微服务 - 学习笔记
微服务是分布式架构的一种形式。早期的软件系统通常是基于单体应用架构设计的,也就是将整个系统作为一个单一的、可执行的应用程序来构建和维护。随着互联网的不断发展,软件系统的架构也是在不断的更新。由原先的单体架构逐渐演变成分布式系统架构,再到目前非常主流的微服务系统架构。分布式系统架构是指将一个软件系统分割成多个独立的服务,并且这些服务可以在不同的计算机或服务器上运行,并通过网络进行通信。微服务系统架构
一、介绍
1.1、技术介绍
1.1.1、系统架构演进
1.项目整体架构
- 单体架构:项目的页面和项目的后端都在一个工程里。
- 好处:所有的功能和内容都在一个项目里。
- 坏处:一旦有功能或页面更新,那么整个项目都要重启更新。
- 前后端分离架构:
- 前端是独立的项目。后端也是独立的项目。 前后端通过API的方式进行请求。
- 前后端各司其职。
- 当下还是单体架构:将一个项目的所有功能模块维护在一个项目里。
- 后端某一个模块挂了。会影响全局。
- 集群:
- 服务器大于等于2台。
- 多台服务器,部署的内容是相同的。
- 压力分摊,提高高可用性。
- 服务更新,所有集群都要更新。
- 每个项目都变成了高耦合。低内聚。
- 分布式:
- 多台服务器部署不同的内容。 逻辑上每个服务器部署的项目还是单体架构
- 低耦合、高内聚。
- 多台服务器之间强调的是:内聚时,可以通过远程调用。提供不同的服务。
- 微服务:
- 将一个完整的项目,按照功能模块的方式进行划分,拆分成一个个独立的模块(项目),每个模块独立运行,独立使用自己的数据库,每个模块也可以使用不同的技术进行开发。
- 微服务是分布式部署的。
- 分布式微服务架构项目
- 区别:分布式更在乎的是将不同的服务部署在不同的服务器上,通过远程调用的方式进行通信。微服务更在乎的是站在软件系统的角度,按照功能和模块拆分成独立的小项目。
微服务是分布式架构的一种形式。
2.单体架构
早期的软件系统通常是基于单体应用架构设计的,也就是将整个系统作为一个单一的、可执行的应用程序来构建和维护。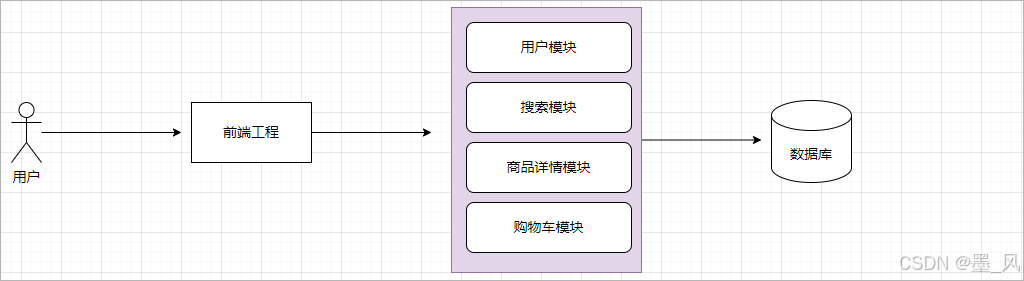
- 单体架构具有以下优点:
- 简单:单体架构模式相对于其他复杂的架构来说,其结构简单易用,便于新手学习和应用。
- 易于维护:由于整个应用程序都在一个代码库中,因此很容易对其进行维护和更新。
- 易于部署:单个可执行文件可以在任何支持运行该语言的环境中运行,并且部署也相对轻松。
- 然而,单体架构也存在一些缺点:
- 扩展性差:单体应用程序所有功能都在一个程序中实现,因此扩展功能时需要新增或修改源代码,并重新部署整个应用程序,这可能会导致系统不稳定和长时间停机。
- 可靠性低:由于单体应用程序集成了所有的逻辑和组件,因此如果其中有一个非常重要的组件出现故障,则可能导致从整个系统崩溃。
- 风险高:单体应用程序中的错误往往比较难以调试,因为代码复杂度高且耦合度强。 综上所述,单体架构适用于小型、简单的软件系统,但是对于大型、复杂的系统来说,单体架构面临诸多挑战,需要采用其他更加灵活和可扩展的架构模式。
3.微服务架构
随着互联网的不断发展,软件系统的架构也是在不断的更新。由原先的单体架构逐渐演变成分布式系统架构,再到目前非常主流的微服务系统架构。
分布式系统架构是指将一个软件系统分割成多个独立的服务,并且这些服务可以在不同的计算机或服务器上运行,并通过网络进行通信。
微服务系统架构:本质上也属于分布式系统架构,在微服务系统架构中,更加重视的是服务拆分粒度。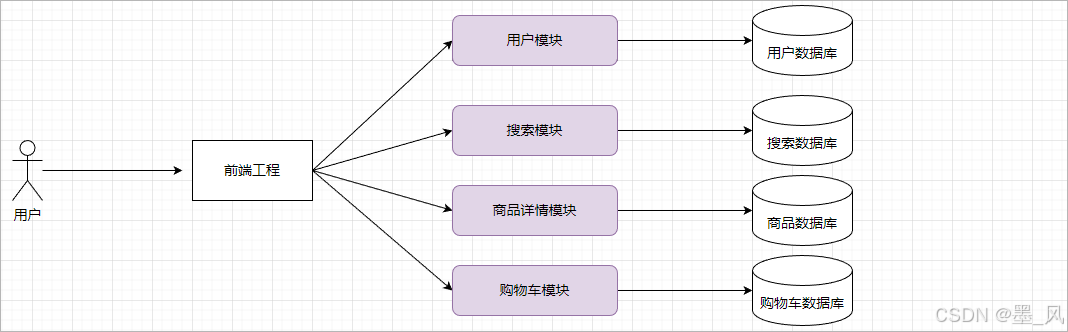
- 微服务架构的特点:
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责。
- 自治:团队独立、技术独立、数据独立,独立部署和交付。
- 面向服务:服务提供统一标准的接口,与语言和技术无关
- 微服务系统架构的优点:
- 可扩展性好:由于系统中的不同组件可以独立地进行扩展和升级,从而提高了整个系统的扩展性和可靠性。
- 容错性高:由于系统中的组件可以在不同的计算机或服务器上运行,因此即使某些节点出现故障也不会影响整个系统的运行。
- 高效性强:分布式系统可以将负载和任务分配到不同的节点上,从而提高系统的并发能力和处理速度。
- 灵活性强:分布式系统可以支持多种编程语言和应用程序框架,并且可以利用各种云计算技术,如Docker、Kubernetes等。
- 微服务系统架构的存在的问题:
- 微服务的管理:这些微服务如果没有进行统一的管理,那么维护性就会极差。
- 服务间的通讯:微服务之间肯定是需要进行通讯,比如购物车微服务需要访问商品微服务。
- 前端访问问题:由于每一个微服务都是部署在独立的一台服务器的,每一个微服务都存在一个对应的端口号,前端在访问指定微服务的时候肯定需要指定微服务的ip地址和端口号,难道需要在前端维护每一个微服务的ip地址和端口号。
- 配置文件管理:当构建服务集群的时候,如果每一个微服务的配置文件还是和微服务进行绑定,那么维护性就极差。
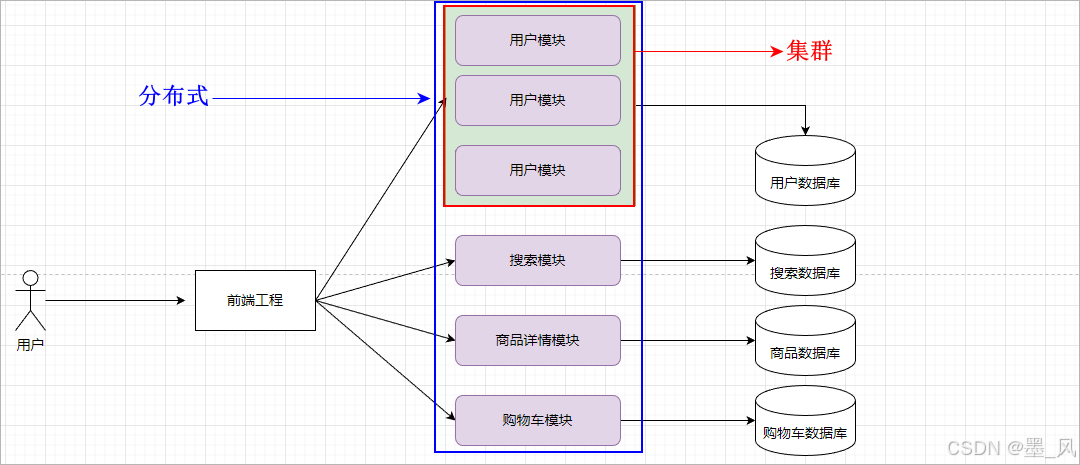
4.分布式和集群
- 分布式:由多台服务器构成的网络环境,在分布式环境下每一台服务器的功能是不一样的。
- 集群: 由多台服务器构成的网络环境,在集群环境下每一台服务器的功能是一样的。
- 分布式环境中每一台服务器都可以做集群,如下图所示:
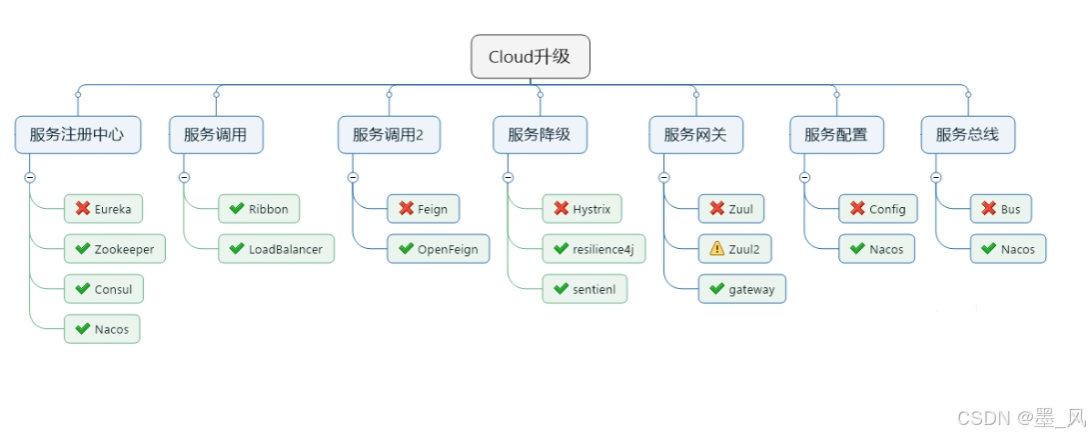
1.1.2、对应技术

1.1.3、市面上实践
框里是springCloud,框外是第三方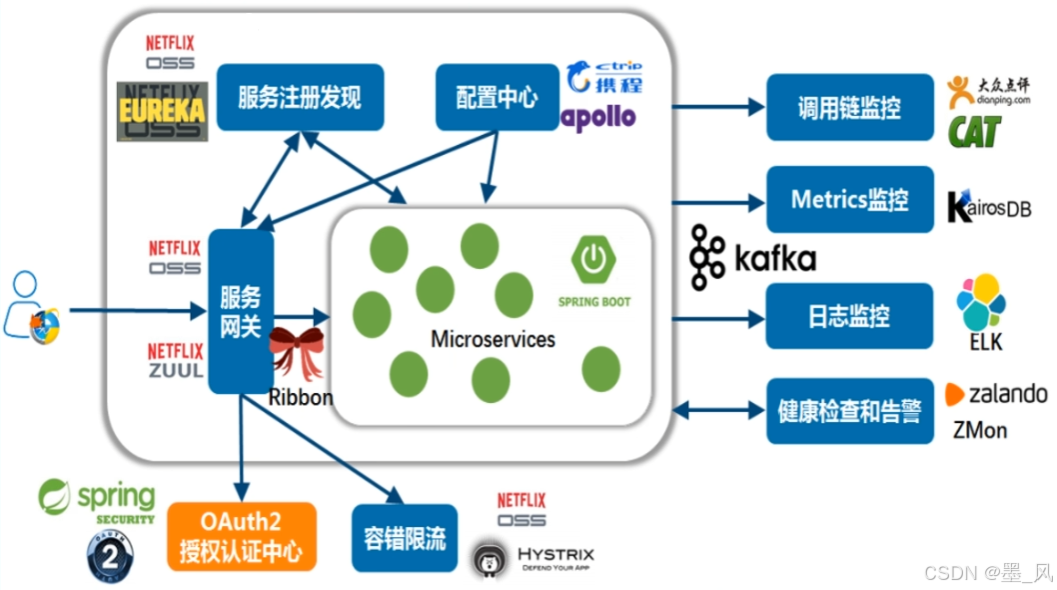
1.2、SpringCloud
1.2.1、介绍
- Spring Cloud 是一系列框架的有序集合。在Spring Cloud这个项目中包含了很多的组件【子框架】,每一个组件都是用来解决问题系统架构中所遇到的问题,因此Spring Cloud可以看做是一套微服务的解决方案。
- 官网
1.2.2、版本对应
SpringCloud基于SpringBoot实现了微服务组件的自动装配,从而提供了良好的开箱即用体验。但对于SpringBoot的版本也有要求: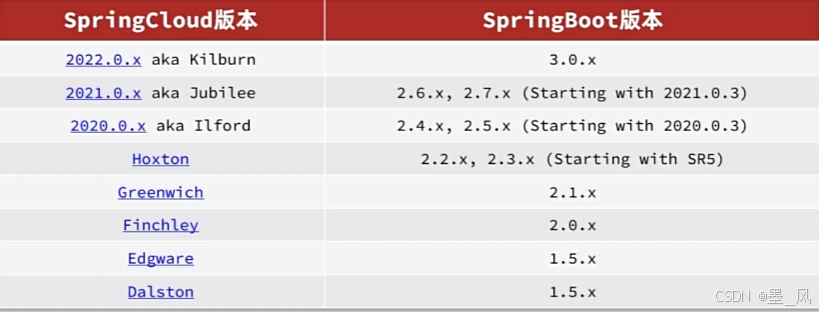
1.3、Spring Cloud Alibaba简介
- Spring Cloud Alibaba是阿里针对微服务系统架构所存在的问题给出了一套解决方案,该项目包含了微服务系统架构必须的一些组件。
- 官网地址
- 版本对应关系
- 注意:
- Spring Cloud Alibaba中所提供的组件是遵循Spring Cloud规范的,两套技术所提供的组件是可以搭配使用的。
- 在现在企业开发中往往是两套技术组件搭配进行使用:Nacos(服务注册中心和配置中心)、Openfeign(远程调用)、Ribbon(客户端负载均衡器)、Gateway(服务网关)、Sentinel(服务保护组件)等。
1.4、微服务拆分原则
- 拆分时机
- 创业型项目:先采用单体架构,快速开发,快速试错。随着规模扩大,逐
渐拆分。 - 确定的大型项目:资金充足,目标明确,可以直接选择微服务架构,避免
后续拆分的麻烦。
- 创业型项目:先采用单体架构,快速开发,快速试错。随着规模扩大,逐
- 拆分目标
- 高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。
- 低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖。
- 拆分方式
- 纵向拆分:按照业务模块来拆分。
- 横向拆分:抽取公共服务,提高复用性。
二、微服务工程创建
2.1、父工程
2.1.1、依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 父项目基本信息 -->
<groupId>com.mofeng</groupId>
<artifactId>cloud-parent</artifactId>
<version>1.0.0</version>
<packaging>pom</packaging> <!-- 父项目必须是 pom 类型 -->
<name>cloud-demo</name>
<description>cloud-demo</description>
<!-- 通用配置 -->
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring.cloud.version>2023.0.3</spring.cloud.version>
<spring.cloud.alibaba.version>2023.0.3.2</spring.cloud.alibaba.version>
<spring.boot.version>3.3.4</spring.boot.version>
<mybatis-springboot.version>3.0.1</mybatis-springboot.version>
<mysql.version>8.0.30</mysql.version>
<!-- <hutool.version>5.8.22</hutool.version>-->
<!-- <junit.version>4.12</junit.version>-->
<!-- <log4j.version>1.2.17</log4j.version>-->
<!-- <lombok.version>1.18.26</lombok.version>-->
<!-- <druid.version>1.1.20</druid.version>-->
<!-- <swagger3.version>2.2.0</swagger3.version>-->
<!-- <mapper.version>4.2.3</mapper.version>-->
<!-- <fastjson2.version>2.0.40</fastjson2.version>-->
<!-- <persistence-api.version>1.0.2</persistence-api.version>-->
<!-- <spring.boot.test.version>3.1.5</spring.boot.test.version>-->
</properties>
<!-- 指定spring boot父工程 -->
<parent>
<artifactId>spring-boot-starter-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>3.3.4</version>
</parent>
<!-- 子模块声明 -->
<modules>
<!-- <module>services</module>-->
</modules>
<!-- 1、只是声明依赖,并不实际引入,子项目按需声明使用的依赖 -->
<!-- 2、子项目可以继承父项目的 version 和 scope -->
<!-- 3、子项目若指定了 version 和 scope,以子项目为准 -->
<dependencyManagement>
<dependencies>
<!--spring boot -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring.boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring.cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud alibaba-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring.cloud.alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- mysql的驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- mybatis和spring boot整合的起步依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis-springboot.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
</plugin>
</plugins>
</build>
</project>
2.2、子模块
2.2.1、层级结构
2.2.2、依赖
2.2.3、补充说明
1、dependencyManagement
Maven使用dependencyManagement元素来提供了一种管理依赖版本号的方式。通常会在一个组织或者项目的最顶层的父POM中看到dependencyManagement元素。使用pom.xml中的dependencyManagement元素能让所有在子项目中引l用一个依赖而不用显式的列出版本号。Maven会沿着父子层次向上走,直到找到一个拥有dependencyManagement元素的项目,然后它就会使用这个dependencyManagement元素中指定的版本号。子工程有的话就直接用子工程的。
2.3、总结
微服务模块
- 建module
- 改POM
- 写YML
- 主启动
- 业务类
2.4、热部署
2.4.1、引入依赖
<!--热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
2.4.2、导入Maven插件
<build>
<finalName>${project.name}</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
</plugin>
</plugins>
</build>
2.4.3、设置idea
1.设置中配置
2.注册表设置
快捷键ctrl + shift + alt + /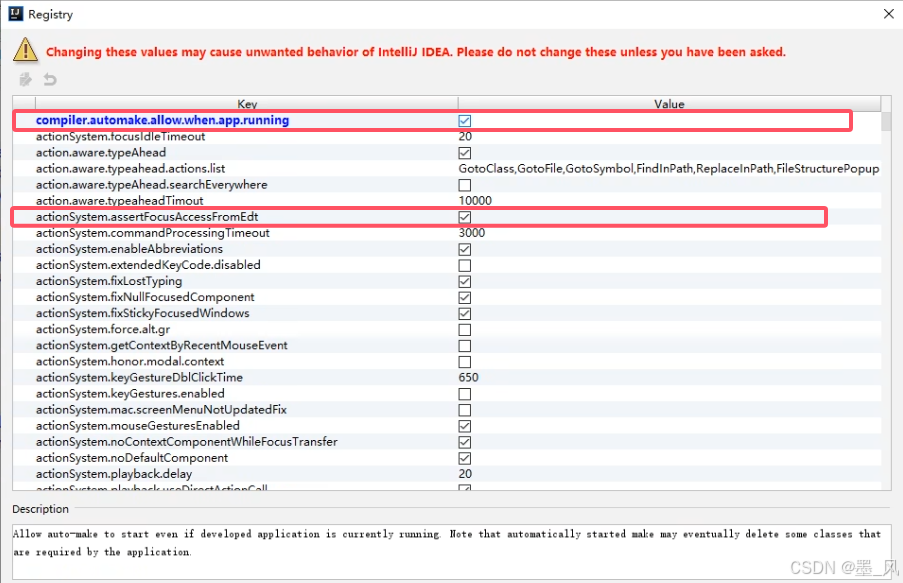
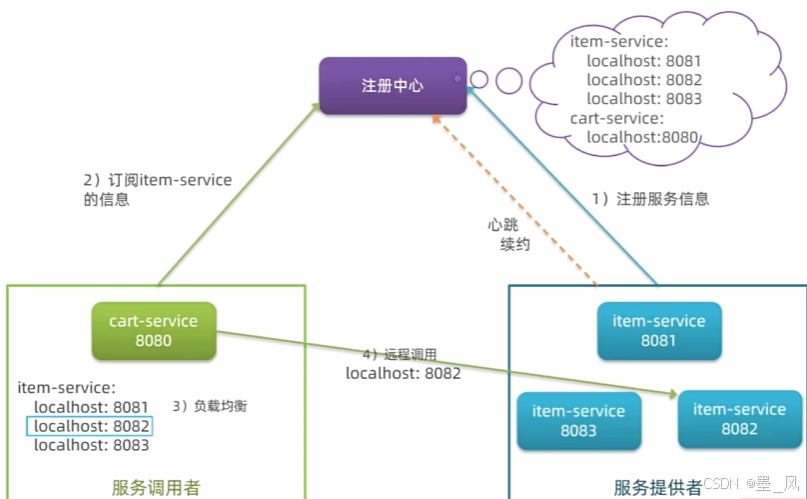
三、注册中心
- 服务治理:在传统的rpc远程调用框架中,管理每个服务与服务之间依赖关系比较复杂,管理比较复杂,所以需要使用服务治理,管理服务于服务之间依赖关系,可以实现服务调用、负载均衡、容错等,实现服务发现与注册。
- 服务提供者:暴露服务接口,供其它服务调用。
- 服务消费者:调用其它服务提供的接口。
- 注册中心:记录并监控微服务各实例状态,推送服务变更信息。
3.1、Nacos注册中心
3.1.1、介绍
Nacos是Dynamic Naming and Configuration Service的首字母简称,一个更易于构建云原生应用的动态服务发现、配置管
理和服务管理平台。- 官网:
https://nacos.io/zh-cn/docs/v2/quickstart/quick-start.html - 启动命令:
startup.cmd-m standalone - 访问地址:http://IP:8848/nacos
- 注意大坑:docker安装的时候,会配置几个端口映射,千万不要改端口映射,不然会注册不到。
3.1.2、服务注册
- 流程:
- 启动微服务:SpringBoot微服务web项目启动
- 引入服务发现依赖:
spring-cloud-starter-alibaba-nacos-discovery
- 配置
Nacos地址:spring.cloud.nacos.server-addr=127.0.0.1:8848 - 查看注册中心效果:访问
http://ocalhost:8848/nacos - 集群模式启动测试:单机情况下通过改变端口模拟微服务集群。
3.1.3、服务发现
- 启动类加
@EnableDiscoveryClient开启服务发现功能。
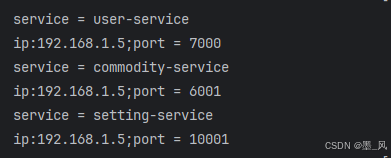
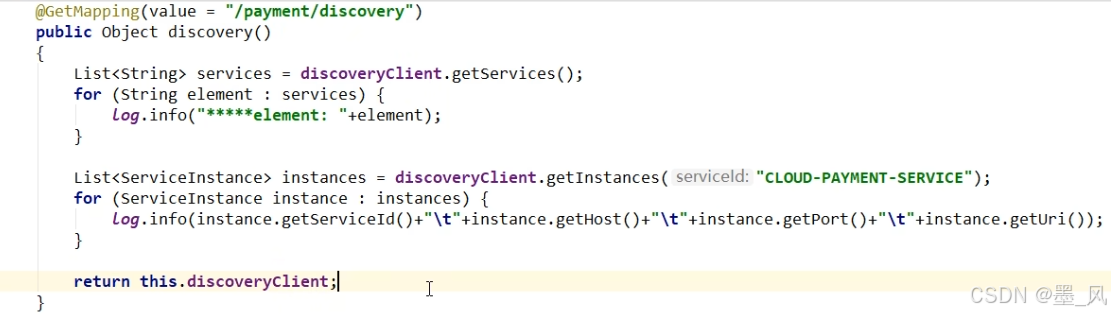
1、DiscoveryClient(标准规范)
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import java.util.List;
@SpringBootTest
class SettingServiceApplicationTests {
@Test
void contextLoads() {
}
@Autowired
DiscoveryClient discoveryclient;
@Test
void discoveryClientTest() {
for (String service : discoveryclient.getServices()) {
System.out.println("service = " + service);
//获取ip+port
List<ServiceInstance> instances = discoveryclient.getInstances(service);
for (ServiceInstance instance : instances) {
System.out.println("ip:" + instance.getHost() + ";" + "port = " + instance.getPort());
}
}
}
}
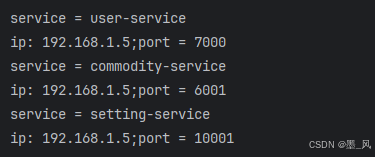
2、NacosServiceDiscovery (Nacos专属)
import com.alibaba.cloud.nacos.discovery.NacosServiceDiscovery;
import com.alibaba.nacos.api.exception.NacosException;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import java.util.List;
@SpringBootTest
class SettingServiceApplicationTests {
@Test
void contextLoads() {
}
@Autowired
NacosServiceDiscovery nacosServiceDiscovery;
@Test
void nacosServiceDiscoveryTest() throws NacosException {
for (String service : nacosServiceDiscovery.getServices()) {
System.out.println("service = " + service);
List<ServiceInstance> instances = nacosServiceDiscovery.getInstances(service);
for (ServiceInstance instance : instances) {
System.out.println("ip: " + instance.getHost() + ";" + "port = " + instance.getPort());
}
}
}
}
3、注解版本(负载均衡)
- 负载均衡注解
<!--负载均衡-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
- 远程调用配置类
@Configuration
public class RestTemplateConfig {
@LoadBalanced//负载均衡注解
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
- 示例代码
@Test
void templateTest() {
String url = "http://commodity-service/heath";
R o = restTemplate.getForObject(url, R.class);
System.out.println(o);
}

