Neus复现(植物数据集)
出现该错误的原因就是原本的DTU数据集是包括掩码图片的,因此是进行的有掩码监督的训练,但是我们自制的Neus数据集是没有掩码图片的,只能进行无掩码监督的训练,因此运行无掩码监督的命令,但是数据集处理文件dataset.py,默认我们的数据集是有掩码的,因此要对dataset.py进行修改,并对运行文件exp_runner.py进行一定的修改。值得注意的是自己制作的植物数据集无掩码,因此在训练的时候
1、使用植物数据集训练Nues
1.1 使用COLMAP制作自己的Neus(DTU格式)的植物数据集(参考CSDN博客)
本节内容参考CSDN上的博客【三维重建】【深度学习】【数据集】基于COLMAP制作自己的NeuS(DTU格式)数据集_dtu数据集-CSDN博客。
DTU格式是NeuS网络模型训练使用的数据集格式之一,本文基于COLMAP软件展示从DTU格式数据集的制作到开始模型训练的完整流程。NeuS通过输入同一场景不同视角下的二维图片和相机位姿,对场景进行三维隐式建模,使用一种新的一阶近似无偏差的公式,从而即使没有掩模监督,也能进行更精确的表面重建。
1.1.1 下载colmap软件
下载COLMAP软件【下载地址】,本文使用的是Windows下的CUDA版本:
解压后双击打开COLMAP.bat,出现如下界面:
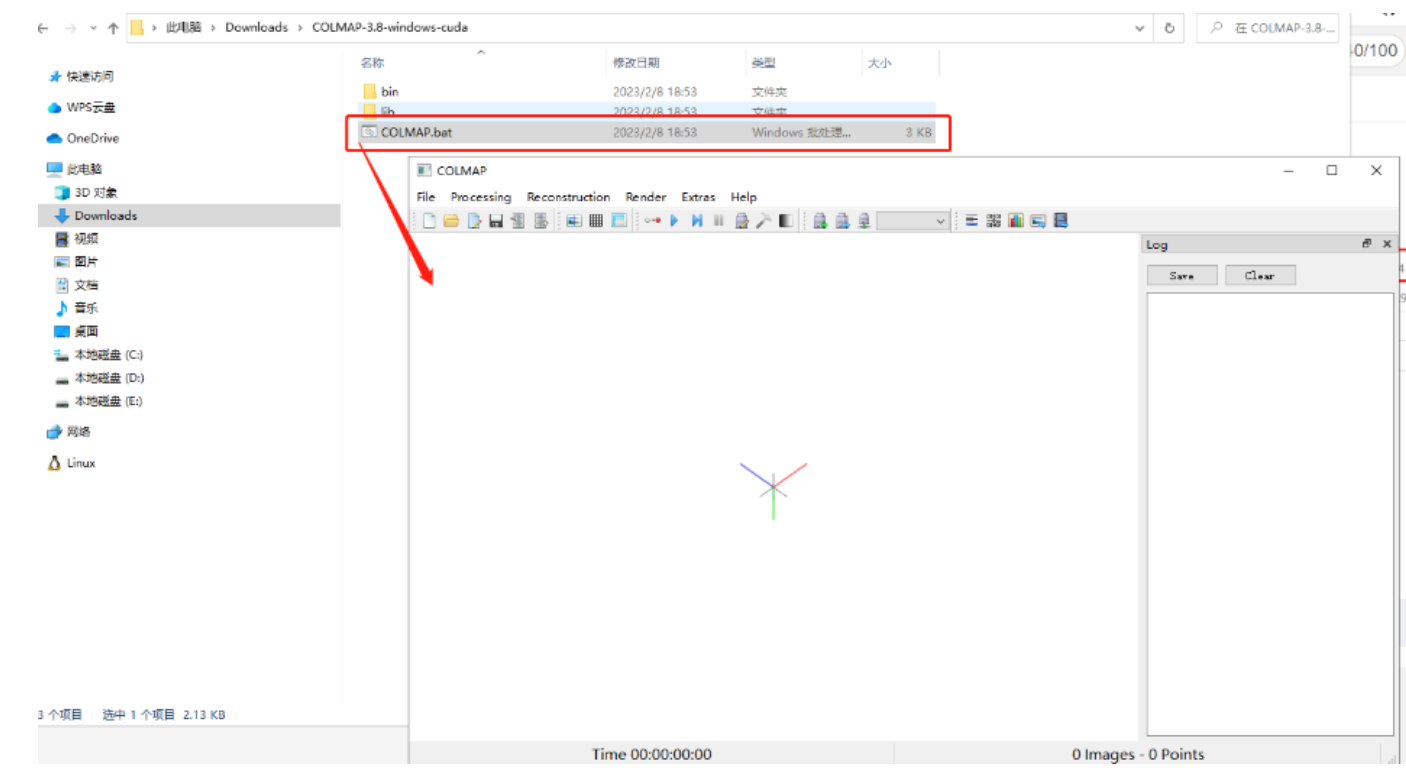
软件安装成功。
1.1.2 下载LLFF源码
# 可能需要科学上网从Github上直接git下载 git clone https://github.com/Fyusion/LLFF.git pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-image pip install -i https://pypi.tuna.tsinghua.edu.cn/simple imageio
1.1.3 采集图片使用colmap获取相机位姿
创建⼯程: 点击File -> New project 以新建一个项目。
点击New,选择一个文件夹(与测试的植物图片M4放置在同一目录),设置工程名M4_colmap以新建工程数据文件。
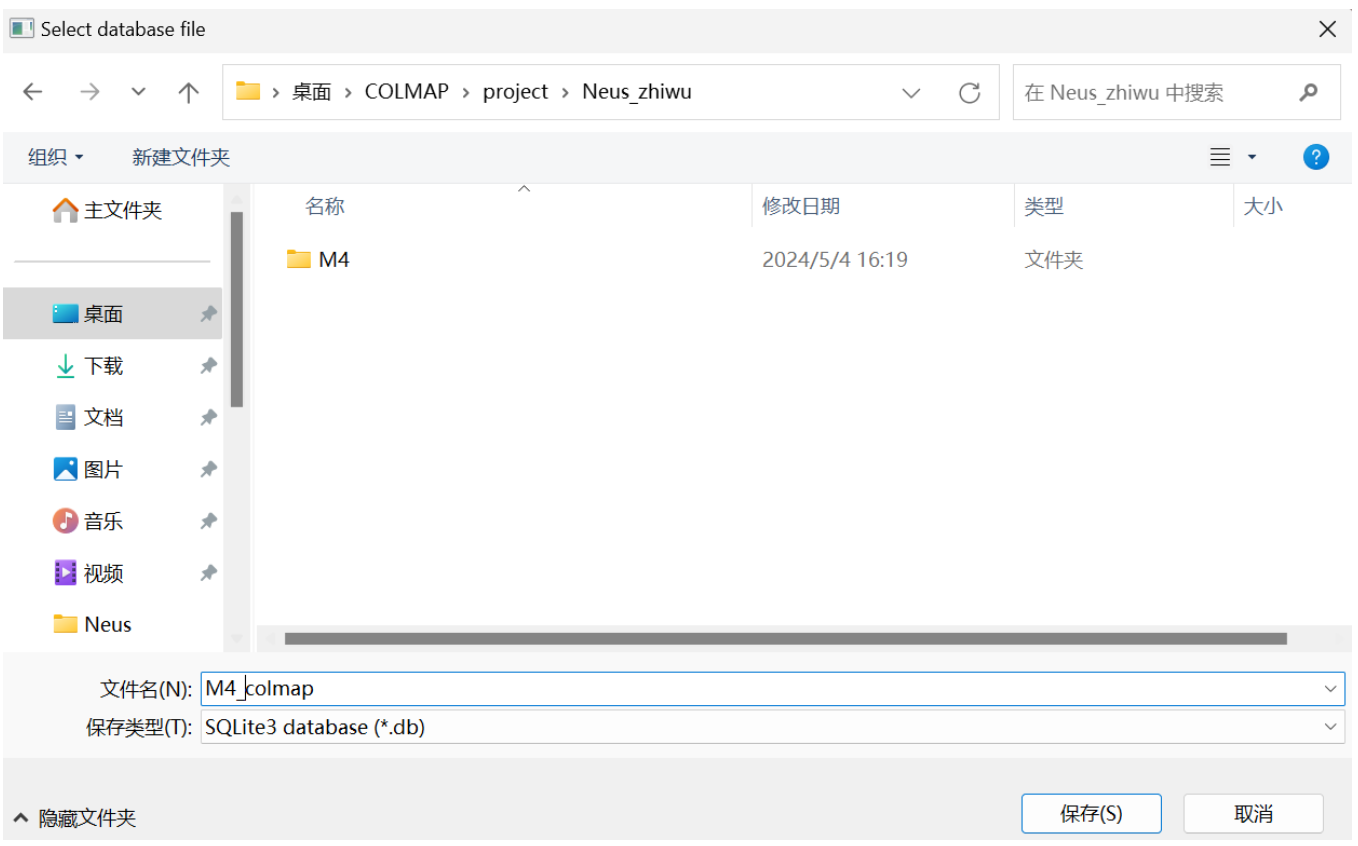
点击Select,选择刚才图像所在的⽂件夹M4,点击Save。
新建工程项目并配置完毕。
点击Processing -> Feature extraction,Camera model选择SIMPLE_PINHOLE,其他配置使用默认配置即可,点击Extract后,自动开始提取图片特征。
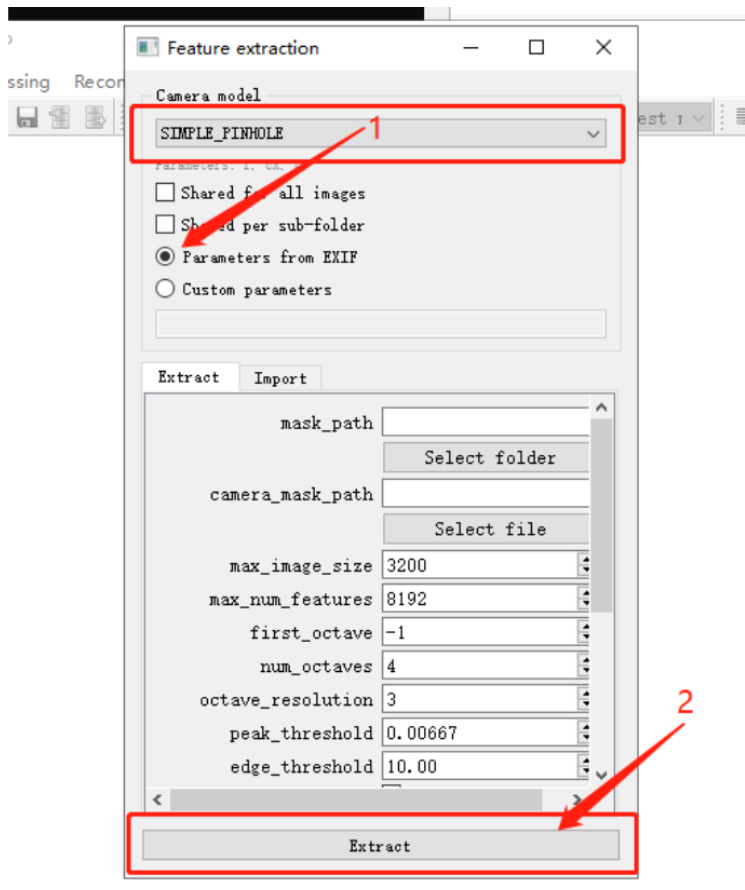
待特征提取完毕后关闭窗口。
点击Processing -> Feature matching,使用默认配置直接点击Run进行特征匹配。
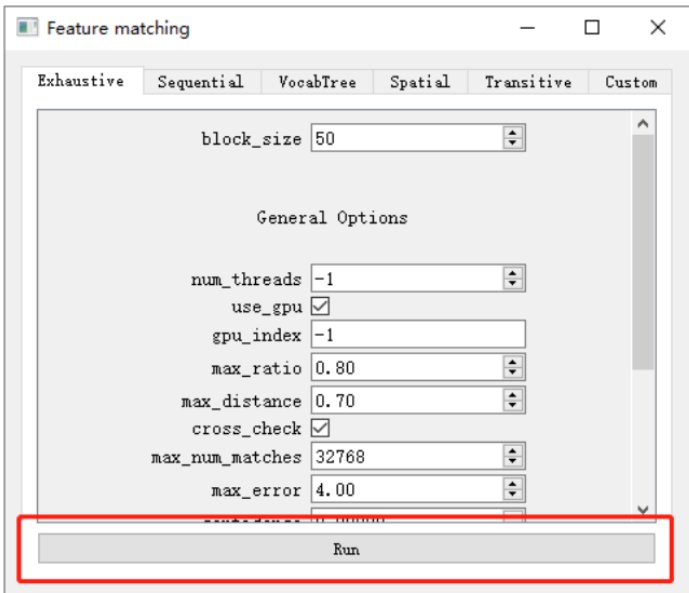
待特征匹配完毕后关闭窗口。在右侧Log一栏中可以查看特征提取与匹配的进度,请确保过程中没有Erro报错。
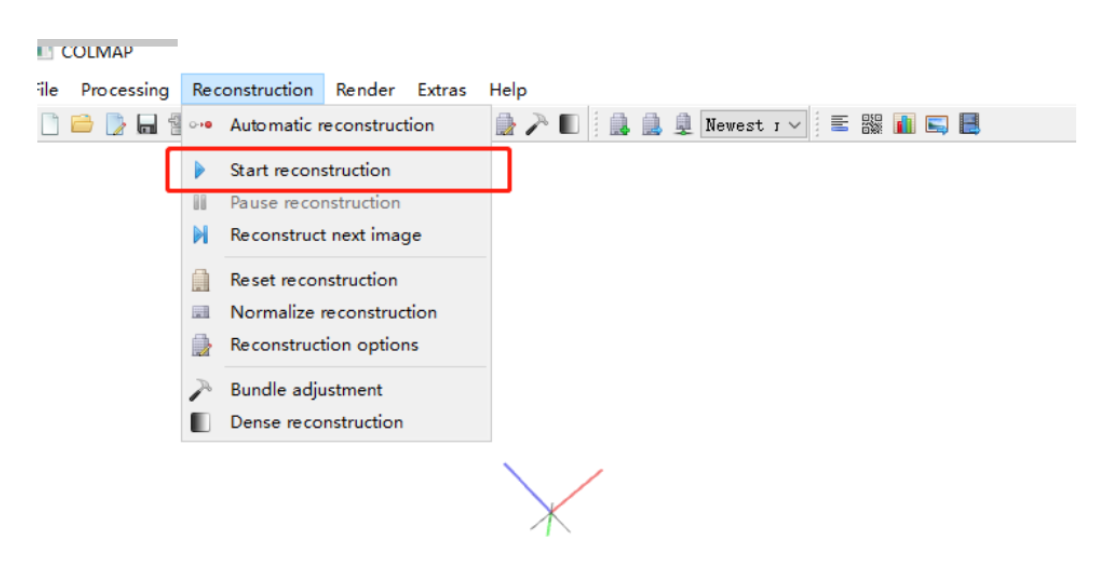
点击Reconstruction -> Start reconstruction进行重建,在窗口中可以看到重建过程,此过程可能会持续一段时间。
重建完毕后,得到如下图,通过右下角Images和Points可以大致判断是否重建成功。
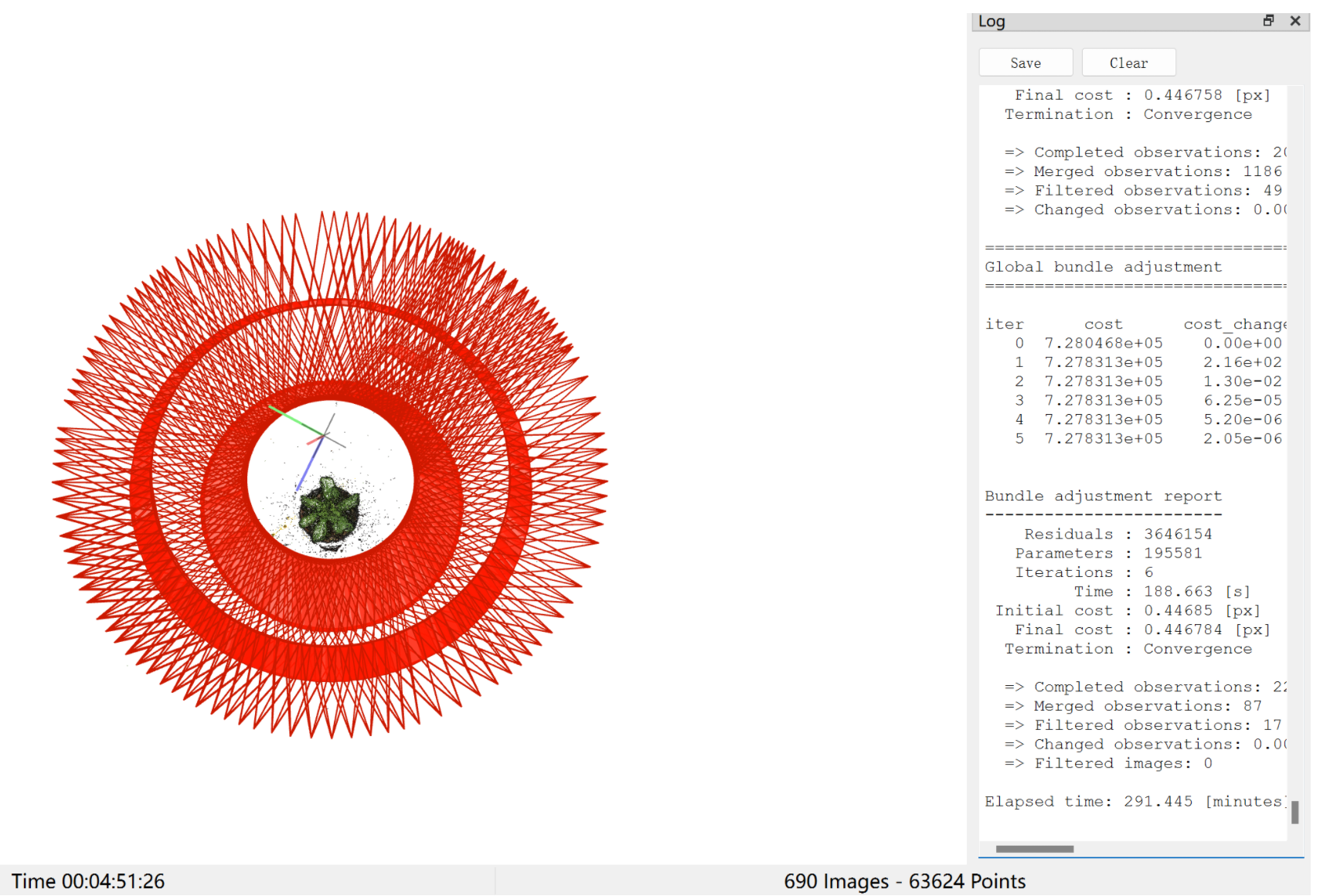
注意:匹配的位姿和图片数目不同在后续的步骤中会导致报错,会在下文中详细说明解决这个问题的方法,暂时继续跟着步骤走。
点击File -> Export model 以导出模型,在保存图像的文件夹所在的目录下新建/sparse/0/文件夹,选择该文件夹将模型导入到该目录下。
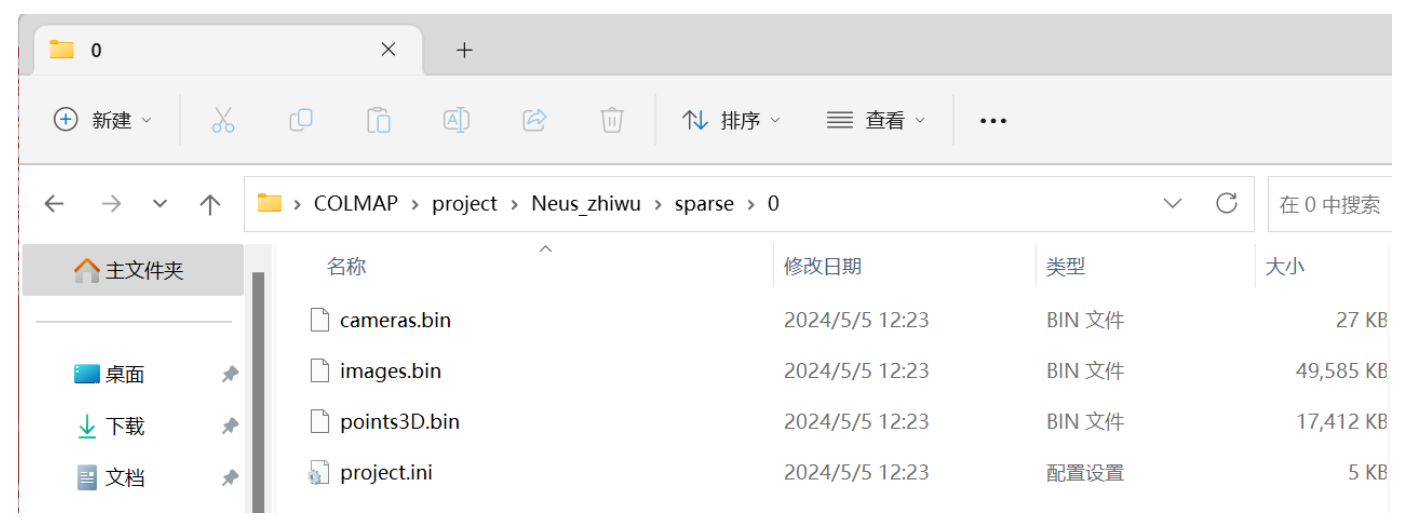
将利用Colmap获得的相机位姿以及数据集进行压缩得到压缩包,将这个压缩包传入autodl中,传入的目录为autodl-tmp/NeuS/Nues_zhiwu。
然后利用下述命令对传入的压缩包进行解压
cd autodl-tmp/NeuS/Nues_zhiwu unzip Neus_zhiwu.zip
解压后可以获得数据集和相机的位姿
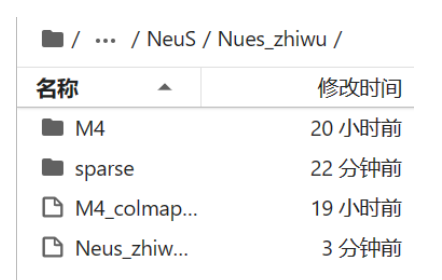
1.1.4 将植物数据集转为LLFF数据的格式
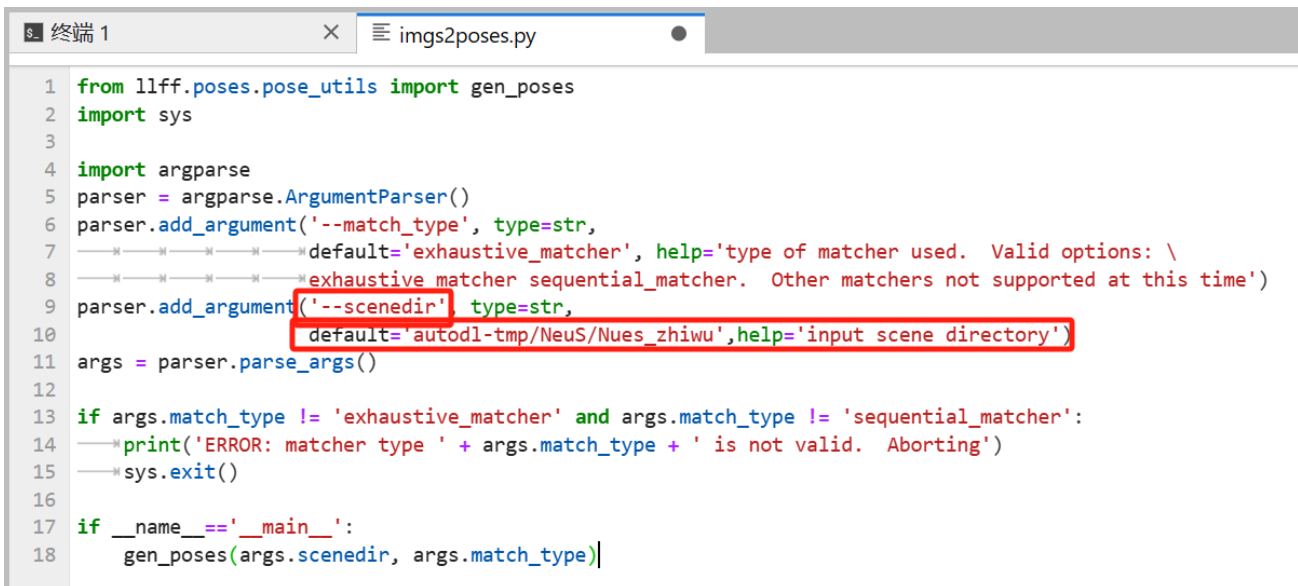
进入LLFF目录下,打开imgs2poses.py文件,新增如下内容,default=‘里面是sparse所在目录的绝对路径’,并将参数’scenedir’修改为是’- -scenedir’。
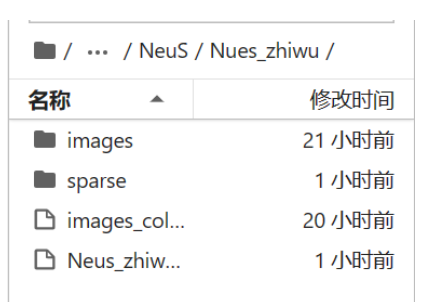
存放照片的文件夹名称必须是images,否则会出错,我这里是M4,所以需要修改成images。
然后进入到LLFF的文件夹中,运行如下命令
python imgs2poses.py
出现如下错误:
Need to run COLMAP
Traceback (most recent call last):
File "imgs2poses.py", line 18, in <module>
gen_poses(args.scenedir, args.match_type)
File "/root/autodl-tmp/NeuS/LLFF/llff/poses/pose_utils.py", line 268, in gen_poses
run_colmap(basedir, match_type)
File "/root/autodl-tmp/NeuS/LLFF/llff/poses/colmap_wrapper.py", line 26, in run_colmap
logfile = open(logfile_name, 'w')
FileNotFoundError: [Errno 2] No such file or directory: 'autodl-tmp/NeuS/Nues_zhiwu/colmap_output.txt'这个错误说明autodl里面的ubuntu系统并没有安装colmap,随后我查阅了如何在ubuntu系统中安装colmap,过程很复杂,涉及很多版本和依赖安装的问题。因此我不打算在我创建的Ubuntu系统中运行LLFF的代码,而是在本地运行LLFF中的代码,因为本地是安装好colmap的,随后再把本地跑LLFF代码的结果上传到autodl即可。
首先通过网址https://github.com/Fyusion/LLFF.git将LLFF这个项目下载下来,存于E盘

并用本地的Pycharm创建一个项目,在新建的项目里面打开LLFF-master
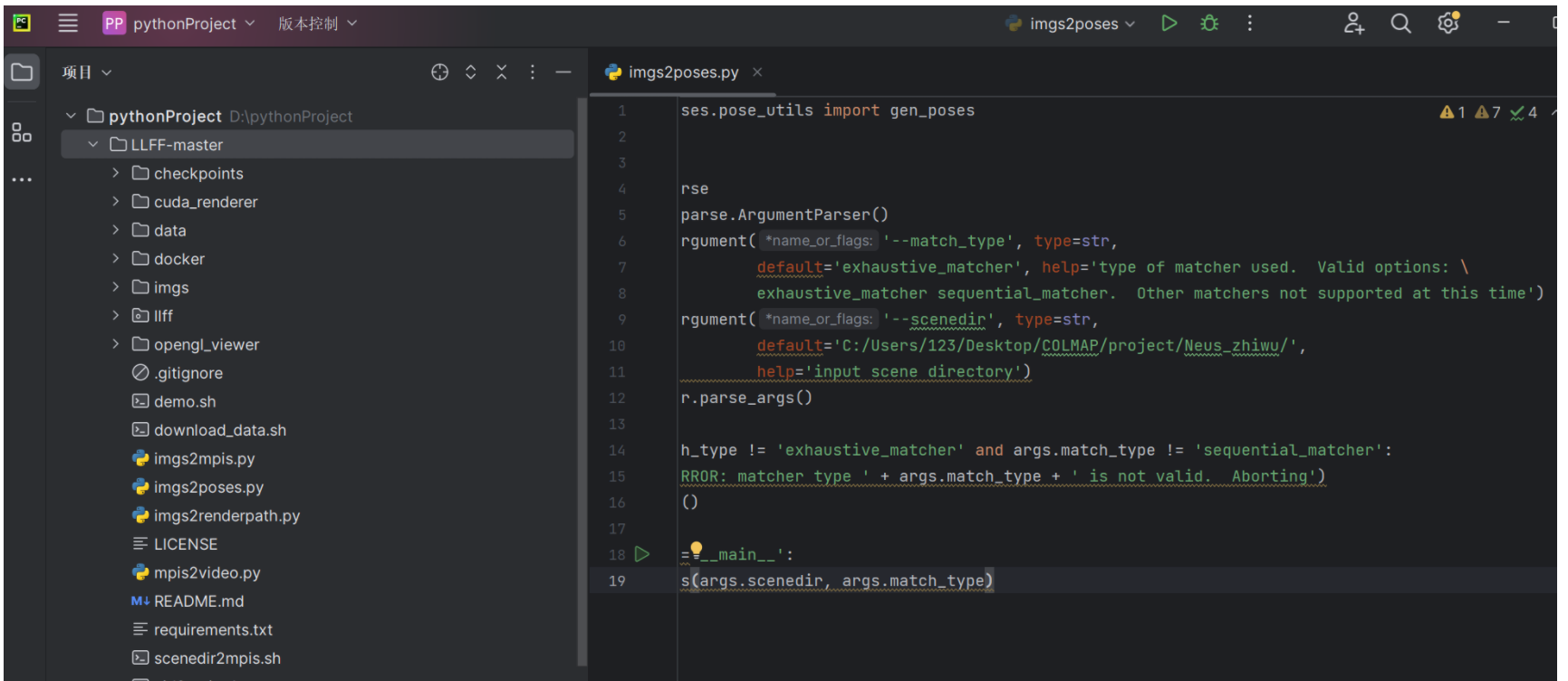
找到imgs2poses.py文件,仍做如下两个修改
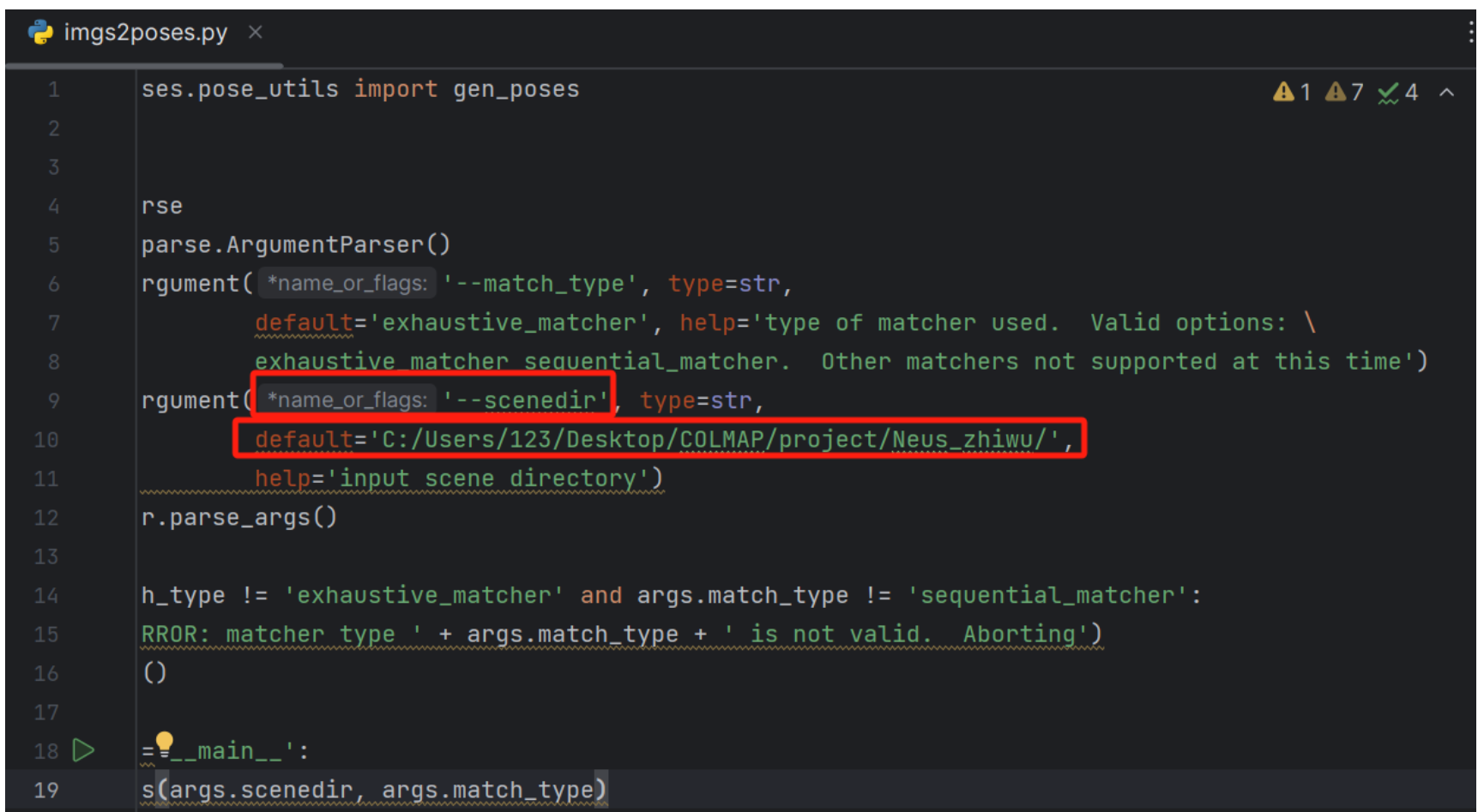
然后直接运行imgs2poses.py文件,出现如下错误
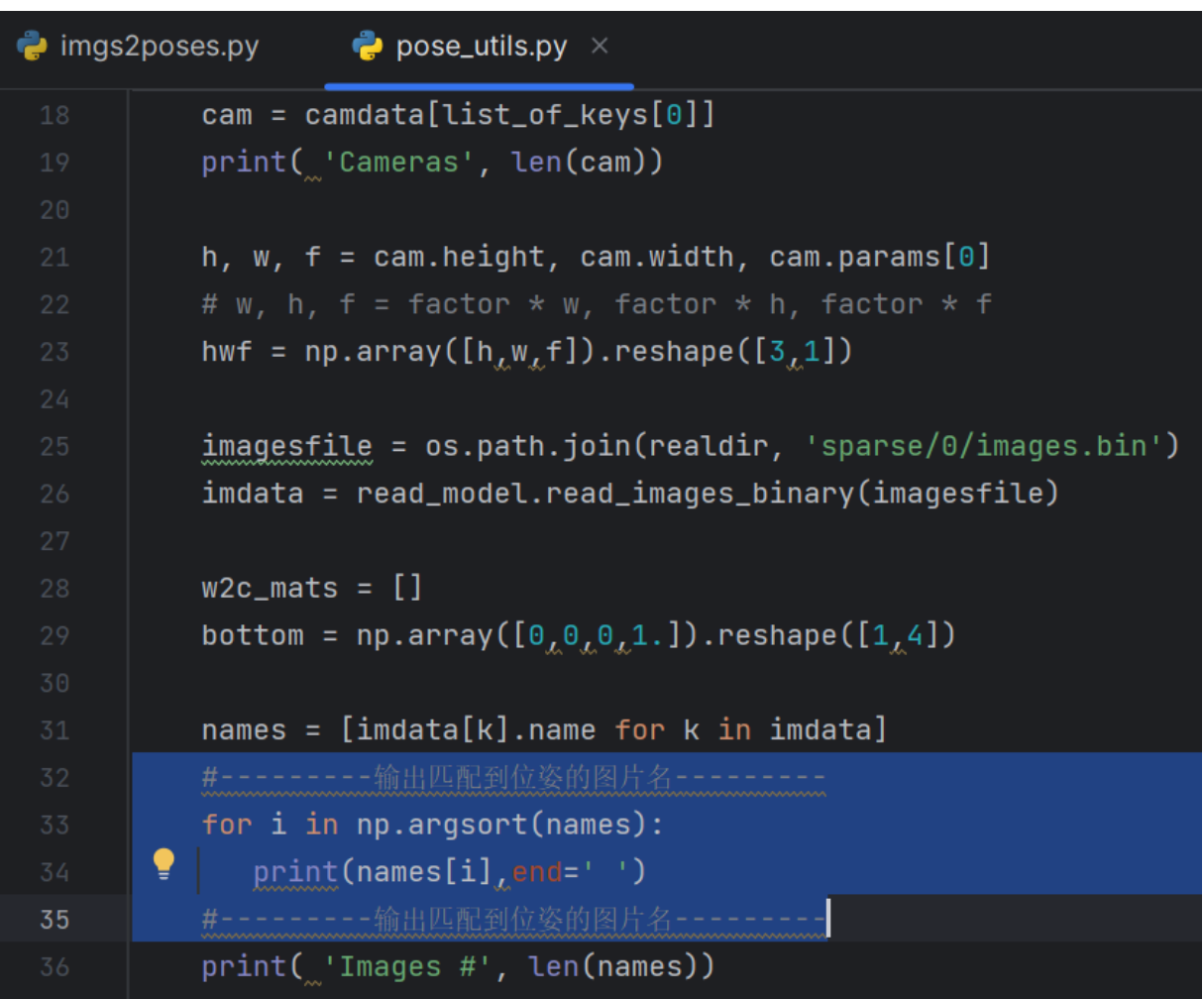
这个问题是之前所说的匹配的位姿和图片数目不同导致的,现在在这里解决这个问题。通过在 LLFF/llff/poses/pose_utils.py 文件的32行左右添加如下代码:
#---------输出匹配到位姿的图片名--------- for i in np.argsort(names): print(names[i],end=' ') #---------输出匹配到位姿的图片名---------
添加代码位置如下图所示:
显示出所有匹配到位姿的图片。

进入图像保存的目录,根据输出的匹配到位姿的图片名称删除没有匹配到位姿的图像,而后重新进行 “位姿计算” 这一步骤。
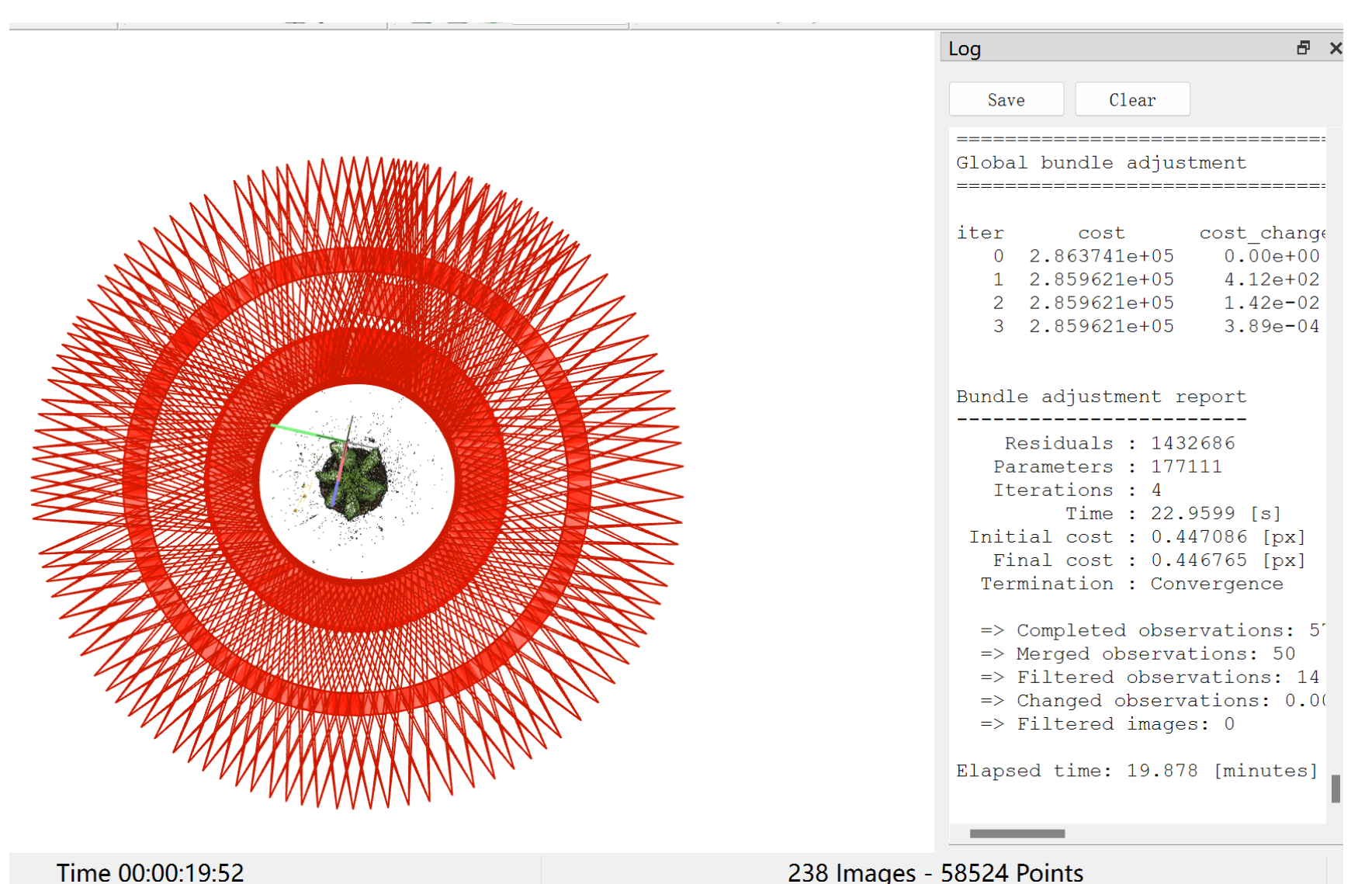
在重新又做完colmap的一系列步骤之后,又重新运行imgs2poses.py文件,成功运行后会得到如下的提示信息

并获得一个如下装有图片位姿的文件poses_bounds.npy,至此将我们自己的数据集转为LLFF格式的数据集就到此结束。
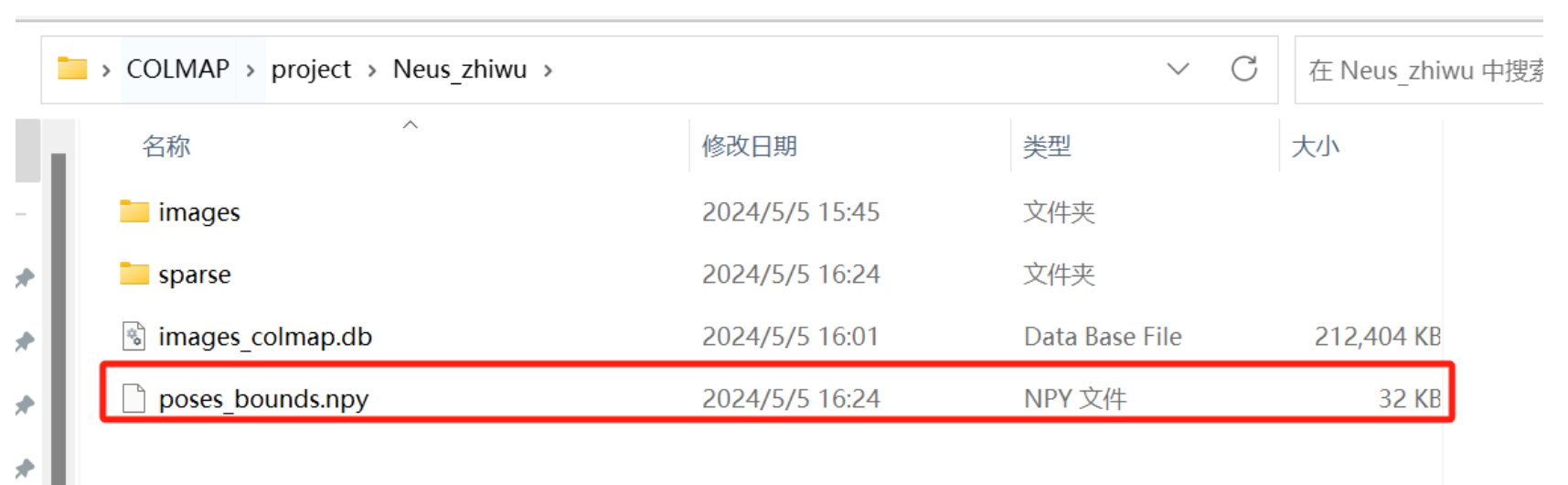
将这里处理好的文件Neus_zhiwu再次传入autodl中,将之前的传入的那个文件删掉,如下图
1.1.5 将LLFF格式的植物数据集转为DTU数据集格式
