【数据结构】排序(sort) -- 归并排序(merge sort)
目录
一、前言
常见的排序算法有:
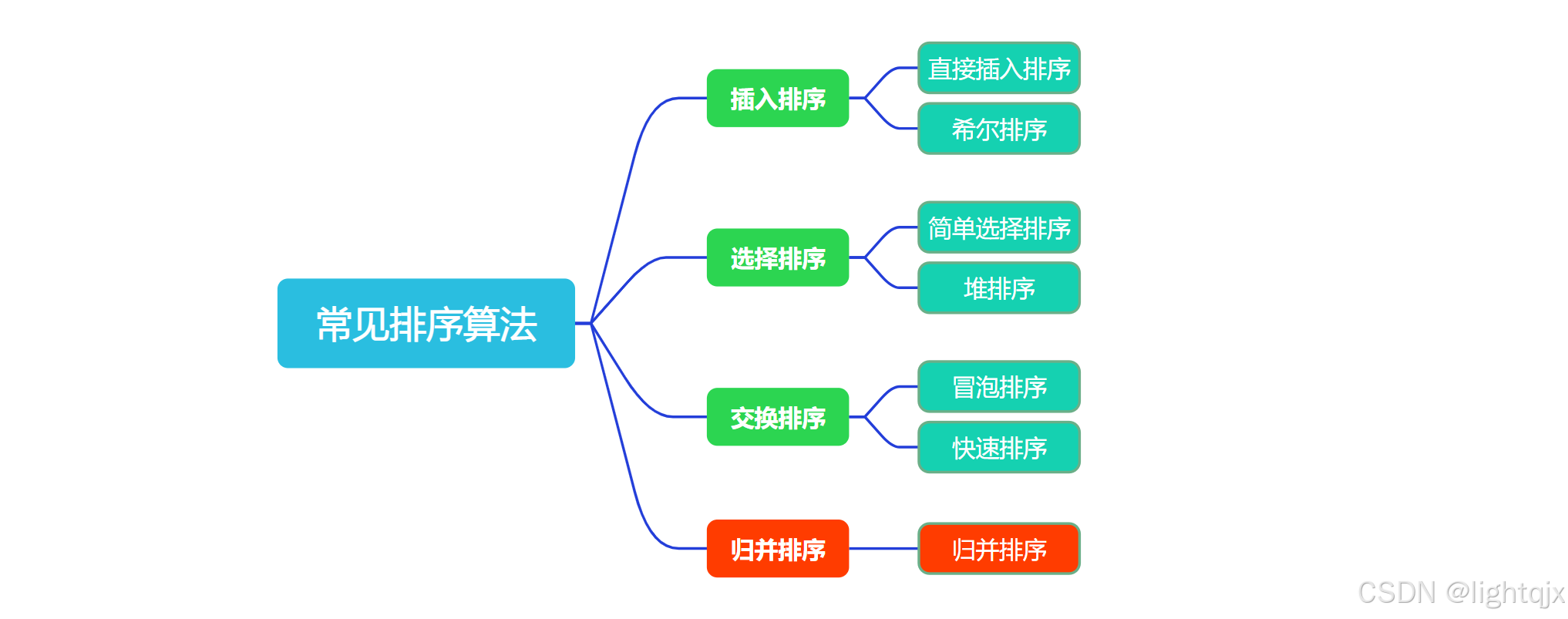
在上述几个排序算法中,最难的就是归并排序了。本章要介绍的便是 归并排序(merge sort)。
二、基本思想
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。归并是将两个或两个以上的有序序列归并成一个有序序列,归并排序的主要思想是将若干有序序列逐步归并,最终归并为一个有序序列。将两个有序表合并成一个有序表,称为二路归并。
二路归并排序是归并排序中最简单的排序方法。
三、排序思路
归并排序的具体思路:
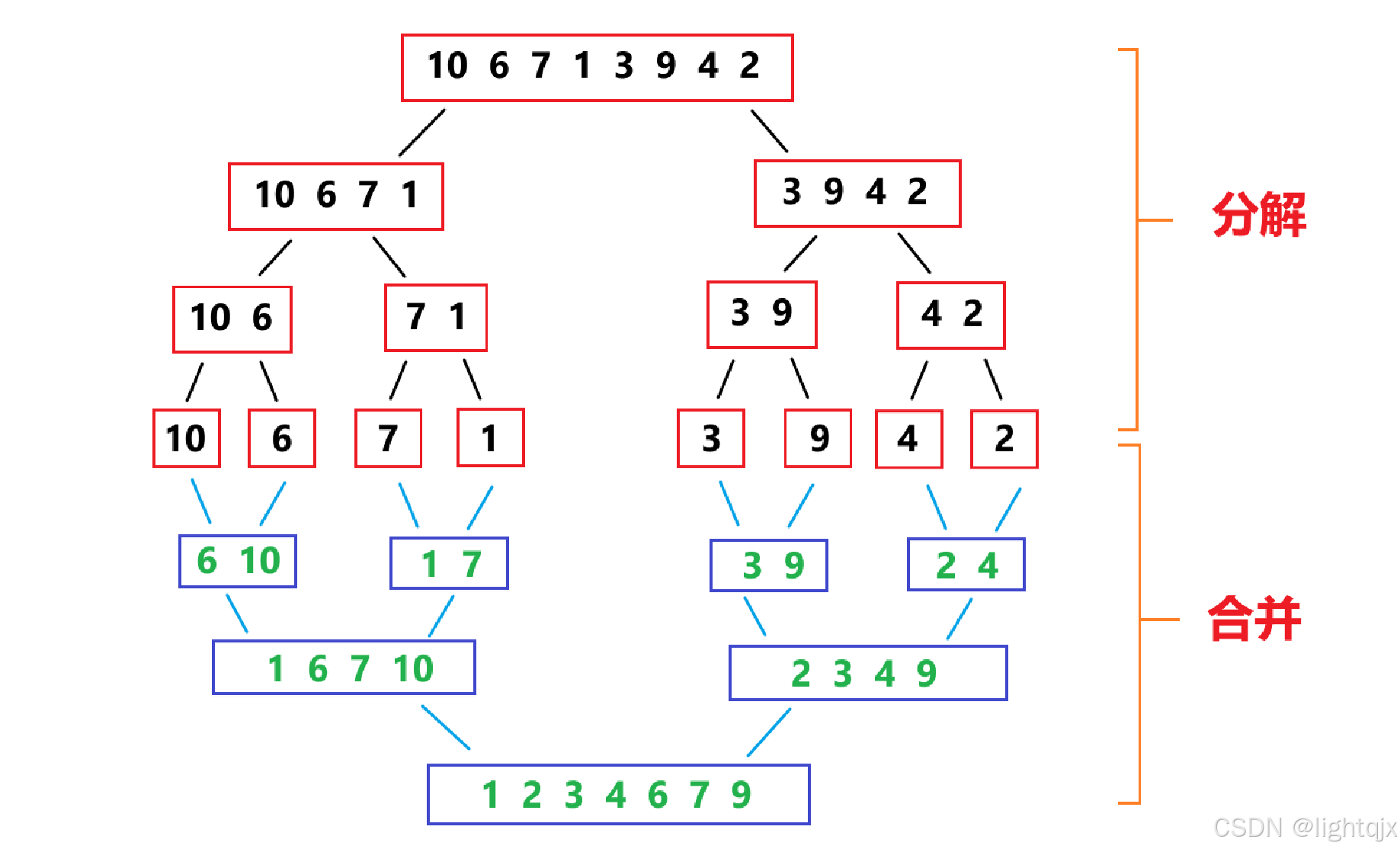
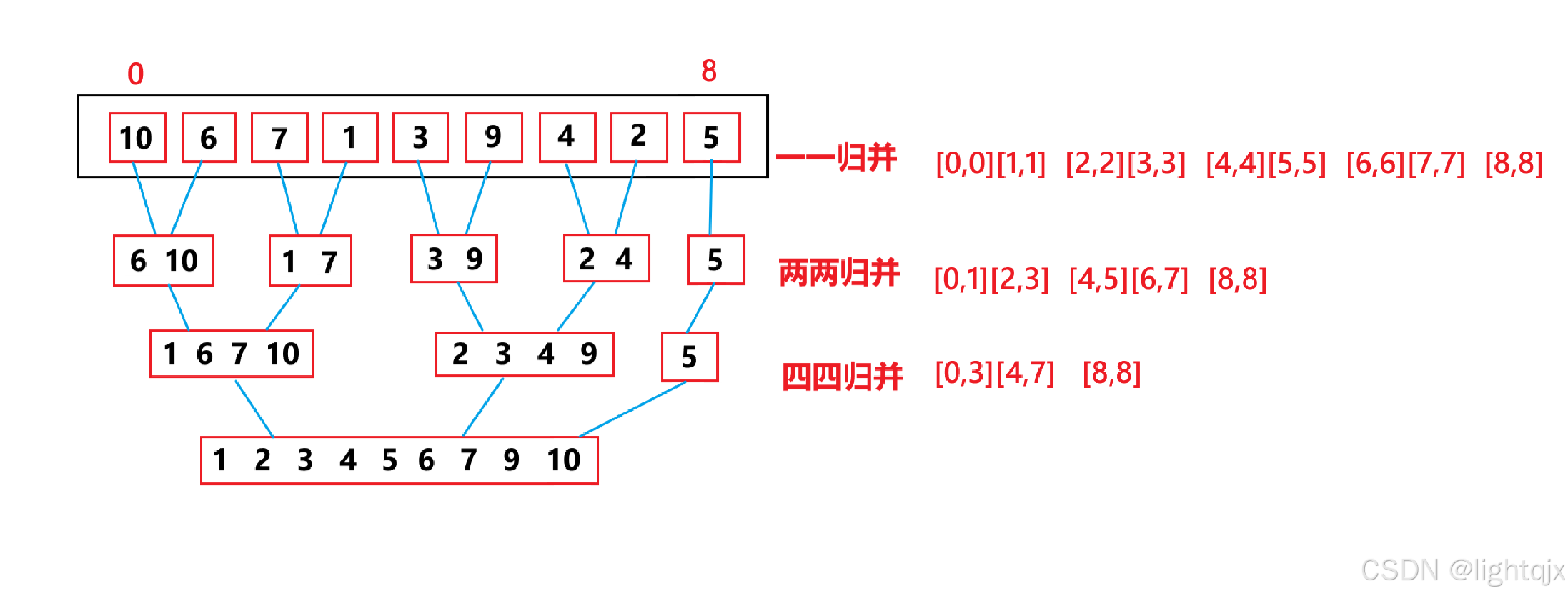
如果要用归并排序来排序一组数据,首先,需要将该组数据逐渐两两分开,直到分成每组数据只有一个数据为止,这样就得到了数据个数为1的许多个序列。然后,在对它们进行两两合并形成新的有序序列,之后就重复操作,将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
图示解析:
四、递归实现
