几种强化学习算法输出的Q值的可视化(hil-serl/td3+bc/td3+bc+distributional)
原文发表在知乎,格式更规正一些,可参考:《近期一直在看一些强化学习相关的算法,所有的出发点其实来源于字节跳动的gr-rl论文(前期写过一篇文章:《关于gr-rl与pi-0.6(π₀.₆)的一些想法》),它里面有一个核心的点就是离线用了td3+bc训练了一个critic模型(关于td3+bc,前期也写过一篇文章:《td3+bc与conrft强化学习算法总结》),critic模型输出了一个Q值,强化学
原文发表在知乎,格式更规正一些,可参考:《几种强化学习算法输出的Q值的可视化(hil-serl/td3+bc/td3+bc+distributional)》
近期一直在看一些强化学习相关的算法,所有的出发点其实来源于字节跳动的gr-rl论文(前期写过一篇文章:《关于gr-rl与pi-0.6(π₀.₆)的一些想法》),它里面有一个核心的点就是离线用了td3+bc训练了一个critic模型(关于td3+bc,前期也写过一篇文章:《td3+bc与conrft强化学习算法总结》),critic模型输出了一个Q值,强化学习里面的Q值代表在当前状态s下,采取了一个动作a,所获得的收益以及后续所有收益的期望值。
如下图所示(来源于gr-rl论文),在离线阶段训练出的critic模型可以充当一个progress predictor,一方面可以充当一个任务的进度显示器,对数据中的噪声(下图中深蓝色曲线的波动部分)进行一些filter,另一方面在online强化学习算法中可以对策略进行监督指导。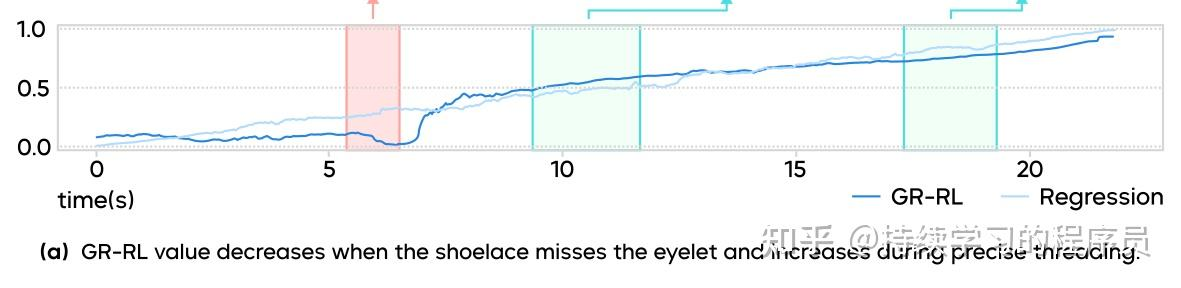
所以近期的几个工作的目标都是想复现一下gr-rl中的这个critic模型的效果,做了几个工作:
hil-serl版:设计了一稍微有些难度的任务,用前期复现过的hil-serl算法再复现一次,复现过程可参考:《具身智能hil-serl强化学习算法在lerobot机械臂上复现-案例2》,此版本hil-serl算法内部使用的是SAC强化学习算法,是一个纯online的学习过程,笔者持续坚持了8小时才训练出了一个有较高成功率的策略。
