dify进行RAG实战:法律法规RAG案例,90%以上准确度
RAG(Retrieval-Augmented Generation)系统需要数据标注和清洗以确保知识库的准确性和检索效率。在Dify系统中,自有知识库的分段会打上关键词,这些关键词是检索的关键。如果用户问题包含这些关键词,相关分段的得分会提高,从而增加被召回的概率。然而,自有知识库的关键词可能杂乱且与上下文无关,特别是在法律等场景中,分段有层级关系,用户问题可能需要结合多条法律条款解决。数据标注
1. 为什么RAG需要数据标注,数据清洗?
Dify如果你使用自有的知识库直接嵌入,它的分段里会给你打上关键词(也支持你自己编辑元数据),这个关键词就是查找的关键,如果用户的问题里直接包含了这个关键词,那么这个分段的得分自然就会高上去,得分高,被召回的可能性越大,那么大模型得到的知识是正确的概率就越大。
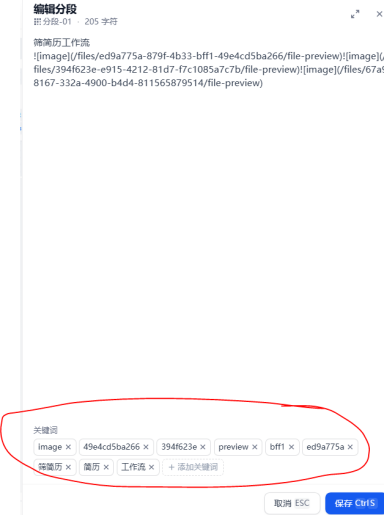
dify自有的知识库添加进去的话,关键词往往是杂乱的,且和上下文无关。但是在很多场景中,分段是有层级关系的,比如法律场景:第x章 第x条 第x款类似的场景,用户的问题往往是需要结合多条法律条款解决,需要返回多条法律,如果没有专门做标注,容易出现召回分数过低导致召回错误或召回不全的情况。
为了验证这一点,我们用一个例子,第一个知识库不做数据标注,第二个知识库做数据标注
