Yolov8 姿态估计
每个关键点由x,y,v组成,v代表该点是否可见。
原文:Yolov8 姿态估计 - 知乎 (zhihu.com)
YOLOv8论文还没有,官方默默又加了新模型:姿态估计。
现在你可以用YOLOv8做目标检测、实例分割、图像分类、目标跟踪、姿态估计,未完待续。。。。。。
一、Yolov8姿态估计
Yolov8的姿态估计模型是在COCO数据集训练的,目前支持的是人体的检测和姿态估计。
测试一下:
yolo pose predict model=yolov8n-pose.pt source='bus.jpg' show=True save=True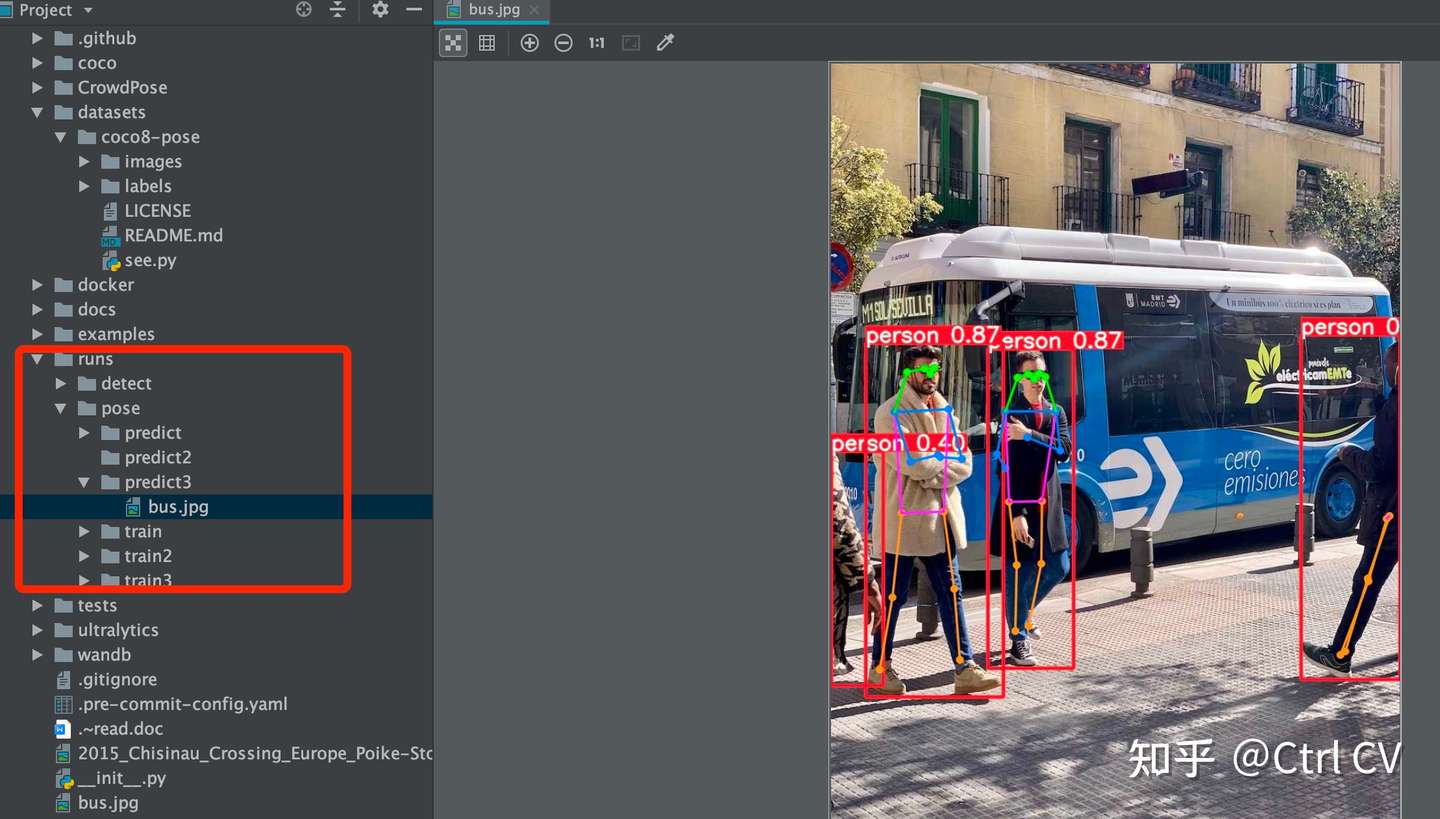
其中pose指定任务类型,predict代表我们是要做推断,模型这里我选择的是最轻量级的YOLOv8n-pose,”show=True save=True“代表显示并保存。运行的话,程序会自动下载需要的模型。
如果要用YOLOv8调用摄像头的话,命令如下:
yolo pose predict model=yolov8n-pose.pt source=0 show=True save=True视频的话同理,只需将source=0 改为视频的路径即可。下面看一下效果:
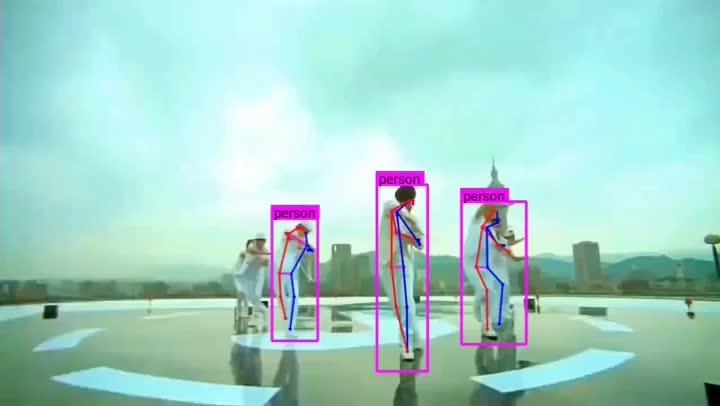
00:30
