深度学习之目标检测Faster RCNN模型算法流程详解说明(超详细理论篇,含R-CNN、Fast-RCNN 、Faster-RCNN 核心差异对比表)
Faster R-CNN “从论文背景到代码细节” 一次性讲透。先回顾 R-CNN → Fast R-CNN 的进化痛点:候选框外置、特征重复计算、训练分段。随后聚焦 Faster R-CNN 的“一箭三雕”——RPN 网络内生候选框、共享卷积特征、端到端多任务损失,彻底拔掉速度瓶颈。Faster R-CNN:用RPN网络内生候选框,共享卷积端到端训练,5步流程秒懂;精度和速度双升,却显存高、调参
1.Faster RCNN论文背景
2. Faster-RCNN算法流程
(1)RCNN、Fast-RCNN算法流程
(2)特征提取conv layers
(3)Region Proposal Networks(RPN)
(4)ROI Pooling作用
(5)Classification
3.Faster RCNN问题和优缺点
关于本篇更多可查看之前更详细部分文章
1.卷积神经网络CNN里经典网络模型之 AlexNet全网最详解(理论篇)
2.目标检测简介
3.深度学习之目标检测R-CNN模型算法流程详解说明(超详细理论篇)
4.深度学习之目标检测Fast-RCNN模型算法流程详解说明(超详细理论篇)
5.目标检测标注工具常用的三种:LabelImg、CVAT、Roboflow
6.卷积神经网络CNN进步史之分类领域小论文文章总结帮助初学者找文献
7.PASCAL VOC、ILSVRC和MS COCO三大竞赛简单介绍
8.PASCAL VOC、ILSVRC和MS COCO三大竞赛核心数据集版本总节
9.OC vs COCO vs YOLO格式终极对比:2025年目标检测项目到底该选哪个标注格式?避坑指南+决策树
10.Pascal VOC数据集划分的致命陷阱与最佳实践:为什么99%的开发者都该以JPEGImages图片文件夹为基准,而不是Annotations XML?
11.关于Fast R-CNN中提到“共享卷积计算”和“空间金字塔池化”这两个紧密相连、推动目标检测发展的核心概念——解决R-CNN致命问题的钥匙
12.关于Fast R-CNN 中全连接层双任务头的实现原理及与传统 FC8 的区别
13.关于R-CNN中Selective Search选择性搜索候选框原理+步骤+代码+参数详细说明
R-CNN、Fast-RCNN 、Faster-RCNN 核心差异对比表
| 对比维度 | R-CNN | Fast-RCNN | Faster-RCNN |
|---|---|---|---|
| 核心定位 | 目标检测开山之作,验证 CNN + 候选框可行性 | 优化 R-CNN 效率,提出共享卷积 + 多任务损失 | 彻底解决速度瓶颈,提出 RPN 实现端到端检测 |
| 候选区域生成方式 | 选择性搜索(Selective Search),独立于网络,速度慢 | 选择性搜索(Selective Search),独立于网络 | RPN(区域提议网络),与骨干网络共享特征,内生候选框 |
| 卷积特征提取逻辑 | 对每个候选框单独预处理、单独输入 CNN,无特征共享,重复计算严重 | 整张图输入 CNN,一次卷积生成特征图,所有候选框共享特征 | 整张图输入 CNN,一次卷积生成特征图,特征同时供给 RPN 和检测头,全程共享 |