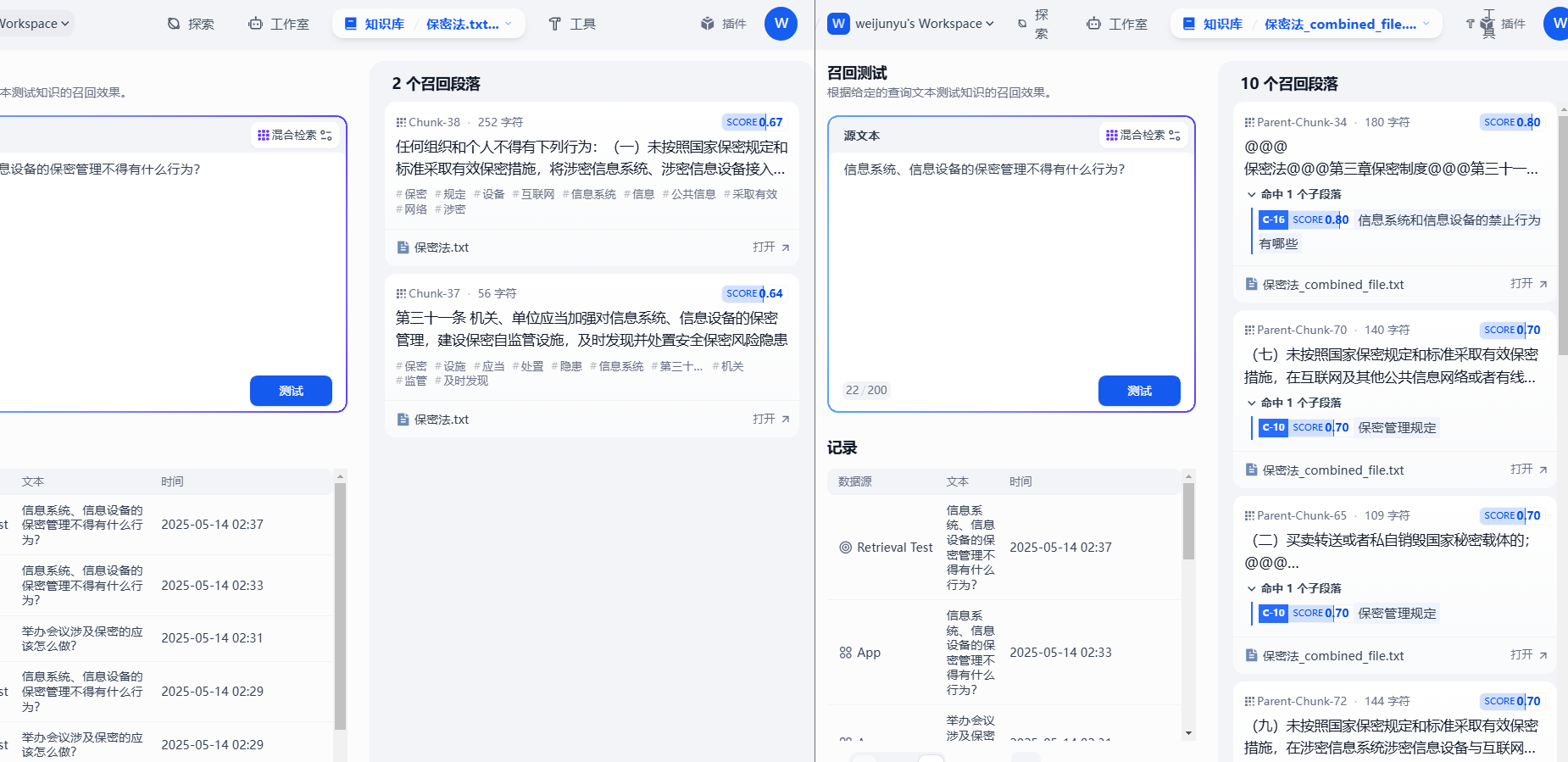
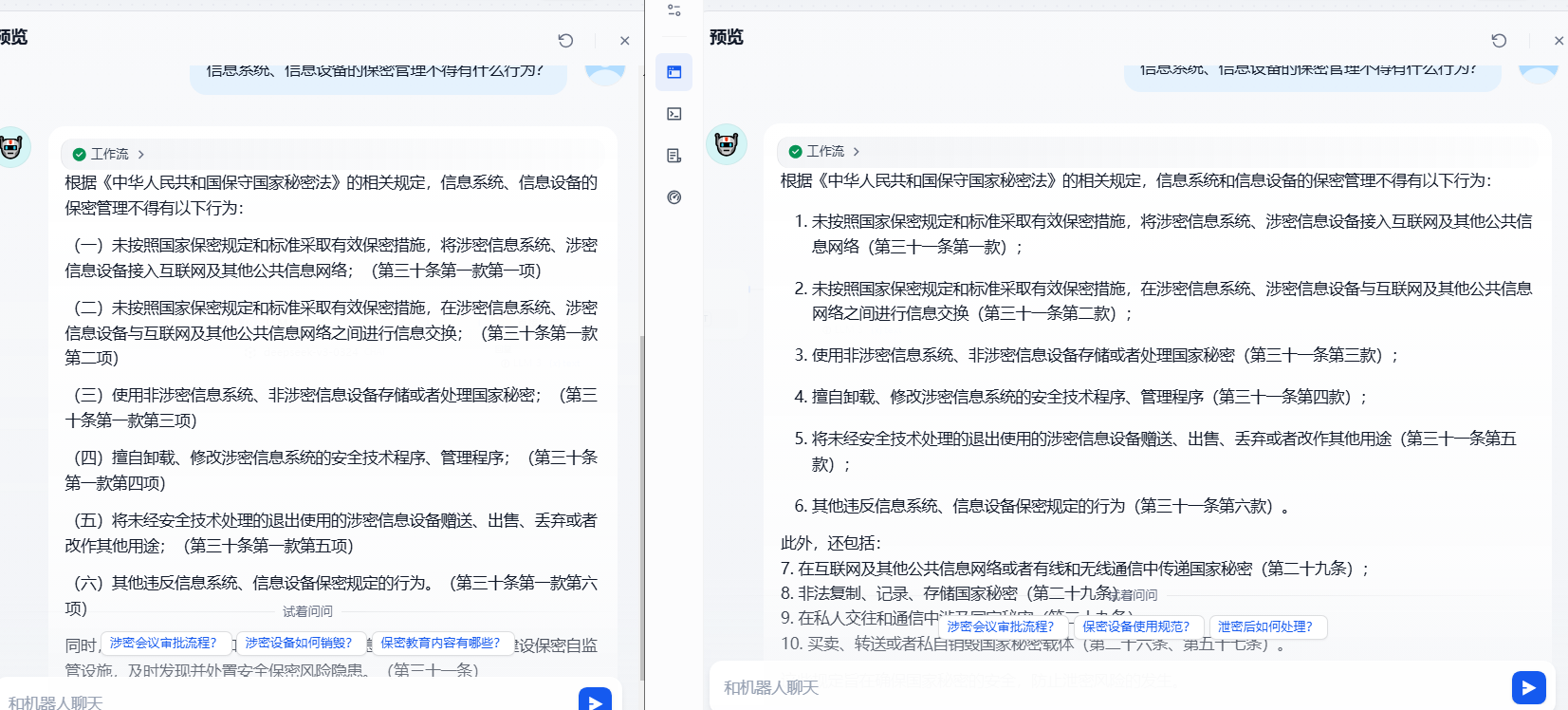
可以看到在召回测试中,不做数据标注,分数都偏低,这里我们都设置的是0.61的召回分数,不做数据标注仅能返回两条数据,注定了这种方式返回的段落给大模型参考会不够全面。
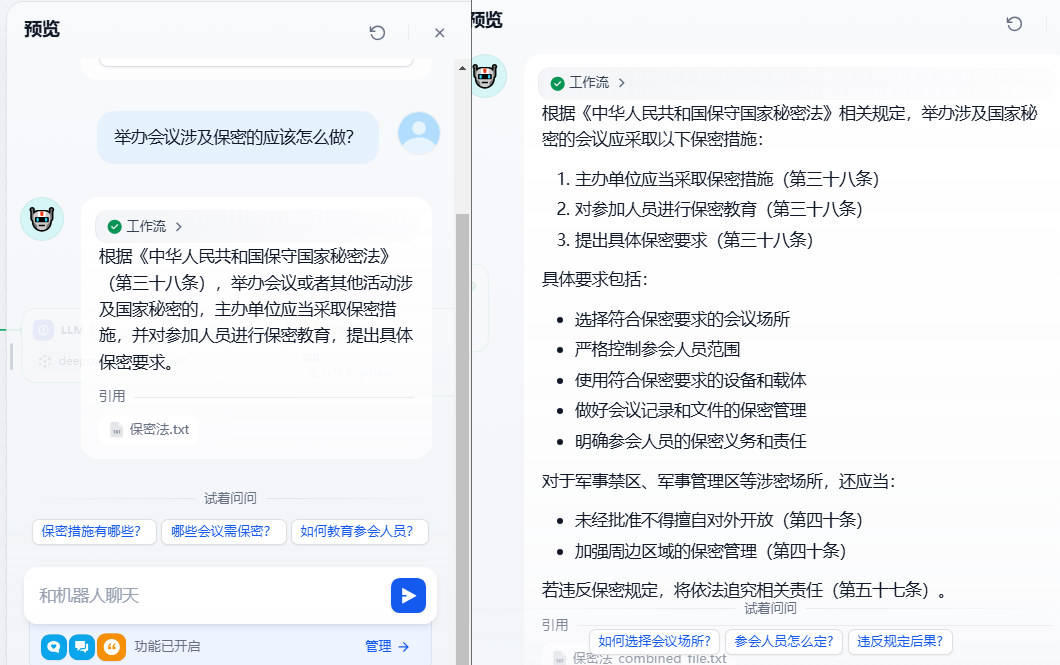
我们再使用相同问题提问,看谁的效果好,可以看到右边做了数据标注的知识库明显回答的要更加全面
2. 如何进行数据清洗和标注?以法律为例,通用标注见其他文档