这个网址提供了LLFF数据格式转DTU数据格式的代码。 将代码解压到autodl-tmp/NueS/tools目录下。如下
然后回到NeuS文件目录(一定要返回这个目录在运行下面的命令,否则允许命令会出现路径问题),直接运行如下命令,就可以将LLFF格式的植物数据集转为DTU数据集格式。
python tools/preprocess_llff.py Neus_zhiwu
运行这个命令时一定要注意我们已经在autodl-tmp/NeuS目录下了,因此py文件应该输入的是相对路径tools/preprocess_llff.py,后面的Neus_zhiwu也是相对路径,将装有LLFF格式的植物数据集文件autodl-tmp/NeuS/Neus_zhiwu的相对路径输入,即Neus_zhiwu。
运行成功之后会得到如下的提示信息:

并会得到cameras_sphere.npz,这就DTU数据集格式的植物数据集,如下
那么做到这一步,自制的NeuS数据集已经完成了,可以用自己的数据集进行训练。
1.2 使用自制的植物数据集训练Neus(参考CSDN博客)
利用【三维重建】【深度学习】【数据集】基于COLMAP制作自己的NeuS(DTU格式)数据集_dtu数据集-CSDN博客该篇博客的方法自制的数据集训练Neus。
值得注意的是自己制作的植物数据集无掩码,因此在训练的时候,要使用无掩码的命令进行训练,其中在NeuS源码中的dataset.py文件中要进行修改。并且一定要检查输入的图像有没有改成.jpg格式,存放图像的文件夹和代码中的路径有没有不一致的情况,一些细节还是需要注意的。
首先将文件Neus_zhiwu移到pubulic_data的目录下:
再将Neus_zhiwu中的images文件名改为image:
运行如下无掩码监督的命令:
python exp_runner.py --mode train --conf ./confs/womask.conf --case Neus_zhiwu
出现如下错误:
Hello Wooden
Load data: Begin
Traceback (most recent call last):
File "exp_runner.py", line 389, in <module>
runner = Runner(args.conf, args.mode, args.case, args.is_continue)
File "exp_runner.py", line 35, in __init__
self.dataset = Dataset(self.conf['dataset'])
File "/root/autodl-tmp/NeuS/models/dataset.py", line 59, in __init__
self.masks_np = np.stack([cv.imread(im_name) for im_name in self.masks_lis]) / 256.0
File "<__array_function__ internals>", line 200, in stack
File "/root/miniconda3/lib/python3.8/site-packages/numpy/core/shape_base.py", line 460, in stack
raise ValueError('need at least one array to stack')
ValueError: need at least one array to stack出现该错误的原因就是原本的DTU数据集是包括掩码图片的,因此是进行的有掩码监督的训练,但是我们自制的Neus数据集是没有掩码图片的,只能进行无掩码监督的训练,因此运行无掩码监督的命令,但是数据集处理文件dataset.py,默认我们的数据集是有掩码的,因此要对dataset.py进行修改,并对运行文件exp_runner.py进行一定的修改。
下面是进行修改了的dataset.py的代码,也就是进行无掩码监督训练的dataset.py的代码:
import torch
import torch.nn.functional as F
import cv2 as cv
import numpy as np
import os
from glob import glob
from icecream import ic
from scipy.spatial.transform import Rotation as Rot
from scipy.spatial.transform import Slerp
# This function is borrowed from IDR: https://github.com/lioryariv/idr
def load_K_Rt_from_P(filename, P=None):
if P is None:
lines = open(filename).read().splitlines()
if len(lines) == 4:
lines = lines[1:]
lines = [[x[0], x[1], x[2], x[3]] for x in (x.split(" ") for x in lines)]
P = np.asarray(lines).astype(np.float32).squeeze()
out = cv.decomposeProjectionMatrix(P)
K = out[0]
R = out[1]
t = out[2]
K = K / K[2, 2]
intrinsics = np.eye(4)
intrinsics[:3, :3] = K
pose = np.eye(4, dtype=np.float32)
pose[:3, :3] = R.transpose()
pose[:3, 3] = (t[:3] / t[3])[:, 0]
return intrinsics, pose
class Dataset:
def __init__(self, conf):
super(Dataset, self).__init__()
print('Load data: Begin')
self.device = torch.device('cuda')
self.conf = conf
self.data_dir = conf.get_string('data_dir')
self.render_cameras_name = conf.get_string('render_cameras_name')
self.object_cameras_name = conf.get_string('object_cameras_name')
self.camera_outside_sphere = conf.get_bool('camera_outside_sphere', default=True)
self.scale_mat_scale = conf.get_float('scale_mat_scale', default=1.1)
camera_dict = np.load(os.path.join(self.data_dir, self.render_cameras_name))
self.camera_dict = camera_dict
self.images_lis = sorted(glob(os.path.join(self.data_dir, 'image/*.png')))
self.n_images = len(self.images_lis)
self.images_np = np.stack([cv.imread(im_name) for im_name in self.images_lis]) / 256.0
self.masks_lis = sorted(glob(os.path.join(self.data_dir, 'mask/*.png')))
self.has_masks = len(self.masks_lis) > 0
if self.has_masks:
imgs = [cv.imread(im_name) for im_name in self.masks_lis]
if any(img is None for img in imgs):
raise ValueError("One or more mask images could not be loaded. Check file paths and image formats.")
self.masks_np = np.stack(imgs) / 256.0
self.masks = torch.from_numpy(self.masks_np.astype(np.float32)).to(self.device) # [n_images, H, W, 3]