td3+bc版:将工作1中的SAC算法改造成td3+bc算法。因为hil-serl的框架是一个actor/learner框架(《强化学习Actor/Learner框架介绍(lerobot版)》),在线交互由actor进程负责,模型训练由learner进程负责。所以直接改造learner模块即可,加载离线数据集并进行模型训练,同时不启动actor进程,这样整体上就将hil-serl在线online强化学习框架,就变成了一个可offline强化学习的框架。通过offline强化学习,学习到了一个td3+bc算法版本的critic模型。
td3+bc版+distributional版:将工作二中经典的td3+bc改造成一个值分布的版本。简单来说,传统的强化学习输出的Q值是一个期望值,而值分布的版本输出的是一个分布,用分布替代期望值,效果预期会更好。而值分布强化学习算法又有很多种算法,例如C51,QR-DQN等。笔者选择了C51复现了一下,发现效果一般。
整体上工作一的critic模型的效果最好,可接近gr-rl中的效果。工作二其次,后续可以继续在工作二的critic模型基础之上,再进行online的强化学习,预计会加快整体的训练过程。工作三一般。
下面就把上面三个工作展开讲一下:
工作一:hil-serl版
数据集
先说一下训练数据集,hil-serl算法复现过程的后期,大部分都是策略自动化的下发动作,人工只是在个别的时刻去接管,纠正策略。hil-serl框架会自动保存最近30000个step的数据,这些数据大部分都是策略自动化产生的。笔者统计了一下,共保存了232个episode:
139个成功,平均15秒/episode
93个失败,平均10秒/episode
整体来看,这个数据集的量级,正负样本的比例都可以直接拿来使用。当然,在工作一里面只是生产出了可用的数据集,工作一本身与此数据集没有太大关系,因为hil-serl的训练过程是纯在线的,使用的是历史上8个小时持续交互过程中的操作数据。这个数据集主要是给后面的工作二,工作三来使用。
评测数据集就选取上面数据集的前10个episode,其中有4个是成功的,其余是失败的。
数据集笔者已经上传到hugging face,地址:MrXuan/push_cube_complex ,有兴趣可自行下载。
Q值的可视化
