INT303 Big Data Analysis 大数据分析 Pt.1 导论
数据科学从经验观察发展为理论分析与计算建模的跨学科领域。现代数据挖掘通过特征提取、模型训练和在线服务等流程,将海量异构数据转化为商业与科研价值。以Hubway骑行数据和社交网络推荐系统为例,展示了数据整合、特征工程和相似性分析等核心技术。面对数据缺失问题,可采用协同过滤、聚类或预测模型进行补全。数据可视化不仅辅助探索性分析,还能验证假设并指导决策。这一流程涵盖数据收集、清洗、建模到应用的全周期,需
文章目录
1. 导论
很久以前(数千年前),科学还仅仅是经验性的,人们通过数星星等方式,依靠经验来描述各种现象。
在几百年前,人们开始采用理论方法,试图推导出方程来描述普遍现象。
在20世纪,工程学和计算机科学在汽车、飞机、电网、电视、互联网领域发挥了重要作用。
但是,在20世纪考虑的问题一般是:
- 化肥的使用对农作物产量的影响。
- 吸烟与肺癌之间的因果关系。
为了解决现在的这些问题,我们需要通过数据分析来解决。
例如刚刚两个问题的解决方案需要:
- 收集并分析农业实验数据(将土地分为若干块,其中一些地块施用化肥,另一些地块不施用化肥,然后记录并比较两组地块的农作物产量)。
- 收集并分析观察性研究数据(长期跟踪吸烟者和非吸烟者的健康状况,收集和分析数据来确定吸烟与肺癌之间的关系)。
分析这些数据的工作是由统计学家和计算机工程师完成的,而将统计学和计算机科学知识结合起来的便是数据分析师。也就是:Analyzing these was the job of: Statisticians + Computer Engineering= Data Analyst。
现在我们将数据看作是新时代的石油。因为它很有价值,但如果未经提炼,实际上无法真正被使用。数据需要被分解、分析,才能具有价值。
如今,数据无处不在,几乎所有人类、物理或机器活动都会产生数据。而且每个人都在收集数据。无论是个人使用各种设备和应用程序,还是企业、政府机构等,都在不断地产生和收集各种数据。这些数据可以用于各种目的,如科学研究、商业决策、健康监测等。
