大模型微调一文全解析
本文将带你走进大模型微调的世界,让你体会如何高效的让大模型根据自己的想法从基座模型变成某领域的专家。
引言:为什么大模型需要微调?
当我们惊叹于GPT-4的多轮对话能力、LLaMA的代码生成效率,以及 DeepSeek 深度解读问题的能力时,也会意识到它们的不完美,并非万能的,比如我要问一下某些专业领域的知识,它们也会卡壳,给出完全错误的信息,那么怎样才能让大模型完全具备我想让它具备的能力呢——答案就是微调,这些大模型的"通用能力"到"专属能力"的跨越,离不开微调技术的加持。想象一下,预训练大模型如同接受了"通识教育"的全才,而微调则是为其定制"专业课程"——通过注入医疗、法律等垂直领域的知识,让模型从"什么都懂一点"变成"某领域专家"。
那么为什么要选择微调呢,因为在算力有限的现实场景中,全量微调(调整所有参数)如同让全才重学专业知识,成本高昂(训练130B模型需数万GPU小时);而参数高效微调(PEFT)则像给全才配备"专业手册",仅需调整少量参数就能快速掌握领域技能,说白了就是可以花小钱办大事,这种既节省资源也能实现目的的方法渐渐成为了训练大模型的主流。本文将系统解析大模型微调的核心技术,从理论原理到实战代码,帮你掌握从"通用"到"专属"的转化密码。
下图是一般大模型得优化参数优化流程,你可以阅读一下这张图再来和微调做个对比。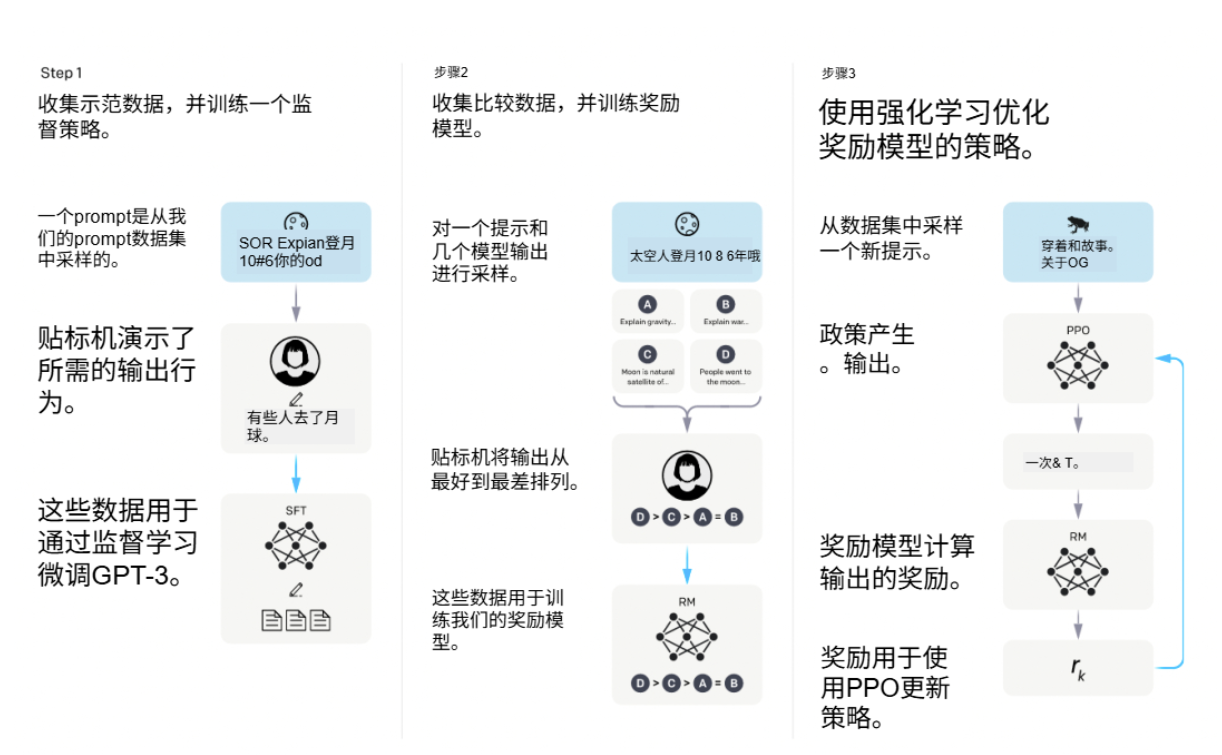
一、微调的底层逻辑
大模型的能力形成离不开"两阶段成长模型",理解这一机制可以让你更好的掌握微调的前提,接下来我们就来看看大模型预训练与微调的协同机制。
1. 预训练:构建通用知识基座
预训练如同模型的"基础教育阶段",通用能力也是在这个阶段完成的,具体训练是在海量无标注数据(如全网文本、书籍、代码)中学习语言规律和世界知识。以GPT-3为例:
- 训练数据量:45TB文本(约1万亿tokens)
- 核心目标:学习
P(next token | context)的概率分布,即给定上下文预测下一个词的能力 - 产出:具备"通用认知"的基座模型(Base Model),能完成简单问答、文本生成等基础任务,但缺乏领域深度
预训练的本质是无监督特征学习,通过Transformer的自注意力机制,模型将文本转化为包含语义、语法、逻辑的高维向量(如768维或1024维)。这些向量如同"知识积木",为后续微调提供基础。
我们常说的基座模型就是在这一阶段产生,我们来看一下关于基座模型的定义:基座模型(Foundation Model)是指通过大规模数据预训练、具备通用任务处理能力的底层人工智能模型。这类模型通常基于深度学习架构(如Transformer),能够通过微调或提示工程适配多种下游任务,成为各类AI应用的技术基础。典型代表包括GPT、BERT、Claude等大语言模型,以及Stable Diffusion等多模态模型。
从上面的正反基座模型解释的对比就可以看出,模型在这个时候才具备了微调的基本条件,下面我们就来看看什么是微调。
2. 微调
微调就相当于大模型的"专业教育阶段",在领域数据集上调整模型参数,让"通用知识"适配"特定任务"。例如:
- 医疗领域:用病历、医学论文微调,使模型能解读CT报告
- 法律领域:用法条、判例微调,使模型能生成合规合同
微调的核心不是"重学知识",而是调整知识的应用方式。以情感分析任务为例,预训练模型已理解"开心"是积极情绪,但微调需让它学会在电商评论中识别"物流慢"属于负面情感——这是知识在特定场景的适配。
