小白也能懂!CNN卷积神经网络入门指南!
卷积就是用一个“可移动的小窗口”(叫数据窗口),和图像逐元素相乘再相加的操作。这个小窗口其实是卷积核(滤波器),里面是一组固定权重,就像“特征探测器”,帮网络提取图像特征(比如边缘、纹理)。就像人眼先看轮廓再看细节,CNN通过卷积,能一步步“看到”图像的特征——比如第一层卷积可能提取出图像的边缘,后面的卷积层能提取出物体的局部结构,最后组合成完整的物体特征~
还在为看不懂卷积神经网络头疼?别慌!这篇超详细入门文,从基础原理到核心操作,手把手带你搞懂CNN,零基础也能轻松get~先补个小知识:没了解过神经网络的同学,可先看我们这一篇文章→神经网络小白入门:从0看懂基础神经网络算法,公式+步骤超详细!
另外,我整理了卷积神经网络(CNN)算法经典论文+示例代码,感兴趣的dd~
一、先搞懂:图像在电脑里长啥样?
想学好CNN,得先知道图像的“数字形态”:
-
灰度图:是个二维矩阵,每个元素值在0-255之间,0代表最暗,255代表最亮,比如一张黑白照片,就是靠这样的矩阵存储。

-
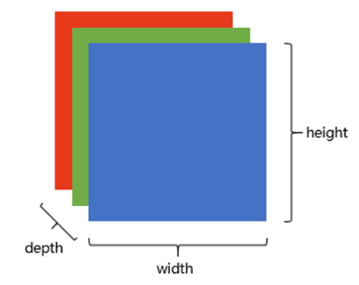
RGB图:我们平时看的彩色图,是由红(R)、绿(G)、蓝(B)三个通道组成,相当于3个有序排列的二维矩阵,也能理解成三维张量,用(宽,高,深)来描述,这里的“深”就是通道数。
二、为啥非得学CNN?传统神经网络不够用?
传统神经网络有个大bug——没法实现“平移不变性”:
比如同一种物体,放在图像左侧和右侧,传统神经网络可能会认成两种不同东西(因为输入神经元对应位置固定)。
而我们需要的是:不管物体在图像哪个位置,都能准确识别!这时候CNN就派上用场了,它靠卷积操作捕捉图像局部特征,不受物体位置影响,完美解决这个问题~
三、核心来了!什么是“卷积”?
1. 通俗理解
卷积就是用一个“可移动的小窗口”(叫数据窗口),和图像逐元素相乘再相加的操作。这个小窗口其实是卷积核(滤波器),里面是一组固定权重,就像“特征探测器”,帮网络提取图像特征(比如边缘、纹理)。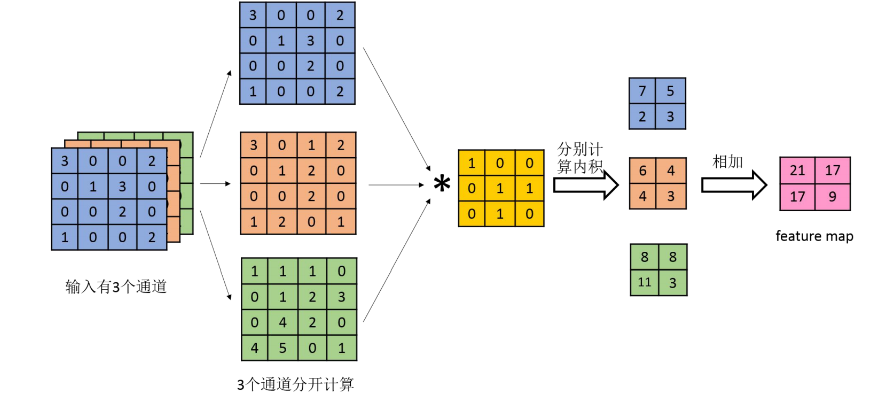
2. 关键参数要记牢
- 步长(stride):数据窗口每次滑动的距离,比如stride=2,就是每次移2个像素。
- 卷积核个数:决定输出特征图的“深度(depth)”,有几个卷积核,输出深度就为几。
- 零填充(zero-padding):在图像外围补几圈0,目的是让卷积核能覆盖图像边缘,还能调整输出特征图尺寸。
3. 必看公式:输出特征图尺寸怎么算?
