java基于RAG构建AI智能客服系统
基于RAG(Retrieval-Augmented Generation)技术,可以有效地构建Java智能问答客服机器人。首先,将包含QA对的Word文档导入系统,通过数据清洗和转换模块将其处理为向量化数据。接着,使用VectorStore接口将这些向量存储并建立索引。当用户提问时,机器人通过DocumentRetriever检索与问题最相关的文档片段,并利用预训练的大模型生成最终的回答。这种方法

整体介绍:
基于RAG(Retrieval-Augmented Generation)技术,可以有效地构建Java智能问答客服机器人。首先,将包含QA对的Word文档导入系统,通过数据清洗和转换模块将其处理为向量化数据。接着,使用VectorStore接口将这些向量存储并建立索引。当用户提问时,机器人通过DocumentRetriever检索与问题最相关的文档片段,并利用预训练的大模型生成最终的回答。这种方法不仅提高了回答的准确性,还增强了系统的灵活性和可扩展性。在Spring AI Alibaba框架下,借助DashScopeApi和ChatClient等组件,能够快速搭建起一个高效、智能的客服解决方案。
目录
src/components/ChatComponent.js
rag介绍:
检索增强生成(RAG)是一种结合了检索模型和生成模型的技术,旨在通过引入私有知识库来辅助大模型的文本生成过程。在使用大模型时,常见的问题是模型可能出现“幻觉”,即生成内容与事实不符,并且由于缺乏对特定企业数据的理解,导致回答不够精准或过于泛化。RAG通过访问私有知识库中的信息,在生成阶段提供更加准确、相关的回应,从而显著改善这些问题。
RAG的主要流程
在RAG(Retrieval-Augmented Generation)中,主要流程可以分为索引构建流程和使用流程两个部分。这两个流程确保了数据能够高效、准确地被处理和利用。
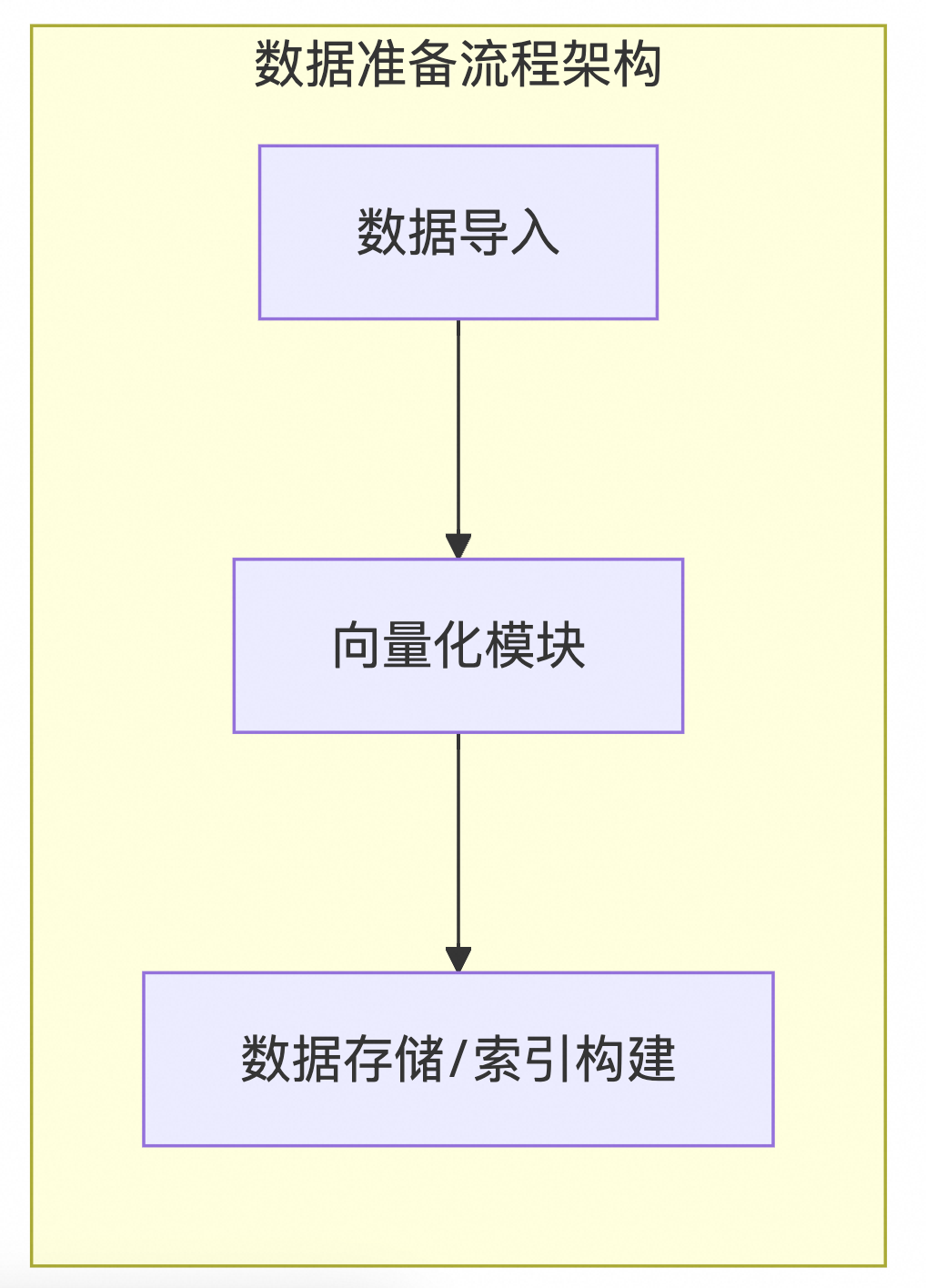
索引构建流程
数据导入阶段,首先从各种数据源收集原始数据,如文本或文档等,随后进行数据清洗,去除噪音并处理缺失值,最后将数据转换为适合向量化处理的格式。接下来是向量化模块,这里会从已经清洗和转换的数据中提取特征,并通过预训练的语言模型(例如BERT、GLP等)或其他自定义算法将其转换成向量表示形式。最后一步是数据存储/索引构建,在此步骤中,向量化后的数据会被存储到数据库或文件系统里,并基于这些数据构建索引来支持快速检索,索引的形式包括但不限于倒排索引、B树或哈希表。
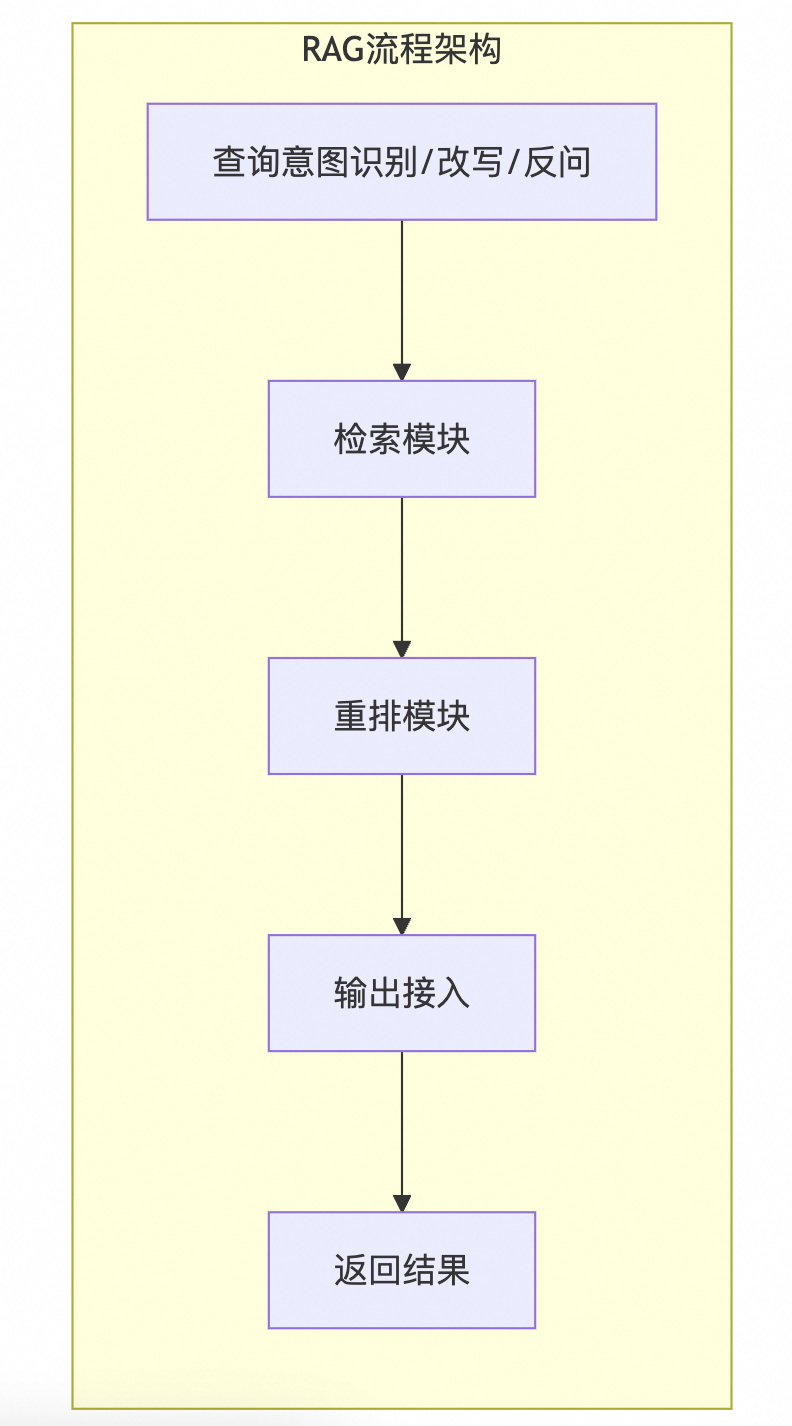
使用流程
当用户提出查询时,首先通过查询意图识别/改写/反问模块来理解用户的需求,这可能涉及对原始问题的改写以提高检索效率,有时还会生成反问来澄清需求。接着,检索模块利用之前创建的索引来查找与用户查询最相关的文档或数据片段。之后,重排模块根据相关性及其他因素对检索结果进行排序,并应用机器学习技术进一步优化排序顺序。紧接着,输出接入模块负责将排序后的信息整合成易于理解的形式,并生成最终的回答准备返回给用户。最后,在返回结果环节,生成的答案被展示给用户,并收集用户的反馈用于后续改进。
