QSDsan、PooPyLab 与、bsm2-python实现仿真
从环境信息可以看到这是一个BSM1项目,位于EXPOsan项目的子目录中。目录结构显示这是一个污水处理模型相关的项目,包含了:Python模块文件(init.py, analyses.py, model.py, system.py)README.rst文档数据文件(Excel和MAT文件)图片文件这段代码主要作用是建立和运行一个废水处理厂的动态模拟,遵循基准模拟模型BSM1的标准。它允许用户灵活选
🌞欢迎来到人工智能的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
🌠本阶段属于练气阶段,希望各位仙友顺利完成突破
📆首发时间:🌹2025年8月31日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

QSDsan项目结构
从环境信息可以看到这是一个BSM1项目,位于EXPOsan项目的子目录中。目录结构显示这是
一个污水处理模型相关的项目,包含了:
Python模块文件(init.py, analyses.py, model.py, system.py)
README.rst文档
数据文件(Excel和MAT文件)
图片文件
文档链接:Helpful Basics - QSDsan 1.4.2
system.py
这段代码主要作用是建立和运行一个废水处理厂的动态模拟,遵循基准模拟模型BSM1的标
准。它允许用户灵活选择不同的活性污泥模型(ASM1或ASM2d)和反应器配置(CSTR或
PFR),并通过动态模拟来分析系统的性能,例如计算污泥停留时间 (SRT)。
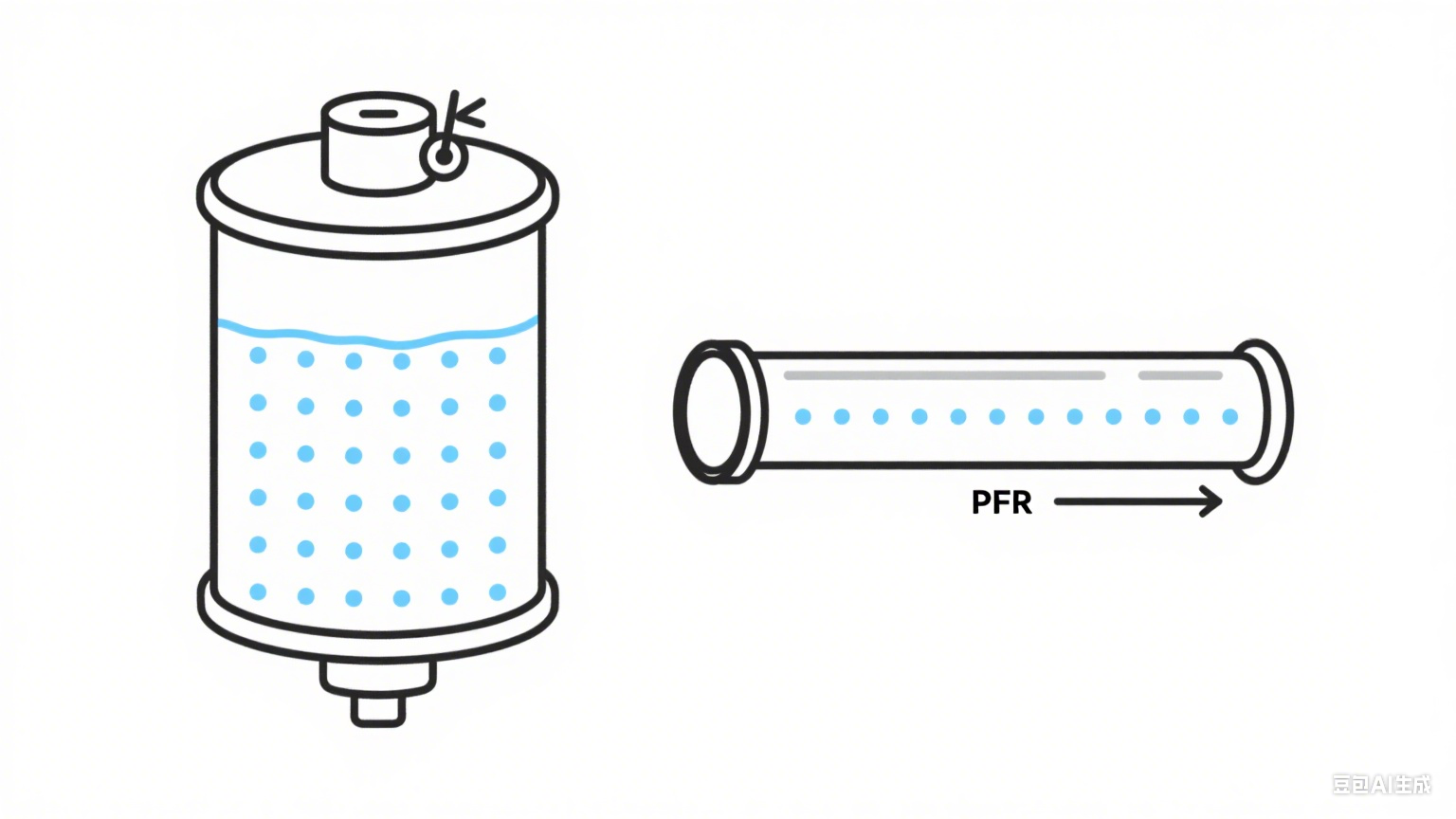
CSTR 是“完全混合”的,像一个大水桶,整个容器内浓度都一样。
PFR 是“没有混合”的,像一个长管道,浓度沿着流程方向逐渐变化。

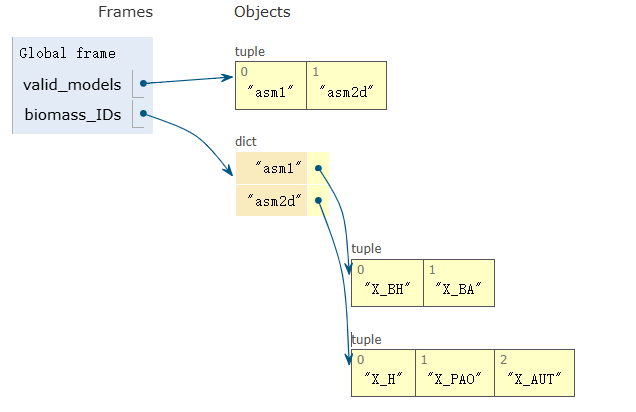
1️⃣参数和实用函数
使用一个字典作为配置表,将每个模型名称(例如 'asm1')作为键,将该模型中需要识别和跟
踪的所有生物量标识符(例如 ('X_BH', 'X_BA'))作为值。
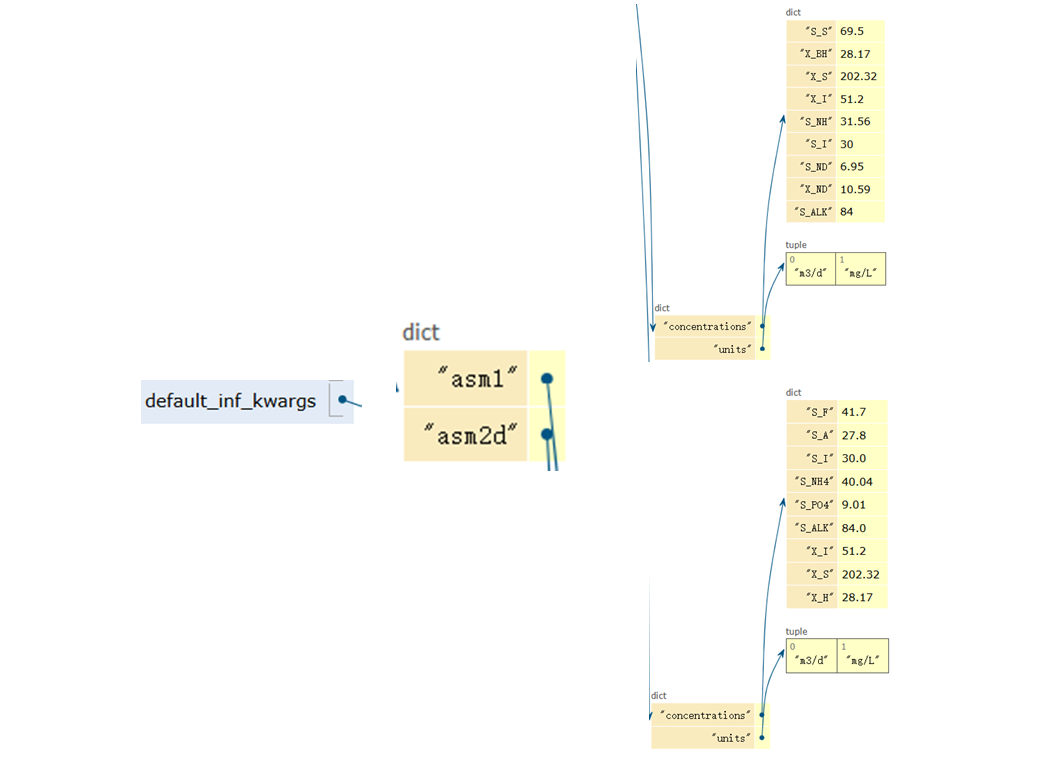
在进水参数的设置上,它使用了一个字典作为配置表,键是模型名称(如'asm1'),值则是
另一个包含所有进水参数(如各种物质的浓度)的字典。
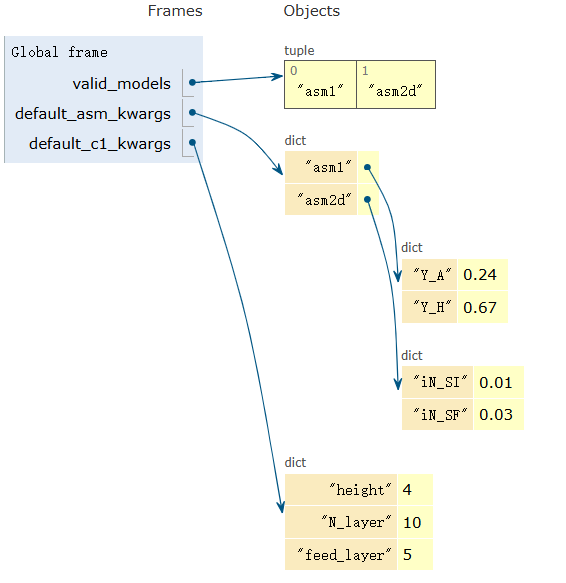
为不同的污水处理模型(ASM1和ASM2d)以及二沉池定义了一套完整的默认参数,包括生物
动力学、化学计量学和物理参数。使用字典来存储这些复杂的参数集。每个模型名称(如'asm1')
或组件名称(如'default_c1_kwargs')作为键,其对应的值则是一个包含所有具体参数的嵌套字
典。这种方式使得代码非常清晰、模块化,并且方便在不同模拟场景下快速加载或修改参数,而不
需要在代码中硬编码这些数值。
underflow 和 wastage 分别代表回流污泥流量和排放污泥流量,它们是控制系统微生物总量的关
键;surface_area 和 height 定义了池子的物理尺寸;N_layer 和 feed_layer 是模型中的分层设
置,用于模拟固体的沉降;而 X_threshold、v_max、v_max_practical 以及 rh, rp, fns 等,则是
描述污泥沉降特性的动力学和经验参数,它们决定了污泥如何从水中分离出来。
定义了不同模型(ASM1和ASM2d)的默认初始浓度,并提供了一个函数,能批量地将这些初
始值应用到污水处理厂模拟系统的各个单元中。使用两个字典来存储不同模型所需的初始浓度值。
dct = df.to_dict('index')
