汇丰银行 java后端开发最新面试题
HashMap 底层实现介绍一下?
在 JDK 1.7 版本之前, HashMap 数据结构是数组和链表,HashMap通过哈希算法将元素的键(Key)映射到数组中的槽位(Bucket)。如果多个键映射到同一个槽位,它们会以链表的形式存储在同一个槽位上,因为链表的查询时间是O(n),所以冲突很严重,一个索引上的链表非常长,效率就很低了。
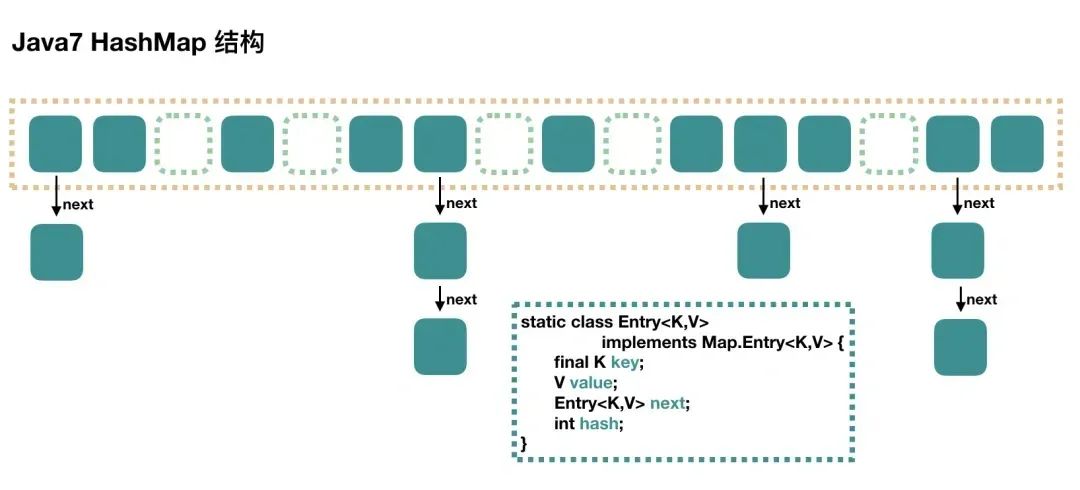
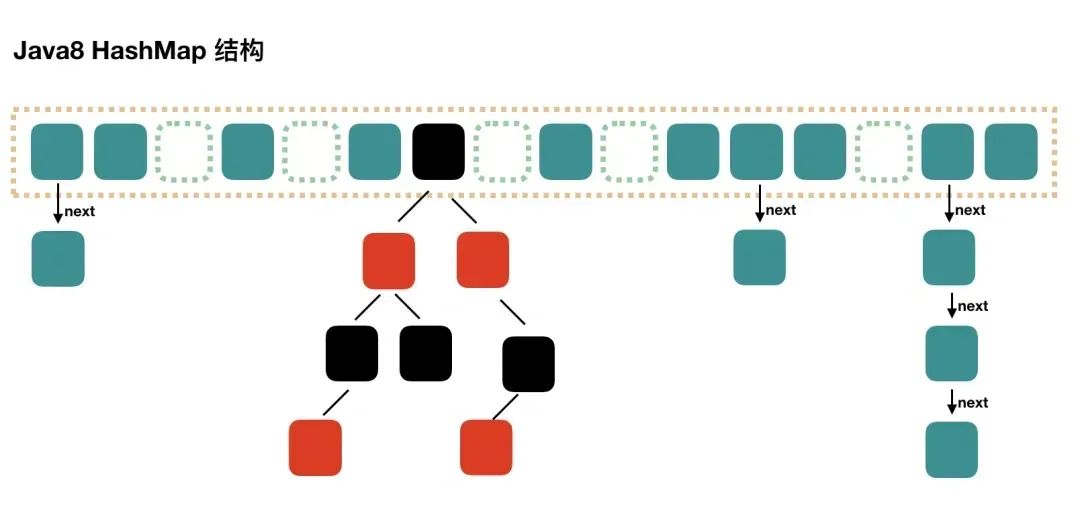
所以在 JDK 1.8 版本的时候做了优化,当一个链表的长度超过8的时候就转换数据结构,不再使用链表存储,而是使用红黑树,查找时使用红黑树,时间复杂度O(log n),可以提高查询性能,但是在数量较少时,即数量小于6时,会将红黑树转换回链表。
null
HashMap 是如何获取元素的?
