ComfyUI 文生图工作流
ComfyUI 文生图工作原理
文章目录
文生图(Text-to-Image)的本质可以理解为扩散模型的 反向去噪过程。
- 模型权重文件:我们常用的
v1-5-pruned-emaonly-fp16.safetensors本质上是一个封装好的“知识库”。它记录了模型在训练阶段学到的从纯高斯噪声中提取结构、逐步还原图像的能力。 - 生成逻辑:在推理时,我们只需输入提示词(Prompt),模型便会以文字语义为引导,在随机噪声中通过不断的迭代去噪,最终“打磨”出符合描述的目标图片。

为了实现高效生成,Stable Diffusion 引入了两个重要的空间概念:
(1)潜在空间 (Latent Space)
潜在空间是扩散模型进行运算的抽象数学空间。通过 VAE(变分自编码器)的编码,原始图片被压缩成极小的高维向量。
- 核心优势:它极大地降低了数据维度,减少了计算开销,使降噪过程在低功耗设备(如个人电脑)上运行成为可能。
- 形象比喻:就像建筑师在动工前绘制的设计蓝图。蓝图虽小,却承载了建筑的所有结构特征。在蓝图上修改方案(进行降噪计算),成本远低于直接搬动砖块(像素)。
(2)像素空间 (Pixel Space)
像素空间是我们肉眼所见的直观空间。
- 定义:它由成千上万个 R、G、B 像素点组成,是图像最终存储和展示的形式。
- 转换过程:当模型在潜在空间完成降噪后,VAE 的解码器会将那张“蓝图”还原成细节丰富的像素图,即我们最终看到的精美画作。
1 理解 Stable Diffusion网络
Stable Diffusion 模型里包含了三个组件:CLIP、VAE、UNet,这三个组件的参数和大小分布:
| 组件 | 参数个数 | 文件大小 | 占比 |
|---|---|---|---|
| CLIP | 123,060,480 | 492 MB | 12% |
| VAE | 83,653,863 | 335 MB | 8% |
| UNet | 859,520,964 | 3.44 GB | 80% |
| Total | 1,066,235,307 | 4.27 GB | 100% |
2 基础 UNet 网络

(1)整体流程:对称的“U”型结构
在 U-Net 架构中,图像从左侧输入,经过网络深度处理后,从右侧输出相同尺寸的图片。原生的 U-Net 主要用于医学图像分割,其输出是像素级的标签图;而在 Stable Diffusion(SD)中,其核心的反卷积网络(Denoiser)则利用此结构输出降噪后的图像。
(2)下采样(Encoder):捕捉高层语义
图像经过逐层下采样(Downsampling),空间尺寸逐渐减小(如减小至 32 × 32 32 \times 32 32×32)。这个过程被称为编码(Encoding)。
- 核心逻辑:下采样并非简单的信息丢失,而是通过牺牲空间分辨率来换取语义深度。
- 宏观视野:原始图片包含海量的像素细节,模型很难直接识别出复杂的物体。通过压缩,模型能够过滤掉细微的噪声,专注于捕捉图像的高维描述(例如:识别出图中有一只“猫”或一栋“房子”),从而在宏观层面上理解图片的本质特征。
(3)上采样(Decoder):空间分辨率还原
为了得到与原图尺寸一致的结果,网络右侧通过逐层上采样(Upsampling)进行解码(Decoding)。
- 作用:将下采样提取到的宏观语义信息,重新映射回原始的空间维度。
- 应用场景:在语义分割任务中,我们不仅要识别出“猫”,还必须精确标定每一个属于猫的像素点。因此,必须将信息还原到原图尺寸,这种预测才有实际意义。
(4)跳跃连接:
下采样不可避免地会丢失空间细节(如边缘、纹理),单纯依靠上采样很难完美还原。为了解决这一痛点,U-Net 引入了关键的跳跃连接(图中横向延伸的灰色箭头)。
- 机制:它跳过了传统的串行路径,直接将左侧编码器每一层保留的微观细节信息,水平传递并拼接到右侧对应层级的解码器中。
- 优势:上采样层在进行计算时,同时拥有了两种信息:
- 来自下方的宏观语义(知道这里画的是什么)。
- 来自左侧的微观细节(知道具体的轮廓和像素位置)。
这种“语义”与“细节”的完美融合,使得 U-Net 既能理解图像内容,又能精准定位或还原细节。
3 VAE变分自编码器
3.1 AutoEncoder AE 自编码器
(1)什么是自编码器(Autoencoder)?