else:
self.masks_np = None
self.masks = None
print("No masks found, continuing without mask supervision.")
# world_mat is a projection matrix from world to image
self.world_mats_np = [camera_dict['world_mat_%d' % idx].astype(np.float32) for idx in range(self.n_images)]
self.scale_mats_np = []
# scale_mat: used for coordinate normalization, we assume the scene to render is inside a unit sphere at origin.
self.scale_mats_np = [camera_dict['scale_mat_%d' % idx].astype(np.float32) for idx in range(self.n_images)]
self.intrinsics_all = []
self.pose_all = []
for scale_mat, world_mat in zip(self.scale_mats_np, self.world_mats_np):
P = world_mat @ scale_mat
P = P[:3, :4]
intrinsics, pose = load_K_Rt_from_P(None, P)
self.intrinsics_all.append(torch.from_numpy(intrinsics).float())
self.pose_all.append(torch.from_numpy(pose).float())
self.images = torch.from_numpy(self.images_np.astype(np.float32)).to(self.device) # [n_images, H, W, 3]
# After correction
if self.has_masks:
self.masks = torch.from_numpy(self.masks_np.astype(np.float32)).to(self.device) # [n_images, H, W, 3]
else:
self.masks = None
self.intrinsics_all = torch.stack(self.intrinsics_all).to(self.device) # [n_images, 4, 4]
self.intrinsics_all_inv = torch.inverse(self.intrinsics_all) # [n_images, 4, 4]
self.focal = self.intrinsics_all[0][0, 0]
self.pose_all = torch.stack(self.pose_all).to(self.device) # [n_images, 4, 4]
self.H, self.W = self.images.shape[1], self.images.shape[2]
self.image_pixels = self.H * self.W
object_bbox_min = np.array([-1.01, -1.01, -1.01, 1.0])
object_bbox_max = np.array([ 1.01, 1.01, 1.01, 1.0])
# Object scale mat: region of interest to **extract mesh**
object_scale_mat = np.load(os.path.join(self.data_dir, self.object_cameras_name))['scale_mat_0']
object_bbox_min = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_min[:, None]
object_bbox_max = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_max[:, None]
self.object_bbox_min = object_bbox_min[:3, 0]
self.object_bbox_max = object_bbox_max[:3, 0]
print('Load data: End')
def gen_rays_at(self, img_idx, resolution_level=1):
"""
Generate rays at world space from one camera.
"""
l = resolution_level
tx = torch.linspace(0, self.W - 1, self.W // l)
ty = torch.linspace(0, self.H - 1, self.H // l)
pixels_x, pixels_y = torch.meshgrid(tx, ty)
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1) # W, H, 3
p = torch.matmul(self.intrinsics_all_inv[img_idx, None, None, :3, :3], p[:, :, :, None]).squeeze() # W, H, 3
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # W, H, 3
rays_v = torch.matmul(self.pose_all[img_idx, None, None, :3, :3], rays_v[:, :, :, None]).squeeze() # W, H, 3
rays_o = self.pose_all[img_idx, None, None, :3, 3].expand(rays_v.shape) # W, H, 3
return rays_o.transpose(0, 1), rays_v.transpose(0, 1)
def gen_random_rays_at(self, img_idx, batch_size):
pixels_x = torch.randint(low=0, high=self.W, size=[batch_size]).to(self.device)
pixels_y = torch.randint(0, self.H, (batch_size,)).to(self.device)
color = self.images[img_idx][(pixels_y, pixels_x)] # batch_size, 3
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1).float() # batch_size, 3
p = torch.matmul(self.intrinsics_all_inv[img_idx, None, :3, :3], p[:, :, None]).squeeze() # batch_size, 3
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # batch_size, 3
rays_v = torch.matmul(self.pose_all[img_idx, None, :3, :3], rays_v[:, :, None]).squeeze() # batch_size, 3
rays_o = self.pose_all[img_idx, None, :3, 3].expand(rays_v.shape) # batch_size, 3
if self.has_masks:
mask = self.masks[img_idx][(pixels_y, pixels_x)] # batch_size, 3
return torch.cat([rays_o, rays_v, color, mask[:, :1]], dim -1)
return torch.cat([rays_o, rays_v, color], dim=-1)
