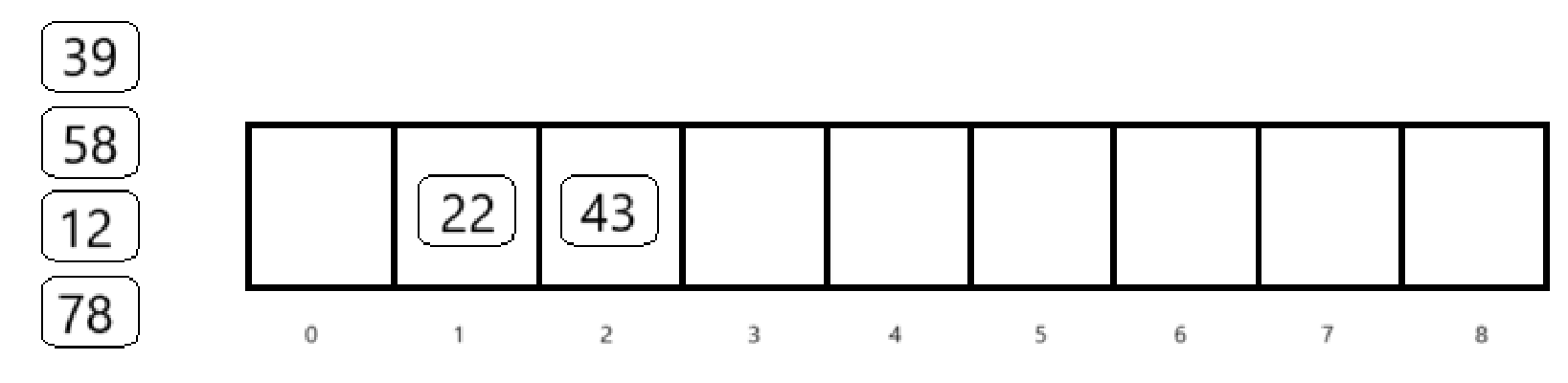
其他元素按照同样方法插入数组,最后可以得到: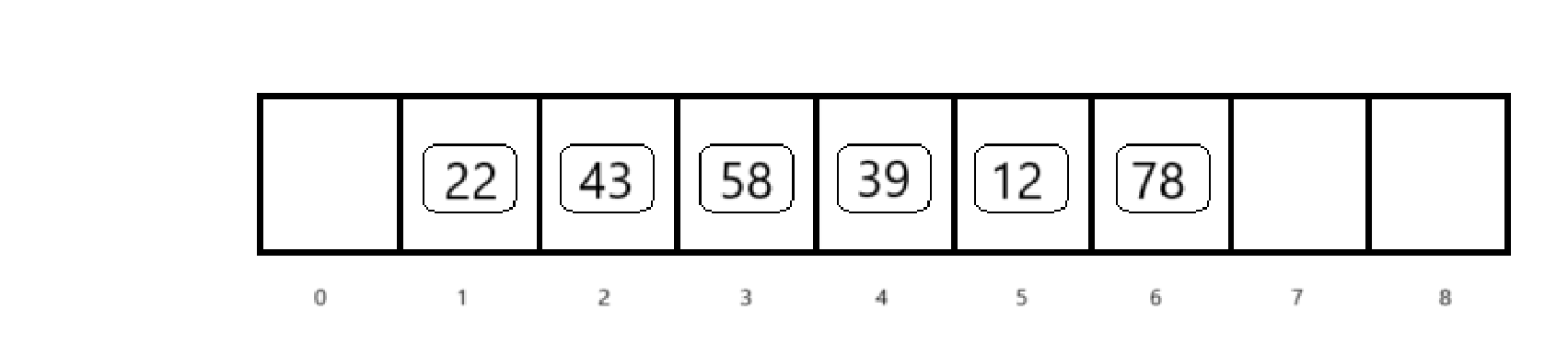
这个方法的问题是:容易出现关键字在某一区域堆积(聚集、堆集)
意思就是 每次发生冲突的时候,就会往下一个位置放,原本应该映射到下一个位置的关键字,就要放到下下个位置,这就导致关键字最后都堆积在某一块区域了
查找:
查找元素78
H(key) = key%7 -->H(78) = 1
将元素78和下标1上的元素进行对比,如果不一样,就按照线性探测,向后走,当比较到下标6的时候,找到了元素78
查找元素79:
H(key) = key%7 -->H(79) = 2
将元素79和下标2上的元素进行对比,不一样,向后找,直到找到下标为7的位置,发现下标为7的位置是空的,那么就是没有查找到
需要注意的是,做查找的时候要按照插入时的规则进行,因为我插入就是直接查找下一个没有元素的位置,所以这里查找的时候也直接向后找就可以了
删除:
删除12:找到下标5
那问题来了 如果直接将下标5的元素删掉,那就会截断78的查找路径
怎么说呢?
