【第3篇】FasterNet(CVPR2023):基于部分卷积PConv,打造更快精度更高更具成本效益的神经网络!
本文介绍FasterNet(CVPR2023, 由香港科技大学出品),一种基于部分卷积网络PConv的新网络,模型的动机在于减少计算冗余和内存访问提升更快的速度同时,保持更高的精度。PConv通过仅对特征中的部分通道应用常规卷积,有效地降低了FLOPs,提高了计算效率。实验结果显示,FasterNet在GPU、CPU和ARM处理器上均表现出优于MobileViT的性能,同时保持了高精度。
论文题目:Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
文献地址:https://arxiv.org/pdf/2303.03667v3
源码地址:https://github.com/jierunchen/fasternet

近期准备将近几年工作过程中涉及到的一些还不错的模型结构进行发布。届时,也会把相应用的比较好的模型魔改案例在另一个专栏进行整理发布,帮助大家在跟进最新CV任务的同时,掌握模型魔改的技巧。 可以期待一下! 还希望大家多多关注、留言,你们的支持是我更新的动力~
🌠🌠🌠本篇内容:本文介绍FasterNet(CVPR2023, 由香港科技大学出品),一种基于部分卷积网络PConv的新网络,模型的动机在于减少计算冗余和内存访问提升更快的速度同时,保持更高的精度。PConv通过仅对特征中的部分通道应用常规卷积,有效地降低了FLOPs,提高了计算效率。实验结果显示,FasterNet在GPU、CPU和ARM处理器上均表现出优于MobileViT的性能,同时保持了高精度。
五分钟回顾模型
FasterNet是从追求低延迟高吞吐的角度出发,设计具有成本效益的快速神经网络。发现 FLOPs的减少不能准确地转化为延迟减少的原因是由于频繁的内存访问。因此,作者从减少内存访问的角度出发,利用特征图的冗余,设计了PConv。
具体而言,在卷积过程中,仅对部分输入通道应用常规卷积Conv,对其余通道保持不变。形成了T型卷积的卷积模式。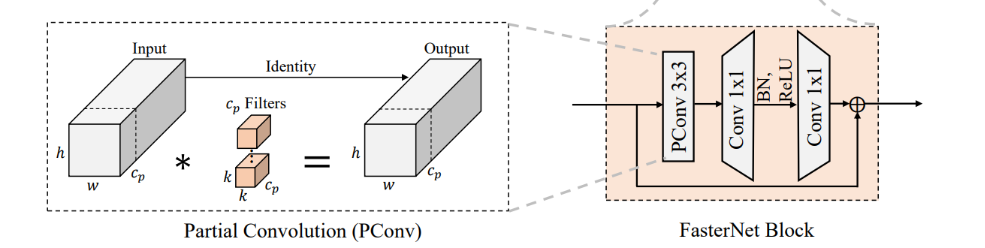
模型的整体结构方面,共包含有4个stage,每个stage前面包含一个Embedding层(步长为4的常规4×4卷积)或一个Merging层(步长为2的常规2×2卷积),用于空间下采样和通道数量扩展。
FasterNet Block由PConv构成的倒置残差网络构成:PConv-PWConv(1x1)-PWConv(1x1)。
实验结果
FasterNet论文中提供了与其他先进骨干网络在分类精度Top-1 Acc与不同设备上GPU、CPU、ARM上的吞吐量Throughput或者延迟Latency,如下图所示。FasterNet在平衡精度和吞吐量/延迟方面达到了最新的水平,基本处于非劣解前沿的位置。当具有相似top-1 Acc精度时,FasterNet在各种设备上的运行速度比各种CNN和ViT模型更快。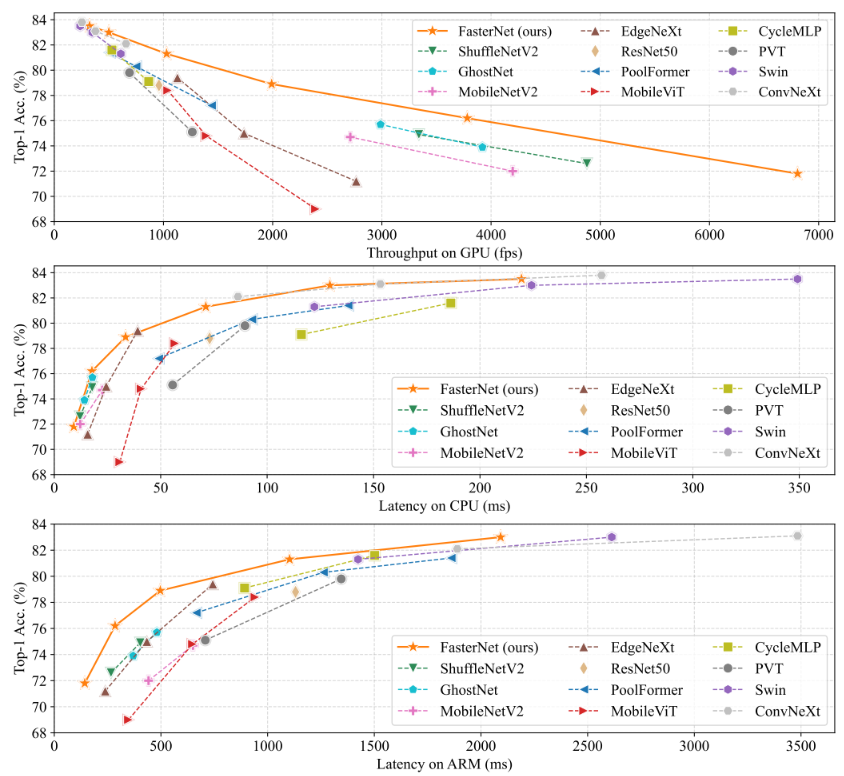