自编码器通过一种“自我监督”的方式来学习如何压缩和还原图像,它由两个核心部分组成:
- 编码器(Encoder):负责将高维的图像“压缩”成低维的特征向量(编码)。
- 解码器(Decoder):负责将这个低维编码“还原”回原始图像。
(2)图像生成的本质:从“输入”到“多样性”
- 输入决定输出:为了避免程序只能生成单一图像,必须引入输入(如序号或向量)来区分不同的生成结果。
- 语义连续性:理想的生成模型不仅要能区分图像,还要求相近的输入能产生相似的输出。例如,输入向量的微小变化应对应图像特征(如身高、性别)的微小改变。
(3)核心目标:最小化重构误差
- 学习机制:通过对比“原始图像”与“生成图像”的差异,模型自动学习如何提取图像最精华的特征。
- 信息压缩:只要神经网络足够复杂,模型可以将大量图像信息压缩到极短的向量中。
(4)潜在的陷阱:语义信息的缺失
- 过度压缩的风险:如果模型仅仅通过“编号”(如0, 1, 2)来记住图片,虽然实现了极致压缩,但编码失去了语义意义。
- 插值失效:在这种情况下, 两个编码之间的中间值(如1.5)无法生成具有逻辑关联的中间状态图像,导致模型失去泛化和创作能力。
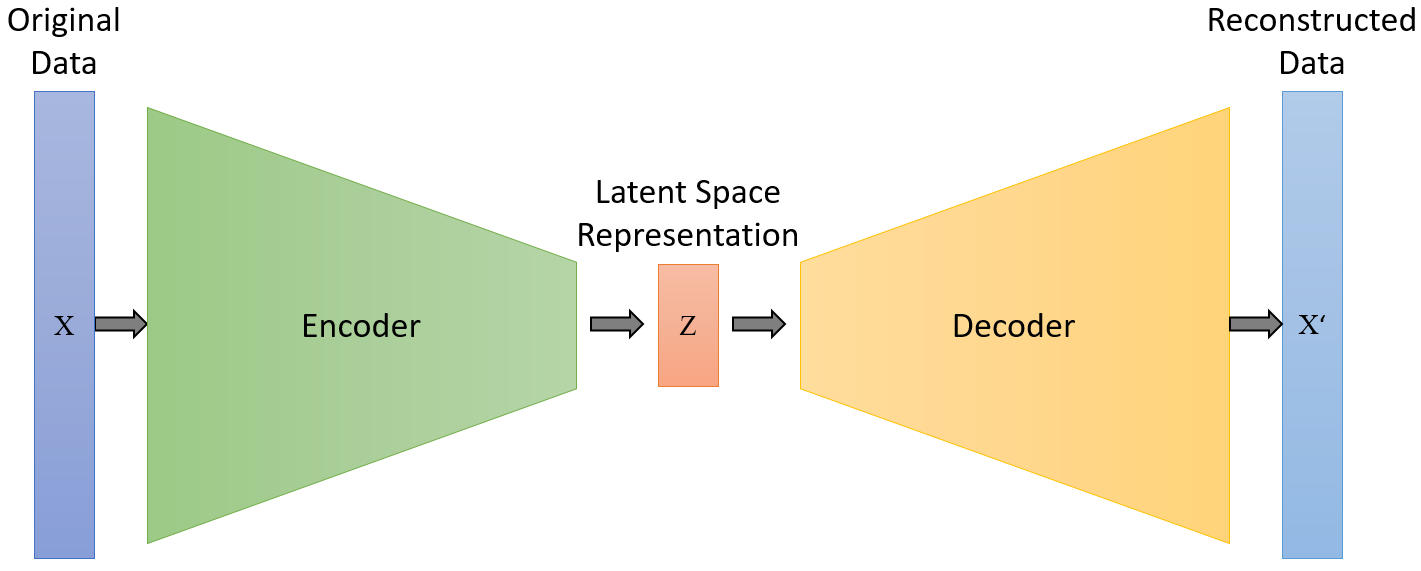
如上图所示,自编码器 (Autoencoder, AE) 的经典架构由三个核心部分组成:编码器 (Encoder) 将原始数据 X X X 压缩为低维的潜空间表示 (Latent Space Representation, Z Z Z),随后解码器 (Decoder) 尝试从这个压缩包中还原出重构数据 X ′ X' X′。其核心目标是让输出的 X ′ X' X′ 尽可能接近输入的 X X X。
虽然图中的普通 AE 擅长信息压缩,但在内容生成任务上存在一个致命缺陷:
- 潜空间的“破碎性”:在普通 AE 中,潜空间 Z Z Z 是离散且无序的。模型可能把“猫”映射到坐标 ( 1 , 1 ) (1, 1) (1,1),把“狗”映射到 ( 10 , 10 ) (10, 10) (10,10),但如果你随机采样中间的坐标 ( 5 , 5 ) (5, 5) (5,5),解码器往往会生成一些毫无意义的噪声,因为它从未学习过这两个点之间的区域。
- 缺乏生成能力:如果编码仅仅是“序号”或孤立的点,我们就无法通过在潜空间里“自由漫步”来生成具有连续语义的新图像(比如一张介于猫和狗之间的图)。
3.2 VAE 变分自编码器
变分自编码器 (VAE) 的出现就是为了解决这个问题。它不再将输入映射为一个固定的点,而是映射为一个概率分布(通常是高斯分布的均值和方差)。
核心改进: VAE 强制要求潜空间服从特定的分布(如标准正态分布)。这使得整个潜空间变得连续且平滑。这样一来,我们在潜空间中随意选取一个位置,解码器都能生成一张逻辑合理的图片,从而实现了从“单纯压缩”到“真正生成”的跨越。
