【大数据机器学习毕业设计选题】基于Python爬虫的京东美妆商品评论数据可视化分析 美妆商品评论情感分析 (hadoop+spark+hive))
京东美妆商品评论数据可视化分析系统摘要 本项目开发了一个基于Python爬虫的京东美妆商品评论数据可视化分析系统,整合了大数据技术与机器学习算法。系统通过爬虫获取京东美妆商品评论数据,利用Hadoop+Spark+Hive进行数据处理,采用聚类算法分析商品特征,并通过Echarts实现多维可视化展示。功能包括用户登录注册、商品信息查看、评论情感分析、店铺支持率预测等。系统采用Django+Vue框
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于Python爬虫的京东美妆商品评论数据可视化分析 美妆商品评论情感分析 (hadoop+spark+hive))
1、京东美妆商品评论数据可视化分析-前言介绍
1.1背景
随着电子商务的快速发展,消费者在选择美妆产品时,越来越依赖于在线平台的商品评价和用户反馈。京东作为国内领先的电商平台,其美妆产品的评论信息不仅反映了商品的市场表现,还为消费者提供了重要的决策依据。然而,面对海量的商品评论数据,如何高效地提取有价值的信息,并利用这些数据预测商品的市场趋势,成为了商家和消费者共同面临的挑战。传统的人工分析方式不仅效率低下,且难以应对数据的快速增长。因此,开发一个基于京东美妆商品评论数据的分析系统,能够通过机器学习技术对数据进行处理与预测,帮助用户更好地理解商品的市场表现,已成为一种迫切需求。
1.2课题功能、技术
本课题旨在设计并实现一个基于Python爬虫的京东美妆商品评论数据可视化分析系统。系统通过Python爬虫技术从京东平台获取美妆商品的详细评论数据,包括评论内容、价格、销量、评分等多维度信息。然后,利用聚类算法对商品进行数据分析,发现相似商品的特征与趋势。基于分析结果,系统通过Echarts实现大屏数据可视化,包括价格统计、评论数统计、销售量统计以及评论描述占比等指标。同时,系统结合大数据技术(Hadoop、Spark、Hive)进行数据处理与存储,提供对店铺支持率的预测功能,用户可以输入店铺信息、价格和销量等参数,系统根据历史数据预测店铺的未来表现。