u = sys.flowsheet.unit批量设置初始条件
根据一个名为 df 的 DataFrame 中的数据,为模拟系统中的各个处理单元(如曝气池、二沉
池、CSTR等)设置初始浓度。
dct = df.to_dict('index')
u = sys.flowsheet.unit将传入的 DataFrame 转换成一个嵌套字典,其中最外层的键是 DataFrame 的索引(通常是处
理单元的 ID,如 'C1', 'AS', 'R1' 等),而值则是包含所有浓度数据的字典。这使得通过单元 ID
快速查找其初始参数成为可能。获取了模拟系统中所有已注册单元的“注册表”,方便通过它们的 ID 直接访问它们。
for k in u:
if k.ID == 'C1': continue
elif k.ID == 'AS':
k.set_init_conc(concentrations=df.iloc[:-3])
else:
k.set_init_conc(**dct[k.ID])if k.ID == 'C1': continue:这行代码跳过了二沉池,因为它有单独的初始化方法,不能与其他
反应器混用。elif k.ID == 'AS':如果单元 ID 是 'AS'(通常代表活塞流反应器 PFR),则调用
k.set_init_conc 方法来设置其初始浓度。df.iloc[:-3] 的作用是选择 DataFrame 中的所有行,
除了最后三行,这通常是因为最后三行是为二沉池专门准备的。else::对于其他单元(通常是
CSTRs),代码会从之前转换好的字典 dct 中找到对应的初始浓度,并使用 ** 操作符将字典的键
值对作为参数传递给 set_init_conc 方法。
c1s = {k:v for k,v in dct['C1_s'].items() if v>0}
c1x = {k:v for k,v in dct['C1_x'].items() if v>0}
tss = [v for v in dct['C1_tss'].values() if v>0]
u.C1.set_init_solubles(**c1s)
u.C1.set_init_sludge_solids(**c1x)
u.C1.set_init_TSS(tss)这段代码是专门针对二沉池的初始化。
c1s, c1x, tss 分别从字典 dct 中提取出二沉池所需的可溶性物质、污泥固体和总悬浮固体的初始浓
度,并通过过滤 v>0 来确保只设置有效的参数。
然后,它调用 u.C1(即二沉池单元)的三个特定方法来设置这些参数:set_init_solubles、
set_init_sludge_solids 和 set_init_TSS。这反映了二沉池复杂的固液两相初始状态,需要更精细的
初始化设置。
kind = suspended_growth_model.lower().replace('-', '').replace('_', '')
asm_kwargs = asm_kwargs or default_asm_kwargs[kind]
if kind == 'asm1':
pc.create_asm1_cmps() # 创建ASM1组件
asm = pc.ASM1(**asm_kwargs)
DO_ID = 'S_O' # ASM1的溶解氧ID
Temp = 273.15+20 # 温度
elif kind == 'asm2d':
pc.create_asm2d_cmps() # 创建ASM2d组件
asm = pc.ASM2d(**asm_kwargs)
DO_ID = 'S_O2' # ASM2d的溶解氧ID
Temp = 273.15+15 # 温度
else:
raise ValueError('`suspended_growth_model` 只能是 "ASM1" 或 "ASM2d" ')这行代码是一个“或”逻辑表达式,用于处理可选参数。asm_kwargs 是用户传入的自定义活性
