python面试题收集(持续更新)
B+树索引就是mysql结合B树和索引顺序升级开发的一种平衡搜索树。实际底层实现跟B树没有关系。特点是非叶子节点只存储索引,而叶子结点存储实际的数据。所有叶子结点都是由一个双向链表管理和连接的,数据都是排好序的。因为这些特点,索引B+树适合进行范围查询。答:回表就是使用非聚簇索引搜索时,索引字段不包含搜索所需的字段,那么就要通过主键去查找完整数据的过程。往往会带来随机I/O操作,使得查询慢。
面试题回答
python语法和使用相关
什么是装饰器,怎么使用?
答:装饰器是一个用来增强或修改函数功能的设计模式。他的本质其实还是函数,只不过python为其添加了语法糖,可以通过@decorator来调用装饰器。一般可以用来进行函数执行前或后进行某些操作的执行,比如日志记录,权限认证等。
使用则是声明一个函数,参数是函数,返回值也是一个函数,如下:
def my_decoractor(my_func):
def wrapper():
# 记录日志
my_func()
# 其他操作
return
return wrapper
@my_decoractor()
def my_func():
pass
# 本质跟该用法一样
myfunc = my_decoractor(my_func)
myfunc()
# 当装饰器需要传参,但装饰器函数只接受函数参数时,需要再套一层函数来包装,如下:
def outer(i):
def my_decoractor(my_func):
def wrapper(*args, **kwargs):
if i == 0:
print("参数异常")
else:
my_func()
return wrapper
return my_decorator
@outer(1)
def my_func():
pass
什么是yield
答:yield是python中一种生成器的关键词,它是用于将一个函数变为生成器使用,当调用使用yield的函数时,它不会立刻返回值,而是要等下一次执行时才会返回。可以通过next方法获取生成器的值,for循环中也会自动调用该接口。所以它一般是用于读取大数据。
def func():
yield 1
yield 2
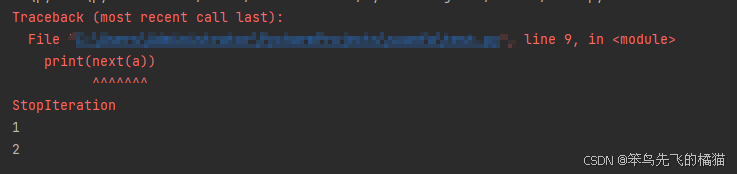
a = func() # 此时执行还不会返回1
print(next(a)) # 1
print(next(a)) # 2
print(next(a)) # StopIteration报错
请你介绍下python的垃圾回收机制
答:垃圾回收机制是python用于内存管理的一个机制,它使使用者无需关心内存。
回答的重点应该是其使用了什么方法来管理不同生存周期的对象
请讲解下什么是python的asynio,有用过吗
asyncio是python3实现的单线程异步变成,用于异步处理I/O操作,提高系统响应。
await:挂起与等待,后面跟着的必须是可等待对象。核心作用是挂起当前协程,将控制权交还给事件循环。
异步方法前要先用async标记其为异步方法
asyncio.run(异步方法):运行异步方法,但一般使用中,用来运行最高层级的入口点 “main()” 函数
基本使用
import asyncio
# 异步方法
async def getServerInfo():
# 模拟查询过程
await asyncio.sleep(0.1)
return {"name":"legend", "id":1}
async def main()
serverInfo = await getServerInfo()
print(serverInfo)
asyncio.run(main()) # 一般用来执行最高层级的main
asyncio.run(getServerInfo()) # 但是也可以单独调用异步方法
使用注意事项,只要使用了await的函数,都要async修饰。否则报错
import asyncio
async def nested():
return 42
def main():
a = await asyncio.run(nested())
print(a)
main()
asyncio.create_task(异步方法):打包为一个 任务,该协程将自动排入日程准备立即运行
多个异步接口需要执行,使用create_task打包成一个任务
import asyncio
async def nested():
print("3284236423")
return 42
async def nested2():
print("478624234")
return [1,2,3,4]
async def main():
task1 = asyncio.create_task(
nested2()
)
task2 = asyncio.create_task(
nested()
)
asyncio.run(main())
结果: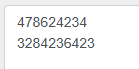
- 如果只是执行create_task,没有用await来接住他返回的值,那么就在执行完函数后就销毁了。
- 而且他们的执行顺序不会因为await获取的时机不一样,而改变。主要是取决于各自谁先执行完
import asyncio
async def nested():
print("3284236423")
return 42
async def nested2():
print("478624234")
return [1,2,3,4]
async def main():
task1 = asyncio.create_task(
nested2()
)
task2 = asyncio.create_task(
nested()
)
t1 = await task2
print(t1)
t2 = await task1
print(t2)
asyncio.run(main())
# 执行耗时不同时
import asyncio
async def nested():
await asyncio.sleep(0.2)
print("3284236423")
return 42
async def nested2():
await asyncio.sleep(0.4)
print("478624234")
return [1,2,3,4]
