基于B站热点评论数据文本分析,包括词频分析、BERT模型情感分析、LDA主题分析
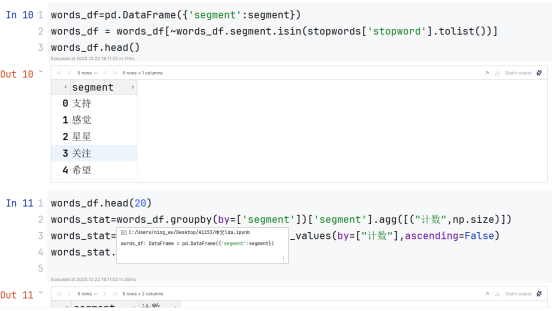
主题数(num_topics=5)的选择需基于困惑度与一致性曲线的拐点分析:困惑度衡量模型对数据的拟合程度(值越低越好),一致性评估主题内词语的语义相关性(值越高越好),理想的主题数应使困惑度较低同时一致性较高,找到两者平衡的肘点位置。接下来,进行正则清洗的步骤。TF‑IDF(词频‑逆文档频率)是一种用于评估词语在文档集合中重要程度的统计度量方法,其核心思想是:一个词语在当前文档中出现次数越多(T
思路步骤:
数据清洗:
使用pandas读取数据文件,并进行数据清洗和预处理,包括去除重复值。
文本清洗与分词:使用正则表达式提取字符,并调用 jieba 对文本进行分词,同时去除停用词,保留有意义的词语。
文本去重:剔除重复内容,以确保分析的效率和数据质量。
词频分析:
计算词频并生成词云图,统计文本中词语的出现频率,并使用WordCloud库生成词云图展示结果。
情感分析:利用BERT模型对文本进行深度编码,然后通过一个简单的全连接层进行分类。通过微调BERT模型的所有参数,使其适应情感分析任务。同时,采用了多种优化技巧(如权重衰减、学习率调度、早停等)来提高模型性能。最终通过划分积极消极及中性三种不同的情感倾向,并统计各个情感倾向的数量。
主题分析:
进行一致性和困惑度计算,通过改变主题数量范围,计算不同主题数量下的一致性和困惑度,并绘制折线图展示结果。
使用TF-IDF模型提取文本的关键词,计算每个关键词在文本中的权重,并输出关键词。
对主题建模结果进行可视化,使用pyLDAvis库生成LDA主题模型的可视化结果,并保存为HTML文件。根据LDA模型计算主题之间的相关性和关键词之间的权重。
数据处理实现:
数据处理的过程如下:
数据清洗主要包括去重和正则清洗两个步骤。
首先,通过使用drop_duplicates函数对原始数据进行去重操作。在代码中,根据内容这一列进行去重,并将去重后的结果重新赋值给新的DataFrame。这样可以确保每条内容的唯一性,避免出现重复的数据。

接下来,进行正则清洗的步骤。正则清洗主要是针对内容,去除除了中英文字符和数字以外的其他字符。具体实现通过使用正则表达式的方式,调用re.sub函数进行替换。在代码中,使用正则表达式[^\u4e00-\u9fa5^a-z^A-Z^0-9^,.,。!:]|,将博文全文中除了中英文字符、数字和部分标点符号(逗号、句号、感叹号、冒号)以外的字符都替换为空格,从而实现清洗效果。
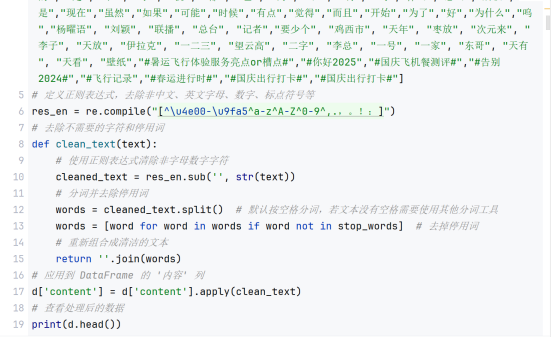
清洗后的结果保存为新的DataFrame,并将其写入Excel文件。通过这样的数据清洗过程,可以确保数据的准确性和一致性,使得后续的数据分析和处理更加可靠和有效。
