ForceVLA——将具备力感知的MoE整合进π0的动作专家中:从而融合“视觉 语言 力反馈”实现精密插拔(非夕集成了六维力传感器,已开源)
摘要:ForceVLA是一种新型视觉-语言-动作(VLA)模型,通过引入力感知专家混合(MoE)模块,将6D力反馈与视觉语言信息融合,显著提升了机器人在精密插拔等接触密集型任务中的表现。相比现有主要依赖视觉的VLA模型,ForceVLA能动态感知任务各阶段的力变化,实现更精确的物理交互。该模型在π0框架基础上,通过SigLIP视觉语言编码器处理多摄像头输入,并结合本体感知和力觉信息,利用条件流匹配
前言
我司「七月在线」目前侧重以下两大本体的场景落地(其实,我在之前的博客里或多或少也说过,当然,还尚未如下此般明确)
- 人形层面,侧重
1.1 人形灵巧操作
1.2 人形展厅讲解 - 机械臂层面,侧重
2.1 智能装配
2.2 精密插拔,比如电源插拔、耳机插孔、USB插拔
对于后者——机械臂层面,之前我们看到过
- 在VLM的指引下,装配宜家家居
- 更看到过在各种RL方法之下的插拔
以及结合ResNet视觉与MLP触觉且带语义增强的电源插拔
今天我们再看一个在VLA下且带触觉的精密插拔工作,即本文要介绍的ForceVLA
- 当然 也不用对「VLA可以做高精度任务」感到奇怪,毕竟我们之前在《实时动作分块RTC——为解决高延迟,让π0.5也可以点燃火柴、插入网线:执行当前动作分块时生成下一个分块,且已执行的冻结 未执行的则补全》这篇文章中见识过了
- 此外,进一步讲,本工作虽然证明了可以完成我个人密切关注的:精密插拔,但不代表成功率一上来就有很高,比如本文中的ForceVLA
虽然完成了Insert USB操作,但其成功率目前还很低,不到50%——详见下图左下角,期待其后续的迭代/改进,但至少高于π0不少
且Insert Plug的成功率达到了80%,当然 也还有待提高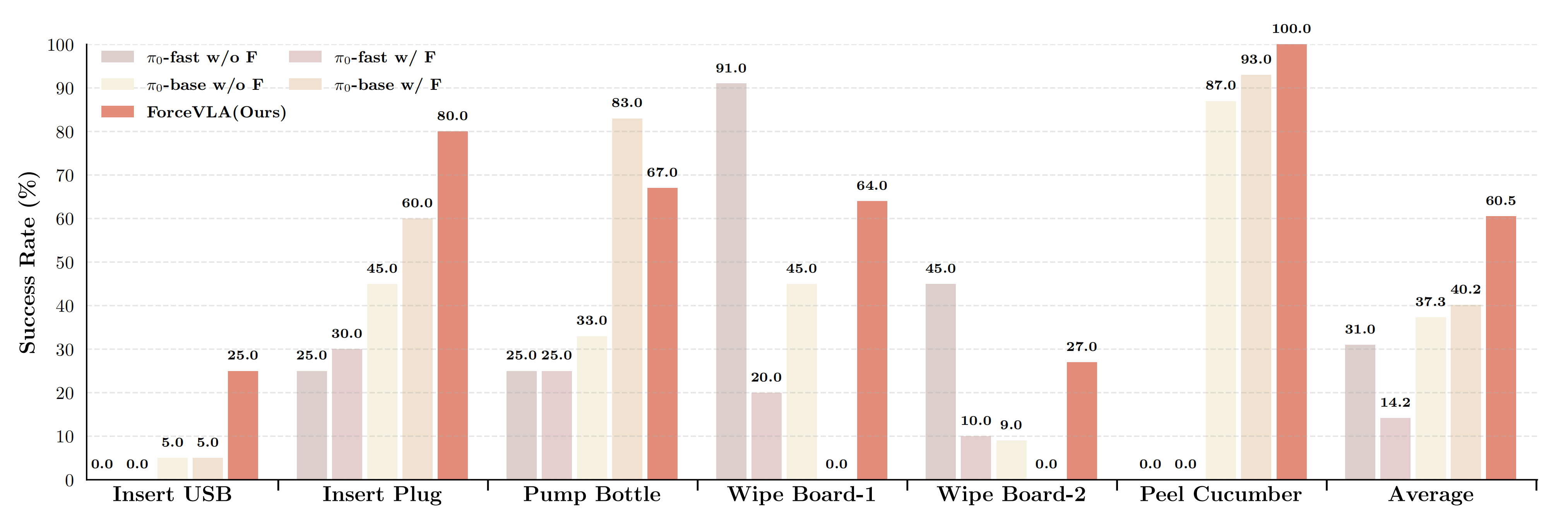
第一部分 ForceVLA
1.1 引言、相关工作、预备知识
1.1.1 引言
如ForceVLA原论文所说,π0[10] 仅需少量演示即可高效微调
- 然而,复杂接触的操作不仅需要语义基础和空间规划,更本质上依赖于交互力[12,13]。现有的VLA模型主要依靠视觉和语言线索,往往忽视了力觉感知这一对精确物理交互至关重要的模态
- 相比之下,人类能够自然地整合触觉和本体感觉反馈,从而调整操作策略 [14]。因此,VLA模型在插入、工具使用等任务中常常表现不佳
或在遮挡或视觉条件较差的情况下进行装配,容易导致系统行为脆弱或任务失败
此外,不同任务阶段对力的需求也在不断变化:精细抓取、受控插入和柔顺表面接触——每一阶段都需要不同形式的力调节。目前的方法缺乏感知和适应这些动态变化的机制,限制了其对物理交互进行时序推理的能力
为了解决这些局限性,来自1 Fudan University, 2 Shanghai Jiao Tong University,3 National University of Singapore, 4 Shanghai University, 5 Xi’an Jiaotong University的研究者提出了ForceVLA
