【序列晋升】32 Spring Cloud Data Flow 数据流编排的云原生解决方案
Spring Cloud Data Flow(SCDF)是一个用于构建、部署和管理数据流应用的开源框架,它简化了数据管道的开发与运维,使开发人员能够专注于业务逻辑而非底层基础设施细节。SCDF基于Spring Boot和Spring Cloud生态系统构建,支持流式处理和批处理任务的统一编排,为现代云原生环境提供了灵活的数据流管理工具。
目录
Spring Cloud Data Flow(SCDF)是一个用于构建、部署和管理数据流应用的开源框架,它简化了数据管道的开发与运维,使开发人员能够专注于业务逻辑而非底层基础设施细节。SCDF基于Spring Boot和Spring Cloud生态系统构建,支持流式处理和批处理任务的统一编排,为现代云原生环境提供了灵活的数据流管理工具。作为Spring XD的云原生重构版本,SCDF解决了XD在容器化和云环境部署中的局限性,通过模块化架构和微服务设计理念,实现了数据流编排的轻量化与高可用性。本文将深入探讨SCDF的核心概念、架构设计、关键特性及使用方法,帮助技术开发人员全面了解这一数据流编排工具。

一、什么是Spring Cloud Data Flow?
Spring Cloud Data Flow是一个开源工具,用于定义、部署和管理数据流应用程序 。它构建在Spring Boot和Spring Cloud之上,提供了一套统一的编程模型来处理流式和批处理数据。SCDF的核心理念是简化数据管道的开发和运维,使开发人员能够专注于业务逻辑本身,而不是底层基础设施的搭建与维护。
SCDF主要面向以下两类应用场景:
- 流式处理(Stream):处理持续流动的数据,如实时日志分析、事件流处理等。
- 批处理任务(Task):处理有限数据集,如定时数据同步、ETL作业等 。
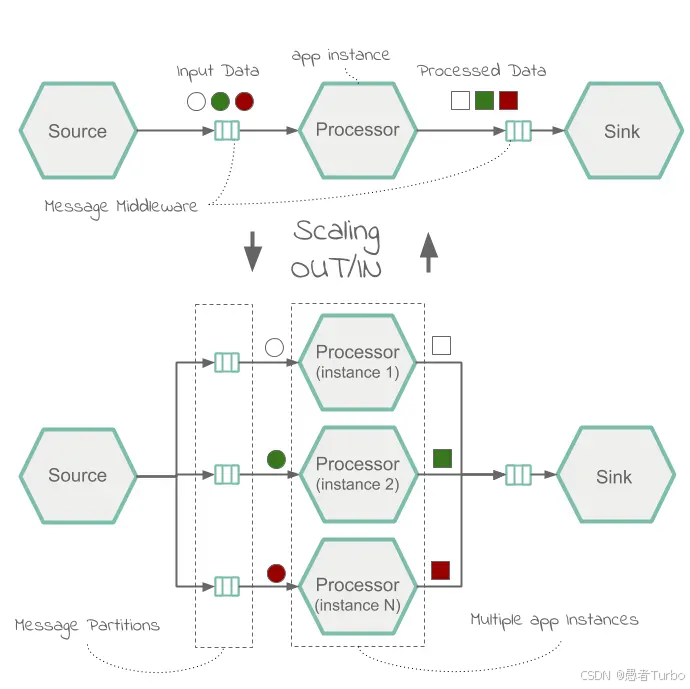
SCDF本身不处理数据,而是通过Spring Cloud Deployer将应用部署到目标平台(如Kubernetes、Cloud Foundry等),依赖消息中间件(如Kafka、RabbitMQ)和处理引擎(如Spark、Flink)来执行实际的数据处理操作。这种设计使得SCDF成为一个轻量级的编排框架,而非重型的数据处理引擎。
二、诞生背景与演进历程
2.1 Spring XD的起源
Spring XD(eXtreme Data)是SCDF的前身,最初由Pivotal公司于2016年左右推出。XD的核心是模块化数据流处理,支持消息中间件(如Kafka)和批处理框架(如Spark)的集成。它采用单节点和分布式两种运行模式,通过命令行界面(CLI)进行管理,允许用户创建数据管道并将其部署到物理服务器或虚拟机上 。
2.2 Spring XD的云原生局限性