对于归并排序,可以用递归实现。
第一步:分解
先对初始数据的区间1进行分解,分解成两个区间,这两个区间再进行划分,又可以分成4个,如此重复进行分解,直到分解成每一个区间中只有一个元素。
第二步:合并
这里需要考虑一个问题:当分解成每一个区间只有一个元素时,要怎么合并?如果直接在原数组上进行操作,如果只有两个数据,则只需要交换它们就行了,但如果数据多了,这就不划算了。所以最好的办法就是:新开辟一个数组来存储合并后的数据,合并之后再将数据拷贝回去。
C语言代码实现:
// 归并排序递归实现
void _MergeSort(int* a, int begin, int end, int* tmp)
{
//最终停止递归的条件,此时区间中只有一个数据
if (begin >= end)
{
return;
}
int mid = (begin + end) / 2;//获取中间数据的下标
//分成区间:[begin, mid] 和 [mid + 1, end]
_MergeSort(a, begin, mid, tmp);// 对[begin, mid]进行分解
_MergeSort(a, mid + 1, end, tmp);// 对[mid + 1, end]进行分解
//跳过这两个递归函数时,就说明在[begin, mid],[mid + 1, end]中已经有序,开始合并
int begin1 = begin, end1 = mid;// [begin, mid]区间
int begin2 = mid + 1, end2 = end;// [mid + 1, end]区间
int i = begin1;// 设置待拷贝数组的下标初始位置
//对[begin, mid],[mid + 1, end]进行合并
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
//如果有一方没有拷贝完的情况,将剩余的数据直接拷贝
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));//拷贝
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);//申请临时数组,暂时存储合并的数据
if (tmp == NULL)
{
perror("malloc fail\n");
return;
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}五、非递归实现
对于归并排序的非递归实现,这是比较难实现的。因为这和要排序的数据数据个数有关。
