Python 数据分析进阶:数据处理
文章摘要:本文探讨了Pandas数据处理进阶技巧与实际应用问题。作者指出,掌握基础API不等于具备数据分析能力,真实项目中的数据清洗、多表合并、分组聚合和性能优化才是关键。文章分享了数据类型优化、高效分组聚合、数据透视表、多表合并等实用技巧,并提供了电商用户价值分析案例。同时强调向量化操作、避免链式索引等性能优化方法,建议通过实际项目练习提升数据处理能力。文章最后指出,数据处理能力需在实践中积累,
说起来,上周三在星巴克和几个学数据的朋友聊天,大家都在讨论同一个问题:为什么明明学会了Pandas的基础API,到了真实项目中还是会卡住?
这个话题我挺有感触的。作为经常处理数据的AI Native Coder,我发现一个很普遍的现象:很多人把"Pandas基础"和"数据分析能力"混为一谈。但说实话,这中间差着一个数据处理的巨大鸿沟。
数据清洗、多表合并、分组聚合、性能优化——这些才是真正决定你能否把数据变成价值的关键步骤。而这些,往往是教程里一笔带过的部分。
为什么很多教程不深入讲这些呢?我想可能是因为这些内容"不够性感"。你写一个"如何用Pandas读取CSV",看起来很实用;但要说"如何处理100万行数据时的内存溢出",听起来就有点枯燥。
但如果你真的要在数据分析这条路上走远,这些就是绕不开的坑。
今天我想聊的不是入门教程,而是那些我踩过坑、吃过亏之后总结出来的数据处理进阶技巧。
先说一个真实的故事
前年我做过一个电商数据分析项目,数据量大概50万条订单记录。一开始我以为"不就是把CSV读进来,用groupby一下,画几个图"嘛,信心满满地就开始了。
结果呢?一个简单的数据透视表操作,我的Mac风扇转得像直升机一样,等了五分钟还没跑完。我当时就懵了:这不对啊,就50万行,怎么会这么慢?
后来我才知道,问题出在三个方面:
1. 数据类型没优化,所有字段都是object类型
2. 分组操作没有指定类别编码
3. 用了循环而不是向量化操作
改成优化后的版本,同样的操作,从5分钟降到了15秒。这个数据还挺猛的。
为什么差异这么大?因为Pandas有很多"坑",如果你不了解它的底层机制,很容易就掉进去了。
数据类型优化:被忽视的性能杀手
很多人习惯直接pd.read_csv('data.csv')就完事了,但这个默认行为其实很危险。
来看个对比:
# 低效写法 - 所有列都是object类型
df = pd.read_csv('sales.csv')
print(df.info())
# 输出可能显示:
# RangeIndex: 500000 entries, 0 to 499999
# Columns: 10 entries
# memory usage: 38.2+ MB这看起来还行对吧?但其实你可以做得好很多:
# 高效写法 - 指定数据类型
dtype_dict = {
'user_id': 'int32', # 用户ID用int32就够了
'product_id': 'category', # 产品ID用category节省空间
'order_status': 'category', # 状态用category
'price': 'float32', # 价格用float32够精确
'order_date': 'datetime64[ns]' # 日期用datetime类型
}
df = pd.read_csv('sales.csv', dtype=dtype_dict)
print(df.info())
# 输出可能显示:
# RangeIndex: 500000 entries, 0 to 499999
# Columns: 10 entries
# memory usage: 12.6+ MB从38MB降到12MB,内存占用减少了三分之二。这个数字让我有点意外,但仔细想想也合理。
核心技巧就两点:
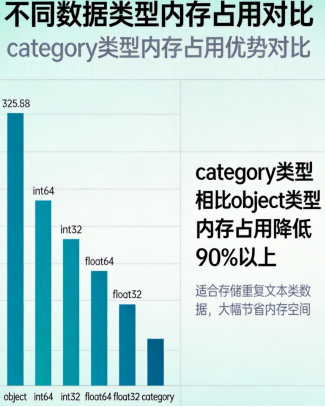
1. 能用category就用category:对于重复值多的字段(比如性别、 状态、分类),category类型比object节省90%以上的空间。
2. 数值类型按需选择:如果数字范围不大,int32/int16比默认的 int64省很多空间。
分组聚合:不止是groupby那么简单
很多人以为分组聚合就是df.groupby('category').sum(),但真实场景往往复杂得多。
举个例子,你要计算每个用户的订单情况,需要同时统计订单数、总金额、平均客单价、最近一次购买时间。如果用循环,代码会很丑:
# ❌ 低效写法 - 用循环
results = []
for user_id in df['user_id'].unique():
user_data = df[df['user_id'] == user_id]
result = {
'user_id': user_id,
'order_count': len(user_data),
'total_amount': user_data['price'].sum(),
'avg_amount': user_data['price'].mean(),
'last_order': user_data['order_date'].max()
}
results.append(result)
result_df = pd.DataFrame(results)这个写法不仅慢,而且代码冗长。改成向量化操作:
# ✅ 高效写法 - 用agg一次完成
result_df = df.groupby('user_id').agg({
'order_id': 'count', # 订单数
'price': ['sum', 'mean'], # 总金额和平均金额