污泥模型参数字典。default_asm_kwargs[kind] 是根据标准化后的 kind 变量,从预设的默认参数
字典中获取的参数。如果用户没有传入 asm_kwargs(即它是空值),则使用默认参数字典中的
值。这确保了即使没有指定参数,模型也能使用预设的默认值进行初始化。
这是一个条件分支,根据 kind 变量的值来执行不同的初始化逻辑。
如果 kind 是 'asm1':pc.create_asm1_cmps():调用一个函数,创建并注册 ASM1 模型所需的所
有化学组分(如易降解有机物、氨氮、硝酸盐等)。asm = pc.ASM1(**asm_kwargs):创建一个
ASM1 类的实例,并使用 asm_kwargs 中的参数对其进行初始化。DO_ID = 'S_O':为 ASM1 模型
设定溶解氧的标识符为 'S_O'。Temp = 273.15+20:设定 ASM1 模型的默认温度为 20∘C。
如果 kind 是 'asm2d':pc.create_asm2d_cmps():创建并注册 ASM2d 模型所需的化学组分,这
比 ASM1 的组分多,因为它包含磷的相关物质。asm = pc.ASM2d(**asm_kwargs):创建一个
ASM2d 类的实例。DO_ID = 'S_O2':为 ASM2d 模型设定溶解氧的标识符为 'S_O2'。
Temp = 273.15+15:设定 ASM2d 模型的默认温度为 15∘C。
wastewater = WasteStream('wastewater', T=Temp)
inf_kwargs = inf_kwargs or default_inf_kwargs[kind]
# 根据浓度和流量设置进水
wastewater.set_flow_by_concentration(Q, **inf_kwargs)这段代码首先创建了一个代表进水流的对象,然后灵活地加载了默认或自定义的进水浓度和
单位,最后将这些参数应用到进水流对象上,从而完成了对进水流的完整配置。
# 工艺模型
if aeration_processes:
aer1, aer2, aer3 = aeration_processes
kLa = [aer.KLa for aer in aeration_processes]
else:
# 如果没有指定曝气器,则使用默认的
aer1 = aer2 = pc.DiffusedAeration('aer1', DO_ID, KLa=240, DOsat=8.0, V=V_ae)
if kind == 'asm1':
kLa = [240, 240, 84]
aer3 = pc.DiffusedAeration('aer3', DO_ID, KLa=84, DOsat=8.0, V=V_ae)
else:
kLa = [240]*3
aer3 = aer1if aeration_processes:
这行代码检查函数参数 aeration_processes 是否为空。如果用户在调用 create_system 函数时传
入了一个包含曝气器对象的元组,那么这个条件就成立。
aer1, aer2, aer3 = aeration_processes:如果用户提供了曝气器,这段代码会通过元组解包
(tuple unpacking)的方式,将元组中的曝气器实例分别赋值给 aer1, aer2 和 aer3 变量。
kLa = [aer.KLa for aer in aeration_processes]:这行代码使用了列表推导式(list
comprehension),它遍历用户提供的曝气器元组,提取每个曝气器的 KLa(即传氧系数)属性,
并将这些值组成一个名为 kLa 的列表。这个 kLa 列表将在后续用于配置 PFR 模型。