hil-serl训练结束后,直接就产出了critic模型,笔者从上面的数据集中抽取出了前面10个episode进行效果评测。其中有4个episode是成功的,其余是失败的。可以临时修改一些代码(代码没有提交,可参考本文附录进行临时修改),输出这10个episode内每个step的Q值。Q值直接在modeling_sac.py中compute_loss_critic函数的最后一行打个断点,把计算出来的Q值提取出来画成曲线图。
这10个episode的数据画出曲线图如下。初步可以看到第2,4,6,8四个episode的曲线看起来递增的趋势比较明显,其它的显得杂乱,经过与实际的视频对比,确实只有这四个episode成功的完成任务,其它的都失败。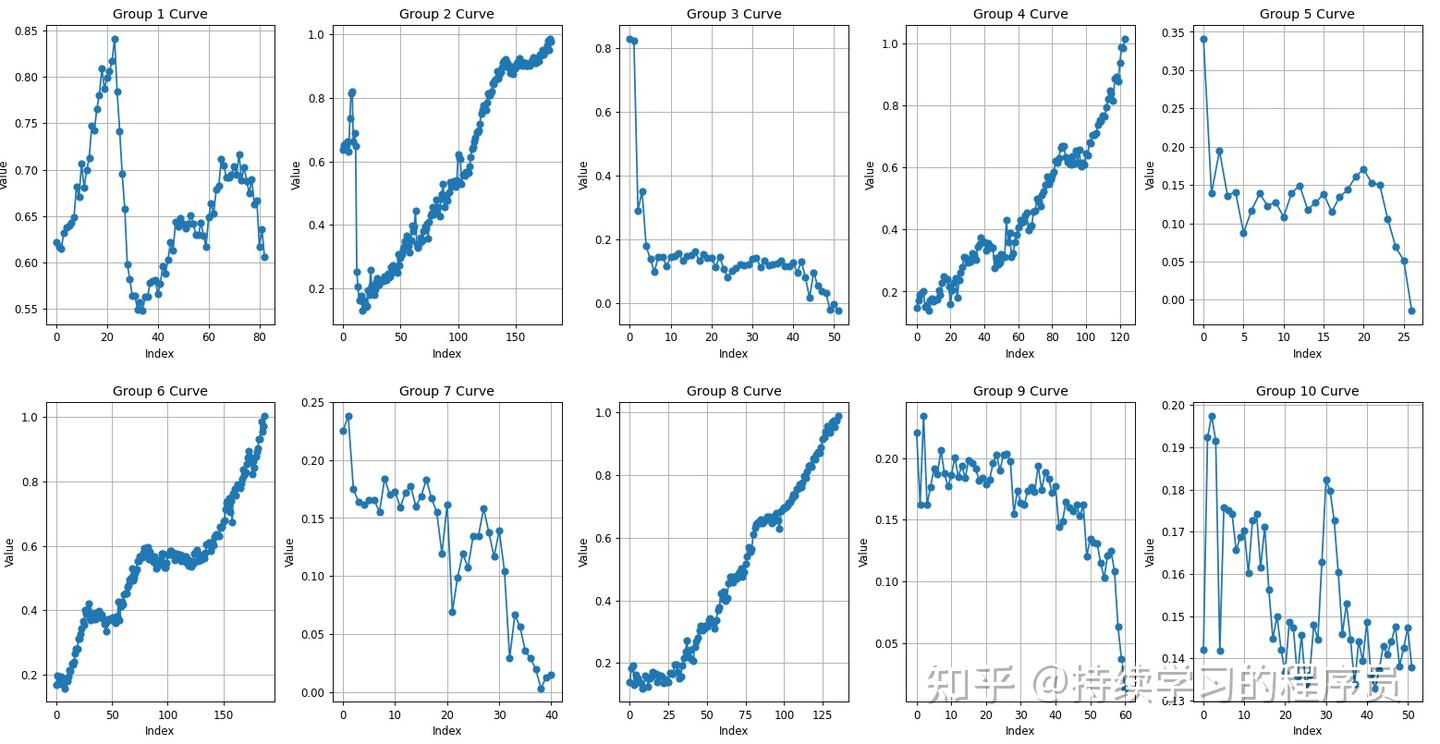
具体将第6个episode提取出来,就是上图中的Group-6 Curve,从上面的曲线图可以看出来,大概3-5和8-13秒的时候,曲线图是相对平坦的,也就是这两段应该有些异常。把对应的视频提取出来(命令参考本文附录),视频链接如下,因为对应的图像是128*128,所以转成视频后分辨率很低,但不影响内容表达。通过视频可以明显看出来这两段时间内机械臂在原地犹豫抖动。所以可以通过Q值的曲线明显的对此episode的质量进行判断,也可以对此episode进行一些filter,将不好的数据剔除去,用filter后的数据再去训练,会取得更好的效果。
episode6对应视频
blibli链接
hil-serl训练出的critic模型输出的Q值目前来看是最优的,毕竟是经过了8个小时的持续训练,且经过效果验证的一个版本。
工作二:td3+bc版:将sac算法改为td3+bc(经典td3+bc)
代码地址:https://github.com/hxdoit/lerobot.git,切换到分支td3_bc,其中版本:commit 006b33f3dc259f4fbdde1269ee3bf841180c14a0是经典td3+bc,再往后的提交中,又将critic函数的输出更新为概率分布(具体可以参考工作3),代码整体上以功能实现且最小修改为主,优雅性和简介性请先容忍。
运行下面命令可开始训练,在此之前需要改一下数据的目录:
