卷积神经网络(CNN)
介绍了卷积神经网络各层的设计、卷积的概念、卷积神经网络反向传播的计算步骤以及使用pytorch实现卷积神经网络的代码。
CNN(卷积神经网络)
引言
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它由若干卷积层和池化层组成,尤其在图像处理方面CNN的表现十分出色。卷积神经网络种有一个感受野的概念。感受野(Receptive Field) 是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。
1989年,LeCun结合反向传播算法与权值共享的卷积神经层发明了卷积神经网络,并首次将卷积神经网络成功应用到美国邮局的手写字符识别系统中。1998年,LeCun提出了卷积神经网络的经典网络模型LeNet-5,并再次提高手写字符识别的正确率(Gradient-based learning applied to document recognition)。CNN的基本结构由输入层、卷积层(convolutional layer)、池化层(pooling layer,也称为取样层)、全连接层及输出层构成。卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。由于卷积层中输出特征图的每个神经元与其输入进行局部连接,并通过对应的连接权值与局部输入进行加权求和再加上偏置值,得到该神经元输入值,该过程等同于卷积过程,CNN也由此而得名。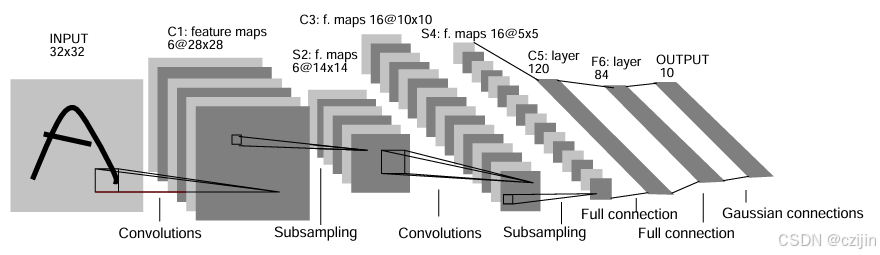
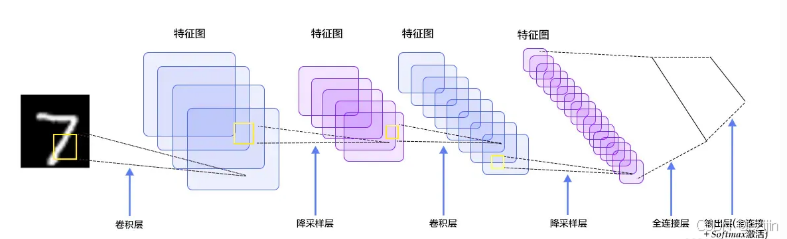
输入层用于输入图像信息,卷积层用于提取图像底层特征,池化层用于防止过拟合以及降维,全连接层用于汇总卷积层和池化层得到的信息,输出层根据全连接层的信息输出概率最大的结果。
因此本文全部内容分为:引言、背景(卷积的介绍)、输入层、卷积层、池化层、全连接层、输出层、理论分析、总结以及代码。
背景
首先我们来介绍一下为什么会出现卷积神经网络,顾名思义,相比于神经网络,卷积神经网络多了一个卷积的概念。引言中提到,CNN在图像处理方面表现很好,那么在卷积神经网络出现之前,对于图像处理的方法具有哪些缺陷呢?首先研究人员需要手工提取图片特征,然后输入到神经网络全连接层,从而进行图像处理,而手工设计的特征往往只能捕捉到图像的某些特定方面的信息,特征表示能力有限。其次对于图像的变换适应性弱,影响影响图像识别的准确性。
其次我们来介绍一下卷积的概念(可以观看B站王木头的视频从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变——B站王木头)
对于两个函数 f ( x ) f(x) f(x)和 g ( x ) g(x) g(x),卷积可以表示为:
∫ − ∞ ∞ f ( τ ) g ( x − τ ) d τ \int_{-\infty}^{\infty}f(\tau)g(x-\tau)d\tau ∫−∞∞f(τ)g(x−τ)dτ
用一个例子来帮助理解什么是卷积:
我们假设 f f f表示吃进去食物,用 g g g函数表示食物消化后剩多少(比例),那么我们就可以进行计算。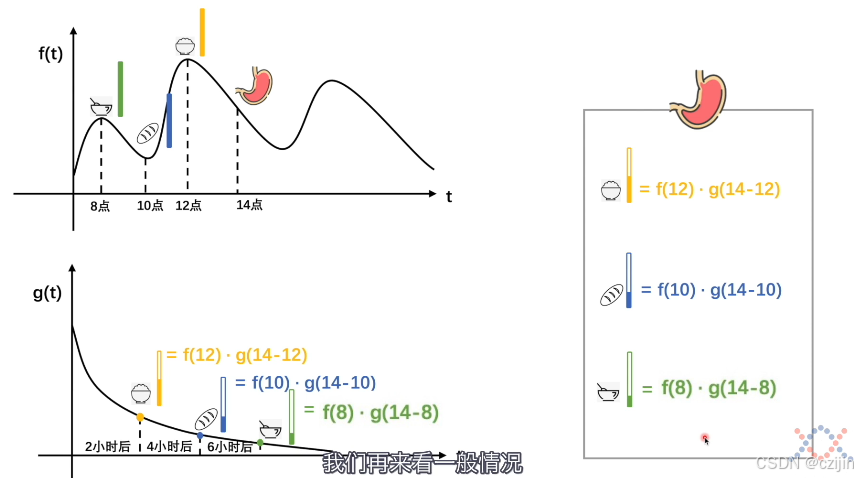