def gen_rays_between(self, idx_0, idx_1, ratio, resolution_level=1):
"""
Interpolate pose between two cameras.
"""
l = resolution_level
tx = torch.linspace(0, self.W - 1, self.W // l)
ty = torch.linspace(0, self.H - 1, self.H // l)
pixels_x, pixels_y = torch.meshgrid(tx, ty)
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1) # W, H, 3
p = torch.matmul(self.intrinsics_all_inv[0, None, None, :3, :3], p[:, :, :, None]).squeeze() # W, H, 3
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # W, H, 3
trans = self.pose_all[idx_0, :3, 3] * (1.0 - ratio) + self.pose_all[idx_1, :3, 3] * ratio
pose_0 = self.pose_all[idx_0].detach().cpu().numpy()
pose_1 = self.pose_all[idx_1].detach().cpu().numpy()
pose_0 = np.linalg.inv(pose_0)
pose_1 = np.linalg.inv(pose_1)
rot_0 = pose_0[:3, :3]
rot_1 = pose_1[:3, :3]
rots = Rot.from_matrix(np.stack([rot_0, rot_1]))
key_times = [0, 1]
slerp = Slerp(key_times, rots)
rot = slerp(ratio)
pose = np.diag([1.0, 1.0, 1.0, 1.0])
pose = pose.astype(np.float32)
pose[:3, :3] = rot.as_matrix()
pose[:3, 3] = ((1.0 - ratio) * pose_0 + ratio * pose_1)[:3, 3]
pose = np.linalg.inv(pose)
rot = torch.from_numpy(pose[:3, :3]).cuda()
trans = torch.from_numpy(pose[:3, 3]).cuda()
rays_v = torch.matmul(rot[None, None, :3, :3], rays_v[:, :, :, None]).squeeze() # W, H, 3
rays_o = trans[None, None, :3].expand(rays_v.shape) # W, H, 3
return rays_o.transpose(0, 1), rays_v.transpose(0, 1)
def near_far_from_sphere(self, rays_o, rays_d):
a = torch.sum(rays_d**2, dim=-1, keepdim=True)
b = 2.0 * torch.sum(rays_o * rays_d, dim=-1, keepdim=True)
mid = 0.5 * (-b) / a
near = mid - 1.0
far = mid + 1.0
return near, far
def image_at(self, idx, resolution_level):
img = cv.imread(self.images_lis[idx])
return (cv.resize(img, (self.W // resolution_level, self.H // resolution_level))).clip(0, 255)这是有掩码监督训练的dataset.py的代码:
import torch
import torch.nn.functional as F
import cv2 as cv
import numpy as np
import os
from glob import glob
from icecream import ic
from scipy.spatial.transform import Rotation as Rot
from scipy.spatial.transform import Slerp
# This function is borrowed from IDR: https://github.com/lioryariv/idr
def load_K_Rt_from_P(filename, P=None):
if P is None:
lines = open(filename).read().splitlines()
if len(lines) == 4:
lines = lines[1:]
lines = [[x[0], x[1], x[2], x[3]] for x in (x.split(" ") for x in lines)]
P = np.asarray(lines).astype(np.float32).squeeze()
out = cv.decomposeProjectionMatrix(P)
K = out[0]
R = out[1]
t = out[2]
K = K / K[2, 2]
intrinsics = np.eye(4)
intrinsics[:3, :3] = K
pose = np.eye(4, dtype=np.float32)
pose[:3, :3] = R.transpose()
pose[:3, 3] = (t[:3] / t[3])[:, 0]
return intrinsics, pose
class Dataset:
def __init__(self, conf):
super(Dataset, self).__init__()
print('Load data: Begin')
self.device = torch.device('cuda')
self.conf = conf
self.data_dir = conf.get_string('data_dir')
self.render_cameras_name = conf.get_string('render_cameras_name')
self.object_cameras_name = conf.get_string('object_cameras_name')
self.camera_outside_sphere = conf.get_bool('camera_outside_sphere', default=True)
self.scale_mat_scale = conf.get_float('scale_mat_scale', default=1.1)
camera_dict = np.load(os.path.join(self.data_dir, self.render_cameras_name))
self.camera_dict = camera_dict
self.images_lis = sorted(glob(os.path.join(self.data_dir, 'image/*.png')))
self.n_images = len(self.images_lis)
self.images_np = np.stack([cv.imread(im_name) for im_name in self.images_lis]) / 256.0
self.masks_lis = sorted(glob(os.path.join(self.data_dir, 'mask/*.png')))
self.masks_np = np.stack([cv.imread(im_name) for im_name in self.masks_lis]) / 256.0
# world_mat is a projection matrix from world to image
self.world_mats_np = [camera_dict['world_mat_%d' % idx].astype(np.float32) for idx in range(self.n_images)]
self.scale_mats_np = []