else:
如果 aeration_processes 参数为空(即用户没有指定曝气器),则执行 else 块中的代码,使用默
认的曝气器配置。
aer1 = aer2 = pc.DiffusedAeration('aer1', DO_ID, KLa=240, DOsat=8.0, V=V_ae):这行代码创建
了一个名为 'aer1' 的 DiffusedAeration(曝气器)对象,并将其赋值给 aer1 和 aer2。它使用预设
的参数:
DO_ID:溶解氧的标识符('S_O' 或 'S_O2',取决于模型)。
KLa=240:默认的传氧系数。
DOsat=8.0:默认的溶解氧饱和浓度。
V=V_ae:曝气器所在的反应器体积。
if kind == 'asm1'::这里又有一个条件分支,用于处理 ASM1 和 ASM2d 之间的差异。
kLa = [240, 240, 84]:对于 ASM1 模型,曝气池的 kLa 值是不同的,第三个池子的值更小
(84)。这种设置反映了 ASM1 基准模型的特定配置,在最后一段曝气池使用较低的曝气强度。
aer3 = pc.DiffusedAeration('aer3', DO_ID, KLa=84, DOsat=8.0, V=V_ae):单独创建了第三个曝气
器,其 KLa 为84。
else::
kLa = [240]*3:对于 ASM2d 模型,默认情况下所有好氧池的 kLa 都相同,所以这里创建了一个包
含3个240的列表。
aer3 = aer1:由于 kLa 值都相同,所以第三个曝气器可以直接使用和第一个相同的实例。
# 创建单元操作
c1_kwargs = settler_kwargs or default_c1_kwargs
if reactor_model == 'CSTR': # 如果选择CSTR模型
# 定义CSTR的参数
an_kwargs = dict(V_max=V_an, aeration=None, suspended_growth_model=asm)
ae_kwargs = dict(V_max=V_ae, DO_ID=DO_ID, suspended_growth_model=asm)
if kind == 'asm1':
# ASM1模型由两个缺氧池和三个好氧池组成
A1 = su.CSTR('A1', ins=[wastewater, 'RWW', 'RAS'], **an_kwargs)
A2 = su.CSTR('A2', A1-0, **an_kwargs)
O1 = su.CSTR('O1', A2-0, aeration=aer1, **ae_kwargs)
O2 = su.CSTR('O2', O1-0, aeration=aer2, **ae_kwargs)
# O3有两个出口,一个用于内部回流,一个去二沉池
O3 = su.CSTR('O3', O2-0, [1-A1, 'treated'], split=[Q_intr, Q+Q_ras],
aeration=aer3, **ae_kwargs)
C1 = su.FlatBottomCircularClarifier('C1', O3-1,
['effluent', 2-A1, 'WAS'],
**c1_kwargs)
path=(A1, A2, O1, O2, O3, C1)
else: # ASM2d模型
# ASM2d模型由四个缺氧池和三个好氧池组成
A1 = su.CSTR('A1', ins=[wastewater, 'RAS'], **an_kwargs)
A2 = su.CSTR('A2', A1-0, **an_kwargs)
A3 = su.CSTR('A3', [A2-0, 'RWW'], **an_kwargs)
A4 = su.CSTR('A4', A3-0, **an_kwargs)