数据清洗是数据分析的前提和基础,通过去重和正则清洗等步骤,可以对原始数据进行初步的处理和整理,为后续的数据分析和挖掘提供高质量、准确的数据基础。清洗后的数据具有更好的可用性和可靠性,能够提供更准确、可靠的结果和结论,从而支持决策和解决实际问题的需求。
主要关注点分析(词频分析):
相关理论和介绍
TF‑IDF(词频‑逆文档频率)是一种用于评估词语在文档集合中重要程度的统计度量方法,其核心思想是:一个词语在当前文档中出现次数越多(TF越高),同时在所有文档中出现次数越少(IDF越高),则该词语对当前文档的区分能力越强,权重越大。
具体计算公式包括两个部分:词频(TF)和逆文档频率(IDF)。词频
表示词语 t 在文档 d 中出现的频率,通常使用归一化后的相对词频,即该词在文档中出现次数除以文档总词数,公式为:
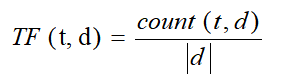
逆文档频率 IDF(t) 衡量词语的普遍重要性,计算公式为:
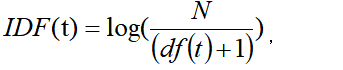
,
其中 N 是文档总数,df(t) 是包含词语 t 的文档数量。最终 TF‑IDF 权重为两者乘积:
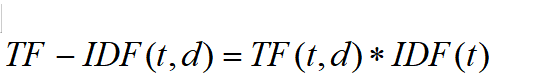
在实现中,TfidfVectorizer 自动完成这一计算过程:首先对分词后的评论进行词频统计,然后计算每个词的 IDF 值,最终生成稀疏的 TF‑IDF 特征矩阵。通过计算各特征词的平均 TF‑IDF 权重,可以识别出在整个评论集中具有高区分度的关键词,这些关键词往往能代表内容的核心主题或情感倾向,为后续的文本分析提供量化依据。
实现流程
词频分析可以按照以下步骤进行:
读取经过数据清洗的B站数据。
使用jieba库对每条内容进行分词处理,得到分词后的结果。
创建一个空的列表或字典用于存储词频统计结果。
遍历分词结果列表,对每个词语进行词频统计,将词语及其出现次数添加到词频统计结果中。
对词频统计结果进行排序,可以按照词频降序排列。
根据需求选择关注的主题,筛选出与该主题相关的词语。
可以根据需要设定阈值,过滤掉低频词语,只保留出现频率较高的词语。
将词频统计结果进行可视化展示,可以使用柱状图、词云图等方式进行展示。
分析词频统计结果,根据高频词语来了解内容的关键关注点和问题。
通过词频分析,可以了解内容的关注度和热度,找出内容被用最多的关键词,从而揭示出内容的主要关注点和议题。结果如下:

根据结果可以看出,评论内容呈现明显的情感与文化双重特征。词频分布揭示了内容成功触达受众情感与认知双维度,形成了情感共鸣与文化认同相互促进的良性传播循环。
情感分析
相关公式和介绍
BERT(Bidirectional Encoder Representations from Transformers)模型是基于Transformer编码器结构的预训练语言表示模型。其核心计算基于多头自注意力机制,公式为:
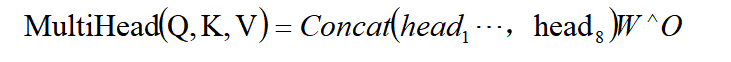
其中每个注意力头的计算为:
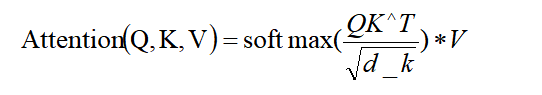