| 关键特征对齐层 | 无(直接裁剪缩放候选框) | RoI Pooling,将候选框映射到特征图并归一化尺寸 | RoI Pooling,功能与 Fast-RCNN 一致,输入候选框来自 RPN |
| 分类与回归机制 | 分类:20 个独立二分类 SVM 回归:20 个独立线性回归器 无多任务联合 |
分类 + 回归双任务头,共享全连接层特征 多任务损失联合优化 |
分类 + 回归双任务头,结构与 Fast-RCNN 一致 候选框来自 RPN,与检测网络深度耦合 |
| 训练模式 | 三阶段独立训练: 1. CNN 微调 2. SVM 训练 3. 回归器训练 非端到端 |
端到端训练: 一次训练优化卷积层 + 全连接层 + 双任务头 候选框仍需离线生成 |
真正端到端训练: 联合优化骨干网络 + RPN + 检测头 候选框生成与检测一体化 |
| 效率瓶颈 | 候选框单独卷积,重复计算 + 硬盘缓存特征,速度极慢 | 候选框生成依赖选择性搜索,仍为速度瓶颈 | 无离线步骤,RPN 生成候选框速度远超选择性搜索,整体效率最高 |
| 存储开销 | 需缓存大量候选框特征向量,占用数百 GB 硬盘空间 | 无需缓存特征,仅需内存存储特征图,开销小 | 与 Fast-RCNN 相当,无额外存储负担 |
一、Faster RCNN论文背景
在目标检测领域,传统的方法通常分为两个阶段:生成候选区域和对这些区域进行分类。然而,这些方法的处理速度较慢,限制了实时应用的可能性。在此之前,有两个重要的工作推动了目标检测领域的发展。第一个是R-CNN(Region-based Convolutional Neural Networks)方法,它首次将卷积神经网络(CNN)应用于目标检测中。R-CNN通过在图像中提取固定大小的候选区域,然后对每个候选区域进行分类,从而实现目标检测。尽管R-CNN在准确性上表现出色,但其处理速度非常慢。第二个工作是SPP-net(Spatial Pyramid Pooling Network),它引入了空间金字塔池化层来提高处理速度,但其仍然需要在每个候选区域上运行CNN。
论文链接https://arxiv.org/pdf/1506.01497.pdf
“Faster R-CNN” 是一篇于2015年发布的论文,题为 “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”。该论文由Shaoqing Ren、Kaiming He、Ross Girshick和Jian Sun等人共同撰写,发表在IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI)期刊上。
该论文提出了一个包含共享卷积层和RPN的网络结构。共享卷积层用于提取图像的特征表示,RPN则通过滑动窗口在特征图上生成候选区域,并预测每个窗口是否包含目标以及目标的边界框。生成的候选区域经过候选区域池化层提取特征向量,并输入到后续的分类器进行目标分类。
“Faster R-CNN” 的创新点在于将候选区域生成和目标分类集成到一个网络中,实现了端到端的目标检测,并取得了较高的准确性和较快的处理速度。
二、Faster-RCNN算法流程
