dify1.11.1 + vllm0.13.0部署Qwen/Qwen3-32B(开启Function Calling)
本文详细介绍了在vllm 0.13.0环境下部署通义千问3-32B模型的过程。首先通过魔塔社区下载模型文件,使用vllm启动服务并配置参数(包括开启Function Calling功能)。随后在Dify平台中安装vllm插件,完成模型配置和能力设置。最后构建了一个简单的agent测试模型工具调用功能,验证了时间工具的正确性。整个过程展示了新版vllm在双卡并行下的优秀性能表现,为开发者提供了完整的
·
1.系统环境
- vllm版本
vllm最近升级到了最新版,查看当前版本可以用如下命令
python -c "import vllm; print(vllm.__version__)"

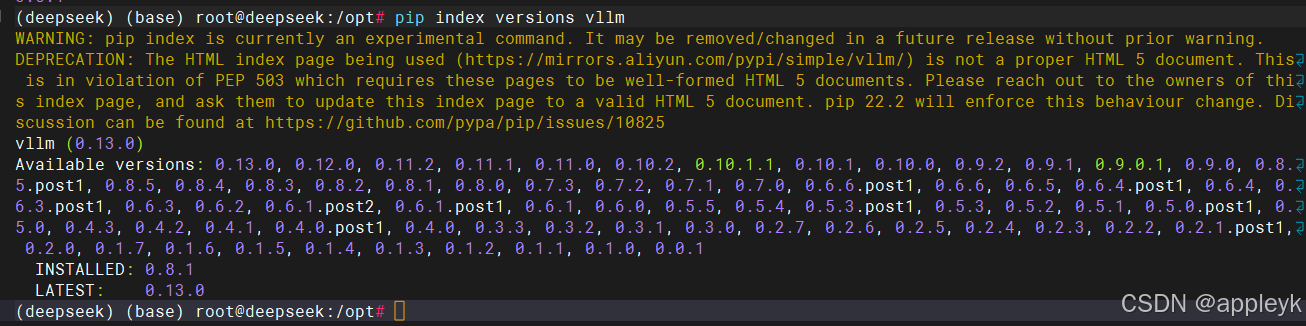
- pythyon版本

- 显存