数据是复杂的,因为其有多种类型且覆盖空间和时间方面。
多种类型包括数据库表格、文本、时间序列数据、图像、视频、图数据。
空间方面:数据具有地理位置信息,如地图上的坐标点、用户在不同地点的活动记录等。
时间方面:数据具有时间信息,如事件发生的时间、数据采集的时间等。
不同类型数据是相互关联的。例如,从手机中可以收集到用户的位置信息、社交关系、签到记录、社交媒体上的观点和状态更新、摄像头拍摄的图像以及搜索引擎的查询记录等。
这些复杂且相互关联的数据为科学研究、商业决策、社会管理等提供了丰富的资源,但也带来了数据处理和分析的挑战。
1.1 数据挖掘(Data Mining)
数据挖掘是一个将原始数据转化为有价值信息的过程。通过数据挖掘,可以从看似无序的大量数据中发现模式、趋势和关联,从而为决策提供科学依据,创造经济价值。
例如精确医疗/个性化医疗。它根据患者独特的特征,包括遗传信息、环境因素和生活方式等,为患者量身定制医疗护理和治疗方案。这种医疗方法的目标是提供更准确的诊断、改善治疗结果、减少副作用,并通过定制医疗护理来满足每个患者特定的需求。
再例如在足球和篮球等团队运动中,数据挖掘技术被用来分析运动员的表现、战术执行、对手的策略等,以帮助教练和团队做出更明智的决策。
数据挖掘是研究如何收集、处理、分析以及从中获得有用见解的过程。它也是一种能力,使我们能够从海量数据中提取有用的信息和知识,从而支持决策、优化业务流程、发现新的商业机会等。
1.1.1 数据挖掘流程(Data Mining Pipeline)
具体分为三个主要部分:数据管道(Data Pipeline)、模型拟合管道(Model Fitting Pipeline)和在线服务系统(Online Serving System)。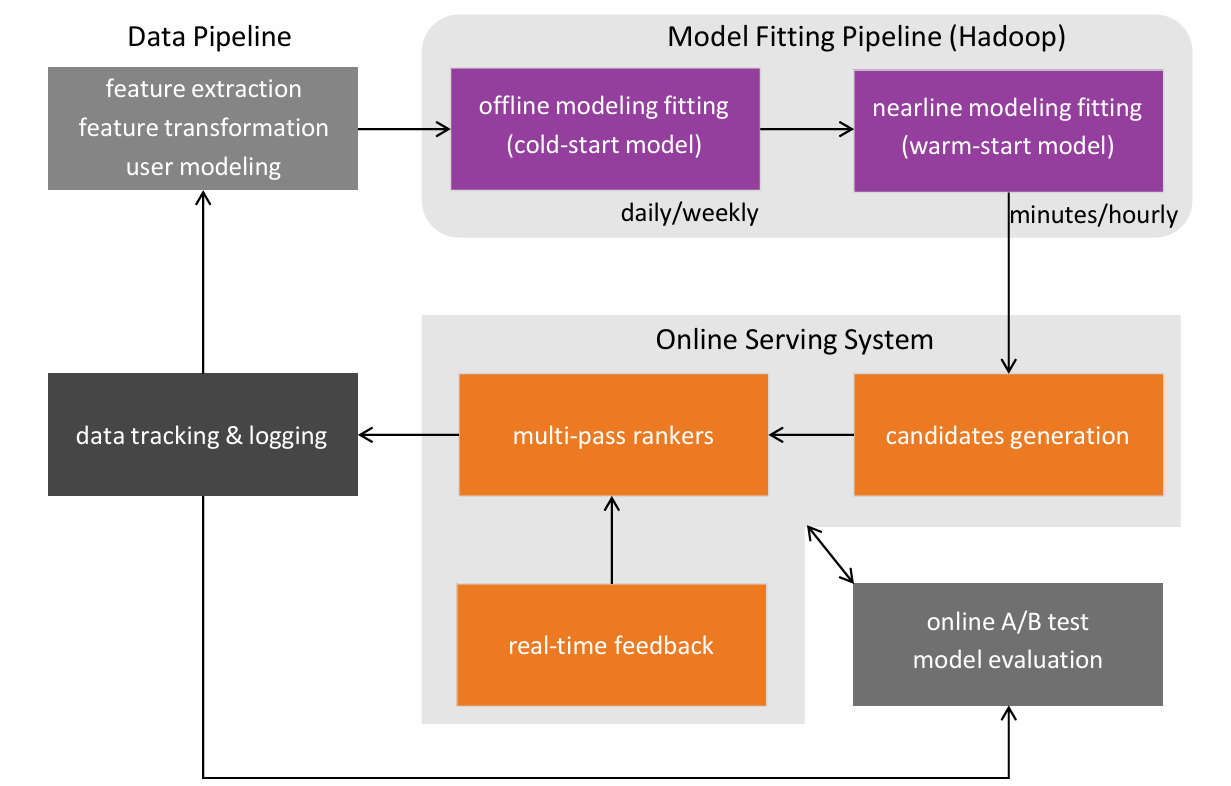
- 数据管道(Data Pipeline)
Feature Extraction(特征提取):从原始数据中提取有用的特征,这些特征对于后续的模型训练至关重要。
Feature Transformation(特征转换):对提取的特征进行转换,如归一化、标准化等,以提高模型的性能。