比如上图中,8点吃进去了豆腐脑,10点吃进去了面包,12点吃进去了米饭,那么到14点胃里还剩下多少,就可以用图中右侧的方法来计算,米饭是12时吃进去的,表示为 f ( 12 ) f(12) f(12),同理其他食物分别表示为 f ( 10 ) f(10) f(10)、 f ( 8 ) f(8) f(8),由于进食和消化量一直都在边化(消化速率和吃进去的食物是无关的,因为最后会全部消化完),所以要计算胃中剩下的食物比较麻烦,但是利用卷积可以轻松解决。当12点吃入米饭,到14点(两个小时候),剩余比例就是g(14-12),那么剩余量就是 f ( 12 ) ∗ g ( 14 − 12 ) f(12)*g(14-12) f(12)∗g(14−12),其他同理。
推广到一般情况,从x时刻吃,到t时刻剩下多少,那么计算t到x时刻吃的食物经过时间(t-x),然后用x时刻进食量乘上t-x后对应的剩余比例。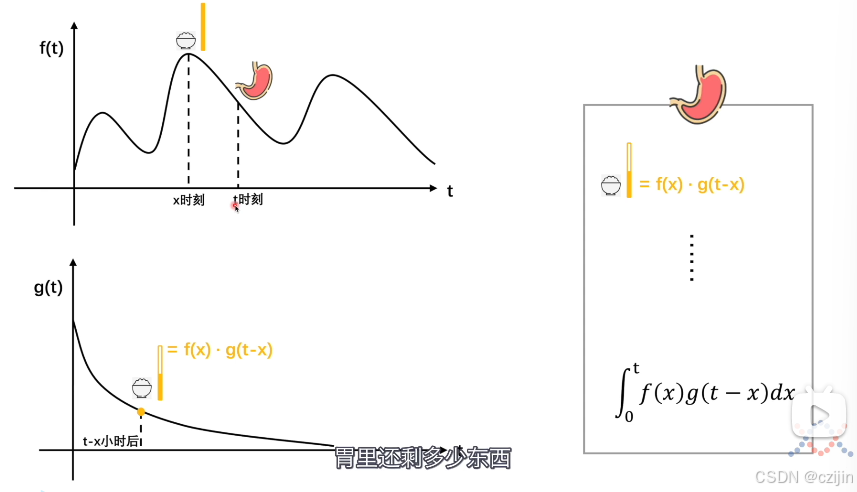
这只是某个时刻进食后的情况,我们需要把前面所有时刻累加起来,最后求得t时刻胃里食物剩余量。最后可以转化为一个积分过程。
判断卷积的一个重要指标:f函数和g函数中自变量相加是否能够消去一个未知数,比如f(x)和g(t-x)可以消去未知数x。
接下来我们看看 τ \tau τ和 x − τ x-\tau x−τ在图像上的对应情况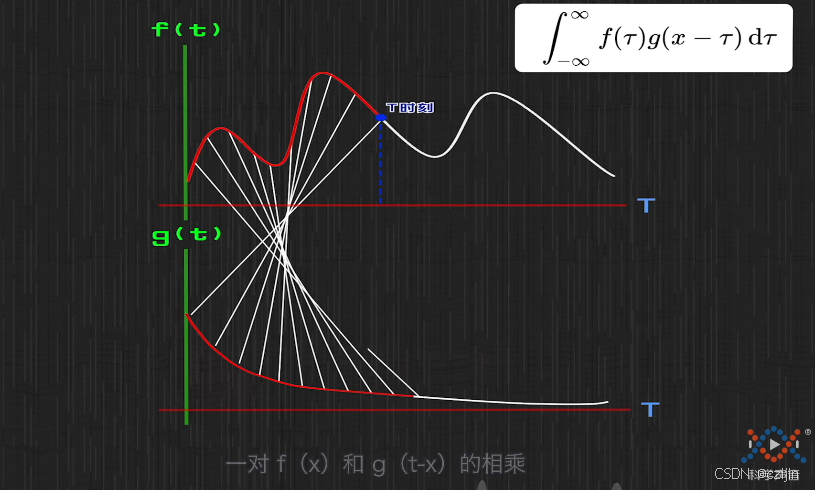
τ \tau τ时刻刚吃下去食物,此时还未开始消化,所以在g图像上就对应横坐标为0的点(即 τ − τ = 0 \tau - \tau = 0 τ−τ=0) τ \tau τ时刻前的对应每一种食物在 τ \tau τ时刻的剩余比例都是可以用直线一一对应。图中每一条直线都可以看成一对 f ( x ) ∗ g ( τ − x ) f(x)*g(\tau - x) f(x)∗g(τ−x),最后我们把所有直线相加,就是胃里食物的总剩余量。此时就有一个相加积分公式 ∫ 0 τ f ( x ) g ( τ − x ) d x \int_0^{\tau} f(x)g(\tau-x)dx ∫0τf(x)g(τ−x)dx,只需要替换上下限和变量就有卷积公式了。
因此我们可以找一个系统,这个系统的输入(f(x))是一个不稳定的输入(因为一直不间断吃东西,始终在变化),输出是一个稳定的输出(因为g函数对于任何食物都是稳定的,随着时间变化,以同样比率消化食物)。通过卷积就可以计算这个系统的存量(即胃里剩余的食物)。这也就是卷积的一个价值所在。
卷积的“卷”:我们讲上面的图,也就是g(x)进行一个翻转,可以得到下面的图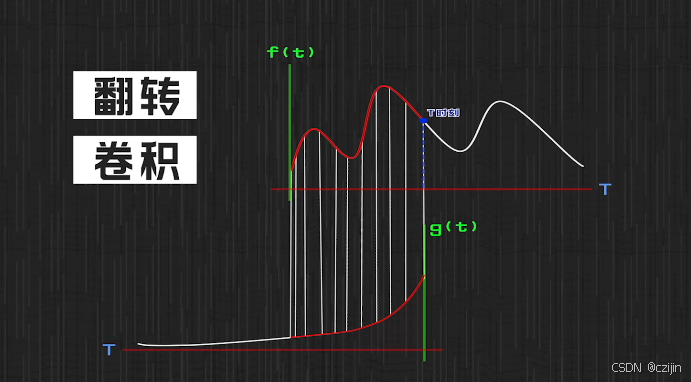
那么就可以体现出一一对应了(类似的图还有B站UP梗直哥用火车穿山洞对于卷积的讲解)。那么卷积看上去就是把一一对应的直线卷曲变成了之前的那张图。
我们将上面的卷积解释带入到对图像处理的应用场景中,那么就无法进行理解,找不出不稳定的输入和稳定输出。
对于图像卷积的操作如下图,通过一个3x3的卷积核,获得特征图。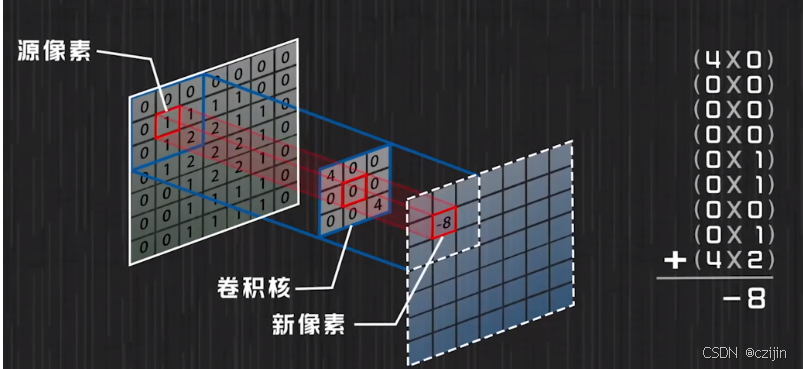
图像原本的像素点先和对应的卷积核相乘后再相加,即可得到对应新的像素点,用卷积核把整个图像都扫一遍,得到的就是卷积操作后的新图像。
此时有一个存在问题的地方,就是每次扫描时,中间的数据会被反复扫描,但是外圈只会被扫到一次,那么外层特征就可能会丢失,此时可以通过添加padding(一般设置为0)来保证外层特征被扫描到。