- 其对应的论文为:ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation
其对应的作者为
Jiawen Yu1∗, Hairuo Liu2∗, Qiaojun Yu2∗,
Jieji Ren2, Ce Hao3, Haitong Ding 4,Guangyu Huang5, Guofan Huang1, Yan Song1,
Panpan Cai2†, Cewu Lu2†, Wenqiang Zhang1† - 其项目网址为:sites.google.com/view/forcevla2025
作者说,计划开源,至于具体开源时间 得等
————
26年1月3日发现,该项目已开源:github.com/ft-robotic/ForceVLA,赞
具体而言,其通过引入具备力感知的专家混合(Mixture-of-Experts, MoE)模块来增强VLA模型,从而在高接触操作任务中实现有效推理和具备情境感知、力信息驱动的动作生成,如图1所示
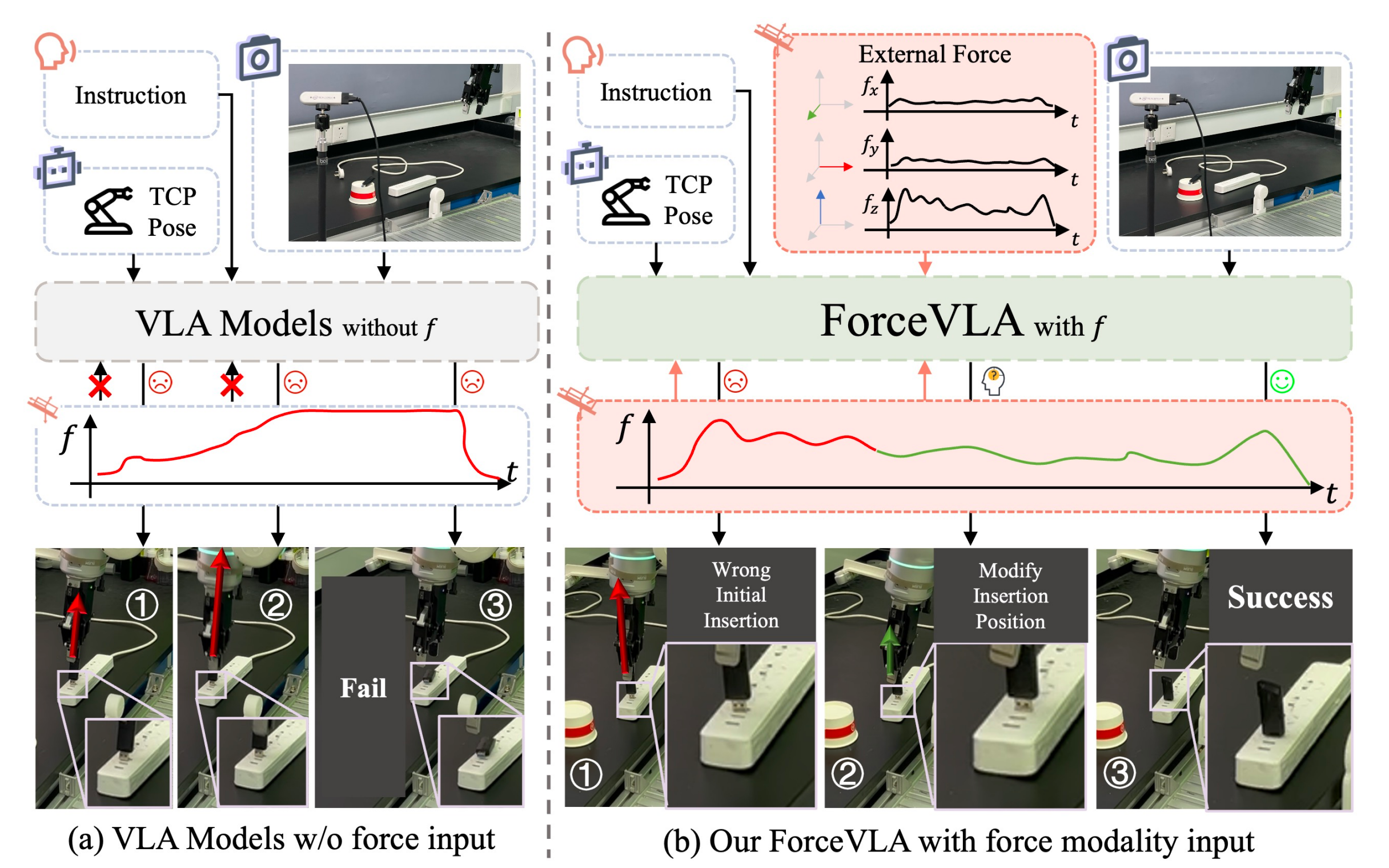
- ForceVLA的核心思想在于,将机器人末端执行器感知到的六维外部力视为一类重要模态,并将其正式整合进动作专家模块,以便在物理交互过程中基于力反馈实现具有阶段感知的动作生成
- 为实现这一整合,ForceVLA引入了名为FVL MoE的力感知MoE模块,专为在动作规划过程中,将视觉-语言表征与来自具身交互的实时力反馈进行模态和阶段感知融合而设计
通过门控机制,FVLMoE可针对专家子网络动态计算路由权重,每个子网络专注于任务执行阶段中的不同模态
ForceVLA通过根据高层任务指令和低层交互反馈自适应激活这些专家,从而捕捉物理交互过程中微妙但关键的、依赖阶段的变化,并生成精确、阶段对齐且具备力感知的动作分块
1.1.2 相关工作
第一,对于机器人VLA领域
- 近期在视觉-语言-动作(VLA)模型方面的研究,主要致力于利用大规模多模态预训练,实现机器人策略在不同任务和实体间的泛化能力[4,6,9,15,16,17,18,19,20]。这些模型通常通过端到端学习,将视觉和语言输入映射为低级控制信号
基于流的架构(如π0[10,21])将预训练的视觉-语言编码器与高速动作解码器集成,实现高频率输出 - 其他研究则引入了推理机制[22,23,24,25]、动作空间压缩或三维点云输入[26],以提升指令理解和任务执行能力
基于扩散的模型[5,27,28,29,30]通过引入随机生成,能够实现多样化、长时序行为,但通常伴随较高的训练和推理成本
尽管取得了诸多进展,大多数VLA方法仍然局限于视觉和语言输入,在需要触觉反馈的接触丰富或遮挡操作场景下,其效果有限
第二,对于接触丰富的操作领域
- 传统的仅依赖视觉的方法在需要细粒度反馈的动态交互中表现不佳。为了解决这一问题,近期的研究整合了力觉传感[31,32,33,34],从而提升了运动的稳定性和精度