User Modeling(用户建模):构建用户模型,理解用户的行为和偏好。 - 模型拟合管道(Model Fitting Pipeline)
Offline Modeling Fitting(离线模型拟合):使用冷启动模型(cold-start model),在离线环境中进行模型训练,通常在每天或每周进行一次。
Nearline Modeling Fitting(近线模型拟合):使用热启动模型(warm-start model),在近线环境中进行模型训练,通常在几分钟或几小时内进行一次。这种模型可以更快地适应数据的变化。 - 在线服务系统(Online Serving System)
Candidates Generation(候选生成):生成候选推荐项,这些推荐项将被用于在线服务。
Multi-pass Rankers(多通道排序器):对候选推荐项进行多通道排序,以确定最终的推荐列表。
Real-time Feedback(实时反馈):收集用户对推荐结果的实时反馈,用于进一步优化推荐系统。
Online A/B Test Model Evaluation(在线A/B测试模型评估):通过在线A/B测试来评估模型的性能,确保推荐系统的有效性和准确性。
除了这三个部分以外数据跟踪与日志记录(Data Tracking & Logging)负责跟踪和记录数据的处理过程,以便进行监控、调试和优化。
1.1.2 跨学科领域
数据挖掘(Data Mining)作为一个跨学科领域,受到多个不同学科的影响和贡献的。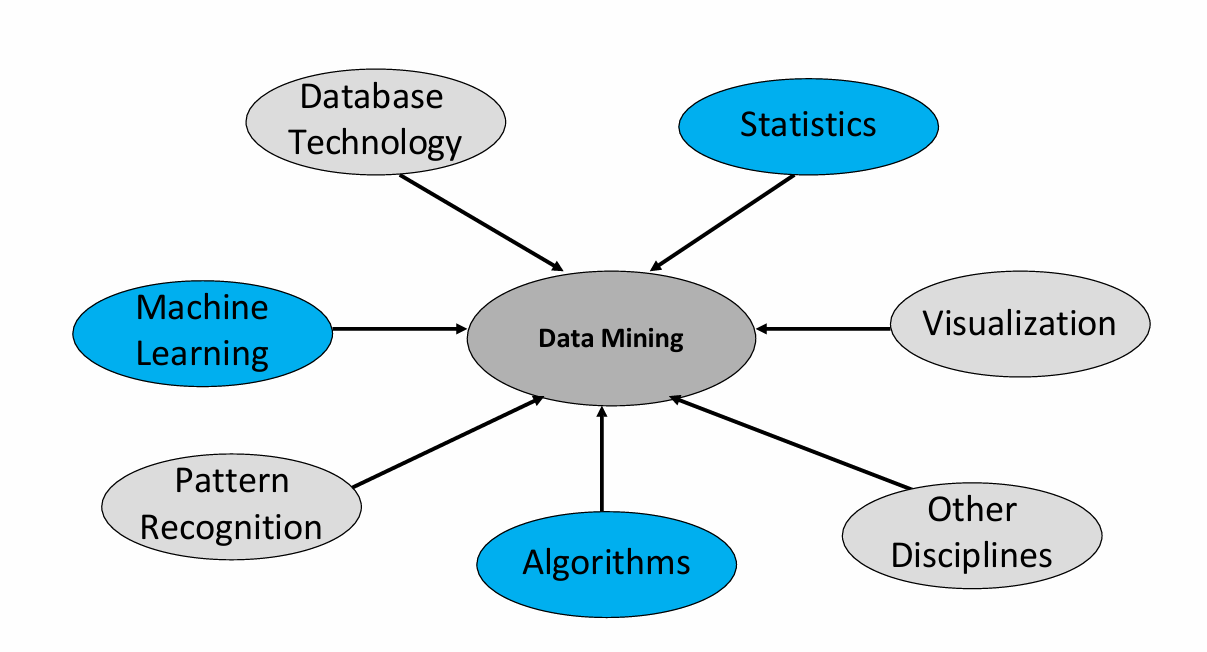
一般有六个学科与之紧密相关:
- Database Technology(数据库技术):
数据库技术提供了存储、管理和检索大量数据的方法和工具。在数据挖掘中,高效的数据存储和访问是进行数据分析的前提。 - Statistics(统计学):
统计学提供了数据分析的理论基础和方法,包括概率论、假设检验、回归分析等,这些都是评估数据模式和做出预测的重要工具。 - Machine Learning(机器学习):