1.3 意义
本课题的意义在于通过技术手段提升电商平台数据分析的效率与精准度。通过爬虫技术自动化获取并处理京东平台的海量评论数据,能够为商家提供有价值的市场洞察,帮助其优化商品定价、调整营销策略。此外,基于聚类算法的分析能够揭示不同商品群体的特征,辅助消费者做出更为明智的购买决策。Echarts的数据可视化展示为用户提供了直观的数据图表,增强了信息的可读性和易理解性。综上所述,本课题不仅为电商平台提供了智能化的数据分析与预测解决方案,也为消费者提供了一个高效、便捷的决策支持工具,具有广泛的实际应用价值和商业潜力。
2、京东美妆商品评论数据可视化分析-研究内容
1、数据采集与清洗:通过Python爬虫从京东平台自动获取美妆商品评论数据,采集内容包括评论文本、商品价格、销量、评分等信息。采用正则表达式和NLP技术对评论内容进行预处理,去除无效字符,填充缺失值,并删除重复数据,确保数据的准确性和完整性。
2、数据存储:使用Python及Pandas对爬取的原始数据进行清洗和预处理,筛选出高质量数据。通过聚类算法对商品评论数据进行分析,发现具有相似购买特征的商品群体,并基于这些群体进行市场趋势预测,帮助商家了解消费者偏好和市场动态。
3、数据可视化展示:通过Echarts库对美妆商品数据进行多维度的可视化展示,涵盖价格统计、评论数、销售量等指标。利用饼图、柱状图等图表直观展示评论分析结果,并通过动态交互界面实现数据的实时更新,为用户提供直观的分析结果与趋势预测。
4、Web框架搭建:前端使用Vue框架构建动态页面,提供良好的用户交互体验,展示商品数据和预测结果。后端采用Django框架实现数据管理、用户权限、商品管理等功能,并通过RESTful API接口将数据与前端进行高效交互,确保系统的稳定性和可扩展性。
5、系统集成与部署:系统测试包括功能测试、性能测试和安全性测试,确保各模块的稳定性与准确性。通过模拟高并发用户访问,测试系统的响应速度与处理能力。同时,对系统的安全性进行评估,保障用户数据的隐私与安全,避免潜在的安全漏洞。