二、模型训练:
按照coco128-pose.yaml的"样例"组织好数据并修改coco128-pose.yaml后,你只需要一句命令即可开始训练:
yolo pose train data=coco128-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640查看下coco128-pose.yaml文件
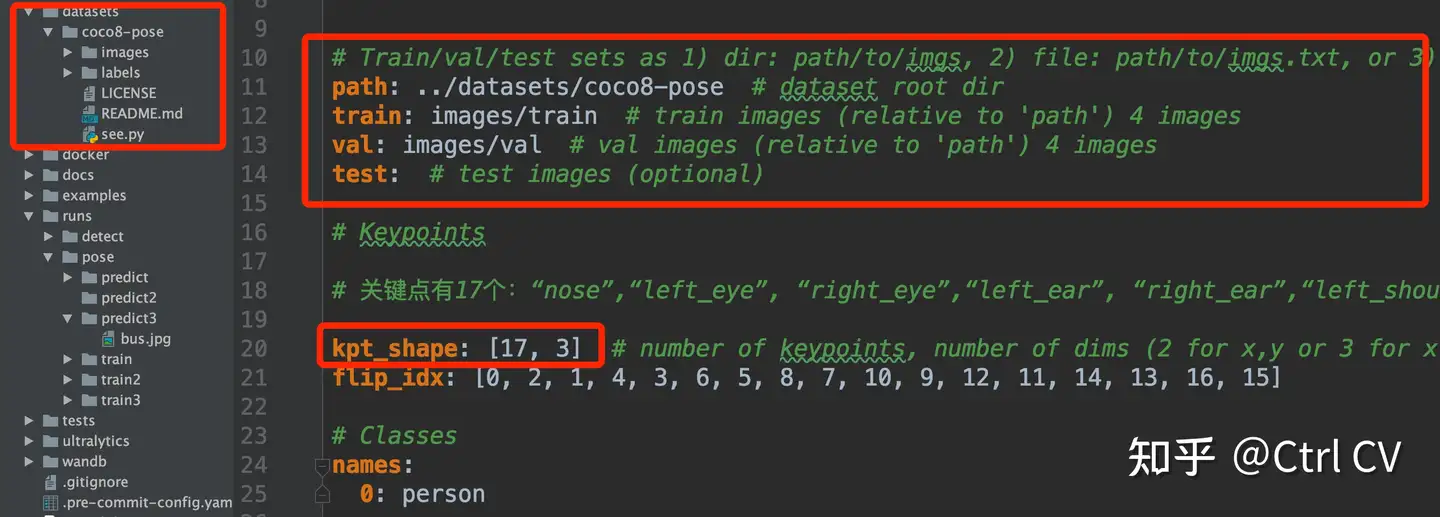
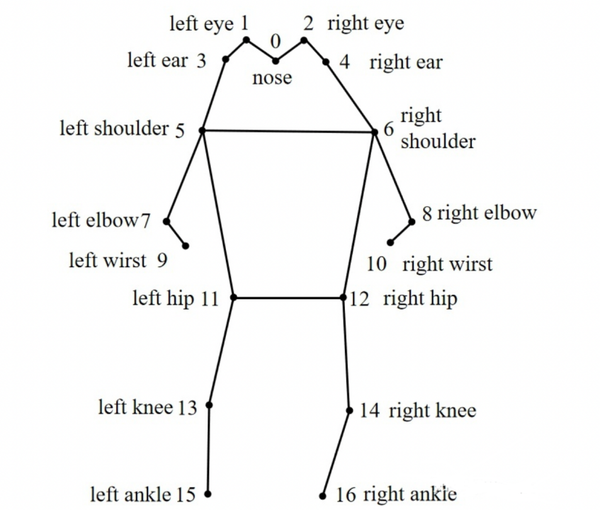
COCO的annotation一共有17个关节点。
分别是:“nose”,“left_eye”, “right_eye”,“left_ear”, “right_ear”,“left_shoulder”, “right_shoulder”,“left_elbow”, “right_elbow”,“left_wrist”, “right_wrist”,“left_hip”, “right_hip”,“left_knee”, “right_knee”,“left_ankle”, “right_ankle”。示例图如下:
查看yolo格式的数据
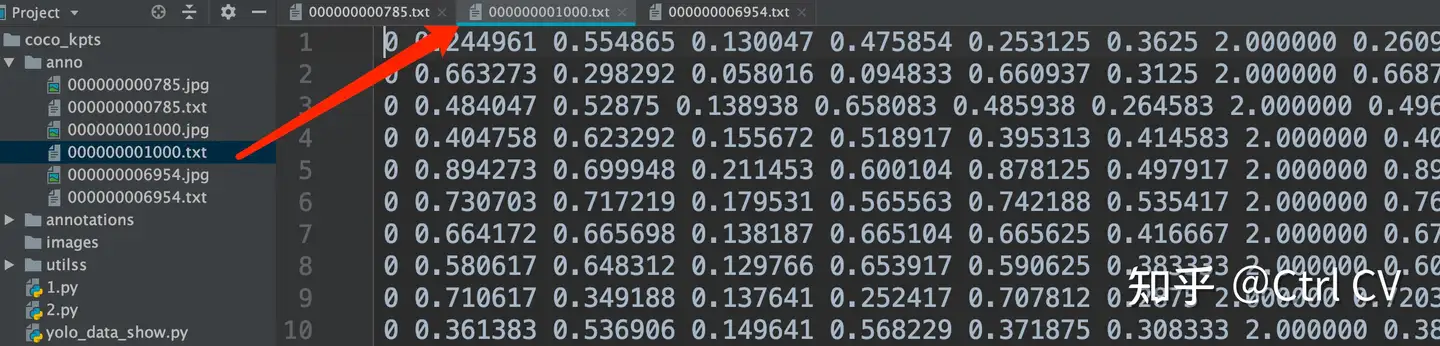
可以看到所有坐标数据都压缩了。