- K、V分别由输入向量通过线性变换得到:
- Q=HW_q,K=HW_k,V=HW_v,H为隐藏层表示。BERT采用双向训练策略,通过Masked Language Model(MLM)和Next Sentence Prediction(NSP)两个预训练任务学习上下文相关的词向量表示。
在实现中,BertModel接收input_ids(词索引)、attention_mask(注意力掩码)和token_type_ids(句子分段标识)作为输入。模型通过12层或24层Transformer编码器堆叠,每层包含自注意力子层和前馈神经网络子层,均采用残差连接和层归一化:
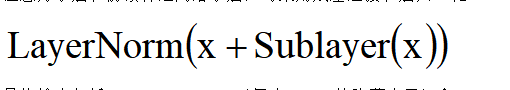
最终输出包括last_hidden_state(每个token的隐藏表示)和pooler_output([CLS]标记的池化表示,用于分类任务)。本代码取pooler_output作为全连接层输入。
该分类模型在BERT基础上添加线性分类层,公式为:
![]()
其中h_{[CLS]}为[CLS]标记的768维隐藏表示。模型微调时所有BERT参数参与梯度更新(requires_grad=True),使预训练表示适应下游任务。这种架构充分利用BERT的双向语境理解能力,在输入序列经过多层Transformer编码后,通过分类头实现文本分类任务。
软硬件环境要求
|
类别 |
项目 |
要求 |
说明 |
|
硬件 |
处理器 |
GPU |
自动检测CUDA可用性 |
|
GPU显存 |
≥4GB |
BERT-base模型训练需求 |
|
|
系统内存 |
≥8GB RAM |
数据处理和模型加载 |
|
|
软件 |
操作系统 |
Windows10 |
|
|
Python版本 |
3.7+ |
||
|
深度学习框架 |
PyTorch 1.7+ |
模型训练基础 |
|
|
关键库 |
transformers 4.0+ |
BERT模型实现 |
|
|
scikit-learn 0.24+ |
评估指标计算 |
表格详细列出了运行情感分析模型所需的硬件和软件配置。硬件方面要求具备GPU(推荐)或CPU,GPU显存至少4GB以支持BERT-base模型的训练,系统内存不少于8GB。软件环境需要Python 3.7及以上版本,核心依赖包括PyTorch、Transformers、Scikit-learn等库。这些配置确保了模型能够正常加载预训练的BERT参数、执行训练过程并生成各类评估。
BERT模型核心参数
|
参数名 |
默认值 |
类型 |
说明 |
|
bert_path |
'./bert_pretrain' |
字符串 |
BERT预训练模型本地路径 |
|
hidden_size |
768 |
整数 |
BERT-base隐藏层维度 |
|
max_sequence_length |
512 |
整数 |
最大输入序列长度(BERT限制) |
|
tokenizer |