1–1.RCNN算法流程4个步骤:
- R-CNN 的流程呈 “串行化、独立化”,分为 3 个互不关联的阶段,无端到端训练能力。
-
步骤1:候选区域生成(Selective Search)
对单张输入图像,使用选择性搜索生成约2000个候选区域(Region Proposals, RPs),输出每个候选框的坐标(x1,y1,x2,y2)。 -
步骤2:CNN特征提取(独立提取,重复计算)
① 对每个候选区域单独预处理:裁剪→缩放为227×227→减均值→归一化
② 将每个预处理后的候选区域单独输入微调后的CNN(如AlexNet)
③ 提取每个候选区域的FC7层4096维特征向量,缓存所有特征(硬盘存储,占用大量空间)
(注:每个候选区域都要完整走一遍CNN,无特征共享,重复计算严重) -
步骤3:独立分类与边界框回归
① 分类:将缓存的4096维特征输入独立训练的20个二分类SVM,输出类别置信度,筛选高置信度候选框
② 回归:将筛选后的候选框特征输入独立训练的20个线性回归器,修正边界框坐标
③ 后处理:NMS(非极大值抑制)去重,得到最终检测结果 -
步骤4:训练流程(三阶段独立训练)
① 阶段1:CNN微调(修改预训练CNN最后一层为21类softmax,在检测数据集上微调)
② 阶段2:SVM训练(用CNN提取的特征,按严格样本标准训练独立SVM)
③ 阶段3:回归器训练(用CNN提取的特征,训练独立线性回归器)
-
1-2.Fast-RCNN算法流程:
- Fast R-CNN 的核心创新是 “共享卷积特征 + RoI Pooling + 多任务损失”,流程更简洁,效率大幅提升,支持端到端训练。
-
步骤1:候选区域生成(仍沿用Selective Search)
对单张输入图像,使用选择性搜索生成约2000个候选区域,输出每个候选框的坐标(x1,y1,x2,y2)。 -
步骤2:共享卷积特征提取(仅一次卷积,无重复计算)
① 将整张输入图像直接输入CNN(如AlexNet/VGG16),进行一次完整的卷积层计算,得到整张图像的卷积特征图(Feature Map)
② 无需对每个候选区域单独处理,大幅减少计算量(这是与R-CNN最核心的效率差异) -
步骤3:RoI Pooling(核心创新,对齐特征与候选区域)
① 将步骤1生成的每个候选区域坐标,映射到卷积特征图上(根据卷积层的步长、填充等参数,缩小候选框尺寸)
② 对每个映射后的候选区域(RoI,感兴趣区域),使用RoI Pooling将其归一化为固定尺寸(如7×7,适配后续全连接层)
③ 输出每个RoI的固定尺寸特征图,为后续全连接层提供统一输入 -
步骤4:多任务联合分类与回归(整合进网络,端到端)
① 将每个RoI的固定尺寸特征图输入全连接层(FC6→FC7),输出4096维特征向量
② 全连接层分支为两个任务头(共享FC7特征):- 分类分支:FC8输出K+1类(K个目标类+1个背景类),经softmax激活,输出类别概率分布
- 回归分支:FC8输出4×(K+1)维偏移量(每个类别对应4个边界框偏移量dx,dy,dw,dh),无需独立训练回归器
-
③ 后处理:根据分类概率筛选高置信度候选框,用对应类别的偏移量修正边界框,再经NMS去重,得到最终检测结果
-
步骤5:训练流程(端到端多任务训练)
① 初始化:用ImageNet预训练CNN初始化网络参数