Xie 等人[35,13]对力反馈在机器人控制中的作用进行了基础性研究 - 触觉传感同样成为一种强大的感知方式:TLA[36]和Tac-Man[37]在精细操作和关节任务中展现了更优的性能
- 多模态融合方法[38,39]在复杂环境中显示出潜力,然而当前的方法往往局限于静态模态融合,缺乏动态路由或统一的建模框架。此外,鲜有研究在现实世界的接触丰富场景下评估跨任务的泛化能力
第三,对于MoE 架构相关工作
- 混合专家(Mixture-of-Experts, MoE)架构通过激活稀疏的专家子网络,提高了模型的可扩展性和效率 [40,41,42,43,44]
后续研究 [45] 提升了 MoE 的训练稳定性和任务迁移能力
在多模态领域,LIMOE [46] 将稀疏专家层集成到视觉-语言联合学习中 - 近期在机器人领域的应用 [47,29] 将 MoE 层引入 VLA 模型,以增强策略泛化和适应能力。然而,这些方法在很大程度上忽略了对力觉/触觉模态的显式建模,并且缺乏在高接触任务中跨多模态信号进行动态路由的机制
1.1.3 预备知识
首先是问题表述
下图图2展示了机器人操作任务的设置
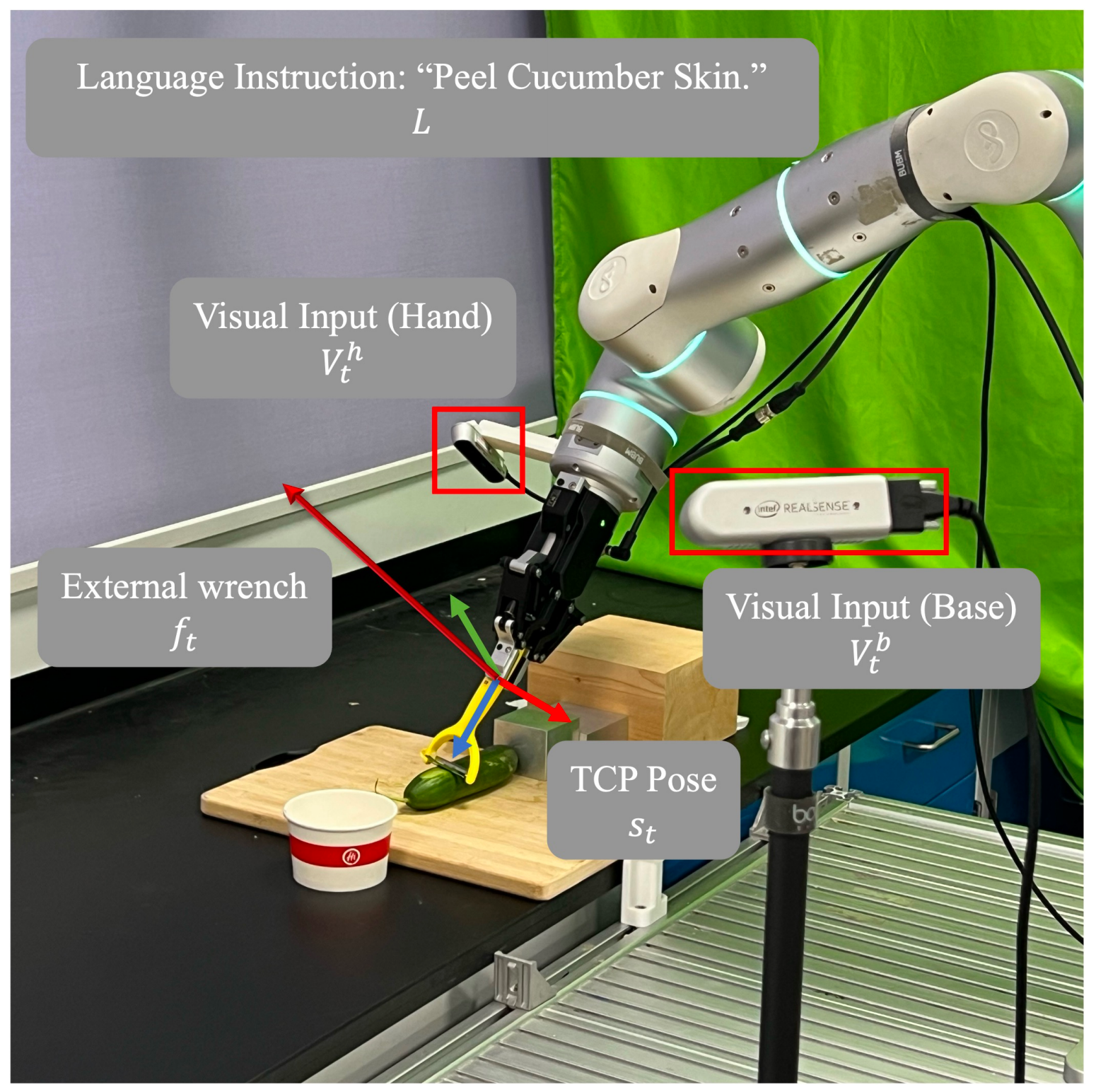
- 在时间步
,机器人的观测包括
底座和手部的视觉输入
和
这些数据被收集统称为 - 给定语言指令
,目标是学习一个端到端的策略
,该策略输出低层次、可执行的动作片段
[10],以最大化完成高接触任务的可能性
其中,是由TCP位姿与夹爪宽度拼接而成的向量
TCP位置由笛卡尔坐标表示,姿态由欧拉角
表示。
是作用在TCP上的外部力矩估计,并以世界坐标系表示,包括
的力和
其次,对于MoE 架构
作者选择了 Mixture-of-专家(MoE) [44, 42] 作为他们的融合层。其核心思想是将不同模态分配给)一组更大但更小型、专门化的” 专家” 子网络,对于任意给定的输入token,只有其中一部分被激活
- 一个MoE 层通常由一组N 个专家网络组成,记为
,以及一个门控网络(也称为路由器),记为
该网络接收一个输入token,并动态决定由
个专家中的哪些来处理它
在流行的稀疏MoE 实现中,对于输入token会生成分数或logits
——用于从总共N 个专家中选择一个较小的k 个专家子集(通常k = 1 或k = 2,其中k ≪N) - 输入的token x 仅被路由到这
个激活的专家。这些激活专家的输出
随后被聚合,通常通过加权和实现,其中权重
也由门控网络生成
MoE 层的最终输出可以表示为:
其中表示门控网络为输入
1.2 ForceVLA
ForceVLA 是一种面向接触密集型操作的端到端多模态机器人策略。其流程如图 3 所示
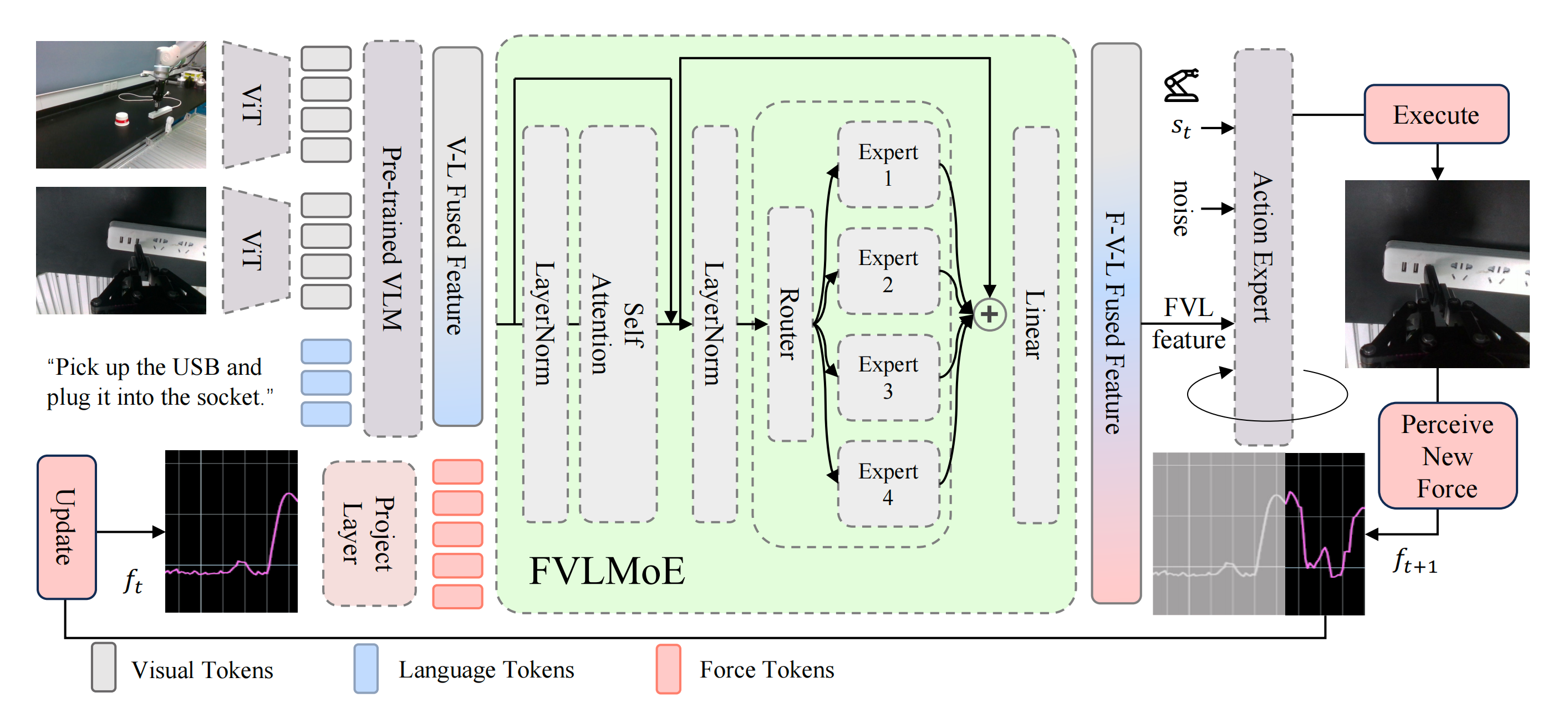
- 在π0 框架 [10] 的基础上,ForceVLA 融合了视觉、语言、本体感知以及六轴力反馈,并通过条件流匹配模型 [48,49] 生成动作