同时,在大型变体FasterNet-L实现了83.5%的Top-1 Acc,在与Swin-B和ConvneXT-B在精度上基本相当的同时,在GPU上的吞吐量提升了36.29%和27.68%;节省42%和22%的CPU计算时间。其他变体上精度也具有不俗的表现。
本文方法
FasterNet模型结构主要包含PConv和模型整体结构组成两个方面。
一、 理论部分(CVPR2023, HKUST)
A. PConv详解
FasterNet是一个从追求低延迟和高吞吐角度出发,设计具有成本效益的快速神经网络。作者结合相关文献,从Conv、DWConv的FLOPs和访存次数进行分析,发现FLOPs的减少不能准确地转化为延迟减少的原因是由于频繁的内存访问,尤其像DWConv。因此,作者从减少内存访问的角度出发,利用特征图的冗余,设计了PConv。具体而言,在卷积过程中,仅对部分输入通道应用常规卷积Conv,对其余通道保持不变。
通过上图©中的结构图不难看出,PConv只对输入特征的部分通道进行卷积操作,其余通道不做卷积操,保持不变。因此,卷积核的通道数量和个数都会减少。随之会带来FLOPs和内存访问量的减少。
这种局部卷积的处理方式和华为的GhostNet很像,如下图所示。GhostNet首先对输入特征图进行1x1卷积,压缩输入特征图的通道数量,之后使用DW卷积获得特征图,并将压缩后的特征图进行Concat得到最终的Output。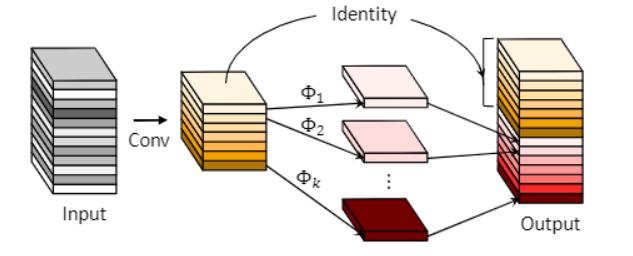
进一步来说,Conv、DWConv和PWConv的FLOPs分别如下所示:
- Conv: h ∗ w ∗ k 2 ∗ c 2 h*w*k^2*c^2 h∗w∗k2∗c2
- DWConv: h ∗ w ∗ k 2 ∗ c h*w*k^2*c h∗w∗k2∗c
- PConv: h ∗ w ∗ k 2 ∗ c p 2 h*w*k^2*c_p^2 h∗w∗k2∗cp2 , 其中, c p c_p cp的定义通常 r = c p / c = 1 / 4 r=c_p/c=1/4 r=cp/c=1/4 , 也就是说,FLOPs是Conv的 1 / 16 1/16 1/16
Conv、DWConv和PWConv的内存访问量如下所示:
- Conv: h ∗ w ∗ 2 c + k 2 ∗ c 2 ≈ h ∗ w ∗ 2 c h*w*2c + k^2*c^2 ≈ h*w*2c h∗w∗2c+k2∗c2≈h∗w∗2c
- DWConv: h ∗ w ∗ 2 c ‘ + k 2 ∗ c ‘ ≈ h ∗ w ∗ 2 c ‘ h*w*2c^` + k^2 * c^` ≈ h*w*2c^` h∗w∗2c‘+k2∗c‘≈h∗w∗2c‘
- PConv: h ∗ w ∗ 2 c p + k 2 ∗ c p 2 h*w*2c_p + k^2*c_p^2 h∗w∗2cp+k2∗cp2 ,其中, c p c_p cp的定义通常 r = c p / c = 1 / 4 r=c_p/c=1/4 r=cp/c=1/4
PConv仅对部分通道进行卷积操作,其余通道保持不变。那么,是否可以简单删除剩余的( c − c p c-c_p c−cp)通道?