# scale_mat: used for coordinate normalization, we assume the scene to render is inside a unit sphere at origin.
self.scale_mats_np = [camera_dict['scale_mat_%d' % idx].astype(np.float32) for idx in range(self.n_images)]
self.intrinsics_all = []
self.pose_all = []
for scale_mat, world_mat in zip(self.scale_mats_np, self.world_mats_np):
P = world_mat @ scale_mat
P = P[:3, :4]
intrinsics, pose = load_K_Rt_from_P(None, P)
self.intrinsics_all.append(torch.from_numpy(intrinsics).float())
self.pose_all.append(torch.from_numpy(pose).float())
self.images = torch.from_numpy(self.images_np.astype(np.float32)).to(self.device) # [n_images, H, W, 3]
self.masks = torch.from_numpy(self.masks_np.astype(np.float32)).to(self.device) # [n_images, H, W, 3]
self.intrinsics_all = torch.stack(self.intrinsics_all).to(self.device) # [n_images, 4, 4]
self.intrinsics_all_inv = torch.inverse(self.intrinsics_all) # [n_images, 4, 4]
self.focal = self.intrinsics_all[0][0, 0]
self.pose_all = torch.stack(self.pose_all).to(self.device) # [n_images, 4, 4]
self.H, self.W = self.images.shape[1], self.images.shape[2]
self.image_pixels = self.H * self.W
object_bbox_min = np.array([-1.01, -1.01, -1.01, 1.0])
object_bbox_max = np.array([ 1.01, 1.01, 1.01, 1.0])
# Object scale mat: region of interest to **extract mesh**
object_scale_mat = np.load(os.path.join(self.data_dir, self.object_cameras_name))['scale_mat_0']
object_bbox_min = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_min[:, None]
object_bbox_max = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_max[:, None]
self.object_bbox_min = object_bbox_min[:3, 0]
self.object_bbox_max = object_bbox_max[:3, 0]
print('Load data: End')
def gen_rays_at(self, img_idx, resolution_level=1):
"""
Generate rays at world space from one camera.
"""
l = resolution_level
tx = torch.linspace(0, self.W - 1, self.W // l)
ty = torch.linspace(0, self.H - 1, self.H // l)
pixels_x, pixels_y = torch.meshgrid(tx, ty)
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1) # W, H, 3
p = torch.matmul(self.intrinsics_all_inv[img_idx, None, None, :3, :3], p[:, :, :, None]).squeeze() # W, H, 3
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # W, H, 3
rays_v = torch.matmul(self.pose_all[img_idx, None, None, :3, :3], rays_v[:, :, :, None]).squeeze() # W, H, 3
rays_o = self.pose_all[img_idx, None, None, :3, 3].expand(rays_v.shape) # W, H, 3
return rays_o.transpose(0, 1), rays_v.transpose(0, 1)
def gen_random_rays_at(self, img_idx, batch_size):
"""
Generate random rays at world space from one camera.
"""
pixels_x = torch.randint(low=0, high=self.W, size=[batch_size]).to(self.device)
pixels_y = torch.randint(low=0, high=self.H, size=[batch_size]).to(self.device)
color = self.images[img_idx][(pixels_y, pixels_x)] # batch_size, 3
mask = self.masks[img_idx][(pixels_y, pixels_x)] # batch_size, 3
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1).float() # batch_size, 3
p = torch.matmul(self.intrinsics_all_inv[img_idx, None, :3, :3], p[:, :, None]).squeeze() # batch_size, 3
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # batch_size, 3
rays_v = torch.matmul(self.pose_all[img_idx, None, :3, :3], rays_v[:, :, None]).squeeze() # batch_size, 3
rays_o = self.pose_all[img_idx, None, :3, 3].expand(rays_v.shape) # batch_size, 3
# 确保所有张量都在 `self.device` 上
rays_o = rays_o.to(self.device)
rays_v = rays_v.to(self.device)
color = color.to(self.device)
mask = mask.to(self.device)
return torch.cat([rays_o, rays_v, color, mask[:, :1]], dim=-1)
def gen_rays_between(self, idx_0, idx_1, ratio, resolution_level=1):
"""
Interpolate pose between two cameras.
"""
l = resolution_level
tx = torch.linspace(0, self.W - 1, self.W // l)
ty = torch.linspace(0, self.H - 1, self.H // l)
pixels_x, pixels_y = torch.meshgrid(tx, ty)
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1) # W, H, 3
p = torch.matmul(self.intrinsics_all_inv[0, None, None, :3, :3], p[:, :, :, None]).squeeze() # W, H, 3
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # W, H, 3
trans = self.pose_all[idx_0, :3, 3] * (1.0 - ratio) + self.pose_all[idx_1, :3, 3] * ratio
pose_0 = self.pose_all[idx_0].detach().cpu().numpy()
pose_1 = self.pose_all[idx_1].detach().cpu().numpy()
pose_0 = np.linalg.inv(pose_0)
pose_1 = np.linalg.inv(pose_1)
rot_0 = pose_0[:3, :3]
rot_1 = pose_1[:3, :3]
rots = Rot.from_matrix(np.stack([rot_0, rot_1]))
key_times = [0, 1]
slerp = Slerp(key_times, rots)
rot = slerp(ratio)
pose = np.diag([1.0, 1.0, 1.0, 1.0])
pose = pose.astype(np.float32)
pose[:3, :3] = rot.as_matrix()
pose[:3, 3] = ((1.0 - ratio) * pose_0 + ratio * pose_1)[:3, 3]
pose = np.linalg.inv(pose)
rot = torch.from_numpy(pose[:3, :3]).cuda()
trans = torch.from_numpy(pose[:3, 3]).cuda()
rays_v = torch.matmul(rot[None, None, :3, :3], rays_v[:, :, :, None]).squeeze() # W, H, 3
rays_o = trans[None, None, :3].expand(rays_v.shape) # W, H, 3
return rays_o.transpose(0, 1), rays_v.transpose(0, 1)
def near_far_from_sphere(self, rays_o, rays_d):
a = torch.sum(rays_d**2, dim=-1, keepdim=True)
b = 2.0 * torch.sum(rays_o * rays_d, dim=-1, keepdim=True)
mid = 0.5 * (-b) / a
near = mid - 1.0
far = mid + 1.0
return near, far
def image_at(self, idx, resolution_level):
img = cv.imread(self.images_lis[idx])
return (cv.resize(img, (self.W // resolution_level, self.H // resolution_level))).clip(0, 255)这是邮电大学学长分享的无掩码监督训练的dataset.py的代码:
import torch
import torch.nn.functional as F
import cv2 as cv
import numpy as np
import os
from glob import glob
from icecream import ic
from scipy.spatial.transform import Rotation as Rot
from scipy.spatial.transform import Slerp
# This function is borrowed from IDR: https://github.com/lioryariv/idr
def load_K_Rt_from_P(filename, P=None):
if P is None:
lines = open(filename).read().splitlines()
if len(lines) == 4:
lines = lines[1:]
lines = [[x[0], x[1], x[2], x[3]] for x in (x.split(" ") for x in lines)]
P = np.asarray(lines).astype(np.float32).squeeze()
out = cv.decomposeProjectionMatrix(P)
K = out[0]
R = out[1]
t = out[2]
K = K / K[2, 2]
intrinsics = np.eye(4)
intrinsics[:3, :3] = K
pose = np.eye(4, dtype=np.float32)
pose[:3, :3] = R.transpose()
pose[:3, 3] = (t[:3] / t[3])[:, 0]
return intrinsics, pose
class Dataset:
def __init__(self, conf):
super(Dataset, self).__init__()
print('Load data: Begin')
self.device = torch.device('cuda')
self.conf = conf
self.data_dir = conf.get_string('data_dir')
self.render_cameras_name = conf.get_string('render_cameras_name')
self.object_cameras_name = conf.get_string('object_cameras_name')
self.camera_outside_sphere = conf.get_bool('camera_outside_sphere', default=True)
self.scale_mat_scale = conf.get_float('scale_mat_scale', default=1.1)
camera_dict = np.load(os.path.join(self.data_dir, self.render_cameras_name))
self.camera_dict = camera_dict
self.images_lis = sorted(glob(os.path.join(self.data_dir, 'images/*.jpg')))
print("Image paths:", self.images_lis) # 打印图像路径列表
self.n_images = len(self.images_lis)
self.images_np = np.stack([cv.imread(im_name) for im_name in self.images_lis]) / 256.0
#self.masks_lis = sorted(glob(os.path.join(self.data_dir, 'mask/*.jpg')))
#self.masks_np = np.stack([cv.imread(im_name) for im_name in self.masks_lis]) / 256.0 删除mask
# world_mat is a projection matrix from world to image
self.world_mats_np = [camera_dict['world_mat_%d' % idx].astype(np.float32) for idx in range(self.n_images)]
self.scale_mats_np = []
# scale_mat: used for coordinate normalization, we assume the scene to render is inside a unit sphere at origin.
self.scale_mats_np = [camera_dict['scale_mat_%d' % idx].astype(np.float32) for idx in range(self.n_images)]
self.intrinsics_all = []
self.pose_all = []
for scale_mat, world_mat in zip(self.scale_mats_np, self.world_mats_np):
P = world_mat @ scale_mat
P = P[:3, :4]
intrinsics, pose = load_K_Rt_from_P(None, P)
self.intrinsics_all.append(torch.from_numpy(intrinsics).float())
self.pose_all.append(torch.from_numpy(pose).float())
self.images = torch.from_numpy(self.images_np.astype(np.float32)).cpu() # [n_images, H, W, 3]
#self.masks = torch.from_numpy(self.masks_np.astype(np.float32)).cpu() # [n_images, H, W, 3] 删除mask
self.intrinsics_all = torch.stack(self.intrinsics_all).to(self.device) # [n_images, 4, 4]
self.intrinsics_all_inv = torch.inverse(self.intrinsics_all) # [n_images, 4, 4]
self.focal = self.intrinsics_all[0][0, 0]
self.pose_all = torch.stack(self.pose_all).to(self.device) # [n_images, 4, 4]
self.H, self.W = self.images.shape[1], self.images.shape[2]
self.image_pixels = self.H * self.W
object_bbox_min = np.array([-1.01, -1.01, -1.01, 1.0])
object_bbox_max = np.array([ 1.01, 1.01, 1.01, 1.0])
# Object scale mat: region of interest to **extract mesh**
object_scale_mat = np.load(os.path.join(self.data_dir, self.object_cameras_name))['scale_mat_0']
object_bbox_min = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_min[:, None]
object_bbox_max = np.linalg.inv(self.scale_mats_np[0]) @ object_scale_mat @ object_bbox_max[:, None]
self.object_bbox_min = object_bbox_min[:3, 0]
self.object_bbox_max = object_bbox_max[:3, 0]
print('Load data: End')
def gen_rays_at(self, img_idx, resolution_level=1):
"""
Generate rays at world space from one camera.
"""
l = resolution_level
tx = torch.linspace(0, self.W - 1, self.W // l)
ty = torch.linspace(0, self.H - 1, self.H // l)
pixels_x, pixels_y = torch.meshgrid(tx, ty)
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1) # W, H, 3
p = torch.matmul(self.intrinsics_all_inv[img_idx, None, None, :3, :3], p[:, :, :, None]).squeeze() # W, H, 3
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # W, H, 3
rays_v = torch.matmul(self.pose_all[img_idx, None, None, :3, :3], rays_v[:, :, :, None]).squeeze() # W, H, 3
rays_o = self.pose_all[img_idx, None, None, :3, 3].expand(rays_v.shape) # W, H, 3
return rays_o.transpose(0, 1), rays_v.transpose(0, 1)
def gen_random_rays_at(self, img_idx, batch_size):
"""
Generate random rays at world space from one camera.
"""
pixels_x = torch.randint(low=0, high=self.W, size=[batch_size])
pixels_y = torch.randint(low=0, high=self.H, size=[batch_size])
color = self.images[img_idx][(pixels_y, pixels_x)] # batch_size, 3
#mask = self.masks[img_idx][(pixels_y, pixels_x)] # batch_size, 3 删除mask
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1).float() # batch_size, 3
p = torch.matmul(self.intrinsics_all_inv[img_idx, None, :3, :3], p[:, :, None]).squeeze() # batch_size, 3
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # batch_size, 3
rays_v = torch.matmul(self.pose_all[img_idx, None, :3, :3], rays_v[:, :, None]).squeeze() # batch_size, 3
rays_o = self.pose_all[img_idx, None, :3, 3].expand(rays_v.shape) # batch_size, 3
return torch.cat([rays_o.cpu(), rays_v.cpu(), color, ], dim=-1).cuda() # batch_size, 10 修改过删除mask
def gen_rays_between(self, idx_0, idx_1, ratio, resolution_level=1):
"""
Interpolate pose between two cameras.