第一步,选择合适的数据提取工具
如pdf格式的文件,你需要利用包括mineU,olm,marker-pdf等工具进行提取并转为md格式,转完以后,你需要检查是否出现问题。(这里特别注意,扫描件以及含有图片,很多表格的文件需要特别检查,这与当下ocr大模型的提取能力相关,每个工具都有自己的优势)
第二步,比如法律条文。运行法律条文数据标注,清洗工作流(dify)ps:这个工作流是b站一个大佬iCHN-DeepGen做的,我花了一百买来学习研究,过段时间我会把研究成果总结为文章,请继续关注我。
上传文件和输出文件名
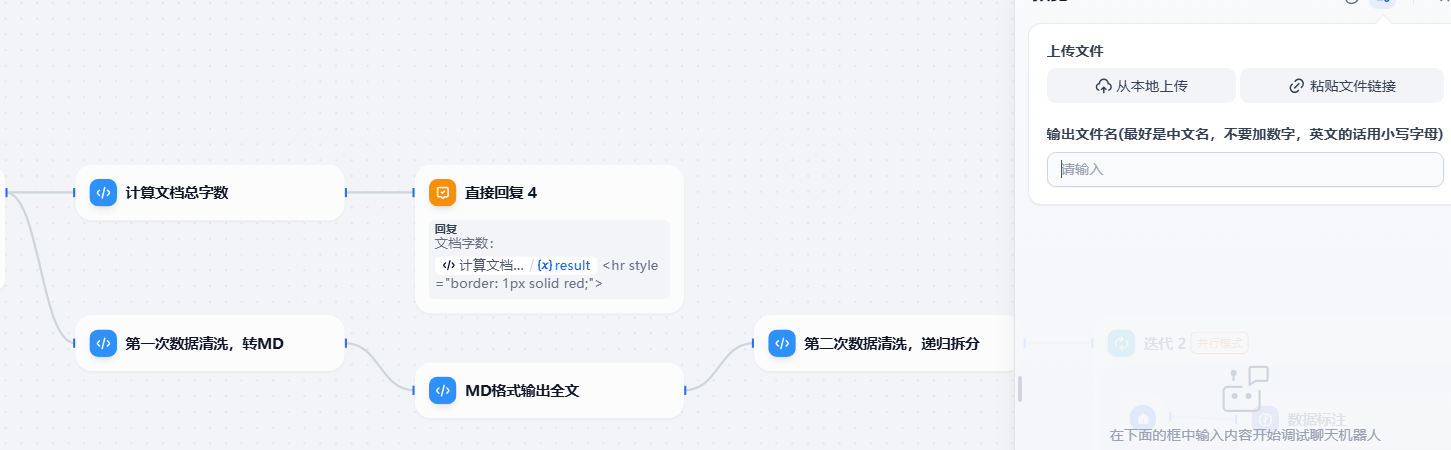