async def main():
task1 = asyncio.create_task(
nested2()
)
task2 = asyncio.create_task(
nested()
)
t1 = await task2
print(t1)
t2 = await task1
print(t2)
asyncio.run(main())
结果
模拟耗时相同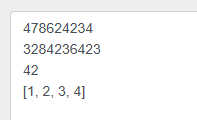
耗时不同
asyncio.gather
批量执行task
事件循环,他是如何管理所有协程
事件循环是单线程调度器,管理所有协程的执行、切换和回调。
每个协程在事件循环中有三种状态:
# 协程状态
PENDING = "pending" # 等待执行
RUNNING = "running" # 正在执行
FINISHED = "finished" # 执行完成
# 事件循环维护一个状态表
{
"task1": {"state": "RUNNING", "result": None},
"task2": {"state": "PENDING", "result": None},
"task3": {"state": "FINISHED", "result": "data"}
}
采用3个队列管理
# 事件循环内部有三个核心队列
class EventLoop:
def __init__(self):
self._ready = deque() # 可执行队列
self._scheduled = [] # 定时队列
self._callbacks = [] # 回调队列
def run_forever(self):
while True:
# 1. 执行所有可执行任务
self._run_ready()
# 2. 处理定时任务
self._process_scheduled()
# 3. 处理I/O事件
self._run_once()
# 4. 如果没有任务,退出
if not self._ready and not self._scheduled:
break
Task和Future的区别
JWT是什么,原理是怎样
JWT是一种用于各方之间传递安全信息的令牌格式。通常会在请求头中发送该jwt,服务器则验证其有效性及用户身份验证。
但是其是无状态,服务器端不保存该令牌。所以常用于分布式系统和微服务架构中。
他主要由三部分构成:
- Header是描述令牌的元数据,通常包含使用的加密算法,令牌类型
- Payload是声明。其中分为私有声明和公有声明。一般jwt的常规设置,比如过期时间、发行者、何时生效等,都是在公有声明中填写,而一些额外数据,则是在私有声明中填写。一般不要把敏感数据放在此处,比如用户密码。
- signature签名,由Header和Payload用指定的加密算法生成的字符串,用以验证JWT的真实性和完整性。确保传输过程中令牌内容没有被篡改。
他的优点是包含了所有必要信息,因此验证时不需要查询数据库;以及它是基于JSON实现的,常见编程语言都支持。
面试你可能问
除了JWT的token外,还有其他登录鉴权的方式吗?
-
session-cookie方式,该方法会在服务端创建一个session会话并将会话id通过Cookie发送给客户端,客户端保存该cookie,后续请求中携带该Cookie即可维持会话状态。但是其弊端是无法在别的服务器中使用,因为该会话只存储在第一次访问的服务器中,所以不适合分布式应用。且如果会话数量较大,也会增加服务器内存的消耗,甚至导致服务器宕机。
-
OAuth2.0认证,它是一种开放授权协议,允许用户在不暴露用户名和密码的情况下,授权第三方访问其受保护的资源,比如支付宝api、微信支付等。优点是用户体验号,避免了多账户管理,安全性高。但缺点是依赖第三方服务,适用性较窄。
从网络角度,用户从输入网址到网页显示,期间发生了什么
首先通过浏览器会解析URL,根据请求信息生成对应的HTTP请求报文。
然后浏览器会检查本地缓存、操作系统缓存中是否有域名对应的ip地址。如果没有,就向配置的DNS服务器发送查询请求,等DNS返回IP地址。
然后使用TCP或UDP封装请求报文为TCP/UDP数据包。然后再封装源ip地址和目标ip地址的IP头部。
接着在IP头部前再封装一层MAC头部。
数据封装好后,通过网卡,将内存中的数据包转换成电信号,通过网线进行传输。
传输过程中经过交换机、路由器,最终到达目标设备。
目标设备接受到数据包后,按照之前数据封装顺序的倒序解包即可获得数据。
可以说下session、cookie、token的区别吗
session是有状态的会话机制,它保存在服务器中。他通过Cookie将session id发给浏览器,浏览器保存该Cookie并在后续请求中携带该cookie。
cookie是一种存储在用户浏览器端的小型数据文件,用于跟踪和保存用户状态信息。
Token是一种无状态的令牌,本质是一串加密字符串。用于身份验证和授权,服务器生成token后发送给客户端保存,后续客户端携带该token即可访问服务器。他和session的区别是,只要是拥有秘钥的服务器,都可以识别token,而session只有存储了session id的服务器才能识别
操作系统
什么是进程和线程
答:进程是资源配置的基本单元,进程之间互相独立,各自拥有自己的内存空间。
线程是CPU调度的基本单元,一个进程里可以开启多个线程。线程间共享进程的内存空间和资源,但是每个线程有自己独立的栈和寄存器。
可能问
他们的区别是什么
答:通信方式不同,进程之间的通信需要通过管道、消息队列、共享内存、套接字等。而同一个进程中的线程因为共享内存空间,因此可以直接读取内存,但是要注意使用同步机制避免数据错误。
请问你还听过协程吗?它是操作系统中存在吗?(或者问讲讲他是什么以及和进程线程有什么区别)
协程是程序员创造出来的,是一种用户态内的上下文切换技术。它能够在单线程内并发执行多个任务。可以成为轻量级线程。它是通过程序控制,而不是通过操作系统调度。通常在特定的点,比如I/O操作进行切换,这使得协程具有非抢占式的特性。它适用于高并发网络应用,比如聊天服务器、游戏等。
python中实现协程的方法有yield,asyncio装饰器(py3.4),async/await关键子(py3.5,主流推荐这个)
项目中因为使用的2.7版本,所以使用yield实现协程
你可以详细讲下async怎么使用吗?
