卷积神经网络的基石——基础卷积模块
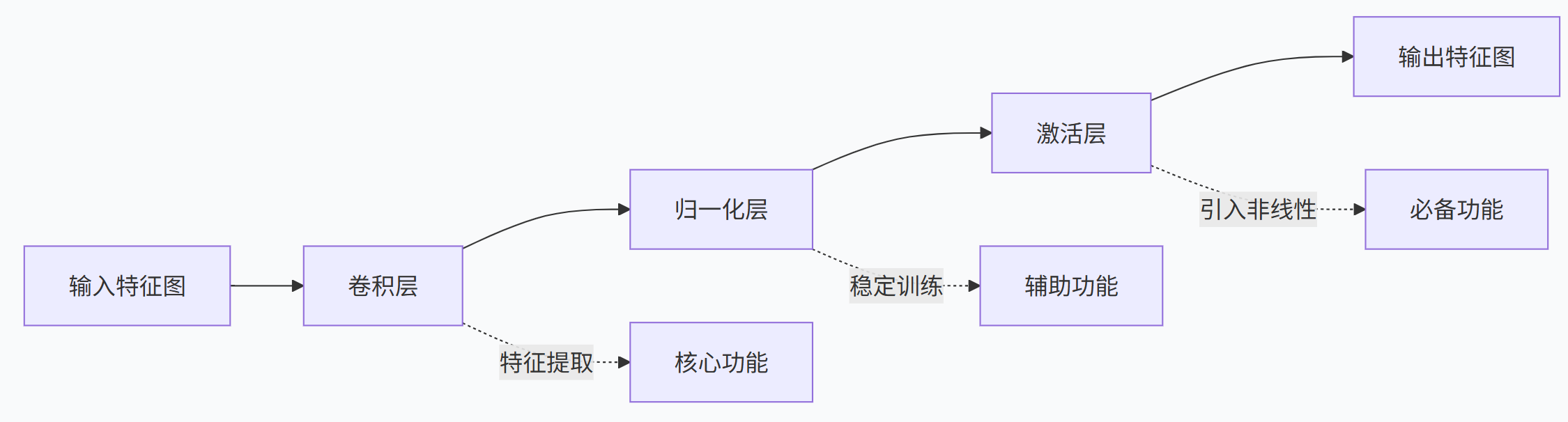
基础卷积模块是CNN的核心构建单元,由卷积层、归一化层和激活函数组成。卷积层通过滑动窗口提取局部特征;归一化层(如BN)稳定训练过程;激活函数(如ReLU)引入非线性。现代标准组合顺序为Conv→BN→ReLU,相比早期的Conv→ReLU→BN更有效。残差连接通过将输入直接加到输出上,解决了深层网络的梯度消失问题,使网络能设计得更深。基础模块加上残差连接即构成残差模块,成为现代CNN的常见形态。
🎯什么是基础卷积模块?
基础卷积模块(Convolutional Block) 是卷积神经网络(CNN)的核心构建单元,通常由卷积层、归一化层、激活函数按固定顺序组合而成,用于高效提取图像的局部特征并引入非线性表达。
🧩 核心组件技术解析
卷积层 (Convolutional Layer)
卷积层通过可学习的卷积核在输入特征图上执行滑动窗口运算,提取局部特征。
# 卷积层的PyTorch实现
import torch.nn as nn
conv_layer = nn.Conv2d(
in_channels=3, # 输入通道数(如RGB图像为3)
out_channels=64, # 输出通道数(卷积核数量)
kernel_size=3, # 卷积核大小(3x3)
stride=1, # 步长
padding=1, # 填充(保持尺寸不变)
bias=False # 通常与BN层一起使用时关闭bias
)可视化理解:想象你用一个手电筒在图像上扫描,手电筒的光圈就是卷积核。每扫描到一个位置,你就会记录下这个区域的"特征描述"。多个卷积核就像多个不同颜色的手电筒,每个都能发现图像中不同的模式——边缘、纹理、颜色变化等。
归一化层 (Normalization Layer)
对卷积层的输出进行归一化,使其分布更加稳定。这可以加速模型收敛,缓解梯度消失/爆炸,并具有一定的正则化效果(防止过拟合)。
常见选择:
-
Batch Normalization (BN):最常用,在批次维度上进行归一化。
-
Layer Normalization (LN):常用于RNN/Transformer,在特征维度上进行归一化。
-
Instance Normalization (IN):常用于风格迁移。
bn_layer = nn.BatchNorm2d(num_features=64) # 参数为通道数激活层 (Activation Layer)
引入非线性。如果没有激活函数,无论多少层网络都只是线性变换,无法拟合复杂的非线性函数。
常见选择:
-
ReLU (Rectified Linear Unit):最常用,计算简单,能有效缓解梯度消失,公式为
max(0, x)。 -
Leaky ReLU / PReLU / ELU:ReLU的变体,旨在解决ReLU神经元死亡的问题。