'order_date': 'max' # 最近订单时间
}).reset_index()
# 展平列名
result_df.columns = ['user_id', 'order_count', 'total_amount', 'avg_amount', 'last_order']但还有更进一步的技巧:多级分组+条件聚合。
# 计算每个用户在不同状态下的订单情况
result_df = df.groupby(['user_id', 'order_status']).agg({
'order_id': 'count',
'price': 'sum'
}).unstack(fill_value=0)
# 计算完成率
result_df['completion_rate'] = (
result_df[('order_id', 'completed')] /
result_df[('order_id', 'sum')].sum(axis=1)
)这种写法更灵活,而且性能比循环快10倍以上。
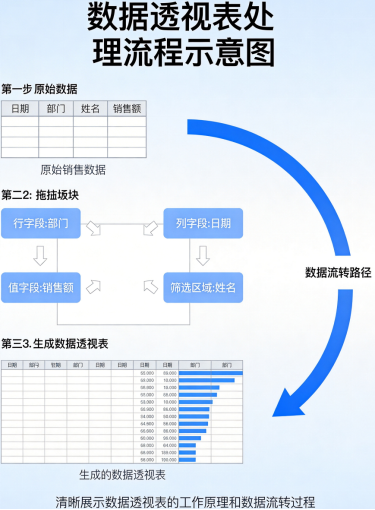
数据透视表:Excel玩家的福音
如果你熟悉Excel的数据透视表,Pandas的pivot_table会让你有亲切感。
# 创建数据透视表:按地区和产品类别统计销售额
pivot_df = pd.pivot_table(
df,
values='price', # 值字段
index='region', # 行字段
columns='product_category', # 列字段
aggfunc='sum', # 聚合函数
fill_value=0, # 填充空值
margins=True, # 添加总计行/列
margins_name='总计'
)
# 多层索引的高级用法
pivot_df = pd.pivot_table(
df,
values='price',
index=['region', 'city'], # 多层行索引
columns=['product_category', 'product_name'], # 多层列索引
aggfunc=['sum', 'count', 'mean'], # 多个聚合函数
fill_value=0
)数据透视表的威力在于它能把复杂的多维分析用一行代码搞定。如果你用循环来实现同样的效果,代码量至少是它的10倍。
多表合并:join的艺术
真实项目里,数据往往分散在多个表里。这时候就需要用到合并操作。
Pandas有三种主要的合并方式:merge、join、concat,很多人搞混它们的区别。
merge:类似SQL的JOIN,基于列的合并
# 内连接 - 只保留匹配的行
merged_df = pd.merge(
orders_df,
users_df,
on='user_id', # 基于user_id列合并
how='inner' # 内连接
)
# 左连接 - 保留左表所有行
merged_df = pd.merge(
orders_df,
users_df,
on='user_id',
how='left' # 左连接
)
# 多列匹配 + 不同列名
merged_df = pd.merge(
orders_df,
product_df,
left_on='product_id', # 左表的列名
right_on='id', # 右表的列名
how='left'
)join:基于索引的合并
# 先设置索引再join
orders_df = orders_df.set_index('user_id')
users_df = users_df.set_index('user_id')
merged_df = orders_df.join(users_df, how='left')concat:简单的拼接
# 垂直拼接(追加行)
all_orders = pd.concat([df1, df2, df3], ignore_index=True)
# 水平拼接(追加列)
all_data = pd.concat([df1, df2], axis=1)这里有个坑:大数据量合并时要小心内存。如果你要合并两个大表,考虑先用pd.merge(..., validate='one_to_one')来验证关系是否正确,避免意外生成过大的结果。
数据清洗:最耗时间但最有价值
很多教程把数据清洗一笔带过,但根据我的经验,数据清洗往往占项目时间的70%以上。
常见问题和解决方案:
1. 缺失值处理
# 检查缺失值
print(df.isnull().sum())
# 删除缺失值 - 简单粗暴
df_clean = df.dropna()
# 填充缺失值 - 根据业务逻辑
df['price'] = df['price'].fillna(0) # 价格缺失填0
df['age'] = df['age'].fillna(df['age'].median()) # 年龄用中位数填充
df['city'] = df['city'].fillna('未知') # 城市用"未知"填充
# 前向填充 - 适用于时间序列数据
df['temperature'] = df['temperature'].fillna(method='ffill')2. 重复值处理
# 检查重复值
print(df.duplicated().sum())
# 删除重复值 - 基于所有列
df_clean = df.drop_duplicates()
# 删除重复值 - 基于特定列
df_clean = df.drop_duplicates(subset=['user_id', 'order_date'])3. 异常值检测和处理
# 基于统计方法的异常值检测
mean = df['price'].mean()