asyncio是Python用于编写并发代码的库,提供了异步I/O、事件循环、协程和任务等功能。
我讲下基础的使用
import asyncio
# 定义协程程序
async def test():
await asyncio.sleep(2)
return 1
async def main():
response = await test()
print(response)
# py3.7之前
# 获取事件循环队列
result = main() # 此时程序还不会执行
loop = asyncio.get_event_loop()
# 加入队列
loop.run_until_complete(result)
#py3.7及之后版本
result = main()
asyncio.run(result)
服务器中断是什么,分别是什么?
指CPU在正常运行程序时,由于内部/外部事件(或由程序)引起CPU中断正在运行的程序,而转到
为中断事件服务的程序中去,服务完毕,再返回执行原程序的这一过程。
可以分为硬中断和软中断:
- 硬中断:由于外部硬件设备,比如例如磁盘、网卡、键盘等设备在检测到某种事件时会向CPU发送中断信号。
- 软中断:由操作系统内核程序触发的,用于处理一些不能被中断的工作或延迟执行的任务。
虚拟地址的意义
- 虚拟内存技术扩大了各自进程的地址空间
- 每个进程运行在各自的虚拟地址空间,互相不干扰对方。虚拟内存为特定的内存地址提供写保护。可以防止代码或数据被恶意篡改
- 内存中可以保留多个进程,当一个进程等待在等待数据读入内存的过程中,可以将cpu资源交给另外一个进程使用,提高并发性
Django
ORM中Meta常用的字段作用
答:
class Meta:
# ---常用
db_table = 'table_name' # 自定义表名
index_together = ('tag1', 'tag2') # 联合索引
unique_together = ('tag3', 'tag4') # 联合唯一索引
verbose_name = 'table_name' # /admin/中显示的表名称
verbose_name_plural = verbose_name #这个选项是指定,模型的复数形式是什么
ordering = 'ordering_tag' # 排序字段
abstract =True # 抽象基类
如果想要了解其他非常用字段,那么可以前往官方文档说明
DateTimeField字段的auto_now_add和auto_now的区别
答:auto_now_add: 当数据被创建时,以当前时间作为默认值写入当前字段
auto_now:当数据被更新时,以当前时间作为值写入当前字段
简述下MVC和MTV模式
答:MVC表示model,view,control三层,分别是 模型、视图和控制器。模型负责业务对象与数据库的映射,视图负责与用户的交互,控制器负责接收用户的输入,调用模型和视图去完成用户的请求。该模式的好处是解决了业务逻辑、数据和界面显示的耦合问题,使得开发和维护更清晰和简单。
MTV模式表示model,template,view,分别是模型,模板,视图,模型也是负责业务对象与数据库的映射,模板使用用于页面渲染,视图是负责处理用户输入的数据,调用模型,并返回数据给模板渲染。该模式的好处也是为了对各组件进行解耦。
Django的生命周期(一个请求在Django中经历了什么流程)
答:
- 一般是用户通过浏览器向服务器发起一个请求,然后通过web服务器封装请求,例如uWsgi
- 接着经过中间件,对请求进行校验或者添加数据
- 通过URL控制器匹配相应的视图函数
- 视图函数进行业务逻辑处理,根据业务需求返回数据或者渲染页面
- 相应中间件对相应的数据进行处理
- wsgi服务器将相应的内容发给浏览器
可能会问:
什么是中间件
答:是用来处理Django请求和响应的钩子。用于在全局范围内改变Django的输入和输出。每个中间件组件都负责做一些特定的功能。
Django中间件常用的方法有哪几个,分别是什么时候调用
中间件常用方法有process_request、process_response、process_exception、process_view、process_template_response。
分别是请求到达视图之前调用、响应数据后调用、视图有异常时调用、路由匹配完成后调用、调用TemplateResponse或者有render属性时调用
详解:
process_request
- 执行顺序:
- 按照配置文件中的中间件从上往下执行
- 每一个请求来的时候都需要经过process_request方法
- 该方法有一个request参数
- 如果某一个中间件使用Response或者HttpResponse之类的函数执行返回逻辑,那么就中断当前请求的执行。比如进行权限验证拦截。
- 如果中间件中没有定义该方法,则跳过检验下一个中间件
- 该方法在每个请求到达视图之前被调用,可以对请求进行预处理。
class AuthenticationMiddleware:
def process_request(self, request):
# 在这里进行身份验证操作
if not request.user.is_authenticated:
# 如果用户未经身份验证,则返回HttpResponse或重定向到登录页面
process_response
- 执行顺序
- 按照注册的中间件从最后往上依次执行