但是上述与卷积的关系中,f函数和g函数的判断如何进行呢?图像的卷积似乎就是感受野中的图片和卷积核相乘,再进行相加,那么就和卷积公式 ∫ − ∞ ∞ f ( τ ) g ( x − τ ) d τ \int_{-\infty}^{\infty}f(\tau)g(x-\tau)d\tau ∫−∞∞f(τ)g(x−τ)dτ类似了。因此图像就是一个f函数,卷积核就是一个g函数(图像总是变化的,是不稳定输入,卷积核是不变的,是稳定输出)。
我们将吃饭的例子换成蝴蝶效应,在某时刻蝴蝶震动翅膀,后续某个时刻就发生了飓风,但是发生飓风的概率是随着时间减小的,所以可以表示为下图: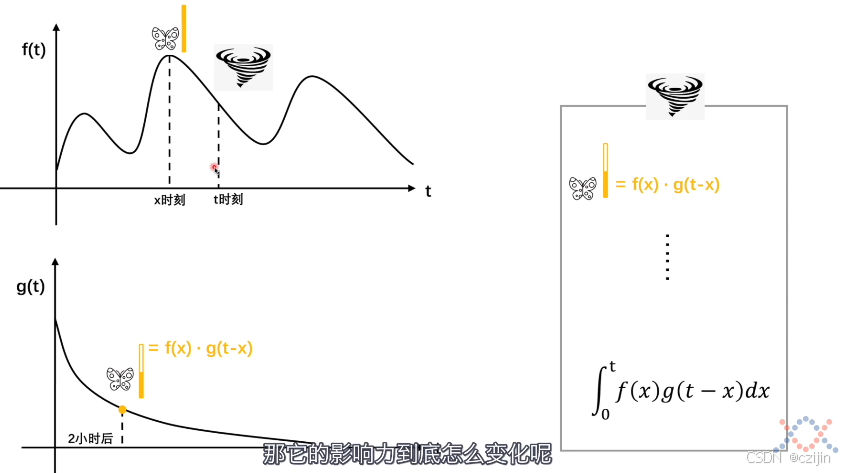
那么此时的卷积就表示之前蝴蝶扇动翅膀对飓风发生的影响。那么卷积就又可以总结为众多事件对某时刻发生的事件的影响值
类比到图像上的卷积,我们就可以看成,计算周围像素点对于某个像素点的影响。
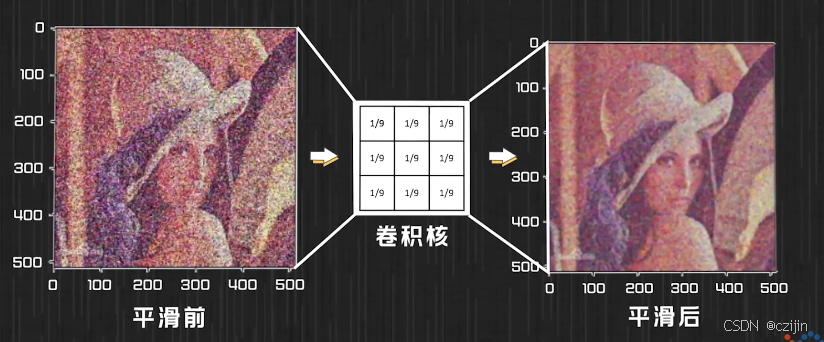
我们用一个3 * 3的卷积核,每个数值都为1/9,来进行卷积,那么表示的意义就是找一个像素点,把它周围的像素点全部加起来,然后求平均,这样子对图像进行卷积后,图像就会变得更加平滑。因此又叫平滑卷积。平滑卷积使得周围像素点与当前像素点相差不要太多,因此就是求平均。类似的还有5×5的卷积核以及7×7的卷积核,也就是周围两圈像素点和三圈像素点对当前像素点产生的影响。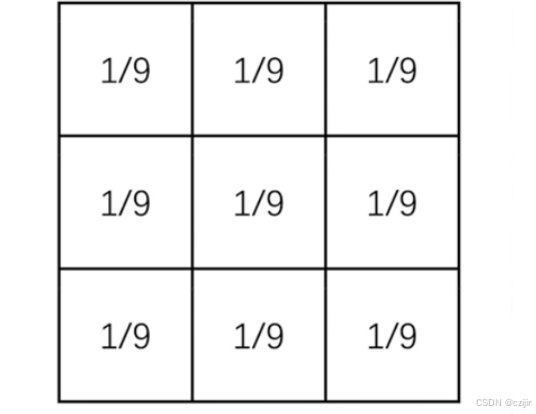
现在只考虑点(x,y) 周围像素点对当前像素点的影响: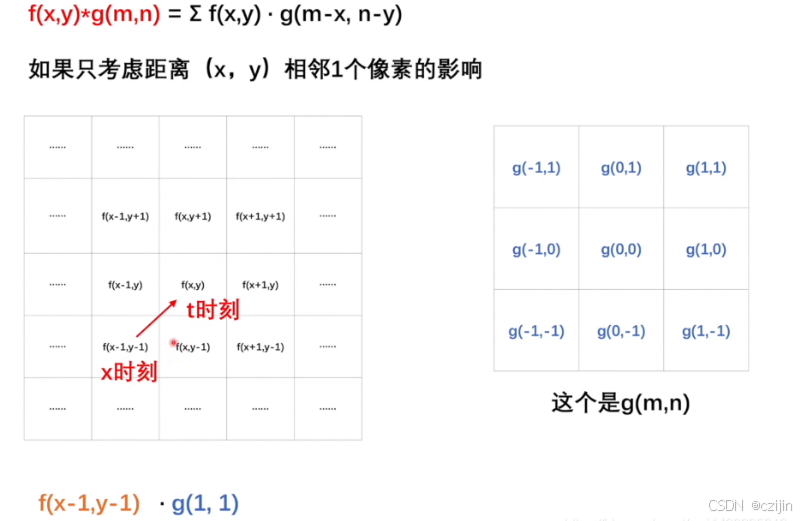
我们找到(x-1,y-1)像素点的像素值f(x-1,y-1)然后乘上影响比例g(),就能得到影响值。
我们使用之前吃饭例子中的 g ( τ − x ) g(\tau - x) g(τ−x),那么就有下图的对应: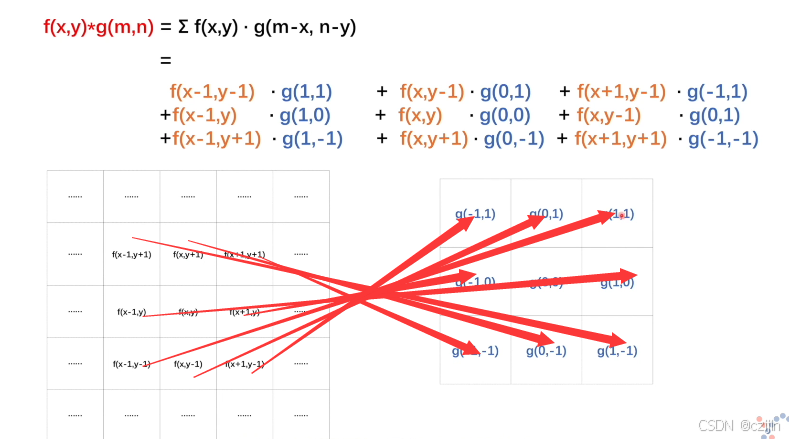
这样子看是卷曲的,那么我们旋转180度之后,就变成了下图的一一对应。
输入层
输入层主要用用于输入图像的信息,对于输入图像,可以转换为一个二维矩阵(以黑白图像为例,彩色图像需要多通道,需要高维的矩阵),每个矩阵值是一个像素值,下图是一个例子。
卷积层
图像输入之后,得到一个二维矩阵,那么就该进行矩阵的特征提取,卷积操作就会为存在特征的区域确定一个高值,不存在特征的区域就是低值。
输入图片是一张黑白线条人脸,人眼是需要提取的特征,那么就可以将人眼的表示作为卷积核,通过卷积核在图像上的移动来确定眼睛的部位。经过卷积后会得到一个新的二维矩阵即特征图,然后对特征图进行上色(高值与低值颜色不同),即可得到相应的特征。
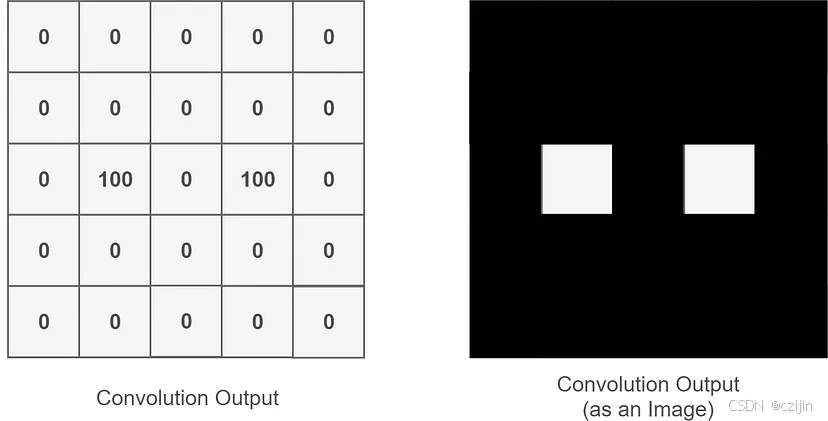
背景中我们介绍了卷积神经网络的扫描过程,下面我们介绍彩色图片的卷积过程:
输入图片是彩色图片,有三个通道,所以输入图片的尺寸就是7×7×3,而我们只考虑第一个通道,也就是从第一个7×7的二维矩阵中提取特征,那么我们只需要使用每组卷积核的第一个卷积核即可,偏置项最后计算的结果加上它就可以,最终通过计算就可以得到特征图。可以发现,有几个卷积核就有几个特征图,因为我们现在只使用了两个卷积核,所以会得到两个特征图。
有时候我们将卷积核叫做滤波器,当数据窗口进行滑动时,滤波器的权重始终是不会改变的,这个权重不变的性质就是CNN中的参数(权重)共享机制。
举一个例子:我们要从下面的图片中识别出X和O,通过与标准答案比对可以轻松识别出来。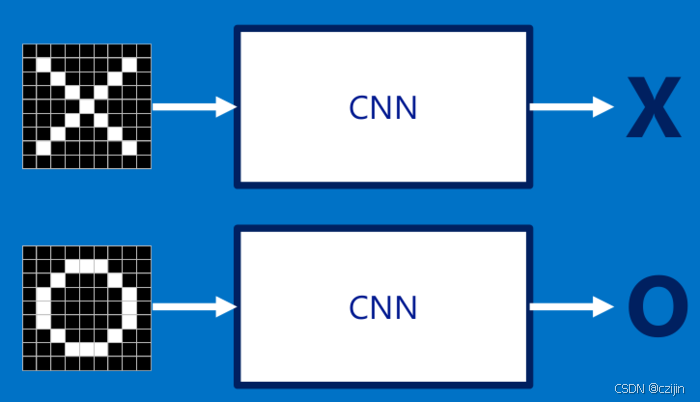