3.1.4、注册中心宕机后
- 调用过(存在缓存),远程调用不在依赖注册中心,可以通过。
- 没调用过(第一次发起远程调用),不能通过。
3.1.5、总结

3.2、Eureka注册中心
3.2.1、介绍
Eureka采用了CS的设计架构,EurekaServer作为服务注册功能的服务器,它是服务注册中心。而系统中的其他微服务,使用Eureka的客户端连接到Eureka Server并维持心
跳连接。这样系统的维护人员就可以通过EEureka Server来监控系统中各个微服务是否正常运行。- 在服务注册与发现中,有一个注册中心。当服务器启动的时候,会把当前自己服务器的信息比如服务地址通讯地址等以别名方式注册到注册中心上。另一方(消费者服务提供
者),以该别名的方式去注册中心上获取到实际的服务通讯地址,然后再实现本地RPC调用RPC远程调用框架核心设计思想:在于注册中心,因为使用注册中心管理每个服务与
服务之间的一个依赖关系(服务治理概念)。在任何rpc远程框架中,都会有一个注册中心(存放服务地址相关信息(接口地址)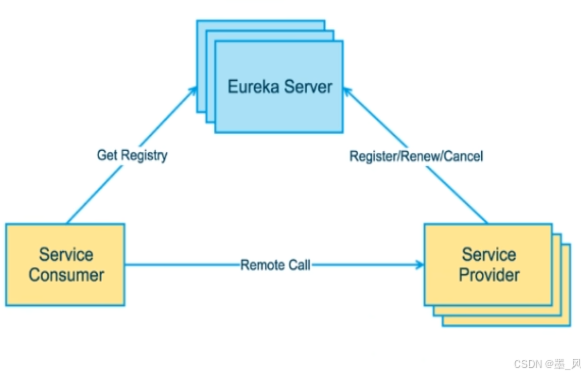
EurekaServer提供服务注册服务:各个微服务节点通过配置启动后,会在Eureka Server中进行注册,这样Eureka Server中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观看到。EurekaClient通过注册中心进行访问:是一个Java客户端,用于简化Eureka Server的交互,客户端同时也具备一个内置的、使用轮询(round-robin)负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒)。如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除(默认90秒)。
3.2.2、搭建Eureka Server
1、pom文件
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
<version>4.1.2</version>
</dependency>
2、yml
spring:
application:
name: mofeng-eureka
server:
port: 7001
eureka:
instance:
hostname: localhost #eureka服务端的实例名称
client:
register-with-eureka: false # 单机模式不注册自己
fetch-registry: false # 单机模式不获取注册表
service-url:
# Eureka Server 交互的地址查询服务和注册服务都需要依赖这个地址
defaultZone: http://${eureka.instance.hostname):${server.port)/eureka/
3、application.java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class MofengEurekaApplication {
public static void main(String[] args) {
SpringApplication.run(MofengEurekaApplication.class, args);
}
}
4、检查
3.2.3、搭建Eureka Client
1、pom文件
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
<version>4.1.2</version>
</dependency>
2、yml
eureka:
client:
#表示是否将自己注册进EurekaServer默认为true。
register-with-eureka: true
#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡
fetchRegistry: true
service-url:
defaultZone: http://localhost:7001/eureka
3、application.java
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaClient
public class MofengEurekaApplication {
public static void main(String[] args) {
SpringApplication.run(MofengEurekaApplication.class, args);
}
}
4、检查

3.2.4、Server集群搭建
1、注意
本地搭建的话,记得改下host配置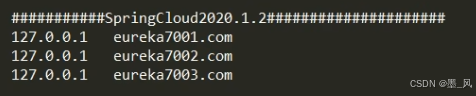
2、Server的yml文件修改(其他不用改)
7001端口
7002端口
3、client yml配置(其他不用改)

3.2.5、服务信息补充完整(带服务名和IP)
必须包含的依赖
配置文件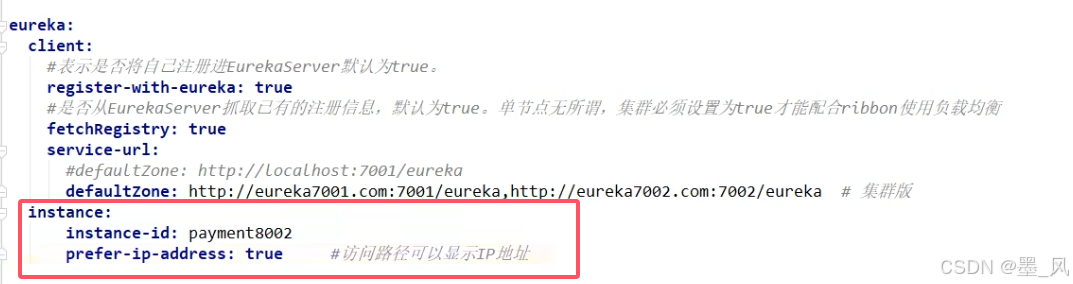
3.2.6、服务发现
- 需要在启动类上加注解:
@EnableDiscoverClient - 示例代码
四、配置中心
4.1、Nacos配置中心
4.1.1、介绍
当微服务部署的实例越来越多,达到数十、数百时,逐个修改微服务配置就显得十分的不方便,而且很容易出错。我们需要一种统一配置管理方案,可以集中管理所有实例的配置。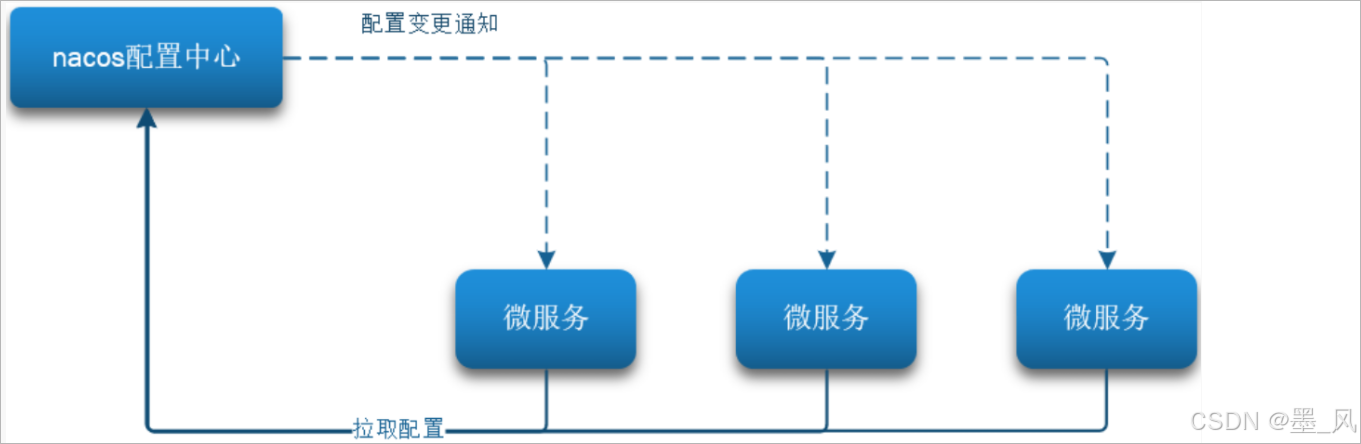
Nacos是Dynamic Naming and Configuration Service的首字母简称,一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。nacos一方面可以将配置集中管理,另一方可以在配置变更时,及时通知微服务,实现配置的热更新。- 官网:
https://nacos.io/zh-cn/docs/v2/quickstart/quick-start.html - 启动命令:
startup.cmd-m standalone - 访问地址:http://IP:8848/nacos
- 配置生效顺序:配置中心(多个则先声明优先) > 配置文件
- 注意大坑:docker安装的时候,会配置几个端口映射,千万不要改端口映射,不然会注册不到。
4.1.2、使用流程
-
注意事项:
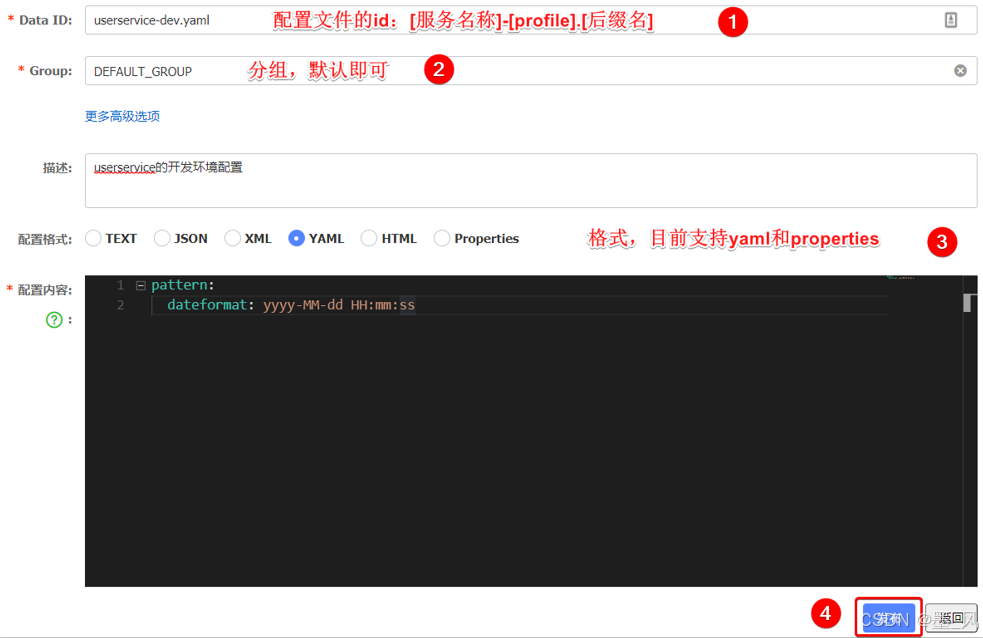
- 配置文件的id设置规则:
[服务名称]-[prefile(环境,测试开发还是生产环境)].[后缀名]
- 配置文件的id设置规则:
-
启动
Nacos(本章示例版本3.0.1 ) -
引入依赖
<!--Nacos 配置中心-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
application.properties配置
spring:
config:
import:
- nacos:userserve-dev.yml # 导入配置
cloud:
nacos:
config:
import-check:
enabled: false # 禁止导入检查,不然不导入配置就会报错
-
创建
data-id(数据集)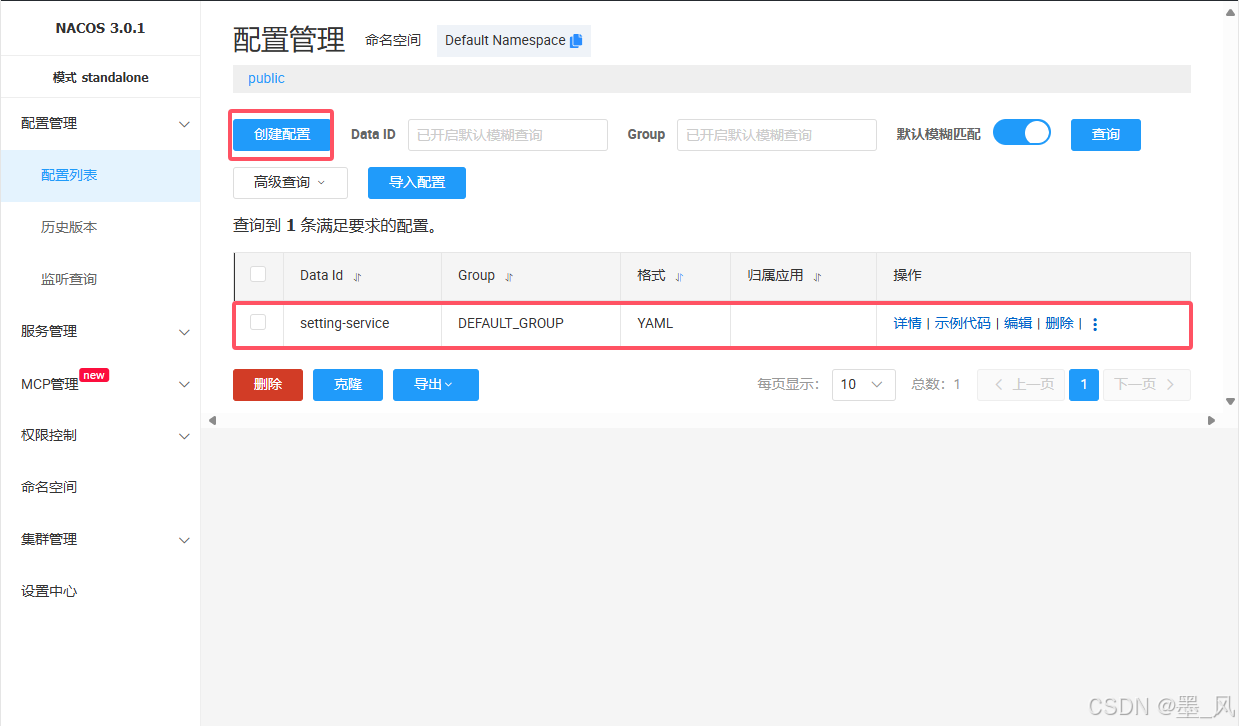
-
测试结果
启动