查找元素78 ,78%7 = 1,78和下标1上的元素不一样,向后找 依次比较,直到找到下标5的位置,发现下标5的位置是空的,那么就认为78不存在,这就导致了错误
所以不可以直接删掉
一般会将删除的位置进行标记,使其不影响其他元素的查找,同理,将空位置也进行标记
比如可以将删除位置标记成 -1,这个数不可以和关键字、空位置的标记重复
在查找时,只有遇到空位置才会结束查找,遇到删除位置时继续查找,不会影响其他关键字的查找
在插入时,关键词可以插入到空位置和删除位置
平方探测法
与线性探测不同,此方法在发生冲突时不是向后一个一个探测,而是以+1²,-1²,+2²,-2²,+3²,-3²,…,的顺序进行探测(同样的,表尾之后是表首)
这种探测方法更加跳跃
优点是可以缓解线性探测法出现的堆积问题
缺点是不一定能探测到散列表所有位置
但是已经有结论:如果表长是某个4k+3的质数(k为正整数),那么一定可以探测到所有位置
所以一般 表长=某个4k+3的质数 (表长是质数)
比如 7 = 4 * 1+3 , 11=4 * 2+3
拉链法
就是把所有的同义词用单链表串起来(映射部分提到同义词)
说白了就是,如果关键字a和b映射的下标相同是 i ,数组是 arr ,也就是把 arr[i] 看作一个链表,初始指向空,将元素使用头插法插入数组
比如还是这样一个数组
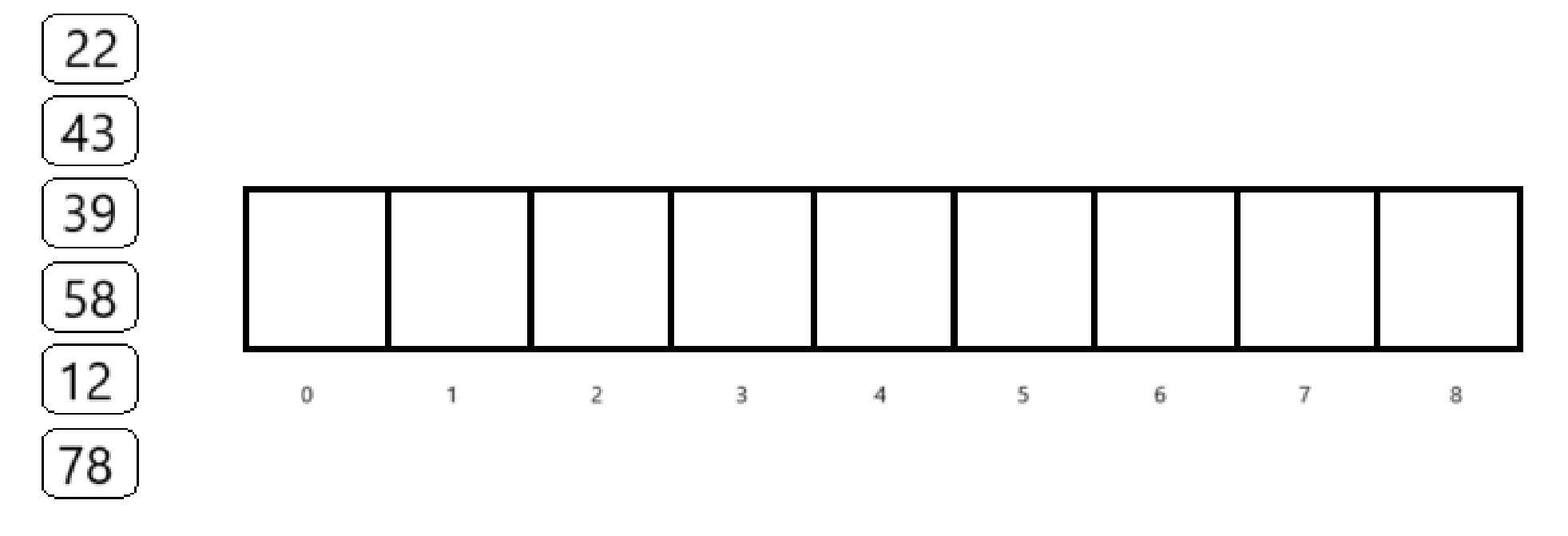
取p=7
如果使用拉链法就是这样的