机器学习是数据挖掘中的核心组成部分,它涉及到开发算法和模型,使计算机能够从数据中学习并做出预测或决策。 - Pattern Recognition(模式识别):
模式识别是识别数据中规律和模式的过程,它在图像处理、语音识别等领域有广泛应用,也是数据挖掘中识别数据模式的关键技术。 - Algorithms(算法):
算法是解决问题的一系列步骤,数据挖掘依赖于各种算法来处理数据、发现知识。这些算法可以是统计的、机器学习的或其他类型的。 - Visualization(可视化):
可视化是将数据和分析结果以图形或图表的形式展示出来,使复杂的数据更容易理解和解释。
至于其他部分可以是分布式计算,其涉及将计算任务分布到多个计算节点上执行,这对于处理大规模数据集尤为重要,因为它可以提高数据处理的速度和效率。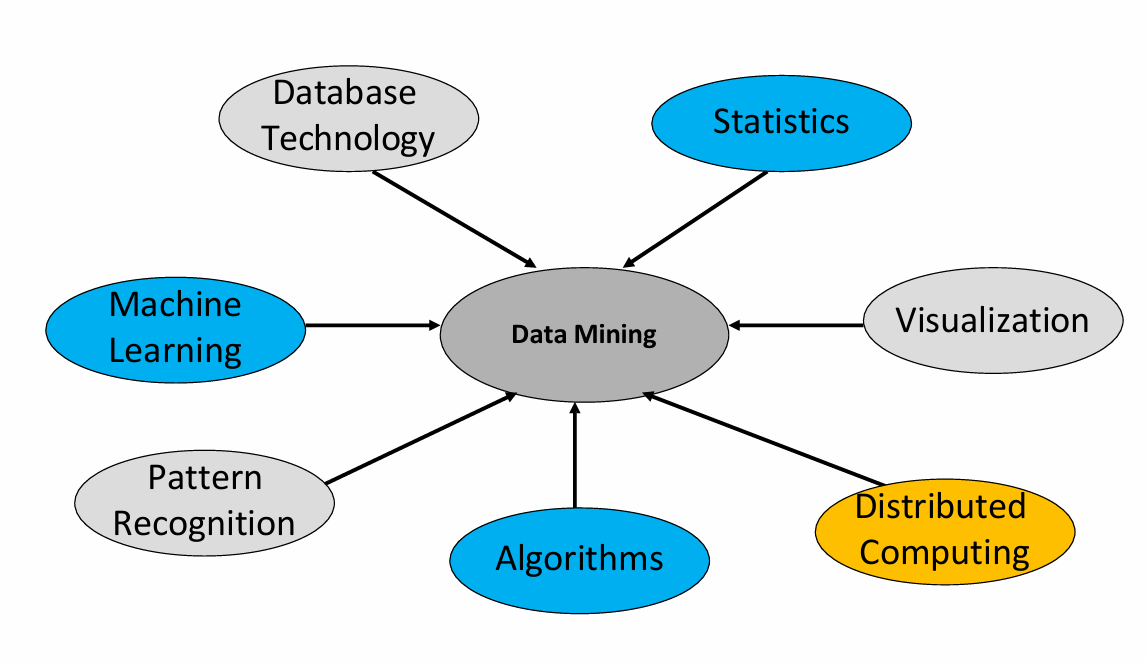
2. 数据科学流程
我们从一个例子出发,Hubway举办了一个数据可视化挑战活动,发布了5年的骑行数据。这些数据能告诉我们关于自行车共享计划的哪些信息?
在细化问题之前,我们需要先查看数据。
基于这些数据,我们可以提出以下问题:
- 谁在使用自行车?男性多还是女性多?老年人还是年轻人?订阅用户还是一次性用户?
- 在哪里?自行车在哪里被借出?波士顿比剑桥多吗?商业区还是住宅区多?旅游景点周围多吗?
- 何时?自行车在何时被借出?周末比工作日多吗?高峰时段多吗?夏天比秋天多吗?
- 为什么?人们租借自行车是为了什么目的/活动?更多的自行车被用于娱乐而不是通勤?更多的自行车被用于旅游目的?自行车被用来避开交通拥堵?
- 用户人口统计特征如何影响自行车的使用时长?或者它们被借出的地点?天气或交通状况如何影响自行车的使用?站点位置的特征如何影响自行车的借出数量?
我们可以发现:
- 有时数据会以分散的形式提供,需要将这些分散的数据合并起来进行分析。这可能涉及到将来自不同来源或不同格式的数据整合到一个统一的数据集中,以便进行更全面的分析。
- 有时想要探索的特征在原始数据中并不存在,需要通过特征工程(Feature Engineering)来创建。特征工程是数据预处理的一部分,涉及从现有数据中创建新的特征,以帮助分析和建模。