HashMap 获取元素的过程主要依赖于哈希计算和链表或红黑树的遍历。
当调用 get(key) 方法时,HashMap 首先会计算 key 的哈希值,然后通过 (n - 1) & hash 确定该 key 对应的桶(bucket)位置,其中 n 是数组的长度。
-
如果该位置存放的是单个节点,直接比较 key 是否相等,相等则返回对应的 value。
-
如果该位置存放的是链表或红黑树,则会遍历该结构,使用
equals()方法逐一比对 key,直到找到匹配的节点并返回 value。如果遍历完仍未找到匹配的 key,则返回 null。
为了提高查询效率,HashMap 在 JDK 8 之后引入了红黑树优化,当链表长度超过 8 且数组长度大于等于 64 时,链表会转换为红黑树,这样在最坏情况下,查询时间复杂度仍能保持在 O(log n)。
整个获取元素的过程高效且稳定,平均时间复杂度为 O(1),但极端情况下(如哈希冲突严重)可能会退化到 O(log n)。
concurrentHashMap 如何加锁保证线程安全?
JDK 1.7 ConcurrentHashMap
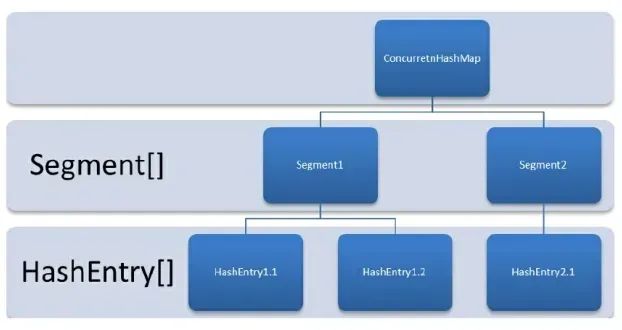
在 JDK 1.7 中它使用的是数组加链表的形式实现的,而数组又分为:大数组 Segment 和小数组 HashEntry。 Segment 是一种可重入锁(ReentrantLock),在 ConcurrentHashMap 里扮演锁的角色;HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素。
null
JDK 1.7 ConcurrentHashMap 分段锁技术将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
JDK 1.8 ConcurrentHashMap
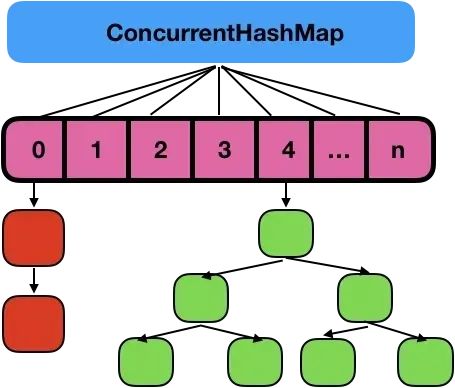
在 JDK 1.7 中,ConcurrentHashMap 虽然是线程安全的,但因为它的底层实现是数组 + 链表的形式,所以在数据比较多的情况下访问是很慢的,因为要遍历整个链表,而 JDK 1.8 则使用了数组 + 链表/红黑树的方式优化了 ConcurrentHashMap 的实现,具体实现结构如下:
null
JDK 1.8 ConcurrentHashMap JDK 1.8 ConcurrentHashMap 主要通过 volatile + CAS 或者 synchronized 来实现的线程安全的。添加元素时首先会判断容器是否为空:
-
如果为空则使用 volatile 加 CAS 来初始化
-
如果容器不为空,则根据存储的元素计算该位置是否为空。
-
如果根据存储的元素计算结果为空,则利用 CAS 设置该节点;
-
如果根据存储的元素计算结果不为空,则使用 synchronized ,然后,遍历桶中的数据,并替换或新增节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
-
如果把上面的执行用一句话归纳的话,就相当于是ConcurrentHashMap通过对头结点加锁来保证线程安全的,锁的粒度相比 Segment 来说更小了,发生冲突和加锁的频率降低了,并发操作的性能就提高了。
而且 JDK 1.8 使用的是红黑树优化了之前的固定链表,那么当数据量比较大的时候,查询性能也得到了很大的提升,从之前的 O(n) 优化到了 O(logn) 的时间复杂度。
synchronized 和 reentrantlock 的区别?
synchronized 和 ReentrantLock 都是 Java 中提供的可重入锁:
-
用法不同:synchronized 可用来修饰普通方法、静态方法和代码块,而 ReentrantLock 只能用在代码块上。
-
获取锁和释放锁方式不同:synchronized 会自动加锁和释放锁,当进入 synchronized 修饰的代码块之后会自动加锁,当离开 synchronized 的代码段之后会自动释放锁。而 ReentrantLock 需要手动加锁和释放锁
-
锁类型不同:synchronized 属于非公平锁,而 ReentrantLock 既可以是公平锁也可以是非公平锁。
-
响应中断不同:ReentrantLock 可以响应中断,解决死锁的问题,而 synchronized 不能响应中断。
-
底层实现不同:synchronized 是 JVM 层面通过监视器实现的,而 ReentrantLock 是基于 AQS 实现的。
JVM 的垃圾回收机制中,mirror gc 与 full gc 区别?