到这里你可能对于微调已经有了一个模糊的概念,接下来我举一个实际例子来说明一下,假如我们现在要微调一个模型让它作为医生助手,为病人解答一些常识性问题,那现在这样的话我们就得现有一个医学常识数据集,数据格式可以如下:
格式:问题-答案对 示例: 问题:什么是高血压?
答案:高血压是指血液在血管中流动时对血管壁造成的压力持续高于正常水平,通常定义为收缩压≥140 mmHg和/或舒张压≥90 mmHg。
问题:糖尿病的主要症状有哪些?
答案:典型症状包括多饮、多尿、多食和体重下降(三多一少),还可能伴有疲劳、视力模糊和伤口愈合缓慢。
然后用这种数据去微调你的大模型,它就会具备医学问答常识,当然这个不是绝对的,还得看你数据集的质量以及微调的效果。
3. 全量微调 vs 参数高效微调
微调又分为全量微调与参数高效微调。全量微调是指在预训练模型的基础上,对所有参数进行更新以适应下游任务。这种方法通常需要较大的计算资源和数据量,但能够充分挖掘模型的潜力。这种微调方式的有点也很明显,模型性能上限高,能够充分利用预训练模型的知识,适合数据量充足且任务复杂的场景;但缺点也同样明显,计算成本高,容易过拟合,尤其是在数据量较少的情况下。
而参数高效微调则是通过冻结大部分预训练模型的参数,仅对少量新增或特定部分的参数进行微调,显著降低计算资源需求。
| 维度 | 全量微调 | 参数高效微调(PEFT) |
|---|---|---|
| 参数调整量 | 100%(如13B模型调整130亿参数) | 0.1%-10%(如13B模型调整130万-1.3亿参数) |
| 计算成本 | 极高(需多卡GPU集群) | 低(单卡GPU可完成) |
| 适用场景 | 通用大模型升级(如GPT-3→GPT-4) | 垂直领域适配(如医疗、金融) |
| 过拟合风险 | 高(需大规模领域数据) | 低(少量数据即可) |
| 典型代表 | GPT-3.5 Fine-tuning | LoRA、Adapter Tuning |
关键结论:90%的实际场景(尤其是企业级应用)不需要全量微调,PEFT技术已能满足需求。
二、Transformer架构
所有微调技术都围绕Transformer架构展开,理解其核心模块是掌握微调的基础。以Encoder-Decoder结构为例:
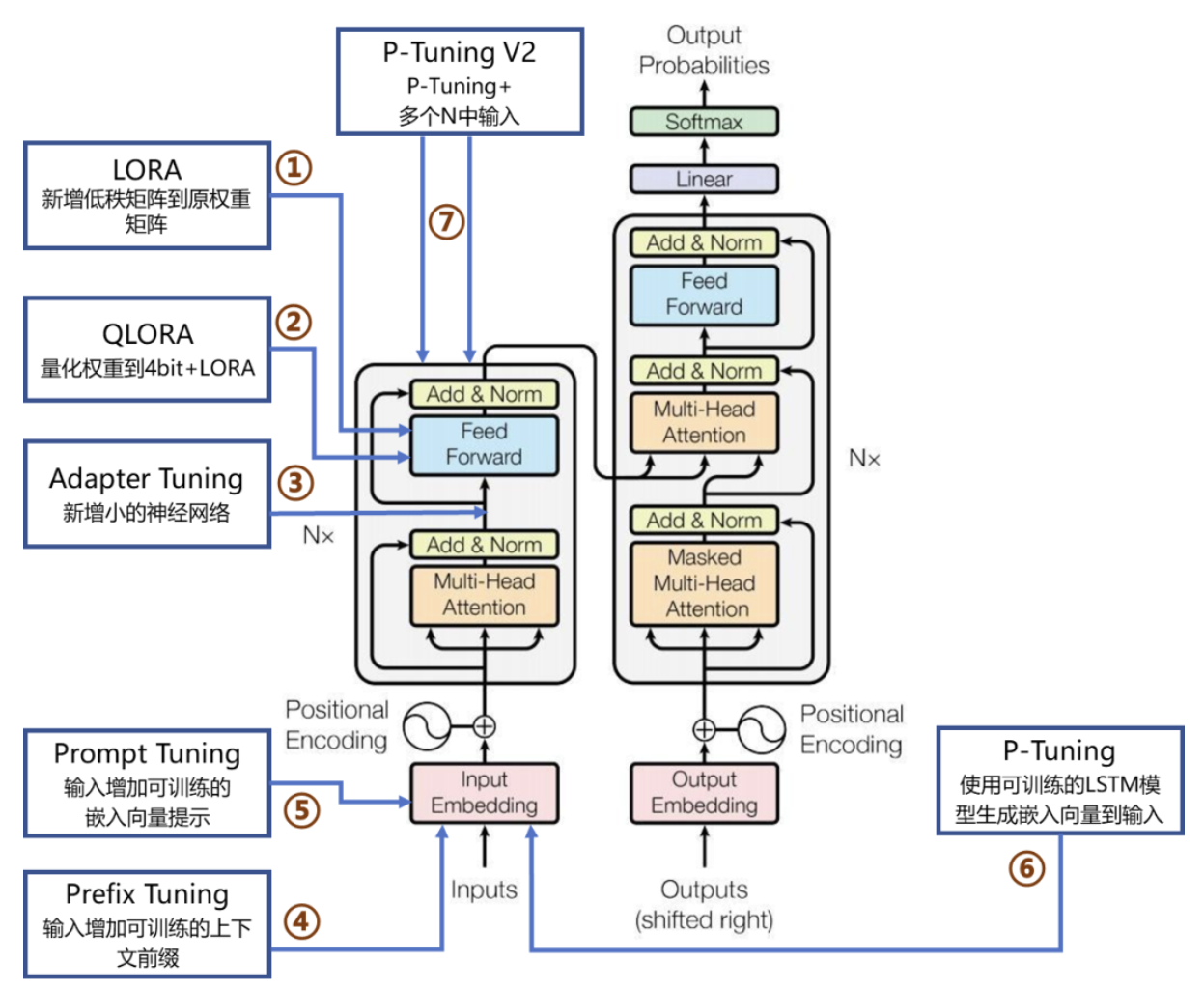
(文字描述:Transformer由输入嵌入层、编码器堆(含多头注意力+前馈网络)、解码器堆(含掩码注意力+交叉注意力)、输出层组成。不同微调技术在这些模块中插入可训练参数:LoRA修改注意力权重矩阵,Adapter在层间插入小网络,Prefix Tuning在输入层添加前缀向量。)
核心模块与微调关联
-
输入嵌入层:将文本转为向量(如Word2Vec、SentencePiece)。Prefix Tuning、Prompt Tuning在此处添加可训练的"虚拟前缀"。
-
多头自注意力(MHA):模型的"理解核心",通过多个注意力头捕捉不同语义关系。LoRA、QLoRA在此处修改权重矩阵,注入领域知识。
-
前馈网络(FFN):对注意力输出做非线性变换(Linear→ReLU→Linear)。Adapter Tuning常在此处插入"瓶颈适配器"。
-
层归一化(Layer Norm):稳定训练的关键(防止梯度爆炸)。部分微调方法(如SSF)通过缩放/偏移归一化后的特征实现适配。
三、参数高效微调(PEFT)核心技术详解
1. LoRA
核心思想:不直接修改原始权重,而是通过低秩矩阵的乘积近似权重更新,大幅减少参数量。
技术原理
- 原始注意力权重矩阵: W ∈ R d × d W \in \mathbb{R}^{d \times d} W∈Rd×d(如d=1024)