② 网络修改:插入RoI Pooling层,添加分类+回归双任务头,定义多任务损失函数(分类交叉熵损失+平滑L1回归损失)
③ 端到端训练:用SGD优化整个网络(卷积层+全连接层+双任务头),一次训练完成分类与回归任务,无需独立训练多个模块
-
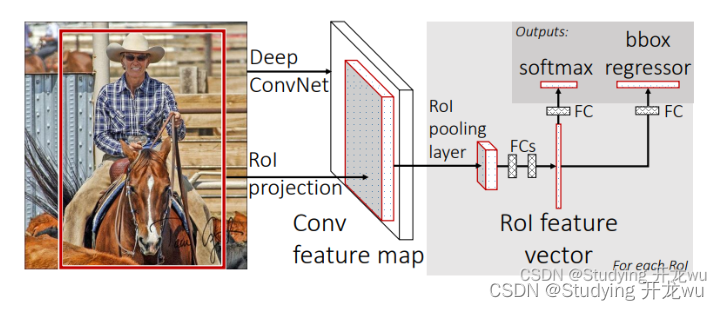
2.Faster-RCNN算法流程:
- Faster R-CNN 的核心创新是 “RPN(区域提议网络)替代 Selective Search + 端到端共享特征 + 统一多任务训练”,彻底解决候选区域生成的速度瓶颈,实现真正意义上的端到端目标检测,流程分为 5 个核心步骤,训练与推理高度整合。
- 步骤 1:共享卷积特征提取(Backbone)
- 输入单张图像,直接送入预训练深度 CNN 骨干网络(如 VGG16、ResNet),完成一次完整卷积计算,输出整张图像的卷积特征图(Feature Map)。
- 该特征图同时供给后续 RPN 网络和 RoI Pooling 层,全程特征共享,无重复计算,大幅提升效率(相比 R-CNN/Fast R-CNN,这是关键优化之一)。
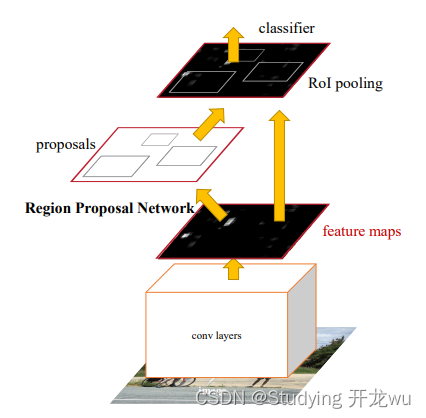
- 步骤 2:RPN 生成候选区域(替代 Selective Search,网络内生候选框)
- RPN 是全卷积网络,与骨干网络共享特征图,自动生成高质量候选框,流程如下:
- 锚框(Anchor)生成:在特征图每个空间位置,生成 9 个预设锚框(3 种尺度 ×3 种宽高比),覆盖多尺度、多形态目标,单张图约生成 20k 个锚框。
- 特征映射与双分支预测:
- 用 3×3 卷积对特征图滑动卷积,提取每个锚框对应的 256 维(或 512 维)特征向量。
- 分支 1(二分类): 1×1 卷积输出 2k 维(k=9)前景 / 背景置信度,判断锚框是否包含目标。
- 分支 2(边界框回归): 1×1 卷积输出 4k 维偏移量,修正锚框坐标,使其更贴近真实目标。
- 候选框筛选与后处理:
- 依据回归偏移量修正锚框,裁剪超出图像边界的无效锚框。
- 按前景置信度排序,取前 12000 个锚框,经 NMS(IoU 阈值 0.7)去重。
- 最终保留 2000 个高置信度候选框(RoI,感兴趣区域),输出坐标 (x1,y1,x2,y2)。
- RPN 是全卷积网络,与骨干网络共享特征图,自动生成高质量候选框,流程如下:
- 步骤 3:RoI Pooling(特征对齐,统一尺寸)
- 将步骤 2 生成的 2000 个 RoI 坐标,映射到步骤 1 的卷积特征图上 (根据骨干网络步长计算映射关系)。
- 对每个映射后的 RoI 区域,用 RoI Pooling 将其池化为固定尺寸(如 7×7)的特征图,消除 RoI 尺寸差异,为后续全连接层提供统一输入。
- 输出每个 RoI 的 7×7 固定尺寸特征图,进入全连接层处理。
- 步骤 4:多任务联合分类与精细边界框回归
- 全连接层映射: 将 7×7 特征图展平,经 FC6→FC7 全连接层,输出 4096 维特征向量。
- 双任务头并行计算(共享 FC7 特征):
- 分类分支:FC8 输出 K+1 类(K 个目标类 + 1 个背景类)概率分布,经 softmax 激活,输出类别置信度。