- 有时为了以合理的确定性回答问题需要我们有足够的数据,因此我们可能需要收集额外的数据。
- 对于最后第五种问题,这种“如何”类的问题一般涉及建立不同变量之间关系模型。
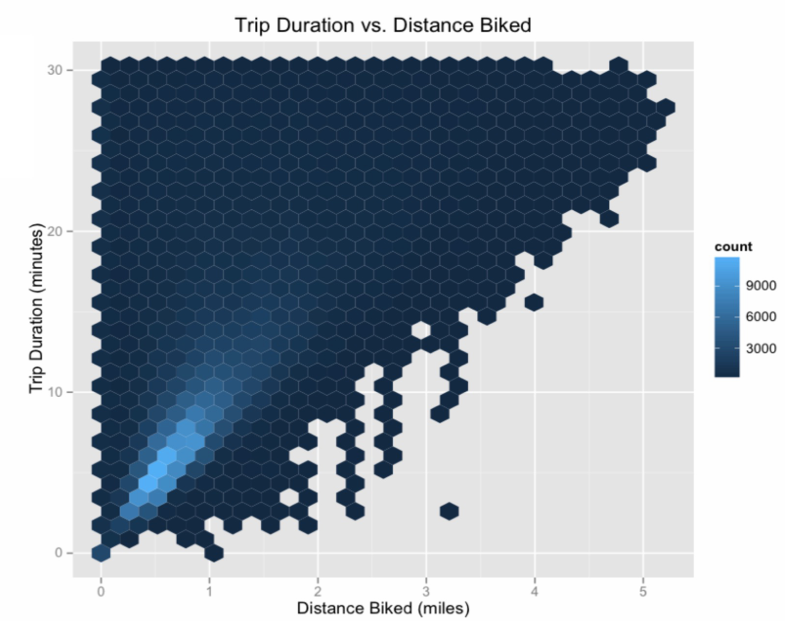
而数据可视化可以帮助我们提出创造性假设,并操作数据来找到这些问题的答案。
这个例子中,从得到数据开始,提出问题,细化问题,收集数据,可视化数据,然后提出假设,这些都是数据科学流程中的重要组成部分。
我们再看一个例子,这个例子中需要我们创建一个类似于中国版Facebook的社交网络平台。
那么问题是需要收集和存储哪些类型的数据?
下图给出了一个数据。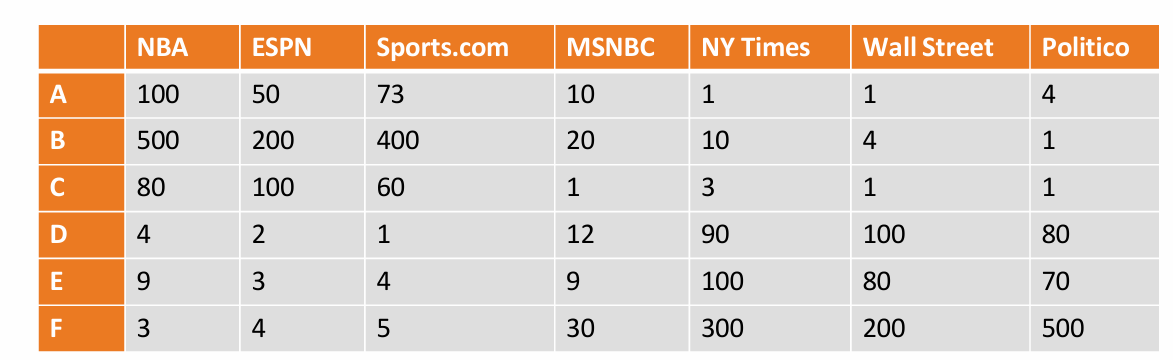
我们可以利用相似性进行数据挖掘。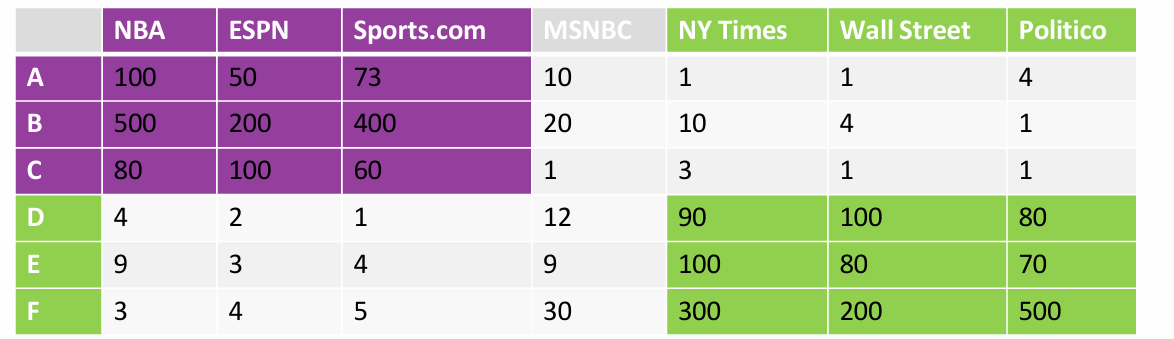
用户A、B、C在体育相关网站(NBA, ESPN, Sports.com)上的点击次数较高,表明他们可能对体育内容更感兴趣。
用户D、E、F在政治相关网站(Politico)上的点击次数较高,表明他们可能对政治内容更感兴趣。
用户B和F在NY Times上的点击次数也较高,这可能表明他们对新闻内容有广泛的兴趣。
在这里我们可以使用余弦相似度、皮尔逊相关系数等方法计算用户点击行为的相似度。
也可以使用聚类算法将相似的用户分组从而得到更多的结论。
那如果我们缺少某个数据该怎么办?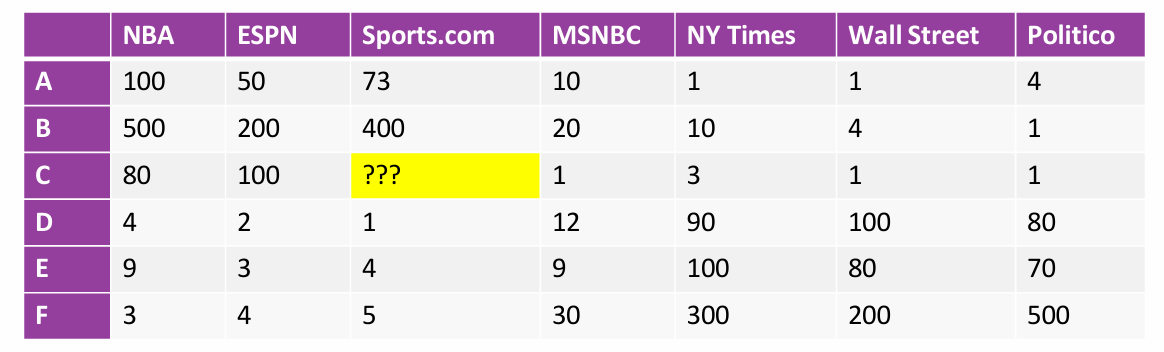
如果两个用户在多个项目上表现出相似的喜好,那么他们可能在未评价的项目上也会表现出相似的喜好。这可以用来预测缺失的值或推荐新的内容。
因此处理缺失数据的方法:
- 相似性填充:可以通过找到与用户C在其他网站上点击行为相似的其他用户(如用户A或B),并使用这些相似用户的Sports.com点击次数来估计用户C的点击次数。
- 聚类分析:使用聚类算法将用户分组,然后在同一个群体内进行平均或模式填充。
- 机器学习模型:训练一个预测模型,如线性回归或决策树,来预测缺失的值。