尽管Spring XD在数据流处理方面表现出色,但它在云原生环境(如Kubernetes)中面临以下主要挑战:
- 部署复杂性:XD依赖物理服务器部署,如内嵌ZooKeeper服务器,难以实现容器化部署。
- 平台耦合性:XD的底层运行时与特定环境紧密耦合,缺乏对现代云平台的原生支持。
- 扩展性不足:XD的扩展方式不够灵活,难以适应云环境的动态资源分配需求。
- 维护成本高:随着XD的迭代,维护和升级成本增加,社区活跃度逐渐下降。
2.3 SCDF的诞生与演进
为解决Spring XD在云原生环境中的不足,Spring团队于2018年左右开始重构XD,最终推出了Spring Cloud Data Flow。SCDF的核心改进包括:
| 改进维度 | Spring XD | Spring Cloud Data Flow |
|---|---|---|
| 部署模式 | 物理服务器/虚拟机 | 支持Kubernetes、Cloud Foundry等云平台 |
| 架构设计 | 单体式架构 | 微服务架构,分离Server、Stream/Task模型和部署引擎 |
| 语言支持 | 主要基于Java | 支持多语言应用(Spring Boot/Shell脚本等) |
| 配置管理 | 手动配置文件管理 | 集成Spring Cloud Config,支持动态配置 |
| 监控系统 | 基本日志监控 | 集成Prometheus、Grafana等可视化监控系统 |

SCDF继承了XD的模块化思想(源/处理器/接收器),但采用Spring Boot/Spring Cloud原生云架构,通过Spring Cloud Deployer实现跨平台部署,彻底解决了XD的云原生兼容性问题。从版本迭代来看,SCDF经历了从2.0到2.11的多次升级,逐步增强了对现代云平台和工具的支持。
三、架构设计与核心组件
3.1 分层架构设计
SCDF采用分层架构设计,主要包含以下层级:
部署层:负责在不同环境(本地、云平台、Kubernetes等)部署数据流应用,通过Spring Cloud Deployer抽象不同平台的部署细节。
核心层:包含数据流的定义、部署和监控的核心逻辑,是SCDF的核心功能实现层。
应用层:由Spring Cloud Stream应用(流式处理)和Spring Cloud Task应用(批处理)组成,这些应用负责实际的数据处理工作。
集成层:与外部系统(如消息中间件、数据存储、监控系统)的集成,提供丰富的连接器和适配器。
3.2 核心组件详解
SCDF的核心组件包括:
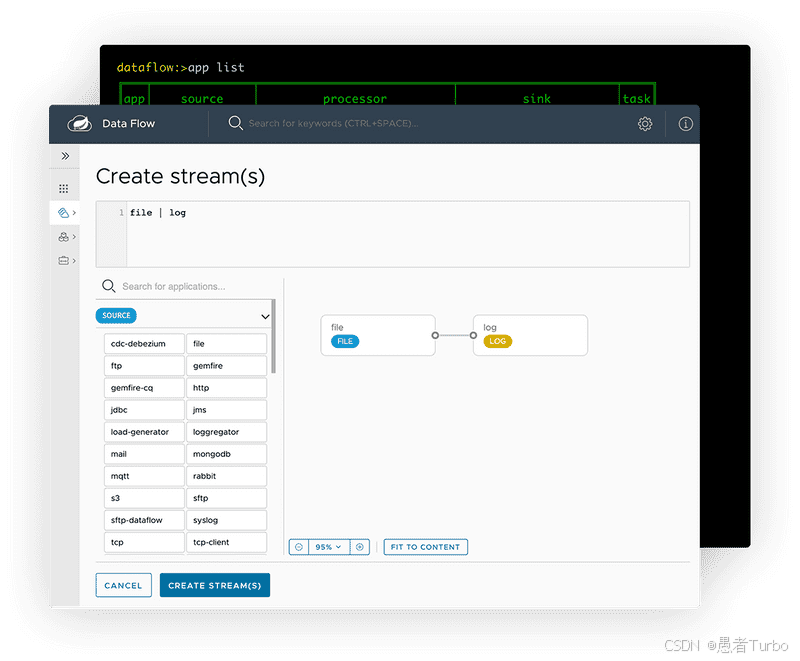
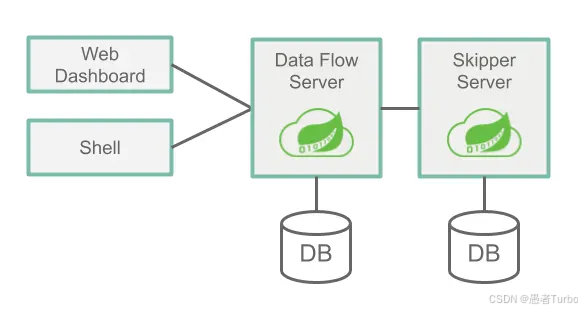
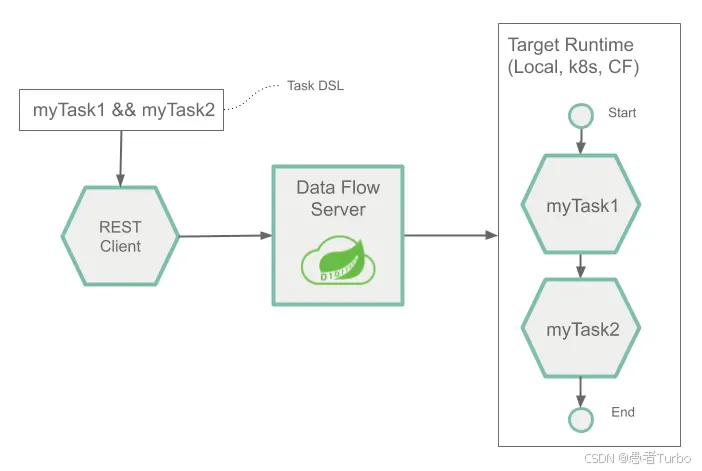