BertTokenizer |
对象 |
BERT分词器实例 |
表格展示了BERT模型的关键配置,包括预训练模型的本地存储路径、隐藏层维度(768维)、最大输入序列长度(512个token)以及分词器实例。这些参数确保了模型能够正确加载预训练的BERT-base中文模型,并按照BERT的标准处理方式对输入文本进行编码和截断,为后续的分类任务提供高质量的文本表示
训练超参数
|
参数名 |
默认值 |
类型 |
说明 |
|
num_epochs |
3 |
整数 |
训练轮数(适合微调) |
|
batch_size |
3 |
整数 |
批处理大小(因显存限制较小) |
|
learning_rate |
5e-5 |
浮点数 |
学习率(BERT微调典型值) |
|
num_classes |
3 |
整数 |
输出类别数(自动从class_list计算) |
|
require_improvement |
1000 |
整数 |
早停阈值(连续1000batch无改进) |
表格列出了控制训练过程的超参数设置。模型采用较小的批处理大小(3)以适应GPU内存限制,设置3个训练轮次进行微调,学习率采用BERT微调的典型值5e-5。早停机制在连续1000个批次无改进时触发,防止过拟合。这些参数平衡了训练效率和模型性能,适合中等规模数据集的微调任务
模型架构参数
|
组件 |
参数 |
值/类型 |
说明 |
|
基础模型 |
模型类型 |
BERT-base |
双向Transformer编码器 |
|
参数量 |
~110M |
预训练参数 |
|
|
层数 |
12 |
Transformer编码器层 |
|
|
注意力头数 |
12 |
多头注意力机制 |
|
|
分类头 |
结构 |
nn.Linear(768, 3) |
全连接层 |
|
输入维度 |
768 |
BERT的[CLS]表示维度 |
|
|
输出维度 |
3 |
对应三类情感 |
|
|
优化设置 |
优化器 |
AdamW |
带权重衰减的Adam |
|
权重衰减 |
0.01 |
正则化防止过拟合 |
|
|
调度器 |
Warmup线性调度 |
学习率预热+线性衰减 |
表格详细描述了模型的架构组成。基础部分采用BERT-base模型,包含约1.1亿参数,12层Transformer编码器。顶部添加简单的线性分类层,将768维特征映射到3维情感类别。优化器使用AdamW配合权重衰减和warmup学习率调度,这种组合在BERT微调任务中表现出色,能稳定训练并提升泛化能力.
实现流程
BERT情感分析流程首先对文本进行预处理,使用BERT分词器将句子转换为包含特殊标记、长度统一的token序列,并生成相应的attention mask和token type ids。随后,加载预训练的BERT模型作为特征提取器,通过在[CLS]标记的输出向量上添加全连接分类层,构建完整的分类架构。训练阶段采用端到端的微调策略,通过交叉熵损失计算预测情感类别(负面、正面、中性)与真实标签的差异,利用AdamW优化器和带warmup的学习率调度器迭代更新包括BERT底层参数在内的所有权重。模型定期在验证集评估性能,选取最佳检查点。最终在测试集进行多维度评估,除准确率等指标外,还通过混淆矩阵和ROC曲线可视化分析模型对不同情感类别的区分能力,充分发挥了BERT在上下文语义理解和迁移学习方面的优势。