当输入图像尺寸为 W i n × H i n × D i n W_{in} \times H_{in} \times D_{in} Win×Hin×Din(宽×高×深度),卷积核尺寸为 K × K K \times K K×K,步长为 s s s,填充数为 p p p时,输出特征图的宽和高计算公式为:
W o u t = W i n − K + 2 p s + 1 W_{out} = \frac{W_{in} - K + 2p}{s} + 1 Wout=sWin−K+2p+1
H o u t = H i n − K + 2 p s + 1 H_{out} = \frac{H_{in} - K + 2p}{s} + 1 Hout=sHin−K+2p+1
输出深度 D o u t D_{out} Dout = 卷积核个数
4. 举个例子更清楚
比如输入图像是4×4(无深度,简化为灰度图),卷积核3×3,stride=1:
- 不填充(p=0):输出宽=(4-3+0)/1 +1=2,高=2,即输出2×2特征图,尺寸变小还丢边缘信息。
- 填充p=1(外围补1圈0):输入变成6×6,输出宽=(6-3+2×1)/1 +1=6,高=6,尺寸和原图像一致,还能捕捉边缘特征~
四、CNN的“身体构造”是怎样的?
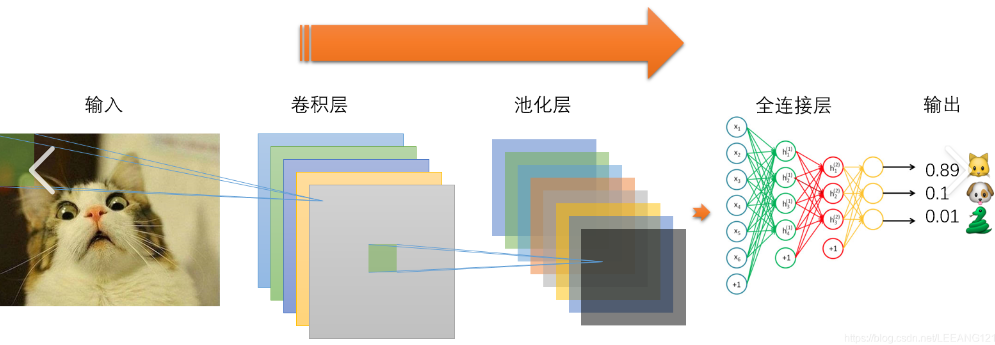
CNN主要由5部分组成,层层递进提取特征:
- 输入层:接收原始图像数据,比如RGB图就是(宽,高,3)的张量。
- 卷积+激活层:先用卷积核做卷积操作,再通过激活函数(比如ReLU)引入“非线性”,让网络能学复杂特征(没有激活函数,再多卷积层也只能学线性特征)。
- 池化层:缩小特征图尺寸,减少计算量。常见两种:
- 最大池化:取池化窗口内最大值(比如2×2窗口,取4个像素里最大的)。
- 平均池化:取池化窗口内平均值。
- 多层堆叠:把“卷积层+激活层+池化层”反复堆叠,浅层学边缘、纹理,深层学更复杂的特征(比如物体的眼睛、鼻子)。
- 全连接+输出层:全连接层把前面提取的特征“汇总”,最后输出结果,比如分类任务输出每个类别的概率,回归任务输出具体数值。
五、最后看个直观效果:卷积后图像变啥样?