"""
l = resolution_level
tx = torch.linspace(0, self.W - 1, self.W // l)
ty = torch.linspace(0, self.H - 1, self.H // l)
pixels_x, pixels_y = torch.meshgrid(tx, ty)
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1) # W, H, 3
p = torch.matmul(self.intrinsics_all_inv[0, None, None, :3, :3], p[:, :, :, None]).squeeze() # W, H, 3
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # W, H, 3
trans = self.pose_all[idx_0, :3, 3] * (1.0 - ratio) + self.pose_all[idx_1, :3, 3] * ratio
pose_0 = self.pose_all[idx_0].detach().cpu().numpy()
pose_1 = self.pose_all[idx_1].detach().cpu().numpy()
pose_0 = np.linalg.inv(pose_0)
pose_1 = np.linalg.inv(pose_1)
rot_0 = pose_0[:3, :3]
rot_1 = pose_1[:3, :3]
rots = Rot.from_matrix(np.stack([rot_0, rot_1]))
key_times = [0, 1]
slerp = Slerp(key_times, rots)
rot = slerp(ratio)
pose = np.diag([1.0, 1.0, 1.0, 1.0])
pose = pose.astype(np.float32)
pose[:3, :3] = rot.as_matrix()
pose[:3, 3] = ((1.0 - ratio) * pose_0 + ratio * pose_1)[:3, 3]
pose = np.linalg.inv(pose)
rot = torch.from_numpy(pose[:3, :3]).cuda()
trans = torch.from_numpy(pose[:3, 3]).cuda()
rays_v = torch.matmul(rot[None, None, :3, :3], rays_v[:, :, :, None]).squeeze() # W, H, 3
rays_o = trans[None, None, :3].expand(rays_v.shape) # W, H, 3
return rays_o.transpose(0, 1), rays_v.transpose(0, 1)
def near_far_from_sphere(self, rays_o, rays_d):
a = torch.sum(rays_d**2, dim=-1, keepdim=True)
b = 2.0 * torch.sum(rays_o * rays_d, dim=-1, keepdim=True)
mid = 0.5 * (-b) / a
near = mid - 1.0
far = mid + 1.0
return near, far
def image_at(self, idx, resolution_level):
img = cv.imread(self.images_lis[idx])
return (cv.resize(img, (self.W // resolution_level, self.H // resolution_level))).clip(0, 255)这是修改了的无掩码监督的exp_runner.py的代码:
import os
import time
import logging
import argparse
import numpy as np
import cv2 as cv
import trimesh
import torch
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
from shutil import copyfile
from icecream import ic
from tqdm import tqdm
from pyhocon import ConfigFactory
from models.dataset import Dataset
from models.fields import RenderingNetwork, SDFNetwork, SingleVarianceNetwork, NeRF
from models.renderer import NeuSRenderer
class Runner:
def __init__(self, conf_path, mode='train', case='CASE_NAME', is_continue=False):
self.device = torch.device('cuda')
# Configuration
self.conf_path = conf_path
f = open(self.conf_path)
conf_text = f.read()
conf_text = conf_text.replace('CASE_NAME', case)
f.close()
self.conf = ConfigFactory.parse_string(conf_text)
self.conf['dataset.data_dir'] = self.conf['dataset.data_dir'].replace('CASE_NAME', case)
self.base_exp_dir = self.conf['general.base_exp_dir']
os.makedirs(self.base_exp_dir, exist_ok=True)
self.dataset = Dataset(self.conf['dataset'])
self.iter_step = 0
# Training parameters
self.end_iter = self.conf.get_int('train.end_iter')
self.save_freq = self.conf.get_int('train.save_freq')
self.report_freq = self.conf.get_int('train.report_freq')
self.val_freq = self.conf.get_int('train.val_freq')
self.val_mesh_freq = self.conf.get_int('train.val_mesh_freq')
self.batch_size = self.conf.get_int('train.batch_size')
self.validate_resolution_level = self.conf.get_int('train.validate_resolution_level')
self.learning_rate = self.conf.get_float('train.learning_rate')
self.learning_rate_alpha = self.conf.get_float('train.learning_rate_alpha')
self.use_white_bkgd = self.conf.get_bool('train.use_white_bkgd')
self.warm_up_end = self.conf.get_float('train.warm_up_end', default=0.0)
self.anneal_end = self.conf.get_float('train.anneal_end', default=0.0)
# Weights
self.igr_weight = self.conf.get_float('train.igr_weight')
self.mask_weight = self.conf.get_float('train.mask_weight')
self.is_continue = is_continue
self.mode = mode
self.model_list = []
self.writer = None
# Networks
params_to_train = []
self.nerf_outside = NeRF(**self.conf['model.nerf']).to(self.device)
self.sdf_network = SDFNetwork(**self.conf['model.sdf_network']).to(self.device)
self.deviation_network = SingleVarianceNetwork(**self.conf['model.variance_network']).to(self.device)
self.color_network = RenderingNetwork(**self.conf['model.rendering_network']).to(self.device)
params_to_train += list(self.nerf_outside.parameters())
params_to_train += list(self.sdf_network.parameters())
params_to_train += list(self.deviation_network.parameters())
params_to_train += list(self.color_network.parameters())
self.optimizer = torch.optim.Adam(params_to_train, lr=self.learning_rate)
self.renderer = NeuSRenderer(self.nerf_outside,
self.sdf_network,
self.deviation_network,
self.color_network,
**self.conf['model.neus_renderer'])
# Load checkpoint
latest_model_name = None
if is_continue:
model_list_raw = os.listdir(os.path.join(self.base_exp_dir, 'checkpoints'))
model_list = []
for model_name in model_list_raw:
if model_name[-3:] == 'pth' and int(model_name[5:-4]) <= self.end_iter:
model_list.append(model_name)
model_list.sort()
latest_model_name = model_list[-1]
if latest_model_name is not None:
logging.info('Find checkpoint: {}'.format(latest_model_name))
self.load_checkpoint(latest_model_name)
# Backup codes and configs for debug
if self.mode[:5] == 'train':
self.file_backup()
def train(self):
self.writer = SummaryWriter(log_dir=os.path.join(self.base_exp_dir, 'logs'))
self.update_learning_rate()
res_step = self.end_iter - self.iter_step
image_perm = self.get_image_perm()
for iter_i in tqdm(range(res_step)):
data = self.dataset.gen_random_rays_at(image_perm[self.iter_step % len(image_perm)], self.batch_size)
rays_o, rays_d, true_rgb = data[:, :3], data[:, 3: 6], data[:, 6: 9],
if not self.dataset.has_masks or mask.shape[1] == 0:
mask = torch.ones((self.batch_size, 1)).to(self.device) # 默认全 1 掩码
near, far = self.dataset.near_far_from_sphere(rays_o, rays_d)
background_rgb = None
if self.use_white_bkgd:
background_rgb = torch.ones([1, 3])
if self.mask_weight > 0.0:
mask = (mask > 0.5).float()
else:
mask = torch.ones_like(true_rgb[..., :1])
mask_sum = mask.sum() + 1e-5
render_out = self.renderer.render(rays_o, rays_d, near, far,
background_rgb=background_rgb,
cos_anneal_ratio=self.get_cos_anneal_ratio())
color_fine = render_out['color_fine']
s_val = render_out['s_val']
cdf_fine = render_out['cdf_fine']
gradient_error = render_out['gradient_error']
weight_max = render_out['weight_max']
weight_sum = render_out['weight_sum']
# Loss
if mask.shape[0] != color_fine.shape[0]:
# 如果掩码尺寸不匹配,扩展掩码维度
mask = mask.expand(color_fine.shape[0], 1)
color_error = (color_fine - true_rgb) * mask
color_fine_loss = F.l1_loss(color_error, torch.zeros_like(color_error), reduction='sum') / mask_sum
psnr = 20.0 * torch.log10(1.0 / (((color_fine - true_rgb)**2 * mask).sum() / (mask_sum * 3.0)).sqrt())
eikonal_loss = gradient_error
mask_loss = F.binary_cross_entropy(weight_sum.clip(1e-3, 1.0 - 1e-3), mask)
loss = color_fine_loss +\
eikonal_loss * self.igr_weight +\
mask_loss * self.mask_weight
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.iter_step += 1
self.writer.add_scalar('Loss/loss', loss, self.iter_step)
self.writer.add_scalar('Loss/color_loss', color_fine_loss, self.iter_step)
self.writer.add_scalar('Loss/eikonal_loss', eikonal_loss, self.iter_step)
self.writer.add_scalar('Statistics/s_val', s_val.mean(), self.iter_step)
self.writer.add_scalar('Statistics/cdf', (cdf_fine[:, :1] * mask).sum() / mask_sum, self.iter_step)
self.writer.add_scalar('Statistics/weight_max', (weight_max * mask).sum() / mask_sum, self.iter_step)
self.writer.add_scalar('Statistics/psnr', psnr, self.iter_step)
if self.iter_step % self.report_freq == 0:
print(self.base_exp_dir)
print('iter:{:8>d} loss = {} lr={}'.format(self.iter_step, loss, self.optimizer.param_groups[0]['lr']))
if self.iter_step % self.save_freq == 0:
self.save_checkpoint()
if self.iter_step % self.val_freq == 0:
self.validate_image()
if self.iter_step % self.val_mesh_freq == 0:
self.validate_mesh()
self.update_learning_rate()
if self.iter_step % len(image_perm) == 0:
image_perm = self.get_image_perm()
def get_image_perm(self):
return torch.randperm(self.dataset.n_images)
def get_cos_anneal_ratio(self):
if self.anneal_end == 0.0:
return 1.0
else:
return np.min([1.0, self.iter_step / self.anneal_end])
def update_learning_rate(self):
if self.iter_step < self.warm_up_end:
learning_factor = self.iter_step / self.warm_up_end
else:
alpha = self.learning_rate_alpha
progress = (self.iter_step - self.warm_up_end) / (self.end_iter - self.warm_up_end)
learning_factor = (np.cos(np.pi * progress) + 1.0) * 0.5 * (1 - alpha) + alpha
for g in self.optimizer.param_groups:
g['lr'] = self.learning_rate * learning_factor
def file_backup(self):
dir_lis = self.conf['general.recording']
os.makedirs(os.path.join(self.base_exp_dir, 'recording'), exist_ok=True)
for dir_name in dir_lis:
cur_dir = os.path.join(self.base_exp_dir, 'recording', dir_name)
os.makedirs(cur_dir, exist_ok=True)
files = os.listdir(dir_name)
for f_name in files:
if f_name[-3:] == '.py':
copyfile(os.path.join(dir_name, f_name), os.path.join(cur_dir, f_name))
copyfile(self.conf_path, os.path.join(self.base_exp_dir, 'recording', 'config.conf'))
def load_checkpoint(self, checkpoint_name):
checkpoint = torch.load(os.path.join(self.base_exp_dir, 'checkpoints', checkpoint_name), map_location=self.device)
self.nerf_outside.load_state_dict(checkpoint['nerf'])
self.sdf_network.load_state_dict(checkpoint['sdf_network_fine'])
self.deviation_network.load_state_dict(checkpoint['variance_network_fine'])
self.color_network.load_state_dict(checkpoint['color_network_fine'])
self.optimizer.load_state_dict(checkpoint['optimizer'])
self.iter_step = checkpoint['iter_step']
logging.info('End')
def save_checkpoint(self):
checkpoint = {
'nerf': self.nerf_outside.state_dict(),
'sdf_network_fine': self.sdf_network.state_dict(),
'variance_network_fine': self.deviation_network.state_dict(),
'color_network_fine': self.color_network.state_dict(),
'optimizer': self.optimizer.state_dict(),
'iter_step': self.iter_step,
}
os.makedirs(os.path.join(self.base_exp_dir, 'checkpoints'), exist_ok=True)
torch.save(checkpoint, os.path.join(self.base_exp_dir, 'checkpoints', 'ckpt_{:0>6d}.pth'.format(self.iter_step)))
def validate_image(self, idx=-1, resolution_level=-1):
if idx < 0:
idx = np.random.randint(self.dataset.n_images)
print('Validate: iter: {}, camera: {}'.format(self.iter_step, idx))
if resolution_level < 0:
resolution_level = self.validate_resolution_level
rays_o, rays_d = self.dataset.gen_rays_at(idx, resolution_level=resolution_level)
H, W, _ = rays_o.shape
rays_o = rays_o.reshape(-1, 3).split(self.batch_size)
rays_d = rays_d.reshape(-1, 3).split(self.batch_size)
out_rgb_fine = []
out_normal_fine = []
for rays_o_batch, rays_d_batch in zip(rays_o, rays_d):
near, far = self.dataset.near_far_from_sphere(rays_o_batch, rays_d_batch)
background_rgb = torch.ones([1, 3]) if self.use_white_bkgd else None
render_out = self.renderer.render(rays_o_batch,
rays_d_batch,
near,
far,
cos_anneal_ratio=self.get_cos_anneal_ratio(),
background_rgb=background_rgb)
def feasible(key): return (key in render_out) and (render_out[key] is not None)
if feasible('color_fine'):
out_rgb_fine.append(render_out['color_fine'].detach().cpu().numpy())
if feasible('gradients') and feasible('weights'):
n_samples = self.renderer.n_samples + self.renderer.n_importance
normals = render_out['gradients'] * render_out['weights'][:, :n_samples, None]
if feasible('inside_sphere'):
normals = normals * render_out['inside_sphere'][..., None]
normals = normals.sum(dim=1).detach().cpu().numpy()
out_normal_fine.append(normals)
del render_out
img_fine = None
if len(out_rgb_fine) > 0:
img_fine = (np.concatenate(out_rgb_fine, axis=0).reshape([H, W, 3, -1]) * 256).clip(0, 255)
normal_img = None
if len(out_normal_fine) > 0:
normal_img = np.concatenate(out_normal_fine, axis=0)
rot = np.linalg.inv(self.dataset.pose_all[idx, :3, :3].detach().cpu().numpy())
normal_img = (np.matmul(rot[None, :, :], normal_img[:, :, None])
.reshape([H, W, 3, -1]) * 128 + 128).clip(0, 255)
os.makedirs(os.path.join(self.base_exp_dir, 'validations_fine'), exist_ok=True)
os.makedirs(os.path.join(self.base_exp_dir, 'normals'), exist_ok=True)
for i in range(img_fine.shape[-1]):
if len(out_rgb_fine) > 0:
cv.imwrite(os.path.join(self.base_exp_dir,
'validations_fine',
'{:0>8d}_{}_{}.png'.format(self.iter_step, i, idx)),
np.concatenate([img_fine[..., i],
self.dataset.image_at(idx, resolution_level=resolution_level)]))
if len(out_normal_fine) > 0:
cv.imwrite(os.path.join(self.base_exp_dir,
'normals',
'{:0>8d}_{}_{}.png'.format(self.iter_step, i, idx)),
normal_img[..., i])
def render_novel_image(self, idx_0, idx_1, ratio, resolution_level):
"""
Interpolate view between two cameras.