如果数据个数有偶数个。这比较好理解。所以我们先来实现偶数个数据的非递归排序,在进行修正,从而达到能够对奇数和偶数都能排序。
对于偶数中,可以先保证能够每次都是两两归并来实现。即对个数据的情况排序
对于个数据:
实现非递归的实现,我们并不会有将数据分解的操作,而是直接将数据看成单个数据,然后从单个数据开始合并,第一次是两两归并,第二次是四四归并,然后是八八归并,......,直到所有数据都完成归并排序。
为了完成从一一归,两两归,四四归,...... 。所以需要一个变量gap来存储要是几几归。
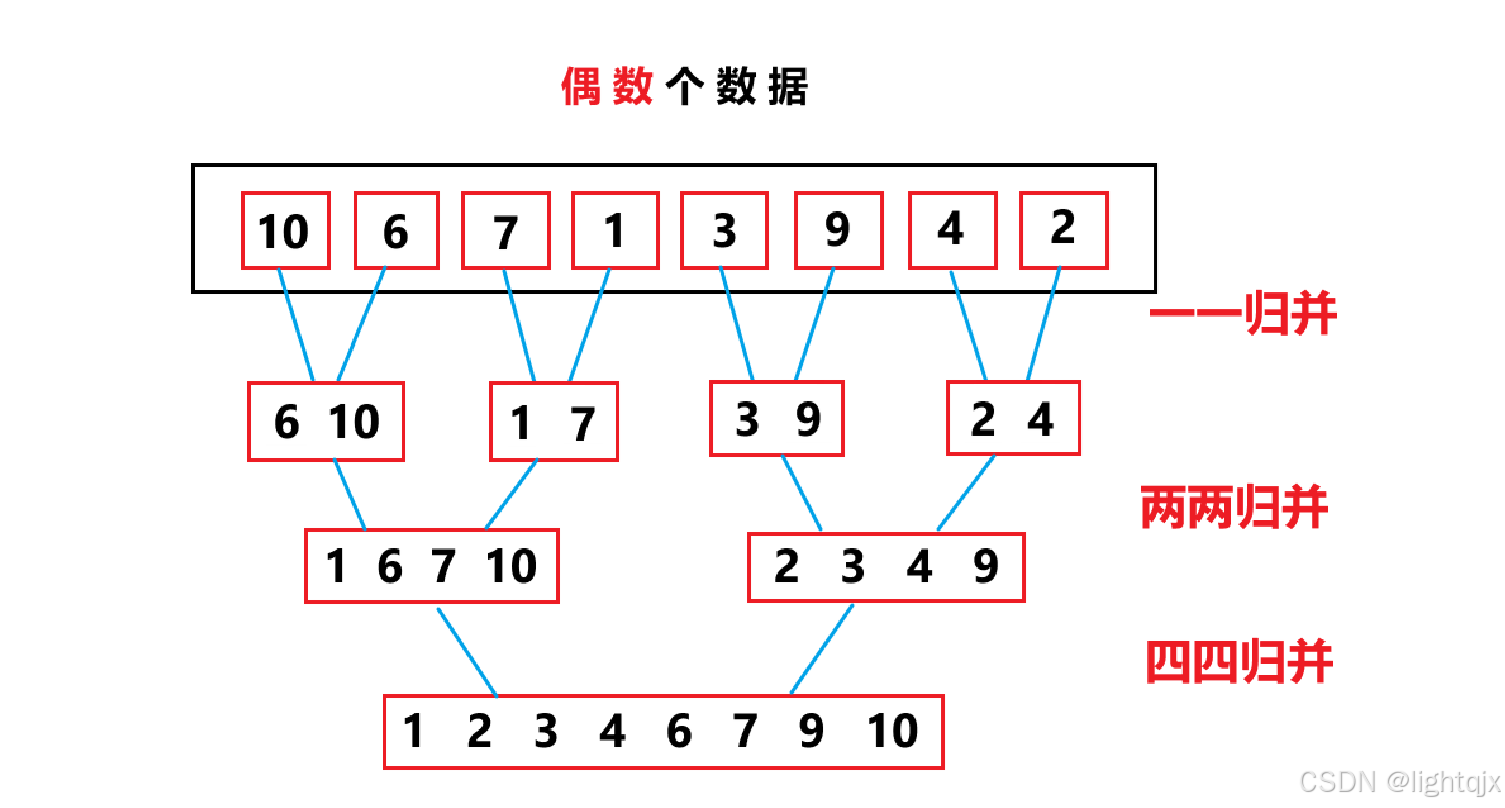
这是非递归归并排序中对于某一种特殊情况的实现。代码如下:
// 归并排序非递归实现
void MergeSortNotRecursive(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail\n");
return;
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//生成本次要归并的区间 [begin1, end1],[begin2, end2]
int begin1 = i, end1 = begin1 + gap - 1;