O1 = su.CSTR('O1', A4-0, aeration=aer1, **ae_kwargs)
O2 = su.CSTR('O2', O1-0, aeration=aer2, **ae_kwargs)
O3 = su.CSTR('O3', O2-0, [1-A3, 'treated'], split=[Q_intr, Q+Q_ras],
aeration=aer3, **ae_kwargs)
C1 = su.FlatBottomCircularClarifier('C1', O3-1,
['effluent', 1-A1, 'WAS'],
**c1_kwargs)
path = (A1, A2, A3, A4, O1, O2, O3, C1)
# 创建系统并设置动态跟踪
sys = System('bsm1_sys', path=path, recycle=(O3-0, C1-1))
sys.set_dynamic_tracker(A1, C1-0)
elif reactor_model == 'PFR': # 如果选择PFR模型
as_kwargs = dict(
DO_ID=DO_ID, DO_sat=8.0, suspended_growth_model=asm,
gas_stripping=False
)
if kind == 'asm1':
# ASM1的PFR模型,5个分段,2个缺氧,3个好氧
AS = su.PFR('AS', ins=[wastewater, 'RAS'], outs='treated',
N_tanks_in_series=5,
V_tanks=[V_an]*2+[V_ae]*3,
influent_fractions=[[1]+[0]*4]*2,
internal_recycles=[(4,0,Q_intr)], # 内部回流从第4个池到第0个池
kLa=[0]*2+kLa, **as_kwargs) # 设置kLa,缺氧池为0
else: # ASM2d的PFR模型
# ASM2d的PFR模型,7个分段,4个缺氧,3个好氧
AS = su.PFR('AS', ins=[wastewater, 'RAS'], outs='treated',
N_tanks_in_series=7,
V_tanks=[V_an]*4+[V_ae]*3,
influent_fractions=[[1]+[0]*6]*2,
internal_recycles=[(6,2,Q_intr)], # 内部回流从第6个池到第2个池
kLa=[0]*4+kLa, **as_kwargs) # 设置kLa,缺氧池为0
# 创建二沉池和系统
C1 = su.FlatBottomCircularClarifier('C1', AS-0,
['effluent', 1-AS, 'WAS'],
**c1_kwargs)
sys = System('bsm1_sys', path=(AS, C1), recycle=(C1-1,))
sys.set_dynamic_tracker(AS, C1-0)
else:
raise ValueError('`reactor_model` 只能是 "CSTR" 或 "PFR"')
sys.set_tolerance(rmol=1e-6)
if init_conds:
if isinstance(init_conds, dict):
# 如果是字典,则对所有反应器应用相同的初始条件
for i in sys.units:
if i.ID == 'C1': continue
i.set_init_conc(**init_conds)
else:
df = init_conds
else:
# 如果没有给定,则从文件中加载默认初始条件
path = os.path.join(data_path, f'initial_conditions_{kind}.xlsx')