- 该方法必须返回HttpResponse对象
- 默认是response
- 支持自定义,比如登录请求响应时携带token
- 如果中间件中没有定义该方法,则跳过检验下一个中间件
- 它接收一个HttpRequest对象和HttpResponse对象作为参数,并且必须返回一个HttpResponse对象
class CustomResponseMiddleware:
def process_response(self, request, response):
# 在这里对响应进行处理
response['X-Custom-Header'] = 'Custom Value'
return response
process_view
- 路由匹配成功后执行视图函数之前
- 顺序是按照配置文件中注册的中间件从上而下的顺序执行
- 该方法在请求到达视图之前被调用,在视图函数执行前执行。
- 可以在此处进行一些操作
- 如修改请求参数或进行记录等。
- 它接收一个HttpRequest对象和一个视图函数作为参数,并且可以返回一个HttpResponse对象或None。如果返回None,则继续执行后续中间件,否则中断请求
class LoggingMiddleware:
def process_view(self, request, view_func, view_args, view_kwargs):
# 在这里记录日志
logger.info(f"Request received: {request.path}")
# 返回None,继续执行原视图函数
return None
process_exception
- 当视图函数中出现异常的情况下触发
- 顺序是按照配置文件中注册了的中间件从下往上依次经过
- 该方法在视图函数抛出异常时被调用。
- 可以在此处捕获异常并进行处理
- 例如返回一个定制的错误页面或进行日志记录等。
- 它接收一个HttpRequest对象和一个异常对象作为参数,可以返回一个HttpResponse对象来替代原始的异常响应。
class ErrorHandlerMiddleware:
def process_exception(self, request, exception):
# 在这里处理异常
if isinstance(exception, CustomException):
# 如果自定义异常,返回一个定制的错误页面
return render(request, 'error.html', {'error': str(exception)})
else:
# 默认情况,返回一个500服务器错误
return HttpResponseServerError("Internal Server Error")
process_template_response
- 返回的 HttpResponse 对象有 render 属性的时候才会触发
- 顺序是按照配置文件中注册了的中间件从下往上依次经过
- 该方法在视图函数返回一个TemplateResponse对象时调用。
- 可以在此处修改模板响应
- 例如添加全局的上下文数据或进行额外的渲染操作。
- 它接收一个HttpRequest对象和一个TemplateResponse对象作为参数,并且必须返回一个TemplateResponse对象。
class GlobalContextMiddleware:
def process_template_response(self, request, response):
# 在这里添加全局的上下文数据
response.context_data['global_data'] = "Global Value"
return response
简述什么是FBV和CBV
答:FBV是指视图通过函数实现,CBV是指视图通过类实现,类实现本质上也是函数实现。
如果请求简单,可以通过FBV实现,如果请求复杂,比如需要处理GET、POST多种请求格式,那么使用CBV更方便。
from django.shortcuts import render,HttpResponse
# FBV
def user(request):
#处理GET请求
if request.method == 'GET':
return HttpResponse('GET')
# 处理POST请求
if request.method == 'POST':
return HttpResponse('POST')
# CBV
class UserView(View):
def get(self,request,*args, **kwargs):
#获取数据
return HttpResponse('GET')
def post(self,request,*args, **kwargs):
#创建数据
return HttpResponse('POST')
def put(self,request,*args, **kwargs):
#更新全部数据
return HttpResponse('put')
def delete(self,request,*args, **kwargs):
#删除数据
return HttpResponse('delete')
def patch(self,request,*args, **kwargs):
#更新局部数据,例如:用户信息的name这样的某几列
return HttpResponse('patch')
可能会问:
你能讲讲为什么说CBV本质也是函数呢?
