Transformer之前馈神经网络(FFN全连接层)
本文深入解析了Transformer架构中的前馈神经网络(FFN)模块,揭示其核心作用与实现原理。FFN位于Transformer层后半部分,采用"升维-激活-降维"的三步结构(线性变换→GELU激活→线性变换),负责深层语义理解。在Transformer中,FFN与注意力机制协同工作:注意力层捕捉词间关系,FFN则进行深度语义加工。关键优势体现在三个方面:实现非线性语义挖掘、
Transformer之前馈神经网络(FFN全连接层)
Transformer之前馈神经网络(FFN全连接层)

前言
在探讨Transformer时,许多人会将目光锁定在其引人瞩目的注意力机制上,然而,真正支撑起这一架构的,常常是被忽视的“隐形大佬”——前馈神经网络(FFN)。本文将深入解析FFN的结构、参数设计及其在Transformer中的核心价值,揭示它在深层语义理解中不可或缺的作用。
FFN是什么?
前馈网络是Transformer模型中的核心组件之一,位于每个Transformer层的后半部分。它的经典结构是:线性变换(升维)→ 激活函数 → 线性变换(降维)
一、前馈网络在Transformer结构图中位置及其意义
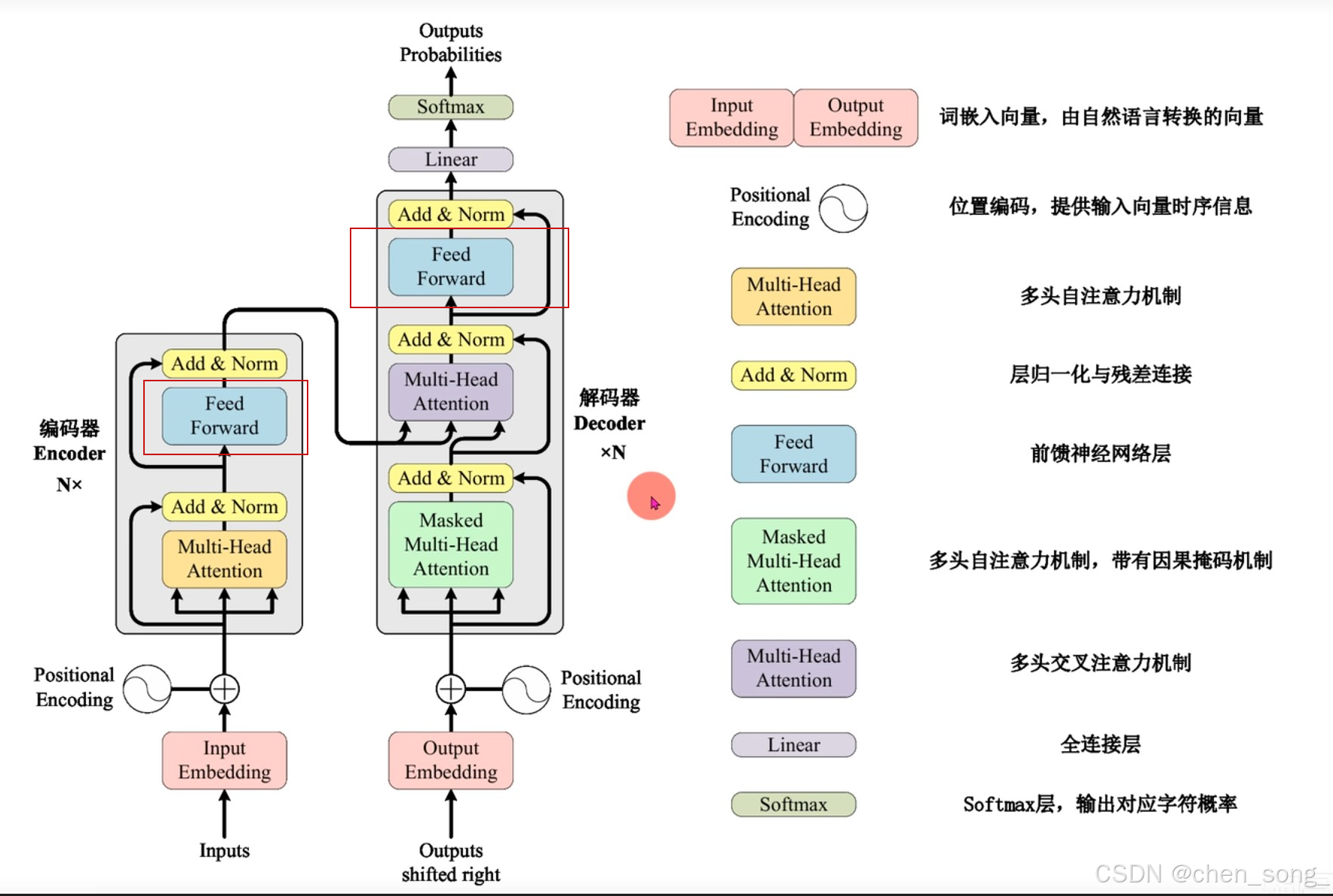
-
首先,明确FFN在Transformer中的位置和角色。FFN并不是孤立存在的,它与注意力层、残差连接共同形成了一个协作闭环。在每个Encoder和Decoder模块中,FFN的工作流程是固定的:注意力层输出后,经过残差连接与归一化,接着进入FFN,再经过一次残差连接与归一化。简而言之,注意力层负责“找关系”,而FFN则负责“挖深度”,二者共同完成信息的处理。
-
FFN的核心原理可被简化为三个加工步骤:升维、激活、降维。 尽管这一结构看似简单,但每一步都有其深意。可以将其比作一个智能工厂,专门处理词向量。在这个过程中,输入的词向量经过升维后,能够更细致地容纳复杂信息,如情绪和隐喻。随后,通过降维,FFN确保与残差连接的输入输出维度一致,从而顺利完成信息的处理。
-
FFN在Transformer中扮演着至关重要的角色,解决了三个关键问题:深度语义挖掘、并行计算的高效性和训练的稳定性。首先,FFN能够将注意力层找到的词与词之间的关联转化为深层的含义。例如,当处理“把猫放在桌上”时,注意力层识别出词之间的关系,而FFN则将“放”理解为“带有空间转移的动作”。其次,FFN能够并行处理多个词向量,显著提升模型的训练和推理速度,远超传统RNN的逐个处理方式。最后,FFN的升维和降维设计有效地与Transformer的残差连接和归一化相结合,确保了模型的稳定训练。
-
数据也显示了FFN的重要性。在传统的Transformer架构中,FFN的参数占比高达60%-80%,成为模型的核心知识载体。随着模型规模的扩大,FFN的参数量也在持续增加,这表明它在模型能力提升中扮演着越来越关键的角色。此外,FFN的计算复杂度为线性,即使在处理长句子时,也不会出现计算量爆炸的情况,兼顾了高效与高性能。
-
那么,FFN与其他神经网络之间有什么区别呢?实际上,FFN并不是简单的替代关系,而是与RNN、CNN及注意力层相辅相成。FFN在处理复杂语义、提高并行计算效率和保证训练稳定性等方面具有独特优势。
