携程酒店数据采集
本文介绍了两种爬取携程酒店数据的方法:requests模块和drissionpage模块。首先通过开发者工具分析数据位置,然后详细说明了使用drissionpage模块的步骤:1)配置浏览器路径;2)监听数据包特征;3)访问网站并等待加载;4)获取响应数据。文章提供了完整的代码示例,演示了如何通过自动化工具直接获取酒店列表数据。这种方法相比requests模块更简单,适合初学者快速上手网页数据采集
·
一.数据来源分析
1.明确需求
明确采集的网站以及数据内容
- 网址:https://hotels.ctrip.com/hotels/list
- 数据:酒店相关信息
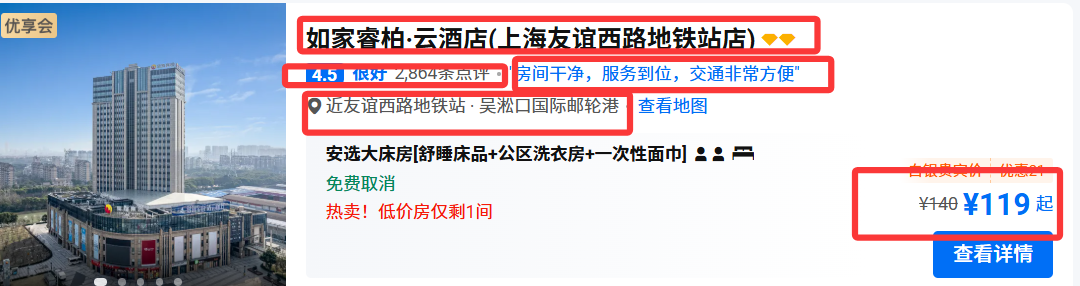
2.抓包分析
通过浏览器的开发者工具分析对应的数据的位置
- 打开开发者工具
- 刷新网页
- 让本网页的数据内容重新加载一遍(网站数据包)
- 通过关键字搜索找到对应的数据位置
- 关键字搜索:需要什么搜索什么
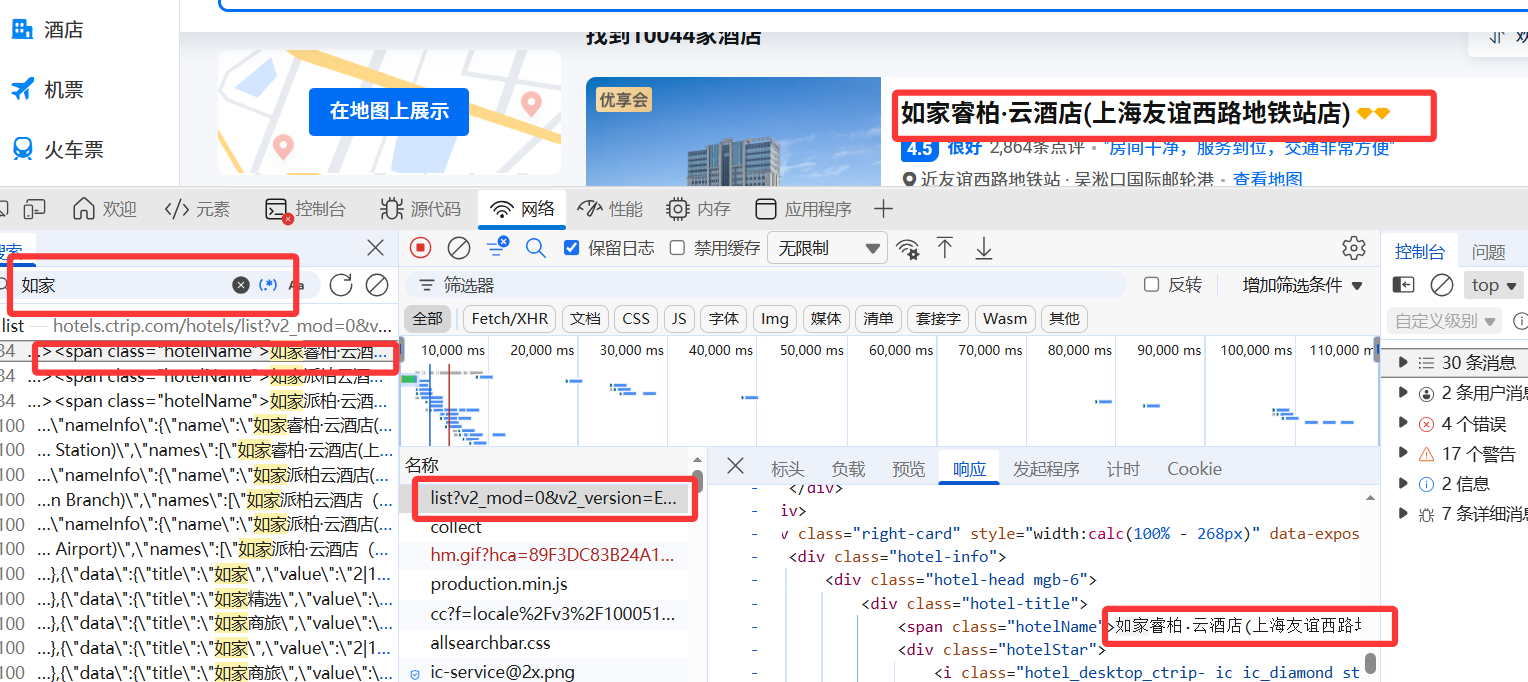
- 关键字搜索:需要什么搜索什么
二.代码实现步骤
requests(伪装成浏览器获取数据)
模拟浏览器:涉及网站存在加密