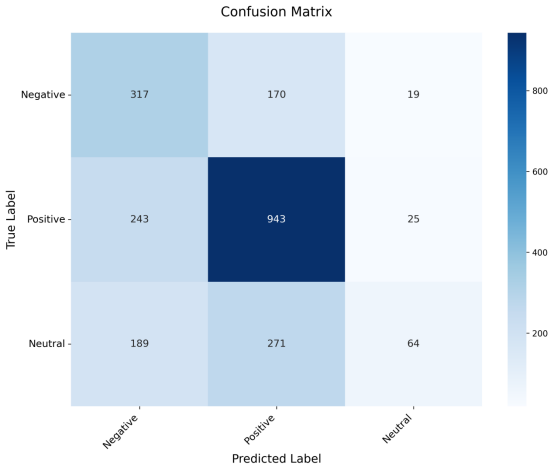
混淆矩阵图
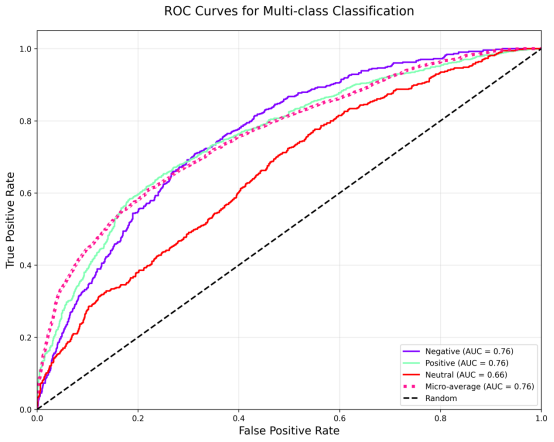
ROC曲线图
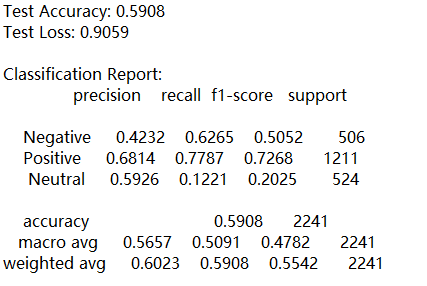
根据BERT情感分析模型的评估结果,整体表现显示模型具备一定的分类能力但仍存在明显的优化空间。在训练过程中,训练集与验证集的准确率和损失曲线均呈现收敛趋势,且未见显著过拟合现象,表明模型学习过程较为稳定。然而,模型在测试集上的最终准确率为59.08%,虽高于随机分类基线(约33.3%),但分类性能仍有较大提升余地,测试损失为0.9059也印证了这一点。
从分类性能细分来看,混淆矩阵图中,模型对不同情感类别的识别能力差异显著。积极情感类别的分类效果最好,精确率达0.68,召回率为0.78,F1分数为0.73,表明模型能较好地捕捉正面情感特征。消极情感类别的召回率(0.63)相对较高,但精确率(0.42)偏低,说明模型存在将其他类别误判为消极的倾向。中性情感类别的识别效果最不理想,召回率仅为0.12,F1分数低至0.20,绝大部分中性样本被错误划分到积极或消极类别,这反映出中性情感因语义边界模糊而难以被准确区分。
ROC曲线的分析结果进一步证实了上述发现:积极和消极类别的AUC值均为0.76,表明模型对这两类情感具有一定区分能力;而中性类别的AUC仅为0.66,分类性能明显较弱。宏观平均AUC为0.76,说明模型整体判别能力尚可,但中性类别的低效拉低了整体表现。综合来看,该模型适用于以积极和消极情感为主的二元分类场景,但对中性情感的识别需通过数据增强、样本平衡或特征优化等方法重点改进,以提升整体分类精度与鲁棒性。
最终使用模型进行分析,分析结果会被存储到新列 情感分析 中。通过 groupby 按照情感分类统计微博数量,并用饼图展示各情感类别的占比情况。饼图通过 matplotlib 绘制,显示了每个情感类别(积极、中性、消极)的比例,以便直观展示情感分析的结果。这种方法能够帮助快速了解文本中情感的分布情况。如下图:
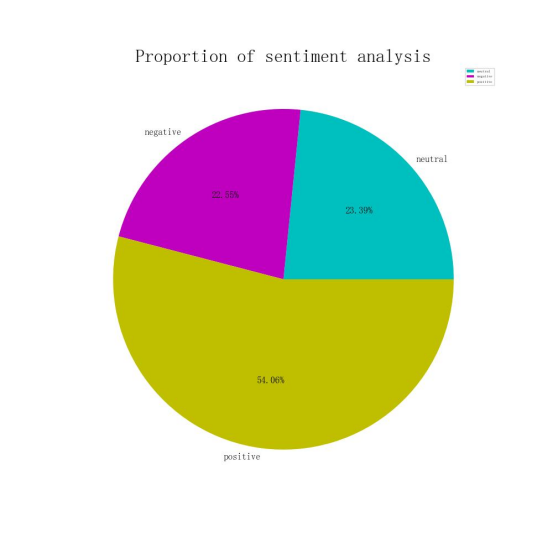
根据情感分析统计结果,整体评论情感以积极为主(54.1%),中性(23.4%)和消极(22.6%)占比较低,反映出观众对内容持高度正面态度。
Lda主题分析
相关公式和介绍