-
Swish / SiLU:近年来在Transformer和高效网络中流行的激活函数。
relu = nn.ReLU(inplace=True) # inplace=True可节省显存🔧 经典组合顺序
🏆 选项A:Conv → BN → ReLU(行业标准)
class StandardConvBlock(nn.Module):
"""现代CNN中最标准的卷积模块"""
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size,
stride, padding, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
return self.relu(self.bn(self.conv(x)))✅ 优点:这种顺序自ResNet提出后被广泛采用,它让BN层直接作用于卷积输出,更好地稳定分布,然后通过ReLU引入非线性。
📜 选项B:Conv → ReLU → BN(历史选择)
早期的网络(如AlexNet)采用这种顺序,但现代架构中较少使用,因为BN放在ReLU之后无法很好地发挥其稳定分布的作用。
# ⚠️ 历史版本,现代很少使用
class HistoricConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size,
stride, padding, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x) # ReLU在前
x = self.bn(x) # BN在后
return x🔄 残差连接 (Residual Connection)
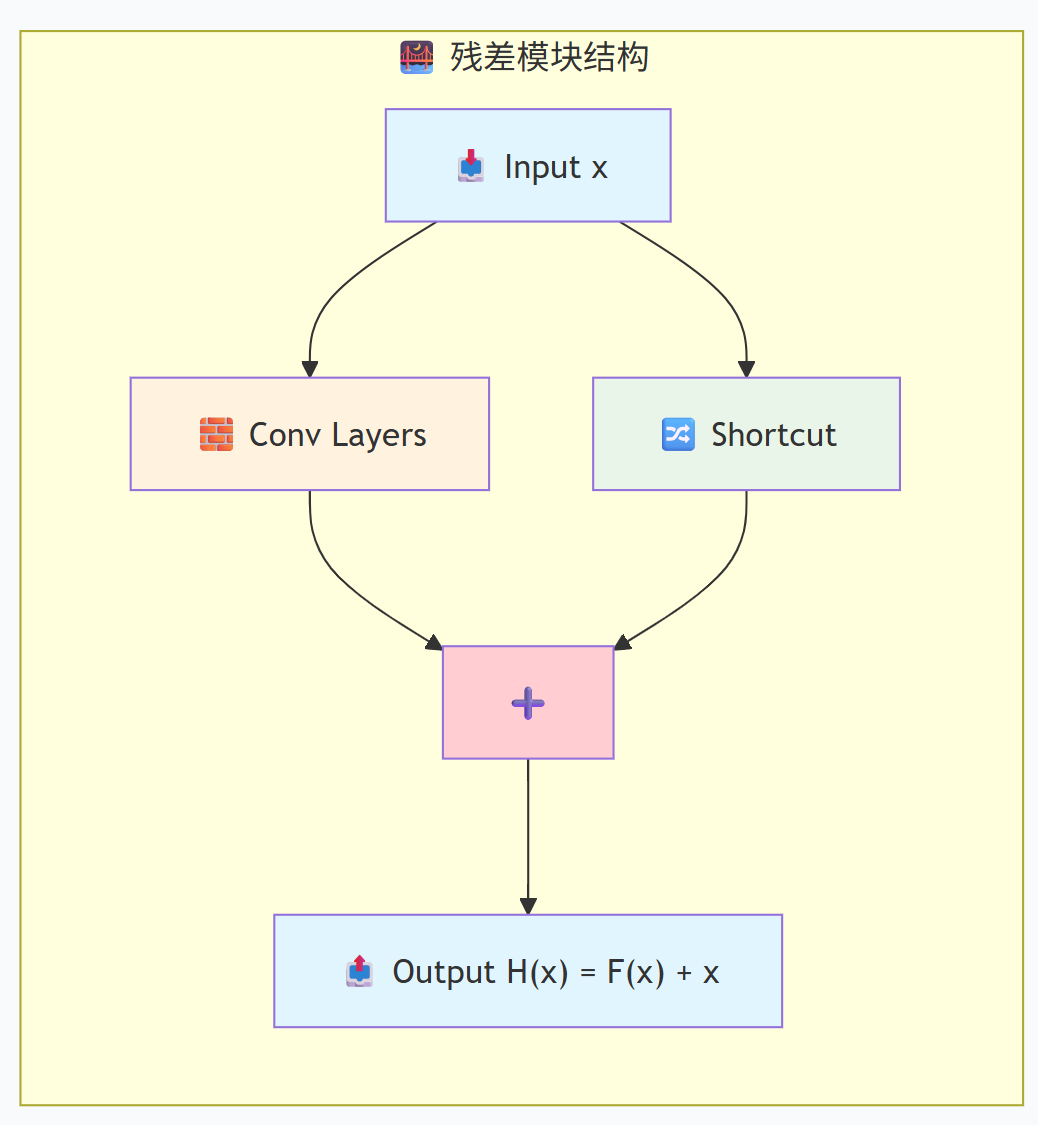
虽然“残差模块”本身算是一个进阶模块,但由于它实在太基础、太常用,现在很多基础模块的构建都会包含它。它不是一个必须的层,而是一种结构设计。
公式:Output = F(x) + x
做法:将模块的输入x直接通过一个捷径(shortcut)连接到模块的输出上,与经过卷积处理的特征F(x)相加。
作用:解决了深层网络中的梯度消失问题,使得网络可以设计得非常深(如ResNet-152)。
💡 残差模块的核心思想
传统模块直接学习映射 H(x),而残差模块学习残差 F(x)=H(x)−x,原始映射变为 H(x)=F(x)+x。
| 映射类型 | 定义 | 学习目标 |
|---|---|---|
| 传统映射 | H(x) | 让网络直接学习从输入 x 到输出 H(x) 的完整变换(比如 “输入图片→提取猫的特征”) |
| 残差映射 | F(x)=H(x)−x | 让网络只学习 “输入 x 到目标 H(x) 之间的差值”(比如 “输入图片→需要补充哪些细节才能变成猫的特征”) |