- 低秩分解: W = W 0 + B A W = W_0 + BA W=W0+BA,其中 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r, A ∈ R r × d A \in \mathbb{R}^{r \times d} A∈Rr×d, r ≪ d r \ll d r≪d(通常r=8-32)
- 参数量对比:原始需 d 2 d^2 d2参数,LoRA仅需 r × d + d × r = 2 r d r \times d + d \times r = 2rd r×d+d×r=2rd(如d=1024,r=16时,参数减少99.7%)
数学表达
微调时仅优化A和B,推理时将 B A BA BA叠加到 W 0 W_0 W0:
新权重 = W 0 + B A \text{新权重} = W_0 + BA 新权重=W0+BA
这种设计让模型在保留预训练知识的同时,快速学习领域特征。
实战代码(Hugging Face PEFT)
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载基座模型
model = AutoModelForCausalLM.from_pretrained("chavinlo/alpaca-native")
tokenizer = AutoTokenizer.from_pretrained("chavinlo/alpaca-native")
# 配置LoRA
lora_config = LoraConfig(
r=16, # 秩
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 目标注意力层
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 转换为LoRA模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 输出:可训练参数占比 ~0.1%
# 训练(伪代码)
# trainer = Trainer(...)
# trainer.train()
优缺点与适用场景
- 优点:参数最少(0.1%-1%)、推理速度快(无需额外计算)、支持多任务切换(仅保存低秩矩阵)
- 缺点:对极复杂任务(如长文本推理)效果略逊
- 适用场景:资源受限场景(单卡训练)、多任务适配(如同时微调客服+营销文案生成)
2. QLoRA
QLoRA是LoRA的"轻量化升级版",通过4位量化技术将模型显存需求降低75%,让33B模型可在单卡24GB GPU上微调。
核心创新:4位NormalFloat(NF4)量化
- 传统量化(如INT4)将权重映射到均匀分布,导致精度损失大;
- NF4针对神经网络权重的正态分布设计,保留更多关键信息(尤其是尾部极端值)。
量化流程
- 模型权重从32位浮点(FP32)量化为4位NF4,存储在显存中;
- 训练时临时反量化为16位脑浮点(BF16)进行计算;
- 低秩矩阵(A和B)仍用BF16存储,保证训练精度。
效果对比
| 模型规模 | 全量微调显存 | LoRA(16位) | QLoRA(4位) |
|---|---|---|---|
| 7B | 28GB | 10GB | 4GB |
| 33B | 132GB | 48GB | 10GB |
| 175B | 700GB | 250GB | 40GB |
适用场景
- 超大模型微调(如LLaMA-33B、Falcon-40B)
- 边缘设备微调(如服务器单卡24GB GPU)