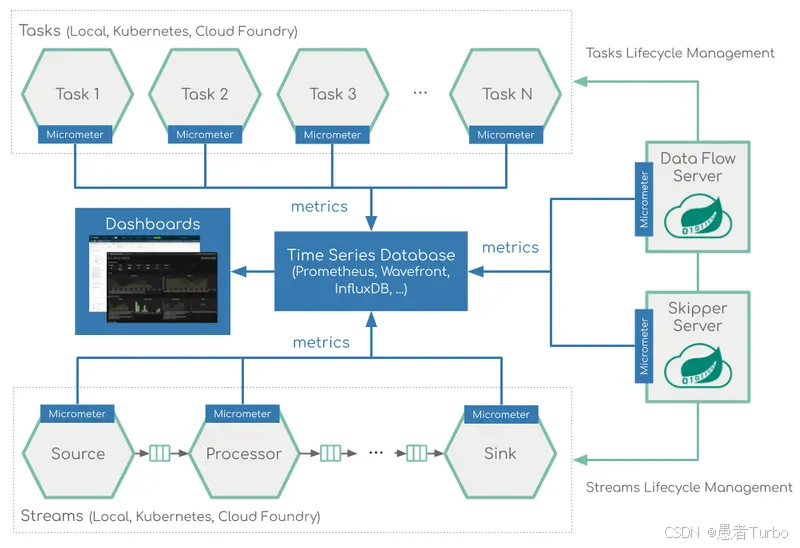
Spring Cloud Data Flow Server:核心服务器,负责管理数据流的生命周期。Server提供REST API,允许用户通过命令行、Dashboard或编程方式与SCDF交互。
Spring Cloud Stream:用于构建消息驱动的微服务应用,处理流式数据。Stream应用通过绑定消息通道(如Kafka topic)实现组件间通信。
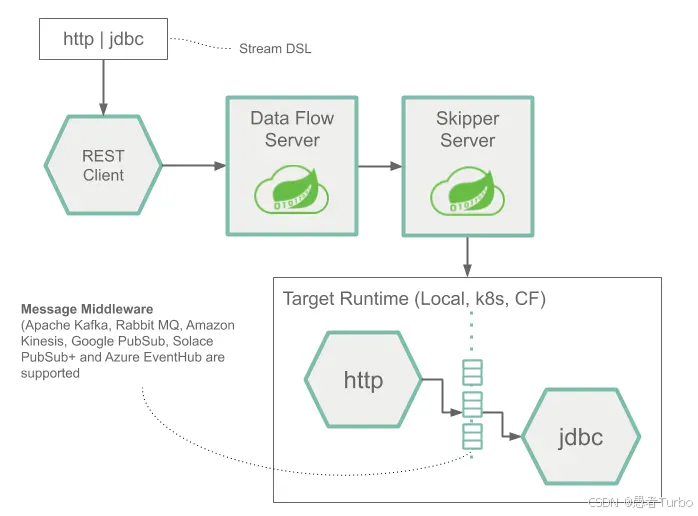
Spring Cloud Task:用于构建短期运行的批处理任务,处理有限数据集。Task应用通常执行一次性作业(如数据同步、报表生成)。
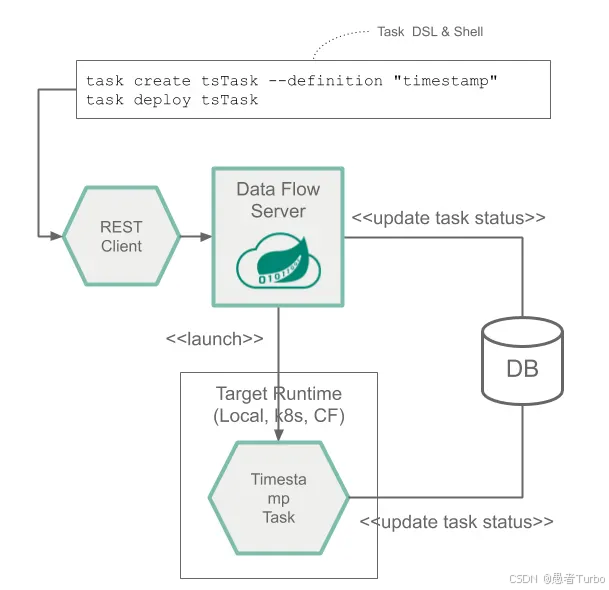
Spring Cloud Skipper:负责应用的升级和回滚,支持蓝绿部署和金丝雀发布。Skipper是SCDF的部署管理组件,通过REST API与Server协同工作。
Dashboard:Web界面,提供图形化方式设计和管理数据流。Dashboard支持拖拽式组件配置,简化了数据流的创建和维护过程。
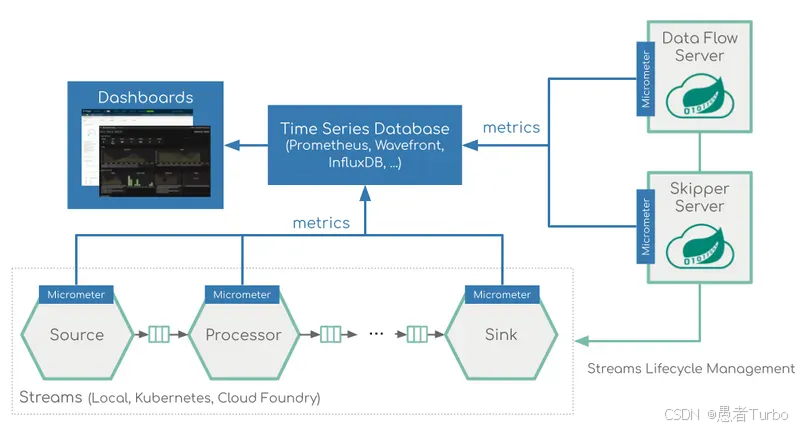
应用注册表:存储可用Stream和Task应用的元数据,包括应用名称、类型(source/processor/sink/task)、部署属性等。
3.3 Server内部模块
SCDF Server的核心模块包括:
应用注册管理:负责应用的注册、存储和检索,确保用户能够轻松访问和组合数据流组件。
流定义解析器:解析用户提供的流定义(通过DSL或Dashboard),验证语法和语义正确性,生成内部表示。
部署协调器:与Spring Cloud Deployer和Skipper交互,协调应用的部署、升级和回滚操作。
任务调度器:管理批处理任务的执行,支持手动触发、定时调度和事件驱动触发。
监控集成:整合Spring Boot Actuator、Prometheus、Grafana等监控系统,提供数据流应用的运行状态和性能指标。
REST API:提供标准的REST接口,允许与其他系统集成或通过编程方式管理SCDF。
四、解决的问题与核心价值
4.1 解决的核心问题
SCDF主要解决以下数据流处理中的复杂问题:
数据管道管理复杂性:传统数据管道需要手动配置和部署多个组件,SCDF通过统一的编排工具简化了这一过程。
多平台兼容性:XD在云原生环境中的部署局限性被SCDF彻底解决,支持Kubernetes、Cloud Foundry等多种现代运行环境。
开发效率低下:提供DSL、Dashboard和REST API等多种方式定义数据流,降低了开发和维护的复杂度。