4.1.3、读取自定义配置
1.@Value代码
@RestController
@RequestMapping(value = "/api/user")
@Slf4j
public class UserController {
@Value("${pattern.dateformat}")
private String pattern ;
}
}
2.@ConfigurationProperties
也可以通过实体类,配合@ConfigurationProperties注解读取自定义配置,代码如下所示:
- 定义一个实体类,代码如下所示:
@Data
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat ;
}
- 在启动类上添加@EnableConfigurationProperties注解,如下所示:
@SpringBootApplication
@EnableConfigurationProperties(value = { PatternProperties.class })
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class , args) ;
}
}
- 使用该实体类,代码如下所示:
@RestController
@RequestMapping(value = "/api/user")
@Slf4j
public class UserController {
@Autowired // 注入实体类
private PatternProperties patternProperties ;
}
4.1.4、配置更新
1.配置热更新
最终的目的,是修改Nacos中的配置后,微服务中无需重启即可让配置生效,也就是配置热更新。实现配置的热更新有两种方式:
- 方式一:在@Value注入的变量所在类上添加注解**@RefreshScope**
@RestController
@RequestMapping(value = "/api/user")
@Slf4j
@RefreshScope
public class UserController {
@Value("${pattern.dateformat}")
private String pattern;
}
}
- 方式二:通过实体类,配合
@ConfigurationProperties注解读取配置信息,自动支持热更新
2.监听配置变化
- 代码
@Bean
public ApplicationRunner applicationRunner(NacosConfigManager nacosConfigManager) {
return args -> {
ConfigService configService = nacosConfigManager.getConfigService();
configService.addListener("Data Id", "Group", new Listener() {
@Override
public Executor getExecutor() {
return Executors.newFixedThreadPool(5);
}
@Override
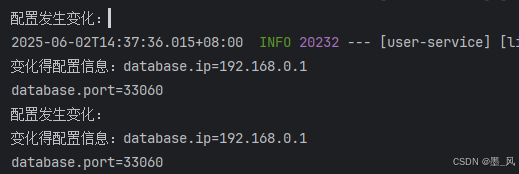
public void receiveConfigInfo(String configInfo) {
System.out.println("配置发生变化:");
System.out.println("变化得配置信息:" + configInfo);
}
});
System.out.println("开始监听配置变化信息");
};
}
- 结果
4.1.5、数据隔离
1、隔离规则
2、按需加载
spring:
profiles:
active: dev
application:
name: user
cloud:
nacos:
server-addr: 192.168.1.10:8848
username:
password:
config:
enabled: false # 关闭自动加载配置
namespace: ${spring.profiles.active:public}
---
spring:
config:
import:
- nacos:common?group=common
- nacos:user-service?group=user
activate:
on-profile: dev # 不同模式下加载不同的配置文件
---
spring:
config:
import:
- nacos:common?group=common
- nacos:user?group=user
- nacos:database?group=user
activate:
on-profile: prod
4.1.6、总结
- 引入
spring-cloud-starter-alibaba-nacos-config依赖,配置Nacos地址。 - 添加数据集(data-id),使用
spring.config.import导入数据集 @Value+@RefreshScope取值+自动刷新@ConfigurationProperties批量绑定自动刷新NacosConfigManager监听配置变化- 配置优先级:Nacos配置中心的配置(后导入的配置 > 先导入的配置) > application.yml
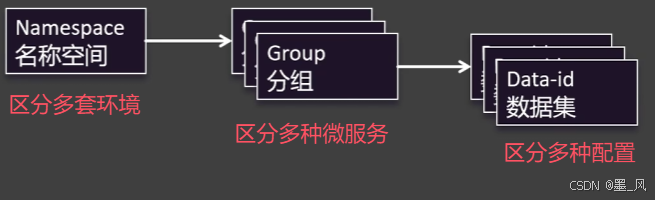
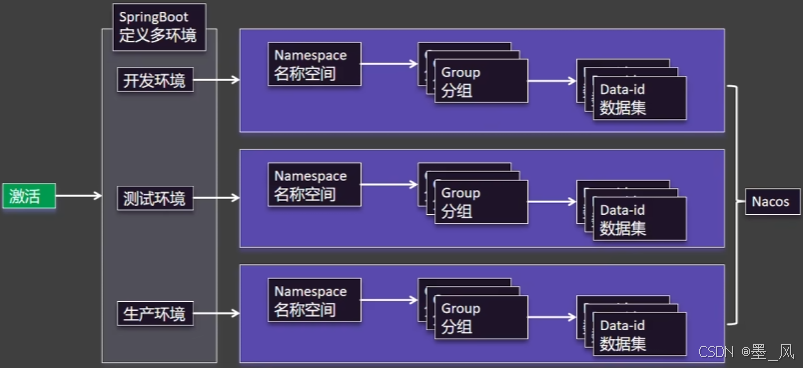
- namespace区分环境、group区分
微服务、data-id区分配置实现数据隔离+环境切换。
五、远程调用
5.1、OpenFeign
5.1.1、介绍
OpenFeign是Spring Cloud原生组件,是声明式REST客户端(RestTemplate是编程式REST客户端),其作用就是帮助我们优雅的实现http请求的发送。- 官方地址:
https://github.com/OpenFeign/feign - 注解驱动
- 指定远程地址:
@FeignClient… - 指定请求方式:
@GetMapping、@PostMapping、@DeleteMapping… - 指定携带数据:
@RequestHeader、@RequestParam、@RequestBody… - 指定结果返回:响应模型。
- 指定远程地址:
5.1.2、基本使用
1.导入依赖
pom文件中引入OpenFeign的依赖
<!-- 加入OpenFeign的依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
2.启动类添加注解
启动类加@EnableFeignClients//开启Feign远程调用功能注解。
@SpringBootApplication
@EnableFeignClients//开启Feign远程调用功能
public class OrderService10000 {
public static void main(String[] args) {
SpringApplication.run(OrderService10000.class,args);
}
}
3.编写OpenFeign的客户端
- 编写接口,之后就可以直接调用的
@FeignClient(value = "服务名") //指定调用的服务在nacos中的名字
public interface CommodityFeignClient {
@GetMapping("/api/user/findUserByUserId/{userId}")
public abstract User queryById(@PathVariable("userId") Long userId) ; // 根据userId查询用户信息的接口方法
}
//"http://服务名/api/user/findUserByUserId/{userId}"
- 这个客户端主要是基于SpringMVC的注解来声明远程调用的信息,比如:
- 请求方式:GET
- 请求路径:
/api/user/findUserByUserId/{userId} - 请求参数:Long userId
- 返回值类型:User
这样,Feign就可以帮助我们发送http请求,无需自己使用RestTemplate来发送了。
4.使用Feign客户端
修改OrderService中的远程调用代码,使用Feign客户端代替RestTemplate:
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper ;
@Autowired
private UserFeignClient userFeignClient ;
@Override
public Order findOrderByOrderId(Long orderId) {
Order order = orderMapper.findOrderByOrderId(orderId);
// 远程调用
User user = userFeignClient.queryById(order.getUserId());
order.setUser(user);
return order ;
}
}
5.1.3、调用第三方服务
contextId:客户端名称,不配置默认就是value
@FeignClient(value = "weather-client", contextId = "weather-client", url = "http://aliv18.data.moji.com")
public interface WeatherFeignClient {
@PostMapping("/whapi/json/alicityweather/condition")
String getWeather(@RequestHeader("Authorization") String auth,
@RequestParam("token") String token,
@RequestParam("cityId") String cityId);
}
@FeignClient(value = "weather-client", url = "http://aliv18.data.moji.com")
public interface WeatherFeignClient {
@PostMapping("/whapi/json/alicityweather/condition")
String getWeather(@RequestHeader("Authorization") String auth,
@RequestParam("token") String token,
@RequestParam("cityId") String cityId);
}
5.1.4、日志
1.介绍
- OpenFeign可以支持很多的自定义配置,如下表所示:
| 类型 | 作用 | 说明 |
|---|---|---|
| feign.Logger.Level | 修改日志级别 | 包含四种不同的级别:NONE、BASIC、HEADERS、FULL |
| feign.codec.Decoder | 响应结果的解析器 | http远程调用的结果做解析,例如解析json字符串为java对象 |
| feign.codec.Encoder | 请求参数编码 | 将请求参数编码,便于通过http请求发送 |
| feign.Contract | 支持的注解格式 | 默认是SpringMVC的注解 |
| feign.Retryer | 失败重试机制 | 请求失败的重试机制,默认是没有,不过会使用Ribbon的重试 |
- 一般情况下,默认值就能满足我们使用,如果要自定义时,只需要创建自定义的@Bean覆盖默认Bean即可。
- 日志的级别分为四种:
| 日志级别 | 描述 |
|---|---|
| NONE | 不记录任何日志信息,这是默认值。 |
| BASIC | 仅记录请求的方法,URL以及响应状态码和执行时间 |
| HEADERS | 在BASIC的基础上,额外记录了请求和响应的头信息 |
| FULL | 记录所有请求和响应的明细,包括头信息、请求体、元数据。 |
2.配置文件
- 基于配置文件修改feign的日志级别可以针对单个服务:
# 将feign包下产生的日志的级别设置为debug
logging:
level:
com.ioart.order.feign: debug
# openfeign日志级别配置
spring:
cloud:
openfeign:
client:
config:
user-server:
loggerLevel: full
- 也可以针对所有服务:
# 将feign包下产生的日志的级别设置为debug
logging:
level:
com.atguigu.spzx.cloud.order.feign: debug
# openfeign日志级别配置
spring:
cloud:
openfeign:
client:
config:
default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置
loggerLevel: full
3.配置类
也可以基于Java代码来修改日志级别,先声明一个类,然后声明一个Logger.Level的对象:
public class DefaultFeignConfiguration {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC; // 日志级别为BASIC
}
}
如果要全局生效,将其放到启动类的@EnableFeignClients这个注解中:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class)
如果是局部生效,则把它放到对应的@FeignClient这个注解中:
@FeignClient(value = "user-service", configuration = DefaultFeignConfiguration .class)
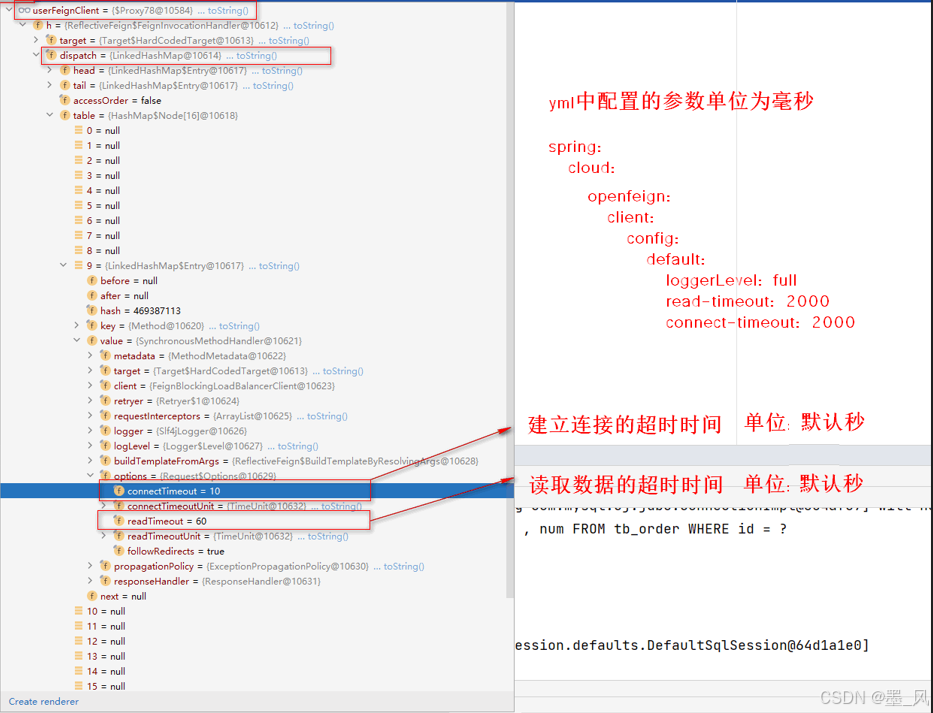
5.1.5、超时控制
1、介绍
- 超时机制概述:Feign 的超时机制是指在使用 Feign 进行服务间的 HTTP 调用时,设置请求的超时时间。当请求超过设定的超时时间后,Feign 将会中断该请求并抛出相应的异常。
- 超时机制的意义:
- 防止长时间等待:通过设置适当的超时时间,可以避免客户端在请求服务时长时间等待响应而导致的性能问题。如果没有超时机制,客户端可能会一直等待,从而影响整个系统的吞吐量和响应时间。
- 避免资源浪费:超时机制可以帮助及时释放占用的资源,例如连接、线程等。如果请求一直处于等待状态而不超时,将导致资源的浪费和系统的负载增加。
- 优化用户体验:超时机制可以防止用户长时间等待无响应的情况发生,提供更好的用户体验。当请求超时时,可以及时给出错误提示或进行相应的处理,以提醒用户或采取其他措施。
- 超时类型:
connectTimeout:连接超时。readTimeout:读取超时。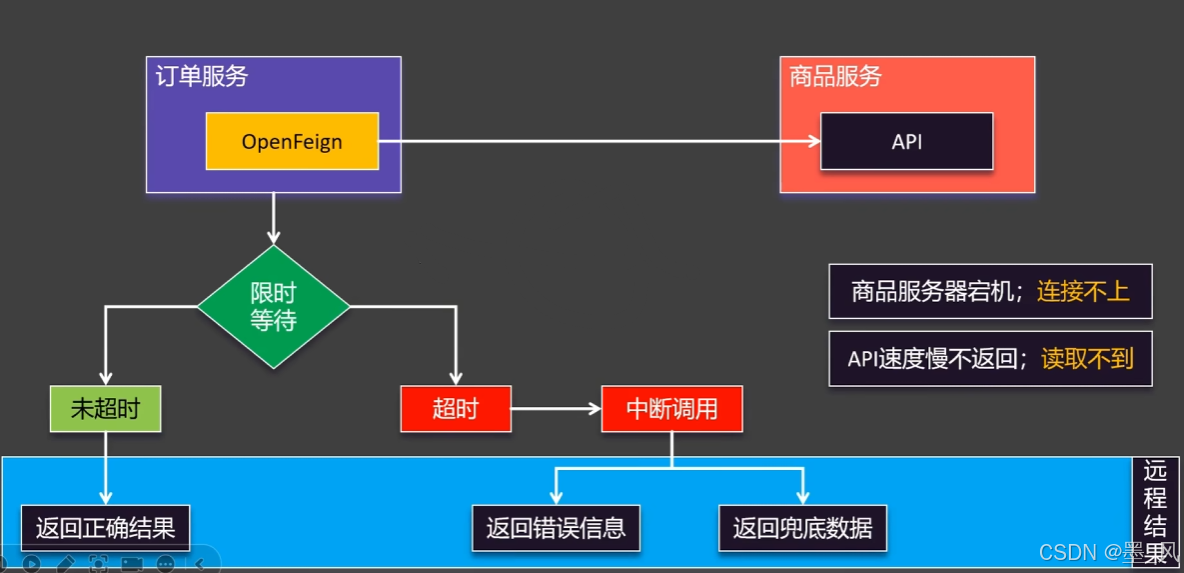
2、配置文件
spring:
cloud:
openfeign:
client:
config:
# 默认全局配置
default:
logger-level: full
connect-timeout: 2000 # 建立连接的超时时间设置为2s
read-timeout: 2000 # 读取数据的超时时间设置为2s
# 单独配置
weather-client:
logger-level: full
connect-timeout: 3000
read-timeout: 3000
5.1.6、重试机制
1.介绍
feign一旦请求超时了,那么此时就会直接抛出**SocketTimeoutException**: Read timed out的异常。请求超时的原因有很多种,如网络抖动、服务不可用等。如果由于网络暂时不可用导致触发了超时机制,那么此时直接返回异常信息就并不是特别的合理,尤其针对查询请求,肯定希望得到一个结果。合理的做法:触发超时以后,让feign进行重试。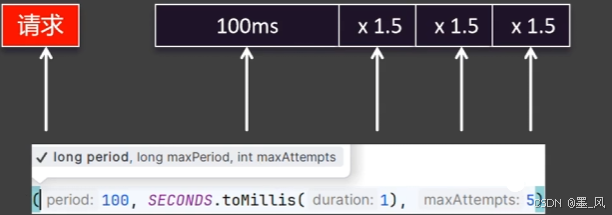
2.自定义重试器
public class FeignClientRetryer implements Retryer {
// 定义两个成员变量来决定重试次数
private int start = 1 ;
private int end = 3 ;
@Override
public void continueOrPropagate(RetryableException e) { // 是否需要进行重试取决于该方法是否抛出异常,如果抛出异常重试结束
if(start >= end) {
throw new RuntimeException(e) ;
}
start++ ;
}
@Override
public Retryer clone() { // 框架底层调用该方法得到一个重试器
return new FeignClientRetryer();
}
}
3.配置文件配置
spring:
cloud:
openfeign:
client:
config:
default:
logger-level: full
connect-timeout: 3000
read-timeout: 3000
# retryer: feign.Retryer.Default # 默认的重试器
retryer: xxx.xxx.xxx.FeignClientRetryer # 自定义的重试器
5.1.7、拦截器
1、图解
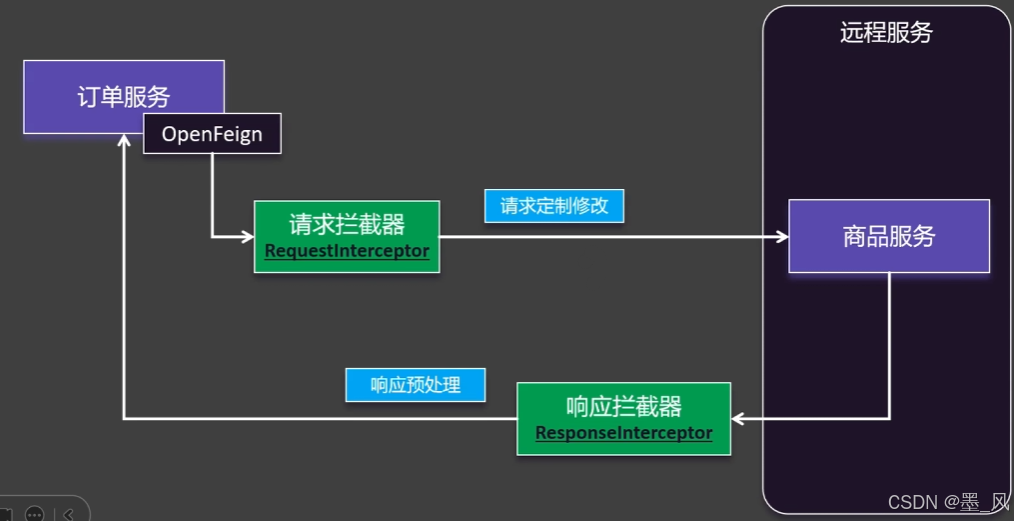
2、使用配置
@Component //加注解或者直接在配置文件中加入此类
public class DefaultOpenFeignInterceptor implements RequestInterceptor {
/**
* 请求拦截器
* @param requestTemplate 1
*/
@Override
public void apply(RequestTemplate requestTemplate) {
requestTemplate.header("X-Token", UUID.randomUUID().toString());
}
}
配置文件
spring:
cloud:
openfeign:
client:
config:
default:
logger-level: full
connect-timeout: 3000
read-timeout: 3000
retryer: feign.Retryer.Default
request-interceptors:
- com.ioart.userservice.interceptor.DefaultOpenFeignInterceptor
5.1.8、兜底返回
1、图解
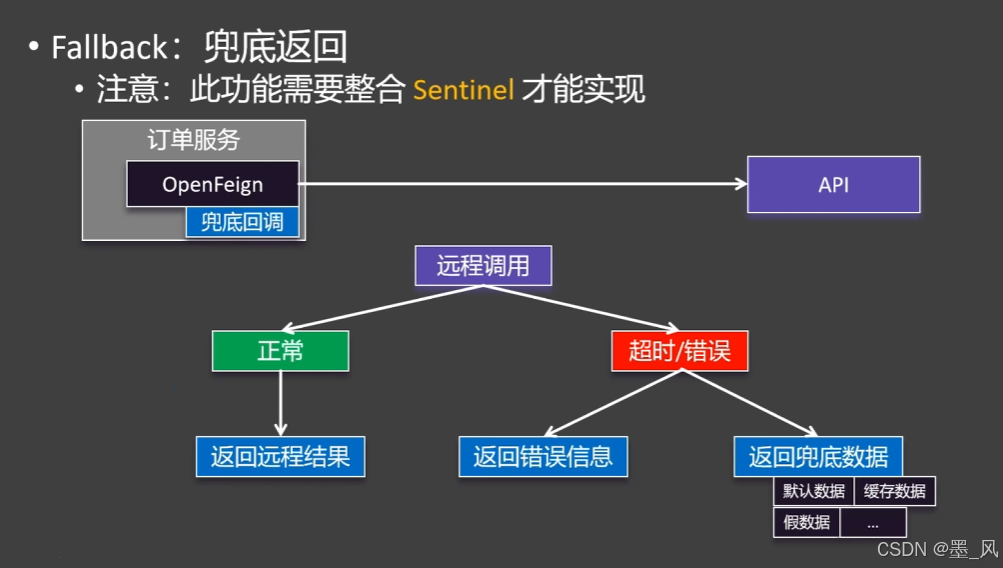
2、实现
- 导入依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
- 代码
@FeignClient(value = "weather-client", url = "http://aliv18.data.moji.com", fallback = WeatherFeignClientFallback.class)
public interface WeatherFeignClient {
@PostMapping("/whapi/json/alicityweather/condition")
String getWeather(@RequestHeader("Authorization") String auth,
@RequestParam("token") String token,
@RequestParam("cityId") String cityId);
}
@Component
public class WeatherFeignClientFallback implements WeatherFeignClient {
@Override
public String getWeather(String auth, String token, String cityId) {
return "";
}
}
- 配置文件
feign:
sentinel:
enabled: true
六、Sentinel服务保护(限流、熔断降级)
6.1、介绍
6.1.1、问题概述
1.雪崩效应
在微服务系统架构中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。一个服务的不可用导致整个系统的不可用的现象就被称之为雪崩效应。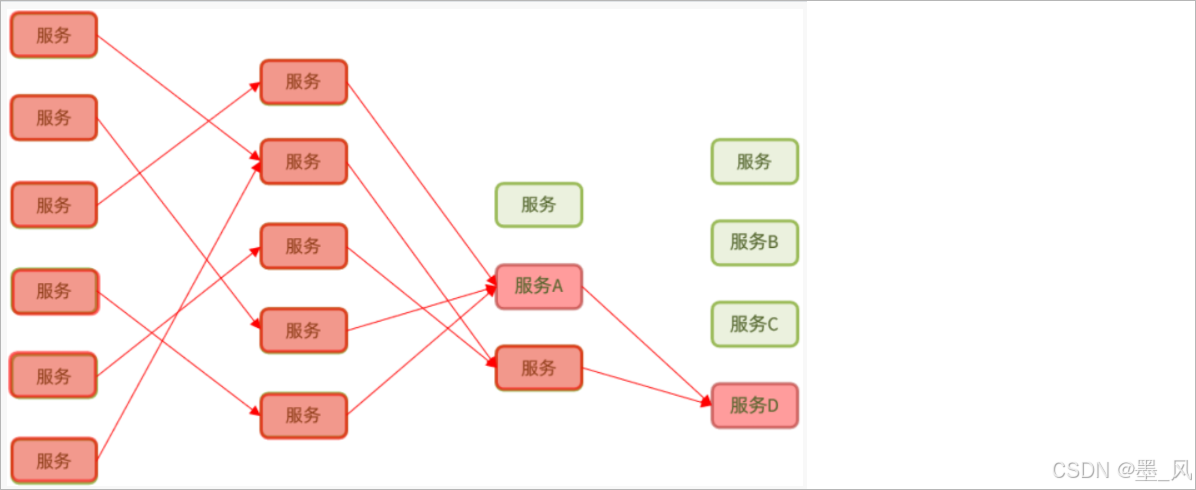
当服务D出现了问题了以后,调用服务D的服务A的线程就得不到及时的释放,在高并发情况下,随着时间的不断推移服务A的系统资源会被线程耗尽,最终导致服务A出现了问题,同理就会导致其他的服务也不能进行访问了。
2.解决方案
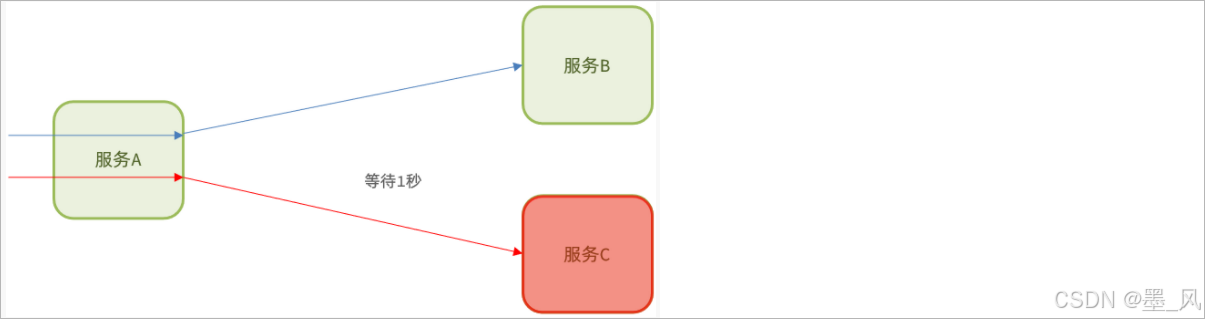
- 超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待。
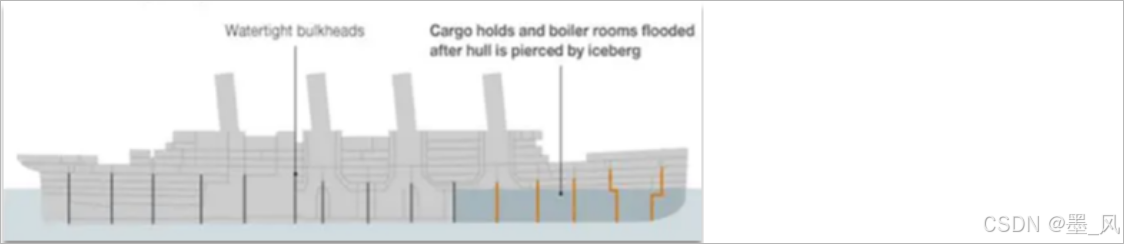
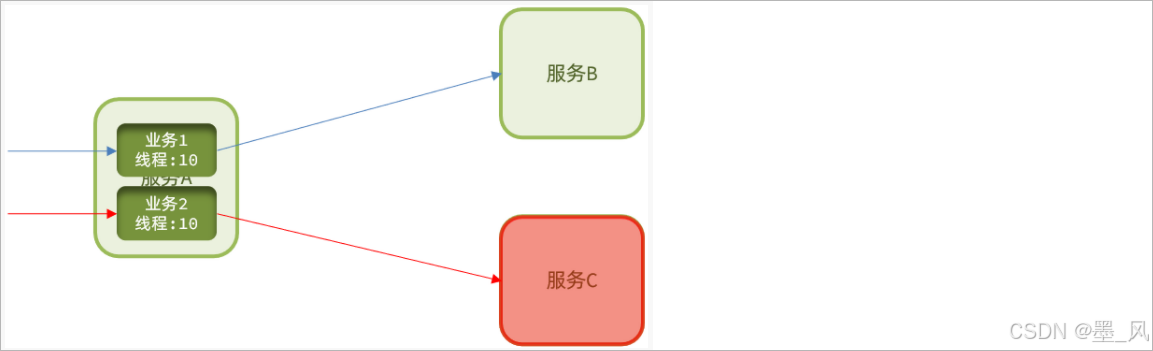
- 隔离处理:将错误隔离在可控的范围之内,不要让其影响到其他的程序的运行。这种设计思想,来源于船舱的设计,如下图所示:船舱都会被隔板分离为多个独立空间,当船体破损时,只会导致部分空间进入,将故障控制在一定范围内,避免整个船体都被淹没。于此类似,我们业务系统也可以使用这种思想来防止出现雪崩效应,常见的隔离方式:线程隔离
- 熔断处理:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。断路器会统计访问某个服务的请求数量,异常比例如下所示:
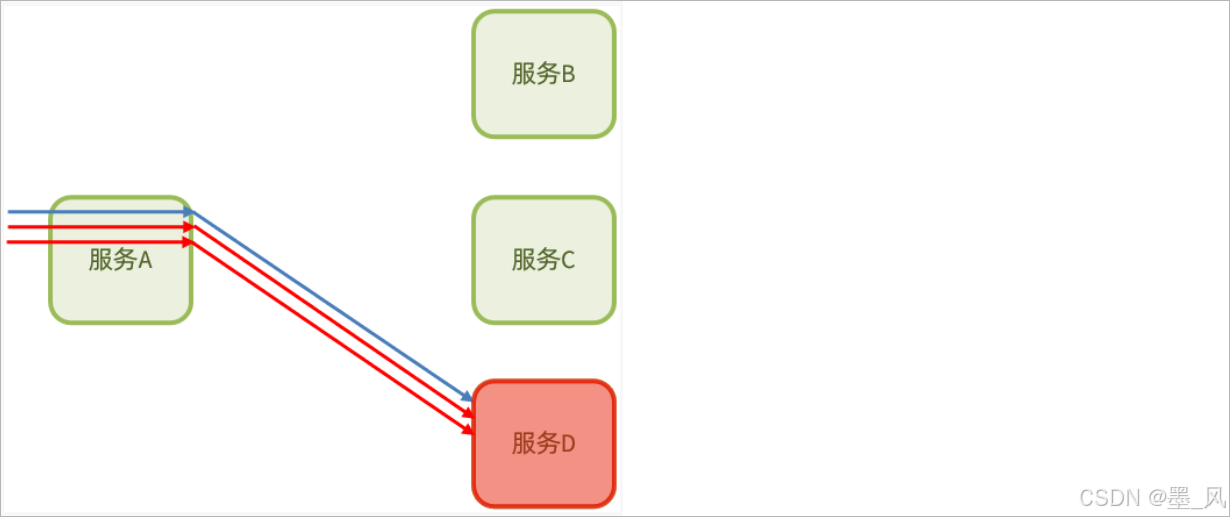 请求了三次,两次出现异常,一次成功。当发现访问服务D的请求异常比例过高时,认为服务D有导致雪崩的风险,会拦截访问服务D的一切请求,形成熔断:
请求了三次,两次出现异常,一次成功。当发现访问服务D的请求异常比例过高时,认为服务D有导致雪崩的风险,会拦截访问服务D的一切请求,形成熔断: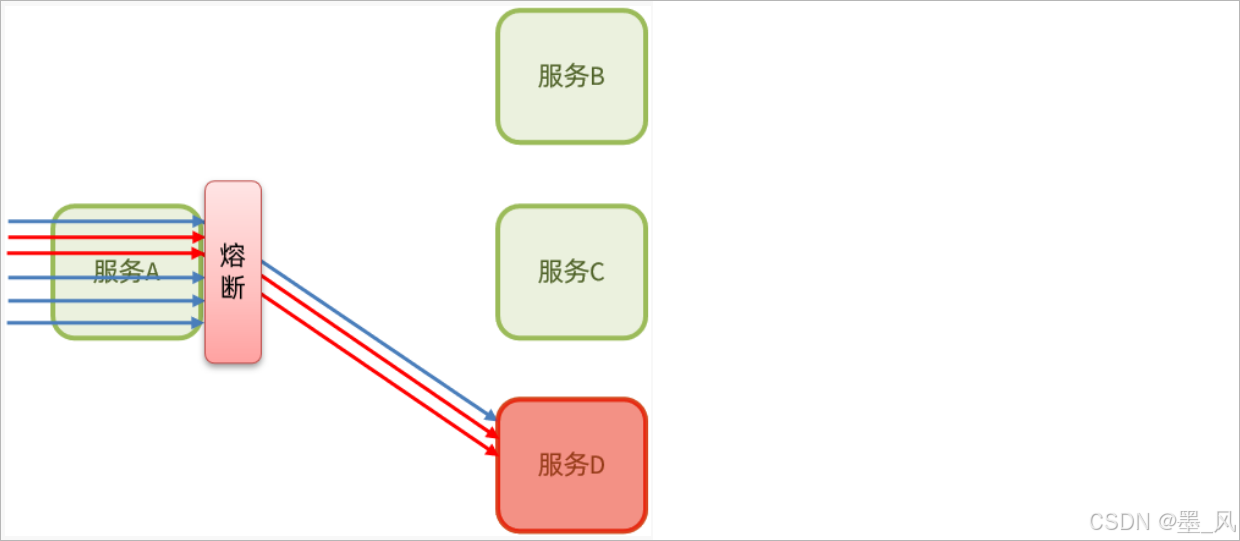 触发熔断了以后,当在访问服务A的时候,就不会在通过服务A去访问服务D了,立马给用户进行返回,返回的是一种默认值,这种返回就是一种兜底方案。这种兜底方案也将其称之为降级逻辑。
触发熔断了以后,当在访问服务A的时候,就不会在通过服务A去访问服务D了,立马给用户进行返回,返回的是一种默认值,这种返回就是一种兜底方案。这种兜底方案也将其称之为降级逻辑。 - 流量控制:限制业务访问的QPS(每秒的请求数),避免服务因流量的突增而故障。
 限流是一种预防措施,避免因瞬间高并发流量而导致服务故障,进而避免雪崩。其他的处理方式是一种补救措施,在部分服务故障时,将故障控制在一定范围,避免雪崩。
限流是一种预防措施,避免因瞬间高并发流量而导致服务故障,进而避免雪崩。其他的处理方式是一种补救措施,在部分服务故障时,将故障控制在一定范围,避免雪崩。
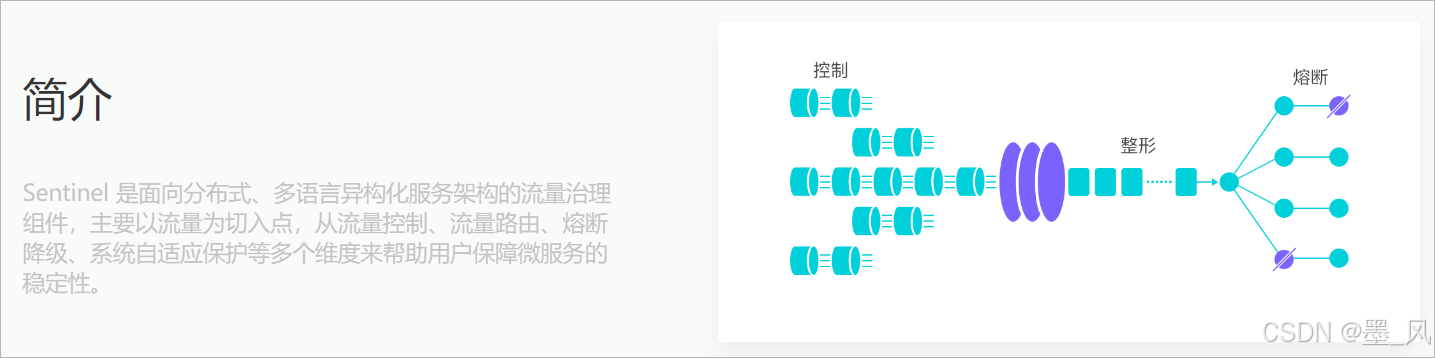
6.1.2、Sentinel介绍
- 官网地址:
https://sentinelguard.io/zh-cn/ - 随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
- Sentinel 的历史:
- 2012 年,Sentinel 诞生,主要功能为入口流量控制。
- 2013-2017 年,Sentinel 在阿里巴巴集团内部迅速发展,成为基础技术模块,覆盖了所有的核心场景。Sentinel 也因此积累了大量的流量归整场景以及生产实践。
- 2018 年,Sentinel 开源,并持续演进。
- 2019 年,Sentinel 朝着多语言扩展的方向不断探索,推出 C++ 原生版本,同时针对 Service Mesh 场景也推出了 Envoy 集群流量控制支持,以解决 Service Mesh 架构下多语言限流的问题。
- 2020 年,推出 Sentinel Go 版本,继续朝着云原生方向演进。
- Sentinel 分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
- 特性:

- 功能:
- 定义资源:
- 主流框架自动适配(
Web Servlet、Dubbo、Spring Cloud、gRPC、Spring WebFlux、Reactor);所有Web接口均为资源。 - 编程式:
SphU API - 声明式:
@SentinelResource
- 主流框架自动适配(
- 定义规则:
- 流量控制(
FlowRule) - 熔断降级(
DegradeRule) - 系统保护(
SystemRule) - 来源访问控制(
AuthorityRule) - 热点参数(
ParamFlowRule)
- 流量控制(
- 整体流程
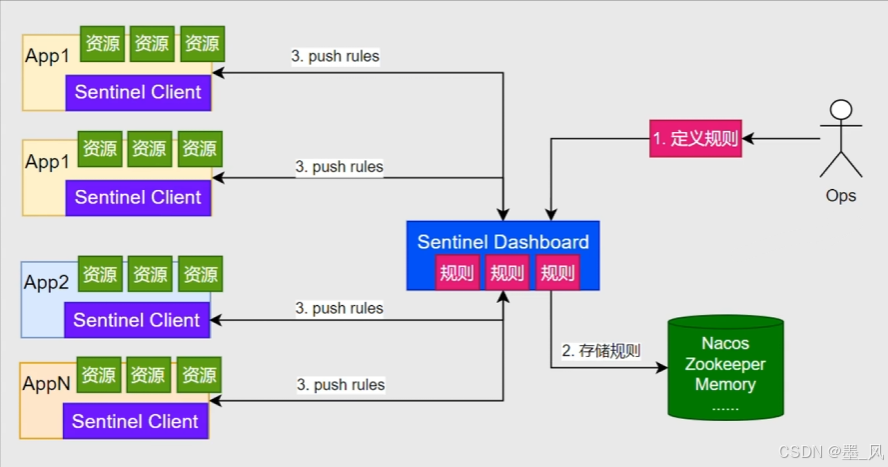
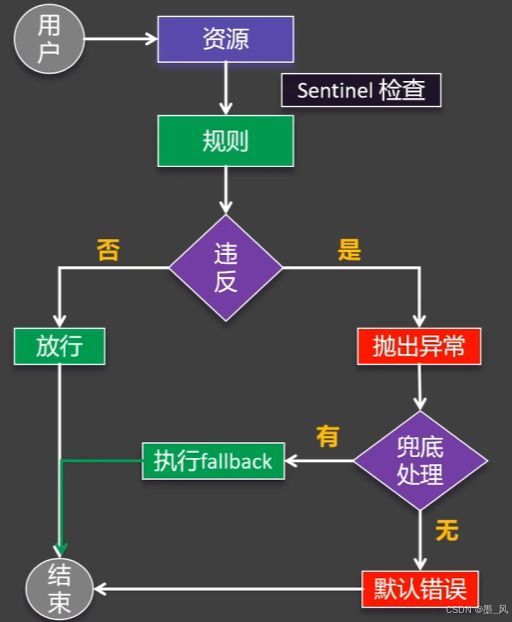
- 工作原理
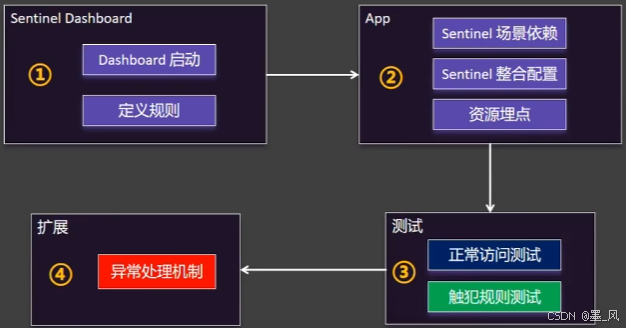
6.2、整合
1、流程
客户端依赖
<!--Sentinel 服务保护-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2、Sentinel-dashboard docker启动
简单的启动方式。
version: '3'
services:
sentinel-dashboard:
image: bladex/sentinel-dashboard:latest
container_name: sentinel-dashboard
ports:
- "8858:8858"
restart: always
- 访问控制台:localhost:8858账户和密码默认是sentinel。
- 访问后:初始化页面就是空白,sentinel是懒加载机制,如果服务没有访问,看不到该服务信息。。
3、服务的配置文件
spring:
cloud:
sentinel:
transport:
dashboard: 192.168.1.10:8858
eager: true # 提前加载
- 启动后,访问user服务的任意接就可以检查是否生效
调用后检查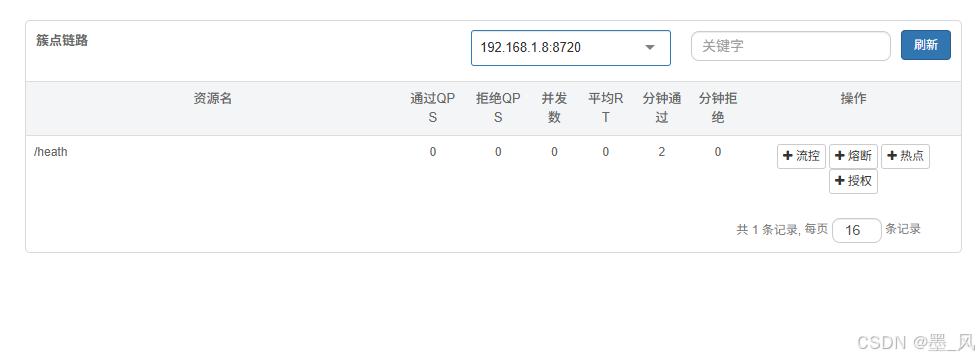
6.3、异常处理
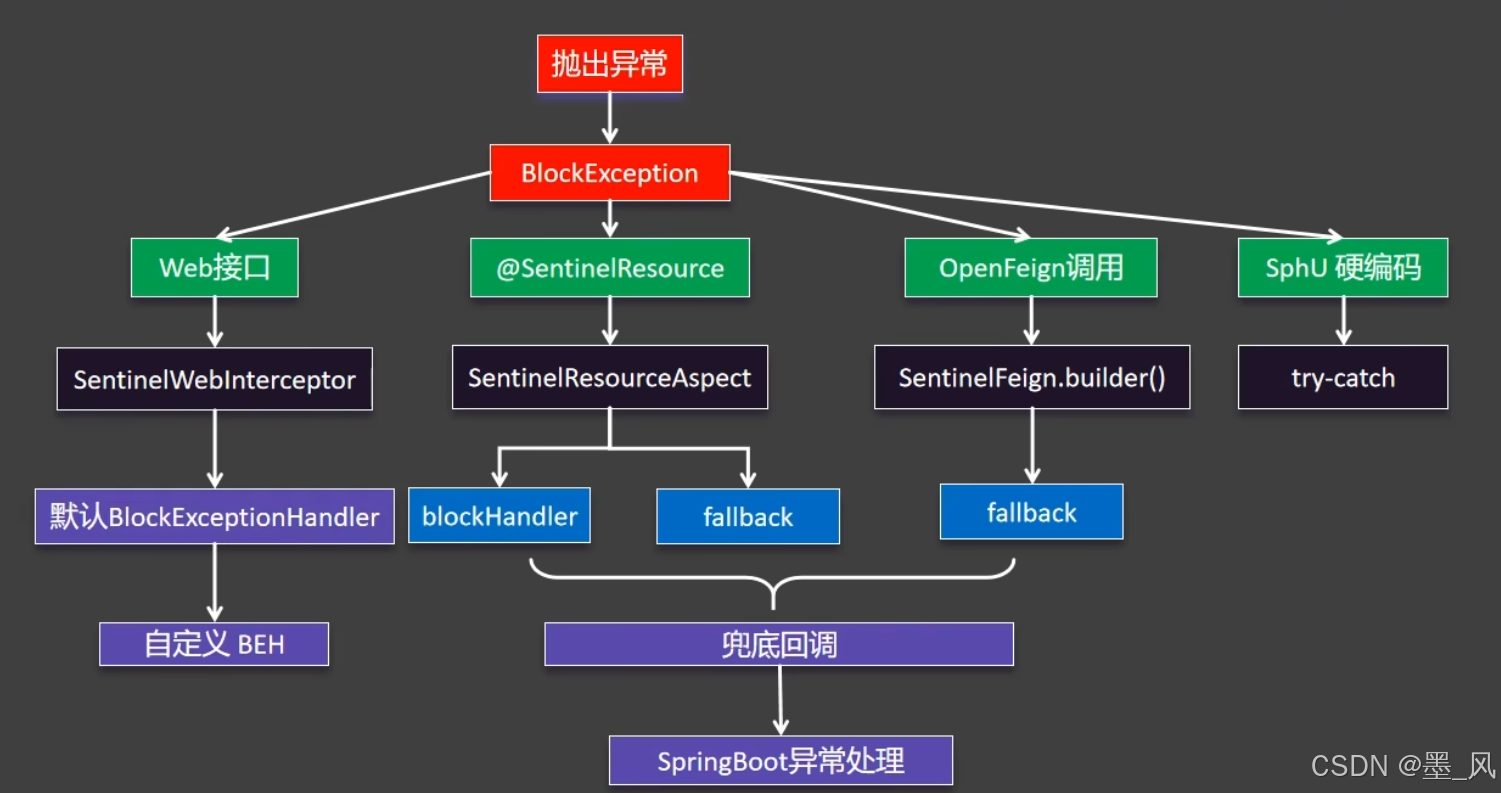
6.3.1、Web接口处理
自定义异常类
public class MyBlockException implements BlockExceptionHandler {
private ObjectMapper objectMapper = new ObjectMapper();
@Override
public void handle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, String resourceName, BlockException e) throws Exception {
httpServletResponse.setContentType("application/json;charset=utf-8");
PrintWriter writer = httpServletResponse.getWriter();
R error = R.error(resourceName + " 被Sentinel限制了,原因:" + e);
String result = objectMapper.writeValueAsString(error);
writer.write(result);
writer.flush();
writer.close();
}
}