就像人眼先看轮廓再看细节,CNN通过卷积,能一步步“看到”图像的特征——比如第一层卷积可能提取出图像的边缘,后面的卷积层能提取出物体的局部结构,最后组合成完整的物体特征~
六、实战!用PyTorch跑通CNN:手写数字分类示例
原理讲完,直接上能跑的代码!下面用PyTorch实现一个简单CNN,完成MNIST手写数字分类(数据集自动下载,不用手动找图),每行都有注释,小白跟着复制粘贴就能运行~
第一步:准备环境
先安装必备库,打开命令行输入以下代码(安装过的可以跳过):
pip install torch torchvision matplotlib numpy
torch:PyTorch核心,用来搭神经网络torchvision:提供现成数据集和图像处理工具matplotlib:画图看数据和预测结果
第二步:完整代码+逐行注释
# 1. 导入需要的库
import torch # PyTorch核心库
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器
from torchvision import datasets, transforms # 数据集+图像预处理
from torch.utils.data import DataLoader # 批量加载数据
import matplotlib.pyplot as plt # 画图工具
import numpy as np # 辅助数值计算
# ---------- 关键:强制指定matplotlib使用英文字体,解决显示乱码 ----------
plt.rcParams["font.family"] = ["Arial", "DejaVu Sans", "Helvetica"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示异常
# ---------------------------------------------------------------------
# 2. 图像预处理:把图片转成模型能读的格式
transform = transforms.Compose([
transforms.ToTensor(), # 把PIL图片转成Tensor(维度:[通道数, 高, 宽])
transforms.Normalize((0.1307,), (0.3081,)) # 标准化
])
# 3. 加载MNIST手写数字数据集(自动下载)
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.MNIST(
root='./data',
train=False,
download=True,
transform=transform
)
# 4. 批量加载数据
train_loader = DataLoader(
train_dataset,
batch_size=64,
shuffle=True
)
test_loader = DataLoader(
test_dataset,
batch_size=1000,
shuffle=False
)
# 5. 搭建CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 第一层:卷积+激活+池化
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 第二层:卷积+激活+池化
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 全连接层
self.fc1 = nn.Linear(in_features=32 * 7 * 7, out_features=128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(in_features=128, out_features=10)
# 前向传播
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = x.view(-1, 32 * 7 * 7)
x = self.relu3(self.fc1(x))
x = self.fc2(x)
return x
# 用于获取中间层特征图
def get_features(self, x):
# 获取第一层卷积后的特征图
conv1_out = self.relu1(self.conv1(x))
pool1_out = self.pool1(conv1_out)
# 获取第二层卷积后的特征图
conv2_out = self.relu2(self.conv2(pool1_out))
pool2_out = self.pool2(conv2_out)
return conv1_out, conv2_out
# 6. 初始化模型、损失函数、优化器
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 7. 训练模型
def train_model(model, train_loader, criterion, optimizer, epochs=5):
model.train()
for epoch in range(epochs):
total_loss = 0.0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * images.size(0)
avg_loss = total_loss / len(train_loader.dataset)
print(f'Training Epoch [{epoch+1}/{epochs}], Average Loss: {avg_loss:.4f}')
# 8. 测试模型
def test_model(model, test_loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'\nTest Set Accuracy: {accuracy:.2f}%')
return accuracy
# 9. 可视化预测结果
def show_predictions(model, test_loader, num_samples=10):
model.eval()
with torch.no_grad():
images, labels = next(iter(test_loader))
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
plt.figure(figsize=(15, 6))
for i in range(num_samples):
plt.subplot(2, 5, i + 1)
# 反标准化以正确显示图像
img = images[i].cpu().numpy().squeeze(0)
img = img * 0.3081 + 0.1307 # Apply denormalization
plt.imshow(img, cmap='gray')
# 根据预测是否正确设置标题颜色
color = 'green' if labels[i].item() == predicted[i].item() else 'red'
plt.title(f'True: {labels[i].item()}\nPred: {predicted[i].item()}', color=color)
plt.axis('off')
plt.tight_layout()
plt.savefig('prediction_results.png') # Save image