应用生命周期管理困难:通过应用注册表和Skipper实现版本控制、升级回滚,简化了应用的管理流程。
监控与可观测性不足:整合Prometheus、Grafana等工具,提供实时指标与日志追踪,增强了系统的监控能力。
4.2 核心价值主张
SCDF的核心价值在于:
统一的数据流编排平台:提供一致的界面和API来管理流式和批处理应用,减少开发人员的学习和使用成本。
云原生友好性:与Docker、Kubernetes等容器技术深度集成,支持弹性伸缩和动态部署,适应现代云环境的需求。
微服务架构:将数据处理拆分为独立的、可组合的微服务,每个组件专注于单一功能,提高了系统的可维护性和可扩展性。
低代码/无代码开发:通过Dashboard的拖拽式界面,非开发人员也能参与数据流的设计和配置,降低了技术门槛。
与Spring生态无缝集成:作为Spring生态系统的一部分,SCDF与Spring Boot、Spring Cloud等组件紧密集成,充分发挥了Spring生态的优势。
五、关键特性与优势
5.1 核心特性
SCDF的关键特性包括:
流式处理支持:通过Spring Cloud Stream构建实时数据管道,支持消息中间件(如Kafka、RabbitMQ)的集成和动态绑定。
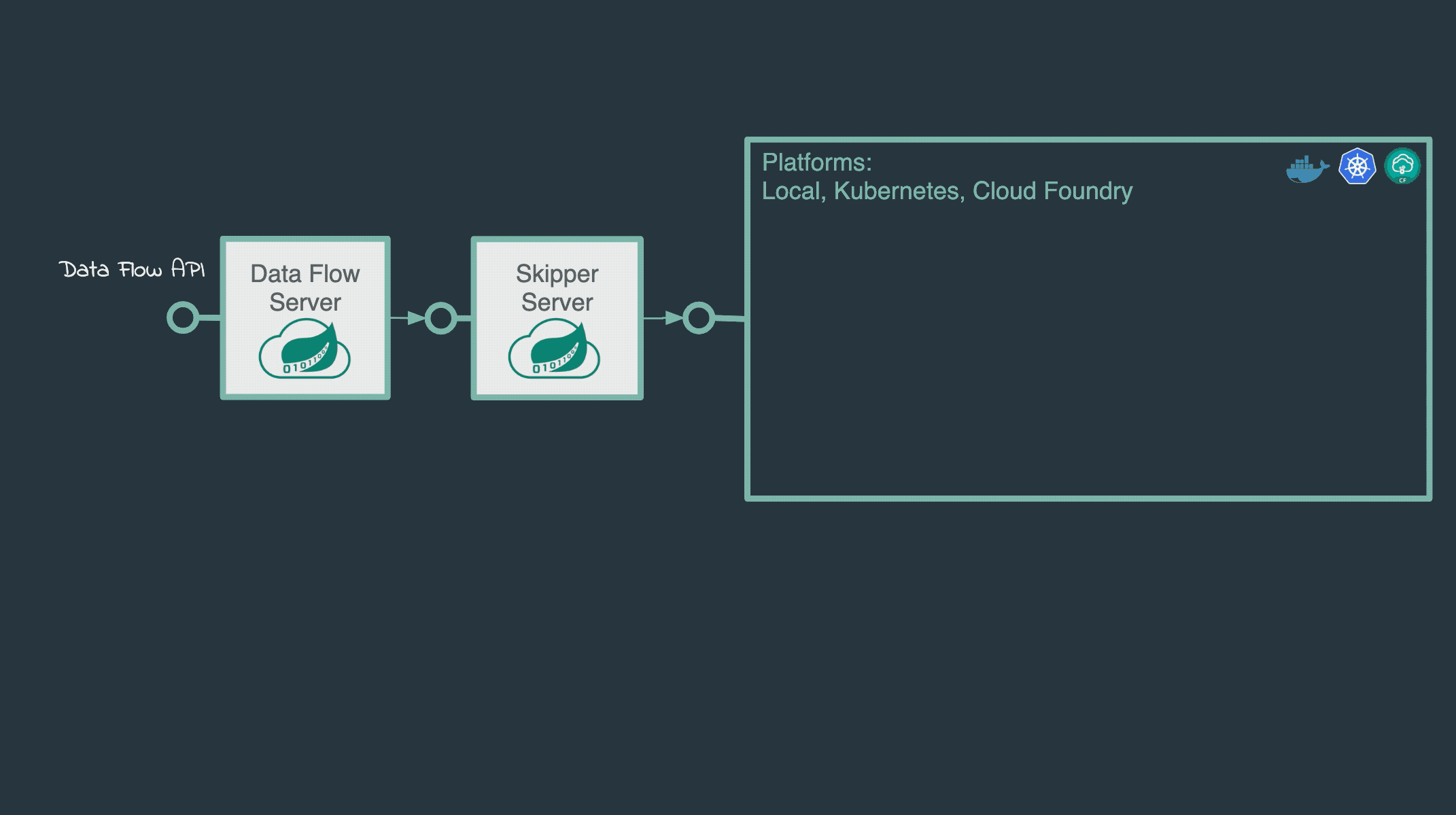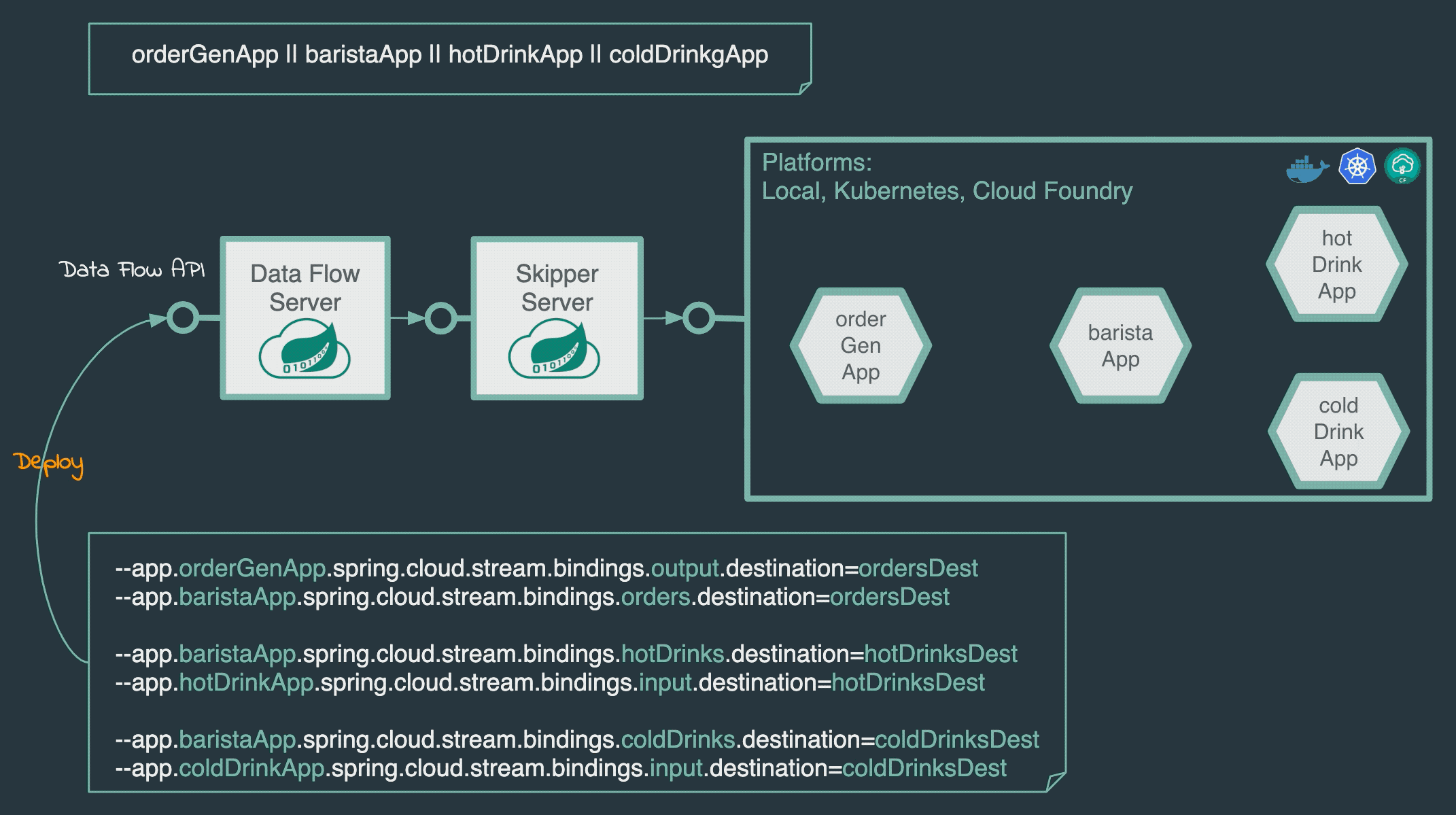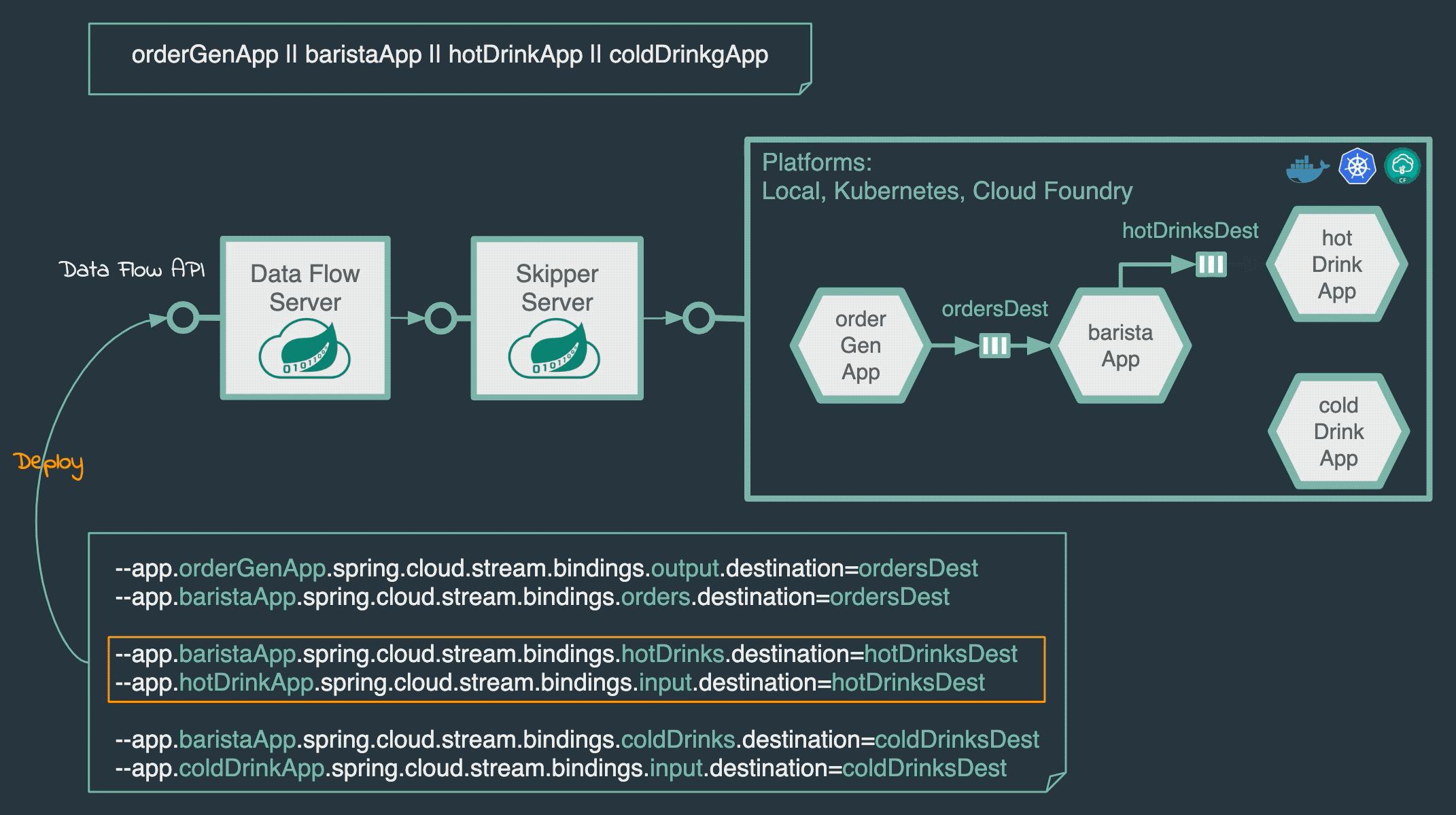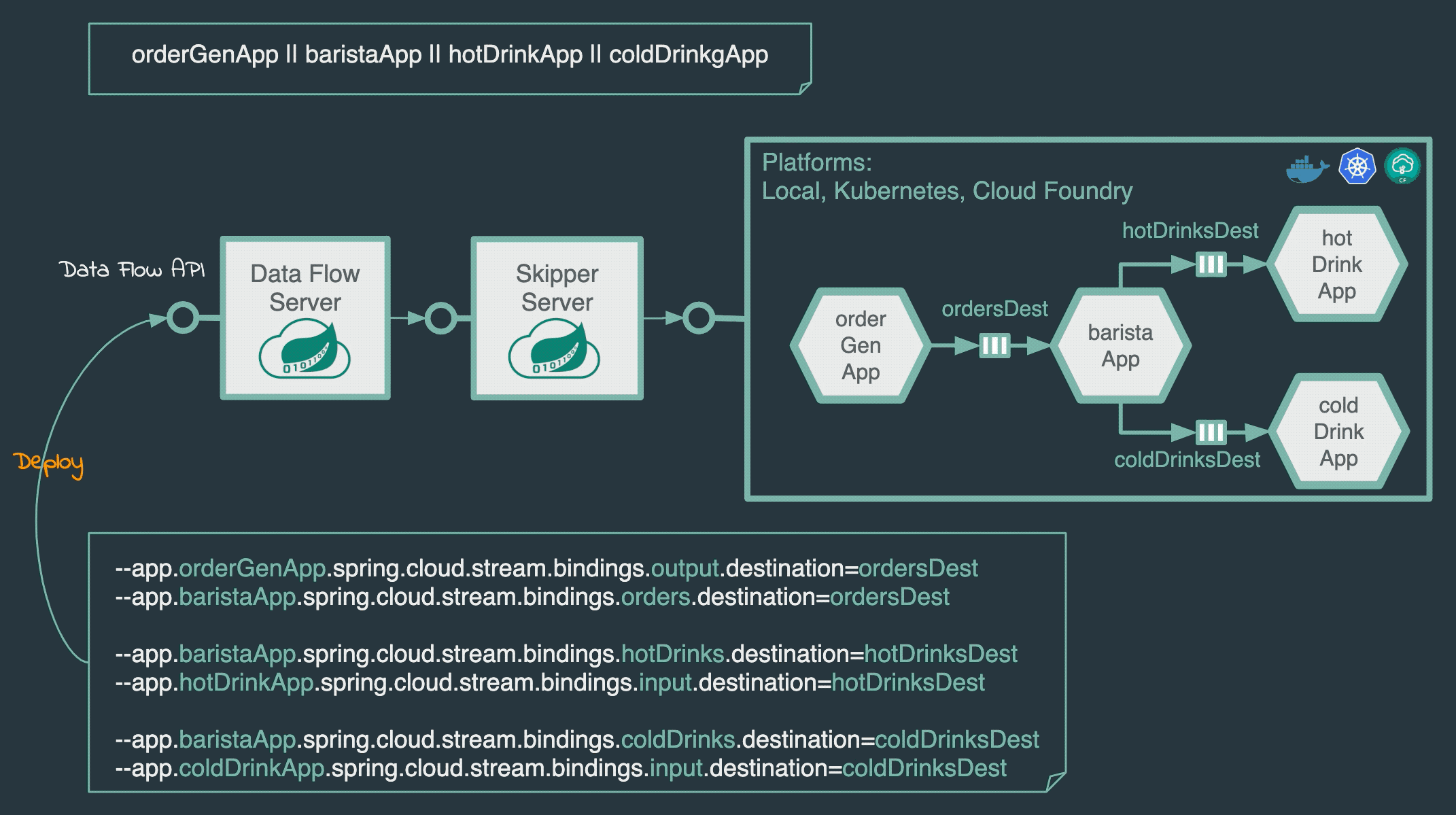
批处理任务支持:通过Spring Cloud Task管理一次性批处理作业,支持手动触发、定时调度和事件驱动触发 。
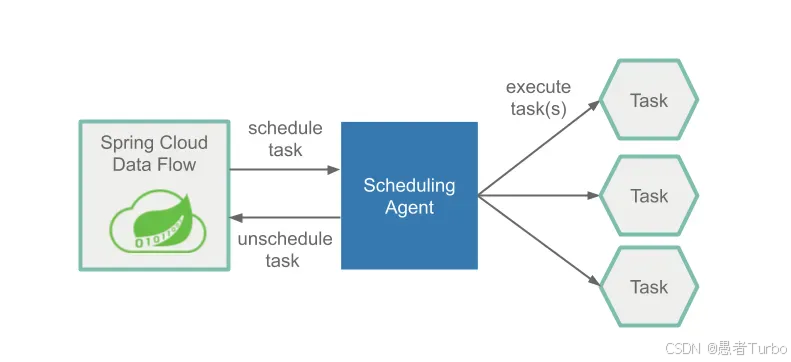
应用生命周期管理:提供应用注册、版本控制、部署、升级、回滚等全生命周期管理功能。
多环境部署支持:支持本地服务器、Cloud Foundry、Kubernetes等多种部署目标,通过Spring Cloud Deployer实现平台无关性。
监控与可观测性:集成Spring Boot Actuator、Prometheus、Grafana等工具,提供应用健康检查、性能指标和日志追踪功能。
可视化界面:提供基于Web的Dashboard,支持拖拽式组件配置和数据流管理,简化了操作流程。
与Spring生态深度集成:与Spring Boot、Spring Cloud、Spring Cloud Skipper等组件紧密集成,充分发挥Spring生态的优势。
5.2 与同类产品的对比
SCDF与其他数据流编排和处理工具的对比:
| 对比维度 | Spring Cloud Data Flow | Apache Airflow | AWS Step Functions | Google Cloud Dataflow | Apache Flink |