Minor GC 和 Full GC 都是 JVM 中触发的垃圾回收操作:
-
回收范围不同:Minor GC 只清理新生代(Eden 区和 Survivor 区),而 Full GC 会清理整个堆内存,包括新生代、老年代和元空间。
-
触发条件不同:Minor GC 是在新生代空间不足时触发,而 Full GC 是在老年代空间不足、元空间不足、调用
System.gc()或 CMS GC 并发失败时触发。 -
STW 时间不同:Minor GC 的暂停时间通常较短(几毫秒到几十毫秒),而 Full GC 的暂停时间较长(可能达到秒级)。
-
使用算法不同:Minor GC 一般采用复制算法,而 Full GC 采用标记 - 清除或标记 - 整理算法。
-
触发频率不同:Minor GC 触发频率较高,而 Full GC 触发频率较低。
内存溢出与内存泄漏区别?
内存泄露:内存泄漏是指程序在运行过程中不再使用的对象仍然被引用,而无法被垃圾收集器回收,从而导致可用内存逐渐减少。虽然在Java中,垃圾回收机制会自动回收不再使用的对象,但如果有对象仍被不再使用的引用持有,垃圾收集器无法回收这些内存,最终可能导致程序的内存使用不断增加。
内存泄露常见原因:
-
静态集合:使用静态数据结构(如
HashMap或ArrayList)存储对象,且未清理。 -
事件监听:未取消对事件源的监听,导致对象持续被引用。
-
线程:未停止的线程可能持有对象引用,无法被回收。
内存溢出:内存溢出是指Java虚拟机(JVM)在申请内存时,无法找到足够的内存,最终引发OutOfMemoryError。这通常发生在堆内存不足以存放新创建的对象时。
内存溢出常见原因:
-
大量对象创建:程序中不断创建大量对象,超出JVM堆的限制。
-
持久引用:大型数据结构(如缓存、集合等)长时间持有对象引用,导致内存累积。
-
递归调用:深度递归导致栈溢出。
什么情况会导致OOM?
Java中的OutOfMemoryError通常发生在JVM无法分配足够内存来满足需求时,具体原因和发生的内存区域密切相关。最常见的情况是Java堆空间溢出,错误信息是Java heap space,这意味着创建了太多对象且它们都被强引用持有(比如内存泄漏),或者要处理的数据量确实超出了配置的最大堆大小(-Xmx),垃圾回收器无法回收足够的空间。
元空间溢出,错误是Metaspace,发生在Java 8之后,原因是加载了过多的类,或者应用程序生成了大量动态类(例如过度使用CGLIB代理、反射、字节码生成),耗尽了存储类元数据的元空间内存。
直接内存溢出,错误信息如Direct buffer memory或allocate native memory,是由于通过NIO的allocateDirect分配了过多的堆外内存缓冲区,且未能及时释放,导致操作系统本地内存不足。
无法创建本地线程,错误是unable to create new native thread,这通常是因为创建的线程数超过了操作系统对单个进程的限制,或者系统资源(尤其是虚拟内存)不足以支撑新线程所需的栈内存(-Xss)。
此外,虽然StackOverflowError严格说不是OOM,但也是内存错误,发生在单个线程的调用栈深度过大(如无限递归)。而GC overhead limit exceeded则是堆空间将耗尽时的一种预警,表明GC花费了绝大部分时间却几乎回收不了内存,通常指向严重的内存泄漏。
诊断OOM的关键是看具体的错误信息,它直接指明了问题区域,然后结合堆转储分析、配置检查和内存监控来定位根本原因。
一道sql,一张表存放四个班级的所有学生成绩,如何取出最高三人成绩?如何按照班级,取出每班最高三人成绩?
取出最高三人成绩的sql :
SELECT *
FROM students
ORDER BY score DESC
LIMIT 3;
直接按成绩降序排序,取前 3 条记录。
取出每班最高三人成绩的sql:
SELECT s1.*
FROM students s1
WHERE (
SELECT COUNT(*)
FROM students s2
WHERE s2.class = s1.class AND s2.score > s1.score
) < 3
ORDER BY s1.class, s1.score DESC;
子查询统计每个班级中比当前学生成绩高的人数,如果人数 < 3,则当前学生为该班级前 3 名。
其他
-
离职原因,是否定居,未来发展计划等?
-
开发流程,编写代码所在比重,如何与产品测试对齐等?
-
英文自我介绍,两个英文问题
关注微信公众号:


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)