但是平时我们会遇到其他类似但是不规整的情况,这种情况人眼可以直接识别,但是对计算机来说很难识别。
这是由于计算机看到的都是下面的情况(此处值设像素值为1和-1),当比较两幅图的时候,如果有任何一个像素值不匹配,那么这两幅图就不匹配。
对于这个例子,计算机认为上述两幅图中的白色像素除了中间的3 * 3的小方格里面是相同的,其他四个角上都不同。
因此计算机会得出,两张图不相同的结论,因此我们希望计算机能够识别做了简单变换的图像。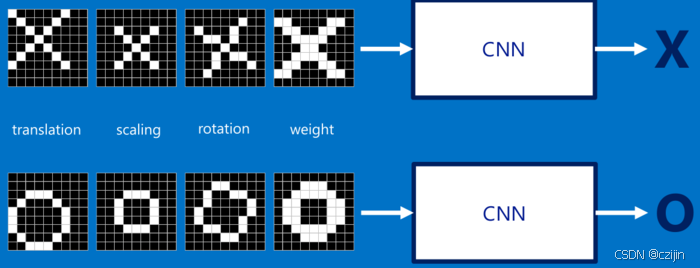
那么通过CNN我们可以解决这个问题,CNN会提取出每个小块进行比对,然后得到匹配信息。
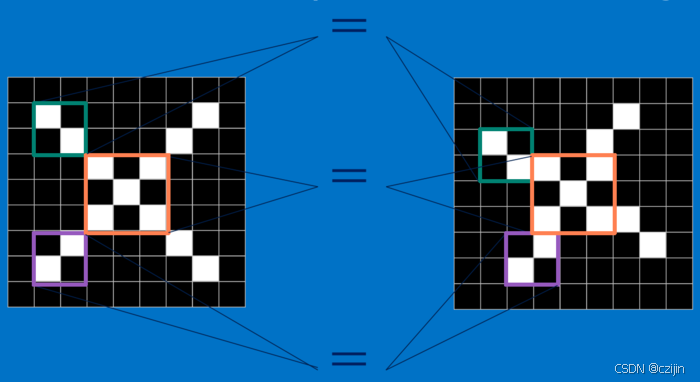
提取出的特征,都是一个小图,不同的特征匹配图像中有不同的特征,以X为例,可以匹配对角线和交叉线等重要特征。
因此,卷积层中的卷积核(滤波器)的作用就是提取出这些小块特征做匹配。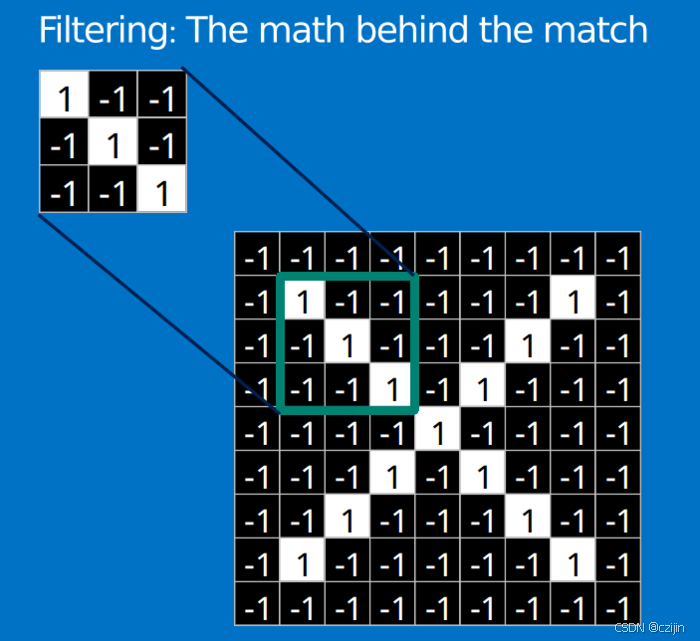
然后把这些局部特征交给神经网络,由神经网络去进行分类判断。
那么除了之前提到的 平滑卷积核,其实还有其他卷积核,比如垂直边界过滤器(卷积核)和水平边界过滤器(卷积核)。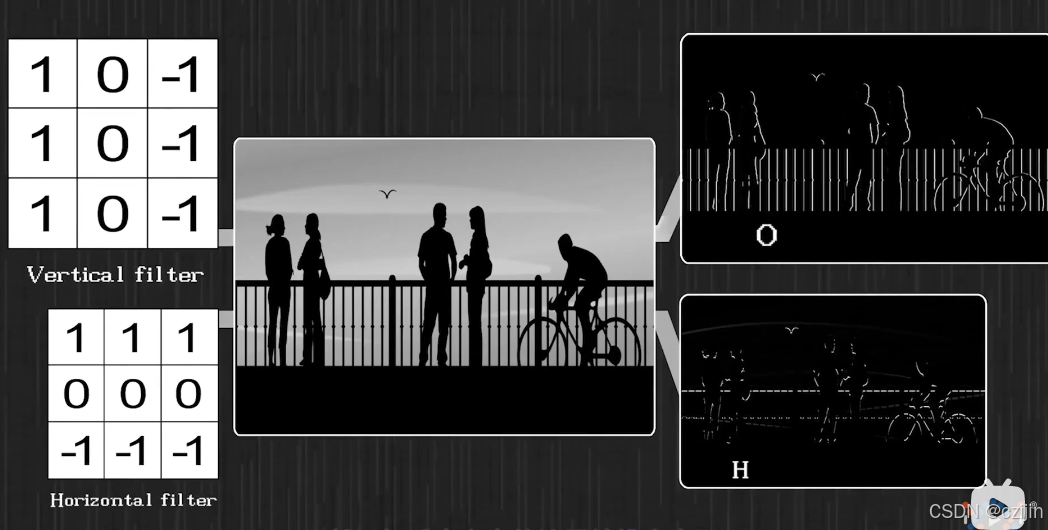
我们可以把图像和卷集合的相乘再相加,看作是周围像素点对当前像素点的影响。其中这个相乘在相加,还可以看作是自己选的像素点对周围像素点的一个试探。总之就是不同的卷积核(模板),可以带来不同的效果
卷积至少有三层含义:
有不稳定的输入,有稳定的输出,则可以通过卷积计算系统的存量
一个卷积核其实就是规定周围像素点对当前像素点会产生怎样的影响
一个过滤器的卷积核,规定了一个像素点会如何试探周围的像素点,以此筛选图像的特征。
总结:卷积就是瞬时行为持续性后果的总和
最后再看一个例子: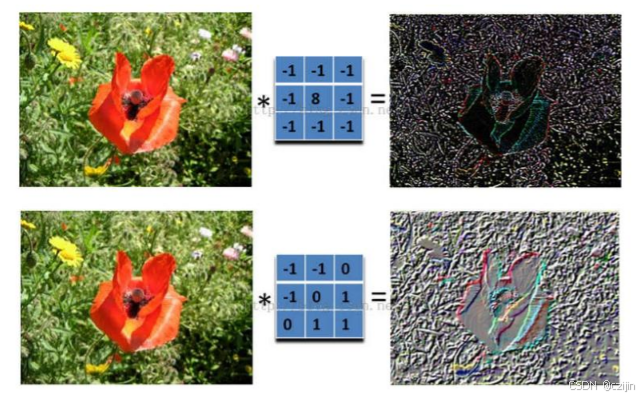
左边是图像输入,中间部分就是滤波器filter(带着一组固定权重的神经元),不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。
池化层
有多少个卷积核就有多少个特征图,这导致如果现实情况较为复杂,就会有更多的卷积核,因此特征数也就会变多,使得出现过拟合问题和维度过高的问题。
为了解决上面的问题,可以使用池化层(又叫做下采样),通过提取特征图中最有代表性的特征,来减小过拟合和特征维度。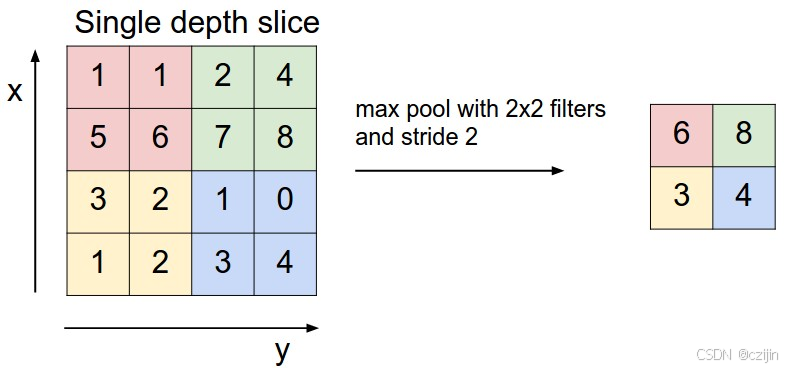
一般会使用最大池化(Max Pooling)来进行最有代表性特征的提取,最大池化过程如下: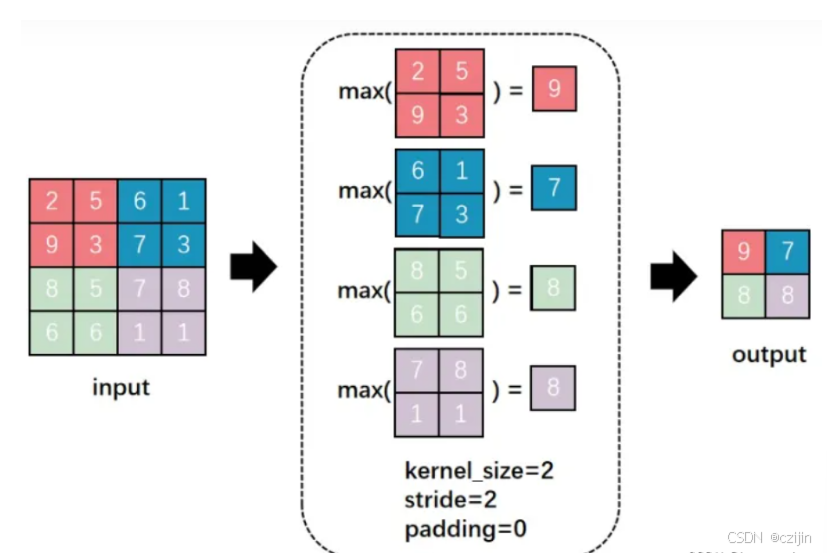
设置一个池化过程的kernel,从kernel中提取最大的值作为最后的保留,其他的stride与padding和卷积过程相同。
此外还有平均池化,平均池化提取kernel区域中的所有值的平均,考虑每个位置对特征的影响。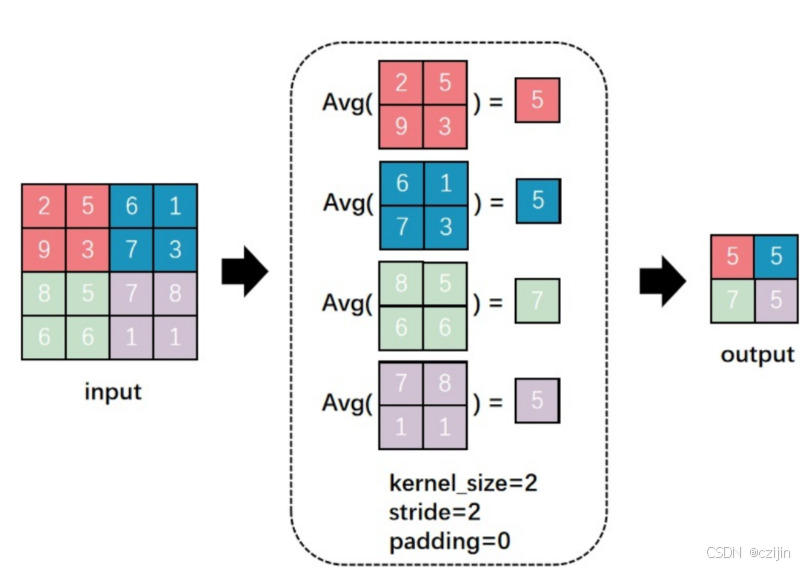
池化层减少了参数量同时保留了原图像的原始特征,能够有效防止过拟合,同时带来了CNN的平移不变性。下面用一个图来说明平移不变性: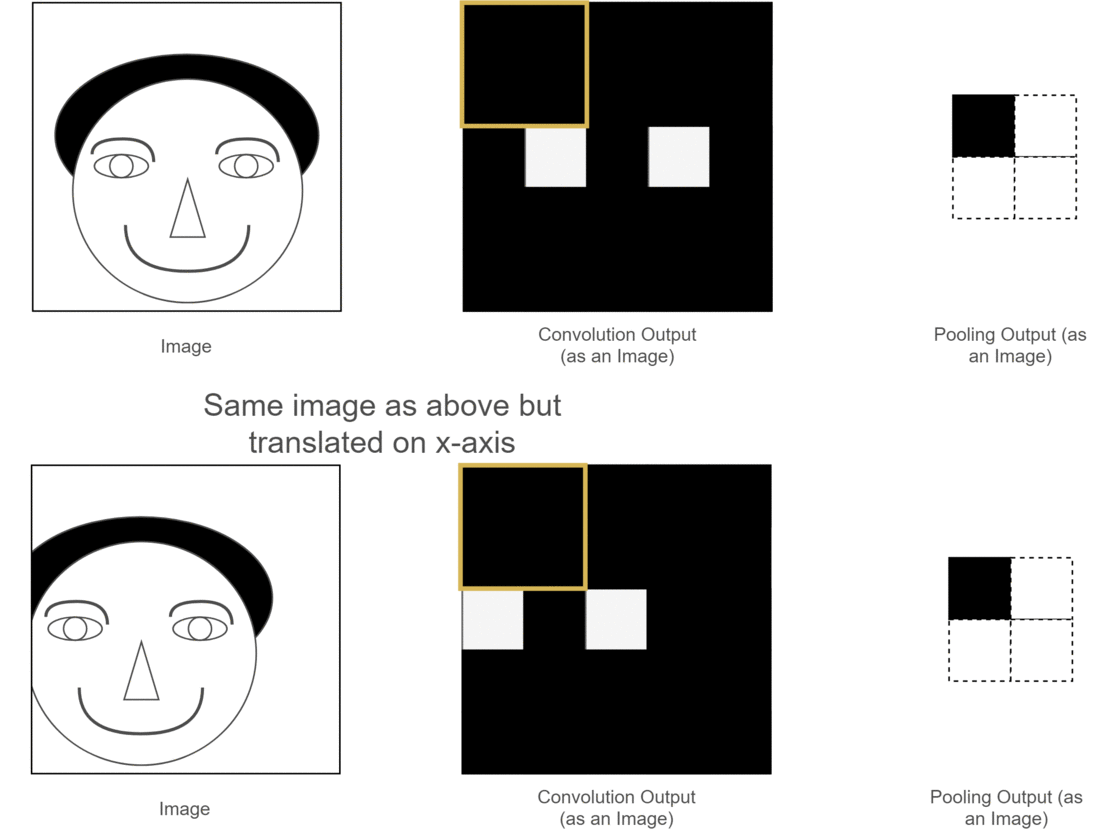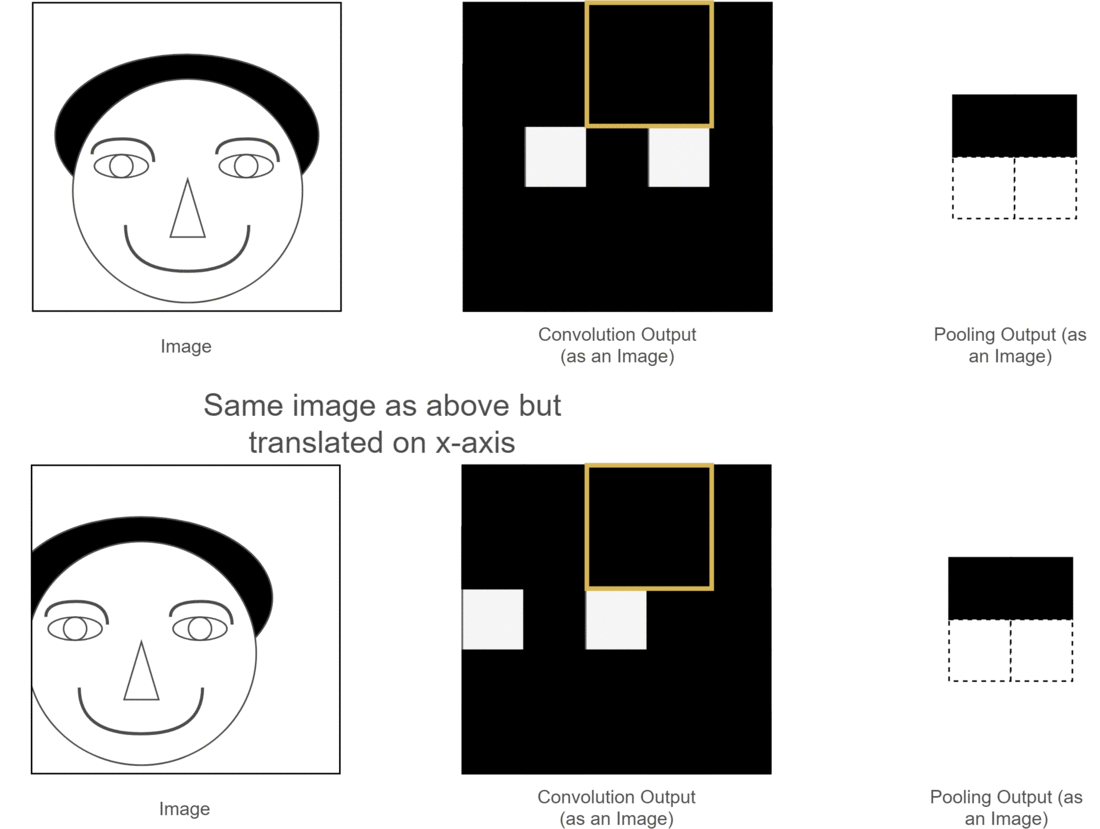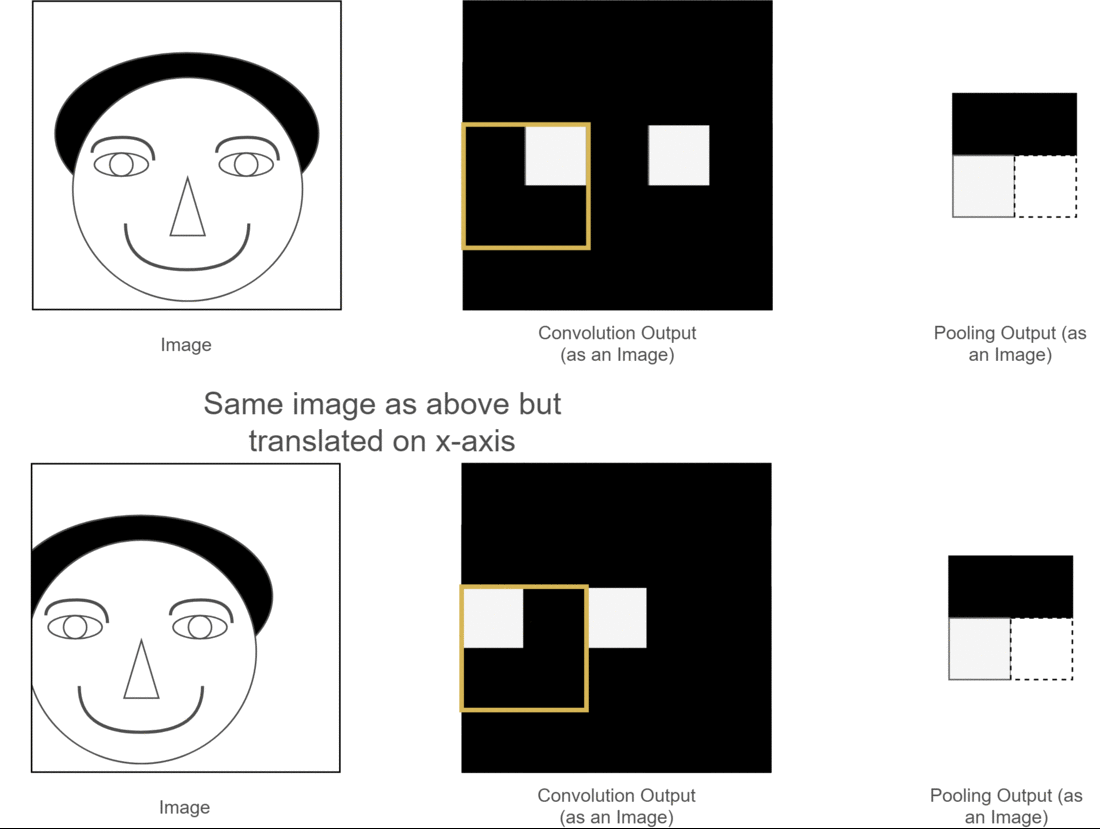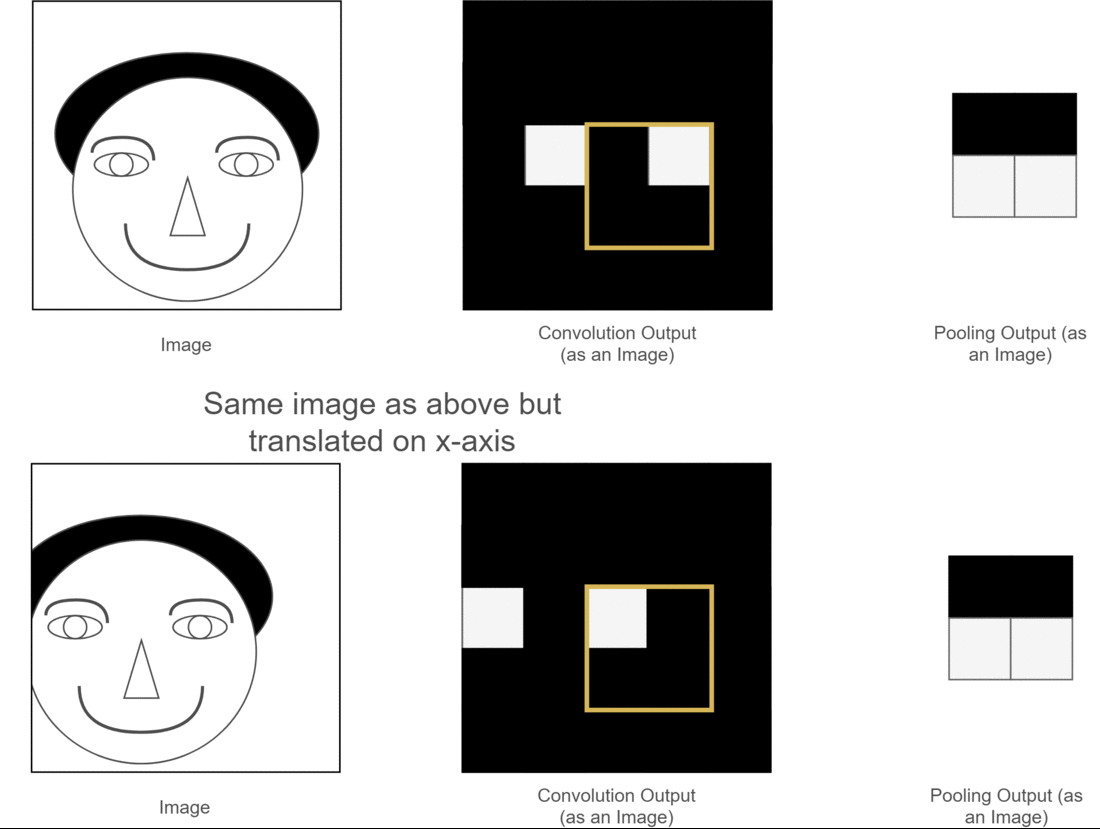