- 回归分支:FC8 输出 4×(K+1) 维边界框偏移量(dx,dy,dw,dh),对每个类别对应的候选框进行精细坐标修正。
- 最终后处理:按类别置信度筛选高置信度框,用对应偏移量修正坐标,再经 NMS 去重,得到最终检测结果。
- 步骤 5:端到端联合训练(四步迭代,统一优化)
- 初始化:用 ImageNet 预训练骨干网络参数,初始化 RPN 和检测头参数。
- 阶段 1:单独训练 RPN(冻结骨干网络,仅优化 RPN 的 3×3 卷积与双分支 1×1 卷积,用二分类交叉熵损失 + 平滑 L1 回归损失)。
- 阶段 2:用阶段 1 的 RPN 生成候选框,训练 Fast R-CNN 检测头(冻结骨干网络,优化全连接层与双任务头,用多任务损失训练)。
- 阶段 3:共享骨干网络特征,联合微调 RPN 与 Fast R-CNN(解冻骨干网络,用 SGD 同时优化骨干网络、RPN、检测头,统一最小化多任务损失,实现端到端训练)。
- 阶段 4:可选微调(针对特定数据集,调整学习率进一步提升精度)。
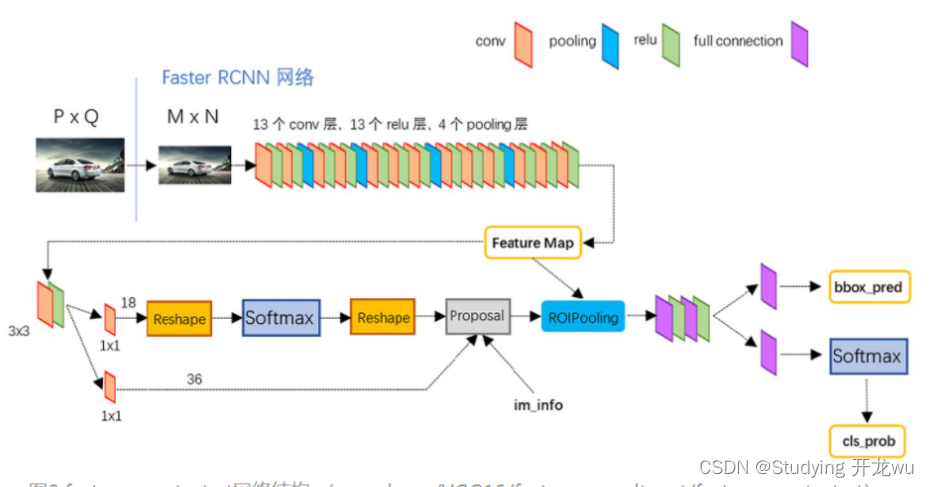
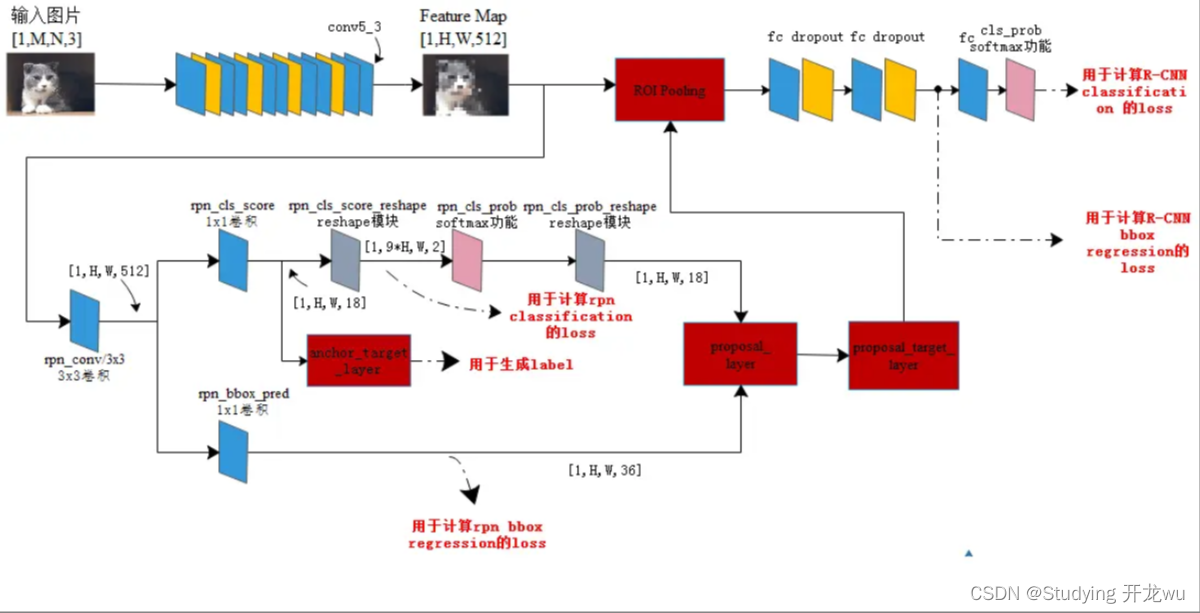
- 步骤 1:共享卷积特征提取(Backbone)
三个图同时参考好思考更多细节部分,每一个步骤展开说明
3.特征提取conv layers
Conv layers包含了conv,pooling,relu三种层。以VGG16模型中的faster_rcnn_test.pt的网络结构为例上图,有13个conv层,13个relu层,4个pooling层。还可以用ResNet、Inception等。
conv层都是:kernel_size=3,pad=1,stride=1
pooling层都是:kernel_size=2,pad=0,stride=2
经过每个conv层后,feature map大小都不变;经过每个pooling层后,feature map的宽高变为之前的一半
4.Region Proposal Networks(RPN)
提取前景(本文称为提取proposal)的方法是Selective Search,简称SS法,通过比较相邻区域的相似度来把相似的区域合并到一起,反复这个过程,最终就得到目标区域,这种方法相当耗时以至于提取proposal的过程比分类的过程还要慢,完全达不到实时的目的。而Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度,把提取proposal的过程也通过网络训练来完成,部分网络还可以和分类过程共用,新的方法称为Reginal Proposal Network(RPN),速度大大提升。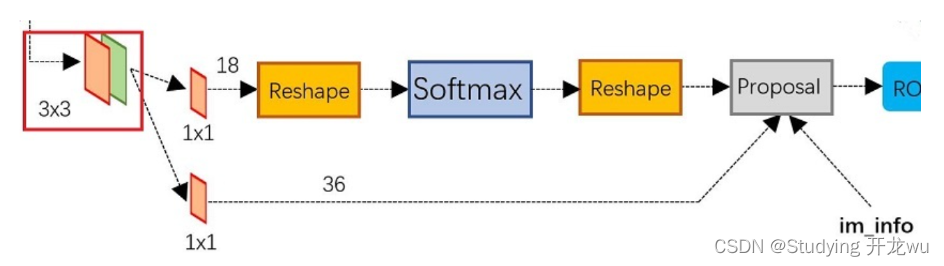
RPN网络结构:
生成anchors -> softmax分类器提取positvie anchors -> bbox reg回归positive anchors -> Proposal Layer生成proposals
RPN作用:
(1)把feature map分割成多个小区域,识别出哪些小区域是前景,哪些是背景,简称RPN Classification.