类实现在url匹配器中的调用是通过as_view()接口,通过阅读源码,as_view实际执行了dispatch,会对request对象进行封装,然后在其内部定制一些功能,比如权限认证、根据请求类型调用不同方法执行等。最后返回dispatch。
请解释一下 QuerySet 的特性,以及如何优化 QuerySet 的性能?
特性:
- 惰性加载: QuerySet 的执行是惰性的,只有在真正需要数据时才会去查询数据库。
- 链式调用: 可以对 QuerySet 进行链式调用,组合多个过滤条件。
- 缓存机制: 第一次遍历 QuerySet 时,Django 会缓存查询结果,后续遍历会直接使用。
- 缓存。
优化方法:
- 使用 values() 或 values_list() 指定需要的字段,避免查询不必要的字段。
- 使用 filter()、exclude() 等方法尽早过滤数据。
使用 iterator() 处理大量数据,避免一次性加载所有数据到内存。 - 避免在循环中执行数据库查询。
- 使用 count()、exists() 等方法代替 len(queryset) 和 if queryset。
跨域请求如何处理
答:
浏览器有一个同源策略,即不允许不同源(同协议、同域名、同端口)的url相互访问,目的是为了保证用户信息的安全,防止恶意网站窃取数据。
但这对实际应用场景来说带来了一些不便,比如访问同一个网站的不同端口的数据时,会被拦截。
Django则提供了组件来完成该任务,django-cors-headers,他会在允许访问的网址http头中添加允许访问的字段,如下: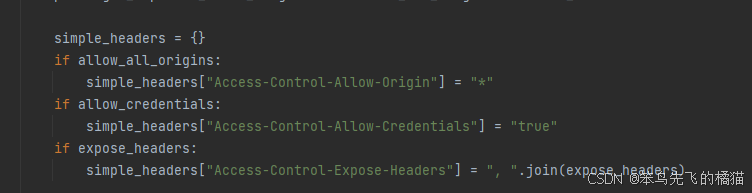
可能会问
Django如何防止csrf攻击
答:csrf攻击是指攻击者通过伪造来源网站发起请求,达到非法目的。
Django内置了CSRF保护机制,通过在视图函数中添加@csrf_protect装饰器或在表单中添加{% csrf_token %}来确保请求是合法的用户操作。它的实现机制如下:
- django第一次响应来自某个客户端的请求时,后端随机产生一个token值,把这个token保存在SESSION状态中;同时,后端把这个token放到cookie中交给前端页面;
- 下次前端需要发起请求(比如发帖)的时候把这个token值加入到请求数据或者头信息中,一起传给后端;Cookies:{csrftoken:xxxxx}
- 后端校验前端请求带过来的token和SESSION里的token是否一致;
请问你了解分布式系统下,跨域问题可以怎么解决吗?
我开发的项目基本上都是公司内部系统,基本上没有分布式场景的应用,但是我也研究过该情况下怎么处理。可以通过以下方式解决:
- 配置nginx将所有机器的流量代理到统一域名,然后在nginx中进行分发
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#gzip on;
# 配置第一个代理规则
# 域名: example1.cn
# 监听端口: 8081
server {
listen 8081;
server_name example1.cn;
location / {
proxy_pass http://127.0.0.1:8080;
}
}
# 配置第二个代理规则
# 域名: example2.cn
# 监听端口: 8081, 端口与第一个规则相同
server {
listen 8081;
server_name example2.cn;
location / {
proxy_pass http://127.0.0.1:9000;
}
}
}
- 使用redis缓存token,统一域名下的访问都到redis中获取token验证是否一致。
请问什么是celery,怎么接入Django使用?