|---|---|---|---|---|---|
| 核心定位 | 数据流编排框架(流+批) | 批处理任务调度 | 通用微服务编排 | 端到端处理引擎(绑定GCP) | 流批一体处理引擎 |
| 部署灵活性 | 云中立(Kubernetes/CF等) | 需自建集群或依赖云服务 | 仅限AWS | 仅限GCP | 云中立,但需手动管理集群 |
| 开发模型 | DSL/Docker/微服务抽象 | Python DAG文件 | JSON状态机定义 | SDK绑定特定语言(Python/Go) | 原生API或Beam模型 |
| 多语言支持 | 支持(Spring Boot/Shell脚本等) | 有限(Python为主) | 支持(通过AWS Lambda) | 有限(绑定GCP SDK) | 有限(Java/Scala) |
| 与SCDF的关系 | - | 需手动集成 | 需手动集成 | 需手动集成 | 可通过SCDF Task模型调用 |
SCDF的优势:
-
统一编排平台:SCDF提供一致的界面和API来管理流式和批处理应用,而其他工具(如Airflow、Step Functions)通常专注于单一类型的任务。
-
云原生原生支持:SCDF与Docker、Kubernetes等容器技术深度集成,支持弹性伸缩和动态部署,而XD和部分竞品缺乏对现代云平台的原生支持。
-
微服务架构:SCDF采用微服务架构,将数据流编排功能分解为独立的服务,提高了系统的可维护性和可扩展性。
-
低代码/无代码开发:通过Dashboard的拖拽式界面,非开发人员也能参与数据流的设计和配置,降低了技术门槛。
-
与Spring生态无缝集成:SCDF与Spring Boot、Spring Cloud等组件紧密集成,充分发挥了Spring生态的优势,简化了开发和部署流程。
六、使用方法与实践指南
6.1 环境搭建
SCDF的环境搭建可以通过docker-compose快速完成:
version: '3'
services:
mysql:
image: mysql:5.7.25
container_name: dataflow-mysql
environment:
MYSQL_DATABASE: dataflow
MYSQL_USER: root
MYSQL_ROOT_PASSWORD: rootpw
expose:
- "3306"
ports:
- "3306:3306"
volumes:
- ./my.cnf:/etc/mysql/my.cnf
kafka-broker:
image: confluentinc/cp-kafka:5.3.1
container_name: dataflow-kafka
expose:
- "9092"