等待清洗完毕后,进入dify的这个目录,file是我创建的文件,用来保存写入的内容,配置文件和权限我已经设置好了,如果有疑问请参考另一篇文档《15-拆解工作流报错解决.pdf》在桌面的文档里
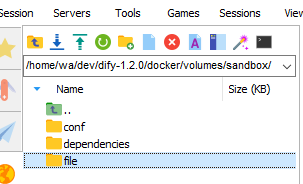
把刚刚 "你取的名字_combined_file.txt" 拿出来
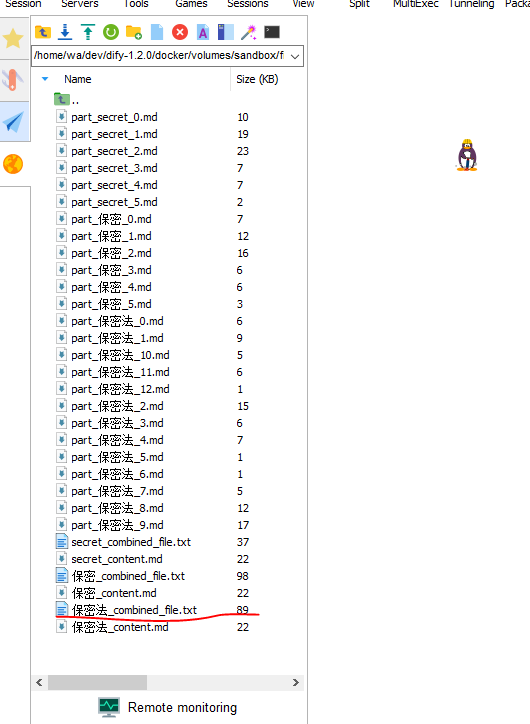
打开检查有没有问题,正常如下。若出现分段和标签有问题,可考虑是不是大模型不行换一个大模型或者对提示词做约束,我遇到过大模型输出的不是我要求的严格的json导致生成的内容和标签混乱的情况。####是分段 @@@是标签