- 模拟请求需要携带响应参数(实时更新),逆向分析加密参数(工程量比较大)
1.发送请求:模拟浏览器对于url地址发送请求
2.获取数据:获取服务返回的响应数据
3.解析数据:提取我们需要的数据内容
4.保存数据:把提取出来的数据保存到本地文件中
drissionpage模块(直接使用浏览器获取数据)
自动化模块:模拟人的行为对于浏览器进行相关操作,简单好上手,适合初学者
- 自动化模块推荐使用drissionpage
1.打开浏览器,访问网站
2.获取数据
3.解析数据
4.保存数据
准备工作
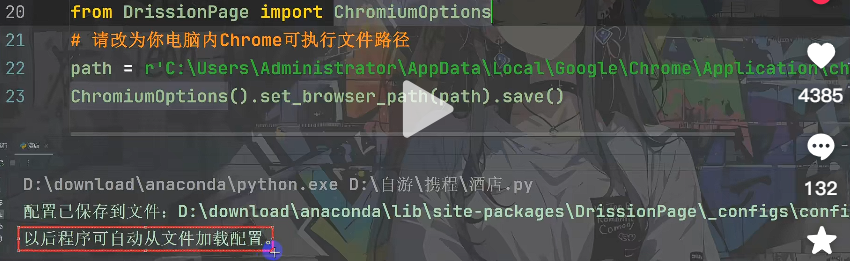
需要让程序自动打开浏览器
- 请问:程序如何知道你用的哪个浏览器
新建一个临时py文件,并输入以下代码,填入自己电脑里的浏览器可执行文件路径,然后运行。
from DrissionPage import ChromiumOptions
path = r"D:\chrome\Chrome.exe" #请改为你自己的可执行浏览器文件路径
Chromiumoptions().set_browser_path(path).save()
1.打开浏览器,访问网站
2.获取数据,
- 监听数据包:监听数据包特征,当网站加载含有这个特征链接,可以直接获取响应数据
- 数据包
- 特征是什么?