-
总而言之,FFN可以被视为Transformer的“大脑皮层”。在这个比喻中,注意力层如同“眼睛和耳朵”,负责感知信息,而FFN则负责理解这些信息的深层意义。通过简单的升维、激活和降维结构,FFN赋予Transformer非线性表达、并行高效及稳定迭代的能力。
下 次当你提到FFN时,请不要再将其视为“背景板”。它不仅仅是一个辅助模块,而是Transformer“会思考”的核心。真正理解FFN,才算是彻底掌握了Transformer的完整逻辑。
二、 代码实现
在Transformer中编码或者解码层中前馈网络输入是 多注意力输出经过残差(Add)、归一化(Layer Norm)处理在输入到前馈网络中的升维、激活、降维 处理中维度是乘以4,升维度, 除以4进行降维度。 然后再结果过拟合(Dropout) 输出了
实际模型中的FFN
| 模型 | FFN配置 | 特点 |
|---|---|---|
| 原始Transformer | 维度×4,ReLU | 确立基本架构 |
| BERT | 维度×4,GELU | 效果优于ReLU |
| GPT系列 | 维度×4 → 维度×(4×2/3) | 使用GeLU等改进 |
| LLaMA | 维度×(8/3)×2,SwiGLU | 更高效的维度利用 |
| GPT-4 | MoE架构,多个专家 | 极大增加容量 |
1、在TransformerBlock层上操作的实现
TransformerBlock::TransformerBlock(const ModelConfig& cfg)
: mha(cfg),
ffn(cfg),
norm_1(torch::nn::LayerNormOptions({cfg.embedding_dim})),
norm_2(torch::nn::LayerNormOptions({cfg.embedding_dim})),
dropout(torch::nn::DropoutOptions(cfg.drop_rate)) {
// 注册模块
register_module("mha", mha);
register_module("ffn", ffn);
register_module("norm_1", norm_1);
register_module("norm_2", norm_2);
register_module("dropout", dropout);
}
torch::Tensor TransformerBlock::forward(torch::Tensor x) {
// 输入: x (batch_size, seq_len, embedding_dim)
auto old_x = x;
// ========== 第一部分: 多头自注意力 ==========
// 1. Layer Norm
x = norm_1->forward(x);
// 2. Multi-Head Attention
x = mha->forward(x);
// 3. Dropout
x = dropout->forward(x);
// 4. 残差连接