3. 创建知识库,
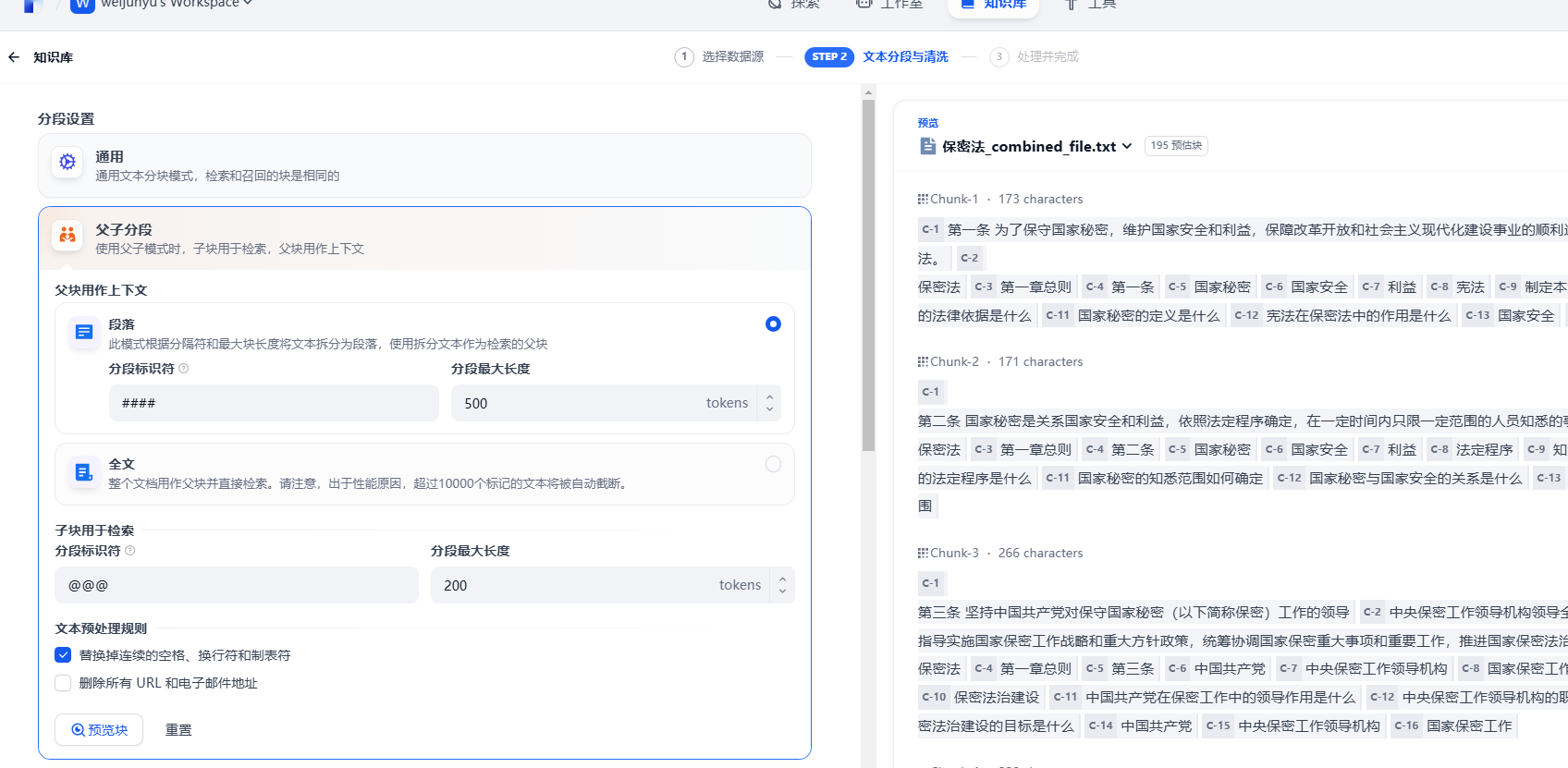
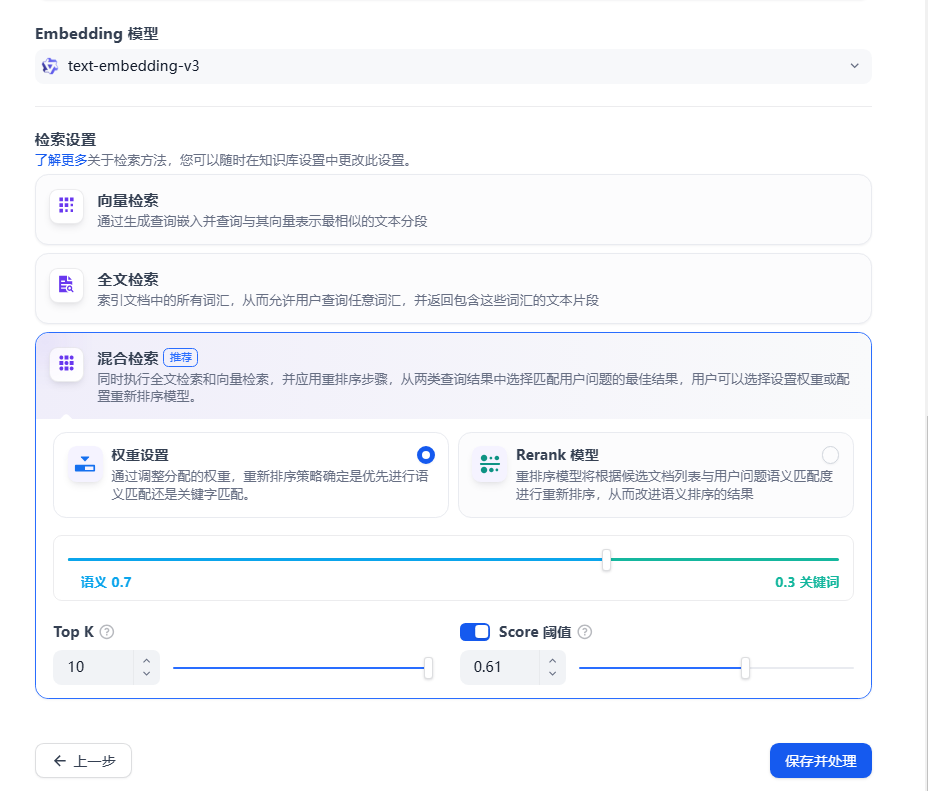
设置分段规则,选择父子分段,混合检索等,如图配置后,点击预览块,看看有没有正确分段。若出现没有包含完整的分块,可调整分段最大长度。父子分段可以很好地利用我们在数据清洗和标注产生的元数据进行检索,提高召回的分数,为大模型提供足够的语料,但是要注意使用score阈值来控制召回的数量,防止不相干数据污染大模型的输入。
4. 第四步,检索提问