3. Adapter Tuning:插入式"专业模块"
Adapter Tuning如同给模型加装"领域插件"——在Transformer层间插入小型神经网络(适配器),仅训练这些插件参数。
适配器结构(瓶颈设计)
每个适配器由3部分组成:
- Down Project:将输入特征(如1024维)压缩到低维(如64维);
- 激活函数:通常用ReLU或GELU引入非线性;
- Up Project:将低维特征还原回原维度(1024维)。
数学表达:
输出 = 原始特征 + Up ( ReLU ( Down ( 原始特征 ) ) ) \text{输出} = \text{原始特征} + \text{Up}(\text{ReLU}(\text{Down}(\text{原始特征}))) 输出=原始特征+Up(ReLU(Down(原始特征)))
(残差连接确保不破坏预训练特征)
在Transformer中的位置
- 主流方案:在多头注意力后、前馈网络后各插入一个适配器(共2N个,N为层数)。
优缺点与适用场景
- 优点:任务隔离性好(不同任务用不同适配器)、可灵活增减模块
- 缺点:推理时需额外计算适配器,速度略慢
- 适用场景:多任务独立微调(如同一模型同时适配医疗+教育领域,互不干扰)
4. Prefix Tuning
Prefix Tuning通过在输入序列前添加可训练的"前缀向量",引导模型生成符合任务需求的输出,如同给模型"写提示词模板"。是一种轻量级的微调方法,用于大型语言模型(LLMs)。一般是在模型输入前添加可学习的连续向量(称为前缀)来调整模型行为,避免直接修改模型参数,从而减少计算开销。适用于资源有限场景下的任务适配。
技术原理
- 前缀向量(如10个虚拟token)在输入嵌入层插入,随任务数据训练;
- 参数高效:仅优化前缀部分的参数,冻结原始模型权重,显著降低训练成本。
- 任务适配:不同任务可配置独立的前缀,实现多任务共享同一模型。
- 模型在生成时,会根据前缀"理解"当前任务(如"生成客服回复"vs"生成产品描述")。
实现步骤
-
初始化前缀矩阵
随机生成形状为(prefix_length, hidden_size)的矩阵,作为可训练参数。
示例代码(PyTorch):prefix = torch.nn.Parameter(torch.randn(prefix_len, hidden_dim)) -
拼接输入序列
将前缀与输入嵌入向量拼接:modified_input = concat([prefix, input_embeddings]) -
冻结原模型
确保仅前缀参数参与梯度更新:for param in model.parameters(): param.requires_grad = False -
优化目标
最小化任务特定损失函数(如交叉熵):
L = − ∑ t log P ( y t ∣ y < t , prefix , x ) \mathcal{L} = -\sum_{t} \log P(y_t | y_{<t}, \text{prefix}, x) L=−t∑logP(yt∣y<t,prefix,x)
对比传统微调
| 方面 | Prefix Tuning | 全参数微调 |
|---|---|---|
| 参数量 | 仅前缀部分(~0.1%) | 全部模型参数 |
| 计算资源 | GPU内存占用低 | 要求高 |
| 多任务支持 | 通过切换前缀实现 | 需保存多个模型副本 |
与Prompt Tuning的区别
| 维度 | Prefix Tuning | Prompt Tuning |
|---|---|---|