数据目录修改位置:src/lerobot/rl/learner.py中initialize_replay_buffer函数中
python -m lerobot.rl.learner --config_path rl_train_config.json
若从上一个状态恢复训练,需要修改:
- “output_dir”: “/home/ubuntu/Downloads/embodient/lerobot/lerobot/outputs/train/2026-01-24/21-36-11_default”,
- “output_dir”: null,
“job_name”: “default”,
- “resume”: true,
训练三小时后:
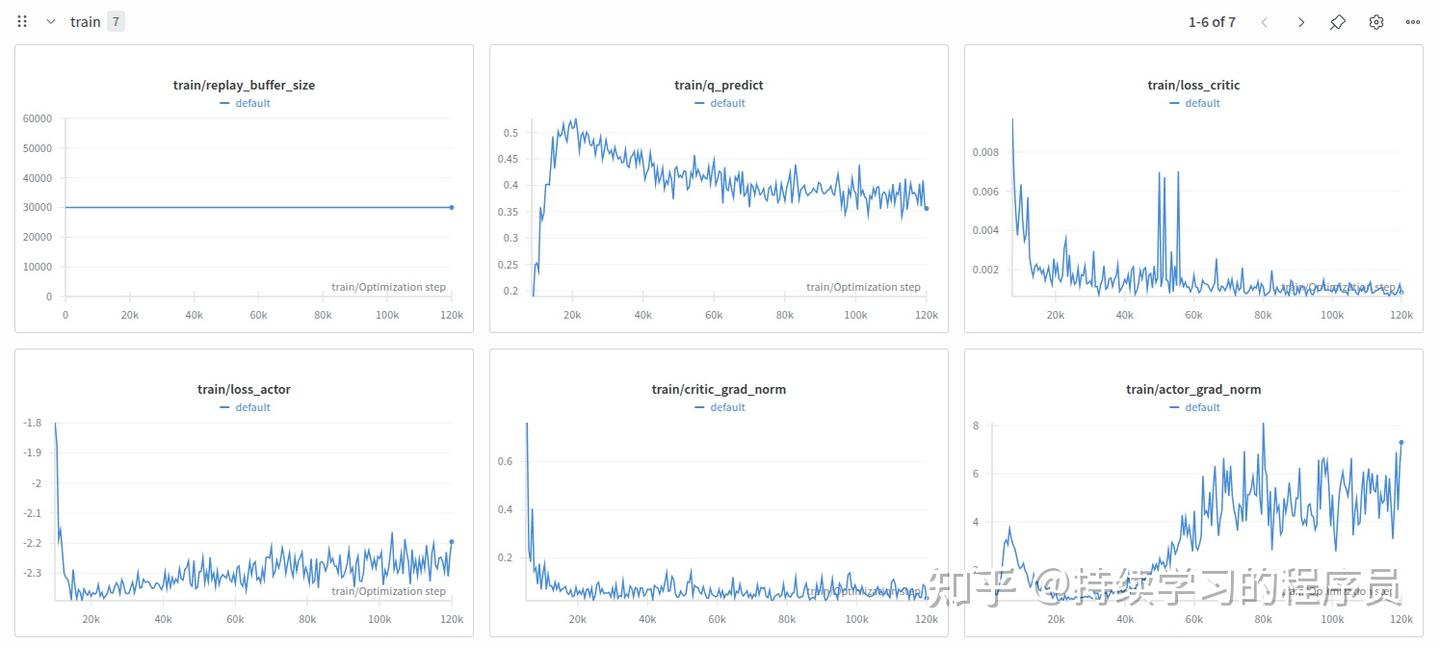
再训1.5小时
共训练了4.5h,180k个step,整体看起来100k最好,在指标上100k的q_predict最低,将评测的10个episode的Q值打印出来如下,可以发现整体上也是不错的,成功的几个episode(2,4,6,8)都有较好的趋势。整体上与工作一的确版本有一些差距,但已经很不错了。(其它节点的checkpoint效果可参考附录)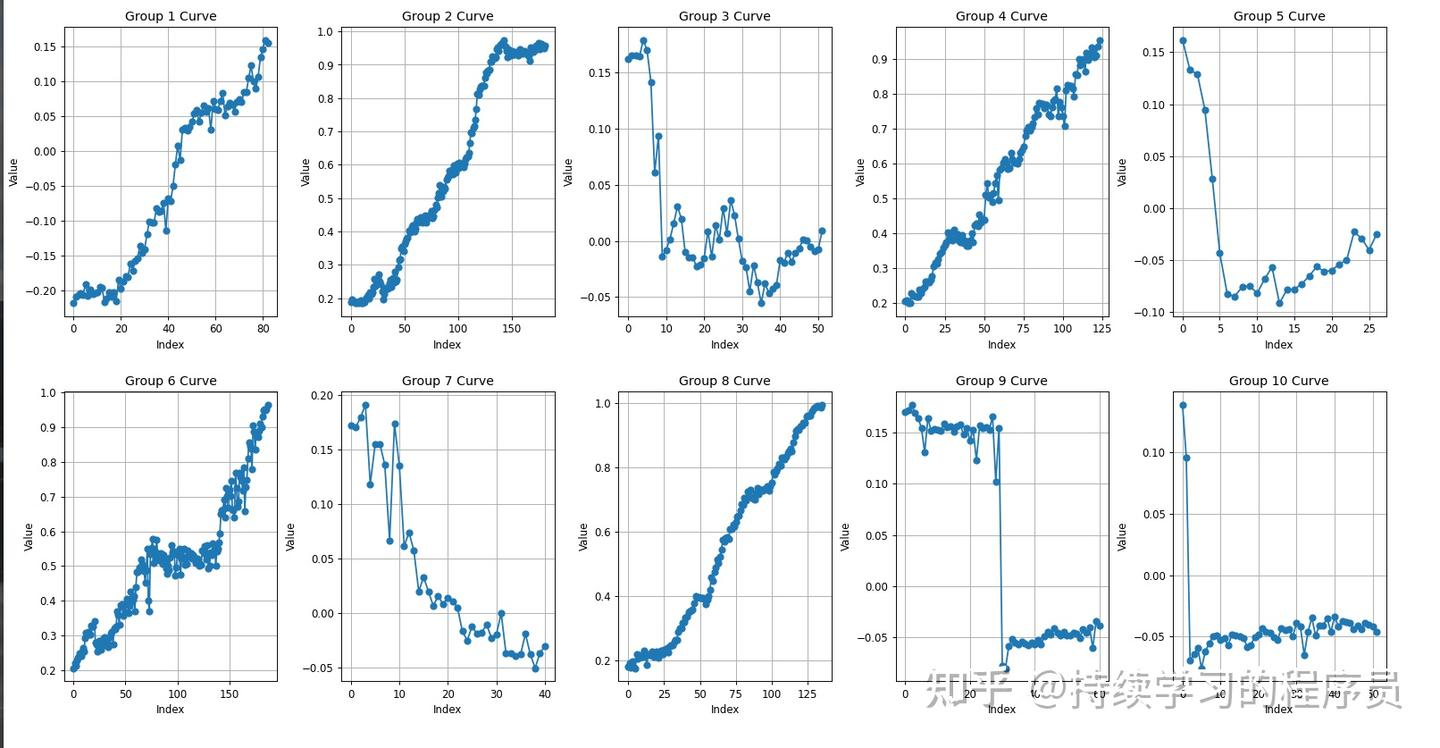
后续笔者会基于此offline训练出来的critic模型,继续进行online的强化学习,然后整体上与hil-serl对比一下,预期可以极大的缩短human in the loop的时间。
工作三:td3+bc+distributional版:带值分布的td3+bc , 基于c51算法
关于值分布的强化学习算法,有几篇文章讲得比较好:
强化学习新思潮1:值分布强化学习(02)
强化学习(RL)中有哪些重要的理论结果?
【DRL-7】Distributional DQN: Quantile Regression-DQN
【方法总结】值分布强化学习(Distributional RL)
笔者选择了c51算法进行复现,代码地址:https://github.com/hxdoit/lerobot.git,切换到分支td3_bc,其中版本:commit 006b33f3dc259f4fbdde1269ee3bf841180c14a0是经典td3+bc,再往后的提交中,又将critic函数的输出更新为概率分布,如果要尝试值分布的强化学习,就获取td3_bc分支的最新代码即可。