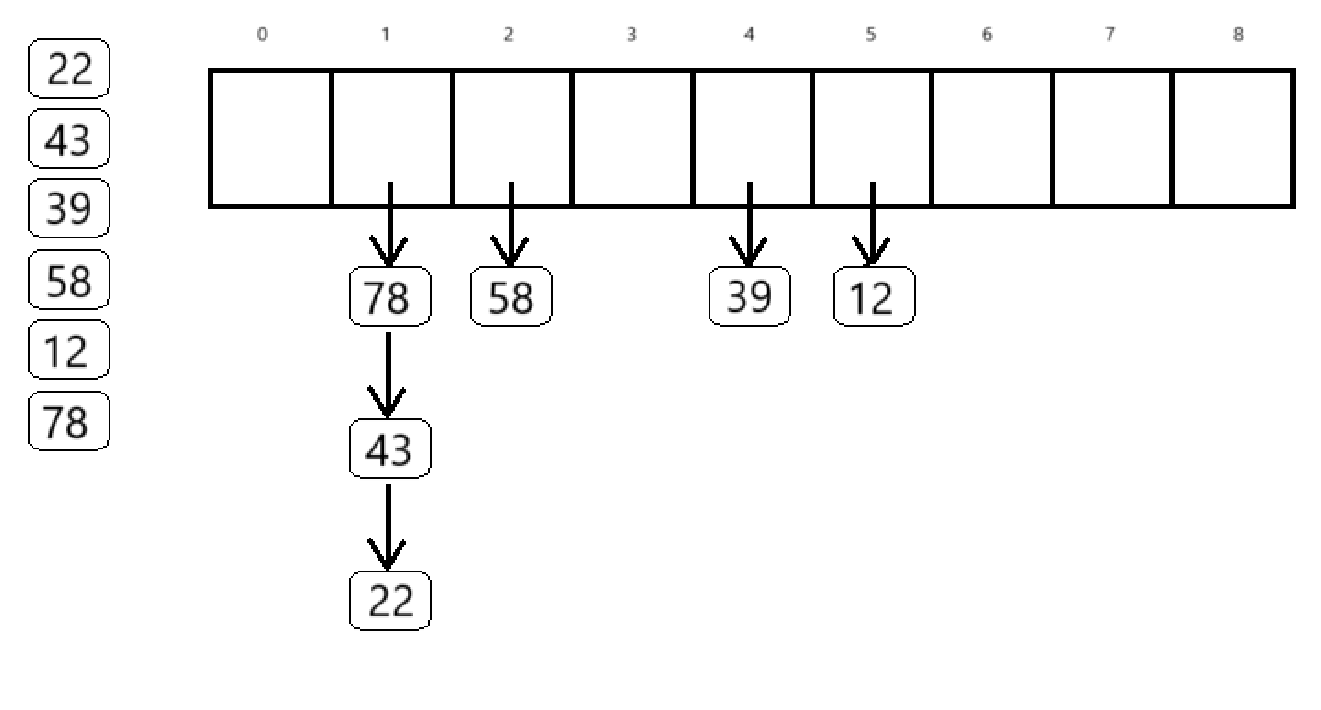
所以数组内每个元素都包括一个头指针,也就是说数组是由一个一个单链表构成的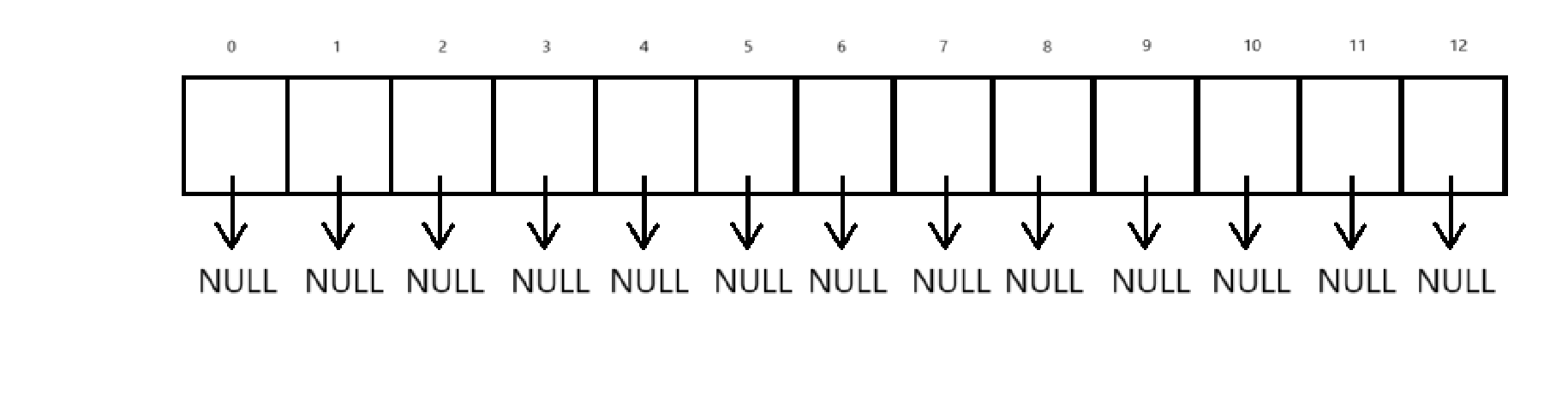
如果某个位置没有元素,那就指向空
用^表示指向空
arr是有13个空间的数组
初始也就是
对下面这些数据进行处理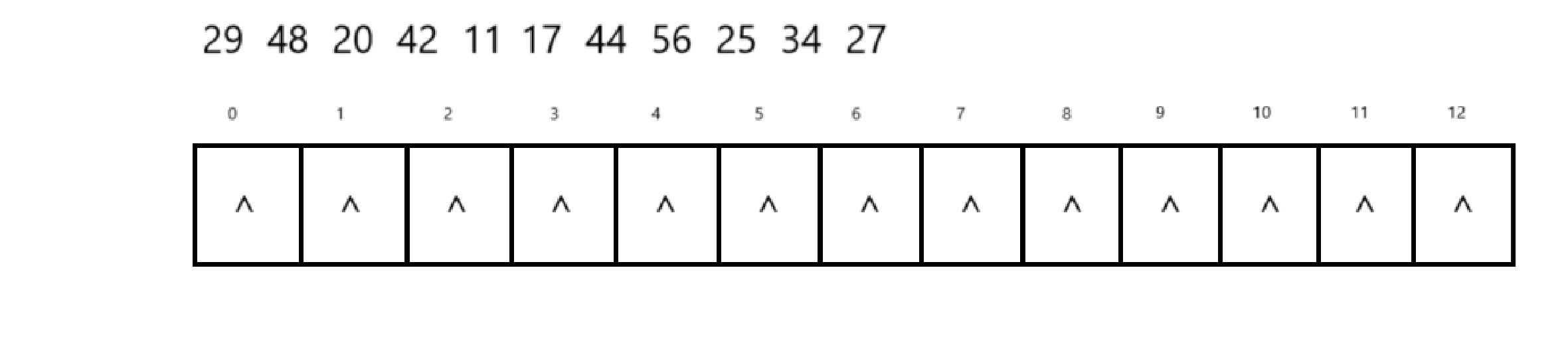
取小于等于表长的最大质数13为p,恰好13=4 * 3 + 1
处理结果就是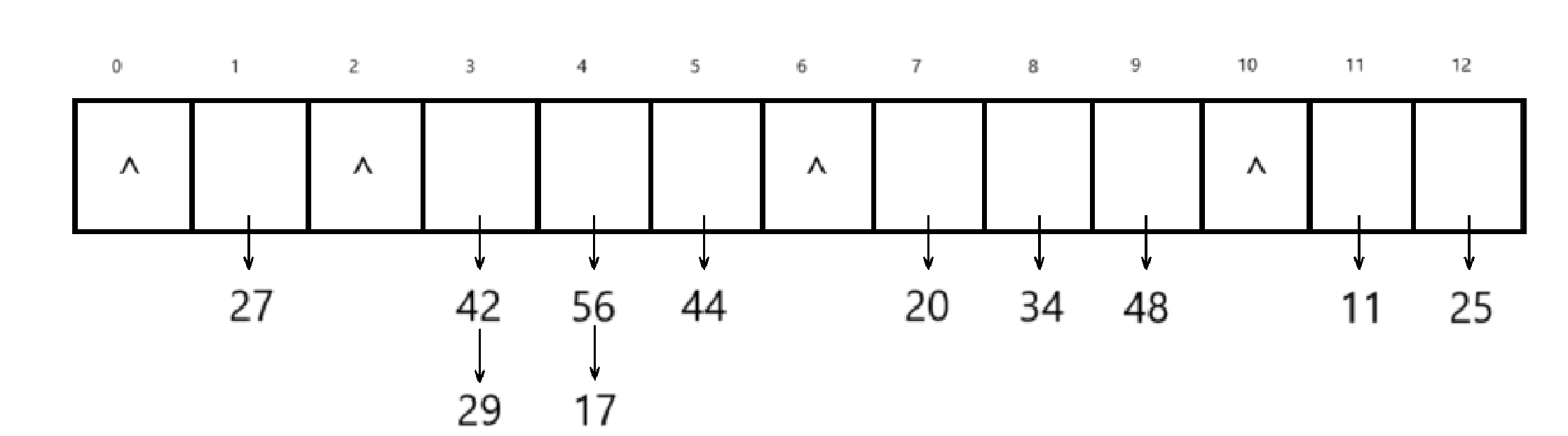
查找元素
查找17:17%13=4 找到下标为4的位置,首先和56进行比较,不相等,向下走,找到了17
查找40:40%13=1 找到下标为1的位置,首先和27进行比较,不相等,向下走,到了NULL,表示没有该元素
拉链法可以直接删除元素
比如删除关键字42,42%13=3,找到下标为3的位置,让42上一个位置直接指向下一个位置就可以了
实现哈希表
开放定址法
- 定义哈希表结构
使用动态数组作为哈希表的结构
同时定义空位置和删除位置
//定义哈希表结构
#define MAX 10
#define Empty -32768
#define Delete -32766
typedef int HDataType;//重定义类型
typedef struct Hash
{
HDataType* arr;//动态数组