通义千问介绍
通义千问是由阿里集团提供的开源大模型服务,支持全尺寸、多模态的大规模模型。在中文开源模型领域中,通义千问具有较高的竞争力。其核心能力体现在以下几个方面:
- 卓越的性能:根据多项客观评测指标(如MMLU、TheoremQA和GPQA等),通义千问超越了Llama 3 70B,显示出了强大的解决问题的能力。它不仅在学术知识、逻辑推理上表现出色,在常识理解和应用上也有不俗的表现。
- 安全性与合规性:通过API调用时,通义千问提供了必要的安全措施来防止恶意攻击,确保用户数据的安全性和隐私保护。
- 完全开放源代码:作为当前最为开放的一个项目之一,通义千问提供了从最小到最大的多种规格的多模态模型供开发者选择使用。无论是对于小型项目还是大型企业级应用来说都非常灵活便捷。
- 经济实惠的价格策略:新用户可以享受到高达100万次免费token的服务,之后继续使用的成本也相对较低;更重要的是,由于它是开源性质的,因此如果自行搭建运行环境的话,理论上是可以实现零成本部署的。
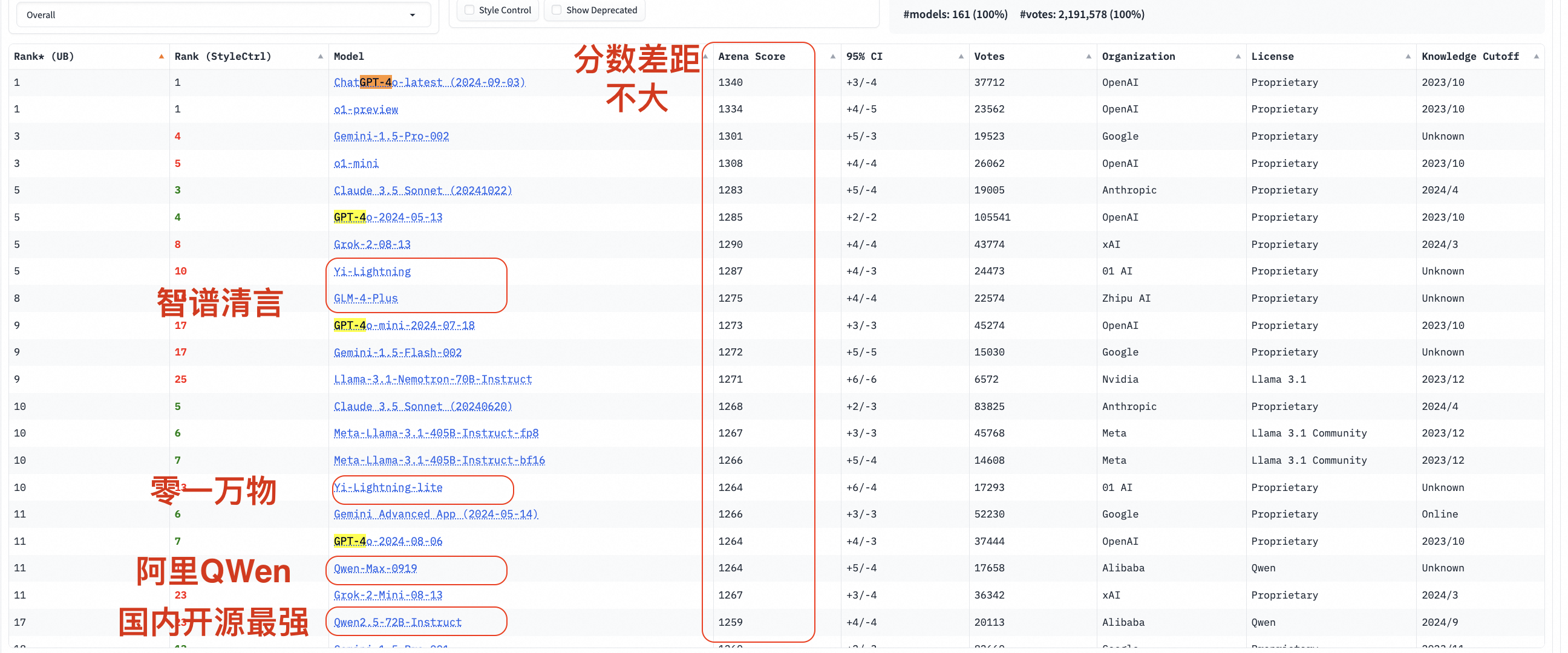
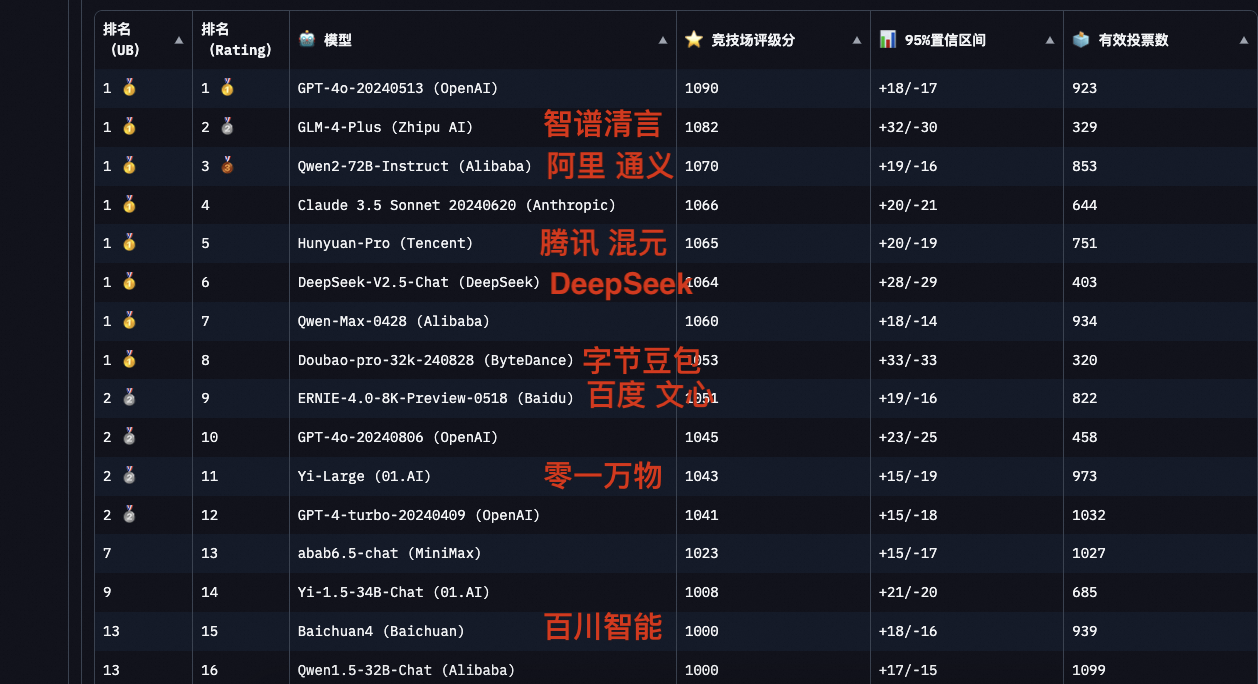
关于通义千问在全球范围内的排名情况,尤其是在国产大模型中的位置,我们可以通过以下链接访问相关平台获取最新信息:
- 思南大模型竞技场 —— 国内权威的人工智能模型评估网站。
- LM Arena —— 国际知名的AI模型评比平台。
![]()
综上所述,无论是在技术实力还是成本效益方面,通义千问都展现出了很强的竞争优势。对于需要利用先进AI技术进行研究或开发项目的个人及组织而言,它无疑是一个值得考虑的选择。
Spring AI Alibaba介绍
Spring AI Alibaba 是由Spring官方团队维护的一个基于Spring AI框架的实现,它专注于阿里云百炼系列云产品的接入。通过提供统一的接口,Spring AI Alibaba极大地简化了开发者在不同AI服务提供商之间切换的成本,支持包括对话、文生图、文生语音等在内的多种生成式模型。此外,它还提供了诸如OutputParser、Prompt Template等功能,使得开发更加便捷高效。作为阿里云的最佳实践之一,Spring AI Alibaba结合了RAG(检索增强生成)能力,允许开发者利用私有或专有数据源来辅助文本生成,非常适合Java开发者快速集成高质量的AI功能到他们的应用程序中。
检索增强的后端代码编写
检索增强的后端代码编写
根据提供的我了解的信息,我们将通过检索增强(RAG)的方式来读取一个名为问答聊天机器人素材.docs的Word文件,并构建向量索引。之后,我们将创建一个对外提供服务的后端接口,其URL地址为http://localhost:8080/ai/ragChat?input=…。首先需要调用buildIndex方法来构建索引。以下是详细的步骤和配置代码。