df = load_data(path, sheet='default')
batch_init(sys, df)
return sys1. 参数处理和类型选择
c1_kwargs = settler_kwargs or default_c1_kwargs:这行代码首先处理二沉池的参数。如果用户
传入了自定义的参数,就使用用户提供的;否则,使用默认的二沉池参数。
if reactor_model == 'CSTR'::这是一个关键的条件分支,它根据用户选择的反应器模型(CSTR 或 PFR)来执行不同的代码路径。
2. CSTR 模型构建
如果选择了 CSTR(多池串联)模型,代码会创建一系列独立的反应器单元并按顺序连接它们。
参数字典:an_kwargs 和 ae_kwargs 分别定义了缺氧池(an)和好氧池(ae)的共享参数,如最大容积和活性污泥模型。
ASM1 流程:
A1, A2:创建两个缺氧 CSTR 单元。A1 接收进水(wastewater)、回流污泥(RAS)和内部回流(RWW)。A2 接收 A1 的出水。
O1, O2, O3:创建三个好氧 CSTR 单元。它们通过串联接收前一个池的出水,并都配置了曝气器(aeration)。
特殊连接:O3 单元被特殊处理,它有两个出口:一个用于内部回流(1-A1,即连接到 A1 的第二个入口),另一个流向二沉池(O3-1)。split=[Q_intr, Q+Q_ras] 决定了这两个出口的流量比例。
C1:创建二沉池(FlatBottomCircularClarifier)。它接收 O3 的出水,并有三个出口:处理后的出水(effluent)、回流污泥(2-A1,回到 A1)和排放污泥(WAS)。
ASM2d 流程:
类似地,ASM2d 流程创建了四个缺氧池(A1 到 A4)和三个好氧池(O1 到 O3),反映了生物除磷需要更长的厌氧区。
这里的内部回流是从最后一个好氧池(O3-0)回到第三个缺氧池(1-A3),这与 ASM1 的回流位置不同,是为了优化反硝化脱氮。
系统封装:sys = System(...) 这行代码将所有单元和流线连接起来,形成一个完整的系统对象。recycle 参数明确了系统中的循环流线,set_dynamic_tracker 则用于追踪特定单元的动态变化。
3. PFR 模型构建
如果选择了 PFR(活塞流反应器)模型,代码会创建一个单个的 PFR 单元,并将其划分成多个分段来模拟推流效果。
as_kwargs:定义了 PFR 的通用参数。
ASM1 流程:
创建一个 PFR 单元(AS)。
N_tanks_in_series=5:将 PFR 划分成5个串联的分段。
V_tanks=[V_an]*2+[V_ae]*3:定义了每个分段的容积,前两个是缺氧区(Van
),后三个是好氧区(Vae
)。
internal_recycles=[(4,0,Q_intr)]:定义了内部回流,从第4个分段(好氧区)回到第0个分段(缺氧区)。
ASM2d 流程:
创建一个 PFR 单元,并将其划分为7个分段(4个缺氧,3个好氧)。
internal_recycles=[(6,2,Q_intr)]:内部回流从第6个分段(好氧区)回到第2个分段(缺氧区),同样是模拟ASM2d的脱氮工艺。
二沉池和系统:最后,代码创建二沉池 C1 并将其连接到 PFR,然后将它们封装成一个系统对象。
4. 容错和初始条件
else: raise ValueError(...):如果 reactor_model 参数无效,则抛出错误。
初始条件:代码最后调用 batch_init 函数,根据用户提供的或默认的初始条件,来为新创建的系统进行初始化。
mode.py
这段代码提供了一个强大的框架,允许用户以结构化的方式,针对不同的研究目的(通用参数
敏感 性、稳态稳定性、决策变量影响等),对复杂的污水处理模型进行不确定性分析。