"""
rays_o, rays_d = self.dataset.gen_rays_between(idx_0, idx_1, ratio, resolution_level=resolution_level)
H, W, _ = rays_o.shape
rays_o = rays_o.reshape(-1, 3).split(self.batch_size)
rays_d = rays_d.reshape(-1, 3).split(self.batch_size)
out_rgb_fine = []
for rays_o_batch, rays_d_batch in zip(rays_o, rays_d):
near, far = self.dataset.near_far_from_sphere(rays_o_batch, rays_d_batch)
background_rgb = torch.ones([1, 3]) if self.use_white_bkgd else None
render_out = self.renderer.render(rays_o_batch,
rays_d_batch,
near,
far,
cos_anneal_ratio=self.get_cos_anneal_ratio(),
background_rgb=background_rgb)
out_rgb_fine.append(render_out['color_fine'].detach().cpu().numpy())
del render_out
img_fine = (np.concatenate(out_rgb_fine, axis=0).reshape([H, W, 3]) * 256).clip(0, 255).astype(np.uint8)
return img_fine
def validate_mesh(self, world_space=False, resolution=64, threshold=0.0):
bound_min = torch.tensor(self.dataset.object_bbox_min, dtype=torch.float32)
bound_max = torch.tensor(self.dataset.object_bbox_max, dtype=torch.float32)
vertices, triangles =\
self.renderer.extract_geometry(bound_min, bound_max, resolution=resolution, threshold=threshold)
os.makedirs(os.path.join(self.base_exp_dir, 'meshes'), exist_ok=True)
if world_space:
vertices = vertices * self.dataset.scale_mats_np[0][0, 0] + self.dataset.scale_mats_np[0][:3, 3][None]
mesh = trimesh.Trimesh(vertices, triangles)
mesh.export(os.path.join(self.base_exp_dir, 'meshes', '{:0>8d}.ply'.format(self.iter_step)))
logging.info('End')
def interpolate_view(self, img_idx_0, img_idx_1):
images = []
n_frames = 60
for i in range(n_frames):
print(i)
images.append(self.render_novel_image(img_idx_0,
img_idx_1,
np.sin(((i / n_frames) - 0.5) * np.pi) * 0.5 + 0.5,
resolution_level=4))
for i in range(n_frames):
images.append(images[n_frames - i - 1])
fourcc = cv.VideoWriter_fourcc(*'mp4v')
video_dir = os.path.join(self.base_exp_dir, 'render')
os.makedirs(video_dir, exist_ok=True)
h, w, _ = images[0].shape
writer = cv.VideoWriter(os.path.join(video_dir,
'{:0>8d}_{}_{}.mp4'.format(self.iter_step, img_idx_0, img_idx_1)),
fourcc, 30, (w, h))
for image in images:
writer.write(image)
writer.release()
if __name__ == '__main__':
print('Hello Wooden')
torch.set_default_tensor_type('torch.cuda.FloatTensor')
FORMAT = "[%(filename)s:%(lineno)s - %(funcName)20s() ] %(message)s"
logging.basicConfig(level=logging.DEBUG, format=FORMAT)
parser = argparse.ArgumentParser()
parser.add_argument('--conf', type=str, default='./confs/base.conf')
parser.add_argument('--mode', type=str, default='train')
parser.add_argument('--mcube_threshold', type=float, default=0.0)
parser.add_argument('--is_continue', default=False, action="store_true")
parser.add_argument('--gpu', type=int, default=0)
parser.add_argument('--case', type=str, default='')
args = parser.parse_args()
torch.cuda.set_device(args.gpu)
runner = Runner(args.conf, args.mode, args.case, args.is_continue)
if args.mode == 'train':
runner.train()
elif args.mode == 'validate_mesh':
runner.validate_mesh(world_space=True, resolution=512, threshold=args.mcube_threshold)
elif args.mode.startswith('interpolate'): # Interpolate views given two image indices
_, img_idx_0, img_idx_1 = args.mode.split('_')
img_idx_0 = int(img_idx_0)
img_idx_1 = int(img_idx_1)
runner.interpolate_view(img_idx_0, img_idx_1)这是有掩码监督的exp_runner.py的代码:
import os
import time
import logging
import argparse
import numpy as np
import cv2 as cv
import trimesh
import torch
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
from shutil import copyfile
from icecream import ic
from tqdm import tqdm
from pyhocon import ConfigFactory
from models.dataset import Dataset
from models.fields import RenderingNetwork, SDFNetwork, SingleVarianceNetwork, NeRF
from models.renderer import NeuSRenderer
class Runner:
def __init__(self, conf_path, mode='train', case='CASE_NAME', is_continue=False):
self.device = torch.device('cuda')
# Configuration
self.conf_path = conf_path
f = open(self.conf_path)
conf_text = f.read()
conf_text = conf_text.replace('CASE_NAME', case)
f.close()
self.conf = ConfigFactory.parse_string(conf_text)
self.conf['dataset.data_dir'] = self.conf['dataset.data_dir'].replace('CASE_NAME', case)
self.base_exp_dir = self.conf['general.base_exp_dir']
os.makedirs(self.base_exp_dir, exist_ok=True)
self.dataset = Dataset(self.conf['dataset'])
self.iter_step = 0
# Training parameters
self.end_iter = self.conf.get_int('train.end_iter')
self.save_freq = self.conf.get_int('train.save_freq')
self.report_freq = self.conf.get_int('train.report_freq')
self.val_freq = self.conf.get_int('train.val_freq')
self.val_mesh_freq = self.conf.get_int('train.val_mesh_freq')
self.batch_size = self.conf.get_int('train.batch_size')
self.validate_resolution_level = self.conf.get_int('train.validate_resolution_level')
self.learning_rate = self.conf.get_float('train.learning_rate')
self.learning_rate_alpha = self.conf.get_float('train.learning_rate_alpha')
self.use_white_bkgd = self.conf.get_bool('train.use_white_bkgd')
self.warm_up_end = self.conf.get_float('train.warm_up_end', default=0.0)
self.anneal_end = self.conf.get_float('train.anneal_end', default=0.0)
# Weights
self.igr_weight = self.conf.get_float('train.igr_weight')
self.mask_weight = self.conf.get_float('train.mask_weight')
self.is_continue = is_continue
self.mode = mode
self.model_list = []
self.writer = None
# Networks
params_to_train = []
self.nerf_outside = NeRF(**self.conf['model.nerf']).to(self.device)
self.sdf_network = SDFNetwork(**self.conf['model.sdf_network']).to(self.device)
self.deviation_network = SingleVarianceNetwork(**self.conf['model.variance_network']).to(self.device)
self.color_network = RenderingNetwork(**self.conf['model.rendering_network']).to(self.device)
params_to_train += list(self.nerf_outside.parameters())
params_to_train += list(self.sdf_network.parameters())
params_to_train += list(self.deviation_network.parameters())
params_to_train += list(self.color_network.parameters())
self.optimizer = torch.optim.Adam(params_to_train, lr=self.learning_rate)
self.renderer = NeuSRenderer(self.nerf_outside,
self.sdf_network,
self.deviation_network,
self.color_network,
**self.conf['model.neus_renderer'])
# Load checkpoint
latest_model_name = None
if is_continue:
model_list_raw = os.listdir(os.path.join(self.base_exp_dir, 'checkpoints'))
model_list = []
for model_name in model_list_raw:
if model_name[-3:] == 'pth' and int(model_name[5:-4]) <= self.end_iter:
model_list.append(model_name)
model_list.sort()
latest_model_name = model_list[-1]
if latest_model_name is not None:
logging.info('Find checkpoint: {}'.format(latest_model_name))
self.load_checkpoint(latest_model_name)
# Backup codes and configs for debug
if self.mode[:5] == 'train':
self.file_backup()
def train(self):
self.writer = SummaryWriter(log_dir=os.path.join(self.base_exp_dir, 'logs'))
self.update_learning_rate()
res_step = self.end_iter - self.iter_step
image_perm = self.get_image_perm()
for iter_i in tqdm(range(res_step)):
data = self.dataset.gen_random_rays_at(image_perm[self.iter_step % len(image_perm)], self.batch_size)
rays_o, rays_d, true_rgb, mask = data[:, :3], data[:, 3: 6], data[:, 6: 9], data[:, 9: 10]
near, far = self.dataset.near_far_from_sphere(rays_o, rays_d)
background_rgb = None
if self.use_white_bkgd:
background_rgb = torch.ones([1, 3])
if self.mask_weight > 0.0:
mask = (mask > 0.5).float()
else:
mask = torch.ones_like(mask)
mask_sum = mask.sum() + 1e-5
render_out = self.renderer.render(rays_o, rays_d, near, far,
background_rgb=background_rgb,
cos_anneal_ratio=self.get_cos_anneal_ratio())
color_fine = render_out['color_fine']
s_val = render_out['s_val']
cdf_fine = render_out['cdf_fine']
gradient_error = render_out['gradient_error']
weight_max = render_out['weight_max']
weight_sum = render_out['weight_sum']
# Loss
color_error = (color_fine - true_rgb) * mask
color_fine_loss = F.l1_loss(color_error, torch.zeros_like(color_error), reduction='sum') / mask_sum
psnr = 20.0 * torch.log10(1.0 / (((color_fine - true_rgb)**2 * mask).sum() / (mask_sum * 3.0)).sqrt())
eikonal_loss = gradient_error
mask_loss = F.binary_cross_entropy(weight_sum.clip(1e-3, 1.0 - 1e-3), mask)
loss = color_fine_loss +\
eikonal_loss * self.igr_weight +\
mask_loss * self.mask_weight
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.iter_step += 1
self.writer.add_scalar('Loss/loss', loss, self.iter_step)
self.writer.add_scalar('Loss/color_loss', color_fine_loss, self.iter_step)
self.writer.add_scalar('Loss/eikonal_loss', eikonal_loss, self.iter_step)
self.writer.add_scalar('Statistics/s_val', s_val.mean(), self.iter_step)
self.writer.add_scalar('Statistics/cdf', (cdf_fine[:, :1] * mask).sum() / mask_sum, self.iter_step)
self.writer.add_scalar('Statistics/weight_max', (weight_max * mask).sum() / mask_sum, self.iter_step)
self.writer.add_scalar('Statistics/psnr', psnr, self.iter_step)
if self.iter_step % self.report_freq == 0:
print(self.base_exp_dir)
print('iter:{:8>d} loss = {} lr={}'.format(self.iter_step, loss, self.optimizer.param_groups[0]['lr']))
if self.iter_step % self.save_freq == 0:
self.save_checkpoint()
if self.iter_step % self.val_freq == 0:
self.validate_image()
if self.iter_step % self.val_mesh_freq == 0:
self.validate_mesh()
self.update_learning_rate()
if self.iter_step % len(image_perm) == 0:
image_perm = self.get_image_perm()
def get_image_perm(self):
return torch.randperm(self.dataset.n_images)
def get_cos_anneal_ratio(self):
if self.anneal_end == 0.0:
return 1.0
else:
return np.min([1.0, self.iter_step / self.anneal_end])
def update_learning_rate(self):
if self.iter_step < self.warm_up_end:
learning_factor = self.iter_step / self.warm_up_end
else:
alpha = self.learning_rate_alpha
progress = (self.iter_step - self.warm_up_end) / (self.end_iter - self.warm_up_end)
learning_factor = (np.cos(np.pi * progress) + 1.0) * 0.5 * (1 - alpha) + alpha
for g in self.optimizer.param_groups:
g['lr'] = self.learning_rate * learning_factor
def file_backup(self):
dir_lis = self.conf['general.recording']
os.makedirs(os.path.join(self.base_exp_dir, 'recording'), exist_ok=True)
for dir_name in dir_lis:
cur_dir = os.path.join(self.base_exp_dir, 'recording', dir_name)
os.makedirs(cur_dir, exist_ok=True)
files = os.listdir(dir_name)
for f_name in files:
if f_name[-3:] == '.py':
copyfile(os.path.join(dir_name, f_name), os.path.join(cur_dir, f_name))
copyfile(self.conf_path, os.path.join(self.base_exp_dir, 'recording', 'config.conf'))
def load_checkpoint(self, checkpoint_name):
checkpoint = torch.load(os.path.join(self.base_exp_dir, 'checkpoints', checkpoint_name), map_location=self.device)
self.nerf_outside.load_state_dict(checkpoint['nerf'])
self.sdf_network.load_state_dict(checkpoint['sdf_network_fine'])
self.deviation_network.load_state_dict(checkpoint['variance_network_fine'])
self.color_network.load_state_dict(checkpoint['color_network_fine'])
self.optimizer.load_state_dict(checkpoint['optimizer'])
self.iter_step = checkpoint['iter_step']
logging.info('End')
def save_checkpoint(self):
checkpoint = {
'nerf': self.nerf_outside.state_dict(),
'sdf_network_fine': self.sdf_network.state_dict(),
'variance_network_fine': self.deviation_network.state_dict(),
'color_network_fine': self.color_network.state_dict(),
'optimizer': self.optimizer.state_dict(),
'iter_step': self.iter_step,
}
os.makedirs(os.path.join(self.base_exp_dir, 'checkpoints'), exist_ok=True)
torch.save(checkpoint, os.path.join(self.base_exp_dir, 'checkpoints', 'ckpt_{:0>6d}.pth'.format(self.iter_step)))
def validate_image(self, idx=-1, resolution_level=-1):
if idx < 0:
idx = np.random.randint(self.dataset.n_images)
print('Validate: iter: {}, camera: {}'.format(self.iter_step, idx))
if resolution_level < 0:
resolution_level = self.validate_resolution_level
rays_o, rays_d = self.dataset.gen_rays_at(idx, resolution_level=resolution_level)
H, W, _ = rays_o.shape
rays_o = rays_o.reshape(-1, 3).split(self.batch_size)
rays_d = rays_d.reshape(-1, 3).split(self.batch_size)
out_rgb_fine = []
out_normal_fine = []
for rays_o_batch, rays_d_batch in zip(rays_o, rays_d):
near, far = self.dataset.near_far_from_sphere(rays_o_batch, rays_d_batch)
background_rgb = torch.ones([1, 3]) if self.use_white_bkgd else None
render_out = self.renderer.render(rays_o_batch,
rays_d_batch,
near,
far,
cos_anneal_ratio=self.get_cos_anneal_ratio(),
background_rgb=background_rgb)
def feasible(key): return (key in render_out) and (render_out[key] is not None)
if feasible('color_fine'):
out_rgb_fine.append(render_out['color_fine'].detach().cpu().numpy())
if feasible('gradients') and feasible('weights'):
n_samples = self.renderer.n_samples + self.renderer.n_importance
normals = render_out['gradients'] * render_out['weights'][:, :n_samples, None]
if feasible('inside_sphere'):
normals = normals * render_out['inside_sphere'][..., None]
normals = normals.sum(dim=1).detach().cpu().numpy()
out_normal_fine.append(normals)
del render_out
img_fine = None
if len(out_rgb_fine) > 0:
img_fine = (np.concatenate(out_rgb_fine, axis=0).reshape([H, W, 3, -1]) * 256).clip(0, 255)
normal_img = None
if len(out_normal_fine) > 0:
normal_img = np.concatenate(out_normal_fine, axis=0)
rot = np.linalg.inv(self.dataset.pose_all[idx, :3, :3].detach().cpu().numpy())
normal_img = (np.matmul(rot[None, :, :], normal_img[:, :, None])
.reshape([H, W, 3, -1]) * 128 + 128).clip(0, 255)
os.makedirs(os.path.join(self.base_exp_dir, 'validations_fine'), exist_ok=True)
os.makedirs(os.path.join(self.base_exp_dir, 'normals'), exist_ok=True)
for i in range(img_fine.shape[-1]):
if len(out_rgb_fine) > 0:
cv.imwrite(os.path.join(self.base_exp_dir,
'validations_fine',
'{:0>8d}_{}_{}.png'.format(self.iter_step, i, idx)),
np.concatenate([img_fine[..., i],
self.dataset.image_at(idx, resolution_level=resolution_level)]))
if len(out_normal_fine) > 0:
cv.imwrite(os.path.join(self.base_exp_dir,
'normals',
'{:0>8d}_{}_{}.png'.format(self.iter_step, i, idx)),
normal_img[..., i])
def render_novel_image(self, idx_0, idx_1, ratio, resolution_level):
"""
Interpolate view between two cameras.