来自多个 RGB 摄像头的视觉输入和任务指令由基于 SigLIP 的视觉-语言模型「基于 PaliGemma [11]」编码为上下文嵌入
这些嵌入与本体感知和力觉信息结合,共同作为条件,指导迭代去噪过程以预测动作轨迹 - FVLMoE是实现高效力整合的核心模块。力传感读数被线性投射为专用的token,并通过专家混合(MoE)模块与视觉-语言嵌入融合
受MoE在多任务和模态特定学习方面优势的启发[51,46],FVLMoE能够自适应地路由并处理多模态输入。其输出为流模型提供了丰富的引导信号,使ForceVLA能够更精确且更具鲁棒性地应对微妙的接触动态以及视觉上模糊的场景
1.2.1 FVLMoE 架构
FVLMoE 模块专为多模态感知信息的融合而设计。其结构使模型能够将视觉和语言中丰富的上下文理解,与力-扭矩传感器捕捉到的即时、细粒度动态信息进行整合——这种融合对于在接触丰富的操作任务中实现稳健且自适应的行为至关重要
FVLMoE 的架构与运行流程可分为以下几个阶段:
- 多模态输入映射
如何确定新型力学模态引入的最佳阶段和方法,是一个重大的设计难题。经过大量实验,作者确立了一种方法:在主视觉-语言模型(VLM)处理完视觉和语言输入后,再引入力学模态
具体而言,力学特征作为独立输入被送入FVLMoE模块,使其类似于高级皮层联络区的功能,负责将VLM预训练的视觉-语言表征与新引入的力学token进行整合
FVLMoE 模块遵循上述设计思路,接收由视觉-语言特征与专用力觉 token 拼接而成的 token 嵌入序列作为输入
来源于主视觉-语言模型的输出,包含了从处理后的图像流和文本指令中获得的上下文理解
经由线性映射
转换为力觉 token 嵌入
最终输入到 FVLMoE 的是拼接后的序列,其中力觉 token 被附加到视觉-语言上下文之后,以便在 MoE 架构中进行后续联合处理
- 多模态路由与融合计算
一旦组合后的多模态序列形成后,它将在 FVLMoE 模块中进行分层处理
个注意力头的多头自注意力机制和一个后续前馈神经网络(FFN)组成,输出为
随后,被送入稀疏专家混合(Mixture-of-Experts, MoE)层。该层包含
个独立的专家网络,每个专家都是一个独立的多层感知机(MLP)
动态门控网络根据学习到的分发权重,为中的每个 token 选择最合适的单一专家(topk=1)进行路由。MoE 计算的输出随后通过残差连接与 MoE 层的输入集成,得到
最终融合后的多模态特征序列将通过一个线性投影层,以匹配动作专家的维度 - 将融合特征注入动作流头
由FVLMoE 模块产生的融合多模态特征序列作为动作生成过程的引导信号,该过程被建模为基于流的去噪模型
这一引导通过首先提取一个特定的子序列实现,该子序列由
的最后
个token 组成;这些token 为
随后,通过元素级加法与
结合
后者和去噪步骤
下的带噪动作轨迹
处理后得到的,其中
和
分别表示状态和动作空间的维度
这种加性注入机制确保了FVLMoE 所发展出的丰富、具备接触感知的上下文理解能够在预测轨迹的每一步直接调制并细化生成的动作序列