std = df['price'].std()
threshold = 3 * std
outliers = df[(df['price'] < mean - threshold) | (df['price'] > mean + threshold)]
# 四分位法(IQR)检测异常值
Q1 = df['price'].quantile(0.25)
Q3 = df['price'].quantile(0.75)
IQR = Q3 - Q1
outliers = df[(df['price'] < Q1 - 1.5*IQR) | (df['price'] > Q3 + 1.5*IQR)]
# 处理异常值 - 可以选择删除、替换或标记
df.loc[df['price'] > Q3 + 1.5*IQR, 'price'] = Q3 + 1.5*IQR # 用边界值替换4. 文本数据清洗
# 去除前后空格
df['name'] = df['name'].str.strip()
# 统一小写
df['name'] = df['name'].str.lower()
# 正则表达式提取
df['phone'] = df['contact_info'].str.extract(r'(\d{11})')
# 替换特定字符
df['address'] = df['address'].str.replace('[\n\t]', '', regex=True)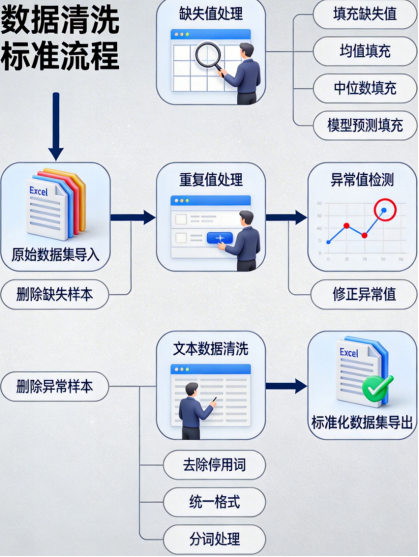
性能优化的黄金法则
最后分享几个我总结的性能优化技巧,这些都是在实际项目中踩坑后总结出来的:
1. 向量化操作代替循环
# ❌ 慢 - 用循环
result = []
for i in range(len(df)):
if df.loc[i, 'price'] > 100:
result.append('高')
else:
result.append('低')
df['category'] = result
# ✅ 快 - 用向量化操作
df['category'] = np.where(df['price'] > 100, '高', '低')2. 避免链式索引
# ❌ 可能有问题 - 链式索引
df[df['price'] > 100]['category'] = '高'
# ✅ 安全 - 用loc
df.loc[df['price'] > 100, 'category'] = '高'3. 用eval处理复杂表达式
# 复杂计算
df['result'] = df.eval('price * quantity * discount_rate')
# 带条件的复杂计算
df['final_price'] = df.eval('price * (1 - discount_rate) where status == "优惠" else price')4. 使用Categorical类型加速
# 对于重复值多的列,转换成category类型
df['status'] = df['status'].astype('category')
# 分组操作会更快
result = df.groupby('status')['price'].sum()5. 考虑用Dask处理大数据
import dask.dataframe as dd
# 当数据量超过内存时,用Dask
ddf = dd.read_csv('large_file.csv')
# 用法类似Pandas,但支持并行处理
result = ddf.groupby('user_id')['price'].sum().compute()
实战案例:电商用户价值分析
把上面的技巧整合一下,做一个完整的案例:
import pandas as pd
import numpy as np
# 1. 读取数据并优化数据类型
dtype_dict = {
'user_id': 'int32',
'product_id': 'category',
'order_status': 'category',
'price': 'float32',
'order_date': 'datetime64[ns]'
}
df = pd.read_csv('sales.csv', dtype=dtype_dict)
# 2. 数据清洗
# 处理缺失值
df['price'] = df['price'].fillna(0)
df['order_status'] = df['order_status'].fillna('unknown')
# 处理异常值
Q1 = df['price'].quantile(0.25)
Q3 = df['price'].quantile(0.75)
IQR = Q3 - Q1
df.loc[df['price'] > Q3 + 1.5*IQR, 'price'] = Q3 + 1.5*IQR
# 3. 用户价值分析
user_analysis = df.groupby('user_id').agg({
'order_id': 'count',
'price': ['sum', 'mean', 'std'],
'order_date': ['min', 'max']
}).reset_index()
# 展平列名
user_analysis.columns = [
'user_id', 'order_count', 'total_amount',
'avg_amount', 'amount_std', 'first_order', 'last_order'
]
# 4. 计算RFM指标(最近购买、购买频率、消费金额)
current_date = df['order_date'].max()