| 前缀长度 | 较长(10-100个虚拟token) | 较短(1-10个虚拟token) |
| 作用范围 | 影响所有Transformer层 | 主要影响输入层 |
| 任务适应性 | 复杂任务(如长文本生成)更优 | 简单分类任务更优 |
适用场景
- 文本生成任务(如广告文案、邮件自动回复)
- 需要保留模型通用风格的场景(如用同一模型生成不同品牌调性的文案)
- 低资源环境:如单卡GPU适配大模型。
- 快速迭代:需要频繁尝试不同任务的场景。
- 隐私保护:原始模型参数不暴露,仅传输前缀。
变体与改进
- 离散提示:将连续前缀替换为可解释的离散token。
- 分层前缀:为不同网络层分配独立前缀。
- 混合微调:结合LoRA等参数高效方法。
注意事项
- 前缀长度影响效果,通常建议10-100个token。
- 初始学习率需调优,过高易导致训练不稳定。
- 部分任务(如生成多样性要求高)可能需结合其他技术。
通过合理设计前缀结构和训练策略,Prefix Tuning能在性能与效率间取得平衡,成为轻量化部署的重要选择。
5. Prompt Tuning
Prompt Tuning 是一种通过优化输入提示(Prompt)来调整预训练语言模型行为的轻量级微调方法。与传统微调(Fine-tuning)相比,它仅需调整少量参数(如软提示或前缀),从而降低计算成本并保持模型泛化能力。
核心原理
-
软提示(Soft Prompts)
传统提示是人工设计的文本(硬提示),而软提示是通过学习得到的连续向量,直接拼接到输入前。这些向量通过梯度下降优化,无需修改模型参数。 -
参数效率
仅需调整提示部分的参数(通常占比小于1%),冻结模型主体,适合资源有限场景。
实现步骤
初始化软提示
随机生成一组可训练的词向量作为提示,长度通常为10-100个token。
优化目标
使用下游任务(如分类、生成)的损失函数,通过反向传播更新软提示参数。例如,分类任务采用交叉熵损失:
L = − ∑ y log p ( y ∣ x , prompt ) \mathcal{L} = -\sum y \log p(y|x, \text{prompt}) L=−∑ylogp(y∣x,prompt)
推理阶段
将训练好的软提示与输入拼接,模型基于调整后的上下文生成结果。
代码示例(PyTorch)
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# 初始化软提示(假设长度为5)
soft_prompt = torch.randn(5, model.config.hidden_size, requires_grad=True)
optimizer = torch.optim.Adam([soft_prompt], lr=1e-3)
# 训练循环
for input_ids, labels in dataloader:
inputs_embeds = model.bert.embeddings(input_ids)
inputs_embeds = torch.cat([soft_prompt.unsqueeze(0).repeat(inputs_embeds.shape[0], 1, 1), inputs_embeds], dim=1)
outputs = model(inputs_embeds=inputs_embeds)
loss = torch.nn.functional.cross_entropy(outputs.logits, labels)
loss.backward()
optimizer.step()
应用场景
- 小样本学习:在数据稀缺时,通过提示调整快速适配任务。