变分自编码器(VAE)在经典的“编码器-解码器”架构基础上,通过概率建模实现了从信息压缩到内容生成。编码器不再将输入映射为单一的固定向量,而是输出潜在空间中正态分布的统计参数(即均值 μ \mu μ 和方差 σ \sigma σ)。为了解决随机采样过程不可导、无法进行反向传播的难题,VAE 引入了重参数化技巧(,将随机性转移到外部变量,从而确保梯度得以顺畅回传。
在优化目标上,VAE 的损失函数由两部分构成:一是重构损失,通过最小化输出与原图的均方误差(MSE)来保证图像质量;二是正则化项,利用 KL 散度 约束学习到的分布趋近于标准正态分布,从而确保潜在空间的连续性和平滑性,使模型具备真正的生成能力。
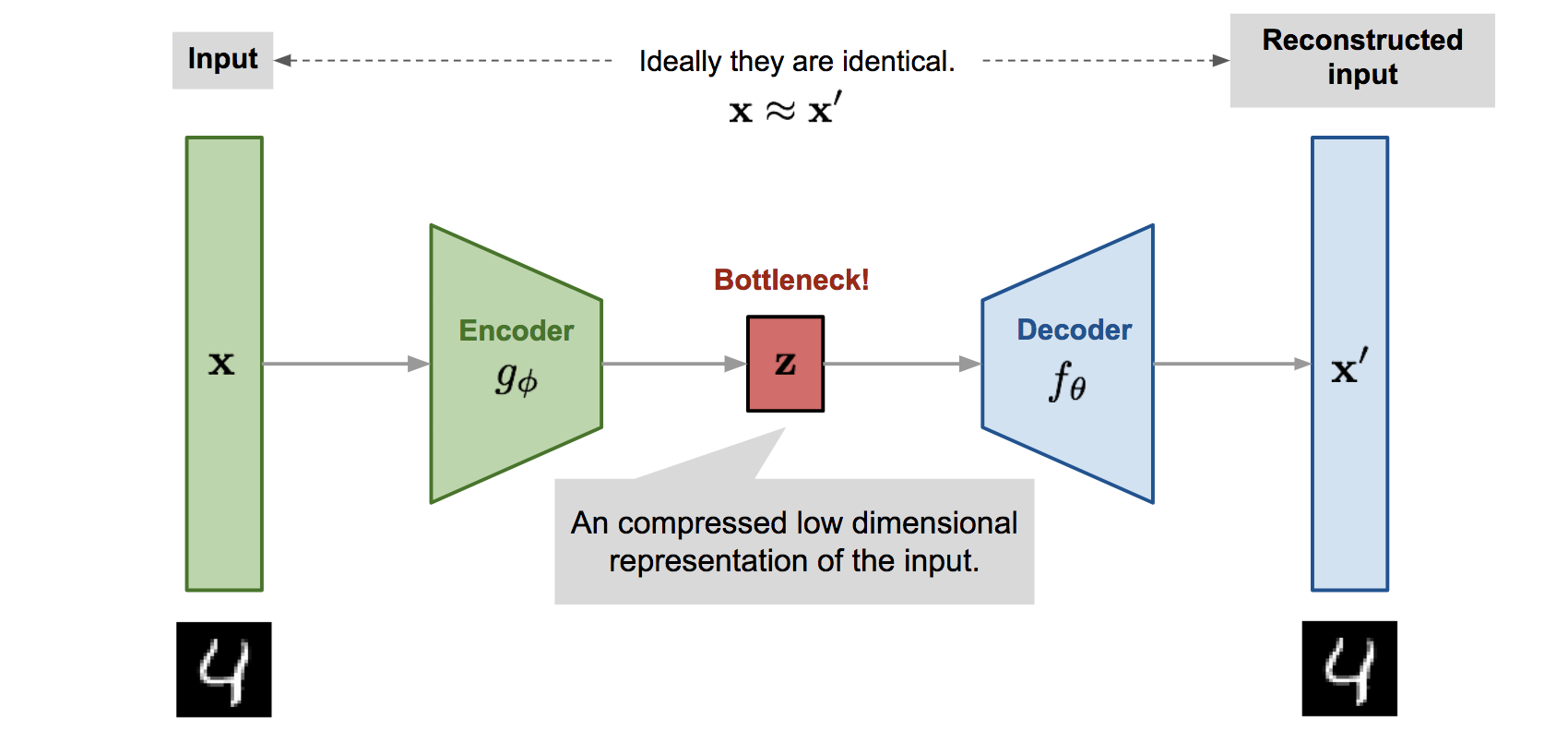
如上图所示,VAE 的具体运行流程可以概括为四个精步骤:
(1)编码分布 (Encoding)
输入图片 X X X 经过编码器神经网络,模型不再输出一个固定的数值,而是输出两个向量:均值 μ \mu μ 和 方差 σ \sigma σ。这两个参数共同定义了一个潜空间里的正态分布。
(2)重参数化采样 (Reparameterization Trick)
VAE 的核心:我们不能直接从编码器生成的分布里随机采样(因为随机过程不可导),所以引入一个外部的随机噪声 ϵ ∼ N ( 0 , 1 ) \epsilon \sim N(0, 1) ϵ∼N(0,1)。通过公式计算得到潜在编码 z z z: z = μ + σ ⊙ ϵ z = \mu + \sigma \odot \epsilon z=μ+σ⊙ϵ
这样随机性就被移到了 ϵ \epsilon ϵ 上,而梯度可以顺着 μ \mu μ 和 σ \sigma σ 正常回传进行训练。
(3)解码重构 (Decoding)
将采样得到的 z z z 送入解码器神经网络,尝试将其还原为原始尺寸的图片 X ′ X' X′。
(4)混合损失计算 (Total Loss)
训练目标由两部分组成,迫使模型在“画得像”和“有逻辑”之间寻找平衡:
- 重构损失 (Reconstruction Loss):计算 X X X 与 X ′ X' X′ 的差异(通常用 MSE),确保解码器能还原出原图。
- KL 散度 (KL Divergence):计算 ( μ , σ ) (\mu, \sigma) (μ,σ) 与标准正态分布 N ( 0 , 1 ) N(0, 1) N(0,1) 之间的距离。它强制潜空间变得连续且平滑,防止模型为了偷懒而把每张图映射成孤立的序号。
4 CLIP 文本编码器