analysis.py
这段代码的目的是将复杂的模拟数据转化为易于理解的图表和统计分析结果。它可以被看作是
模拟模型的“分析后端”。
PooPyLab
# This file is part of PooPyLab.
#
# PooPyLab is a simulation software for biological wastewater treatment
# processes using International Water Association Activated Sludge Models.
#
# Copyright (C) Kai Zhang
#
# PooPyLab is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# PooPyLab is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with PooPyLab. If not, see <http://www.gnu.org/licenses/>.
#
# -----------------------------------------------------------------------------
# Definition of a Completely-mixed Stirred Tank Reactor (CSTR) Process Flow.
#
#
# Process Flow Diagram:
#
# Inlet --p1-> reactor(ra) --p2-> outlet
#
#
# Author: Kai Zhang
#
# Change Log:
# 20201129 KZ: re-run after package structure update
# 20200708 KZ: init
#
from PooPyLab.unit_procs.streams import pipe
from PooPyLab.unit_procs.streams import influent, effluent
from PooPyLab.unit_procs.bio import asm_reactor
inlet = influent()
p1 = pipe()
ra = asm_reactor()
p2 = pipe()
outlet = effluent()
wwtp = [inlet,
p1, ra, p2,
outlet]
SRT = 10 # day, in CSTR, this is not a CONTROLLED operation param.
def construct():
# make an CMAS plant
inlet.set_downstream_main(p1)
p1.set_downstream_main(ra)
ra.set_downstream_main(p2)
p2.set_downstream_main(outlet)
inlet.set_mainstream_flow(37800)
ra.set_model_condition(10, 2.0)
ra.set_active_vol(37800*2) # CSTR SRT = HRT, let HRT = 2 d
print("CMAS PFD constructed.")
return wwtp
文档链接:首页 ·toogad/PooPyLab_Project 维基百科
bsm2-python


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 24
24 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)