3、京东美妆商品评论数据可视化分析-开发技术与环境
- 开发语言:Python
- 后端框架:Django
- 大数据:Hadoop+Spark+Hive
- 前端:Vue
- 数据库:MySQL
- 算法:聚类算法
- 开发工具:Pycharm
4、京东美妆商品评论数据可视化分析-功能介绍
亮点:(爬虫【京东】、机器学习【聚类算法预测】、Echarts可视化)
1、用户功能:登录注册、查看新能源汽车信息、查看详情、在线交流论坛。
2、后台管理员:美妆商品管理、聚类算法预测、系统管理。
3、大屏可视化分析:价格统计、评论数统计、评论描述占比、销售量统计、支持占比。
4、预测:预测店铺支持率,输入店铺、价格和销量。
5、京东美妆商品评论数据可视化分析-论文参考

6、京东美妆商品评论数据可视化分析-成果展示
6.1演示视频
【大数据机器学习毕业设计选题】基于Python爬虫的京东美妆商品评论数据可视化分析 美妆商品评论情感分析 (hadoop+spark+hive))
6.2演示图片
1、用户端页面:
☀️登录注册☀️
☀️用户-查看美妆☀️
2、管理员端页面:
☀️大屏可视化分析☀️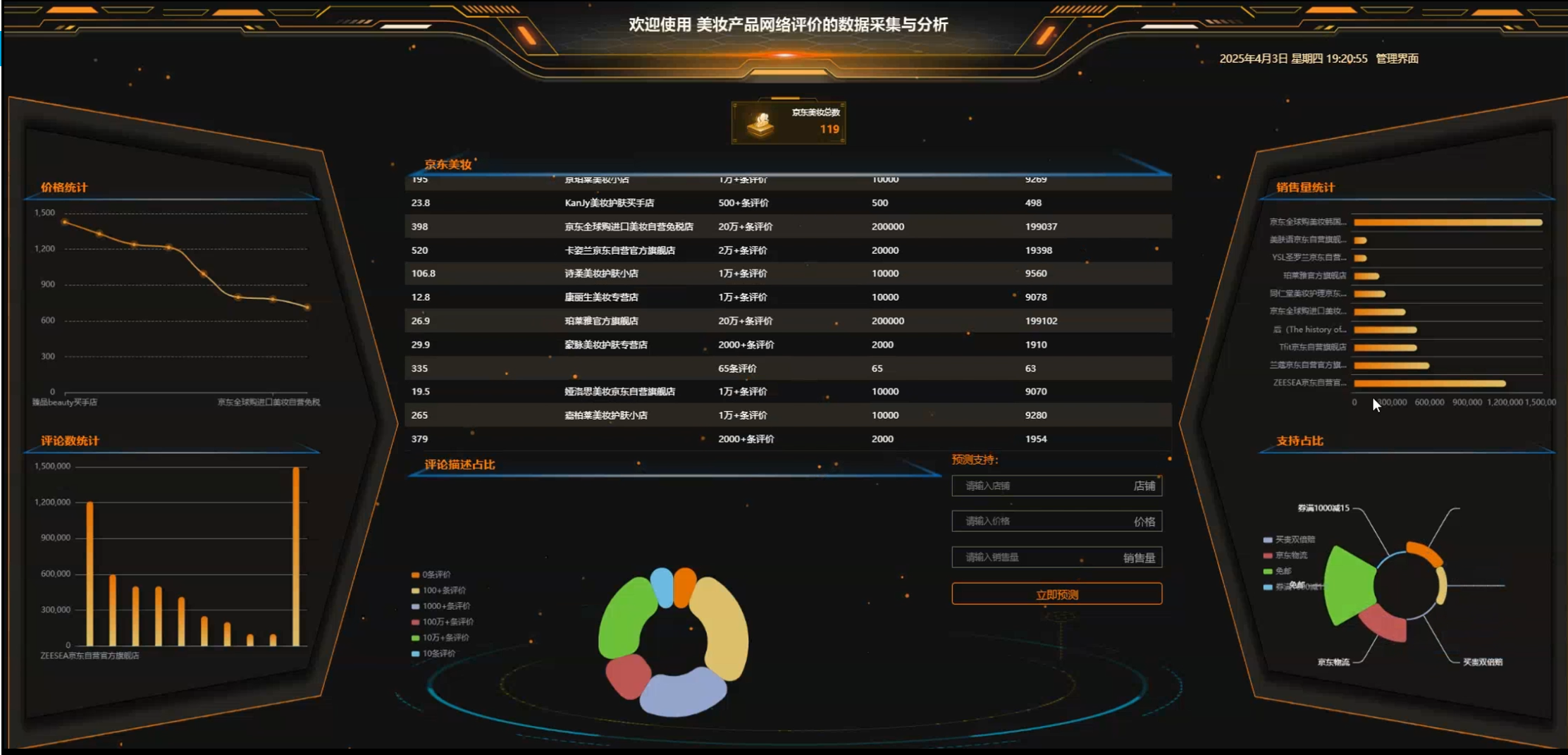
☀️聚类算法-预测支持☀️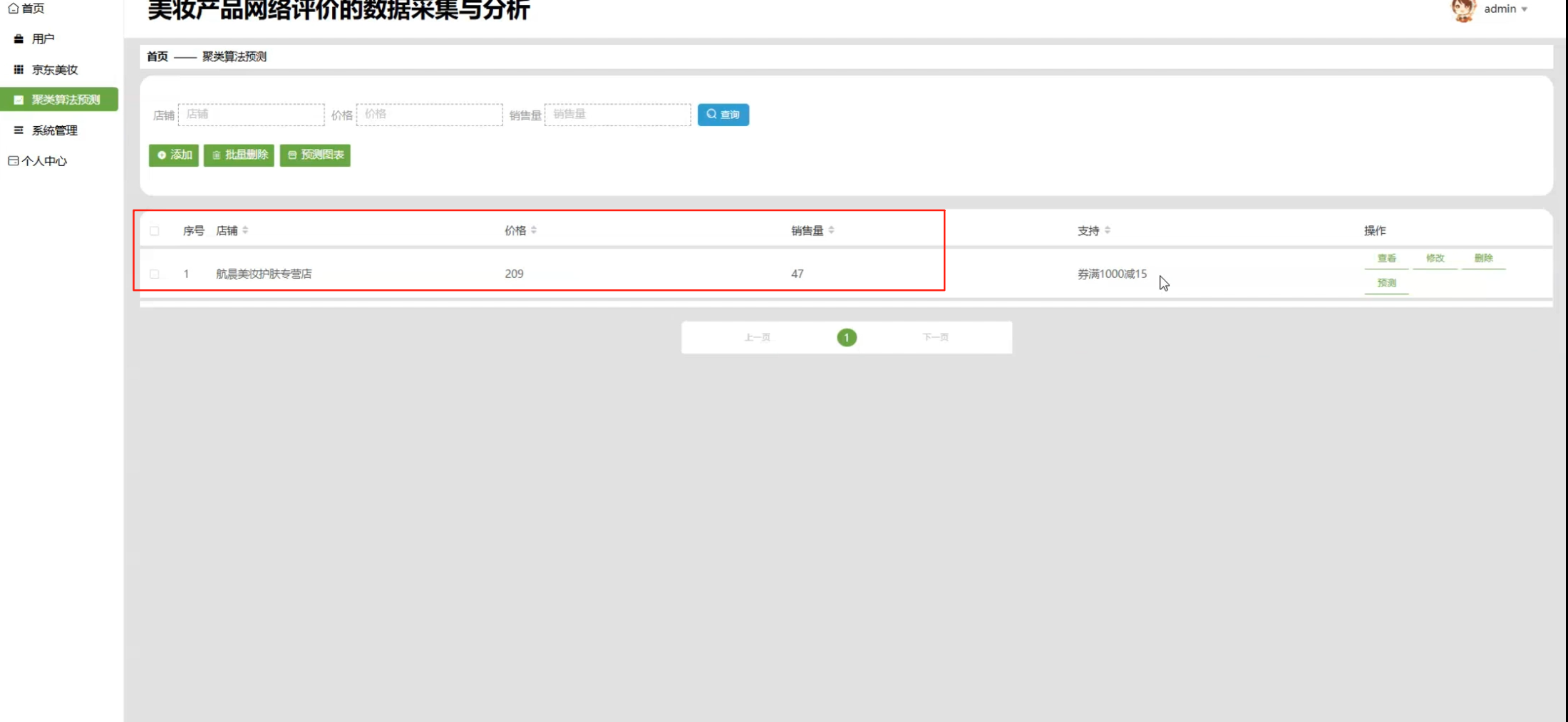
☀️京东美妆管理sunny: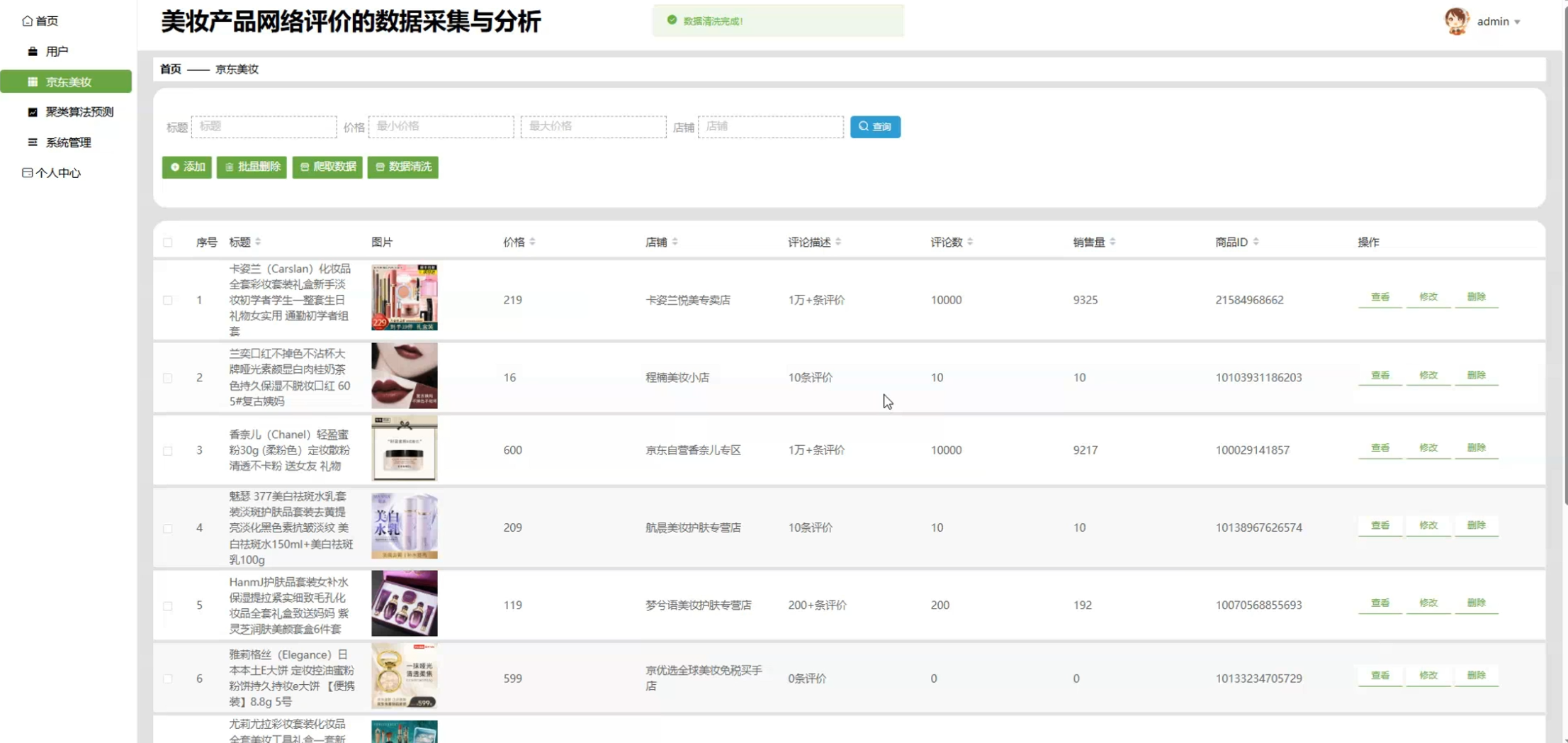
7、代码展示
1.数据清洗【代码如下(示例):】
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_csv('jd_beauty_reviews.csv')
# 查看数据的基本信息
print(data.info())
# 1. 去除重复数据
data = data.drop_duplicates()
# 2. 处理缺失值:对于评分缺失的项,使用均值填充
data['rating'] = data['rating'].fillna(data['rating'].mean())