在 Stable Diffusion (SD) 体系中,文本编码器 (Text Encoder) 充当了“翻译官”的角色。它的核心任务是将人类直观的提示词转换成计算机(尤其是 U-Net 或 Transformer 降噪网络)能够理解的高维数学向量。
4.1 核心模型:CLIP 与 T5
不同版本的 SD 采用了不同配置的编码器:
- SD 1.5:使用单一的 CLIP (ViT-L/14) 模型。它能理解基础的视觉概念,但在处理复杂逻辑和长难句时略显吃力。
- SDXL:为了提升理解力,同时使用了 两个 编码器(CLIP ViT-L 和 OpenCLIP-ViT/bigG),通过双重路径提取更丰富的语义特征。
- SD 3.5 / Flux:引入了 T5-XXL 大型语言模型作为第三个(或核心)编码器。T5 的加入显著增强了模型对复杂指令、长文本及拼写测试的遵循能力。
4.2.文本处理的步骤
如下图所示,文本编码器的工作流程通常分为以下四个环节:

第一步:分词 (Tokenization)
系统将你的提示词切分成一个个“符号”(Tokens)。例如,“a cat” 可能会被切分为 a 和 cat,并根据预设的字典转换成对应的数字索引。
注意:CLIP 通常有 77 个 Token 的长度限制,这也是为什么过长的提示词在旧模型中会被截断。
第二步:向量化 (Embedding)
每一个数字索引会被转换成一个连续的数值向量。这个阶段的向量还只是孤立的词义,没有考虑到语境(例如“苹果”在“苹果手机”和“吃苹果”中意义不同)。
第三步:上下文理解 (Transformer Layers)
向量进入 Transformer 块。通过“自注意力机制 (Self-Attention)”,模型会计算词与词之间的关系。例如,它能理解“红色的”是在修饰“气球”,从而生成带有上下文关联的隐藏状态 (Hidden States)。
第四步:输出与引导 (Conditioning)
最终生成的向量矩阵将作为“条件(Conditioning)”输入给降噪网络。
4.3 如何引导生成:交叉注意力 (Cross-Attention)
这是文本编码器与图像生成结合的关键点。在 U-Net 或 DiT 的每一层中,都会进行 交叉注意力计算:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
- Q (Query):来自图像特征(模型正在画的草图)。
- **K & V **:来自文本编码器输出的向量。
通过这个数学运算,图像的每一个像素点都会去询问提示词向量:“我这里应该画什么颜色?什么材质?” 从而实现文字对图像的精准调控。该视频详细对比了 SD 3.5 Large 的架构,特别是其文本编码器块如何处理提示词并影响最终生成质量。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)