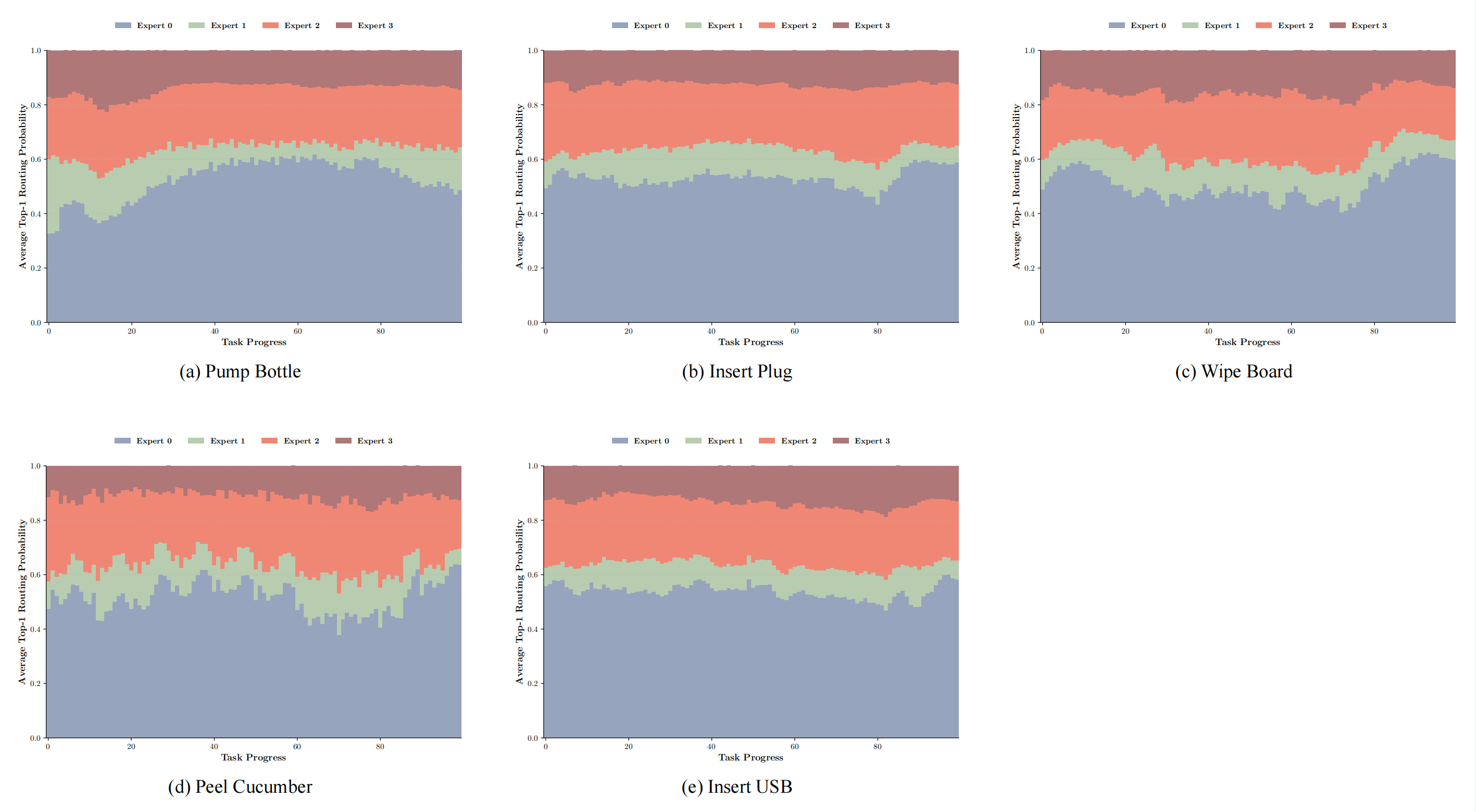
为了分析路由动态,作者首先测量了在MoE模块中,路由器对每个token进行处理时专家选择的概率分布
- 针对可变长度的episode,作者采用了基于百分位的归一化方法:每个任务(约10个episode)通过将每个episode的token序列划分为100个时间上等距的区间来处理,计算每个区间的top-1概率均值,然后在各个episode之间对这些均值取平均
这样既保证了不同episode之间的可比性,同时又保留了时间上的路由动态- 如图9所示,不同任务展现出不同的专家利用模式。一些任务(例如插入插头、削黄瓜)表现出明显的时序专精性,即某些专家在任务的特定阶段占主导地位
其他任务(例如擦白板)则在整个执行过程中对单一专家表现出更为一致的偏好。这些趋势表明,路由器能够根据任务的语义特征和时间结构,动态地在各专家之间分配计算资源
- 此外,作者发现 Expert 0 在多个任务中主导了近一半的 token。该专家的持续激活表明,Expert 0 可能充当通用型专家,负责多模态融合或在多个任务间共享的常规控制原语。其广泛参与与 Expert 1 或 Expert 3 更具选择性、阶段特定的激活形成鲜明对比,这进一步支持了专家间功能专化的假设
这种路由频率的不对称性不仅反映了任务内部的时序语义变化,也体现了架构在训练过程中对某些专家的偏向
1.2.2 数据集:含机器人硬件配置(Flexiv Rizon 7)
为了训练 ForceVLA,作者专门整理了一个全新数据集,重点关注富含接触的操作任务,并强调对视觉、位置感知和力-扭矩数据的同步采集。现有数据集通常缺乏全面的力交互信息,或者缺少足够多样的基于接触的场景,这对于开发健壮的力感知策略来说是必需的
- 他们的数据采集工作采用了Flexiv Rizon 7自由度机械臂,并配备了大寰自适应夹爪
视觉数据通过两台RGB-D相机获取: - 数据采集通过Quest3 VR界面进行人机远程操作,使用自定义映射实现对机械臂末端执行器的控制
五名专家操作员共完成了五项富含接触的任务:瓶子抽吸、插头插入、U盘插入、白板擦拭和黄瓜削皮,具体描述见下文(原文第5.1节)
对于每项任务,操作员均被要求在确保多样且成功的交互模式的同时完成目标。作者在演示过程中不断变换物体的位置和朝向,以增强数据的多样性
最终生成的数据集,作者称之为ForceVLA-Data,共包含244条轨迹,总计14万个同步时间步。所有传感器数据流均以时间戳进行同步。图像被调整为480x640像素,并进行了归一化处理。动作以目标TCP位姿和夹爪宽度的形式表示
PS,作者宣称,ForceVLA-Data数据集以及他们的数据采集代码和处理脚本将会在网站上公开,以促进基于力感知的操作策略学习的进一步研究
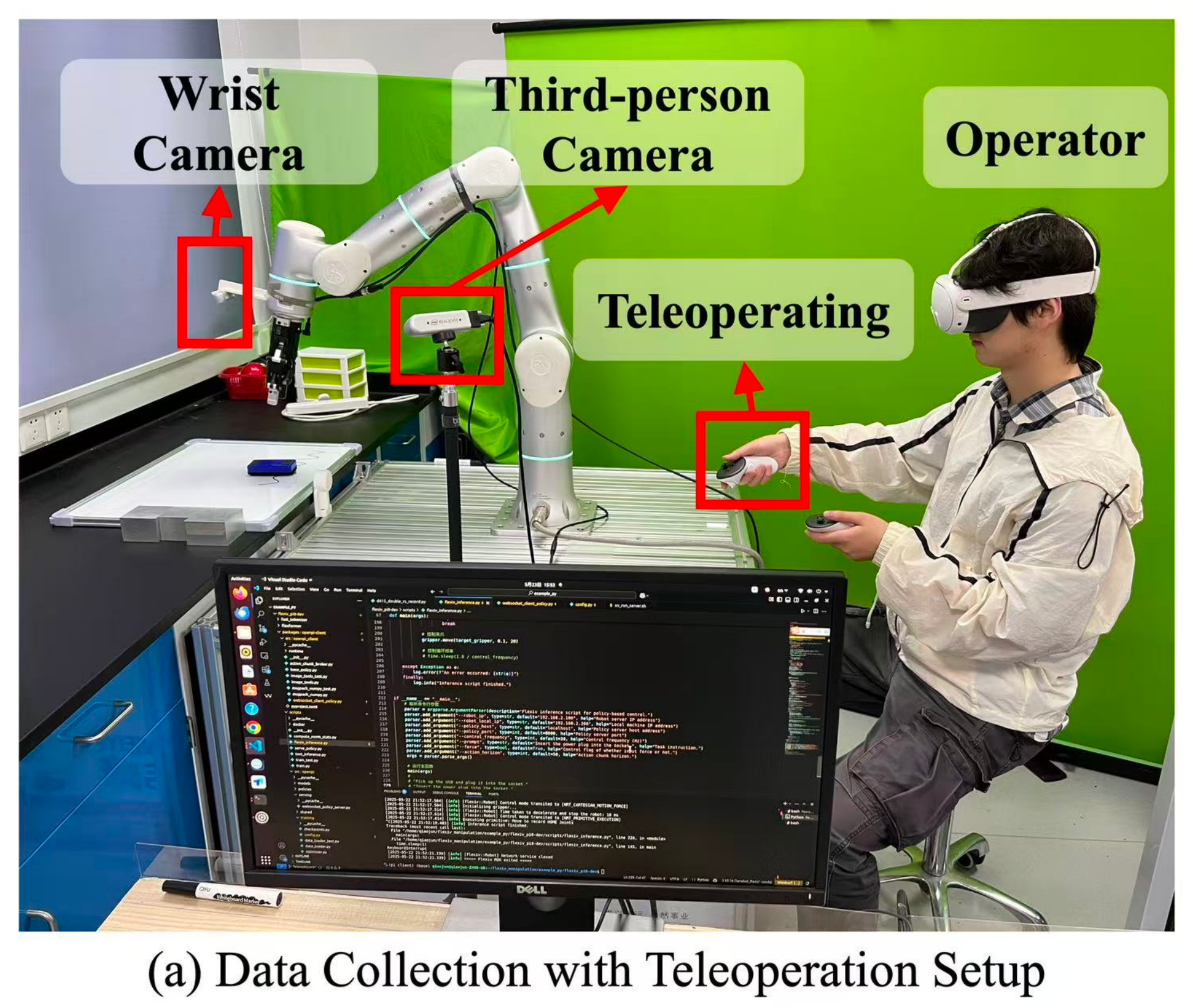
数据采集系统如图8(a)所示
- 该系统配置了一台机械臂,机械臂上安装有腕部摄像头,同时还配备有一个固定的第三人称视角摄像头,以捕捉多样的视觉视角
