VSCode 打造 Python 机器学习 / 数据分析全环境指南:从配置到实战(附 CSV 数据识别示例)
通过 VSCode+Miniconda + 核心库的组合,可快速搭建灵活且高效的 Python 机器学习 / 数据分析环境。本文的 CSV 数据识别示例展示了从数据读取到特征分析的完整流程,结合 VSCode 的插件生态(如 Jupyter、可视化工具),能显著提升开发效率。后续可根据具体需求扩展库与工具,适配更复杂的场景(如自然语言处理、计算机视觉)。
摘要
本文详细介绍如何使用 VSCode 快速搭建稳定、高效的 Python 机器学习 / 数据分析环境,涵盖基础工具链(Python、虚拟环境)、核心库(Pandas、NumPy、Scikit-learn 等)的安装与配置,以及 VSCode 专属插件(如 Python、Jupyter、数据可视化工具)的优化方案。通过 “识别格式化 CSV 表格数据” 实战示例,演示环境的完整应用流程,包括数据读取、清洗、探索性分析及特征识别,帮助初学者快速上手,同时为进阶开发者提供环境调优参考。
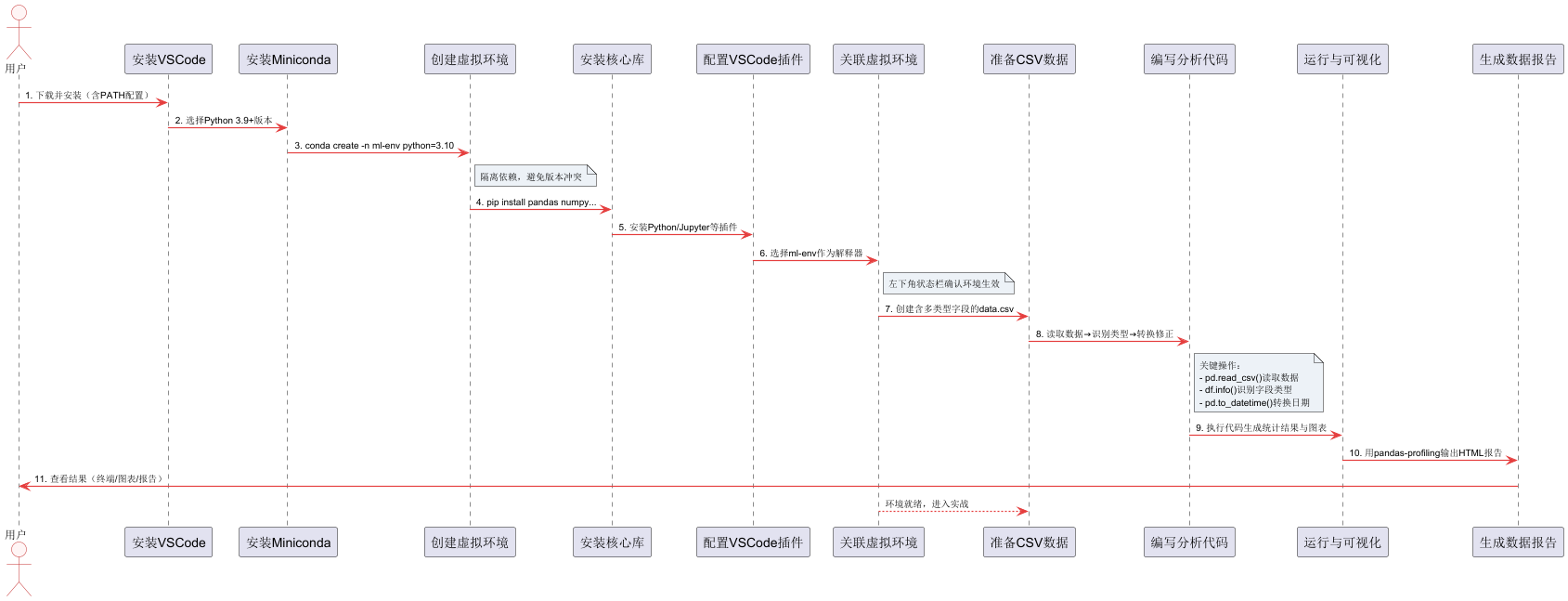
一、环境搭建核心工具链
1. 基础软件安装
(1)安装 VSCode
- 下载地址:VSCode 官网,选择对应系统版本(Windows/macOS/Linux)。
- 安装建议:勾选 “添加到 PATH”(Windows)或 “应用程序文件夹”(macOS),方便终端调用。
(2)安装 Python 环境
推荐使用Miniconda(轻量版 Anaconda,适合管理虚拟环境和依赖):
- 下载地址:Miniconda 官网,选择 Python 3.9 + 版本。
- 安装步骤:
- Windows:勾选 “Add Miniconda to my PATH environment variable”(方便终端调用 conda)。
- macOS/Linux:终端执行安装脚本,按提示完成(默认会添加到 PATH)。
- 验证:终端输入
conda --version或python --version,显示版本号即成功。
2. 虚拟环境创建(避免依赖冲突)
机器学习 / 数据分析项目依赖复杂,建议为每个项目创建独立虚拟环境:
# 终端执行:创建名为"ml-env"的虚拟环境(Python 3.10为例)
conda create -n ml-env python=3.10 -y
# 激活环境(Windows用cmd:conda activate ml-env;PowerShell需先执行conda init powershell)
conda activate ml-env # macOS/Linux终端直接执行
# 验证:终端前缀显示(ml-env),表示环境激活成功
3. 核心库安装
在激活的ml-env环境中,安装数据分析与机器学习必备库:
# 基础数据处理库
pip install pandas numpy openpyxl # pandas用于表格处理,numpy用于数值计算,openpyxl支持Excel文件
# 可视化库
pip install matplotlib seaborn # matplotlib基础绘图,seaborn美化图表
# 机器学习库
pip install scikit-learn # 包含经典机器学习算法(分类、回归等)
# 数据验证/类型识别库(示例专用)
pip install pandas-profiling # 自动生成数据报告,辅助识别数据特征
4. VSCode 插件配置(提升开发效率)
打开 VSCode,在左侧 “扩展” 面板搜索并安装以下插件:
| 插件名称 | 作用 | 核心功能 |
|---|---|---|
| Python(Microsoft) | 核心 Python 支持 | 语法高亮、智能提示、调试、环境切换 |
| Jupyter(Microsoft) | 集成 Jupyter 笔记本 | 在 VSCode 中运行.ipynb 文件,支持单元格执行 |