使用大模型进行问题拆解,将复杂问题拆解
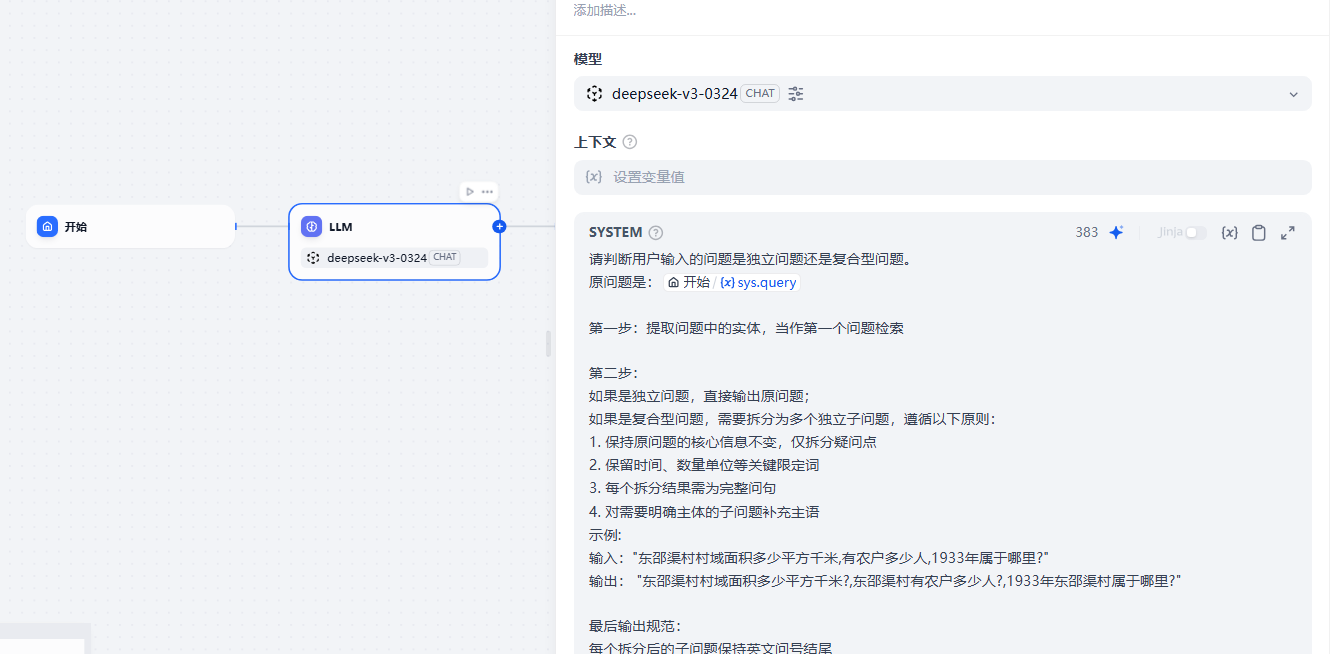
拆解为问题列表后迭代检索
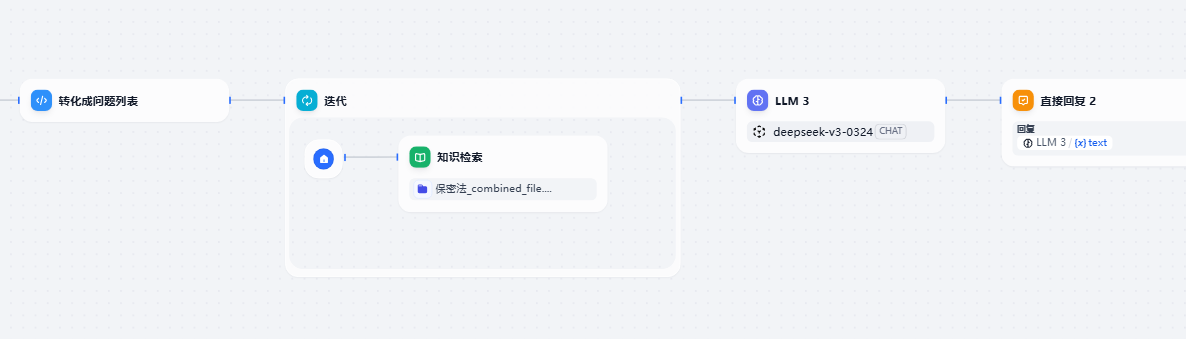
大模型的提示词设计也是非常重要的一环,这里不多赘述
5. 提问测试
使用用户提供或提前准备的测试问题进行测试,根据返回结果继续调整提示词策略或者召回数量。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 53
53 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)