(2)获取前景区域的大致坐标,简称RPN bounding box regression。
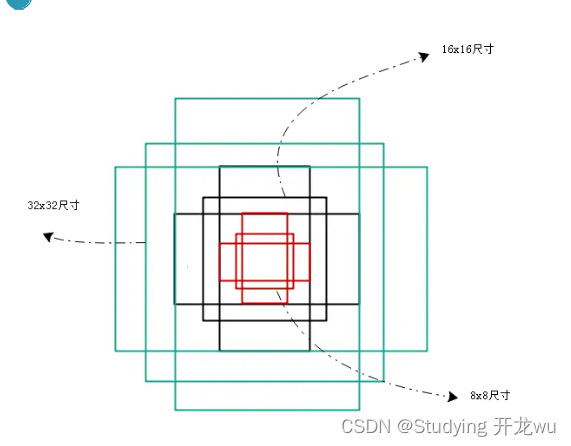
anchors:
anchors是一组预定义的矩形,论文中设置了3种形状,3种比例,一共9个预定义的anchors。 需要注意anchors是针对哪个图像设置的!这样做获得检测框很不准确,但是后面还有2次bounding box regression修正检测框位置。Fast R-CNN以及SPP-net使用的BBR的输入是从任意大小的RoI上池化得到的(RoI pooling),同时回归权重在所有RoI上共享,而Faster R-CNN使用的BBR的输入是固定大小的3 x 3 RoI(3 x 3 convolution),同时不同尺度和长宽比的anchor使用不同的回归器,k个回归器之间并不共享权重。
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
anchors其中每行的4个值 表矩形左上和右下角点坐标。9个矩形共有3种形状,长宽比为大约为 三种
- 特征图上每个像素都对应了k个anchors,会产生大量anchors,在实际训练RPN时,程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练。
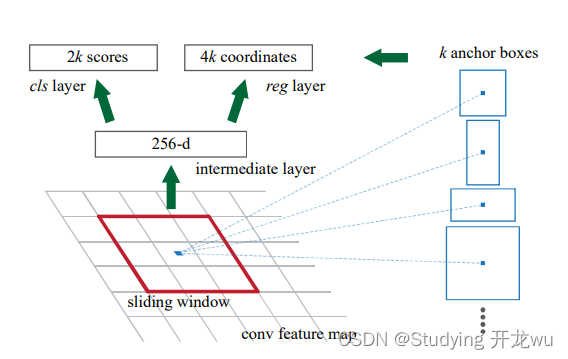
(1)在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions
(2)在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息
(3)假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分positive和negative,所以每个点由256d feature转化为cls=2•k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4•k coordinates
RPN Classification:这是个二分类的过程。先要在feature map上均匀的划分出KxHxW个区域(称为anchor,默认K=9,H是feature map的高度,W是宽度),通过比较这些anchor和ground truth间的重叠情况来决定哪些anchor是前景,哪些是背景,也就是给每一个anchor都打上前景或背景的label。 有了labels,你就可以对RPN进行训练使它对任意输入都具备识别前景、背景的能力。
RPN bounding box regression:用于得出前景的大致位置,要注意这个位置并不精确,准确位置的提取在后面的Proposal Layer bounding box regression。
RPN训练时要把RPN classification和RPN bounding box regression的loss加到一起来实现联合训练。
如图9所示,绿色框为飞机的Ground Truth(GT),红色为提取的positive anchors,即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得positive anchors和GT更加接近。
- Proposal Layer顺序依次处理:
- (1)生成anchors,利用【dx dy dw dh】对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
- (2)按照输入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的positive anchors
- (3)限定超出图像边界的positive anchors为图像边界,防止后续roi pooling时proposal超出图像边界(见文章底部QA部分图21)