答:celery是一个分布式异步任务队列框架,用于将耗时的任务从主程序分离,实现异步执行、定时任务调度和分布式计算。一般用它实现
- 定时任务
- 异步任务
它是由Broker任务队列、Worker工作队列、Backend结果队列组成。客户端调用celery相关接口后,会将任务加入到Broker中,然后Worker会定时读取Broker中的任务,然后执行任务,最后将结果放到BackEnd中存储,客户端去BackEnd获取结果。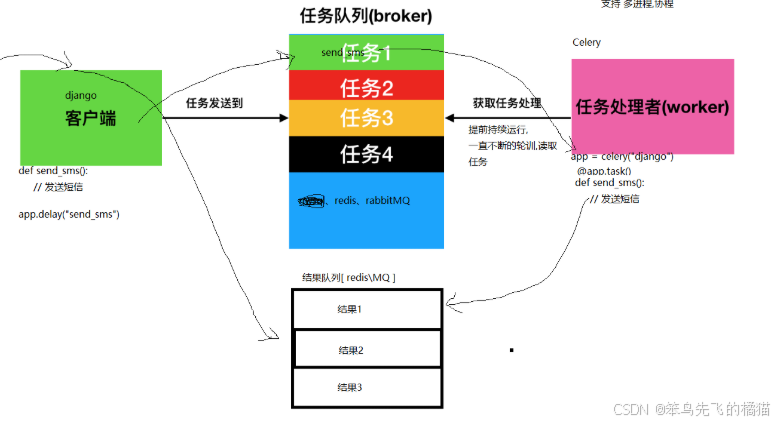
Django接入使用就需要先pip安装celery插件,然后在Django项目的主应用目录下创建celery入口程序,在里面配置celery的设置参数(包括broker、backend使用的组件、最多执行任务数量、任务结果输出格式)和发现项目中的任务,想要celery主动检测出项目目录中的celery任务,,需要使用celery的子应用下都要创建task.py文件。
最后在主应用下初始化celery即可。后续编写异步任务,执行要使用share_task装饰函数,然后再调用异步函数的地方使用delay执行。
celery进阶使用(待补充)
supervisor:后台执行
flower:监控执行过程
Django项目如何生成第三方库列表供他人部署项目时安装
1.在当前项目文件根目录下生成requirements.txt文件pip freeze > requirements.txt
2.执行requirements.txt文件pip install -r requirements.txt
如何优化Django的数据库查询性能
-
使用select_related/prefetch_related减少查询次数。
-
避免在循环中查询(N+1问题)。
-
利用only()/defer()限制字段加载。
-
对高频查询字段添加数据库索引(db_index=True)。
-
使用annotate()和aggregate()聚合数据替代Python计算。
Django的缓存机制
-
内存缓存:如Memcached。
-
文件缓存:缓存数据到文件系统。
-
数据库缓存:使用数据库表存储缓存。
-
Redis缓存(推荐):通过django-redis库集成。
Flask
什么是Flask
答:flask是一个轻量级、灵活、扩展性强的web框架。他只提供简单的功能,如路由,请求和响应,模板渲染。它是用Jinja2模板引擎。他可以通过第三方插件来扩展功能,例如flask-sqlalchemy扩展orm。适合快速开发功能较少的小型系统。
可能会问:
和Django的区别
Django是一个功能更完善、体量更大的web框架。它相比flask提供更全面的功能,但也没有flask那么灵活。比如因为Django自带ORM,如果希望使用NoSQL数据库,比如mongodb,虽然也能用,但是等于自废Django的ORM。那么这种情况,个人感觉使用flask更灵活。
flask的生命周期
客户端—>wsgi应用程序->全局钩子–> 路由 --> 视图 --> 路由—> 全局钩子 —> wsgi应用程序—> 客户端