1. 准备工作
- 环境搭建:确保已安装Spring Boot以及相关的依赖项。
- API密钥:准备好DashScope API密钥,用于与远程向量存储服务通信。
- 文件路径:确定
问答聊天机器人素材.docs文件的具体位置。
2. 创建RAG服务类
我们需要定义一个服务类RagService,该类将负责读取文档、构建向量索引以及处理查询请求。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
public class RagService {
private static final Logger logger = LoggerFactory.getLogger(RagService.class);
private final ChatClient chatClient;
private final VectorStore vectorStore;
private final DashScopeApi dashscopeApi = new DashScopeApi("你的apiKey");
private DocumentRetriever retriever;
public RagService(ChatClient chatClient, EmbeddingModel embeddingModel) {
this.chatClient = chatClient;
vectorStore = new DashScopeCloudStore(dashscopeApi,
new DashScopeStoreOptions("问答聊天机器人素材"));
retriever = new DashScopeDocumentRetriever(dashscopeApi,
DashScopeDocumentRetrieverOptions.builder().withIndexName("问答聊天机器人素材").build());
}
private static final String DEFAULT_USER_TEXT_ADVISE = """
上下文信息如下。
---------------------
{documents}
---------------------
根据上下文和提供的历史信息,而不是先前的知识,
回复用户的评论。如果答案不在上下文中,请告知
用户你无法回答这个问题。
""";
public String buildIndex() {
String filePath = "/path/to/问答聊天机器人素材.docs"; // 替换为实际文件路径
DocumentReader reader = new DashScopeDocumentCloudReader(filePath, dashscopeApi, null);