- (4)剔除尺寸非常小的positive anchors
- (5)对剩余的positive anchors进行NMS(nonmaximum suppression)
- (6)Proposal Layer有3个输入:positive和negative anchors分类器结果rpn_cls_prob_reshape,对应的bbox reg的(e.g. 300)结果作为proposal输出[x1, y1, x2, y2]。
5.ROI Pooling作用
- 1、从feature maps中“抠出”proposals(大小、位置由RPN生成)区域;
- 2、把“抠出”的区域pooling成固定长度的输出
- (1)由于proposals坐标是基于MxN尺度的,先映射回(M/16)x(N/16)尺度
- (2)再将每个proposal对应的feature map区域分为pooled_w x pooled_h的网格
- (3)对网格的每一部分做max pooling
- (4)这样处理后,即使大小不同的proposal输出结果都是pooled_w x pooled_h固定大小,实现了固定长度输出,
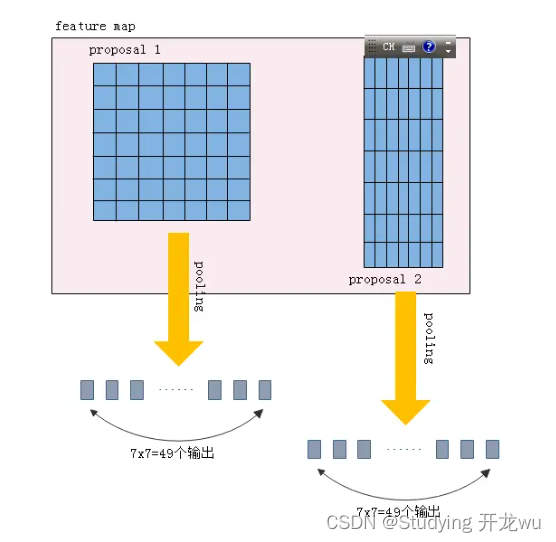
feature map中有两个不同尺寸的proposals,但pooling后都是7x7=49个输出,这样就能为后面的全连接层提供固定长度的输入。RPN网络提取出的proposal大小是会变化的,而分类用的全连接层输入必须固定长度,所以必须有个从可变尺寸变换成固定尺寸输入的过程。在较早的R-CNN和Fast R-CNN结构中都通过对proposal进行拉升(warp)或裁减(crop)到固定尺寸来实现,拉升、裁减的副作用就是原始的输入发生变形或信息量丢失,以致分类不准确。而ROI Pooling就完全规避掉了这个问题,proposal能完整的pooling成全连接的输入,而且没有变形,长度也固定。
6.Classification
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。RPN中只是二分类,区分目标还是背景;这里的分类是要对之前的所有positive anchors识别其具体属于哪一类。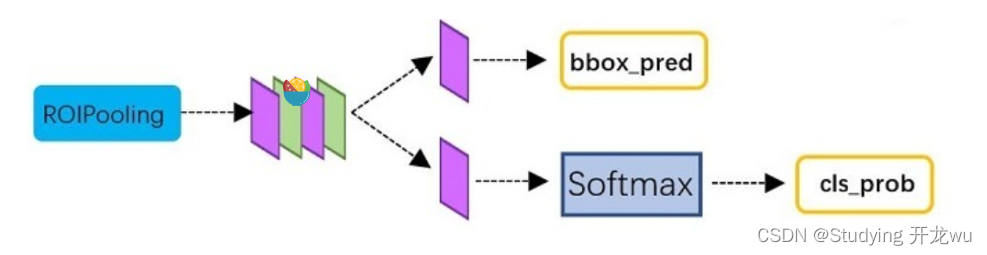
(1)通过全连接层和softmax对所有proposals进行具体类别的分类(通常为多分类)
(2)再次对proposals进行bounding box regression,获取更高精度的最终的predicted box
三、Faster RCNN问题和优缺点
1.问题:
(1)计算复杂度较高:相对于传统的目标检测方法,“Faster R-CNN” 的计算复杂度更高。由于需要进行区域生成网络(RPN)的预测和候选区域的分类,整个网络的计算成本较大。
(2)训练和调参困难:“Faster R-CNN” 模型的训练和调参需要一定的技术和计算资源。要获得最佳的检测性能,需要仔细调整网络的超参数和训练策略。
2.优点:
(1)端到端目标检测:与传统的两阶段目标检测方法相比,“Faster R-CNN” 提供了一个端到端的目标检测框架。通过引入区域生成网络(RPN),候选区域的生成和目标分类可以在同一个网络中进行,使得整个目标检测过程更加简洁和高效。
(2)较高的准确性:“Faster R-CNN” 在目标检测任务中表现出较高的准确性。通过利用深度卷积神经网络(CNN)进行特征提取和候选区域分类,可以获得更准确的目标定位和分类结果。
(3)实时性能改进:相较于传统的方法,“Faster R-CNN” 在实时目标检测方面取得了显著的改进。引入区域生成网络(RPN)的设计使得整个检测过程更加高效,从而实现了更快的检测速度。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 8
8 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)