Flask中的蓝图(Blueprints)是什么?它们有什么作用?
蓝图是flask用来帮助你把一个大项目拆分成多个小模块,方便管理和维护。承担url和视图之间绑定关系的临时容器。
可能会问
运行机制
- 在视图函数被蓝图的add_url_rule方法注册时,这个操作本质就是将视图和url地址的映射关系添加到蓝图的子路由列表deferred_functions中。
- 蓝图对象根本没有路由表,当我们在蓝图中的视图函数上调用route装饰器(或者add_url_role函数)注册路由时,它只是在蓝图对象的内部的deferred_functions(子路由列表)中添加了一个路由项(路由项实际上就是一个绑定了视图和url地址的lambda匿名函数)
- 当执行app.register_blueprint()注册蓝图时,app应用实例对象会将从蓝图对象的 deferred_functions列表中循环取出每一个之前注册的路由项,并把app应用实例对象自己作为参数执行路由项对应的lambda匿名函数,lambda匿名函数执行以后就会调用app.add_url_rule() 方法,这就将蓝图下子路由列表之前暂存的路由全部添加到了app应用实例对象的url_map总路由表中了,所以用户就可以在flask中访问到了蓝图中的视图。当然,能访问蓝图下的视图,自然也就可以通过视图调用其他的功能,例如:蓝图下的其他功能函数或其他的模型对象了
源码流程
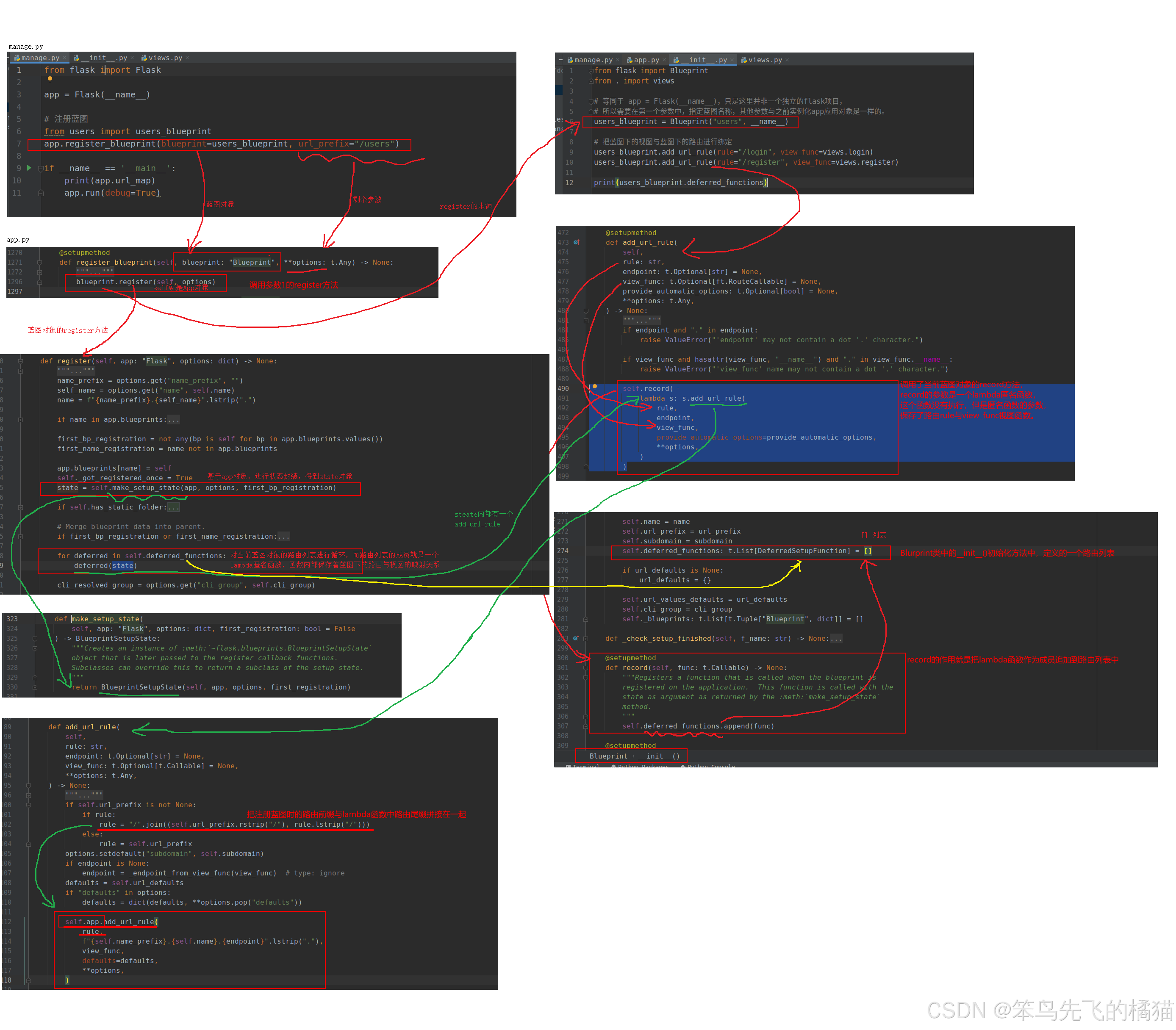
Flask常用扩展库有哪些?
答:常用的扩展库有这些:
- SQLAlchemy:用于ORM,对数据库进行操作
- flask-Migrate:进行数据迁移
- flask-WTF:处理表单数据
- flask-login:用户认证
- flask-mail:邮箱发送
ORM
WebSocket
可以简述下flask的上下文是什么吗?怎么使用?
答:flask上下文是用来管理请求和应用的状态。他分为请求上下文和应用上下文。
请求上下文是用来获取请求的相关数据,比如请求方式,请求地址,cookie等。在flask中就是使用request来保存http请求的数据,而使用session来管理会话的数据。这里有一点比较特别的,就是这两个对象只会创建一次,不会因为客户端不同的请求而创建多个对象。
应用上下文current_app则是存储flask应用实例对象的变量,可以用它来获取当前应用的配置文件current_app.config、连接什么数据库、当前flask应用在什么机器,用什么ip,内存有多大。
request只能在请求视图中使用
from flask import Flask, request, session, current_app, g
app = Flask(__name__)
app.config["SECRET\_KEY"] = "my secret key"
def test():
print(request) # 请求上下文所提供的对象[request或session]只能被视图直接或间接调用!