6.3.2、@SentinelResource标注
- 用于定义资源并配置熔断、降级、流控等规则。详情可以查看
SentinelResourceAspect类。 - 注意:
@SentinelResource一般标注在非Controller层,将其标记为资源,Controller层会自动识别 blockHandler和fallback的区别:blockHandler:只能处理BlockException异常fallback:能处理业务异常,回调方法的异常类最好是Throwable。
- 注解基本属性
| 属性 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| value | String | “” | 资源名称(必填),用于在 Sentinel 控制台标识和配置规则。 |
| entryType | EntryType | OUT | 入口方向(IN/OUT),通常无需修改。 |
| blockHandler | String | “” | 流控/熔断后的处理方法名(需同参数列表,最后加 BlockException)。 |
| blockHandlerClass | Class<?> | void.class | 指定 blockHandler 方法所在的类(方法需静态)。 |
| fallback | String | “” | 降级处理方法名(仅在抛出异常时触发,需与原方法参数一致)。 |
| fallbackClass | Class<?> | void.class | 指定 fallback 方法所在的类(方法需静态)。 |
| defaultFallback | String | “” | 默认降级方法名(无参数或单参数 Throwable)。 |
| exceptionsToTrace | Class<?>[] | {Throwable.class} | 需要跟踪的异常类型。 |
| exceptionsToIgnore | Class<?>[] | {} | 忽略的异常类型(不触发降级)。 |
- 规则
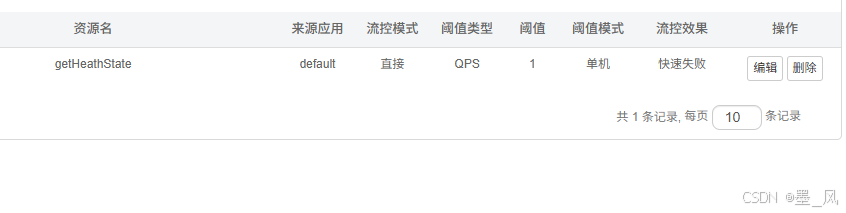
1.按资源名限流(标记单个接口)
//getHeathState属性是资源名称(这个自己瞎起的),blockHandler属性是兜底方法名称
@SentinelResource(value = "getHeathState", blockHandler = "getHeathStateFallBack")
@GetMapping(value = "/findOrderByOrderId/{orderId}")
public R findOrderByOrderId(@PathVariable("orderId") Long orderId) {
System.out.println("访问服务 staring");
int i = 10 / 0;
return R.success(orderService.findOrderByOrderId(orderId));
}
//兜底方法参数和返回值类型,要和controller参数保持一致,并且要多加一个参数:BlockException
public R getHeathStateFallBack(Long orderId, BlockException ex) {
System.out.println("heath staring");
return R.error("兜底回调:" + ex.getClass());
}
- 结果

2.自定义限流处理(标记多个接口)
- 上面兜底方法面临的问题:自定义的处方法和业务代码耦合在一起,每个业务方法都增加一个兜底的,那代码膨胀加剧。
//创建自定义限流处理类,方法必须是public static修饰的
public class CustomerBlockHandler {
//兜底方法参数和返回值类型,要和controller参数保持一致,并且要多加一个参数:BlockException
public static R getHeathStateFallBack(Long orderId, BlockException ex) {
System.out.println("heath staring");
return R.error("兜底回调:" + ex.getClass());
}
}
@RestController
@RequestMapping(value = "/api/order")
public class OrderController {
@Autowired
private OrderService orderService;
//getHeathState属性是资源名称(这个自己瞎起的),blockHandler属性是兜底方法名称
@SentinelResource(value = "getHeathState", blockHandlerClass = CustomerBlockHandler.class, blockHandler = "getHeathStateFallBack")
@GetMapping(value = "/findOrderByOrderId/{orderId}")
public R findOrderByOrderId(@PathVariable("orderId") Long orderId) {
System.out.println("访问服务 staring");
int i = 10 / 0;
return R.success(orderService.findOrderByOrderId(orderId));
}
}
6.3.3、OpenFeign远程调用
- 如果有兜底回调,则会调用远程接口的兜底回调。
- 详情可看
SentinetlFegin.builder()方法。
6.3.4、SphU硬编码
try{
SpuH.entry("资源名");
} catch (BlockException e){
}
6.4、流控规则
6.4.1、介绍
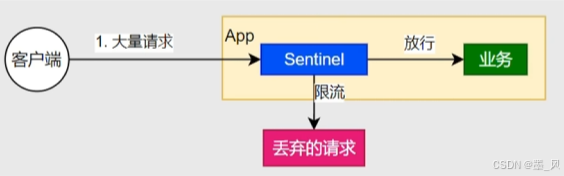
- 限制多余请求,从而保护系统资源不被耗尽。
6.4.2、QPS
QPS表示每秒的请求数,底层使用一个计数器统计请求数量,轻量且速度快。
- 单机
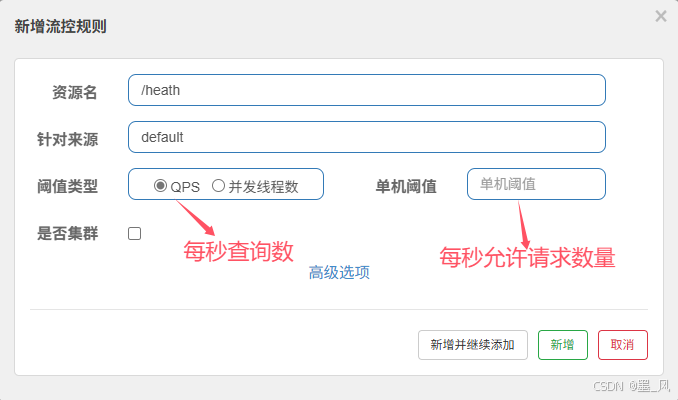
- 集群
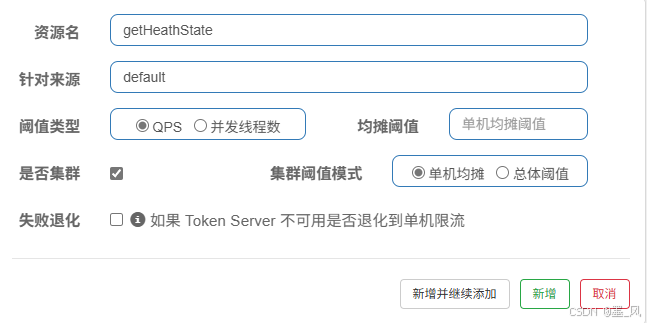
单机均摊:每个机器每秒只能放行 * 个
总体阈值:每秒整个集群只能放行 * 个
6.4.3、并发线程数
并发线程数效果和QPS一样,表示每秒的请求数,但底层需要配合线程池,统计线程池中的线程数量,由于引入线程池,性能低下(线程切换,线程调度)。
6.4.4、高级选项 - 流控模式
- 调用关系包括调用方、被调用方。一个方法又可能会调用其它方法,形成一个调用链路的层次关系。有了调用链路的统计信息,可以行生出多种流量控制手段。
- 在添加限流规则时,点击高级选项,可以选择三种流控模式:
- 直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式。
- 关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流。
- 链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
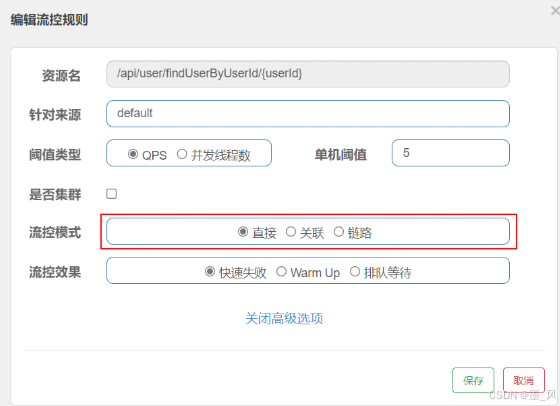
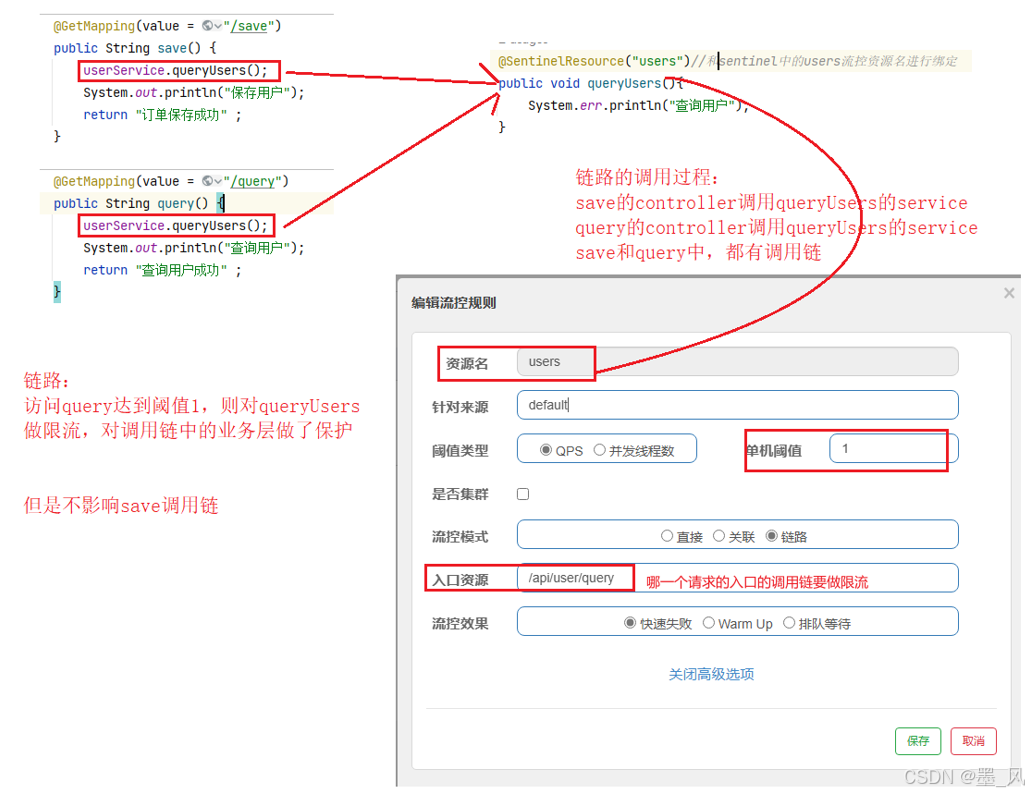
1.直接模式

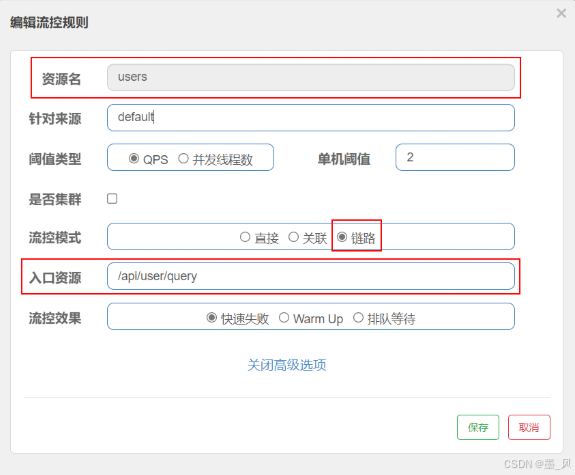
2.链路策略
- 链路模式:只针对从指定链路访问到本资源的请求做统计,判断是否超过阈值,如果超过阈值对从该链路请求进行限流。
- 配置方式:
- /api/user/save --> users
- /api/user/query --> users
- 如果只希望统计从/api/user/query进入到users的请求,并进行限流操作,则可以这样配置:
- 案例代码
//1 在UserService中添加一个queryUsers方法,不用实现业务
public void queryUsers(){
System.err.println("查询用户");
}
//2 在UserController中,添加两个端点,在这两个端点中分别调用UserService中的queryUsers方法
@GetMapping(value = "/save")
public String save() {
userService.queryUsers();
System.out.println("保存用户");
return "订单保存成功" ;
}
@GetMapping(value = "/query")
public String query() {
userService.queryUsers();
System.out.println("查询用户");
return "查询用户成功" ;
}
//3 通过**@SentinelResource**标记UserService中的queryUsers方法为一个sentinel监控的资源(默认情况下,sentinel只监控controller方法)
@SentinelResource("users")
public void queryUsers(){
System.err.println("查询用户");
}
- 更改application.yml文件中的sentinel配置:链路模式中,是对不同来源的两个链路做监控。但是sentinel默认会给进入spring mvc的所有请求设置同一个root资源,会导致链路模式失效。因此需要关闭这种资源整合。
spring:
cloud:
sentinel:
web-context-unify: false # 关闭context整合
3.关联策略
- 关联模式:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流。
- 举例:配置流控规则,当
/api/user/updateUserById资源被访问的QPS超过5时,对/api/user/findUserByUserId/1请求限流。对哪个端点限流,就点击哪个端点后面的按钮。我们是对用户查询/api/user/findUserByUserId/1限流,因此点击它后面的按钮。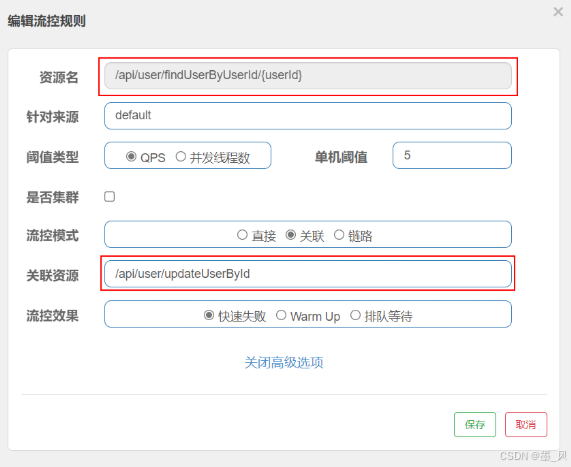
- 关联流控模式的使用场景:
- 两个有竞争关系的资源。
- 一个优先级较高,一个优先级较低。
- 对高优先级的资源的流量进行统计,当超过阈值对低优先级的资源进行限流。
- 整体图解
6.4.5、高级选项 - 流控效果
- 流控效果是指请求达到流控阈值时应该采取的措施,包括三种:
- 快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常,是默认的处理方式。
- warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常,但这种模式阈值会动态变化,从一个较小值逐渐增加到最大阈值。
- 排队等待:让所有的请求按照先后次序进入到一个队列中进行排队,当某一个请求最大的预期等待时间超过了所设定的超时时间时同样是拒绝并抛出异常。
1.快速失败(直接拒绝)
多余请求直接丢弃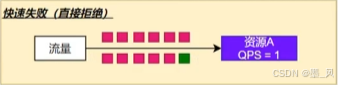
2.Warm Up(预热/冷启动)
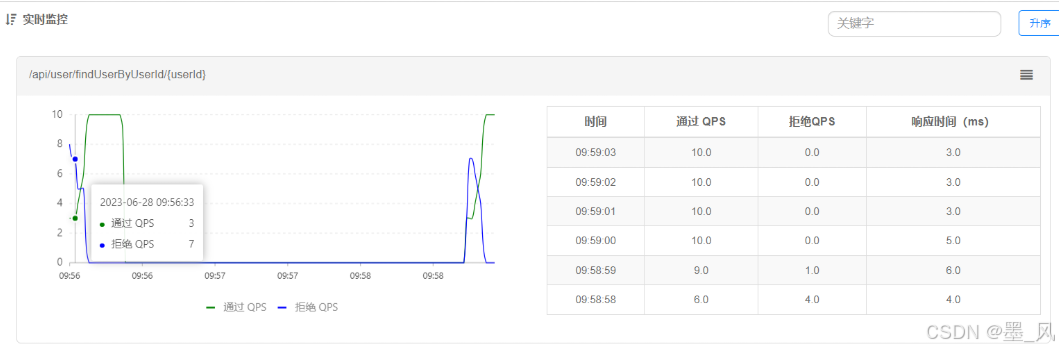
- 阈值一般是一个微服务能承担的最大QPS,但是一个服务刚刚启动时,一切资源尚未初始化(冷启动),如果直接将QPS跑到最大值,可能导致服务瞬间宕机。
- warm up也叫预热模式,是应对服务冷启动的一种方案。阈值会动态变化,从一个较小值逐渐增加到最大阈值。
- 工作特点:请求阈值初始值是 maxThreshold / coldFactor,持续指定时长(预热时间)后,逐渐提高到maxThreshold值,而coldFactor的默认值是3。
- 例如,我设置QPS的maxThreshold为10,预热时间为5秒,那么初始阈值就是 10 / 3 ,也就是3,然后在5秒后逐渐增长到10。
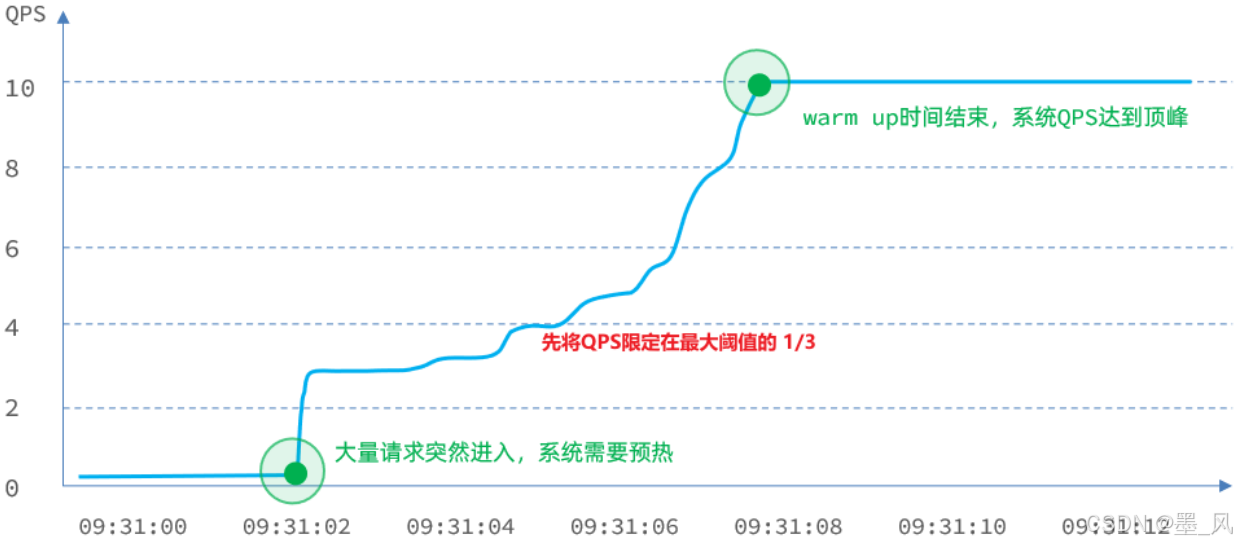
- 案例:给
/api/user/findUserByUserId/{userId}这个资源设置限流,最大QPS为10,利用warm up效果,预热时长为5秒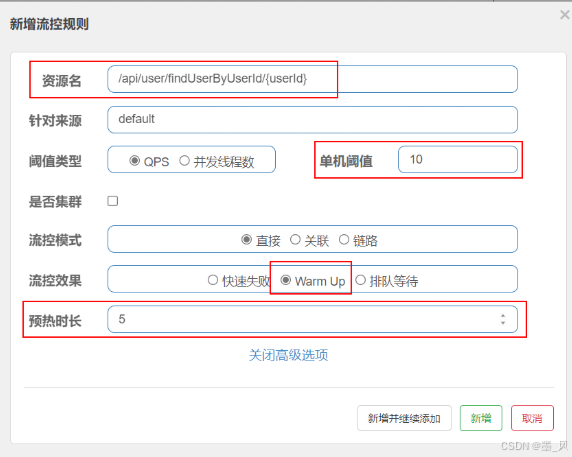
3.排队等待/匀速等待
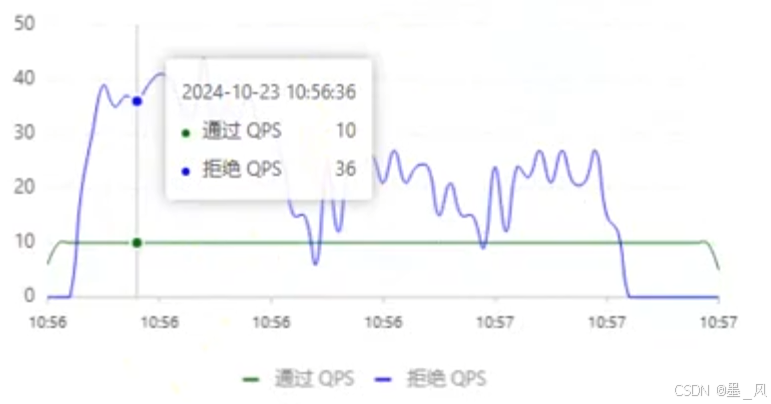
- 排队等待:让所有的请求按照先后次序进入到一个队列中进行排队,当某一个请求最大的预期等待时间超过了所设定的超时时间时同样是拒绝并抛出异常。
- 例如:QPS = 5,意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待时长超过2000ms的请求会被拒绝并抛出异常。
- 那什么叫做预期等待时长呢?比如现在一下子来了12 个请求,因为每200ms执行一个请求,那么:
- 第6个请求的预期等待时长 = 200 * (6 - 1) = 1000ms。
- 第12个请求的预期等待时长 = 200 * (12-1) = 2200ms。
- 现在,第1秒同时接收到10个请求,但第2秒只有1个请求,此时QPS的曲线这样的:

- 如果使用队列模式做流控,所有进入的请求都要排队,以固定的200ms的间隔执行,QPS会变的很平滑。

- 平滑的QPS曲线,对于服务器来说是更友好的。
- 案例:给
/api/user/findUserByUserId/{userId}这个资源设置限流,最大QPS为10,利用排队的流控效果,超时时长设置为5s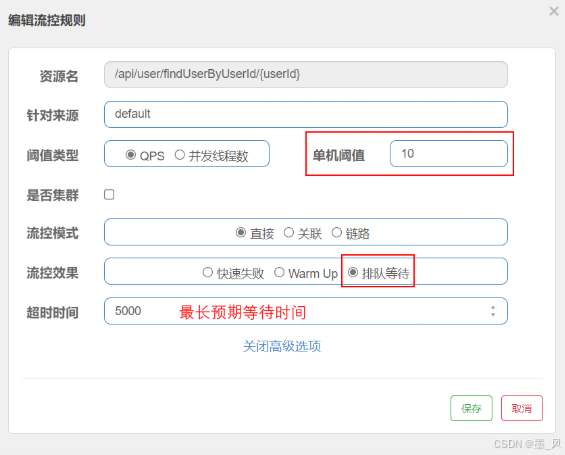
6.5、熔断规则
6.5.1、介绍
- 熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、异常数、慢请求比例,如果超出阔值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
- 最佳实践:熔断降级作为保护自身的手段,通常在客户端(调用端)进行配置。
- 断路器熔断判断策略有三种:慢调用、异常比例、异常数
6.5.2、断路器工作原理
- 状态机包括三个状态:
closed:关闭状态,断路器放行所有请求,并开始统计异常比例、异常数、慢请求比例。超过阈值则切换到open状态。open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态5秒后会进入half-open状态。half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
- 状态切换
- 请求成功:则切换到closed状态
- 请求失败:则切换到open状态
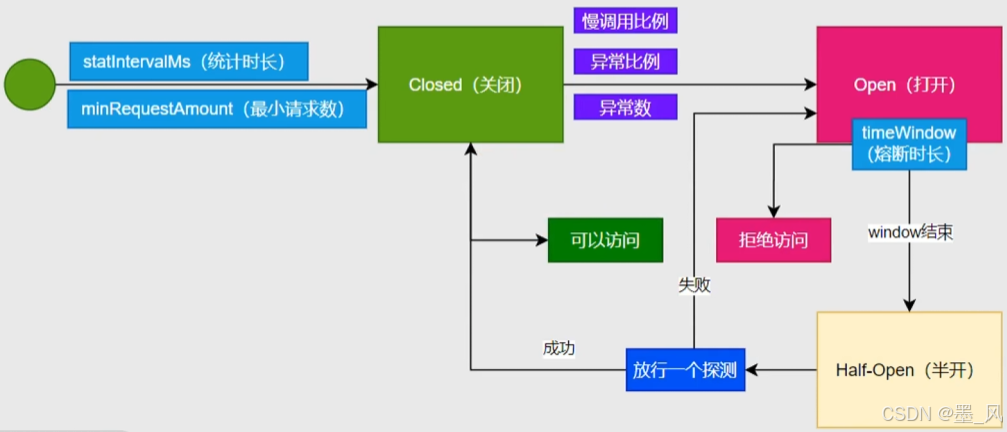
6.5.3、规则 - 慢调用比例
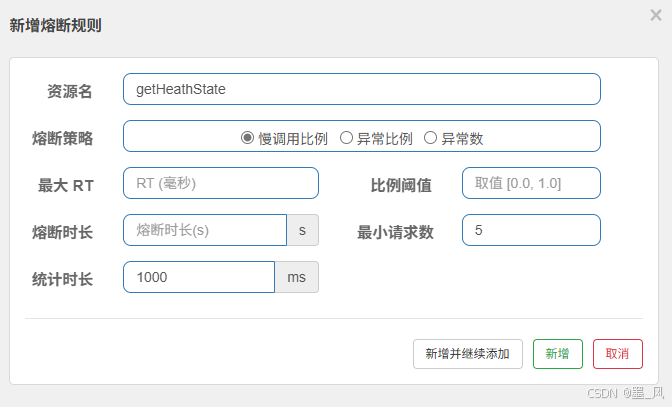
- 统计时长内,有阈值(百分比) 的响应时长大于最大RT时间,则属于慢调用,属于不可靠,打开断路器。
- 最小请求数,先将请求量上去才熔断。
- 熔断时长:指定时间内就不会给远程发请求了
6.5.4、规则 - 异常比例
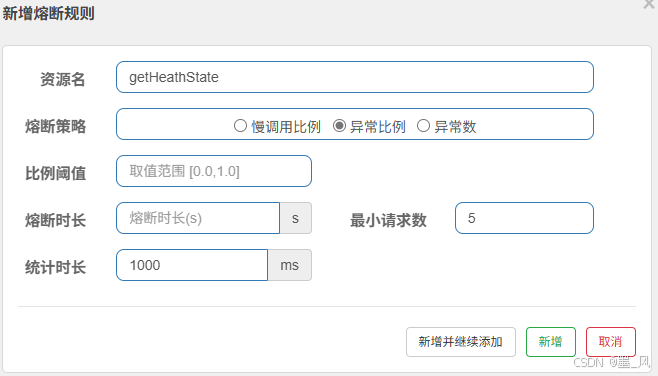
- 比例阈值:假设 0.8,即为总请求数 * 0.8的数量出现错误即会出现熔断。
6.5.5、规则 - 异常数
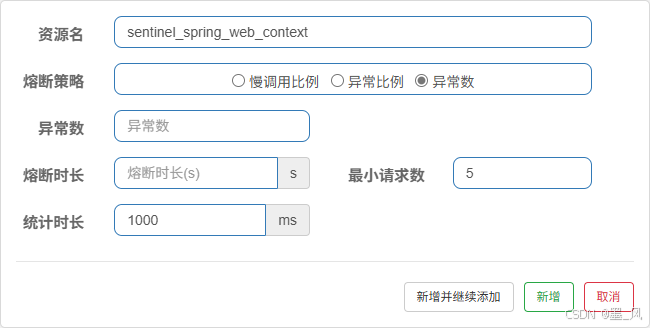
异常数是统计数量的。异常比例统计百分比的
6.6、热点规则
- 之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计参数值相同的请求,判断是否超过QPS阈值。

- 参数索引:参数的序号,例如,
@SentinelResource:加这个注解,给value加热点控制
@GetMapping("/hot")
@SentinelResource(value = "hot")//加这个注解,给value加热点控制
public R getState2(@RequestParam("id") String id) {
return R.ok(id);
}
- 设置规则
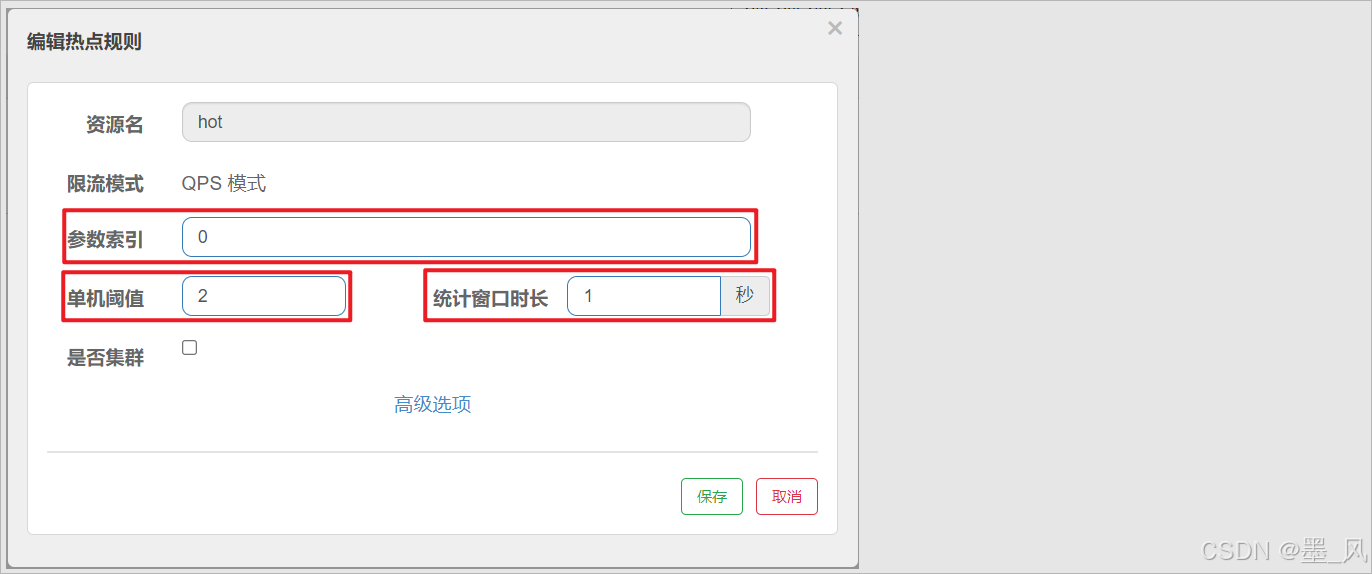
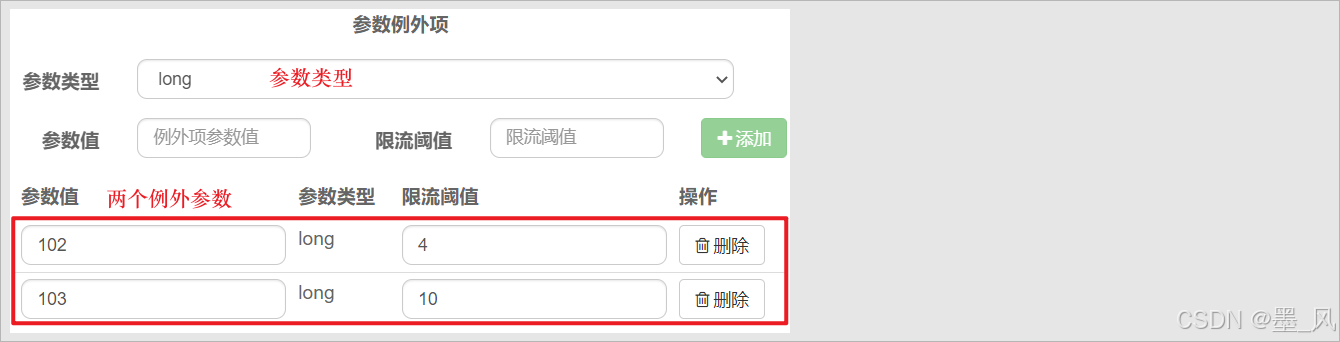
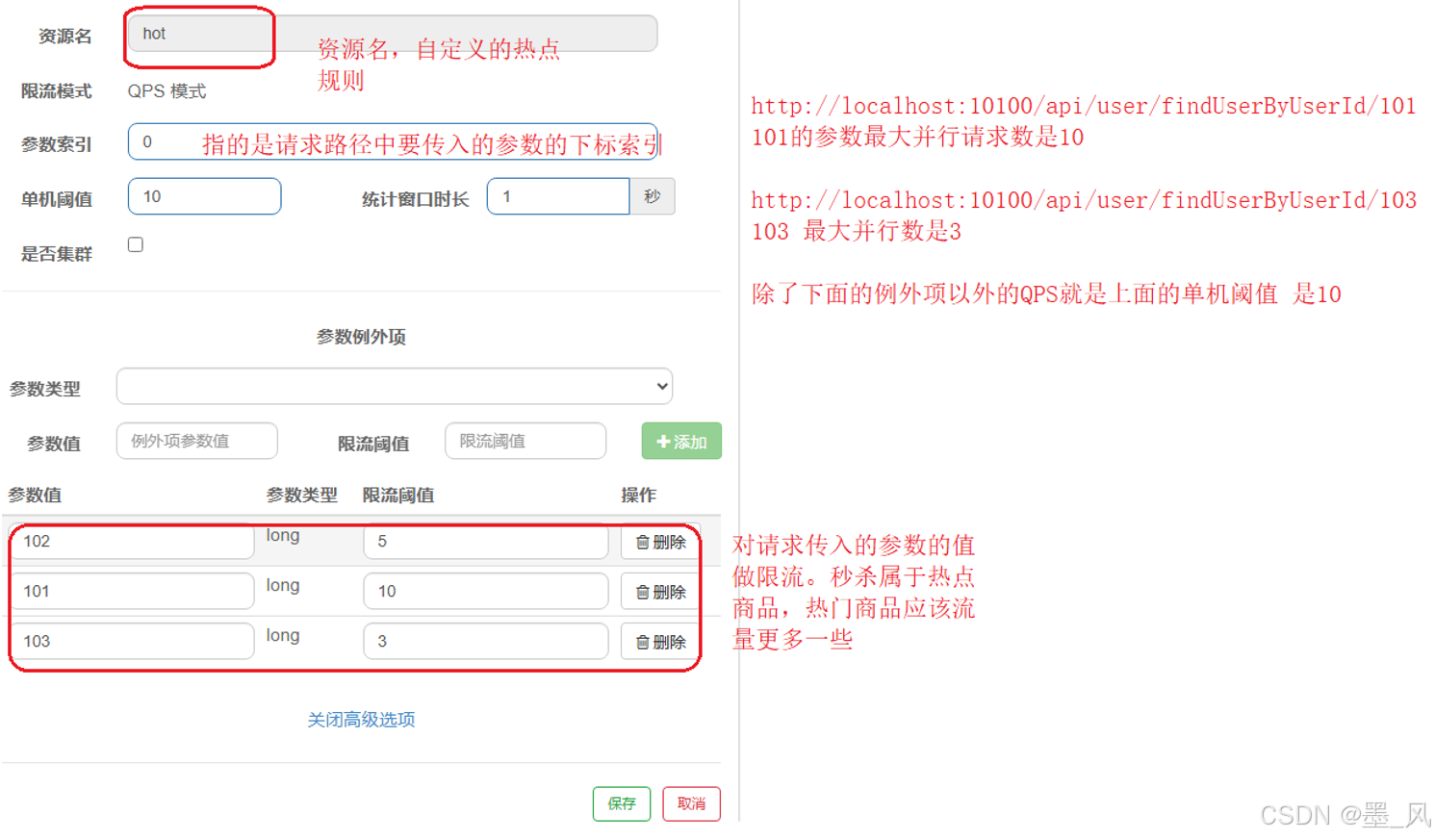
- 代表的含义是:对hot这个资源的0号参数(第一个参数)做统计,每1秒相同参数值的请求数不能超过2。这种配置是对查询商品这个接口的所有商品一视同仁,QPS都限定为5。而在实际开发中,可能部分商品是热点商品,例如秒杀商品,我们希望这部分商品的QPS限制与其它商品不一样,高一些。那就需要配置热点参数限流的高级选项了:
- 整体图解:
6.7、测试工具jemter
6.7.1、下载安装
- Apache JMeter 是 Apache 组织基于 Java 开发的压力测试工具,用于对软件做压力测试。
- 下载地址:
https://archive.apache.org/dist/jmeter/binaries/
6.7.2、修改编码格式
6.7.3、启动运行
- 回到bin目录,双击jemter.bat,自动打开测试窗口,切记,cmd黑窗口不要关闭。
- options->choose Language->简体中文Chinese simplefied
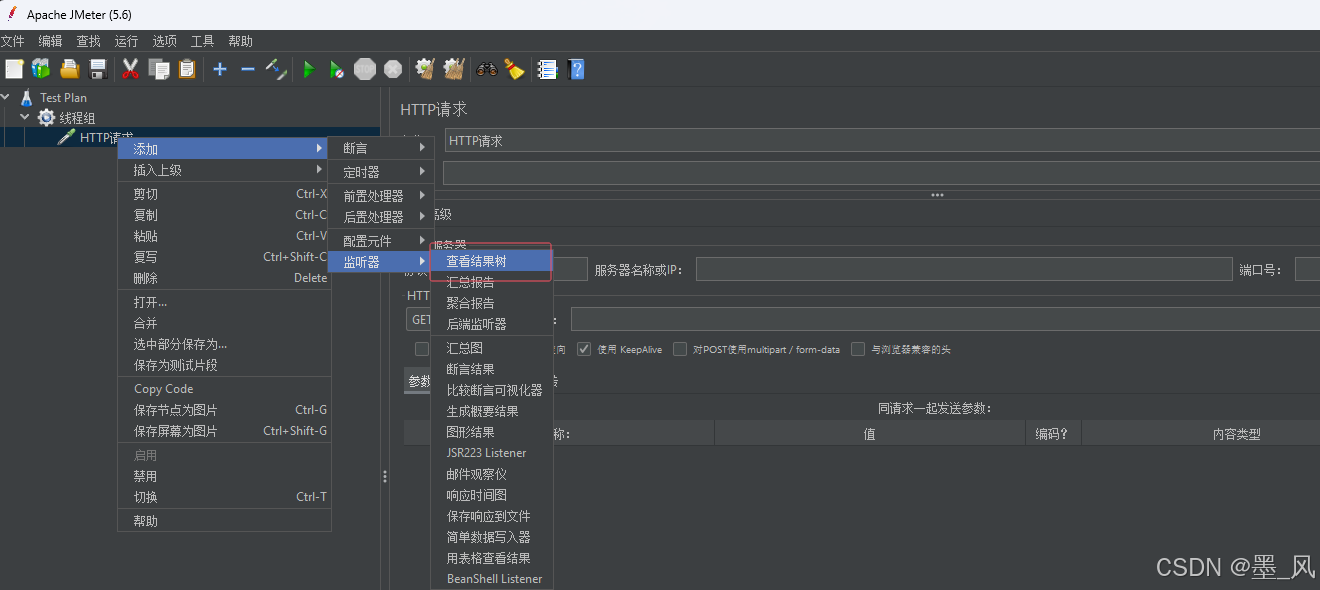
6.7.4、添加任务
- 添加线程组
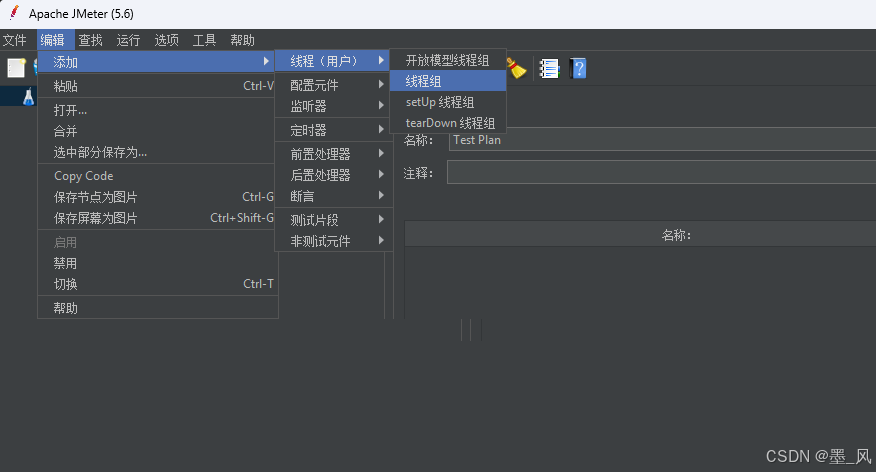
- 配置线程组
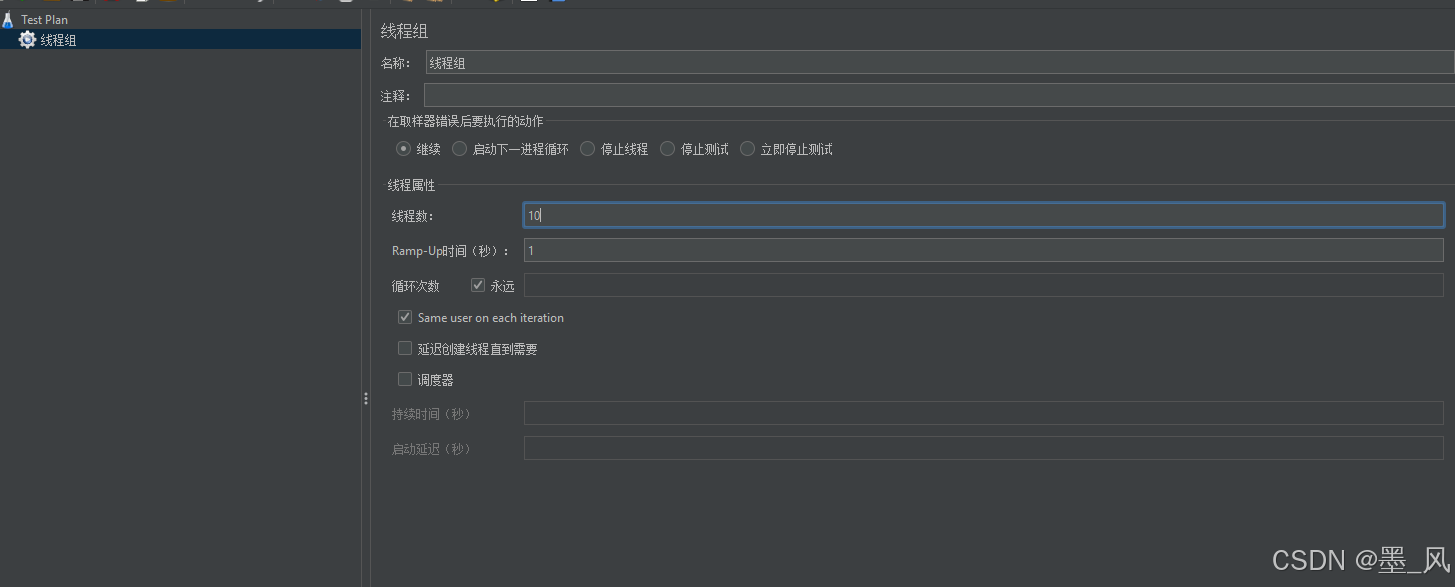
- 添加取样器
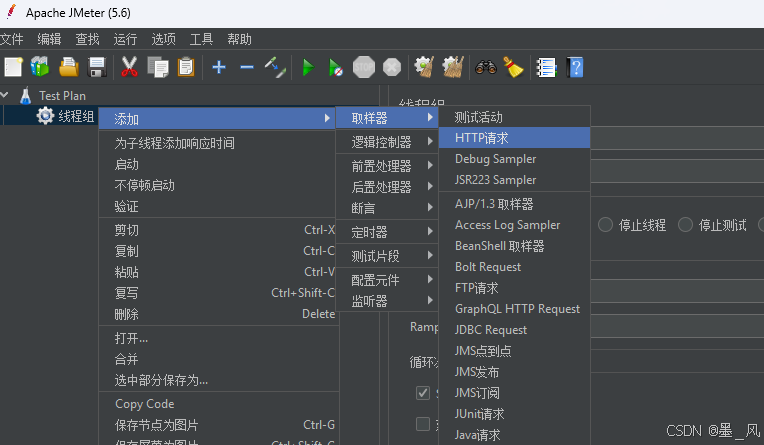
- 设置http请求
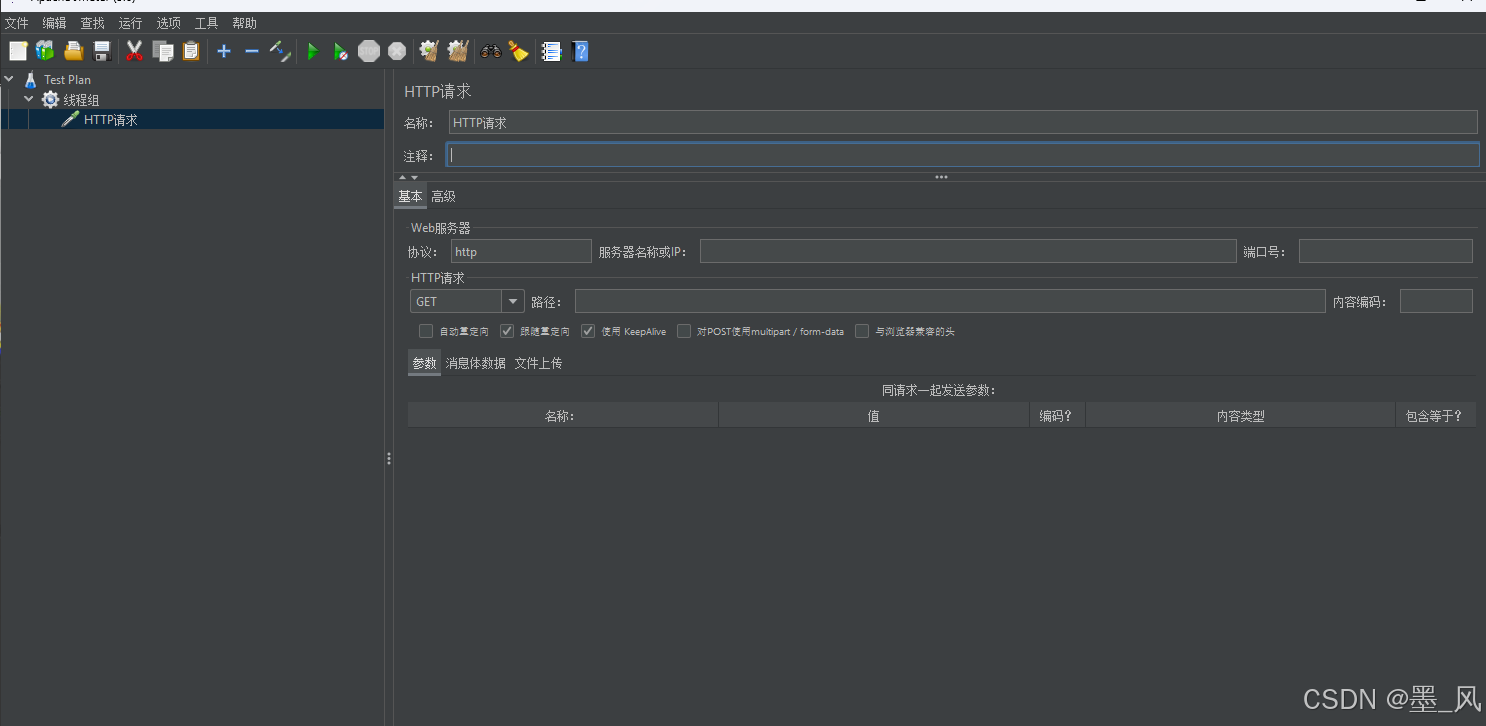
- 添加结构树,以便查看结果
6.8、流控规则持久化
6.8.1、规则持久化概述
- 默认情况下
sentinel没有对规则进行持久化,让对服务进行重启以后,Sentine规则将消失,生产环境需要将配置规则进行持久化。 - 持久化思想:将限流配置规则持久化进Nacos保存,只要刷新
user-service某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对user-service上Sentinel上的流控规则持续有效。
6.8.2、nacos规则持久化配置
1.流控规则配置
在nacos配置中心中添加规则配置,dataID必须是下图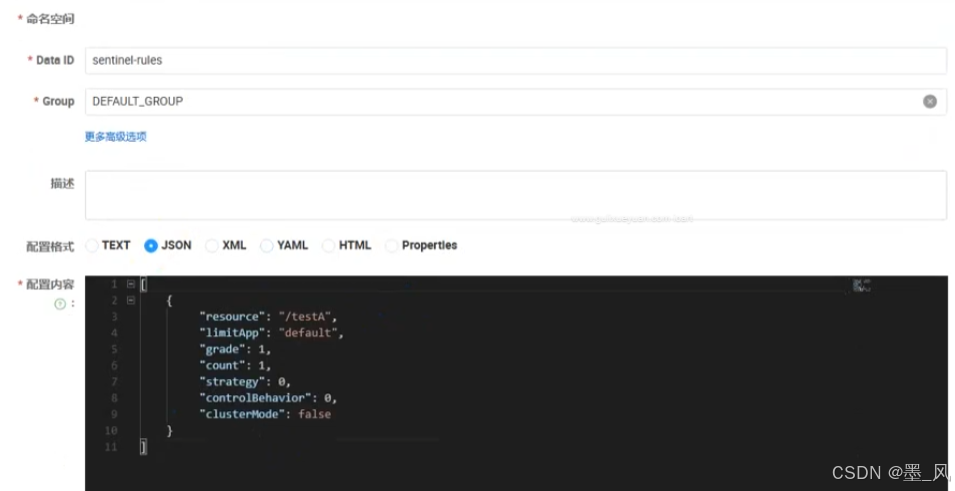
| Field | 说明 | 默认值 |
|---|---|---|
resource |
资源名,资源名是限流规则的作用对象 | |
count |
限流阈值 | |
grade |
限流阈值类型,QPS模式( 1 ) 或并发线程数模式( 0 ) | QPS 模式 |
limitApp |
流控针对的调用来源 | default,代表不区分调用来源 |
strategy |
调用关系限流策略:直接(0)、链路(1)、关联(2) | 根据资源本身(直接) |
controlBehavior |
流控效果(直接拒绝(0)/排队等待(1)/慢启动模式(2)),不支持按调用关系限流 | 直接拒绝 |
clusterMode |
是否集群限流 | 否 |
6.8.3、读取nacos规则配置
微服务可以从nacos配置中心读取规则配置信息然后进行使用。具体步骤如下所示:
- 在user-service微服务中的pom.xml文件中添加如下依赖。
<!-- sentinel持久化到nacos依赖 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
- 在user-service微服务的application.yml文件添加如下配置。
#配置数据库的连接信息
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8080
datasource:
ds1: # 自己起的名字 数据源1
nacos:
serverAddr: localhost:8848
dataId: sentinel-rules
groupId: DEFAULT_GROUP
dataType: Json
ruleType: flow
- 重启user-service微服务,访问任意一个接口,此时就可以在sentinel的控制台看到对应的流控规则了。
七、网关(Gateway)
7.1、介绍
7.1.1、简介
- Gateway是在Spring生态系统之上构建的API网关服务,基于Spring5,SpringBoot2和Project Reactor等技术。Gateway旨在提供一种简单而有效的方式来对API进行路由,以及提供一些强大的过滤器功能,例如:熔断、限流、重试等。
- SpringCloud Gateway是SpringCloud的一个全新项目,基于Spring5.X+SpringBoot2.X和Project Reactor等技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的API路由管理方式。
- 为了提升网关的性能,SpringCloud Gatway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通讯框架Netty。
- SpringCloud Gateway的目标提供统一的路由方式且基于Filter链的方式提供了网关基本的功能,例如:安全、监控/指标、和限流。
- 官网
- Gateway
- 功能
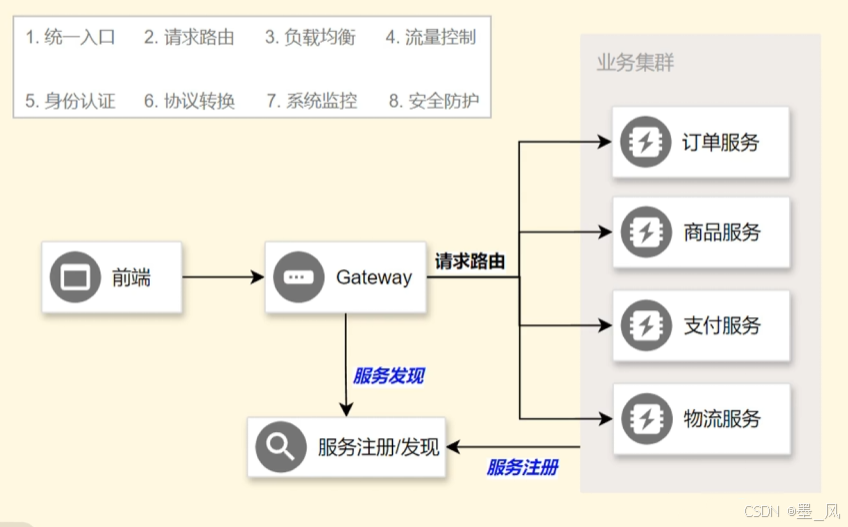
7.1.2、图解
-
架构图
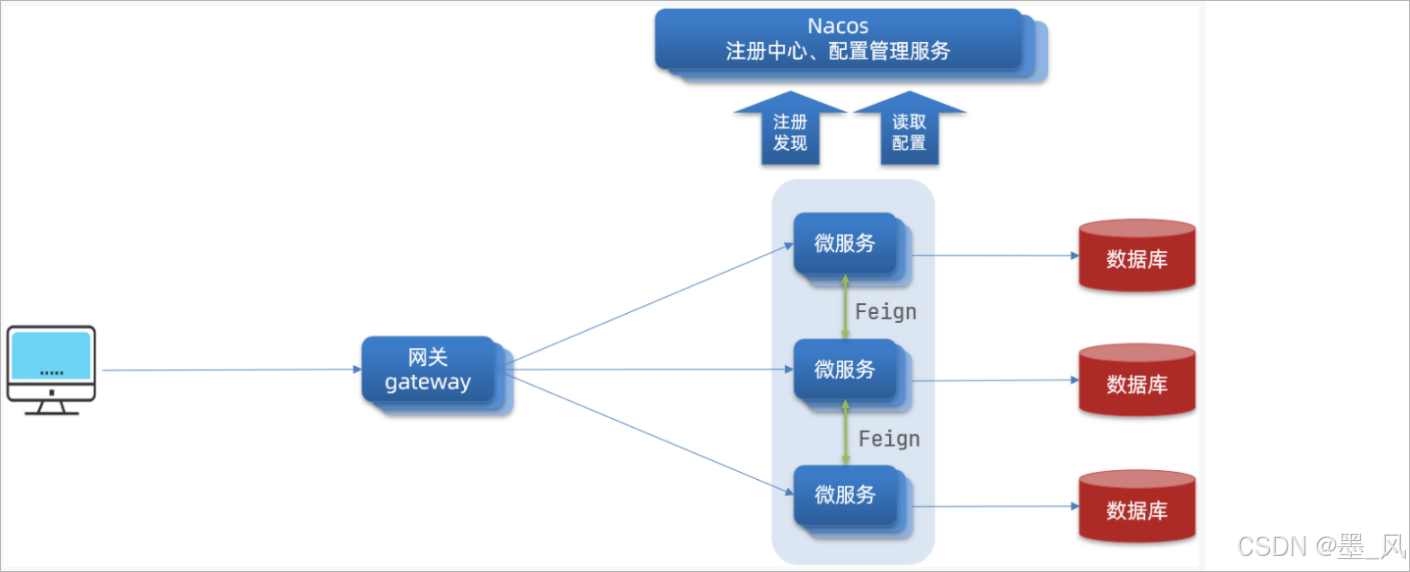
-
原理图
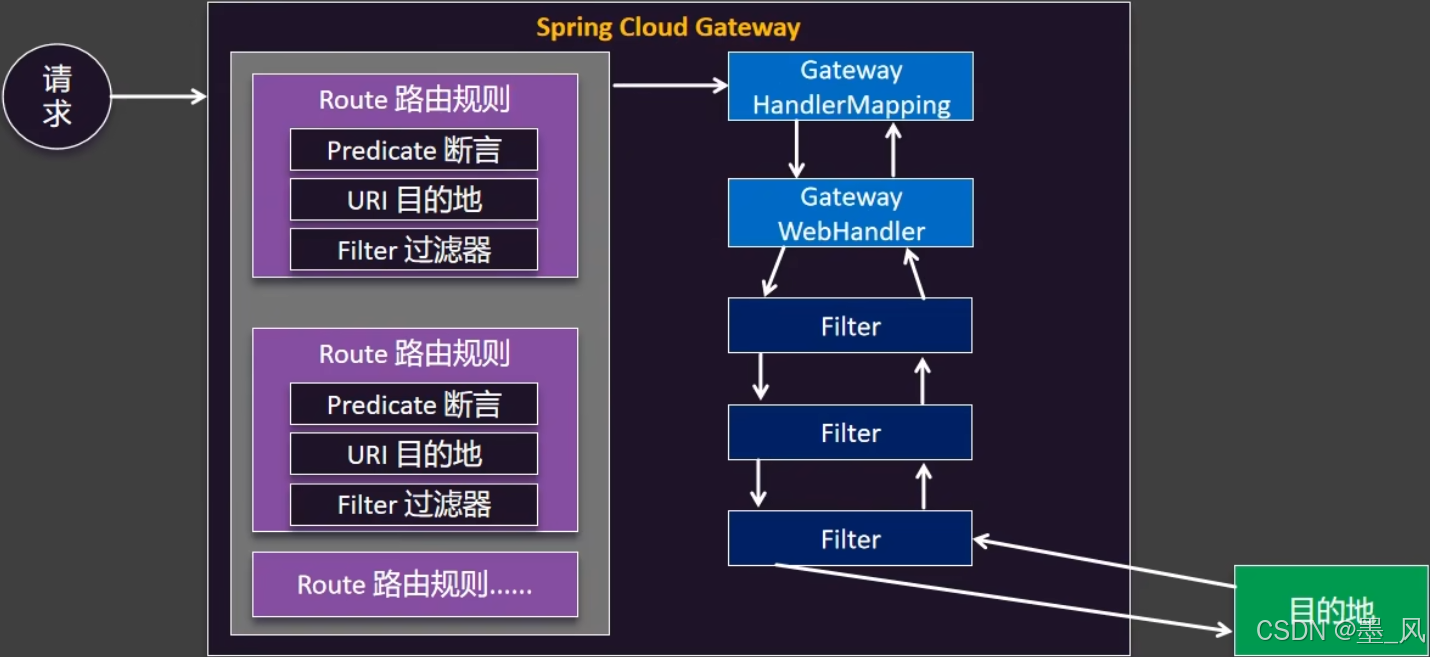
7.1.3、三大核心概念
1.Route(路由)
- 路由是构建网关的基本模块,它由ID,目标URI,一系列的断言和过滤器组成,如果断言为true则匹配该路由。
- 作用:让网关可以找到服务。