图中,两张原始图片的位置有所不同,经过卷积操作后得到了相应的特征图,但是下面的图经过神经网络计算可能会带来误差,导致与上张图结果不同,此时采用池化层,可以使得特征位置相同,为后续神经网络的计算提供了便利。
全连接层
全连接层对前面提取的特征图进行展平,维度变为1xn,最后经过softmax得到一个概率值,该概率值用来进行识别类别。
结合之前的卷积层和池化层,可以得到下面的步骤
经过两次卷积和最大池化之后,得到最后的特征图,此时的特征都是经过计算后得到的,所以代表性比较强,最后经过全连接层,展开为一维的向量,再经过一次计算后,得到最终的识别概率,这就是卷积神经网络的整个过程。
CNN反向传播算法分析
输入:m个图片样本,CNN模型的层数L和所有隐藏层的类型,对于卷积层,要定义卷积核的大小K,卷积核子矩阵的维度F,填充大小P,步幅S。对于池化层,要定义池化区域大小k和池化标准(MAX或Average),对于全连接层,要定义全连接层的激活函数(输出层除外)和各层的神经元个数。梯度迭代参数迭代步长
α,最大迭代次数MAX与停止迭代阈值ϵ。
输出:CNN模型各隐藏层与输出层的W,b
- 初始化各隐藏层与输出层的各W,b的值为一个随机值。
- for iter to 1 to MAX:
- for i =1 to m:
- 将CNN输入 a 1 a^1 a1设置为 x i x_i xi对应的张量
- for l=2 to L-1,根据下面3种情况进行前向传播算法计算
- 如果当前是全连接层:则有 i , l = σ ( z i , l ) = σ ( W l a i , l − 1 + b l ) ^{i,l} = \sigma(z^{i,l}) = \sigma(W^la^{i,l-1}+b^l) i,l=σ(zi,l)=σ(Wlai,l−1+bl)
- 如果当前是卷积层:则有 a i , l = σ ( z i , l ) = σ ( W l ∗ a i , l − 1 + b l ) a^{i,l}=\sigma(z^{i,l})=\sigma(W^l∗a^{i,l−1}+b^l) ai,l=σ(zi,l)=σ(Wl∗ai,l−1+bl)
- 如果当前是池化层:则有 a i , l = p o o l ( a i , l − 1 ) a^{i,l}=pool(a^{i,l−1}) ai,l=pool(ai,l−1), 这里的pool指按照池化区域大小k和池化标准将输入张量缩小的过程。
- 对于输出层第L层: a i , L = s o f t m a x ( z i , L ) = s o f t m a x ( W L ∗ a i , L − 1 + b L ) a^{i,L}=softmax(z^{i,L})=softmax(W^L*a^{i,L−1}+b^L) ai,L=softmax(zi,L)=softmax(WL∗ai,L−1+bL) 通过损失函数计算输出层的 δ i , L \delta^{i,L} δi,L
- for l= L-1 to 2, 根据下面3种情况进行进行反向传播算法计算:
- 如果当前是全连接层: δ i , l = ( W l + 1 ) T δ i , l + 1 ⊙ σ ′ ( z i , l ) \delta^{i,l}=(W^{l+1})^T\delta^{i,l+1}\odot\sigma\prime(z^{i,l}) δi,l=(Wl+1)Tδi,l+1⊙σ′(zi,l)