user_analysis['recency'] = (current_date - user_analysis['last_order']).dt.days
user_analysis['frequency'] = user_analysis['order_count']
user_analysis['monetary'] = user_analysis['total_amount']
# 5. 用户分群
def rfm_segment(row):
r_score = 1 if row['recency'] <= 30 else (2 if row['recency'] <= 90 else 3)
f_score = 1 if row['frequency'] >= 10 else (2 if row['frequency'] >= 5 else 3)
m_score = 1 if row['monetary'] >= 1000 else (2 if row['monetary'] >= 500 else 3)
return f"{r_score}{f_score}{m_score}"
user_analysis['rfm_segment'] = user_analysis.apply(rfm_segment, axis=1)
# 6. 统计各分段用户数量
segment_stats = user_analysis['rfm_segment'].value_counts()
print(segment_stats)这个案例整合了数据类型优化、数据清洗、分组聚合、复杂计算等技巧,是一个典型的数据处理流水线。
NumPy在数值计算中的高级应用
虽然Pandas很强大,但有些场景下NumPy更高效,尤其是在纯数值计算方面。
1. 广播机制
import numpy as np
# 基础广播
a = np.array([[1, 2, 3], [4, 5, 6]]) # 2x3
b = np.array([10, 20, 30]) # 3x1
result = a + b # 广播到2x3
# 实际应用:数据标准化
data = np.random.randn(1000, 10) # 1000个样本,10个特征
mean = np.mean(data, axis=0) # 每列均值
std = np.std(data, axis=0) # 每列标准差
normalized = (data - mean) / std # Z-score标准化2. 高级索引
# 布尔索引
arr = np.array([1, 2, 3, 4, 5, 6])
mask = arr > 3
result = arr[mask] # [4, 5, 6]
# 花式索引
arr = np.array([[1, 2], [3, 4], [5, 6]])
rows = np.array([0, 2])
cols = np.array([1, 0])
result = arr[rows, cols] # [2, 5]3. ufunc(通用函数)
# 自定义ufunc
def my_function(x):
return x**2 if x > 0 else -x**2
# 转换成ufunc,向量化加速
ufunc_my_function = np.frompyfunc(my_function, 1, 1)
result = ufunc_my_function(np.array([-3, -2, -1, 0, 1, 2, 3]))
学习建议
数据处理进阶不是一蹴而就的,我的建议是:
1. 从实际问题出发:不要死记API,找真实数据来练习。Kaggle、天池都有很 好的数据集。
2. 理解底层原理:Pandas很多API背后是NumPy实现的,理解了NumPy, Pandas会更容易。
3. 关注性能:养成查看.info()、用%timeit测试代码性能的习惯。
4. 积累自己的工具库:把常用的数据处理函数整理成自己的模块,方便复 用。
5. 多看官方文档:Pandas和NumPy的官方文档很详细,很多冷门技巧都在里 面。
相关学习资源
• Pandas官方文档:https://pandas.pydata.org/docs/
• NumPy官方文档:https://numpy.org/doc/
• Pandas Cookbook:https://github.com/jvns/pandas-cookbook
• 《利用Python进行数据分析》(Wes McKinney著)
• Kaggle教程:https://www.kaggle.com/learn/pandas
练习题
为了巩固今天的内容,我准备了3个练习题:
题目1:给定一个销售数据集,计算每个产品类别在不同地区的销售额占比, 并用数据透视表展示结果。
题目2:有两个表,一个是用户信息表,一个是订单表,用不同的合并方式 (inner、left、right、outer)合并它们,比较结果的差异。
题目3:对电商数据进行RFM分析(最近购买时间、购买频率、消费金额), 将用户分成8个群体,并统计每个群体的特征。
最后我想说,数据处理这门手艺,没有捷径。
你可能看过很多"速成教程",但真正的能力是在一次又一次的实战中练出来的。我写这篇文章的时候,回想自己踩过的坑、熬过的夜,感触还挺深的。
但好消息是,一旦你掌握了这些技巧,数据处理就会从"痛苦"变成"乐趣"。你会开始享受那种把混乱数据变成清晰洞察的过程。
而这,正是数据分析最迷人的地方。
你在数据处理中遇到过哪些坑?评论区聊聊你的经历。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)