用生活例子理解:学习 “差值” 比学习 “完整目标” 更容易
假设你要教机器人做一件事:把 “普通蛋糕”(输入 x)做成 “生日蛋糕”(目标 H(x))。
- 传统模块思路:让机器人从零学习 “普通蛋糕→生日蛋糕” 的完整流程(烤胚、抹奶油、插蜡烛、写字…),步骤多、难度大,学不会就容易 “忘事”(梯度消失);
- 残差模块思路:先把 “普通蛋糕”(x)直接保留,让机器人只学习 “普通蛋糕→生日蛋糕需要补充的部分”(F(x):加奶油、插蜡烛),最后把 “原蛋糕 + 补充部分”(x+F(x))组合,就是生日蛋糕(H(x))。
显然,学习 “补充哪些东西”(残差)比学习 “完整流程”(直接映射)简单得多 —— 哪怕机器人学不会补充任何东西(F(x)=0),至少还能保留原始的普通蛋糕(x),不会完全失败。
📝 代码实现
class BasicBlock(nn.Module):
"""基础的残差模块(BasicBlock)"""
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super().__init__()
# 第一个卷积
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, stride, 1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
# 第二个卷积
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, 1, 1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x # 保存输入
# 主路径
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 捷径连接
if self.downsample is not None:
identity = self.downsample(x)
# 残差相加
out += identity
out = self.relu(out)
return out
downsample的核心作用是对齐主路径和捷径分支的张量维度,确保残差相加(out += identity)能正常执行;
📝 总结
当你听到“基础卷积模块”时,通常指的是:
卷积层 + 归一化层 + 激活层。
如果加上“跳跃连接”(残差连接,将输入直接加到输出上),它就变成了一个基础的残差模块,这是现代网络的更常见形态。
🔍 卷积层:通过滑动窗口提取特征,让网络"看见"世界
⚖️ 归一化层:稳定训练过程,让网络"学得"更快
⚡ 激活层:引入非线性,让网络"理解"复杂模式
🌉 残差连接:打破深度瓶颈,让网络"建得"更深

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)