作者认为,如果简单的删除通道,PConv将会降级为具有较少通道的常规Conv,这与减少冗余的目标相悖。
那么,剩余的通道用来干什么?
PConv中会添加点卷积PWConv。如下图所示,PConv与PWconv的结合相当于图(b)中的T型卷积模式,对比图©的常规卷积模式。
虽然T型卷积可以直接用于高效计算,但最好还是把T型卷积拆解为PConv和PWConv,如图(a)的模式,这样可以节省计算量。
B. 整体结构详解
FasterNet的结构如下图所示。整体上来看,共包含有4个stage,每个stage前面包含一个Embedding层(步长为4的常规4×4卷积)或一个Merging层(步长为2的常规2×2卷积),用于空间下采样和通道数量扩展。
每个stage包含一个FasterNet Block。作者观察到,最后两个stage中的FasterNet Block消耗更少的内存访问,并且倾向于具有更高的FLOPS,因此,放置了更多FasterNet块,并相应地将更多计算分配给最后两个Stage。
每个FasterNet Block包含有一个PConv,后跟2个PWConv(或Conv 1×1)层。它们一起显示为倒置残差块,其中,中间层具有扩展的通道数量,并且放置了Shorcut以重用输入特征。
标准化和激活层对于高性能神经网络也是不可或缺的。然而,许多先前的工作在整个网络中过度使用这些层,这可能会限制特征多样性,从而损害性能。它还可以降低整体计算速度。相比之下,只将它们放在每个中间PWConv之后,以保持特征多样性并实现较低的延迟。
使用批次归一化(BN)代替其他替代方法。BN的优点是,它可以合并到其相邻的Conv层中,以便更快地进行推断,同时与其他层一样有效。
对于激活层,根据经验选择GELU用于较小的FasterNet变体,ReLU用于较大的FasterNet变体,同时考虑了运行时间和有效性。最后三个层,即全局平均池化、卷积1×1和全连接层,一起用于特征转换和分类。
二、Code
A. PatchEmbed
对一张图像划分为多个块,每个块称为一个patch,PatchEmbed实际上就是对每个patch进行embed输出一个n维向量。
FasterNet中的PatchEmbed操作与Swin Transformer中一致,patch_size=4,patch_stride=4,也就是说,每个patch的大小为4x4,对应的维度为4x4x3 = 48,PatchEmbed操作要把向量的维度变成一个预先设置好的值C,不同变体对应的embed_dim有所区别,FasterNet-m embed_dim是96(与Swin-T相同,也被称为每个token向量的维度),越大的变体对应的数值越大。