@app.route("/")
def index():
print(request)
print(session)
#外部函数在视图函数里面调用,也能使用request或session
test()
return "ok"
# 声明和加载配置
class Config(object):
DEBUG = True
app.config.from_object(Config)
# 编写路由视图
@app.route(rule='/index1')
def index1():
#打印应用上下文对象
print("应用上下文对象:",app)
#判断我们设置的app与falsk内置的current\_app是否相同
print(app == current_app) #True
# 应用上下文提供给我们使用的变量,也是只能在视图或者被视图调用的地方进行使用,
# 但是应用上下文的所有数据来源于于app,每个视图中的应用上下文基本一样
print(current_app.config) # 获取当前项目的所有配置信息
print(current_app.url_map) # 获取当前项目的所有路由信息
return "<h1>hello world!</h1>"
if __name__ == '\_\_main\_\_':
# print(request) # 没有发生客户端请求时,调用request会超出请求上下文的使用范围!
app.run(host="0.0.0.0", port=5000, debug=True)
flask如何处理报错或异常(主要问是怎么处理http异常)
答:使用装饰器app.errorhandler装饰异常处理函数,向装饰器传入报错或异常的状态码,然后可以在异常处理函数中定制http异常发生之后进行的操作,比如跳转页面。
@app.errorhandler(404)
def not_found_error(error):
return 'This page does not exist', 404
可能会问:
flask是否可以主动抛http异常的方法
abort(状态码)
flask如何在请求前后执行一些操作呢?
答:flask可以使用请求全局钩子实现,它类似Django中的中间件,常用的钩子函数有:
- before_first_request
- 在处理第一个请求前执行[项目刚运行第一次被客户端请求时执行的钩子]
- before_request
- 在每一次请求前执行[项目运行后,每一次接收到客户端的request请求都会执行一次]
- 如果在某修饰的函数中返回了一个响应,视图函数将不再被调用
- after_request
- 如果没有抛出错误,在每次请求后执行
- 接受一个参数:视图函数作出的响应
- 在此函数中可以对响应值在返回之前做最后一步修改处理
- 需要将参数中的响应在此参数中进行返回
- teardown_request:
- 在每一次请求后执行
- 接受一个参数:错误信息,如果有相关错误抛出
- 需要设置flask的配置DEBUG=False,teardown_request才会接受到异常对象。
当多个不同实际的钩子存在,他们的执行顺序是以视图执行为中心点,before_request之前(请求过程)的先装饰先执行,after_request之后(响应过程),后装饰的先执行。
from flask import Flask, session
# 应用实例对象
app = Flask(__name__)
"""给app单独设置配置项"""
# 设置秘钥
app.config["SECRET_KEY"] = "my SECRET KEY"
@app.before_first_request
def before_first_request():
"""
这个钩子会在项目启动后第一次被用户访问时执行
可以编写一些初始化项目的代码,例如,数据库初始化,加载一些可以延后引入的全局配置
"""
print("----before_first_request----")
print("系统初始化的时候,执行这个钩子方法")
print("会在接收到第一个客户端请求时,执行这里的代码")
@app.before_request
def before_request():
"""
这个钩子会在每次客户端访问视图的时候执行
# 可以在请求之前进行用户的身份识别,以及对于本次访问的用户权限等进行判断。..
"""
print("----before_request----")
print("每一次接收到客户端请求时,执行这个钩子方法")
print("一般可以用来判断权限,或者转换路由参数或者预处理客户端请求的数据")
@app.after_request
def after_request(response):
print("----after_request----")
print("在处理请求以后,执行这个钩子方法")
print("一般可以用于记录会员/管理员的操作历史,浏览历史,清理收尾的工作")
response.headers["Content-Type"] = "application/json"
response.headers["Company"] = "python.Edu..."
# 必须返回response参数
return response
@app.teardown_request
def teardown_request(exc):
print("----teardown_request----")
print("在每一次请求以后,执行这个钩子方法")
print("如果有异常错误,则会传递错误异常对象到当前方法的参数中")
# 在项目关闭了DEBUG模式以后,则异常信息就会被传递到exc中,我们可以记录异常信息到日志文件中
print(f"错误提示:{exc}") # 异常提示
@app.route("/")
def index():
print("-----------视图函数执行了---------------")
return "ok"
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=False)
如何在Flask中实现跨域请求(CORS)?
答:使用flask-cors扩展来处理跨域请求。然后在项目app初始化,使用CORS封装app
from flask_cors import CORS
from flask import Flask
app = Flask(__name__)
CORS(app)
如何在Flask中处理后台任务?
答:可以使用Celery来处理后台任务。项目中引入celery,然后配置好celery的broker的url和存储结果的队列的url,在初始化项目实例对象处初始化
from celery import Celery
def make_celery(app):
celery = Celery(
app.import_name,
backend=app.config['CELERY_RESULT_BACKEND'],
broker=app.config['CELERY_BROKER_URL']
)
celery.conf.update(app.config)
return celery
app.config.update(
CELERY_BROKER_URL='redis://localhost:6379/0',
CELERY_RESULT_BACKEND='redis://localhost:6379/0'
)
celery = make_celery(app)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)