int size;//个数
}Hash;
- 初始化
首先给数组分配空间,数组中所有元素为空状态
//初始化哈希表
void HashInit(Hash* H)
{
//给数组分配空间
H->arr = (HDataType*)malloc(sizeof(HDataType) * MAX);//MAX是上面提到的p
H->size = 0;
int i;
for (i = 0; i < MAX; i++)
{
H->arr[i] = Empty;//都设置成空状态
}
}
- 得到下标 实际上是哈希函数
不写函数直接算也行
int Index(HDataType x)//得到下标
{
return x % MAX;
}
- 插入关键字
///插入数据
void HashInsert(Hash* H, HDataType x)
{
//得到下标
int index = Index(x);
while (H->arr[index] != Empty || H->arr[index] != Delete)//查找空状态或删除状态的位置
{
index = (index + 1) % MAX;//这里除以MAX 是因为如果查找到数组尾 要回到数组头开始查找 直接取余就可以
}
H->arr[index] = x;
H->size++;
}
- 删除关键字
首先通过关键字找到下标
再将下标上的元素与关键字进行比较 如果不相等继续向后查找,如果查找到空位置或者最开始的位置,说明没有这个元素
//删除关键字
void HashDelete(Hash* H, HDataType x)
{
int index = Index(x);//得到下标
int initial = index;
while (H->arr[index] != x)
{
index = (index + 1) % MAX;
if (H->arr[index] == Empty || index == initial)
{
printf("未查找到该关键字\n");
return;
}
}
//将要删除的位置设置为空
H->arr[index] = Delete;
}
- 查找数据 返回下标
//查找数据 返回下标
int HashSearch(Hash H, HDataType x)
{
int index = Index(x);
int initial = index;//记录一开始的下标 如果遍历回来也是没有查找到
while (H.arr[index] != x)
{
index = (index + 1) % MAX;
if (H.arr[index] == Empty || index >= initial)//1.为空 代表没有这个元素 2.如果遍历了一圈回来还是没有找到 那么也说明没有此元素
{
return -1;
}
}
return index;
}

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)