List<Document> documentList = reader.get();
vectorStore.add(documentList);
return "SUCCESS";
}
public StreamResponseSpec queryWithDocumentRetrieval(String message) {
StreamResponseSpec response = chatClient.prompt().user(message)
.advisors(new DocumentRetrieverAdvisor(retriever, DEFAULT_USER_TEXT_ADVISE)).stream();
return response;
}
}3. 创建控制器类
接下来,我们创建一个控制器类RagController,用于处理HTTP请求并调用RagService中的方法。
import org.springframework.http.HttpServletResponse;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/ai")
public class RagController {
private final RagService ragService;
public RagController(RagService ragService) {
this.ragService = ragService;
}
@GetMapping("/ragChat")
public Flux<String> generate(@RequestParam(value = "input", defaultValue = "2024年6月止,云智能集团的营收是多少?") String message,
HttpServletResponse httpResponse) {
StreamResponseSpec chatResponse = ragService.queryWithDocumentRetrieval(message);
httpResponse.setCharacterEncoding("UTF-8");
return chatResponse.content();
}
@GetMapping("/buildIndex")
public String buildIndex() {
return ragService.buildIndex();
}
}4. 配置Spring Boot应用程序
确保在application.properties或application.yml中正确配置了相关属性,并且在主类中注入了必要的组件。
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class RAGApplication {
public static void main(String[] args) {