- 操作员佩戴Quest 3头显并使用手持控制器对机械臂进行远程操作。附近的一台计算机运行数据采集所需的软件,包括与机器人交互、传感器数据流同步以及管理与VR远程操作硬件通信的程序
图8(b)展示了操作员通过远程操作机械臂,为擦拭白板任务收集演示数据的场景

1.2.3 训练细节
模型主要在配备8 块NVIDIA RTX 4090 GPU(每块24 GB 显存)、64 个物理CPU 核心和251 GB 系统内存的计算节点上进行训练
- 采用Adam 优化器(β1 = 0.9, β2 = 0.95),峰值学习率为2.5 × 10−5,在30,000 步内衰减至2.5 × 10−6
- 多任务训练在2 块GPU 上利用数据并行(全局批量大小为16,通过梯度累积有效批量为2048),由于通信开销,增加更多GPU 收益递减,完成30,000 步约需∼12 小时;
单任务训练使用1 块GPU 进行10,000步(约9 小时),两者均采用bfloat16 精度并进行梯度裁剪——
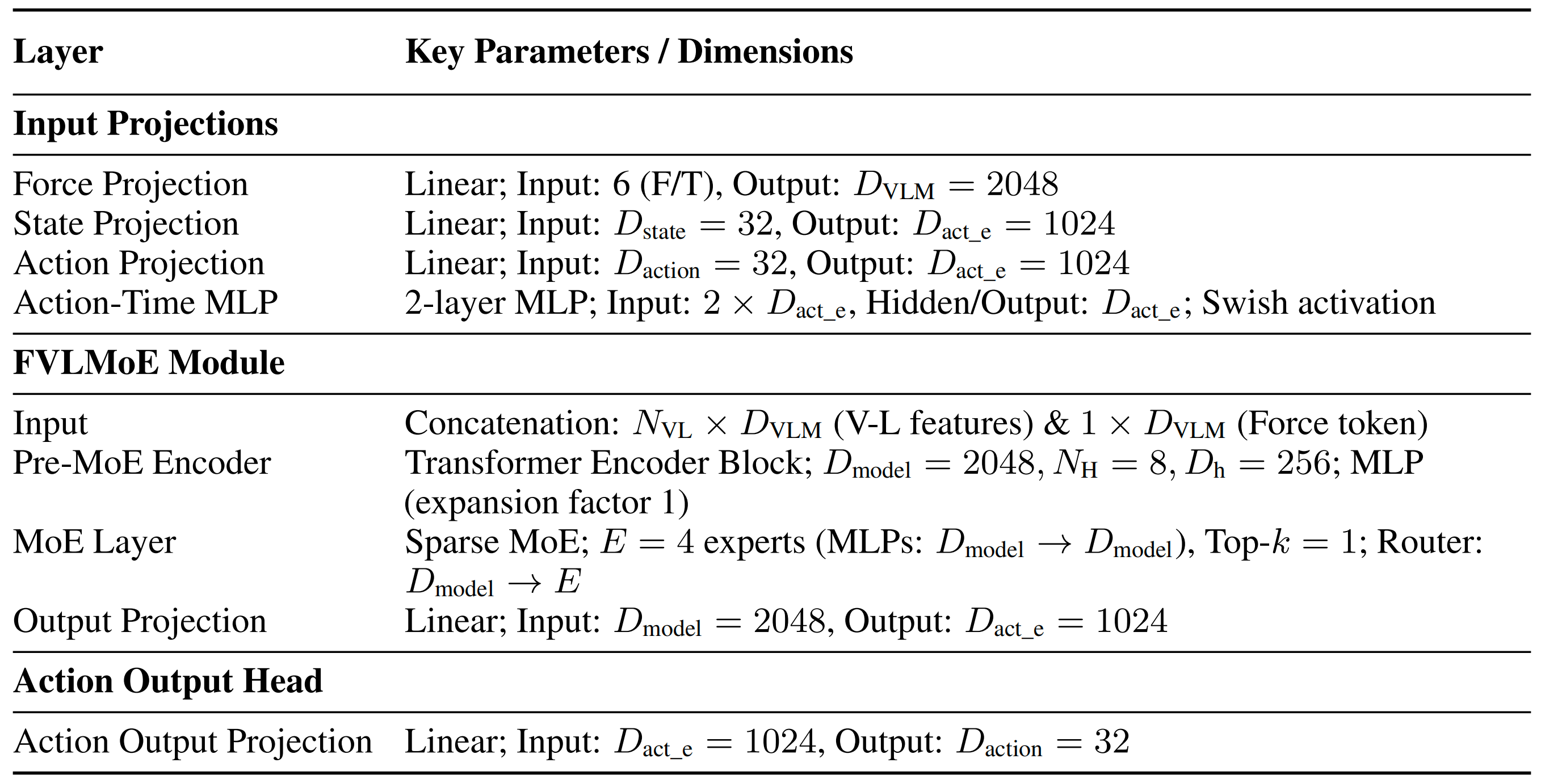
ForceVLA核心处理模块的维度和关键参数,包括输入投影、FVLMoE模块以及动作输出头,详见表4
1.3 实验
本节详细介绍了一系列真实世界中涉及丰富接触的操作实验和分析研究,旨在通过实证方式验证 ForceVLA 模型。评估内容围绕4个核心研究问题展开:
- 与未采用我们专有融合机制、仅结合力信息的基线方法相比,ForceVLA 的整体有效性
- 模型在未见过的物体实例、环境变化和任务条件下的泛化能力
- 所提出的 FVLMoE架构在实现接触丰富操作任务中的多模态最优融合方面的效果
- 以及专家混合模块对异构输入模态的处理能力,以及在专家网络间学习有意义路由行为的能力
1.3.1 实验设置:瓶子压泵、插插头、插入 U 盘、擦白板和削黄瓜
为了评估 ForceVLA 的有效性,作者在5项多样化且富含接触的操作任务上进行了实验:a)插入 U 盘、b)瓶子压泵、c)插插头、d)削黄瓜、e)擦白板,如图 4 所示
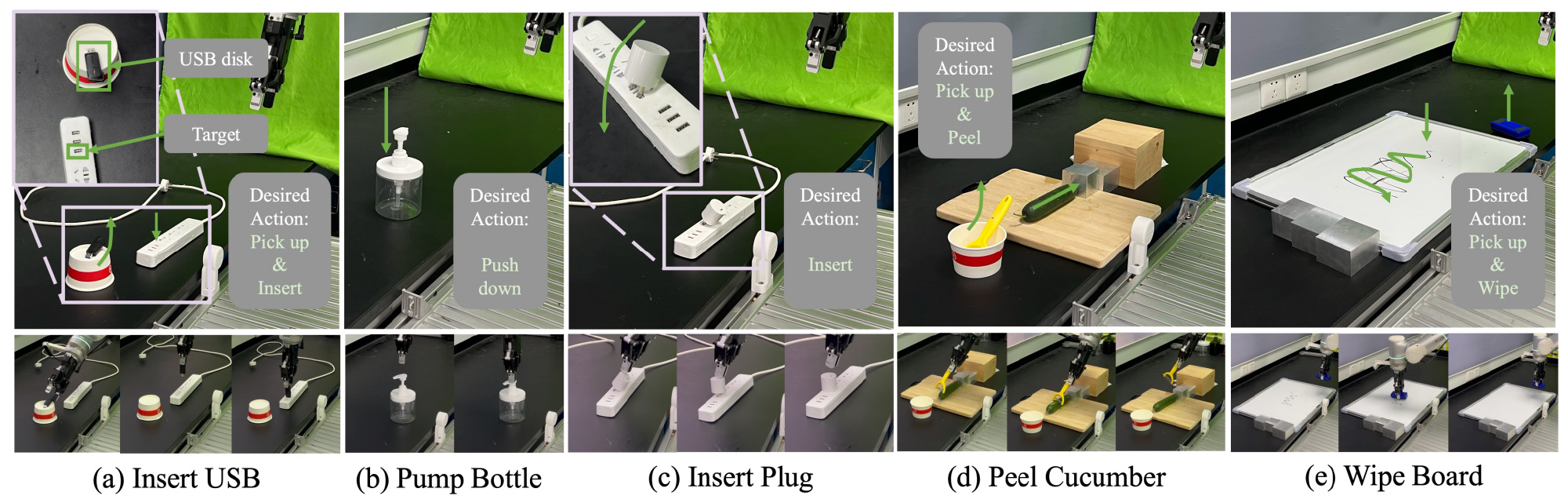
- 选择这些任务旨在考察系统对精细控制的能力、对不同初始条件的适应性,以及多模态反馈(特别是力感知)的实用性
每项任务都带来了独特的物理挑战:
i) b-瓶子压泵需要精确的垂直按压;
ii) c-插插头、a-插入 U 盘要求精准对齐并通过力控完成插入;
iii) e-擦白板强调轨迹平滑控制和表面接触;
iv) d-削黄瓜则考验在持续表面交互过程中施加并保持受控力的能力 - 作者使用每个任务约50次专家演示对ForceVLA进行了训练
评估环节中
c/a插入和b-泵送任务各进行了20次试验
耗时较长的e-白板任务进行了10次试验
d-黄瓜去皮任务则进行了15次试验,每次包含15次去皮动作
成功标准基于具体任务设定,如完全插入、有效擦拭动作或显著的累计去皮覆盖率。这些任务旨在严格检验ForceVLA通过融合视觉、语言与力觉模态,对复杂且不确定动力学建模与控制的能力 - 评估指标与基线