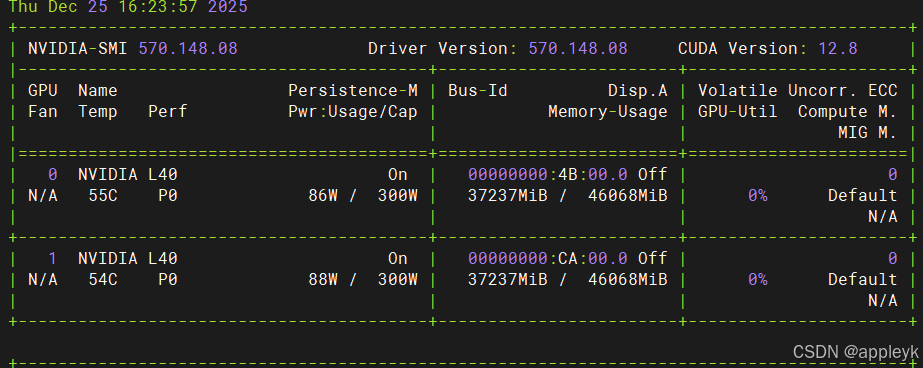
2.魔塔社区下载通义千问3-32B
地址:通义千问3-32B

- 下载命令如下:
modelscope download --model Qwen/Qwen3-32B --local_dir /opt/qwen32b
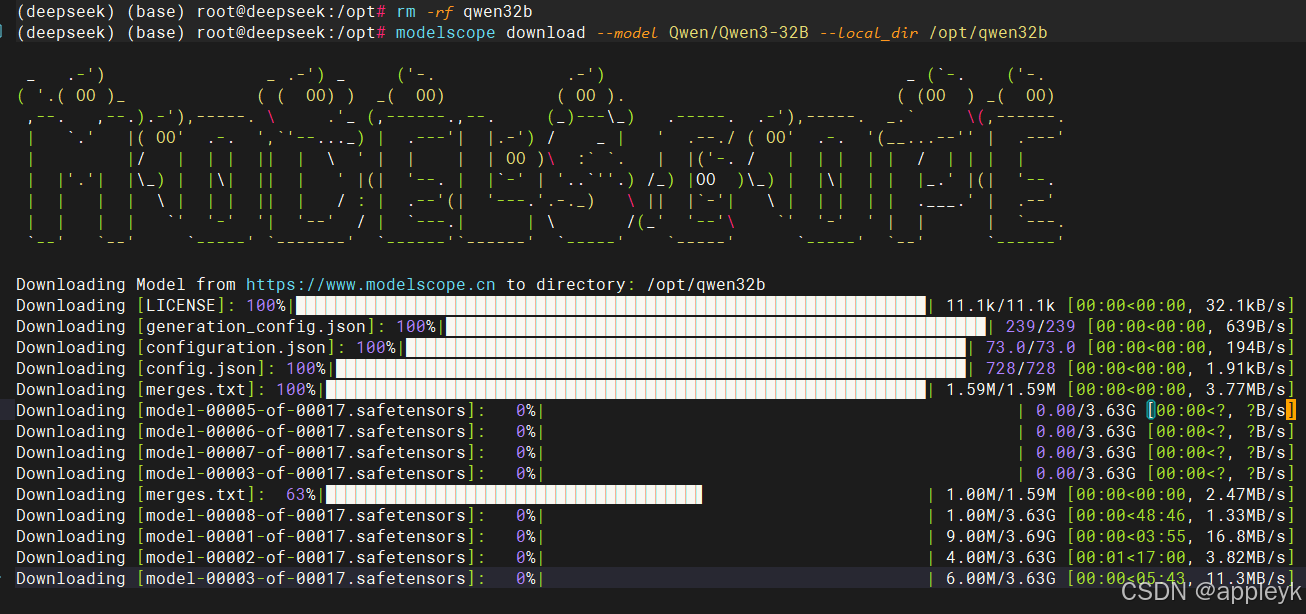
3.模型启动
– 启动命令如下(含开启Function Calling)