SpringApplication.run(RAGApplication.class, args);
}
@Bean
public ChatClient chatClient() {
return new ChatClient(); // 实现ChatClient的具体实例
}
@Bean
public EmbeddingModel embeddingModel() {
return new EmbeddingModel(); // 实现EmbeddingModel的具体实例
}
}检索增强的前端代码编写
在构建一个支持流输出的前端项目时,主要依赖于React框架,并且需要处理来自后端接口的数据流。基于提供的我了解的信息,我们可以按照以下步骤进行:
构建项目并填写代码
首先,确保你已经安装了Node.js和npm。接着,创建一个新的 React 应用并安装所需的依赖:
npx create-react-app frontend
cd frontend
npm installpublic/index.html
这是项目的主HTML文件,无需做特别修改。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Chat App</title>
</head>
<body>
<div id="root"></div>
</body>
</html>
src/index.js
此文件负责渲染应用的根组件到DOM中。
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
ReactDOM.render(
<React.StrictMode>
<App />
</React.StrictMode>,
document.getElementById('root')
);src/App.js
定义了App组件,它将显示我们的聊天组件。
import React from 'react';
import ChatComponent from './components/ChatComponent';
function App() {
return (
<div className="App">
<ChatComponent />
</div>
);
}
export default App;src/components/ChatComponent.js
这是核心部分,实现了用户输入消息、发送请求给后端以及展示接收到的消息的功能。
import React, { useState } from 'react';
function ChatComponent() {
const [input, setInput] = useState('');
const [messages, setMessages] = useState('');
const handleInputChange = (event) => {
setInput(event.target.value);
};
const handleSendMessage = async () => {