每组标签首位是0,代表人类类别,这里只有person一个类别。往后数4位是边界框坐标,再往后面的17*3位是关键点信息。每个关键点由x,y,v组成,v代表该点是否可见。
一组标注信息共(1+4+17*3)=56个数字。即每一行都有56个数字标注。
通过代码简单绘制一下标注信息:
import torch
from utilss.plots import colors, plot_one_box
import cv2
from utilss.general import xywh2xyxy
# 思路
# 将box框的xywh格式转化为xyxy格式并乘上相对应的宽高
# 将kpts姿态数据乘对应的宽高
# 姿态数据中,每3位有一个2,这个是官方coco annotator标注软件会自动插入的值,在yolopose算法detect检测中,该值被定义为每一个关键点的置信度conf
if __name__ == '__main__':
# 将yolo格式的标注好的图片展示出来
# im0 = cv2.imread("anno/000000000785.jpg")
im0 = cv2.imread("anno/000000006954.jpg")
# f = open("anno/000000000785.txt", "r")
f = open("anno/000000006954.txt", "r")
det_list = []
for line in f.readlines():
# line = line.strip('\n') #去掉列表中每一个元素的换行符
det_list = list(map(float, line.split(' ')))
print(det_list)
f.close()
# 前5个参数为 0类型 xyxy
xywh = det_list[1:5]
# 转化为 xyxy格式
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]]
xyxy = (xywh2xyxy(torch.tensor(xywh).view(1, 4)) * gn).view(-1).tolist()
print(xyxy)
# 后51个参数为 姿态数据 官方的是百分比表示法,需要乘宽高
kpts = det_list[5:]
# 640
weight = im0.shape[1]
# 425
height = im0.shape[0]
for index, i in enumerate(kpts):
if index % 3 == 0:
kpts[index] = kpts[index] * weight
if index % 3 == 1:
kpts[index] = kpts[index] * height
if index % 3 == 2:
kpts[index] = 0.9
# 画框打点
plot_one_box(xyxy, im0, label="person", color=colors(0, True), line_thickness=3,
kpt_label=True, kpts=kpts, steps=3, orig_shape=im0.shape[:2])
cv2.imshow("demo", im0)
cv2.waitKey(0) # 1 millisecond


三、训练自己的数据
数据准备,数据标注,参考如下文章:
最后将我们标注好coco格式的数据转为 yolo格式,参考如下
至此,我们的数据已经准备完成,开始训练
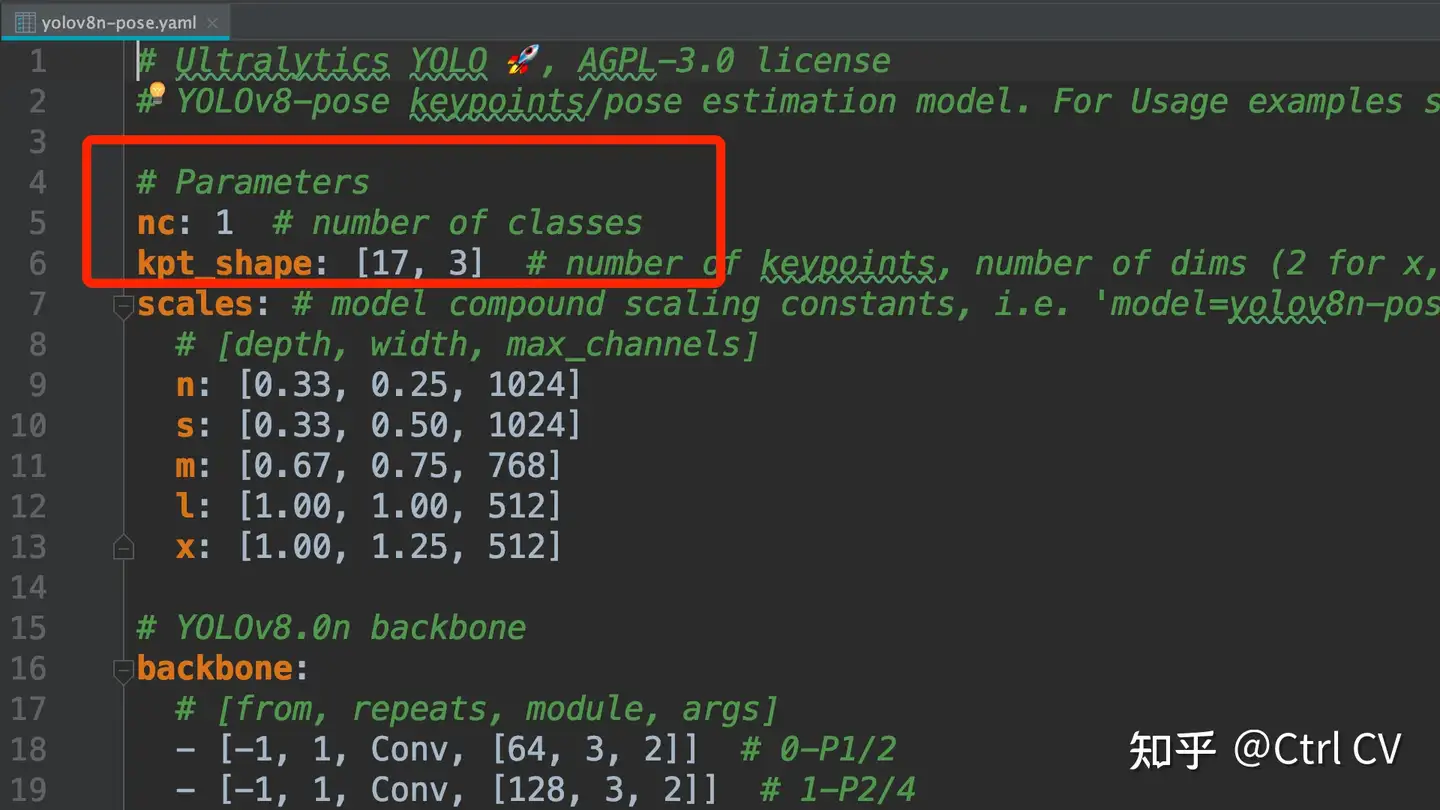
模型配置文件yolov8n-pose.yaml
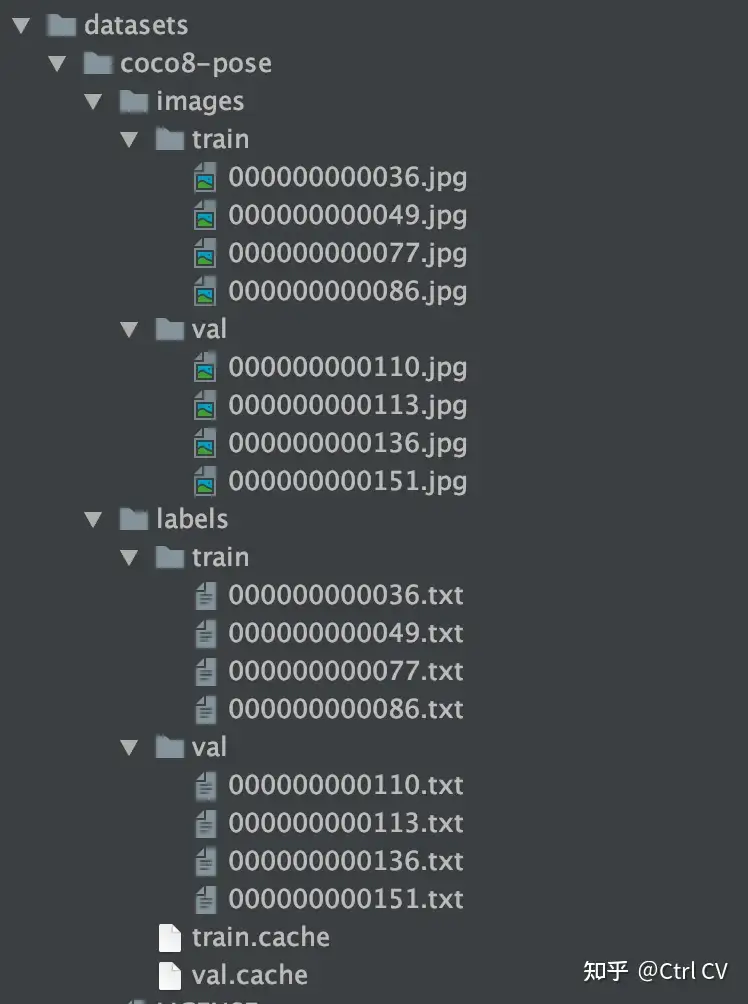
数据配置文件coco8-pose.yaml, 参考上述。
四、总结
YOLOv8的功能越来越多,而且相比于其他开源库,对于工业界来说更友好,涵盖训练、评估、推断、部署全流程,是快速进行项目开发的首选。cv界的全家桶yolov8一直在完善。
下一个集成到yolov8的模型会是什么呢?

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)