2.Predicate(断言)
-参考的是java8的java.util.function.Predicate开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由。
- 作用:在客户端发送的请求路径中,解析出来
uri:/api/user/xxx,匹配断言,满足,找对应的路由 - url与uri
- url:完整协议,
http://localhost:8080/api/user/xxx - uri:去掉协议端口和IP的部分,
/api/user/xxx
- url:完整协议,
3.Filter(过滤)
- 指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改。
- 作用:过滤请求的。可以对请求头中做处理、请求体做处理等。

7.1.4、工作流程
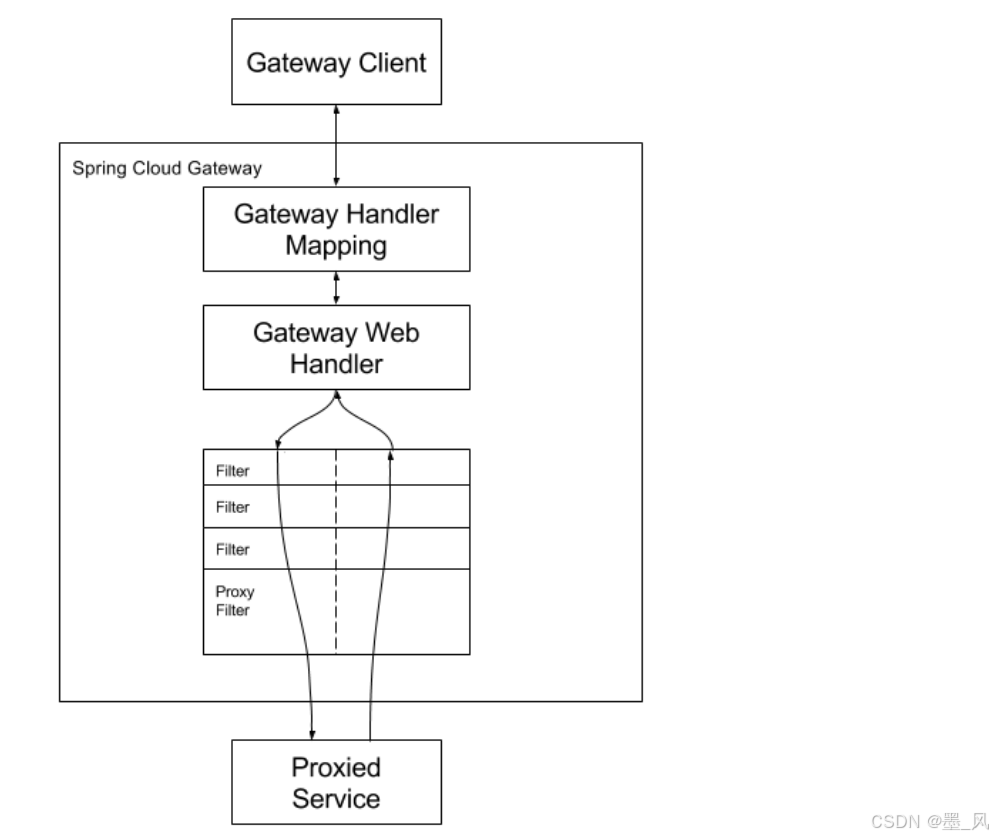
- 客户端向Spring Cloud Gateway发出请求。然后在Gateway Handler Mapping中找到与请求匹配的路由,将其发送到Gateway Web Handler。
- Handler再通过指定的过滤器链来将请求发送给我们实际的服务执行业务逻辑,然后返回。
- 过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(“pre”)或之后(“post”)执行业务逻辑。
- Filter在"pre"类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等,在"post"类型的过滤器中可以做响应内容、响应头的修改,日志的输出,流量控制等有着非常重要的作用

7.1.5、简单使用
- 依赖
<dependencies>
<!-- gateway 网关 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--负载均衡-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!--Nacos 注册中心/服务发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--Nacos 配置中心-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
- 配置文件
server:
port: 8080
spring:
application:
name: gateway-server
cloud:
gateway:
discovery:
locator:
enabled: true
routes:
- id: user-server # 路由id,可以自定义,只要唯一即可
uri: lb://user-server # 路由的目标地址 lb就是负载均衡,后面跟服务名称
predicates: #断言:匹配你指定的规则,来找到上面的服务
- Path=/*/user/** # 路径匹配
- id: order-server
uri: lb://order-server
predicates:
- Path=/*/order/** # 路径匹配
nacos:
discovery:
server-addr: 192.168.1.10:8848
- 重启测试
重启网关,访问:http://localhost:8080/api/user/findUserByUserId/1时,符合/api/user/**规则,请求转发到uri:http://user-server/api/user/findUserByUserId/1,得到结果。
7.2、断言
7.2.1、介绍