vllm serve /opt/qwen32b --tensor-parallel-size 2 --gpu-memory-utilization 0.8 --max-model-len 16000 --enforce-eager --served-model-name qwen3-32b --trust-remote-code --enable-auto-tool-choice --tool-call-parser hermes --host 0.0.0.0 > /opt/vllm.log 2>&1 &
echo $! | sudo tee /var/run/vllm.pid
可以把上述命令写进sh脚本里
- 查看日志启动如下
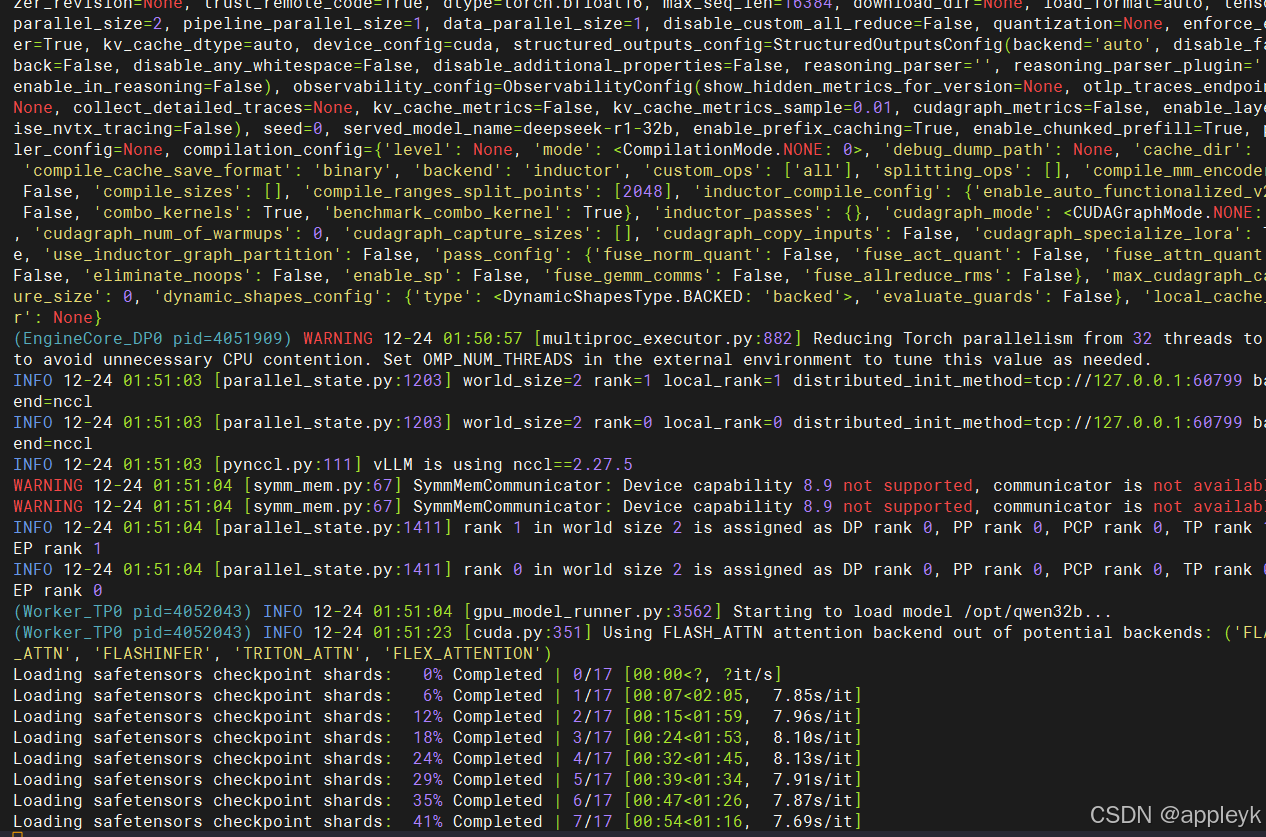
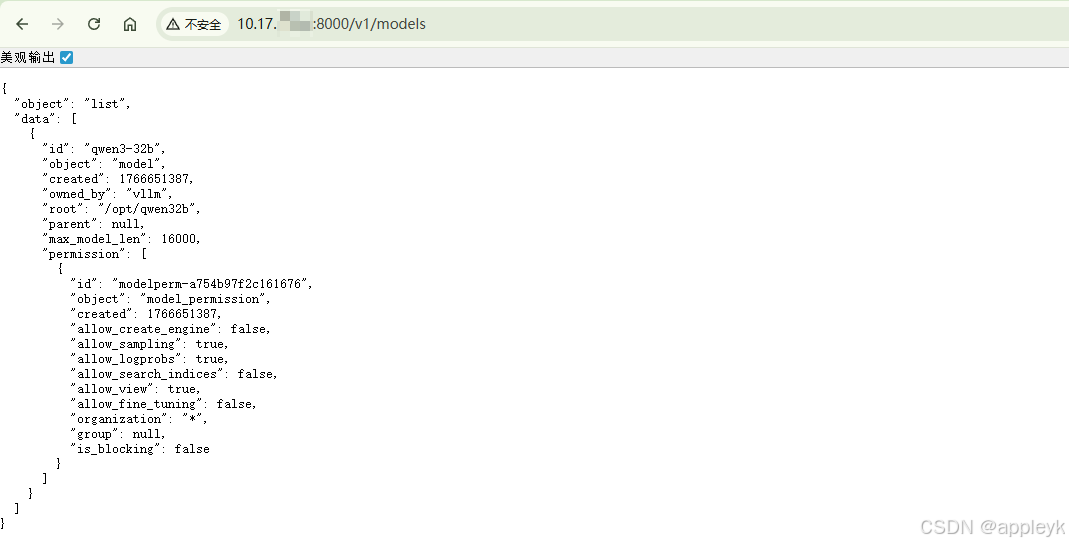
- 浏览器输入地址 : 查询模型列表 以验证vllm是否成功部署qwen32b模型