"""
rays_o, rays_d = self.dataset.gen_rays_between(idx_0, idx_1, ratio, resolution_level=resolution_level)
H, W, _ = rays_o.shape
rays_o = rays_o.reshape(-1, 3).split(self.batch_size)
rays_d = rays_d.reshape(-1, 3).split(self.batch_size)
out_rgb_fine = []
for rays_o_batch, rays_d_batch in zip(rays_o, rays_d):
near, far = self.dataset.near_far_from_sphere(rays_o_batch, rays_d_batch)
background_rgb = torch.ones([1, 3]) if self.use_white_bkgd else None
render_out = self.renderer.render(rays_o_batch,
rays_d_batch,
near,
far,
cos_anneal_ratio=self.get_cos_anneal_ratio(),
background_rgb=background_rgb)
out_rgb_fine.append(render_out['color_fine'].detach().cpu().numpy())
del render_out
img_fine = (np.concatenate(out_rgb_fine, axis=0).reshape([H, W, 3]) * 256).clip(0, 255).astype(np.uint8)
return img_fine
def validate_mesh(self, world_space=False, resolution=64, threshold=0.0):
bound_min = torch.tensor(self.dataset.object_bbox_min, dtype=torch.float32)
bound_max = torch.tensor(self.dataset.object_bbox_max, dtype=torch.float32)
vertices, triangles =\
self.renderer.extract_geometry(bound_min, bound_max, resolution=resolution, threshold=threshold)
os.makedirs(os.path.join(self.base_exp_dir, 'meshes'), exist_ok=True)
if world_space:
vertices = vertices * self.dataset.scale_mats_np[0][0, 0] + self.dataset.scale_mats_np[0][:3, 3][None]
mesh = trimesh.Trimesh(vertices, triangles)
mesh.export(os.path.join(self.base_exp_dir, 'meshes', '{:0>8d}.ply'.format(self.iter_step)))
logging.info('End')
def interpolate_view(self, img_idx_0, img_idx_1):
images = []
n_frames = 60
for i in range(n_frames):
print(i)
images.append(self.render_novel_image(img_idx_0,
img_idx_1,
np.sin(((i / n_frames) - 0.5) * np.pi) * 0.5 + 0.5,
resolution_level=4))
for i in range(n_frames):
images.append(images[n_frames - i - 1])
fourcc = cv.VideoWriter_fourcc(*'mp4v')
video_dir = os.path.join(self.base_exp_dir, 'render')
os.makedirs(video_dir, exist_ok=True)
h, w, _ = images[0].shape
writer = cv.VideoWriter(os.path.join(video_dir,
'{:0>8d}_{}_{}.mp4'.format(self.iter_step, img_idx_0, img_idx_1)),
fourcc, 30, (w, h))
for image in images:
writer.write(image)
writer.release()
if __name__ == '__main__':
print('Hello Wooden')
torch.set_default_tensor_type('torch.cuda.FloatTensor')
FORMAT = "[%(filename)s:%(lineno)s - %(funcName)20s() ] %(message)s"
logging.basicConfig(level=logging.DEBUG, format=FORMAT)
parser = argparse.ArgumentParser()
parser.add_argument('--conf', type=str, default='./confs/base.conf')
parser.add_argument('--mode', type=str, default='train')
parser.add_argument('--mcube_threshold', type=float, default=0.0)
parser.add_argument('--is_continue', default=False, action="store_true")
parser.add_argument('--gpu', type=int, default=0)
parser.add_argument('--case', type=str, default='')
args = parser.parse_args()
torch.cuda.set_device(args.gpu)
runner = Runner(args.conf, args.mode, args.case, args.is_continue)
if args.mode == 'train':
runner.train()
elif args.mode == 'validate_mesh':
runner.validate_mesh(world_space=True, resolution=512, threshold=args.mcube_threshold)
elif args.mode.startswith('interpolate'): # Interpolate views given two image indices
_, img_idx_0, img_idx_1 = args.mode.split('_')
img_idx_0 = int(img_idx_0)
img_idx_1 = int(img_idx_1)
runner.interpolate_view(img_idx_0, img_idx_1)通过5.1和5.2节的内容成功运行了无掩码监督训练的命令,但是最后三维重建的结果什么也没有,更别说表面重建的结果和渲染的视频,这说明可能是自制的数据集出现了问题,也可能是修改的代码出现了问题。因此在咨询师姐之后我又返回github上的Neus项目,准备按照Github上作者的方法自制数据集。
1.3 使用COLMAP制作自己的Neus(DTU格式)的植物数据集(参考github的Neus项目)
1.3.1 Ubuntu系统中安装colmap
按照网上的教程一步一步试错出来的,中间出现了很多版本不兼容和依赖库的问题,但是都解决了,过程过于繁琐,没有记录。
1.3.2 自制数据集过程
根据网址NeuS/preprocess_custom_data 在主 ·龙猫97/NeuS ·GitHub上就可以按照Neus项目的方式自制数据集,然后用自制的数据集来训练Neus。
这里我选择制作DTU格式的N3植物数据集:

在正式制作DTU格式的数据集之前,先对N3植物数据集做一些预处理,首先将所有的图片名称改为000.png、001.png、……、100.png、……这样的格式,批量修改文件名称参考视频一分钟学会,快速批量更改文件名,超级简单哔哩哔哩bilibili。
然后图片的尺寸要统一,每张图片分辨率要一样,如果感觉图片原尺寸大,可以把图片分辨率改为原来的一半试试,这里N3数据集是符合要求的。
然后将N3数据集压缩成压缩包,传入autodl,然后用unzip解压至如下路径:
然后在N3文件夹中创建images文件夹(运行colmap时,它是在指定的路径下去找images文件夹里面存储的图片),然后把图片全部放入images文件夹中
到这一步就可以按照Neus项目自制数据集的步骤开始操作了。
这里我选择根据Neus项目的option2做,也就是使用colmap自制数据集。
首先运行colmap,注意运行下述命令需要在autodl-tmp/NeuS目录下跑(不然会因为路径报错),也就是运行如下命令
python preprocess_custom_data/colmap_preprocess/imgs2poses.py public_data/N3
运行上述命令后,稀疏点云将保存在autodl-tmp/NeuS/public_data/N3/sparse_points.ply中。
将sparse_points.ply下载下来,如下图所示:

然后去定义感兴趣的区域,原始稀疏点云可能很嘈杂,可能不适合定义感兴趣区域(白框表示点云的边界框):

可能需要自己清洁它(这里我们使用 Meshlab 手动清洁它)。清洗后:

然后将其另存为sparse_points_interest.ply,上传至autodl的目录autodl-tmp/NeuS/public_data/N3/sparse_points_interest.ply中。
然后又运行如下命令(注意在autodl-tmp/Neus目录下),对colmap处理的结果进行预处理,从而得到满足格式要求的数据集(数据集里面就包含三个东西:①image;②npz;③mask)
python preprocess_custom_data/colmap_preprocess/gen_cameras.py public_data/N3
然后预处理的数据可以在autodl-tmp/NeuS/public_data/N3/preprocessed中找到,至此就制作完成。
1.4 使用自制的植物数据集训练Neus(参考github的Neus项目)
1.4.1 大叶植物
有掩码训练
python exp_runner.py --mode train --conf ./confs/wmask.conf --case Physalis
训练的结果可以在目录autodltmp/NueS/exp/Physalis/wmask/meshes/300000.ply中找到。每个5000轮次输出一次训练三维重建的结果。
从训练模型中提取表面(有掩码)
python exp_runner.py --mode validate_mesh --conf ./confs/wmask.conf --case Physalis --is_continue
提取的结果可以在目录autodl-tmp/NueS/exp/Physalis/wmask/meshes/300000.ply中找到。只对最后一个训练轮次(300000轮次)进行表面提取,对于前面训练的三维重建的结果不进行表面提取。
视频插值
python exp_runner.py --mode interpolate_0_1 --conf ./confs/wmask.conf --case Physalis --is_continue
这行命令是为了得到渲染视频。视图插值的相应图像集可以exp/Physalis/wmask/render/中找到。
有掩码监督的训练模型(30万次)

有掩码监督的训练模型的表面提取结果(30万次)

渲染得到的视频

5.4.2 M4
有掩码训练
python exp_runner.py --mode train --conf ./confs/wmask.conf --case M4
训练的结果可以在目录autodltmp/NueS/exp/M4/wmask/meshes/300000.ply中找到。每个5000轮次输出一次训练三维重建的结果。
从训练模型中提取表面(有掩码)
python exp_runner.py --mode validate_mesh --conf ./confs/wmask.conf --case M4 --is_continue
提取的结果可以在目录autodl-tmp/NueS/exp/M4/wmask/meshes/300000.ply中找到。只对最后一个训练轮次(300000轮次)进行表面提取,对于前面训练的三维重建的结果不进行表面提取。
视频插值
python exp_runner.py --mode interpolate_0_1 --conf ./confs/wmask.conf --case M4 --is_continue
这行命令是为了得到渲染视频。视图插值的相应图像集可以exp/Physalis/wmask/render/中找到。
有掩码监督的训练模型(30万次)
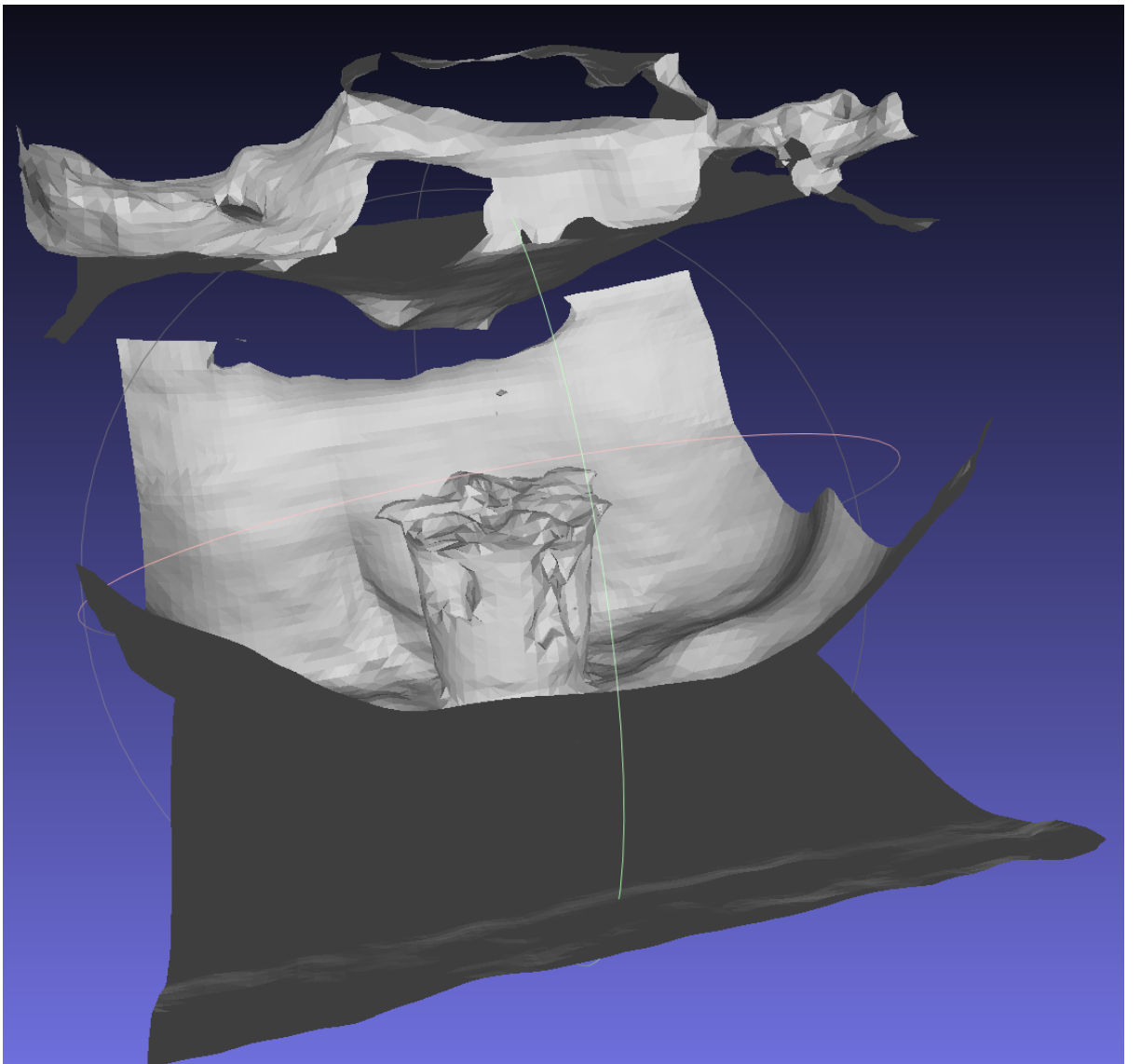
有掩码监督的训练模型的表面提取结果(30万次)

渲染得到的视频


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 32
32 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)