| Excel Viewer | 预览 CSV/Excel 文件 | 无需打开 Excel,直接在 VSCode 查看表格数据 |
| Pylance | Python 语言服务器(增强版) | 更快的代码补全、类型检查 |
| Black Formatter | 代码格式化工具 | 自动统一代码风格(符合 PEP8) |
5. VSCode 环境关联(关键步骤)
- 打开项目文件夹:VSCode 菜单栏 “文件→打开文件夹”,选择你的项目目录(如
ml-projects)。 - 关联虚拟环境:
- 按
Ctrl+Shift+P(macOSCmd+Shift+P)打开命令面板,输入 “Python: Select Interpreter”。 - 选择 “ml-env” 环境(路径含
miniconda3/envs/ml-env或anaconda3/envs/ml-env)。
- 按
- 验证:左下角状态栏会显示当前关联的 Python 环境(如
Python 3.10 ('ml-env'))。
二、实战示例:识别格式化 CSV 表格数据
目标
假设我们有一份未知结构的 CSV 文件(data.csv),需通过程序自动识别其字段类型(如数值型、字符串型、日期型)、缺失值分布,并提取关键特征(如最大值、类别数量),最终生成数据报告。
步骤 1:准备数据
创建data.csv(模拟一份包含多类型字段的表格数据),内容如下:
id,name,age,join_date,score,is_active
1,Alice,28,2023-01-15,92.5,True
2,Bob,,2023-03-20,88.0,False
3,Charlie,32,2022-11-05,,True
4,Diana,25,2023-05-10,95.5,True
5,Eve,30,2023-02-28,79.0,
步骤 2:在 VSCode 中编写代码
- 在项目文件夹中新建
csv_analyzer.py文件(或csv_analyzer.ipynb,推荐用 Jupyter 笔记本分步执行)。 - 代码实现(含注释):
# 导入库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pandas_profiling import ProfileReport
# 步骤1:读取CSV数据
# 注意:若CSV编码特殊(如gbk),需指定encoding参数(如encoding='gbk')
df = pd.read_csv('data.csv')
# 步骤2:初步识别数据结构
print("=== 数据基本信息 ===")
print(f"形状(行×列):{df.shape}") # 输出(5,6),表示5行6列
print("\n=== 前3行数据预览 ===")
print(df.head(3)) # 预览前3行,快速了解字段内容
# 步骤3:识别字段类型与缺失值
print("\n=== 字段类型与非空值统计 ===")
print(df.info()) # 显示每个字段的类型(int64/object/datetime64等)和非空值数量
# 输出解读:
# - id:int64(整数型,无缺失)
# - name:object(字符串型,无缺失)
# - age:float64(数值型,有1个缺失值)
# - join_date:object(暂识别为字符串,实际是日期)
# - score:float64(数值型,有1个缺失值)
# - is_active:object(暂识别为字符串,实际是布尔值)
# 步骤4:转换字段类型(修正识别错误)
# 将join_date转换为日期型
df['join_date'] = pd.to_datetime(df['join_date'], errors='coerce') # errors='coerce'将无效值转为NaT