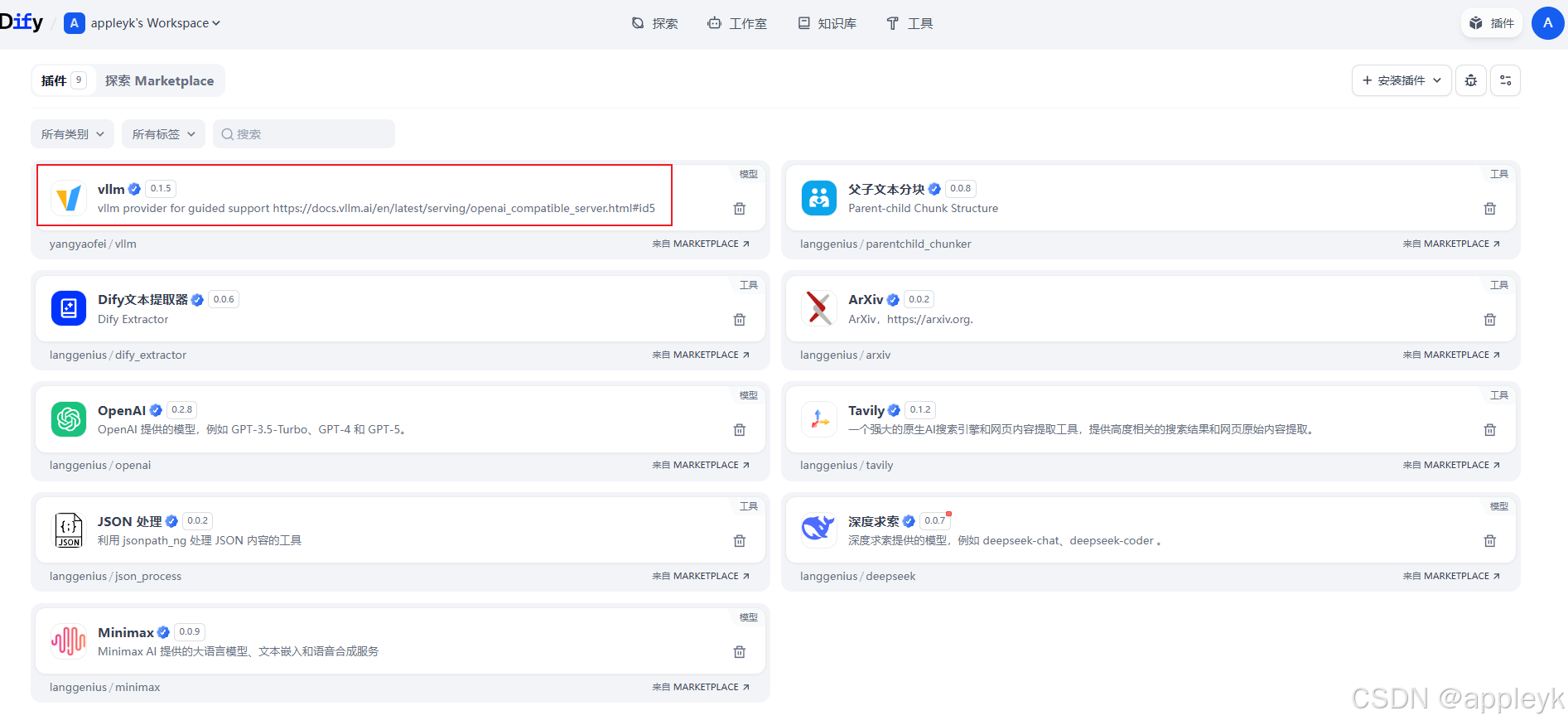
4.dify中配置
4.1 先安装vllm的插件
4.2 设置中配置vllm添加模型
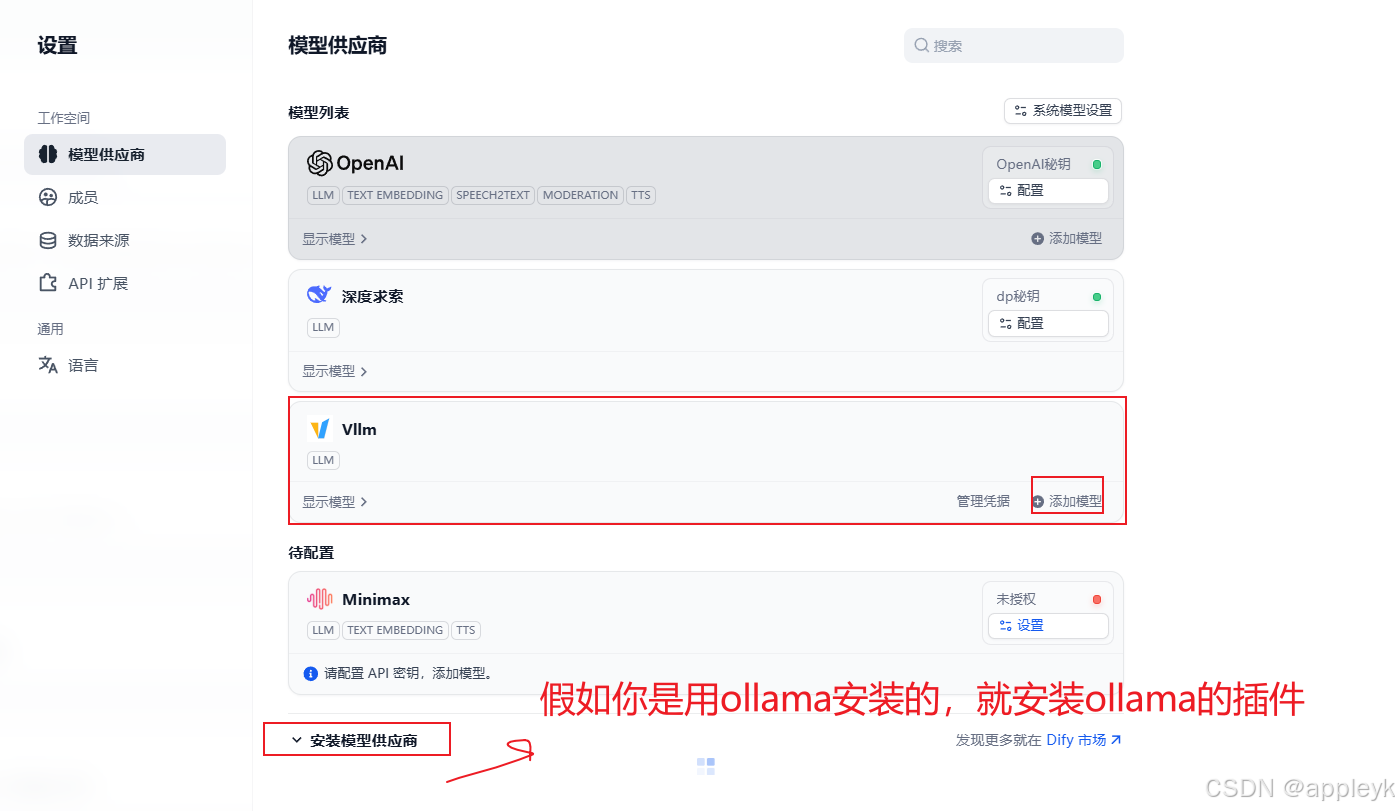
- 模型基本配置如下:
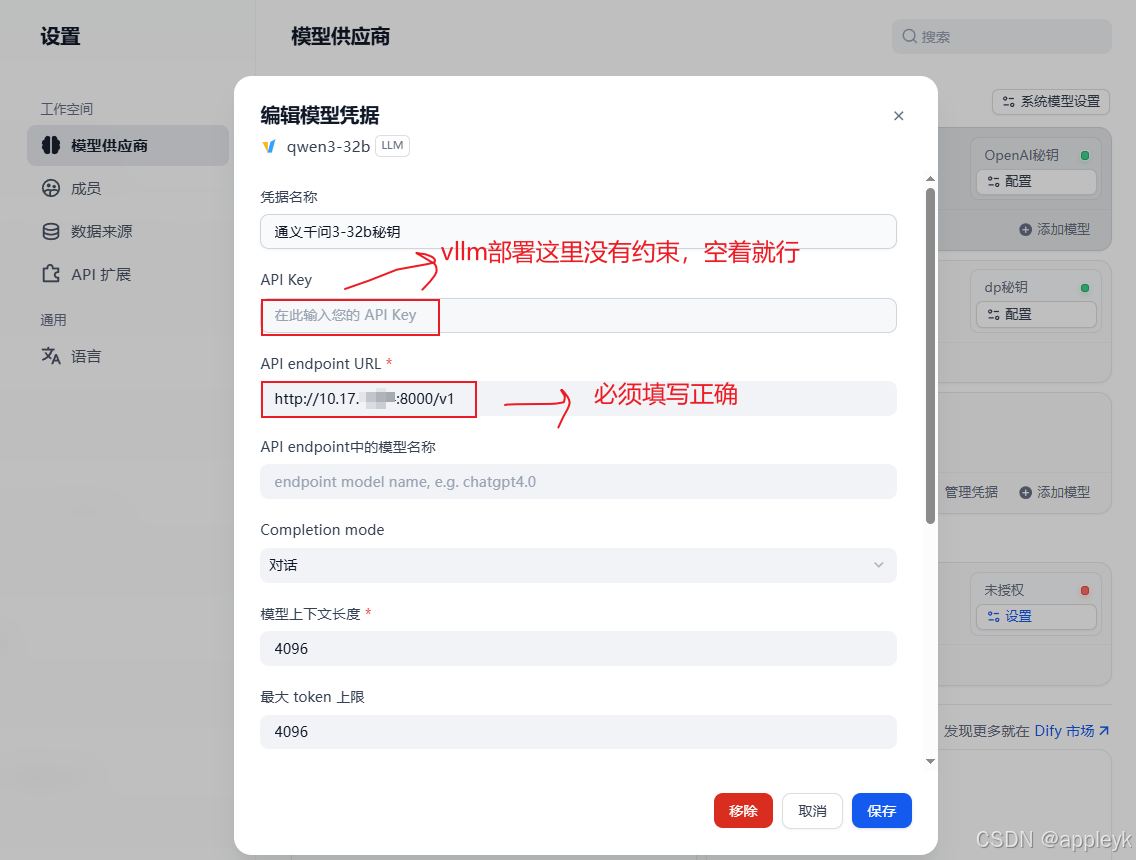
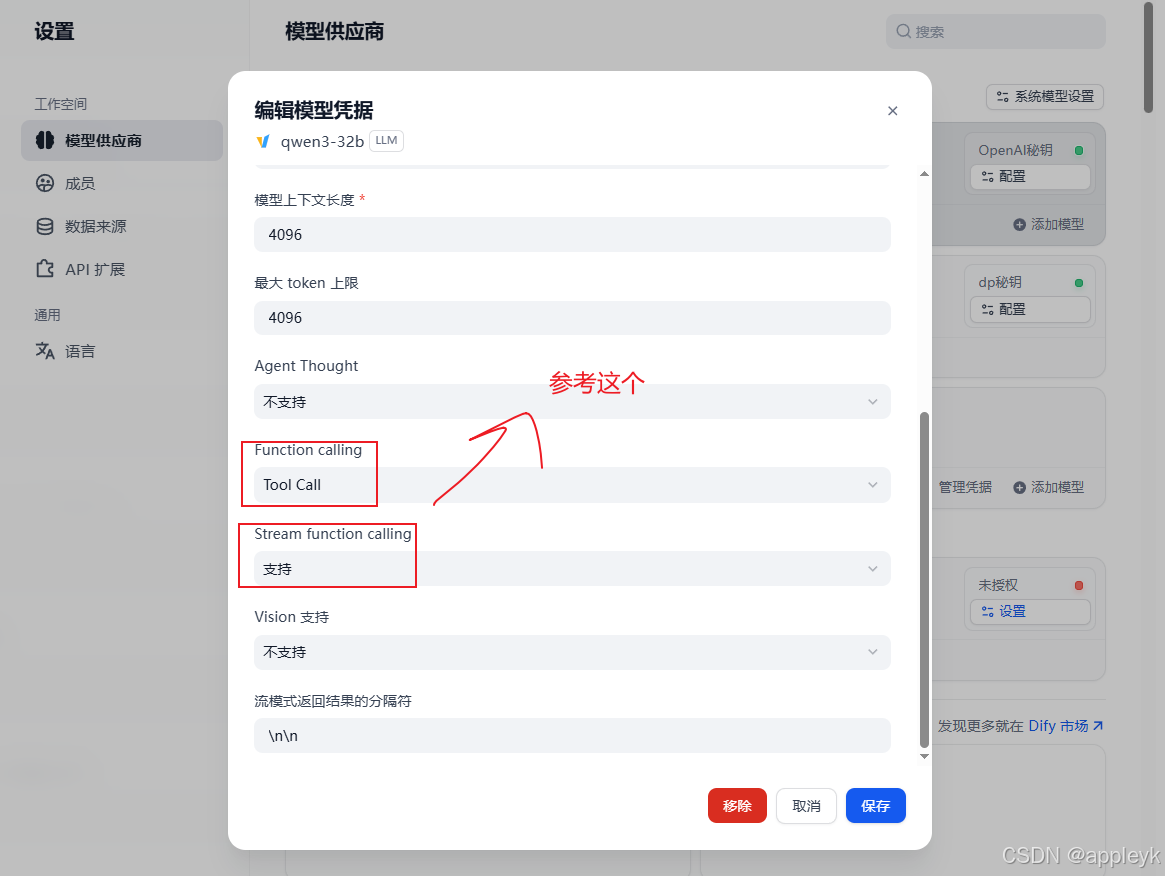