- 多任务学习:为不同任务学习独立提示,共享同一模型 backbone。
- 领域适应:调整提示使模型适应新领域,如医疗、法律文本。
优势与限制
- 优势:参数高效、避免灾难性遗忘、易于部署。
- 限制:提示设计影响性能,长提示可能增加计算开销。
6. 其他主流方法对比
| 方法 | 核心思想 | 可训练参数占比 | 典型应用场景 |
|---|---|---|---|
| P-Tuning | 用LSTM生成动态提示向量 | 0.5%-2% | 自然语言理解(如实体识别) |
| P-Tuning v2 | 多层插入提示向量 | 1%-5% | 复杂推理任务(如法律条款解析) |
| SSF | 缩放+偏移特征向量 | 0.1% | 轻量级领域适配(如情感分析) |
三、微调实战指南
1. 数据集准备:质量比数量更重要
- 规模:PEFT方法对数据量要求低(领域数据1k-10k样本即可);
- 格式:结构化任务(如分类)用<输入, 标签>,生成任务用<指令, 输出>(如"写一封道歉邮件:[客户投诉内容] → [回复]);
- 清洗:去除重复、错误数据(如医疗数据中的错误诊断),避免模型学错知识。
2. 超参数选择:不同方法的"最佳实践"
| 方法 | 学习率 | 训练轮次 | Batch Size | 优化器 |
|---|---|---|---|---|
| LoRA/QLoRA | 3e-4 ~ 5e-4 | 3 ~ 10 | 4 ~ 16 | AdamW |
| Adapter Tuning | 1e-4 ~ 3e-4 | 5 ~ 15 | 8 ~ 32 | Adam |
| Prefix Tuning | 5e-5 ~ 1e-4 | 10 ~ 20 | 2 ~ 8 | AdamW |
关键原则:参数调整越少,学习率可适当越大(如LoRA比全量微调学习率高10倍)。
3. 评估指标:不只看准确率
- 领域指标:医疗任务看F1(实体识别),生成任务看BLEU(翻译)、ROUGE(摘要);
- 通用能力:用保留的通用数据集(如GLUE)测试,避免"领域过拟合"(只会领域任务,丢失通用能力);
- 人工评估:复杂任务(如法律合同生成)需专家检查合规性。
4. 部署策略:从训练到落地
- LoRA/QLoRA:推理时将低秩矩阵合并到原始权重,无额外延迟;
- Adapter:推理时加载适配器参数,需修改推理代码(如Hugging Face Pipeline添加适配器);
- 多任务部署:保存多个低秩矩阵/适配器,按需加载(如早班加载客服模型,晚班加载营销模型)。
结语:微调是"赋能"而非"重构"
大模型微调的本质,不是让模型变成"全新物种",而是最大化利用其预训练知识,快速适配特定需求。从企业角度,用QLoRA微调7B模型解决客服问题,成本仅需数千元,远低于训练专属模型的数百万;从研究者角度,PEFT技术让小实验室也能玩转大模型,推动AI民主化。
选择微调方法时,不必追求"最先进",而要贴合场景:资源有限选QLoRA,多任务选Adapter,生成任务选Prefix Tuning。记住,最好的微调是"润物细无声"——用户只感受到模型变"专业"了,却不知道背后只调整了0.1%的参数。
现在,不妨从用LoRA微调一个简单任务(如公司产品说明书生成)开始,体验大模型从"通用"到"专属"的神奇蜕变。
参考文章:
【大模型微调】一文掌握7种大模型微调的方法
【大模型开发 】 一文搞懂Fine-tuning(大模型微调)
模型微调之基础篇:模型微调概念以及微调框架

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)