这便是推荐系统的背后原理,不仅是这种数据上的,还可以是“好友”这种数据。如果两个人有共同的朋友,那么这两个人也很可能成为朋友。从而通过这种方式进行好友推荐。
刚刚提到了预测任务,其有三种类型:
- 回归(Regression):回归是一种预测连续数值的任务。例如,预测用户点击广告的次数、预测房价、预测销售额等。回归模型试图找到输入变量(如用户特征、时间、地点等)和输出变量(如点击次数)之间的关系。
- 二元分类(Binary Classification):二元分类是一种预测离散结果(通常是二选一)的任务。例如,预测用户是否会点击某个广告(是/否)、预测邮件是否为垃圾邮件(是/否)、预测客户是否会流失(是/否)等。二元分类模型的目标是将输入数据分为两类。
- 分类(Classification):分类是一种预测离散结果(多于两个类别)的任务。例如,预测社交媒体帖子的主题(新闻、体育、娱乐等)、预测客户反馈的情感(正面、负面、中性等)、预测图像中的对象类别(猫、狗、汽车等)等。分类模型的目标是将输入数据分配到多个预定义的类别中。
刚刚提到的数据预测、聚类和分类也都是数据科学流程的重要组成部分。
我们再回到前面说的我们可以通过可视化来进行分析,这里我们也可以使用图像,例如社交网络图表示社交网络中用户(节点)和他们之间的关系(边)的图结构。
我们可以使用PageRank算法(如果一个节点被其他重要节点指向,则该节点很重要)便可以得到谁重要且有影响力?等问题的答案。
3. 新时代数据挖掘(NEW ERA OF DATA MINING)
数据挖掘、机器学习和人工智能之间的区分越来越不明显。在现代语境中,这些术语经常被互换使用,尽管它们在技术上可能有细微的差别。
因此对于现在我们应该尝试在设计算法时,需要考虑它们能否处理大规模的数据集。而且将统计推断用于构建模型。
我们需要知道数据是AI的引擎,而数据挖掘触及与数据相关的一切。
我们涉及到的关于数据的算法需要将结果建立于数据自身身上。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)