LDA(Latent Dirichlet Allocation)主题模型的计算基于概率图模型框架,其核心公式包括文档-主题分布和主题-词分布两个关键部分。文档d的主题分布θ_d服从Dirichlet(α)先验分布,其中α是超参数;主题k的词分布φ_k服从Dirichlet(β)先验分布,β控制词的稀疏性。生成过程中,对文档d中的每个词w,首先从θ_d采样一个主题z,然后从φ_z采样生成词w。最终通过吉布斯采样或变分推断等算法估计后验分布,得到文档的主题混合比例和每个主题下的关键词概率分布。
数学表示为:
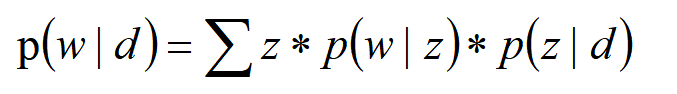
p(w|d) = ∑_z p(w|z)p(z|d),
其中p(z|d)即文档d中主题z的比例,p(w|z)为主题z中词w的生成概率。
在实现中,lda.print_topics()展示了每个主题下的关键词及其概率权重,反映了φ_z的估计结果。而lda.get_document_topics(corpus)则计算每篇文档的主题分布θ_d,通过选取最大概率主题实现文档的主题归类。模型训练通过多次迭代(passes=10)优化参数,随机种子(random_state=42)确保结果可复现。主题数(num_topics=5)的选择需基于困惑度与一致性曲线的拐点分析:困惑度衡量模型对数据的拟合程度(值越低越好),一致性评估主题内词语的语义相关性(值越高越好),理想的主题数应使困惑度较低同时一致性较高,找到两者平衡的肘点位置。
困惑度(Perplexity)
困惑度是信息论中的一个概念,用于衡量概率分布或概率模型预测样本的能力。在LDA主题模型中,困惑度被用来衡量模型对文档的泛化能力。困惑度越低,表示模型越好。
对于LDA模型,困惑度的计算公式为:
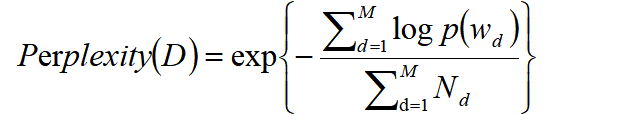
其中:
D 表示测试文档集。
M 是文档的总数。
w d是第d 篇文档中的词。
N d是第 d 篇文档中词的总数。
p(w d) 是模型生成第d 篇文档的概率。
困惑度可以理解为模型在遇到一篇新文档时,对文档中每个词的出现感到“困惑”的程度。因此,困惑度越小,说明模型对文档的预测能力越强。但是,困惑度有时会倾向于生成更少主题的模型,因此需要结合其他指标(如一致性)来评估。
一致性(Coherence)
一致性用于衡量主题模型中主题内部词语之间的关联程度。一致性越高,表示主题内的词语越相关,主题越容易解释。
一致性计算通常基于词共现统计。有多种计算一致性的方法,如c_v、c_uci、c_npmi等。在代码中,使用的是'c_v'方法。
c_v一致性的计算步骤:
对于每个主题,选择前N个最相关的词(通常N取10、15或20)。
计算这些词之间的共现情况(例如,使用滑动窗口在整个语料库中统计)。
基于这些共现统计,计算一致性得分。
具体公式如下:
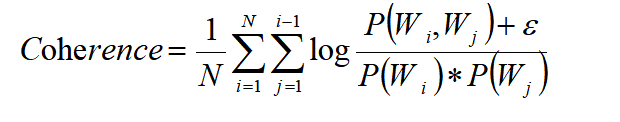
其中:
P(w i,w j) 是词w i和w j共同出现的概率。
P(w i) 是词w i出现的概率。
ϵ 是一个很小的数,防止除数为0。
实际上,c_v方法更复杂,它使用了归一化的点互信息(NPMI)和余弦相似度。具体来说,首先计算每个词对之间的NPMI,然后将这些NPMI值组合成一个向量,最后计算这些向量的余弦相似度