x = x + old_x;
// ========== 第二部分: 前馈网络 ==========
old_x = x; // 为后面的残差连接保存值
// 1. Layer Norm 归一化
x = norm_2->forward(x);
// 2. Feed Forward Network 前馈网络FFN
x = ffn->forward(x);
// 3. Dropout 过拟合
x = dropout->forward(x);
// 4. 残差连接
x = x + old_x;
return x;
}
2、 激活函数 GELU实现
NewGELU::NewGELU() {
// GELU 不需要参数
}
torch::Tensor NewGELU::forward(torch::Tensor x) {
// GELU 公式: GELU(x) = 0.5 * x * (1 + tanh(√(2/π) * (x + 0.044715 * x³)))
// 使用 tanh 近似,计算效率高且数值稳定
const double sqrt_2_over_pi = std::sqrt(2.0 / M_PI);
const double coeff = 0.044715;
return 0.5 * x * (1.0 + torch::tanh(sqrt_2_over_pi * (x + coeff * torch::pow(x, 3.0))));
}
3、升维和降维的实现
FeedForwardNetworkImpl::FeedForwardNetworkImpl(const ModelConfig& cfg)
: layers(torch::nn::Sequential(
torch::nn::Linear(torch::nn::LinearOptions(cfg.embedding_dim, 4 * cfg.embedding_dim)),
NewGELU(),
torch::nn::Linear(torch::nn::LinearOptions(4 * cfg.embedding_dim, cfg.embedding_dim))
)) {
register_module("layers", layers);
}
torch::Tensor FeedForwardNetworkImpl::forward(torch::Tensor x) {
// 通过三层网络:Linear → GELU → Linear
// 输入: (batch_size, seq_len, embedding_dim)
// 输出: (batch_size, seq_len, embedding_dim)
return layers->forward(x);
}
总结
AIGC、LLM大模型项目:https://chensongpoixs.github.io/LLMSAPP/
Transformer使用C++实现仓库地址:https://github.com/chensongpoixs/LLMSAPP/tree/master/Transformer_cpp

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)