try {
// 后端接口地址,请确保已启用CORS
const response = await fetch(`http://localhost:8080/ai/ragChat?input=${input}`);
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
let done = false;
while (!done) {
const { value, done: readerDone } = await reader.read();
done = readerDone;
const chunk = decoder.decode(value, { stream: true });
setMessages((prevMessages) => prevMessages + chunk);
}
// 请求结束后添加换行符以区分不同会话
setMessages((prevMessages) => prevMessages + '\n\n=============================\n\n');
} catch (error) {
console.error('Failed to fetch', error);
}
};
const handleClearMessages = () => {
setMessages('');
};
return (
<div>
<input
type="text"
value={input}
onChange={handleInputChange}
placeholder="Enter your message"
/>
<button onClick={handleSendMessage}>Send</button>
<button onClick={handleClearMessages}>Clear</button>
<div>
<h3>Messages:</h3>
<pre>{messages}</pre>
</div>
</div>
);
}
export default ChatComponent;运行项目
完成上述配置与编码之后,你可以通过如下命令启动你的前端应用:
cd frontend
npm start这将开启开发服务器,默认情况下会在http://localhost:3000上运行。
以上步骤涵盖了从环境准备到具体实现再到最终部署整个过程所需的所有信息。关键在于如何正确地处理流式数据(通过读取响应体中的数据块),并在每次接收新数据时更新UI,从而实现实时显示效果。注意检查网络请求是否成功及后端服务是否正确设置跨源资源共享(CORS),这对于前端能够顺利访问API至关重要。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 30
30 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)