- 设置模型的能力:
5.dify中测试
5.1 简单构建一个agent
- 构建一个agent,利用内置的时间工具测试下,当前部署的qwen3-32b是否可以调用工具
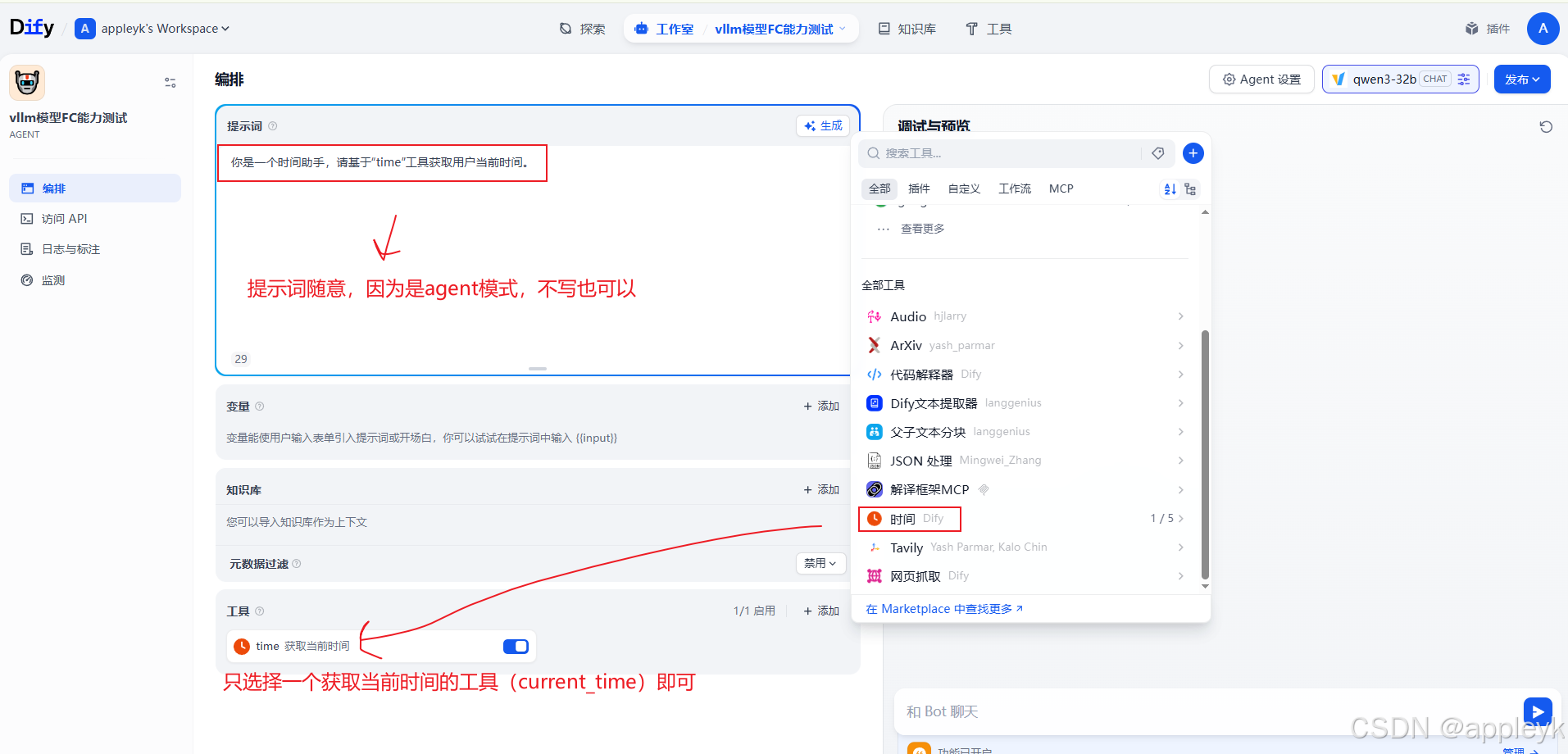
- 配置工具,有条件的可以用mcp替代
- 为了快速响应,关闭qwen3模型的思考模式
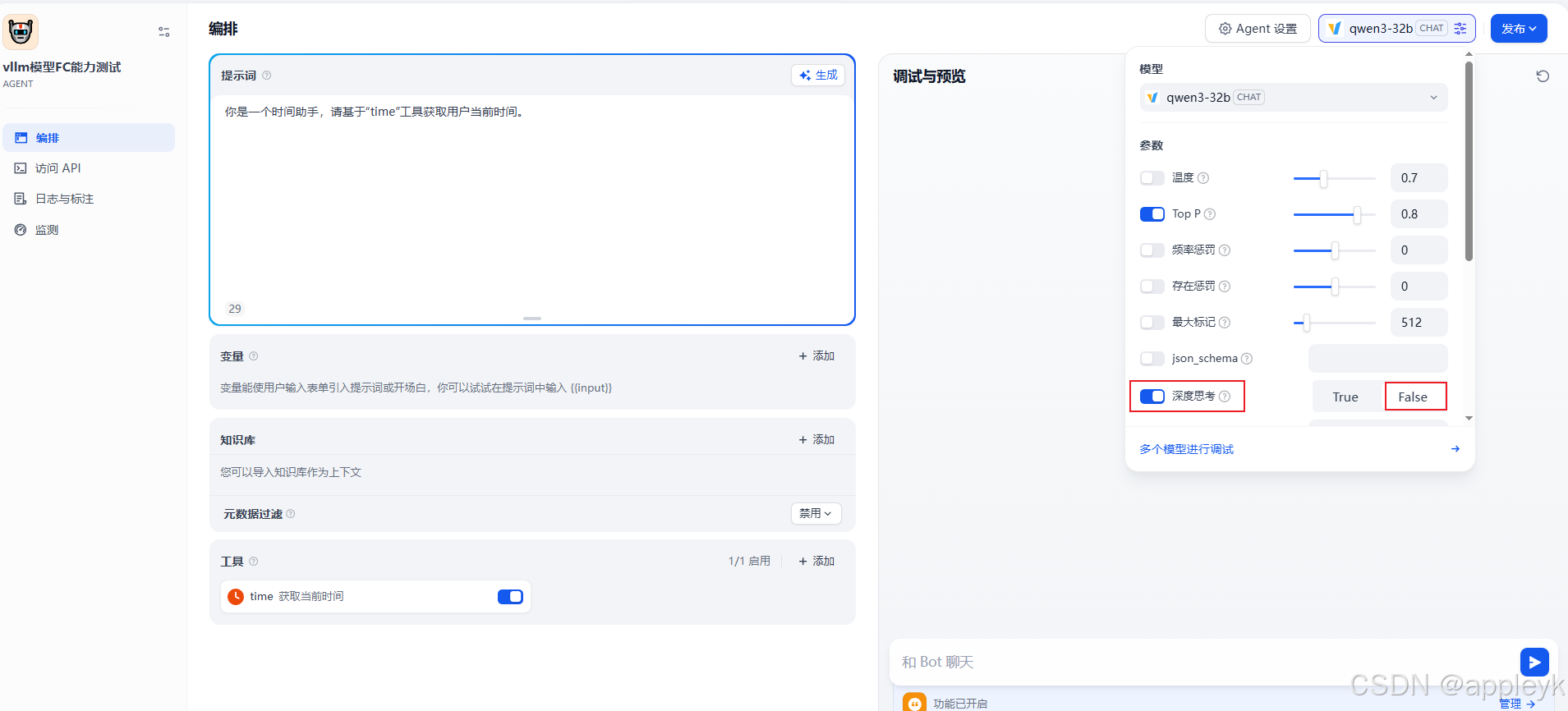