- 如果当前是卷积层: δ i , l = δ i , l + 1 ∗ r o t 180 ( W l + 1 ) ⊙ σ ′ ( z i , l ) \delta^{i,l}=\delta^{i,l+1}∗rot180(W^{l+1})\odot\sigma\prime(z^{i,l}) δi,l=δi,l+1∗rot180(Wl+1)⊙σ′(zi,l)
- 如果当前是池化层: δ i , l = u p s a m p l e ( δ i , l + 1 ) ⊙ σ ′ ( z i , l ) \delta^{i,l}=upsample(\delta^{i,l+1})\odot\sigma\prime(z^{i,l}) δi,l=upsample(δi,l+1)⊙σ′(zi,l)
- for l = 2 to L,根据下面2种情况更新第l层的Wl,bl:
- 如果当前是全连接层: W l = W l − α ∑ i = 1 m δ i , l ( a i , l − 1 ) T W^l=W^l−\alpha \sum_{i=1}^m\delta^{i,l}(a^{i,l−1})^T Wl=Wl−α∑i=1mδi,l(ai,l−1)T, b l = b l − α ∑ i = 1 m δ i , l b^l=b^l−\alpha \sum_{i=1}^m\delta^{i,l} bl=bl−α∑i=1mδi,l
- 如果当前是卷积层,对于每一个卷积核有: W l = W l − α ∑ i = 1 , m a i , l − 1 ∗ δ i , l W^l=W^l−\alpha \sum_{i=1,m}a^{i,l−1}∗\delta^{i,l} Wl=Wl−α∑i=1,mai,l−1∗δi,l, b l = b l − α ∑ i = 1 m ∑ u , v ( δ i , l ) u , v b^l=b^l−\alpha \sum_{i=1}^m\sum_{u,v}(\delta^{i,l})_{u,v} bl=bl−α∑i=1m∑u,v(δi,l)u,v
- 如果所有W,b的变化值都小于停止迭代阈值 ϵ \epsilon ϵ,则跳出迭代循环到步骤3。
- for i =1 to m:
- 输出各隐藏层与输出层的线性关系系数矩阵W和偏倚向量b。
总结
卷积神经网络最经典的应用就是手写数字识别,我们通过一个在线demo来回顾整个过程。
- 将手写数字图片转换为像素矩阵
- 第一次卷积得到6个特征图
- 对每个特征图进行池化操作(也可称为下采样操作),在保留特征的同时缩小数据流,生成6个小特征图,这六个图和上一层各自的特征图长得很像,但尺寸缩小了
- 对池化操作后得到的六个小特征图进行第二次卷积运算,生成了更多的特征图
- 对第二次卷积生成的特征图进行池化操作(下采样操作)
- 将第二次池化操作得到的特征进行第一次全连接
- 将第一次全连接的结果进行第二次全连接
- 将第二次全链接的结果进行最后一次运算,这种运算可能是线性的也可能是非线性的,最终每个位置(一共十个位置,从0到9)都有一个概率值,这个概率值就是将输入的手写数字识别为当前位置数字的概率,最后以概率最大的位置的值作为识别结果。可以看到,右侧上方是我的手写数字,右侧下方是模型(LeNet)的识别结果,最终的识别结果与我输入的手写数字是一致的,这一点从图片左边最上边也可以看到,说明此模型可以成功识别手写数字。
代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #使用functional中的ReLu激活函数