# 将is_active转换为布尔型(处理缺失值)
df['is_active'] = df['is_active'].map({'True': True, 'False': False}).fillna(False) # 缺失值默认False
# 验证转换结果
print("\n=== 修正后的字段类型 ===")
print(df.dtypes)
# 步骤5:数值型字段统计分析(识别分布特征)
print("\n=== 数值型字段统计描述 ===")
print(df[['age', 'score']].describe()) # 输出均值、标准差、最值等
# 解读:age均值≈28.75,score最大值95.5
# 步骤6:可视化分析(直观展示特征)
plt.figure(figsize=(12, 5))
# 子图1:age分布(直方图)
plt.subplot(1, 2, 1)
sns.histplot(df['age'].dropna(), kde=True) # 去除缺失值后绘图
plt.title('Age Distribution')
# 子图2:score与is_active的关系(箱线图)
plt.subplot(1, 2, 2)
sns.boxplot(x='is_active', y='score', data=df)
plt.title('Score vs Is Active')
plt.tight_layout()
plt.show() # VSCode中会直接显示图片
# 步骤7:生成自动化数据报告(含所有特征识别结果)
profile = ProfileReport(df, title="CSV Data Analysis Report", explorative=True)
profile.to_file("data_report.html") # 保存为HTML文件,可直接在浏览器打开
print("\n数据报告已生成:data_report.html")
步骤 3:运行与结果解读
-
运行代码:
- 若用
.py文件:右键 “运行 Python 文件”(或按F5调试运行)。 - 若用
.ipynb文件:点击单元格左侧 “运行” 按钮,分步执行。
- 若用
-
关键结果:
- 终端输出:显示数据形状、字段类型、统计值(如
age有 1 个缺失值,join_date成功转为日期型)。 - 可视化图表:左侧直方图展示
age分布集中在 25-32 岁,右侧箱线图显示活跃用户(is_active=True)的score更高。 - 数据报告:
data_report.html包含字段类型、缺失值比例、相关性分析等,可直接在浏览器打开查看完整结果。
- 终端输出:显示数据形状、字段类型、统计值(如
三、环境优化与扩展建议
- 加速库安装:国内用户可配置豆瓣源(
pip config set global.index-url https://pypi.doubanio.com/simple/),提升下载速度。 - 调试配置:在 VSCode 中创建
.vscode/launch.json,配置断点调试参数(如指定 Python 解释器、程序入口)。 - 扩展工具:如需深度学习,可安装
tensorflow或pytorch(在ml-env环境中执行pip install tensorflow);如需处理大型数据,可添加dask库。 - 版本控制:安装 VSCode 的 “Git” 插件,将代码和数据纳入 Git 管理,方便协作与版本回溯。
小结
通过 VSCode+Miniconda + 核心库的组合,可快速搭建灵活且高效的 Python 机器学习 / 数据分析环境。本文的 CSV 数据识别示例展示了从数据读取到特征分析的完整流程,结合 VSCode 的插件生态(如 Jupyter、可视化工具),能显著提升开发效率。后续可根据具体需求扩展库与工具,适配更复杂的场景(如自然语言处理、计算机视觉)。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)