environment:
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker:9092
- KAFKA_ZOOKEEPER connect=zookeeper:2181
- KAFKA_ADVERTISED_HOST_NAME=kafka-broker
- KAFKA OFFSETS TOPIC REPLICATION_FACTOR=1
depends_on:
- zookeeper
zookeeper:
image: confluentinc/cp-zookeeper:5.3.1
container_name: dataflow-kafka-zookeeper
expose:
- "2181"
environment:
- ZOOKEEPER_client_PORT=2181
dataflow-server:
image: springcloud/spring-cloud-dataflow-server:2.11.5
container_name: dataflow-server
ports:
- "9393:9393"
environment:
- spring.cloud.dataflow.applicationProperties.stream春季.云流 Kafka.binder.brokers=PLAINTEXT://kafka-broker:9092
- spring.cloud.dataflow.applicationProperties.stream春季.云流 Kafka.streams.binder.brokers=PLAINTEXT://kafka-broker:9092
- spring.cloud.dataflow复活节彩蛋= true
- spring DATASOURCE URL=jdbc:postgresql://localhost:5432/dataflow
- spring DATASOURCE username=root
- spring DATASOURCE password=rootpw
- spring DATASOURCE driver-class-name=org.postgresql.Driver
depends_on:
- mysql
- kafka-broker6.2 应用注册
使用Shell或Dashboard注册Stream/Task应用:
# 注册Kafka源应用
dataflow> app register --name http-source --type source --uri maven://org.springframework.cloud.stream.app:jsonhttp-source:2.1.1.RELEASE