LDA作为无监督学习方法,每次运行可能因初始化和语料差异产生不同结果,但核心算法保持稳定。实际应用中,主题数的确定需结合领域知识和指标曲线,避免过度拟合或主题过于宽泛。该模型能够从大量文本中自动发现潜在主题结构,为文本分类、信息检索和内容推荐提供基础,是自然语言处理中主题建模的重要工具。
实现流程
LDA主题分析的实现过程如下:
准备好经过数据清洗和预处理的文本数据。
使用gensim库构建语料库和词袋模型,将文本数据转换为可用于LDA模型的格式。
设置LDA模型的参数,包括主题数量、迭代次数、词频阈值等。
使用LDA模型训练语料库,并得到主题-词语分布和文档-主题分布。
根据需求,选择合适的方法获取每个主题的关键词,可以是按照权重排序或者设定阈值筛选。
可以使用pyLDAvis库对LDA模型进行可视化,生成交互式的主题模型可视化图表,并保存为HTML文件。
分析LDA主题分析结果,根据关键词和文档-主题分布了解每个主题的含义和特点,理解文本数据中不同主题的分布情况。
可以进一步对文本数据进行主题分析,根据文档-主题分布确定每个文档最可能的主题,并将主题信息添加到原始数据中。
通过LDA主题分析,可以发现文本数据中的主题结构和主要内容。主题分析可以帮助我们了解文本数据的内在关联性和分布情况,从而更好地理解文本数据的内容和意义。此外,LDA主题分析还可以用于文本分类、信息检索和推荐系统等领域,提供有关文本数据的深入洞察和应用价值。结果如下:
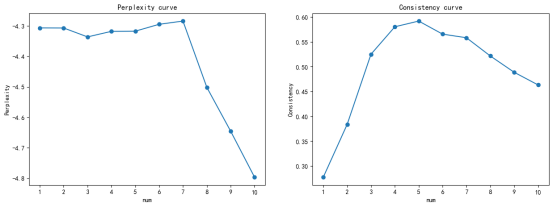
由一致性和困惑度分析曲线图可知,观测到的最佳建模主题数,数值应该取困惑度小同时一致性高的拐点,如本图最困惑度为10,最高一致性为5,以一致性为主,最优主题数5效果最好。
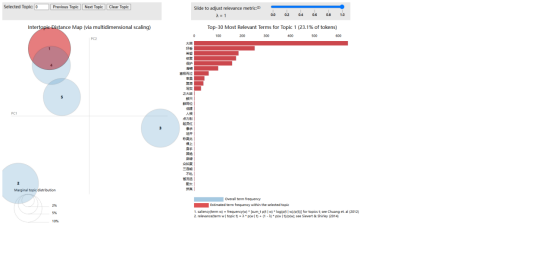
主题分析结果:

根据LDA主题分析结果,用户评论内容呈现出以情感表达为主导、兼具价值认同与保护关切的多元主题结构。
其中,主题1代表即时情感反馈
主题2代表文化内涵理性认同
主题4代表文化遗产保护关切
主题3与主题5则代表文化价值认同
主题分布呈现“情感主导-价值延伸-行动关联”的层次特征。
不同主题情感分析如下
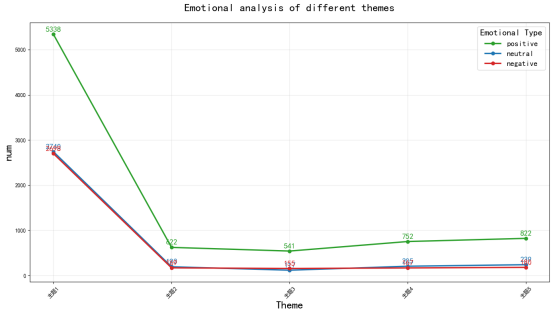
五个主题的情感分析统计结果:

根据对五个主题的情感分析统计结果,大多数主题的评论情感以积极为主,其中主题三、四、五的积极情感比例均超过66%,显示出较强的正面反馈。
这些数据表明,用户评论在多数主题上呈现乐观态度,尤其是在文化和文物相关领域,而主题一因涉及宣传内容而引发更多中性或消极反应,整体情感趋势积极。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 11
11 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)