共训练了180k,指标曲线图如下:
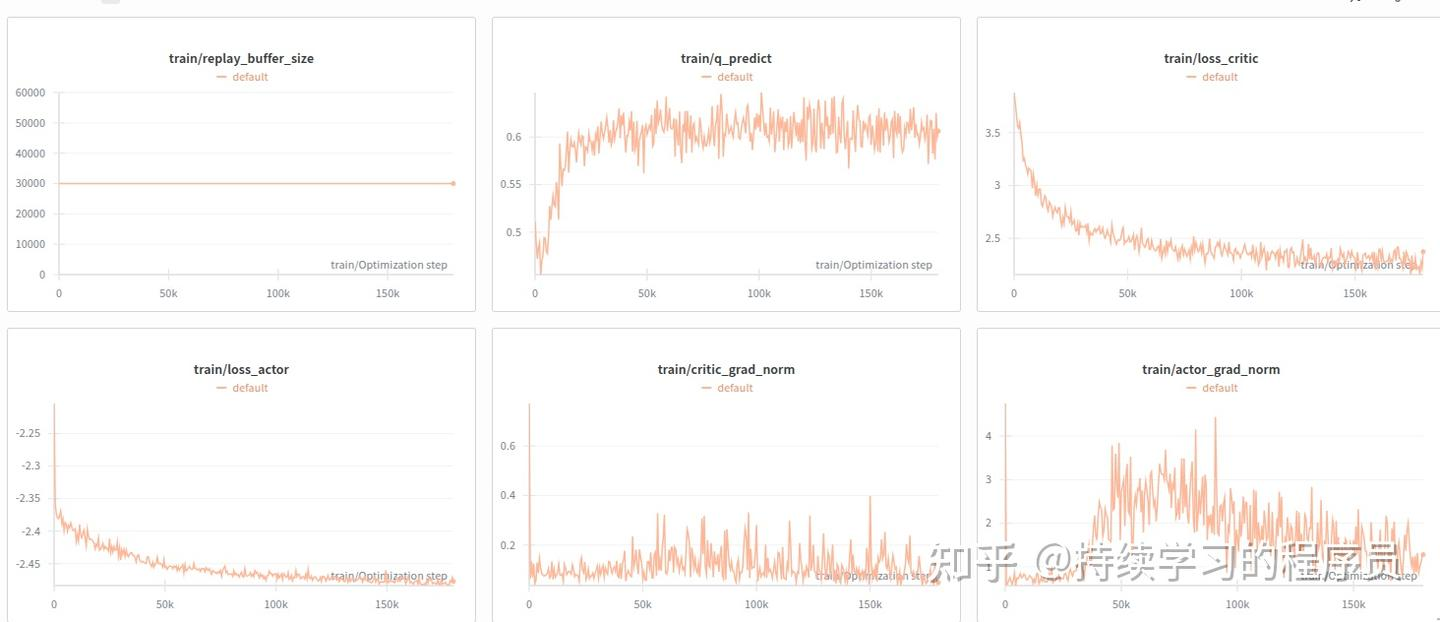
可视化了各episode的Q值,各个checkpoint版本没发现太大的区别,其中第120k的checkpoint的如下:(其它节点的checkpoint效果可参考附录)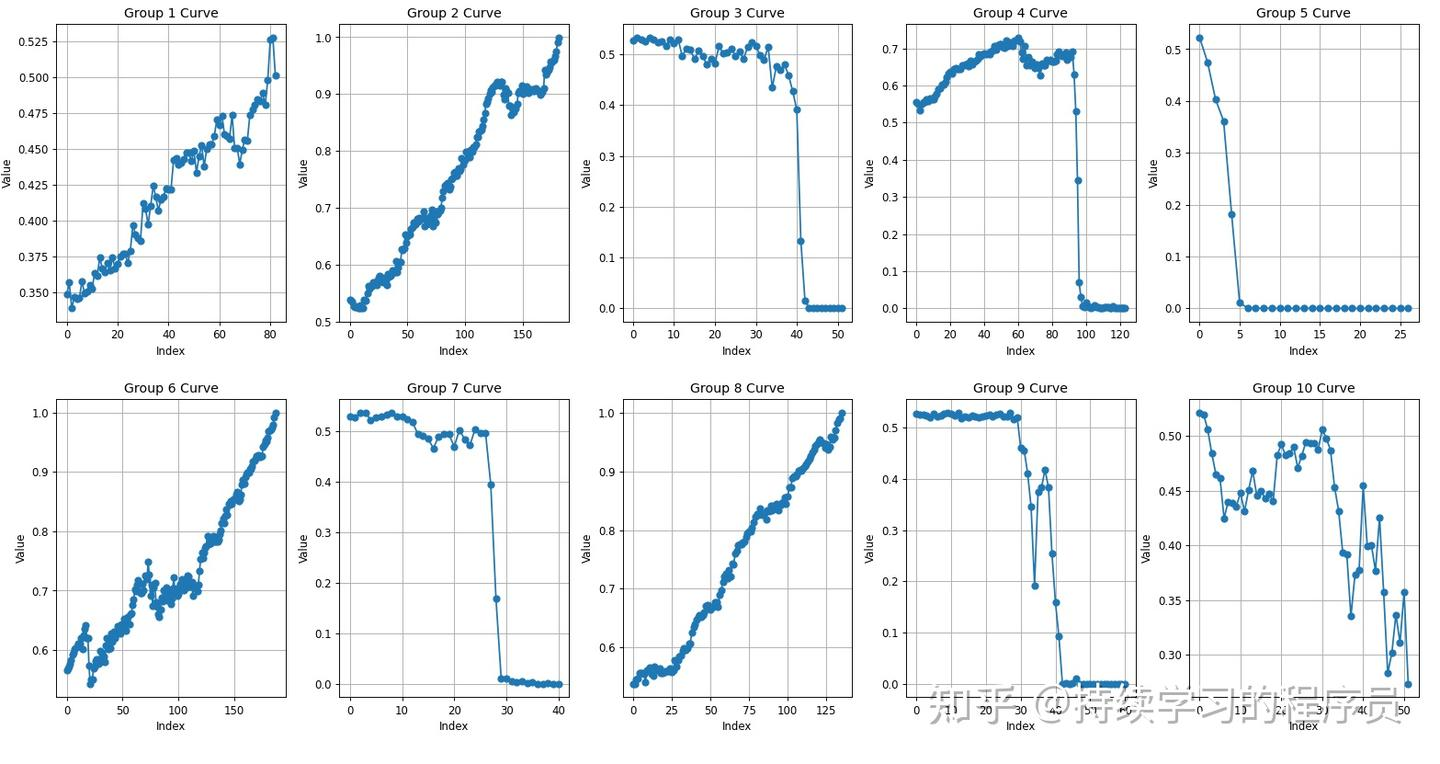
可以发现,整体上对于成功的episode也有一定的趋势,但效果并不如经典的td3+bc版本,图中成功的episode的Q值都是从0.6开始,且第4个episode的趋势也不对。失败的episode整体的Q值也比较大。
附录:
打印Q值可以临时修改代码如下:
— a/src/lerobot/rl/buffer.py
+++ b/src/lerobot/rl/buffer.py
@@ -234,11 +234,14 @@ class ReplayBuffer:
if not self.initialized:
raise RuntimeError(“Cannot sample from an empty buffer. Add transitions first.”)
-
batch_size = min(batch_size, self.size)
-
# batch_size = min(batch_size, self.size) -
batch_size = self.size high = max(0, self.size - 1) if self.optimize_memory and self.size < self.capacity else self.size # Random indices for sampling - create on the same device as storage
-
idx = torch.randint(low=0, high=high, size=(batch_size,), device=self.storage_device)
-