int begin2 = end1 + 1, end2 = begin2 + gap - 1;
int j = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
//如果有一方没有拷贝完的情况,将剩余的数据直接拷贝
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));//拷贝
}
gap *= 2;
}
free(tmp);
}但这种实现并不是正真的归并排序,因为它现在还不能对所有数据进行排序。此时还只适用于具有个数目的数据。
所以,需要改进这种问题。改进方法如下(详细思路):
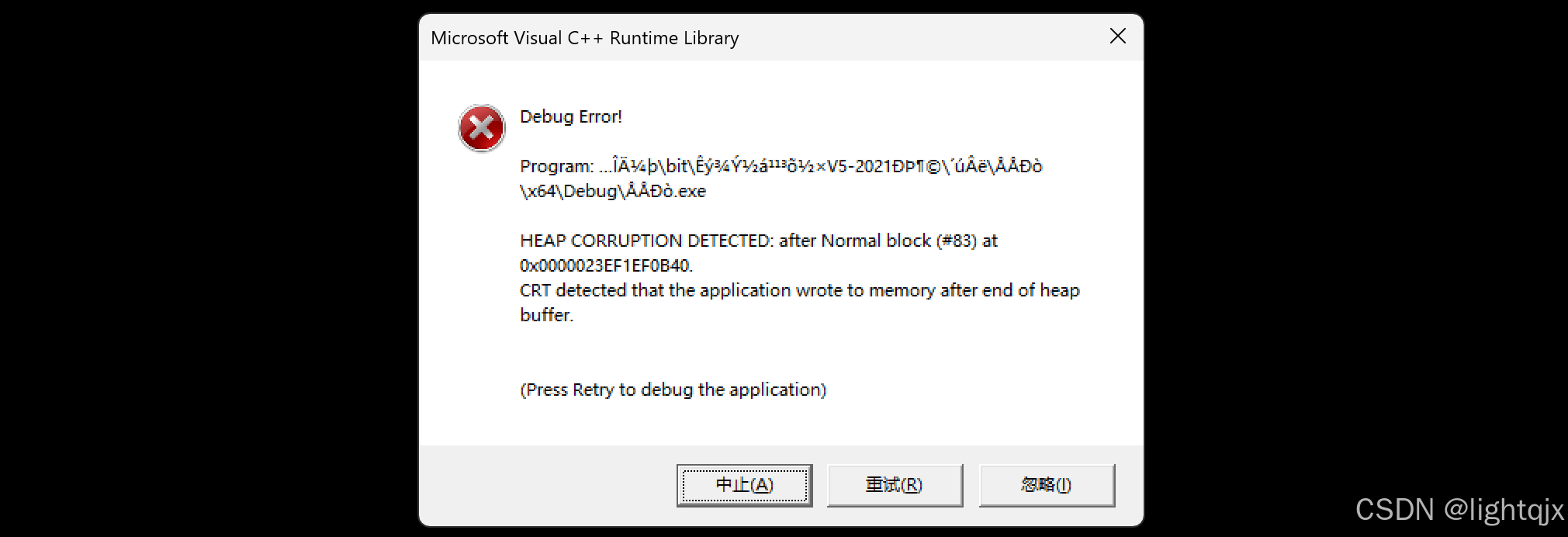
首先,我们要对一组数目不是个的数据进行排序,运行代码后,编译器的运行就会崩溃。如图
这时,如果我们将要归并的区间都打印一下,如图:
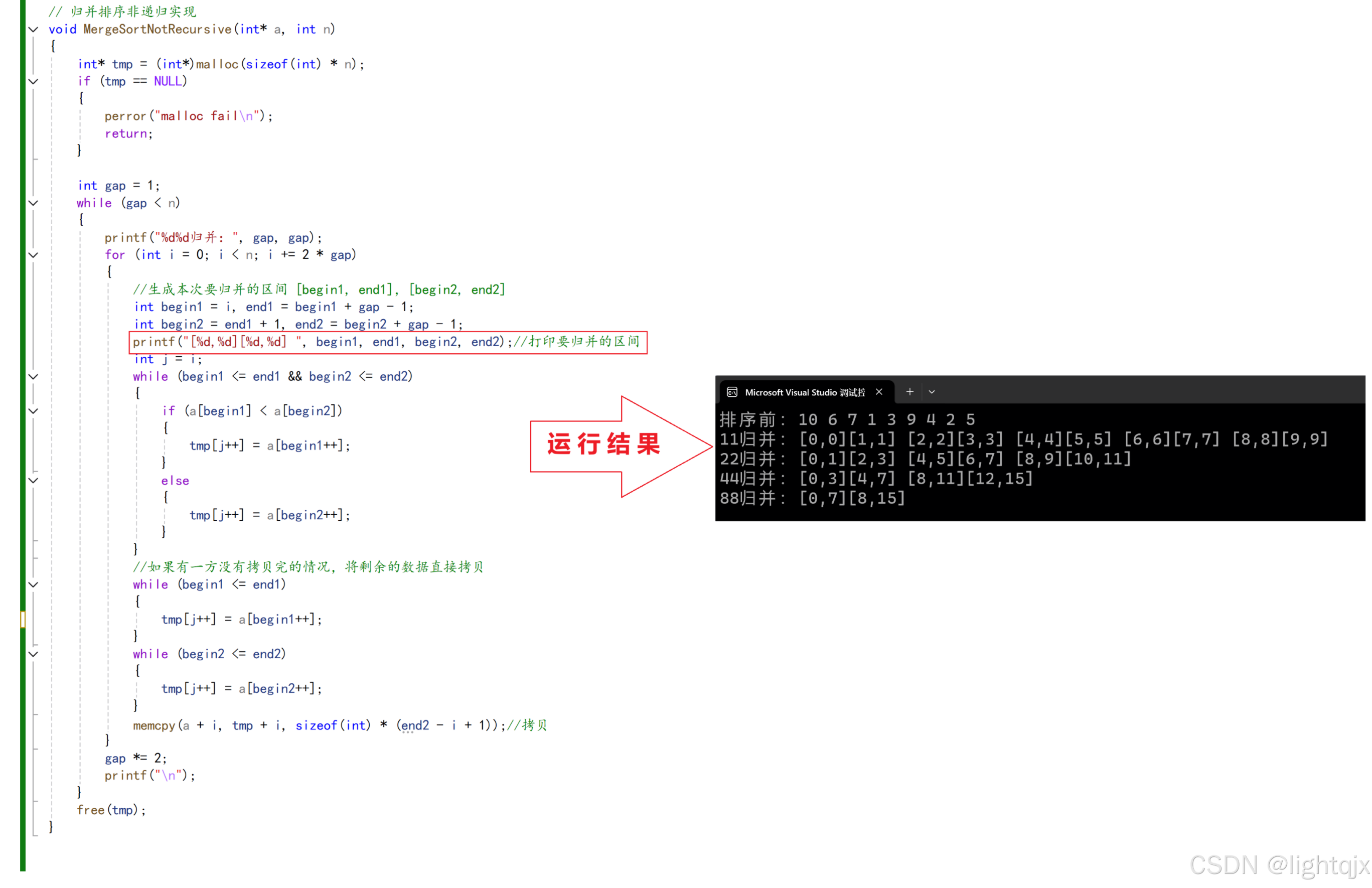
在上图的排序中,对于数据10,6,7,1,3,9,4,2,5 这个9数据中,原本归并的图示如图所示:
代码打印结果:

代码打印的结果和上图示正真排序的区间有很大不同。可以发现代码打印的区间出现了明显的越界。这就是代码崩溃报错的原因。--- 这就是要改进的地方。
改进:
原代码的生成区间:

对越界情况的分析(将复杂问题分为简单问题):
- 首先要知道,这段代码中begin1是一定不会越界的,可能越界的有end1,begin2,end2。
- 如果end1越界(这种情况,begin2,end2也一定会越界),这种情况的解决办法是:在这种情况就不归并了。
- 如果end1没有越界,begin2越界(这时,end2也一定会越界),这种情况的解决办法是:不进行归并了。(和end1越界情况一样)
- 如果end1、begin2没有越界,end2越界,这种情况的解决办法是:继续归并,但要修正end2,将end2赋值为和begin2一样。
归并排序C语言代码实现:
// 归并排序非递归实现
void MergeSortNotRecursive(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail\n");
return;
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//生成本次要归并的区间 [begin1, end1],[begin2, end2]
int begin1 = i, end1 = begin1 + gap - 1;
int begin2 = end1 + 1, end2 = begin2 + gap - 1;
if (end1 >= n || begin2 >= n)
{
//情况1:end1越界
//情况2:end1不越界,begin2越界
break;//不归并了
}
if (end2 >= n)
{
//end1不越界,begin2不越界,end2越界
end2 = n - 1;
}
int j = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
//如果有一方没有拷贝完的情况,将剩余的数据直接拷贝
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));//拷贝
}
gap *= 2;
}
free(tmp);
}六、特性总结
归并排序的特性总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
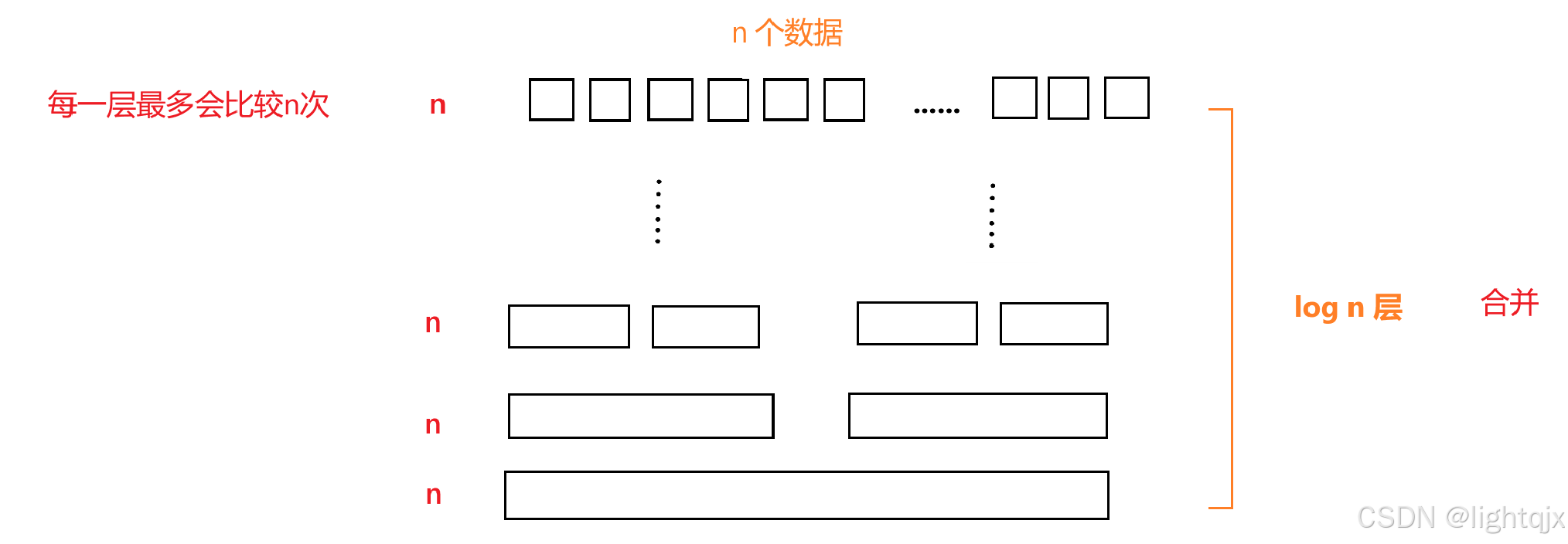
- 时间复杂度:O(N*logN),因为二路归并排序需要
趟,合并两个子序列的时间性能为
- 空间复杂度:O(N)
- 稳定性:稳定
感谢各位观看!希望能多多支持!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)