- 测试如下,时间没问题

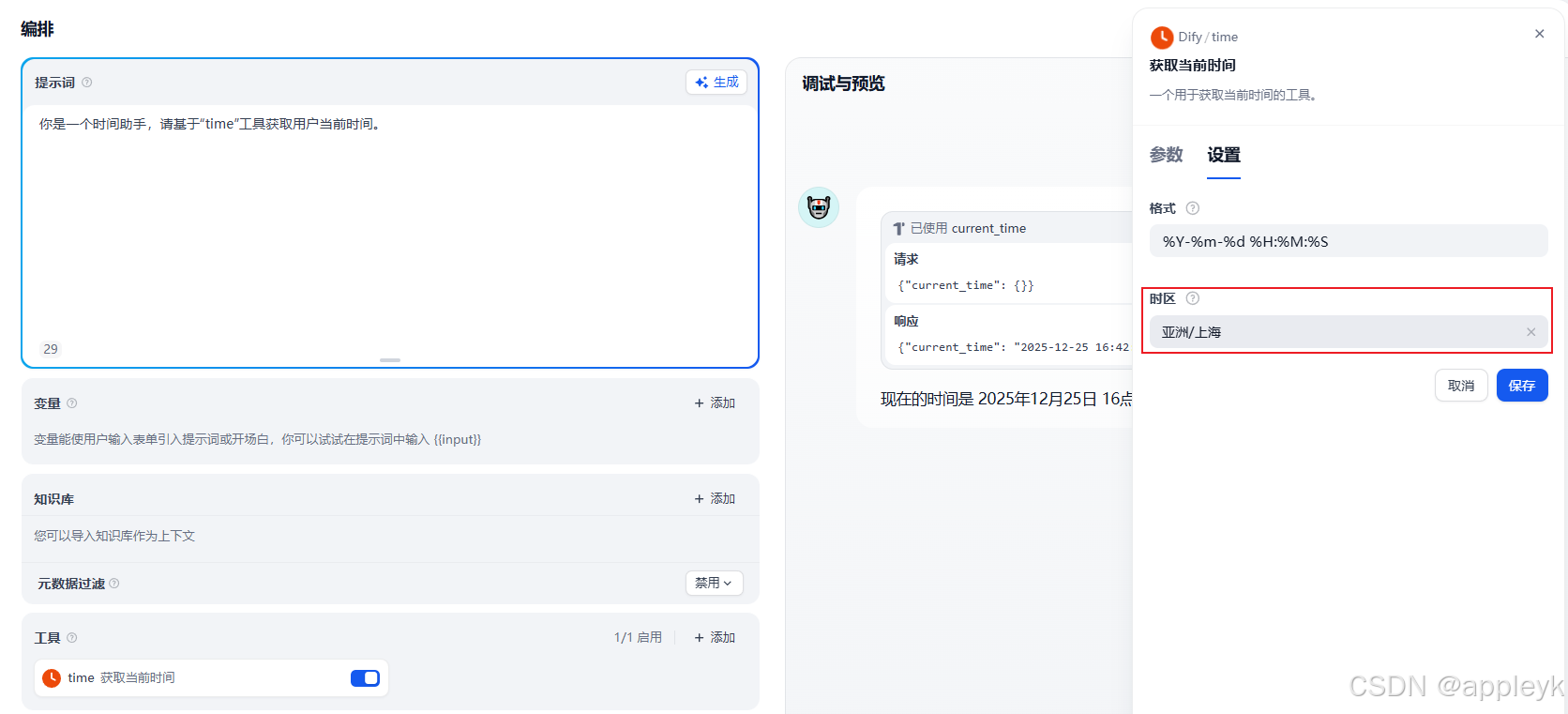
- 如果有问题,记得选下时区
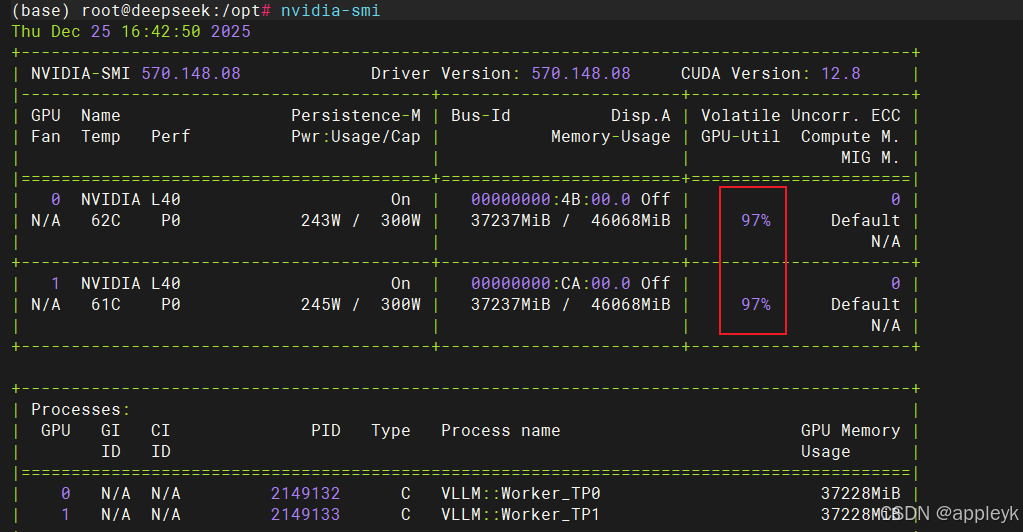
- 最后,两张卡是并行跑的,新版本的vllm在性能上已经很优秀了

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)