#idx = torch.randint(low=0, high=high, size=(batch_size,), device=self.storage_device) -
# all of data -
idx = torch.tensor(list(range(batch_size))).to('cuda:0') # Identify image keys that need augmentation image_keys = [k for k in self.states if k.startswith(OBS_IMAGE)] if self.use_drq else []
@@ -659,8 +662,19 @@ class ReplayBuffer:
if not has_done_key:
print(“‘next.done’ key not found in dataset. Inferring from episode boundaries…”)
-
for i in tqdm(range(num_frames)):
-
first_10_episodes_length = dataset.meta.episodes.select_columns('length')[:10]['length'] -
first_10_episodes_total_length = sum(first_10_episodes_length) -
import os -
import numpy as np -
from PIL import Image -
for i in tqdm(range(first_10_episodes_total_length)): current_sample = dataset[i] -
folder_name = f"group_{current_sample['episode_index']}" -
os.makedirs(folder_name, exist_ok=True) -
image_data = current_sample['observation.images.top'].numpy() -
image = Image.fromarray((image_data.transpose(1, 2, 0) * 255).astype(np.uint8)) -
image_path = os.path.join(folder_name, f"image_{i}.png") -
image.save(image_path) # 保存图片
— a/src/lerobot/rl/learner.py
+++ b/src/lerobot/rl/learner.py
@@ -330,7 +330,7 @@ def add_actor_information_and_train(
batch_size = cfg.batch_size
offline_replay_buffer = None
- if cfg.dataset is not None:
- if False and cfg.dataset is not None:
offline_replay_buffer = initialize_offline_replay_buffer(
cfg=cfg,
device=device,
@@ -395,7 +395,7 @@ def add_actor_information_and_train(
# Sample from the iterators
batch = next(online_iterator)
-
if dataset_repo_id is not None:
-
if False and dataset_repo_id is not None: batch_offline = next(offline_iterator)
将存储的图片列表转换成视频:
%03d.png,代表001.png,002.png…
ffmpeg -framerate 10 -i %03d.png -c:v libx264 -pix_fmt yuv420p output.mp4
工作二:经典td3+bc中各个checkpoint(20k-180k)的Q值趋势图:
180k
160k
140k
(120k)
100k
80k
60k
40k
20k
工作三:td3+bc+distributional中各个checkpoint(20k-120k)的Q值趋势图:
180k
160k
120k
100k
80k
60k

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)