import torch.optim as optim
#数据的准备
batch_size = 64
#神经网络希望输入的数值较小,最好在0-1之间,所以需要先将原始图像(0-255的灰度值)转化为图像张量(值为0-1)
#仅有灰度值->单通道 RGB -> 三通道 读入的图像张量一般为W*H*C (宽、高、通道数) 在pytorch中要转化为C*W*H
transform = transforms.Compose([
#将数据转化为图像张量
transforms.ToTensor(),
#进行归一化处理,切换到0-1分布 (均值, 标准差)
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST(root='./data/mnist/',
train=True,
download=True,
transform=transform
)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size
)
test_dataset = datasets.MNIST(root='./data/mnist/',
train=False,
download=True,
transform=transform
)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size
)
#CNN模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
#两个卷积层
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) #1为in_channels 10为out_channels
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
#池化层
self.pooling = torch.nn.MaxPool2d(2) #2为分组大小2*2
#全连接层 320 = 20 * 4 * 4
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
#先从x数据维度中得到batch_size
batch_size = x.size(0)
#卷积层->池化层->激活函数
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) #将数据展开,为输入全连接层做准备
x = self.fc(x)
return x
model = Net()
#在这里加入两行代码,将数据送入GPU中计算!!!
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device) #将模型的所有内容放入cuda中
#设置损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
#神经网络已经逐渐变大,需要设置冲量momentum=0.5
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
#训练
#将一次迭代封装入函数中
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0): #在这里data返回输入:inputs、输出target
inputs, target = data
#在这里加入一行代码,将数据送入GPU中计算!!!