- 工厂列举(详情看官网)
| 名 | 参数(个数/类型) | 作用 |
|---|---|---|
After |
1/datetime |
在指定时间之后 |
Before |
1/datetime |
在指定时间之前 |
Between |
2/datetime |
在指定时间区间内 |
Cookie |
2/string,rexp |
包含cookie名且必须匹配指定值 |
Header |
2/string,rxp |
包含请求头且必须匹配指定值 |
Host |
N/string |
请求host必须是指定枚举值 |
Method |
N/string |
请求方式必须是指定枚举值 |
Path |
2/List<String>,bool |
请求路径满足规则,是否匹配最后的/ |
Query |
2/string,regexp |
包含指定请求参数 |
RemoteAddr |
1/List<String> |
请求来源于指定网络域(CIDR写法) |
Weight |
2/string,int |
按指定权重负载均衡 |
XForwarded RemoteAddr |
1/List<string> |
从X-Forwarded-For请求头中解析请求来源,并判断是否来源于指定网络域 |
- 代码中查找
断言中的所有Name字段参数,取Route前面即可。例如PathRoutePredicateFactory.class取Path。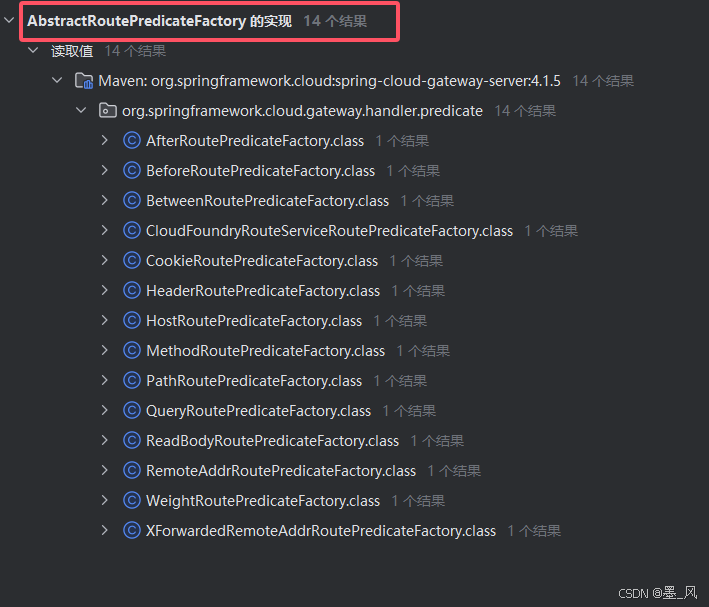
7.2.2、短写法
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates: # 断言
- Path=/api/user/**
7.2.3、全写法
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates: # 断言
- name: Path
args:
patterns: /api/user/**
matchTrailingSlash: true # 默认为true 开启后 /api/user 和/api/user/识别为一个路径,否则识别为2个
7.2.4、自定义断言
- yml
spring:
cloud:
gateway:
routes:
- id: user-service # 唯一ID
uri: lb://lb://user-service #目的地
predicates: # 断言
# 短写法
- Customize=user,lifeng
# 长写法
- name: Customize
args:
param: user
value: lifeng
- 代码
package com.ioart.gateway.predicate;
import jakarta.validation.constraints.NotEmpty;
import org.springframework.cloud.gateway.handler.predicate.AbstractRoutePredicateFactory;
import org.springframework.cloud.gateway.handler.predicate.GatewayPredicate;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.util.MultiValueMap;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.server.ServerWebExchange;
import java.util.Arrays;
import java.util.List;
import java.util.function.Predicate;
/**
* @version 1.0
* @Author moFeng
* @Date 2025/6/7 20:56
* @注释
*/
public class CustomizeRoutePredicateFactory extends AbstractRoutePredicateFactory<CustomizeRoutePredicateFactory.Config> {
public static final String PARAM_KEY = "param";
public static final String VALUE_KEY = "value";
public CustomizeRoutePredicateFactory(Class<Config> configClass) {
super(configClass);
}
@Override
/**
* 判断规则
*/
public Predicate<ServerWebExchange> apply(Config config) {
return new GatewayPredicate() {
@Override
public boolean test(ServerWebExchange serverWebExchange) {
ServerHttpRequest request = serverWebExchange.getRequest();
MultiValueMap<String, String> queryParams = request.getQueryParams();
String param = queryParams.getFirst(config.param);
return (param != null && !param.isEmpty()) && param.equals(config.value);
}
};
}
@Override
/**
* 短写法返回属性的顺序
*/
public List<String> shortcutFieldOrder() {
return Arrays.asList(PARAM_KEY, VALUE_KEY);
}
@Validated
/**
* 可配置参数
*/
public static class Config {
@NotEmpty
private String param;
@NotEmpty
private String value;
public String getParam() {
return param;
}
public void setParam(String param) {
this.param = param;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
}
7.3、过滤器
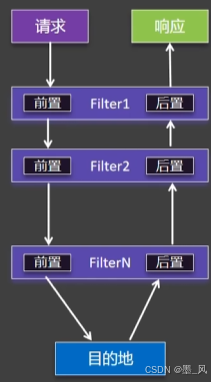
7.3.1、介绍
在gateway中要实现其他的功能:权限控制、流量监控、统一日志处理等。就需要使用到gateway中所提供的过滤器了。过滤器,可以对进入网关的请求和微服务返回的响应做处理: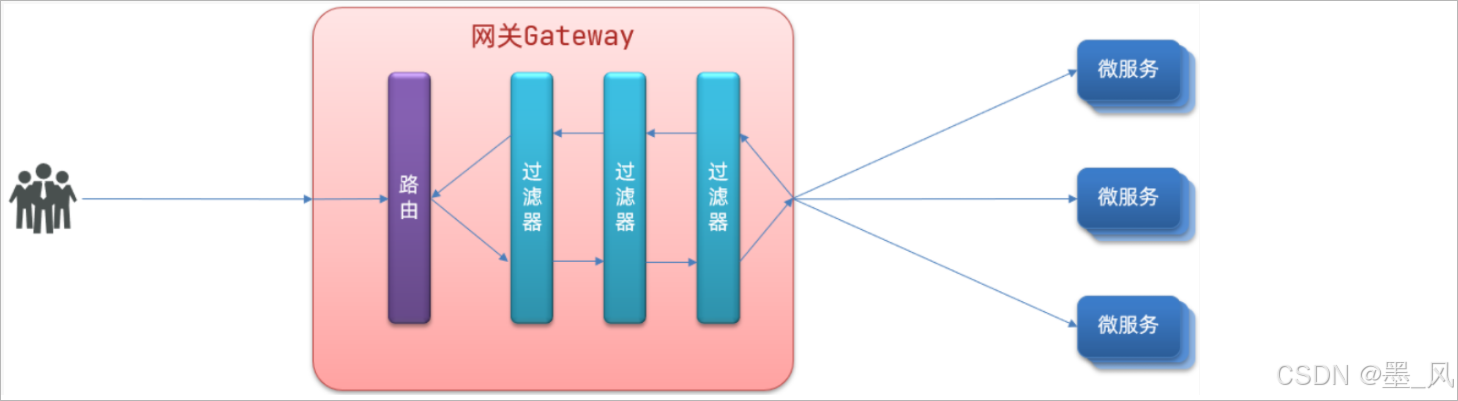
1、流程
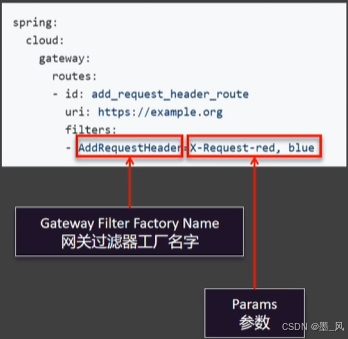
2、示例
3、过滤器工厂
- 在Gateway中提供了三种级别的类型的过滤器:
- 路由过滤器:只针对当前路由有效
- 默认过滤器:针对所有的路由都有效
- 全局过滤器:针对所有的路由都有效,需要进行自定义
- 官网如下图处查看
- 过滤器简介
| 名称 | 参数(个数/类型) | 作⽤ |
|---|---|---|
AddRequestHeader |
2/string |
添加请求头 |
AddRequestHeadersIfNotPresent |
1/List<string> |
如果没有则添加请求头,key:value⽅式 |
AddRequestParameter |
2/string、string |
添加请求参数 |
AddResponseHeader |
2/string、string |
添加响应头 |
CircuitBreaker |
1/string |
仅⽀持forward:/inCaseOfFailureUseThis⽅式进⾏熔断 |
CacheRequestBody |
1/string |
缓存请求体 |
DedupeRespons |
1/string |
移除重复响应头,多个⽤空格分割 |
FallbackHeaders |
1/string |
设置Fallback头 |
JsonToGrpc |
请求体Json转为gRPC |
|
LocalResponseCache |
2/string |
响应数据本地缓存 |
MapRequestHeader |
2/string |
把某个请求头名字变为另⼀个名字 |
ModifyRequestBody |
仅Java代码⽅式 |
修改请求体 |
ModifyResponseBody |
仅Java代码⽅式 |
修改响应体 |
PrefixPath |
1/string |
⾃动添加请求前缀路径 |
PreserveHostHeader |
0 |
保护Host头 |
RedirectTo |
3/string |
重定向到指定位置 |
RemoveJsonAttributesResponseBody |
1/string |
移除响应体中的某些Json字段,多个⽤,分割 |
RemoveRequestHeader |
1/string |
移除请求头 |
RemoveRequestParameter |
1/string |
移除请求参数 |
RemoveResponseHeader |
1/string |
移除响应头 |
RequestHeaderSize |
2/string |
设置请求⼤⼩,超出则响应431状态码 |
RequestRateLimiter |
1/string |
请求限流 |
RewriteLocationResponseHeader |
4/string |
重写Location响应头 |
RewritePath |
2/string |
路径重写 |
RewriteRequestParameter |
2/string |
请求参数重写 |
RewriteResponseHeader |
3/string |
响应头重写 |
SaveSession |
0 |
session保存,配合spring-session框架 |
SecureHeaders |
0 |
安全头设置 |
SetPath |
1/string |
路径修改 |
SetRequestHeader |
2/string |
请求头修改 |
SetResponseHeader |
2/string |
响应头修改 |
SetStatus |
1/int |
设置响应状态码 |
StripPrefix |
1/int |
路径层级拆除 |
Retry |
7/string |
请求重试设置 |
RequestSize |
1/string |
请求⼤⼩限定 |
SetRequestHostHeader |
1/string |
设置Host请求头 |
TokenRelay |
1/string |
OAuth2的token转发 |
7.3.2、使用(路由过滤器)
单个服务生效
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates: # 断言
- name: Path
args:
patterns: /api/user/**
matchTrailingSlash: true # 默认为true 开启后 /api/user 和/api/user/识别为一个路径,否则识别为2个
filters: # 过略器
- RewritePath=/api/user/?(?<segment>.*), /$\{segment} # 路径重写 /api/user/?(?<segment>.*) 重写为/$\{segment}
- AddResponseHeader=X-Response-Red, Blue # 给响应头写一个参数X-Response-Red 值Blue
7.3.3、默认过滤器
如果要对所有的路由都生效,则可以将过滤器工厂写到default下。格式如下:
spring:
cloud:
gateway:
default-filters: # 默认过滤器
- RewritePath=/api/[^/]+/(?<segment>.*), /$\{segment} # 路径重写 /api/user/a 重写为/a
7.3.4、全局过滤器
- 上述的过滤器是gateway中提供的默认的过滤器,每一个过滤器的功能都是固定的。但是如果我们希望拦截请求,做自己的业务逻辑,默认的过滤器就没办法实现。此时就需求使用全局过滤器,全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
- ·注意:全局过滤器不用再ymI中配置,默认网关中所有的路由都要过滤。
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.util.MultiValueMap;
import org.springframework.util.StringUtils;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
/**
* @version 1.0
* @Author moFeng
* @Date 2025/6/7 21:51
* @注释
*/
@Slf4j
@Component
public class CustomGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// ServerHttpRequest request = exchange.getRequest();
// String uri = request.getURI().toString();
// long start = System.currentTimeMillis();
// DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// log.info("请求【{}】开始:时间:{}", uri, dateFormat.format(start));
// //================================以上是前置逻辑======================================
// Mono<Void> filter = chain.filter(exchange)//放行
// .doFinally(result -> {
// //================================下面是后置逻辑======================================
// long end = System.currentTimeMillis();
// log.info("请求【{}】结束:耗时:{}", uri, end - start);
// });
/**判断请求参数中是否有username,如果同时满足则放行,否则拦*/
//exchange代表的是服务瑞接收的请求
ServerHttpRequest request = exchange.getRequest();
//请求头中那是以key=vaLue
MultiValueMap<String, String> queryParams = request.getQueryParams();
//在查询参数中,获取想要的参数
String username = queryParams.getFirst("username");
if (!StringUtils.hasText(username)) {
//拦戳
ServerHttpResponse response = exchange.getResponse();
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
@Override
public int getOrder() {
//指定当前过滤器的执行优先级
return 0;//数字越小,优先级越高
}
}
注释部分的功能代码执行结果
7.3.5、自定义过滤器
这部分格式照着官方的过滤器抄就行了
- 代码
package com.ioart.gateway.filter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.gateway.filter.factory.AbstractGatewayFilterFactory;
import java.util.Arrays;
import java.util.List;
import java.util.UUID;
import org.springframework.cloud.gateway.filter.GatewayFilter;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.support.GatewayToStringStyler;
import org.springframework.http.HttpHeaders;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
/**
* @version 1.0
* @Author moFeng
* @Date 2025/6/7 23:19
* @注释
*/
@Slf4j
@Component
public class OnceTokenGatewayFilterFactory extends AbstractGatewayFilterFactory<OnceTokenGatewayFilterFactory.Config> {
public static final String NAME_KEY = "name";
public static final String VALUE_KEY = "value";
public OnceTokenGatewayFilterFactory(Class<Config> configClass) {
super(configClass);
}
public OnceTokenGatewayFilterFactory() {
super(Config.class);
}
@Override
public List<String> shortcutFieldOrder() {
return Arrays.asList(NAME_KEY, VALUE_KEY);
}
public GatewayFilter apply(final OnceTokenGatewayFilterFactory.Config config) {
return new GatewayFilter() {
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
return chain.filter(exchange).then(Mono.fromRunnable(() -> {
ServerHttpResponse response = exchange.getResponse();
HttpHeaders headers = response.getHeaders();
String value = config.getValue();
if ("uuid".equals(value)) {
value = UUID.randomUUID().toString();
}
if ("jwt".equals(value)) {
value = "jwt.jwt.jwt";
}
headers.add(config.getName(),value);
}));
}
public String toString() {
return GatewayToStringStyler.filterToStringCreator(OnceTokenGatewayFilterFactory.this).append(config.getName(), config.getValue()).toString();
}
};
}
public static class Config {
private String name;
private String value;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
}
- yml
filters: # 过略器
- OnceToken=onceToken, uuid
7.4、跨域
spring:
cloud:
gateway:
# 全局跨域
globalcors:
cors-configurations:
'[/**]':
allowed-origin-patterns: '*' # 允许所有跨域
allowed-headers: '*' # 允许所有头
allowedMethods: '*' # 允许所有请求方式
# - GET
# - POST
routes:
- id: user-service # 唯一ID
uri: lb://lb://user-service #目的地
predicates: # 断言
- - Path=/api/user/**
metadata:
# 局部跨域
cors:
allowedOrigins: '*'
allowedMethods:
- GET
- POST
allowedHeaders: '*'
maxAge: 30
7.5、1.6.6 过滤器执行顺序
- 请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
- 请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
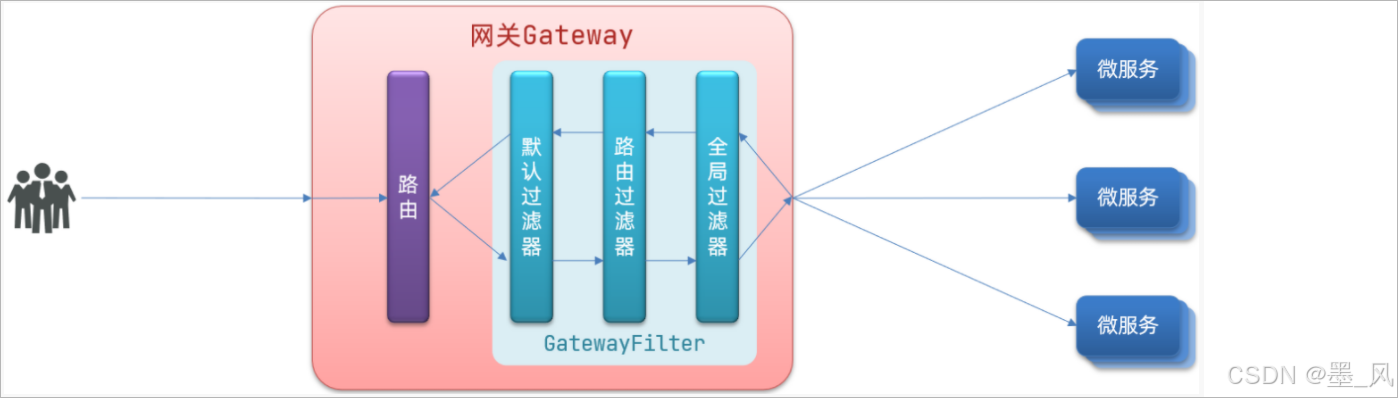
- 排序的规则
- 按照order的值进行排序,order的值越小,优先级越高,执行顺序越靠前。
- 路由过滤器和默认过滤器会按照order的值进行排序,这个值由spring进行指定,默认是按照声明顺序从1递增。
- 当过滤器的order值一样时,会按照 globalFilter > defaultFilter > 路由过滤器的顺序执行。
7.6、微服务调用过网关
没必要,多走一条路。但可以过
/**
* @version 1.0
* @Author moFeng
* @Date 2025/6/2 17:04
* @注释
*/
//@FeignClient(value = "commodity-service", fallback = CommodityFeignClientFallback.class) //feign客户端
@FeignClient(value = "gateway", fallback = CommodityFeignClientFallback.class) //feign客户端
public interface CommodityFeignClient {
// @GetMapping("/heath/state")
// R checkHeath();
@GetMapping("/api/commodity/heath/state")
R checkHeath();
//
// @GetMapping("/heath/test/{userId}")
// R getState(@PathVariable("userId") String userId);
@GetMapping("/api/commodity/heath/test/{userId}")
R getState(@PathVariable("userId") String userId);
// @GetMapping("/heath/test2")
// R getState2(@RequestParam("userId") String userId);
@GetMapping("/api/commodity/heath/test2")
R getState2(@RequestParam("userId") String userId);
}
八、分布式事务(Seata)
8.1、概念
8.1.1、事务概念
- 事务:提供一种“要么什么都不做,要么做全套(All or Nothing)”机制
1.事务的并发问题
- 脏读:事务A读取了事务B更新的数据,事务B未提交并回滚数据,那么A读取到的数据是脏数据。
- 不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
- 幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A更改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
- 小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
2.MySQL事务隔离级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | √ | √ | √ |
| 读已提交(read-committed) | × | √ | √ |
| 可重复读(repeatable-read) | × | × | √ |
| 串行化(serializable) | × | × | × |
mysql默认的事务隔离级别为可重复读repeatable-read
3.事务传播行为
- 指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行。 例如:methodA事务方法调用methodB事务方法时,methodB是继续在调用者methodA的事务中运行呢,还是为自己开启一个新事务运行,这就是由methodB的事务传播行为决定的。
- Spring定义了七种传播行为:参考TransactionDefinition类
| 事务传播行为类型 | 说明 |
|---|---|
| PROPAGATION_REQUIRED | 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。默认 |
| PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行 |
| PROPAGATION_MANDATORY | 使用当前的事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。(一个新的事务将启动,而且如果有一个现有的事务在运行的话,则这个方法将在运行期被挂起,直到新的事务提交或者回滚才恢复执行) |
| PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED | 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。(外层事务抛出异常回滚,那么内层事务必须回滚,反之内层事务并不影响外层事务) |
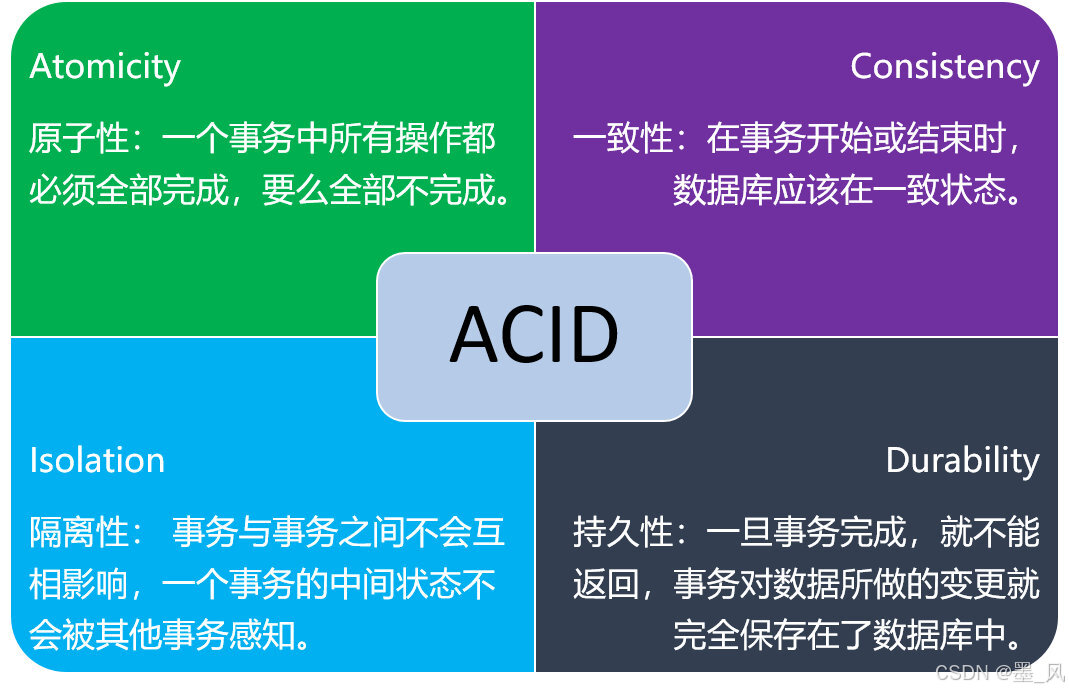
4.事务ACID四大特性
8.1.2、分布式事务
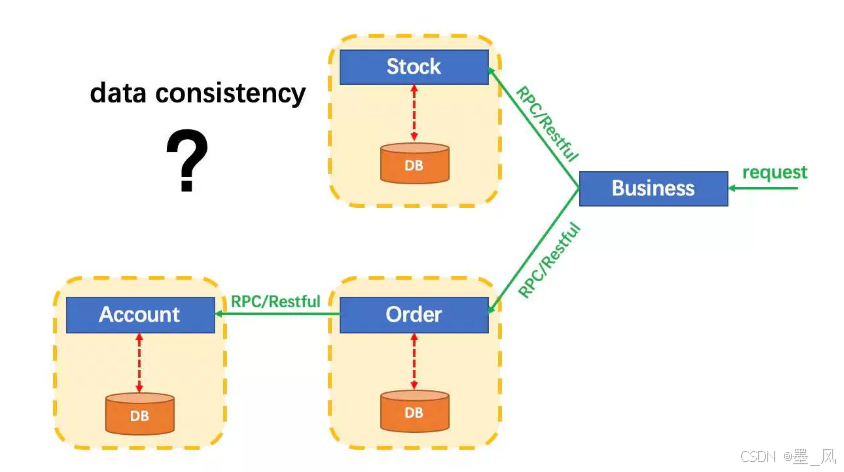
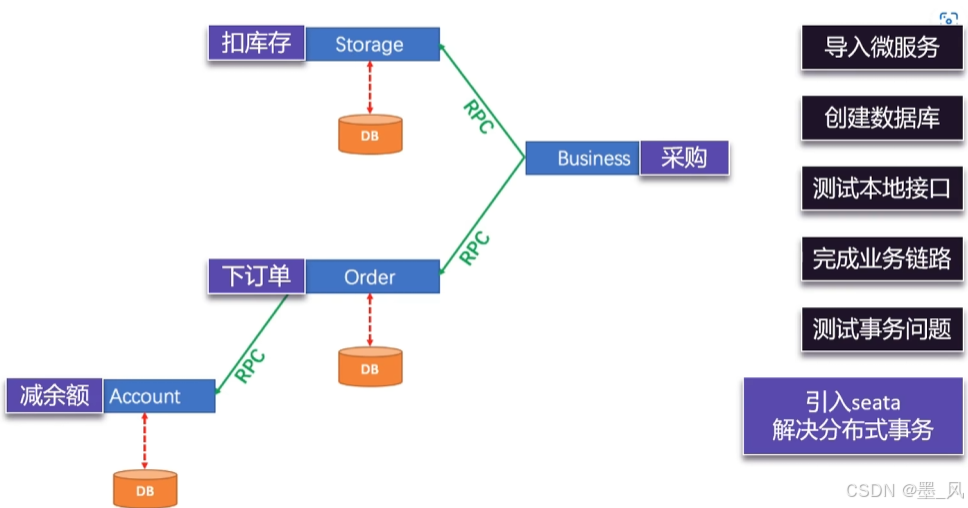
分布式事务 :就是指不是在单个服务或单个数据库架构下,产生的事务!例如,电商行业中比较常见的下单付款案例,包括创建新订单,扣减商品库存,从用户账户余额扣除金额,完成以上操作需要访问三个不同的微服务和三个不同的数据库。
要保证“业务”的原子性,要么所有操作全部成功,要么全部失败,不允许出现部分成功部分失败的现象,ACID难以满足,是分布式事务要解决的问题了。
8.1.3、CAP定理
1.内容
- CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer’s theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。
对于设计分布式系统的架构师来说,CAP 是必须掌握的理论。 - 在一个
分布式系统中,当涉及读写操作时,只能保证一致性(Consistence)、可用性。(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。- C 一致性(Consistency):对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
- A 可用性(Availability):非故障的节点在合理的时间内返回合理的响应
(不是错误和超时的响应)。 - P 分区容忍性(Partition Tolerance):当出现网络分区后
(可能是丢包,也可能是连接中断,还可能是拥塞),系统能够继续“履行职责”。
2.CAP特点
- 在实际设计过程中,每个系统不可能只处理一种数据,而是包含多种类型的数据,
有的数据必须选择 CP,有的数据必须选择 AP,分布式系统理论上不可能选择 CA 架构。 - CP:如下图所示,
为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。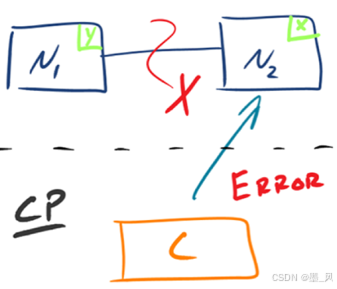
- AP:如下图所示,
为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。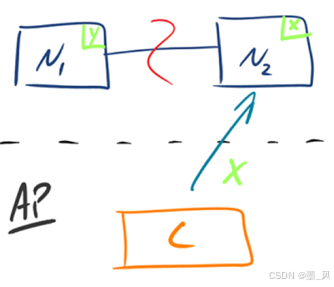
8.1.4、BASE 理论
- BASE理论是对CAP的一种解决思路,包含三个思想:
BasicallyAvailable(基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。SoftState(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。EventuallyConsistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
- 分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论,有两种解决思路:
AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态。
8.1.5、调用链路
8.2、分布式事务解决方案
8.2.1、两阶段提交(2PC-XA)
(1)投票阶段(voting phase):参与者将操作结果通知协调者;
(2)提交阶段(commit phase):协调者收到参与者的通知后,协调者再向参与者发出通知,根据反馈情况决定各参与者是否要提交还是回滚;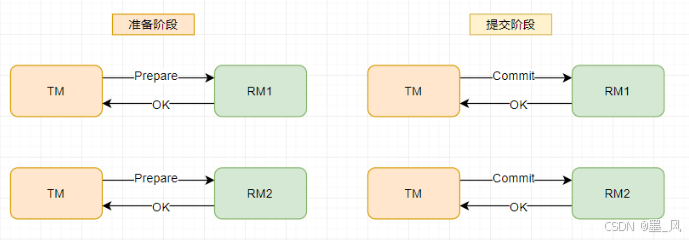
8.2.2、补偿事务(TCC)
TCC事务其实主要包含两个阶段:Try阶段、Confirm/Cancel阶段。其中Try阶段完成业务检查并资源预留,确保在Confirm阶段资源可用,可以最大程度的确保confirm阶段能够执行成功。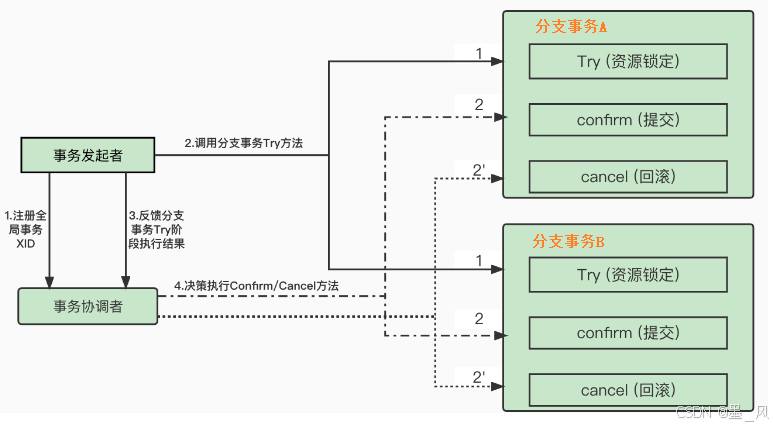
8.2.3、本地消息表
本地消息表这个方案最初是ebay架构师Dan Pritchett在 2008 年发表给 ACM 的文章。设计核心是将需要分布式处理的任务通过消息的方式来异步确保执行。
1.流程
- 订单系统新增一条消息表,将新增订单和新增消息放到一个事务里完成,然后通过轮询的方式去查询消息表,将消息推送到 MQ,库存系统去消费 MQ。
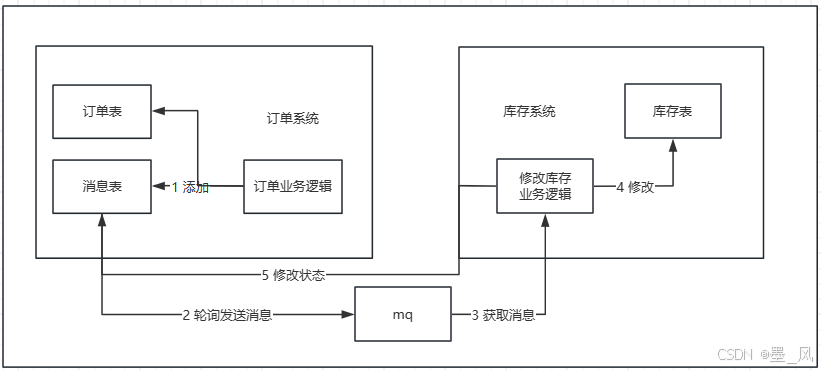
- 执行流程:
- 订单系统,添加一条订单和一条消息,在一个事务里提交。
- 订单系统,使用定时任务轮询查询状态为未同步的消息表,发送到 MQ,如果发送失败,就重试发送。
- 库存系统,接收 MQ 消息,修改库存表,需要保证幂等操作。
- 如果修改成功,调用 RPC 接口修改订单系统消息表的状态为已完成或者直接删除这条消息。如果修改失败,可以不做处理,等待重试。
- 订单系统中的消息有可能由于业务问题会一直重复发送,所以为了避免这种情况可以记录一下发送次数,当达到次数限制之后报警,人工接入处理;库存系统需要保证幂等,避免同一条消息被多次消费造成数据一致。
- 本地消息表这种方案实现了最终一致性,需要在业务系统里增加消息表,业务逻辑中多一次插入的 DB 操作,所以性能会有损耗,而且最终一致性的间隔主要由定时任务的间隔时间决定。
- 优点:一种非常经典的实现,避免了分布式事务,实现了最终一致性。
- 缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
2.MQ事务消息
在上述的本地消息表方案中,生产者需要额外创建消息表,还需要对本地消息表进行轮询,业务负担较重。阿里开源的RocketMQ 4.3之后的版本正式支持事务消息,该事务消息本质上是把本地消息表放到RocketMQ上,解决生产端的消息发送与本地事务执行的原子性问题。
- RocketMQ提供了类似X/Open XA的分布事务功能,通过MQ的事务消息能达到分布式事务的最终一致。
- 发送方在业务执行开始会先向消息服务器中投递 “ 半消息 ” ,半消息即暂时不会真正投递的消息,当发送方(即生产者)将消息成功发送给了MQ服务端且并未将该消息的二次确认结果返回,此时消息状态是“ 暂时不可投递 ” 状态(可以认为是状态未知)。该状态下的消息即半消息。
- 如果出现网络闪断、生产者应用重启等原因导致事务消息二次确认丢失,MQ服务端会通过扫描发现某条消息长期处于 “ 半消息 ” 状态,MQ服务端会主动向生产者查询该消息的最终状态是处于Commit(消息提交)还是Rollback(消息回滚)。这个过程称为消息回查。
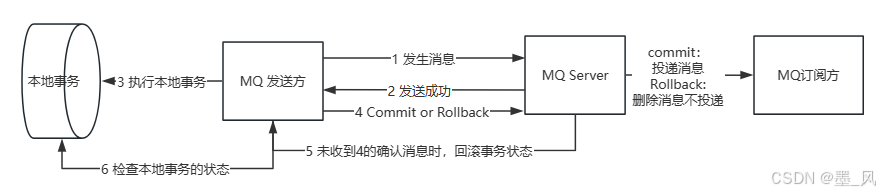
- 具体流程如下:
- Producer 向 MQ 服务器 发送消息 , MQ Server 将消息状态标记为 Prepared(预备状态),注意此时这条消息消费者(MQ订阅方)是无法消费到的。
- MQ 服务器收到消息并持久化成功之后,会向Producer 确认首次消息发送成功,此时消息处于 half message(半消息) 状态,并未发送给对应的 Consumer 。
- Producer 开始执行本地事务逻辑 , 通过本地数据库事务控制。
- 根据事务执行结果,Producer 向 MQ 服务器提交二次确认 ( commit 或者 rollback) 。MQ Server 收到 Commit 状态则将半消息标记为可投递,Consumer 最终将收到该消息;MQ Server 收到 Rollback 状态则删除半消息,Consumer 将不会接受该消息。
- 在断网或者应用重启的情况下,二次确认未成功的发给 MQ Server,MQ Server 会主动向 Producer 启动消息回查。