如果输入分辨率为224x224,此处PatchEmbed之后,维度变为56x56x96,56x56=3136对应的是序列的长度,序列长度太长,而且输入分辨率越大,序列长度就越长,过长的序列长度是不允许的。 --> 需要接降采样操作
实现方式如下所示,主要通过一个卷积操作实现。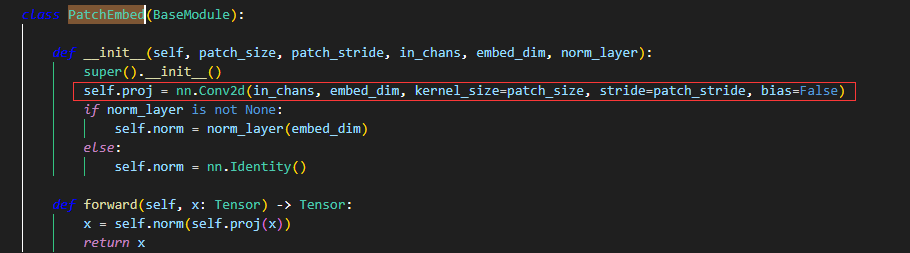
B. BasicStage(FasterNet Block)
结合论文中给出的FasterNet Block,看代码的实现。mlp_hidden_dim = int(dim * mlp_ratio) FasterNet-m中,mlp_ratio=2.0,即在两个1x1卷积中,输出通道数量先2两倍扩增,再恢复与输入一致。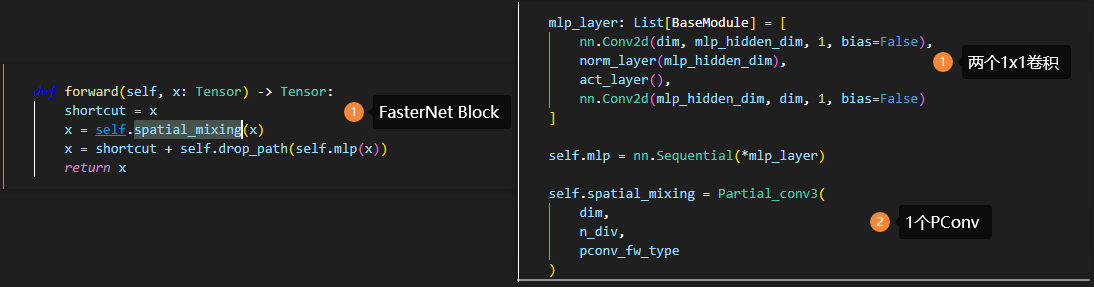
C. Partial_conv3
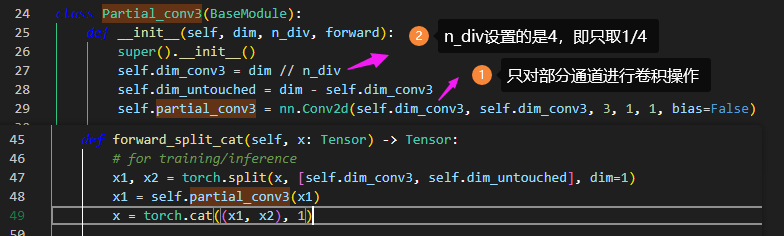
部分卷积实现采取先split,再融合的方式。如下述代码所示,截取通道1/4进行卷积操作,再和剩余通道合并。代码中未看到对剩余的通道进行1x1卷积。
D. PatchMerging
FasterNet中的PatchMerging操作与Swin Transformer一致,patch_size2=2,patch_stride2=2。通过这样类池化的操作进行下采样,**实现层级化小窗的自注意力。**同时,由于采样率的降低,便于大分辨率输入尺寸的使用。
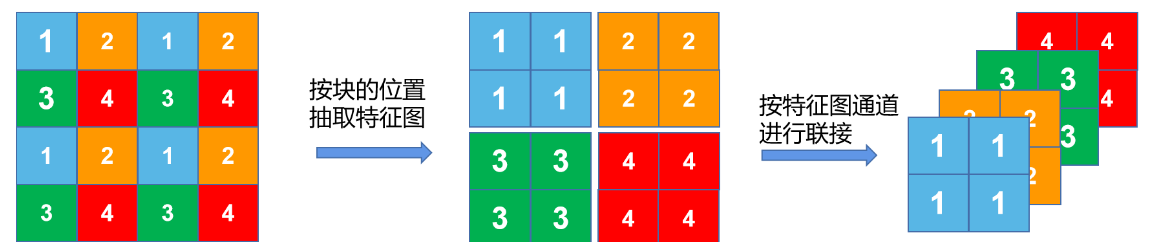
通过卷积的方式实现下采样,并在下采样的同时,扩充通道数。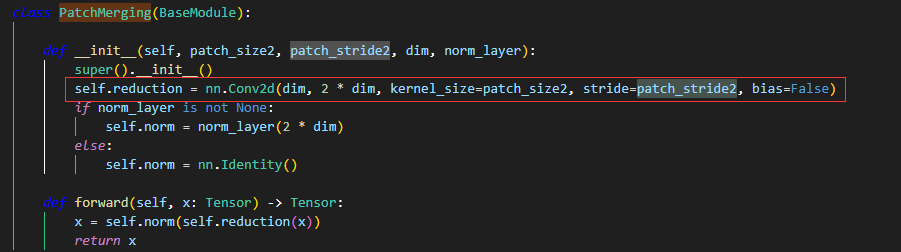
再结合FasterNet的结构,经过一次Embedding,输入分辨率降低4倍,经过三次Merging,分辨率降低8倍,共计32。即如果输入分辨率为224x224,分辨率的变化依次为56x56, 28x28,14x14和7x7,最终的序列长度降低为49,再经过全局池化操作,变为1x1。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)