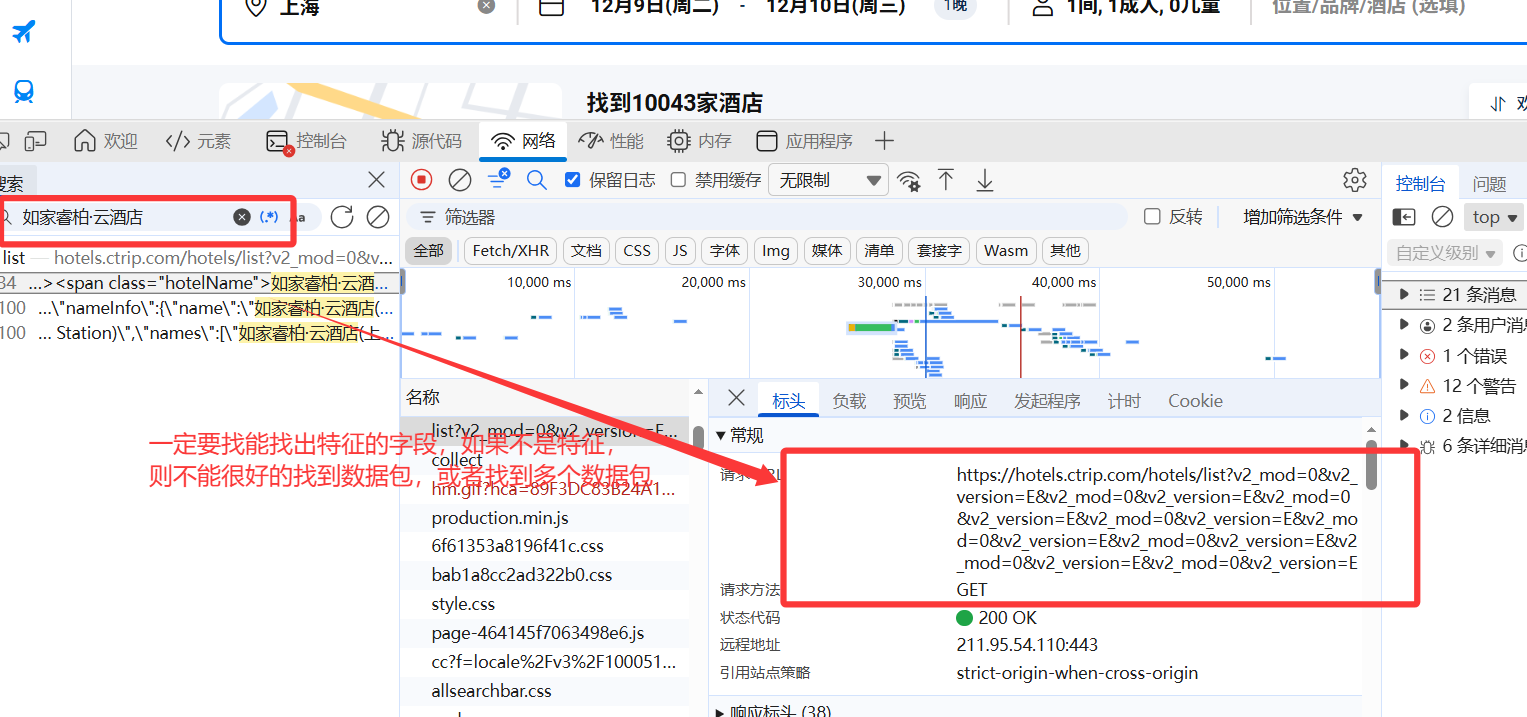
- 监听数据包流程:一定要在执行动作之前
- 先监听数据包
- 再访问网站
- 然后等待加载
- 最后获取数据
代码实现
#导入自动化模块
from DrissionPage import ChromiumPage
# 打开浏览器(实例化浏览器对象)
# 1.打开浏览器,访问网站
dp = ChromiumPage()
#监听数据包
dp.listen.start('fetchHotelList')
# 访问网站
dp.get('https://hotels.ctrip.com/hotels/list')
#等待数据加载
r = dp.listen.wait()
# 2.获取数据
json_data = r.response.body
print(json_data)
##这里爬取出来的数据并不是json数据需要其它方法提取数据。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)