- Producer 根据事务执行结果,对消息回查返回对应的结果。
- Mq Server根据返回结果,决定继续投递消息或者丢弃消息(重复第4步操作)
- 优点: 实现了最终一致性,不需要依赖本地数据库事务。
- 缺点: 目前主流MQ中只有RocketMQ支持事务消息。
8.3、seata简介
- Seata是阿里开源的一个分布式事务框架,能够让大家在操作分布式事务时,像操作本地事务一样简单。一个注解搞定分布式事
- Seata是 2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。致力于提供高性能和简单易用的分布式事务服务,为用户打造一站式的分布式解决方案。
- 官网地址:http://seata.io/,其中的文档、播客中提供了大量的使用说明、源码分析。
- Seata事务管理中有三个重要的角色:
- TC (Transaction Coordinator) - 事务协调者: 维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) - 事务管理器: 定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器: 管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。架构图:
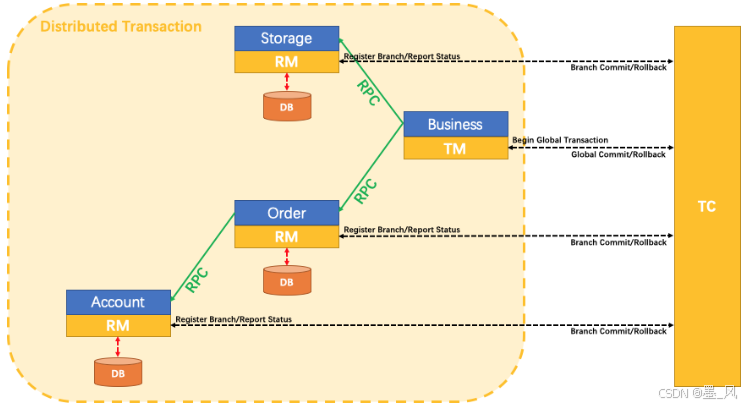
- 总体概括:TM是一个分布式事务的发起者和终结者,TC负责维护分布式事务的运行状态,而RM则负责本地事务的运行。
- Seata基于上述架构提供了四种不同的分布式事务解决方案:(无论哪种方案,都离不开TC,也就是事务的协调者。)
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入
- TCC模式:最终一致的分阶段事务模式,有业务侵入
- AT模式:最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式
- SAGA模式:长事务模式,有业务侵入
8.4、安装(Docker)
8.4.1、Seata数据库
执行以下SQL脚本完成 Seata 数据库创建和表的初始化,在本地或服务器上创建一个 seata 数据库并创建表
-- 1. 执行语句创建名为 seata 的数据库
CREATE DATABASE seata DEFAULT CHARACTER SET utf8mb4 DEFAULT COLLATE utf8mb4_general_ci;
-- 2.执行脚本完成 Seata 表结构的创建
use seata;
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name` VARCHAR(128),
`timeout` INT,
`begin_time` BIGINT,
`application_data` VARCHAR(2000),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id` BIGINT NOT NULL,
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id` VARCHAR(256),
`branch_type` VARCHAR(8),
`status` TINYINT,
`client_id` VARCHAR(64),
`application_data` VARCHAR(2000),
`gmt_create` DATETIME(6),
`gmt_modified` DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key` VARCHAR(128) NOT NULL,
`xid` VARCHAR(128),
`transaction_id` BIGINT,
`branch_id` BIGINT NOT NULL,
`resource_id` VARCHAR(256),
`table_name` VARCHAR(32),
`pk` VARCHAR(36),
`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_status` (`status`),
KEY `idx_branch_id` (`branch_id`),
KEY `idx_xid_and_branch_id` (`xid` , `branch_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE IF NOT EXISTS `distributed_lock`
(
`lock_key` CHAR(20) NOT NULL,
`lock_value` VARCHAR(20) NOT NULL,
`expire` BIGINT,
primary key (`lock_key`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);
8.4.2、Seata 外置配置(Nacos)
- 在 Nacos 默认的 public 命名空间下 ,新建配置 Data ID 为 seata-server.properties ,Group 为 DEFAULT_GROUP 的配置,配置如下:
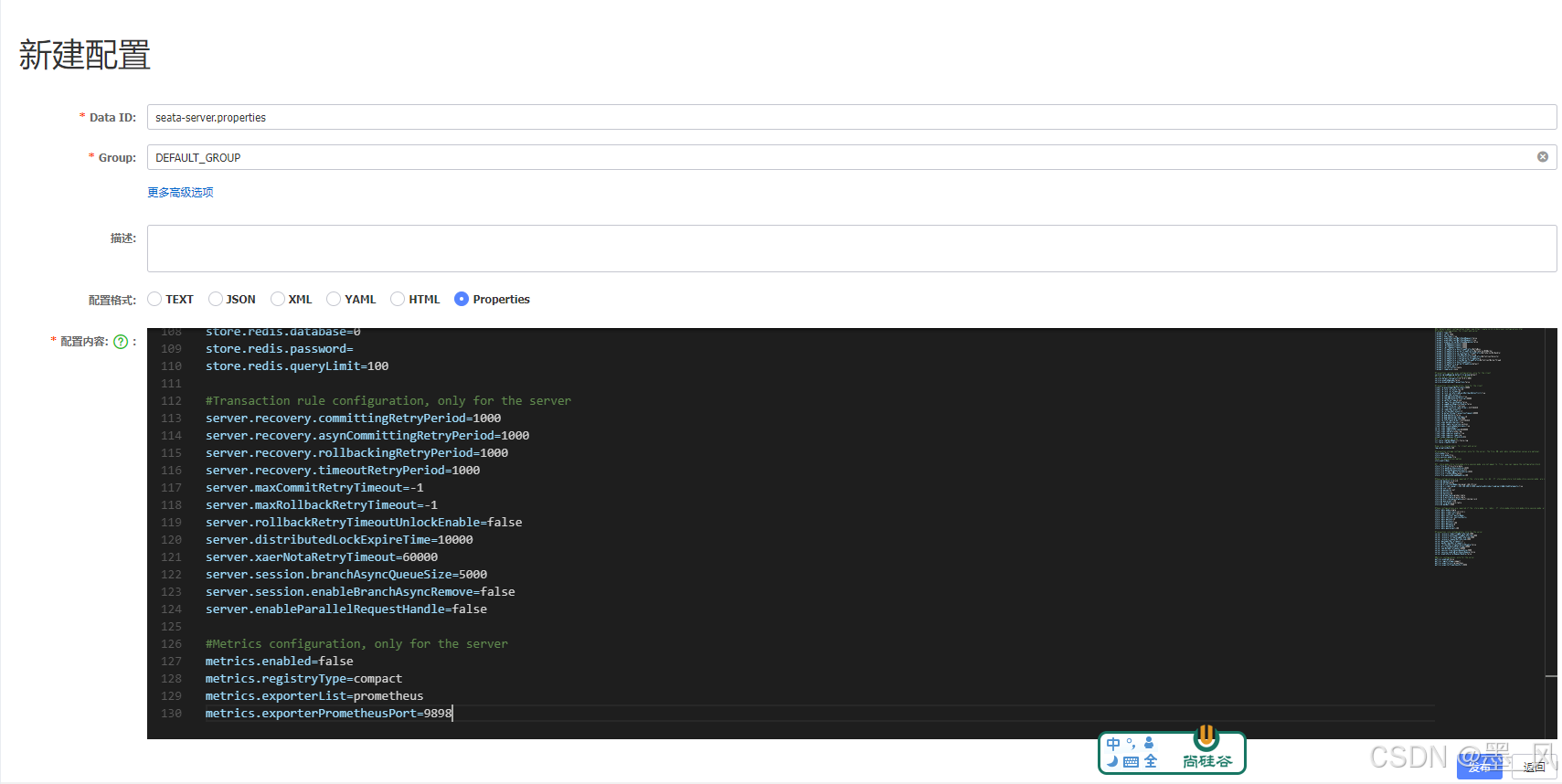
- 获取Seata 配置在线地址:https://github.com/seata/seata/blob/1.5.2/script/config-center/config.txt 仅需修存储模式为db以及对应的db连接配置。
- **store.mode=db **存储模式选择为数据库
- 192.168.200.130 MySQL主机地址
- store.db.user=root 数据库用户名
- store.db.password=root 数据库密码
#For details about configuration items, see https://seata.io/zh-cn/docs/user/configurations.html
#Transport configuration, for client and server
transport.type=TCP
transport.server=NIO
transport.heartbeat=true
transport.enableTmClientBatchSendRequest=false
transport.enableRmClientBatchSendRequest=true
transport.enableTcServerBatchSendResponse=false
transport.rpcRmRequestTimeout=30000
transport.rpcTmRequestTimeout=30000
transport.rpcTcRequestTimeout=30000
transport.threadFactory.bossThreadPrefix=NettyBoss
transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker
transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler
transport.threadFactory.shareBossWorker=false
transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector
transport.threadFactory.clientSelectorThreadSize=1
transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread
transport.threadFactory.bossThreadSize=1
transport.threadFactory.workerThreadSize=default
transport.shutdown.wait=3
transport.serialization=seata
transport.compressor=none
#Transaction routing rules configuration, only for the client
service.vgroupMapping.default_tx_group=default
#If you use a registry, you can ignore it
service.default.grouplist=127.0.0.1:8091
service.enableDegrade=false
service.disableGlobalTransaction=false
#Transaction rule configuration, only for the client
client.rm.asyncCommitBufferLimit=10000
client.rm.lock.retryInterval=10
client.rm.lock.retryTimes=30
client.rm.lock.retryPolicyBranchRollbackOnConflict=true
client.rm.reportRetryCount=5
client.rm.tableMetaCheckEnable=true
client.rm.tableMetaCheckerInterval=60000
client.rm.sqlParserType=druid
client.rm.reportSuccessEnable=false
client.rm.sagaBranchRegisterEnable=false
client.rm.sagaJsonParser=fastjson
client.rm.tccActionInterceptorOrder=-2147482648
client.tm.commitRetryCount=5
client.tm.rollbackRetryCount=5
client.tm.defaultGlobalTransactionTimeout=60000
client.tm.degradeCheck=false
client.tm.degradeCheckAllowTimes=10
client.tm.degradeCheckPeriod=2000
client.tm.interceptorOrder=-2147482648
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
#For TCC transaction mode
tcc.fence.logTableName=tcc_fence_log
tcc.fence.cleanPeriod=1h
#Log rule configuration, for client and server
log.exceptionRate=100
#Transaction storage configuration, only for the server. The file, DB, and redis configuration values are optional.
store.mode=db
store.lock.mode=db
store.session.mode=db
#Used for password encryption
store.publicKey=
#If `store.mode,store.lock.mode,store.session.mode` are not equal to `file`, you can remove the configuration block.
store.file.dir=file_store/data
store.file.maxBranchSessionSize=16384
store.file.maxGlobalSessionSize=512
store.file.fileWriteBufferCacheSize=16384
store.file.flushDiskMode=async
store.file.sessionReloadReadSize=100
#These configurations are required if the `store mode` is `db`. If `store.mode,store.lock.mode,store.session.mode` are not equal to `db`, you can remove the configuration block.
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://192.168.200.130:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=root
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.distributedLockTable=distributed_lock
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
#These configurations are required if the `store mode` is `redis`. If `store.mode,store.lock.mode,store.session.mode` are not equal to `redis`, you can remove the configuration block.
store.redis.mode=single
store.redis.single.host=127.0.0.1
store.redis.single.port=6379
store.redis.sentinel.masterName=
store.redis.sentinel.sentinelHosts=
store.redis.maxConn=10
store.redis.minConn=1
store.redis.maxTotal=100
store.redis.database=0
store.redis.password=
store.redis.queryLimit=100
#Transaction rule configuration, only for the server
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.distributedLockExpireTime=10000
server.xaerNotaRetryTimeout=60000
server.session.branchAsyncQueueSize=5000
server.session.enableBranchAsyncRemove=false
server.enableParallelRequestHandle=false
#Metrics configuration, only for the server
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898
8.4.3、获取seata配置
- 创建临时容器{ 主要的目的:拉取配置文件}
docker run -d --name seata-server -p 8091:8091 -p 7091:7091 seataio/seata-server:1.7.0
- 创建文件夹为容器挂载目录
mkdir -p /mydata/seata/config
- 复制容器配置至宿主机
docker cp seata-server:/seata-server/resources/ /mydata/seata/config
- 删除临时容器
docker rm -f seata-server
8.4.4、修改Seata启动配置-启动容器
在获取到 seata-server 的应用配置之后,因为这里采用 Nacos 作为 seata 的配置中心和注册中心,所以需要修改 application.yml 里的配置中心和注册中心地址,详细配置我们可以从 application.example.yml 拿到。
application.yaml配置如下,直接覆盖 /mydata/seata/config/resources/application.yml- namespace nacos命名空间id,不填默认是public命名空间。
- data-id: seataServer.properties Seata外置文件所处Naocs的Data ID,参考上小节的 导入配置至 Nacos。
- group: DEFAULT_GROUP 指定注册至nacos注册中心的分组名。
- cluster: default 指定注册至nacos注册中心的集群名。
server:
port: 7091
seata:
config:
type: nacos
nacos:
server-addr: 192.168.200.130:8848
namespace:
group: DEFAULT_GROUP
data-id: seata-server.properties
security:
secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017
tokenValidityInMilliseconds: 1800000
registry:
type: nacos
nacos:
application: seata-server
server-addr: 192.168.200.130:8848
namespace:
group: DEFAULT_GROUP
cluster: default
console:
user:
username: seata
password: seata
logging:
config: classpath:logback-spring.xml
file:
path: /mydata/seata/logs
- 创建容器,必须使用宿主机的Seata配置
docker run -d --name seata-server --restart=always -p 8091:8091 -p 7091:7091 -e SEATA_IP=ip -v /mydata/seata/config/resources:/seata-server/resources seataio/seata-server:1.7.0
version: '3.8'
services:
seata-server:
image: seataio/seata-server:1.7.0
container_name: seata-server
restart: always
ports:
- "8091:8091"
- "7091:7091"
environment:
- SEATA_IP=ip
volumes:
- /mydata/seata/config/resources:/seata-server/resources
- 通过Nacos验证Seata注册状态
- Seata管理页面http://ip:7091/
8.5、整合
8.5.1、java
1.配置
- 向数据库添加表:
-- 注意此处0.7.0+ 增加字段 context
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
- 添加依赖:
service-order,service-account,service-user
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.7.1</version>
</dependency>
- 添加配置文件:
service-order:
新增:application.yml
seata:
enabled: true
tx-service-group: ${spring.application.name}-group # 事务组名称
service:
vgroup-mapping:
#指定事务分组至集群映射关系,集群名default需要与seata-server注册到Nacos的cluster保持一致
service-order-group: default
registry:
type: nacos # 使用nacos作为注册中心
nacos:
server-addr: 192.168.200.130:8848 # nacos服务地址
group: DEFAULT_GROUP # 默认服务分组
namespace: "" # 默认命名空间
cluster: default # 默认TC集群名称
service-account:
seata:
enabled: true
tx-service-group: ${spring.application.name}-group # 事务组名称
service:
vgroup-mapping:
#指定事务分组至集群映射关系,集群名default需要与seata-server注册到Nacos的cluster保持一致
service-account-group: default
registry:
type: nacos # 使用nacos作为注册中心
nacos:
server-addr: 192.168.200.130:8848 # nacos服务地址
group: DEFAULT_GROUP # 默认服务分组
namespace: "" # 默认命名空间
cluster: default # 默认TC集群名称
service-user:
seata:
enabled: true
tx-service-group: ${spring.application.name}-group # 事务组名称
service:
vgroup-mapping:
#指定事务分组至集群映射关系,集群名default需要与seata-server注册到Nacos的cluster保持一致
service-user-group: default
registry:
type: nacos # 使用nacos作为注册中心
nacos:
server-addr: 192.168.200.130:8848 # nacos服务地址
group: DEFAULT_GROUP # 默认服务分组
namespace: "" # 默认命名空间
cluster: default # 默认TC集群名称
2.使用
我们只需要使用一个@GlobalTransactional(和@Transactional用法差不多)注解在业务方法上:
@GlobalTransactional
public void purchase(String userId, String commodityCode, int orderCount) {
......
}
8.6、原理
8.6.1、Seata AT 模式
1.简述
- 前提
- 基于支持本地 ACID 事务的关系型数据库。
- Java 应用,通过 JDBC 访问数据库。
- 整体机制:两阶段提交协议的演变,
- 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
- 二阶段:提交异步化,非常快速地完成。回滚通过一阶段的回滚日志进行反向补偿。
2.写隔离
- 一阶段本地事务提交前,需要确保先拿到 全局锁 。
- 拿不到 全局锁 ,不能提交本地事务。
- 拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
以一个示例来说明:
- 两个全局事务 tx1 和 tx2,分别对 a 表的 m 字段进行更新操作,m 的初始值 1000。
- tx1 先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的 全局锁 ,本地提交释放本地锁。 tx2 后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的 全局锁 ,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2 需要重试等待全局锁 。
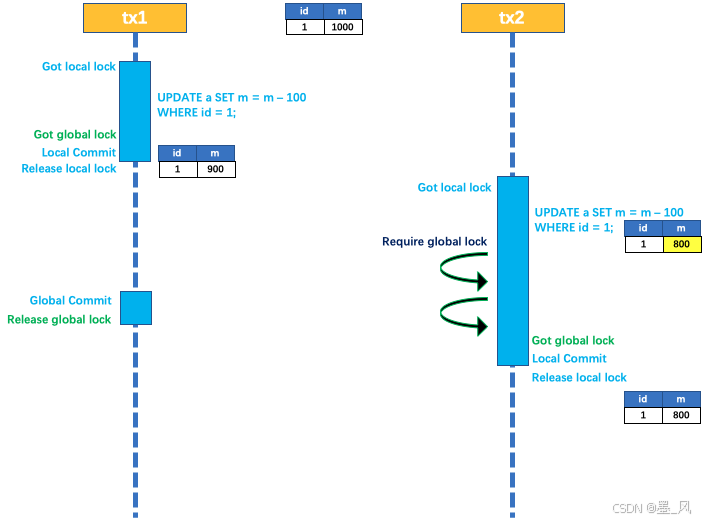
- tx1 二阶段全局提交,释放 全局锁 。tx2 拿到 全局锁 提交本地事务。
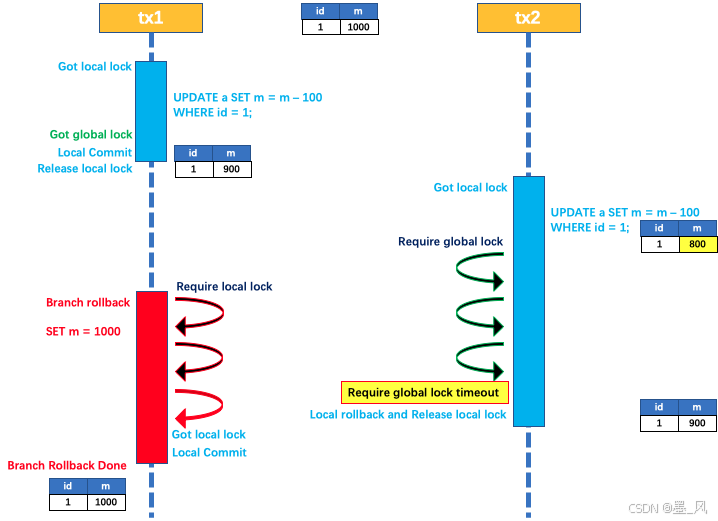
- 如果 tx1 的二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。
- 此时,如果 tx2 仍在等待该数据的 全局锁,同时持有本地锁,则 tx1 的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的 全局锁 等锁超时,放弃 全局锁 并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。
- 因为整个过程 全局锁 在 tx1 结束前一直是被 tx1 持有的,所以不会发生 脏写 的问题。
3.读隔离
- 在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是读未提交(Read Uncommitted) 。
- 如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。
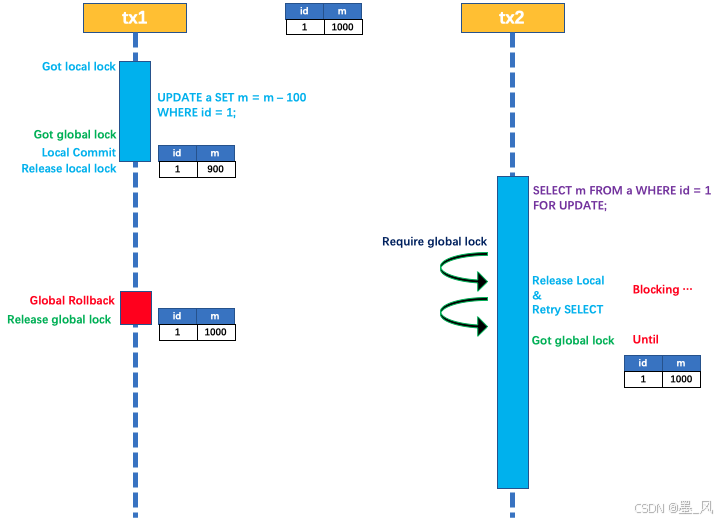
SELECT FOR UPDATE语句的执行会申请 全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。- 出于总体性能上的考虑,Seata 目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
4.工作机制
以一个示例来说明整个 AT 分支的工作过程。
业务表:product
| Field | Type | Key |
|---|---|---|
| id | bigint(20) | PRI |
| name | varchar(100) | |
| since | varchar(100) |
AT 分支事务的业务逻辑:
update product set name = 'GTS' where name = 'TXC';
一阶段
过程:
- 解析 SQL:得到 SQL 的类型(UPDATE),表(product),条件(where name = ‘TXC’)等相关的信息。
- 查询前镜像:根据解析得到的条件信息,生成查询语句,定位数据。
select id, name, since from product where name = 'TXC';
得到前镜像:
| id | name | since |
|---|---|---|
| 1 | TXC | 2014 |
- 执行业务 SQL:更新这条记录的 name 为 ‘GTS’。
- 查询后镜像:根据前镜像的结果,通过主键定位数据。
select id, name, since from product where id = 1;
得到后镜像:
| id | name | since |
|---|---|---|
| 1 | GTS | 2014 |
- 插入回滚日志:把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到
UNDO_LOG表中。
{
"branchId": 641789253,
"undoItems": [{
"afterImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "GTS"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"beforeImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "TXC"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"sqlType": "UPDATE"
}],
"xid": "xid:xxx"
}
- 提交前,向 TC 注册分支:申请 product 表中,主键值等于 1 的记录的 全局锁 。
- 本地事务提交:业务数据的更新和前面步骤中生成的 UNDO LOG 一并提交。
- 将本地事务提交的结果上报给 TC。
二阶段-回滚
- 收到 TC 的分支回滚请求,开启一个本地事务,执行如下操作。
- 通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录。
- 数据校验:拿 UNDO LOG 中的后镜与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理,详细的说明在另外的文档中介绍。
- 根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息生成并执行回滚的语句:
update product set name = 'TXC' where id = 1;
- 提交本地事务。并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
二阶段-提交
- 收到 TC 的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC。
- 异步任务阶段的分支提交请求将异步和批量地删除相应 UNDO LOG 记录。
回滚日志表
- UNDO_LOG Table:不同数据库在类型上会略有差别。
- 以 MySQL 为例:
| Field | Type |
|---|---|
| branch_id | bigint PK |
| xid | varchar(100) |
| context | varchar(128) |
| rollback_info | longblob |
| log_status | tinyint |
| log_created | datetime |
| log_modified | datetime |
-- 注意此处0.7.0+ 增加字段 context
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
九、LoadBalancer
9.1、简介
Spring Cloud LoadBalancer是Spring Cloud中负责客户端负载均衡的模块,其主要原理是通过选择合适的服务实例来实现负载均衡。- 客户端负载均衡:就是负载均衡算法由客户端提供。
9.2、LoadBalancer原理
Spring Cloud LoadBalancer的底层采用了一个拦截器LoadBalancerInterceptor,拦截了RestTemplate发出的请求,对地址做了修改。用一幅图来总结一下: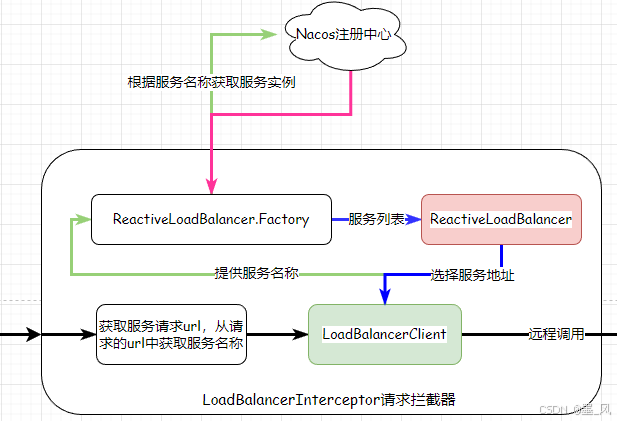
9.3、源码跟踪
-
LoadBalancerInterceptor核心源码如下所示: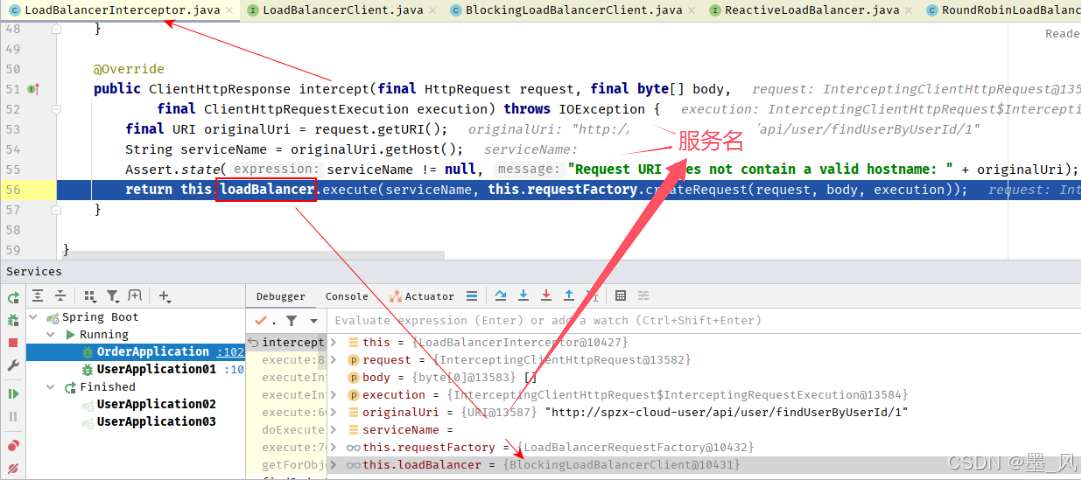
-
可以看到这里的intercept方法,拦截了用户的HttpRequest请求,然后做了几件事:
request.getURI():获取请求uri。originalUri.getHost():获取uri路径的主机名,就是服务id,user-servicethis.loadBalancer.execute():处理服务id,和用户请求。
-
这里的
this.loadBalancer是BlockingLoadBalancerClient类型,继续跟入。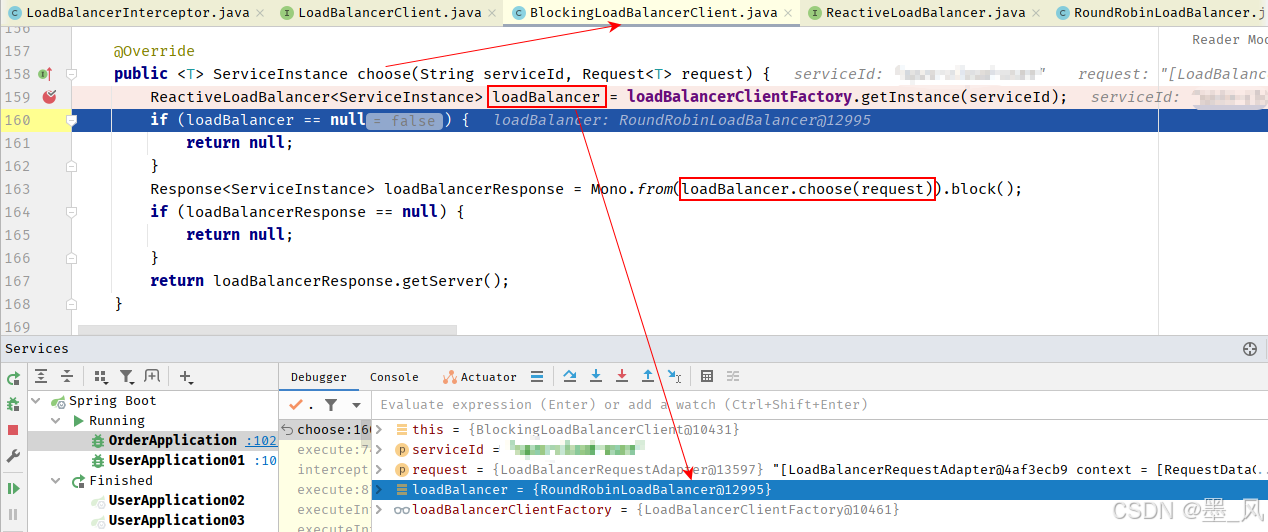
-
ReactiveLoadBalancer.Factory的getInstance方法做了两件事情:- 获取了一个具体的负载均衡算法对象
- 根据服务的id从Nacos注册中心中获取服务地址列表
-
紧跟着调用了RoundRobinLoadBalancer#choose方法,从服务列表中选择一个服务实例对象。
-
默认的负载均衡算法:RoundRobinLoadBalancer
9.4、更改负载均衡算法
LoadBalancer默认的负载均衡算法是RoundRobinLoadBalancer,如果想更改默认的负载均衡算法,那么此时需要向Spring容器中注册一个Bean,并且配置负载均衡的使用者。
代码如下所示:
1、在Spring容器中注册一个Bean
public class CustomLoadBalancerConfiguration {
/**
* @param environment: 用于获取环境属性配置,其中LoadBalancerClientFactory.PROPERTY_NAME表示该负载均衡器要应用的服务名称。
* @param loadBalancerClientFactory: 是Spring Cloud中用于创建负载均衡器的工厂类,通过getLazyProvider方法获取ServiceInstanceListSupplier对象,以提供可用的服务列表。
* ServiceInstanceListSupplier:用于提供ServiceInstance列表的接口,可以从DiscoveryClient或者其他注册中心中获取可用的服务实例列表。
* @return
*/
@Bean
ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
}
}
2、配置负载均衡算法的使用者
@Configuration
@LoadBalancerClients(value = {
@LoadBalancerClient(name = "spzx-cloud-user" , configuration = CustomLoadBalancerConfiguration.class) // 将负载均衡算法应用到指定的服务提供方中
})
public class RestTemplateConfiguration {
@Bean
@LoadBalanced // 让RestTemplate具有负载均衡的能力
public RestTemplate restTemplate() {
return new RestTemplate() ;
}
}

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 8
8 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)