print("Prediction results saved as 'prediction_results.png'")
plt.show()
# 10. 可视化卷积核
def visualize_kernels(model):
# 获取第一层卷积核
kernels = model.conv1.weight.data.cpu().numpy()
# 标准化卷积核以更好地显示
kernels = (kernels - kernels.min()) / (kernels.max() - kernels.min())
plt.figure(figsize=(8, 8))
for i in range(kernels.shape[0]): # 16 kernels
plt.subplot(4, 4, i + 1)
plt.imshow(kernels[i, 0], cmap='gray') # Display each kernel
plt.title(f'Kernel {i+1}')
plt.axis('off')
plt.tight_layout()
plt.savefig('conv1_kernels.png') # Save image
print("Convolution kernels visualization saved as 'conv1_kernels.png'")
plt.show()
# 11. 可视化特征图
def visualize_feature_maps(model, test_loader, img_index=0):
model.eval()
with torch.no_grad():
# 获取一张测试图像
images, _ = next(iter(test_loader))
img = images[img_index:img_index + 1].to(device) # Take a single image
# 获取特征图
conv1_features, conv2_features = model.get_features(img)
# 显示原始图像
plt.figure(figsize=(16, 12))
plt.subplot(3, 6, 1)
original_img = img.cpu().numpy().squeeze()
original_img = original_img * 0.3081 + 0.1307 # Denormalize
plt.imshow(original_img, cmap='gray')
plt.title('Original Image')
plt.axis('off')
# 显示第一层卷积后的特征图
conv1_features = conv1_features.cpu().numpy().squeeze()
for i in range(min(15, conv1_features.shape[0])): # Show first 15 feature maps
plt.subplot(3, 6, i + 2)
feature_map = conv1_features[i]
feature_map = (feature_map - feature_map.min()) / (feature_map.max() - feature_map.min())
plt.imshow(feature_map, cmap='gray')
plt.title(f'1st Layer Feature Map {i+1}')
plt.axis('off')
plt.tight_layout()
plt.savefig('conv1_feature_maps.png')
print("First layer convolution feature maps saved as 'conv1_feature_maps.png'")
plt.show()
# 显示第二层卷积后的特征图
plt.figure(figsize=(16, 12))
plt.subplot(3, 6, 1)
plt.imshow(original_img, cmap='gray')
plt.title('Original Image')
plt.axis('off')
conv2_features = conv2_features.cpu().numpy().squeeze()
for i in range(min(15, conv2_features.shape[0])): # Show first 15 feature maps
plt.subplot(3, 6, i + 2)
feature_map = conv2_features[i]
feature_map = (feature_map - feature_map.min()) / (feature_map.max() - feature_map.min())
plt.imshow(feature_map, cmap='gray')
plt.title(f'2nd Layer Feature Map {i+1}')
plt.axis('off')
plt.tight_layout()
plt.savefig('conv2_feature_maps.png')
print("Second layer convolution feature maps saved as 'conv2_feature_maps.png'")
plt.show()
# 12. 主函数:运行整个流程
if __name__ == '__main__':
print(f'Using device: {device}')
train_model(model, train_loader, criterion, optimizer, epochs=5)
test_model(model, test_loader)
# 生成并保存各种可视化图像
show_predictions(model, test_loader)
visualize_kernels(model)
visualize_feature_maps(model, test_loader, img_index=0) # Visualize feature maps of the 0th test image
运行结果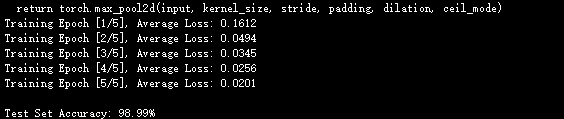



第三步:运行说明&常见问题
-
怎么运行?
把代码复制到PyCharm、VS Code或Jupyter Notebook,点击运行即可。第一次运行会自动下载MNIST数据集,之后会直接用本地数据。 -
预期结果?
- 训练时:每轮的“平均损失”会逐渐降低(从0.3左右降到0.05以下)。
- 测试后:准确率能达到98%以上(比如98.5%),证明模型能准确识别手写数字。
- 最后会弹出10张手写数字图,每张图标注“真实数字”和“预测数字”,大部分都会预测正确。
-
小白常见问题:
- Q:CPU运行太慢?
A:如果电脑有NVIDIA显卡,先装CUDA(参考PyTorch官网的安装指南),代码会自动用GPU加速。 - Q:准确率不够高?
A:把epochs=5改成10(多训练几轮),或把lr=0.001改成0.0005(调小学习率)。 - Q:某行代码看不懂?
A:重点看注释!比如conv1的参数注释,和前面讲的“卷积核个数、步长、填充”完全对应,结合原理再看代码,很快就能理解。
- Q:CPU运行太慢?
跟着跑一遍代码,再回头看前面的CNN原理,是不是感觉“纸上的知识落地了”?动手实践才是理解深度学习的最好方式~

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)