模型性能主要通过在全部五项具有挑战性的接触丰富操作任务中的任务成功率进行评估。针对特定任务(如d-黄瓜去皮),还报告了平均去皮长度和最少去皮次数,以提供更细致的评估
为将他们提出的ForceVLA模型的性能置于背景之中,他们将其与若干精心挑选的基线进行对比,这些基线均源自最先进的π0[10]架构,该架构也是ForceVLA的基础模型
具体变体包括
选择π0-base[10]可以与已有的强大VLA方法进行比较,而“inputForce”变体对于证明我们的FVLMoE融合策略相较于更简单的力集成方法的有效性至关重要
1.3.2 主要结果
首先,对于整体性能
如下图图5所示「将外部力反馈引入π0-base模型能够提升其性能,而ForceVLA的方法取得了最高的平均成功率,展示了在复杂交互动力学下的强健表现。“Wipe Board-1”表示成功完成擦拭动作的成功率,“Wipe Board-2”则指完全擦除标记的成功率」
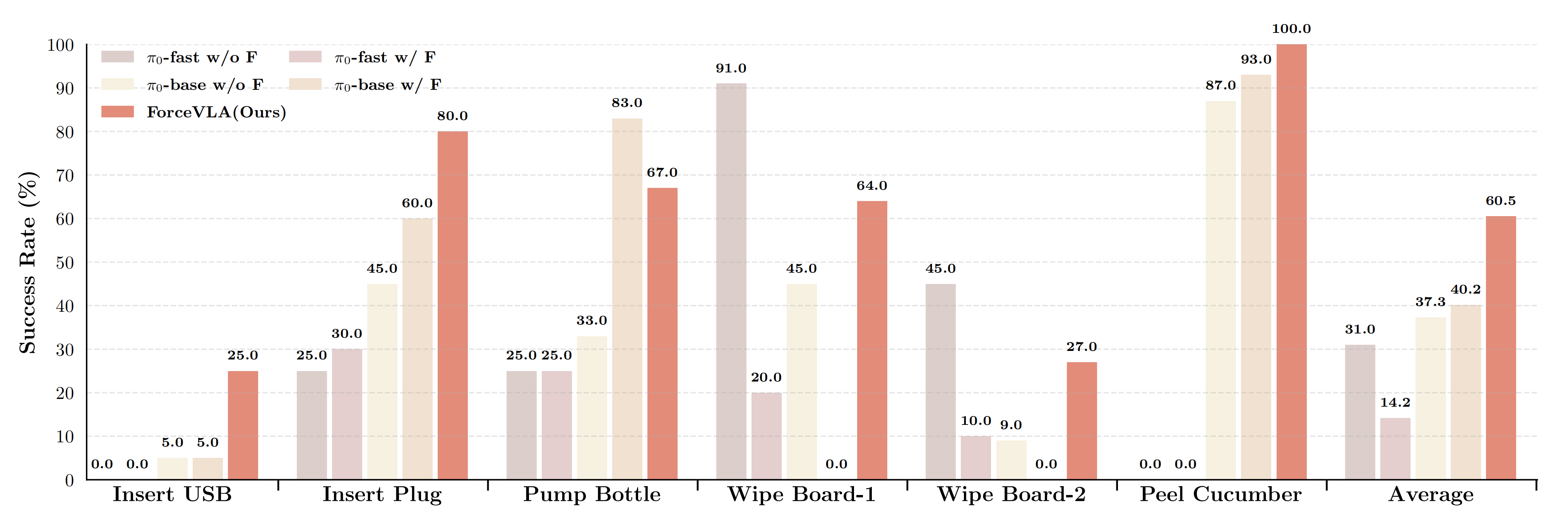
- ForceVLA在全部五项任务中实现了平均60.5%的成功率,显著优于所有基线配置
相比于没有力反馈的标准π0-base模型——原论文这里写的:π0-base w/ F,个人认为 既然是不带力反馈的π0,那就应该是π0-base[10] w/o F,其平均成功率为37.3%
ForceVLA 展现了 23.2% 的性能提升。这突显了融合并高效处理多模态信息(包括力感知)所带来的显著优势。表 1 进一步强调了 ForceVLA 在复杂黄瓜削皮任务上的卓越表现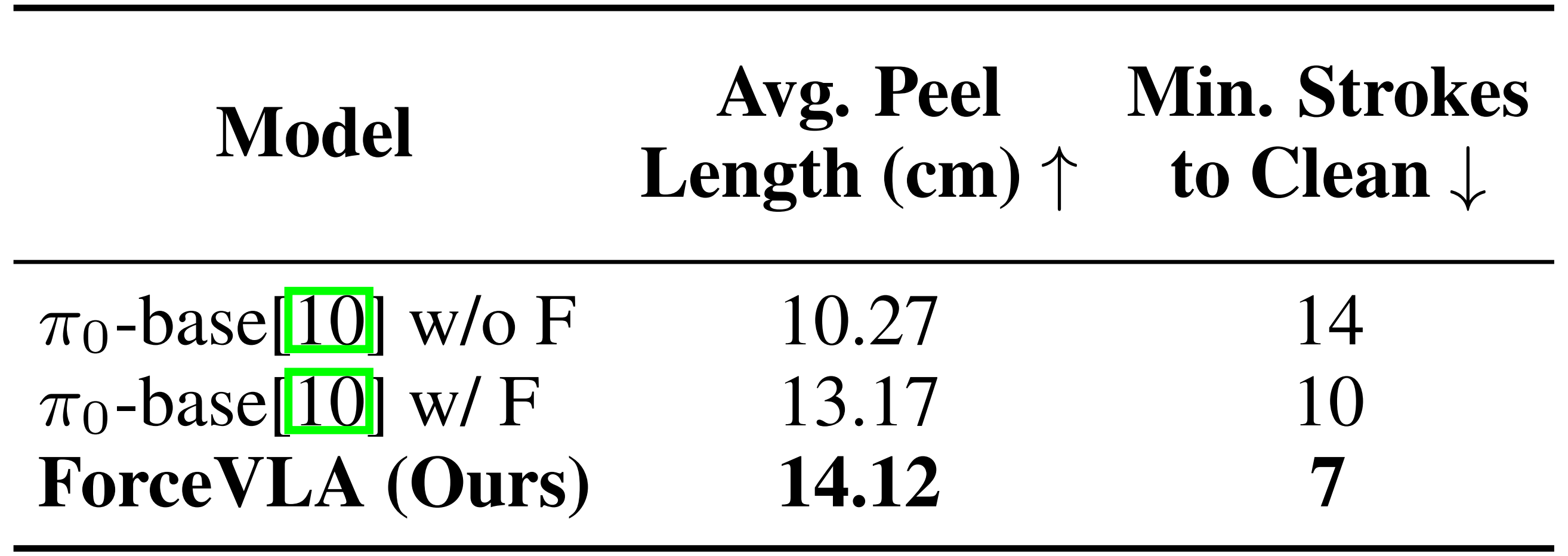
- 他们的模型在两个关键指标上均表现出色:其每次划动的平均削皮长度最长(14.12 厘米↑),显示出在稳定工具姿态、自适应轮廓跟踪以及持续表面接触方面,ForceVLA 相较于 π0-base w/ F (13.17 厘米)和 π0-base w/o F (10.27厘米)具有更强的高保真表面操作能力
同时,ForceVLA 在整体效率上也表现优异,仅需 7 次划动(7↓)即可实现大面积削皮,显著少于 π0-base w/ F 的 10 次和π0-base w/o F 的 14 次
上述结果共同表明,ForceVLA 能够在需要持续且精确力调控的任务中,始终保持高效、稳定的工具与表面交互,并执行高效且目标导向的动作
其次,对于力融合通过FVLMoE的有效性
将原始力信号引入π0-base后,性能从37.3%提升至40.2%,验证了力反馈的实用性
然而,ForceVLA的表现更优,达到60.5%,这表明高效的融合——由他们的FVLMoE模块实现——对于充分利用触觉信息至关重要。这说明,除了信息本身的存在之外,力数据的集成方式对于性能提升至关重要
最后,对于π0-base 和π0-fast 模型的选择
作为他们的基础基线,作者评估了π0-base 和π0-fast 两种变体