# 注册日志接收器应用
dataflow> app register --name log-sink --type sink --uri maven://org.springframework.cloud.stream.app:log-sink:2.1.1.RELEASE
# 注册Kafka处理器应用
dataflow> app register --name transform-processor --type processor --uri maven://org.springframework.cloud.stream.app:transform-processor:2.1.1.RELEASE6.3 数据流定义
通过DSL或Dashboard定义数据流:
# 定义一个简单的数据流
dataflow> stream create --name my-stream --definition "http-source | transform-processor | log-sink"
# 部署数据流
dataflow> stream deploy --name my-stream6.4 任务定义与调度
定义和调度批处理任务:
# 定义一个批处理任务
dataflow> task create --name my-batch-job --definition "app1 --param1=value1 app2 --param2=value2"
# 调度任务
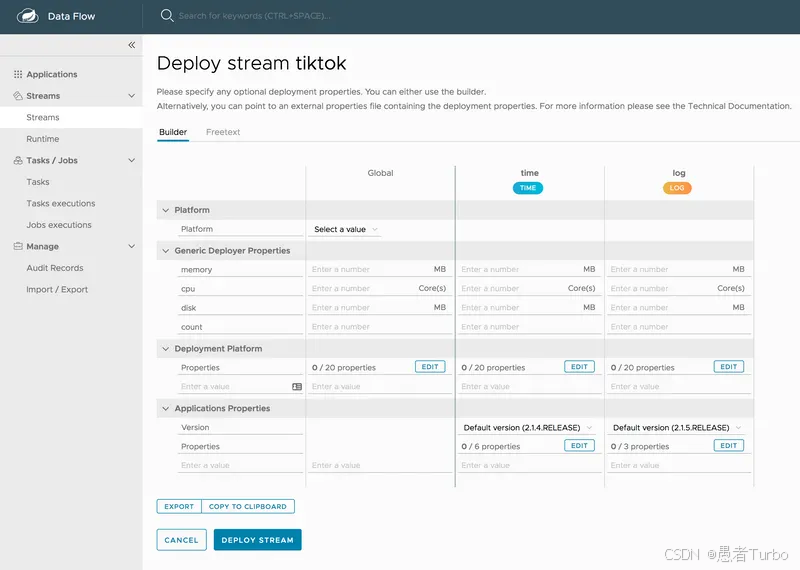
dataflow> schedule create --name my-schedule --expression "0 0 * * * *" --task-name my-batch-job6.5 监控与管理
通过Dashboard或命令行监控数据流和任务:
# 查看流状态
dataflow> stream info my-stream
# 查看任务执行历史
dataflow> task execution list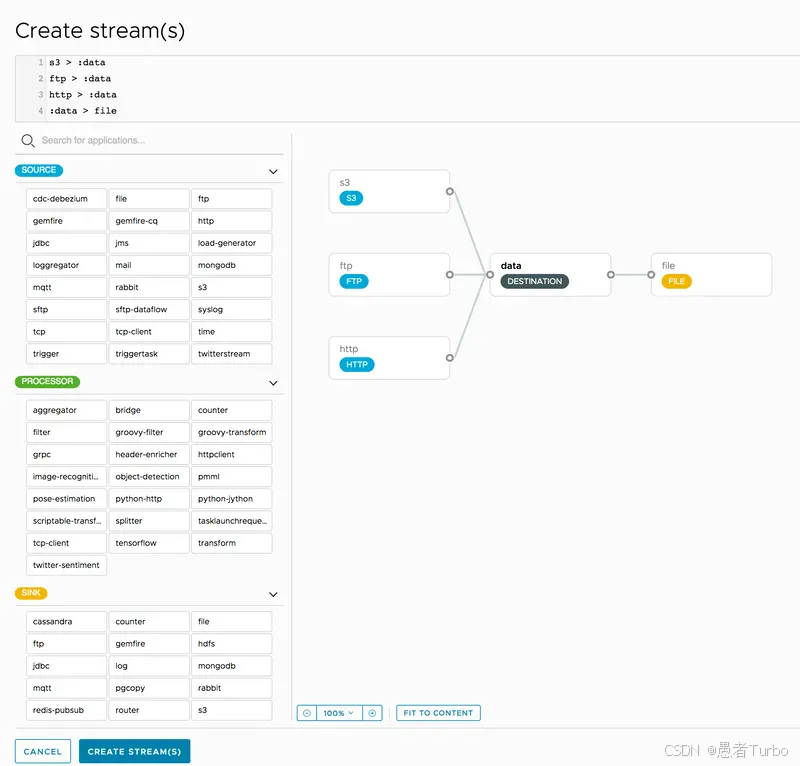
七、最佳实践与常见问题
7.1 最佳实践
模块化设计:将数据流拆分为独立的组件(源、处理器、接收器),每个组件专注于单一功能,提高可维护性。
版本控制:使用应用注册表和Skipper管理应用版本,确保部署的一致性和可回滚性。
配置分离:通过Spring Cloud Config实现配置与代码分离,支持不同环境的配置切换 。
资源优化:根据数据流的负载情况,动态调整组件的资源分配(如内存、CPU),优化系统性能。
监控集成:整合Prometheus、Grafana等监控工具,实现数据流的实时监控和性能分析。
安全加固:配置访问控制、安全认证和审计日志,确保数据流的安全性和合规性。
7.2 常见问题与解决方案
依赖管理问题:
- 问题描述:新手在使用SCDF时,可能会遇到依赖管理问题,尤其是在Maven或Gradle构建工具中配置依赖时。
- 解决方案:使用Spring Initializr生成基础项目结构,确保依赖版本与SCDF兼容;使用Spring Cloud BOM统一管理依赖版本;检查配置文件中的关键配置项(如消息中间件地址、认证信息)是否正确 。
配置文件问题:
- 问题描述:新手在配置SCDF时,可能会遇到配置文件(如application.yml或application.properties)中的配置项不正确或缺失的问题。
- 解决方案:参考官方文档确认配置项的详细说明和默认值;使用示例配置作为模板进行修改;检查配置文件中的数据库连接、消息队列等关键配置是否一致 。
运行环境问题:
- 问题描述:新手在本地或云环境中运行SCDF时,可能会遇到环境配置问题,如Kubernetes或Cloud Foundry的配置不正确。
- 解决方案:检查平台配置是否正确(如服务地址、认证信息);使用官方工具验证环境配置;查看应用程序日志获取详细错误信息 。
性能优化问题:
- 问题描述:数据流处理性能不足,如延迟高、吞吐量低。
- 解决方案:调整消息中间件的分区数和副本数;优化处理器逻辑,减少计算复杂度;增加处理器实例数量;使用更高效的序列化格式。
版本兼容性问题:
- 问题描述:不同版本的SCDF、Spring Cloud Stream/Task和消息中间件之间存在兼容性问题。
- 解决方案:参考官方文档确认版本兼容性;使用Spring Cloud BOM统一管理依赖版本;在升级前进行充分测试;使用Skipper进行平滑升级 。
八、未来发展趋势与总结
随着云原生技术的不断发展,SCDF也在持续演进。未来SCDF可能会进一步增强对多云环境的支持,提供更强大的监控和分析功能,以及更灵活的部署和扩展机制。同时,随着Apache Flink等流处理引擎的普及,SCDF可能会提供更深度的集成和支持,帮助用户构建更复杂的数据处理管道。
总结来说,Spring Cloud Data Flow是一个强大的数据流编排框架,它简化了数据管道的开发和运维,使开发人员能够专注于业务逻辑而非底层基础设施细节。SCDF通过模块化架构和微服务设计理念,实现了数据流编排的轻量化与高可用性,为现代云原生环境提供了灵活的数据流管理工具。对于使用Spring生态的开发团队,SCDF是一个理想的数据流编排选择,能够显著提高开发效率和系统可靠性。
SCDF的核心价值在于提供一个统一、灵活、云原生友好的数据流编排平台,帮助开发人员构建、部署和管理复杂的数据处理管道。通过本文的介绍,希望读者能够全面了解SCDF的功能和优势,并在实际项目中充分利用这一工具简化数据流处理的开发和运维流程。
参考资料:
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)