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
#前向 + 反向 + 更新
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
def test():
correct = 0
total = 0
with torch.no_grad(): #不需要计算梯度
for data in test_loader: #遍历数据集中的每一个batch
images, labels = data #保存测试的输入和输出
#在这里加入一行代码将数据送入GPU
images, labels = images.to(device), labels.to(device)
outputs = model(images)#得到预测输出
_, predicted = torch.max(outputs.data, dim=1)#dim=1沿着索引为1的维度(行)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set:%d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
[1, 300] loss: 0.631
[1, 600] loss: 0.823
[1, 900] loss: 0.959
Accuracy on test set:96 %
[2, 300] loss: 0.112
[2, 600] loss: 0.208
[2, 900] loss: 0.299
Accuracy on test set:97 %
[3, 300] loss: 0.079
[3, 600] loss: 0.153
[3, 900] loss: 0.226
Accuracy on test set:98 %
[4, 300] loss: 0.066
[4, 600] loss: 0.130
[4, 900] loss: 0.190
Accuracy on test set:98 %
[5, 300] loss: 0.054
[5, 600] loss: 0.108
[5, 900] loss: 0.164
Accuracy on test set:98 %
[6, 300] loss: 0.048
[6, 600] loss: 0.100
[6, 900] loss: 0.148
Accuracy on test set:98 %
[7, 300] loss: 0.046
[7, 600] loss: 0.094
[7, 900] loss: 0.135
Accuracy on test set:98 %
[8, 300] loss: 0.040
[8, 600] loss: 0.081
[8, 900] loss: 0.123
Accuracy on test set:98 %
[9, 300] loss: 0.038
[9, 600] loss: 0.073
[9, 900] loss: 0.114
Accuracy on test set:98 %
[10, 300] loss: 0.034
[10, 600] loss: 0.071
[10, 900] loss: 0.107
Accuracy on test set:98 %
参考
从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变——B站王木头

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)