# 对评论文本进行清洗,去除非字母数字字符
import re
data['review'] = data['review'].apply(lambda x: re.sub(r'[^a-zA-Z0-9\s]', '', str(x)))
# 3. 格式化评论日期(假设评论日期在'date'列)
data['date'] = pd.to_datetime(data['date'], errors='coerce')
# 4. 去除评分为负值的记录
data = data[data['rating'] >= 0]
# 5. 过滤掉销量过低的商品(假设销量在'sales'列)
data = data[data['sales'] >= 10]
# 6. 重设索引
data.reset_index(drop=True, inplace=True)
# 输出清洗后的数据
print(data.head())
2.大屏可视化【代码如下(示例):】
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import pandas as pd
# 加载用户评分数据(假设数据包含'user_id', 'product_id', 'rating'列)
ratings_data = pd.read_csv('user_ratings.csv')
# 创建用户-商品评分矩阵
ratings_matrix = ratings_data.pivot(index='user_id', columns='product_id', values='rating').fillna(0)
# 计算相似度矩阵(使用余弦相似度)
similarity_matrix = cosine_similarity(ratings_matrix)
# 将相似度矩阵转换为DataFrame格式,便于后续操作
similarity_df = pd.DataFrame(similarity_matrix, index=ratings_matrix.index, columns=ratings_matrix.index)
# 基于相似度的推荐函数
def recommend_products(user_id, top_n=5):
# 获取当前用户与其他所有用户的相似度
similar_users = similarity_df[user_id].sort_values(ascending=False)[1:] # 排除自己与自己的相似度
# 计算推荐分数(加权平均)
recommended_products = {}
for similar_user, similarity_score in similar_users.items():
user_ratings = ratings_data[ratings_data['user_id'] == similar_user]
for _, row in user_ratings.iterrows():
if row['product_id'] not in recommended_products:
recommended_products[row['product_id']] = 0
recommended_products[row['product_id']] += similarity_score * row['rating']
# 按推荐分数排序,选择前top_n个产品
recommended_products = sorted(recommended_products.items(), key=lambda x: x[1], reverse=True)[:top_n]
return recommended_products
# 假设我们为用户ID为1的用户推荐5个产品
user_id = 1
recommended = recommend_products(user_id, top_n=5)
# 输出推荐的产品ID及其评分
for product, score in recommended:
print(f"推荐产品ID: {product}, 推荐分数: {score:.2f}")
8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)