π0-base 架构表现出更优越的整体性能:π0-base w/ F (40.2 %) 和π0-base w/oF (37.3 %) 的表现明显优于π0-fast w/ F (14.2 %) 和π0-fast w/o F (31.0 %)
- 虽然π0-fast变体仅在白板擦拭任务上表现出一定的比较优势:这可能是由于其更简单的动作生成机制更适合此类动作,但当直接加入原始力输入时,π0-fast 架构的性能显著下降(从31.0 %降至14.2 %)
作者认为,这种敏感性源于其高度优化且紧凑的token 空间,很可能因简单投影的力token 缺乏相应的大规模预训练而受到干扰 - 相反,π0-base 在直接引入力输入后表现出适度提升,其更大的表征能力可能使其能够部分利用这些新的感知信号
故鉴于其更优的总体性能和对原始力集成的更强鲁棒性,π0-base 被选为ForceVLA 开发和评估的主要基线模型
1.3.3 模型泛化能力
为了评估ForceVLA的泛化能力,作者设计了五种实验设置,这些设置在任务多样性和物理不确定性方面逐步增加,如图6所示

这些设置包括:
- Object Gen. 1,在瓶子抽吸任务中更换瓶子的类型
- Object Gen. 2,在插拔插头任务中更换插头的类型
- Height Gen.,调整初始瓶子的高度并在扭矩限制下衡量成功率
- 视觉遮挡,即插头和插座的部分区域被遮挡
- 以及(5)插座不稳定,通过在插座下方添加杂物引入物理不稳定性。这些变化测试了模型的感知鲁棒性和物理适应性,相关结果汇总于表2
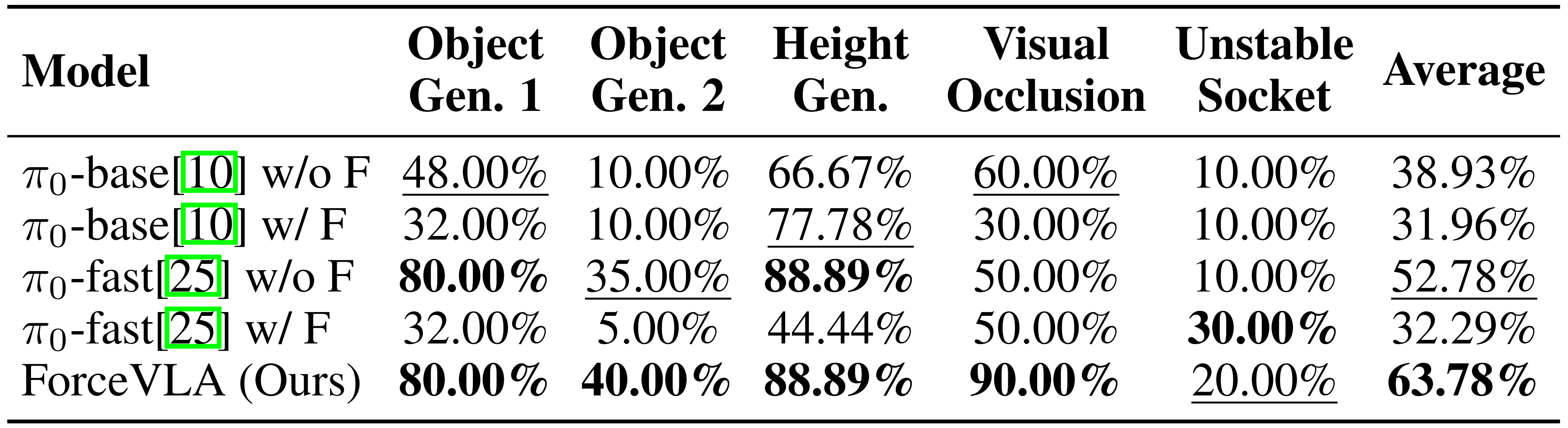
在所有环境中,ForceVLA 展现出卓越的泛化能力,尤其是在需要精细物理交互的场景中表现突出
- 在 Object Gen. 1 任务中,其成功率达到 80.00%,明显优于未使用力输入或仅简单处理力信息的基线模型
- 在 Height Gen. 设置中,ForceVLA 能有效地根据不同深度调整交互力,避免了其他模型中出现的扭矩限制违规问题
- 此外,ForceVLA 在视觉退化条件下依然保持较高的成功率(在视觉遮挡下为 90.00%),显示其依赖多模态反馈,而不仅仅依赖视觉线索
这些结果强调了所提出的 FVLMoE 架构在智能整合力信息方面的关键作用——不仅用于感知接触,还能根据动态物理条件调节动作,从而实现更灵活且更具鲁棒性的机器人操作
1.3.4 消融实验
为了验证ForceVLA的架构设计,特别是力反馈的集成,作者进行了全面的消融实验,结果如表3所示

他们比较了早期融合、晚期融合以及作者提出的融合策略
- 早期融合方法,如“VLM之前的线性融合”和“VLM之前的MoE融合”,即在视觉-语言模型(VLM)之前注入力数据,会显著降低性能
值得注意的是,基于MoE的早期融合完全失败(成功率为0%),这表明对对预训练视觉语言模型(VLM)的输入表示进行干预会破坏其已学习的特征分布,从而削弱其高效处理视觉-语言信号的能力 - 而后期融合策略表现更佳。将“VLM后拼接”方法(相当于在解码阶段附加力感知特征的基础基线方法)应用后,成功率提升至60%,这证明了力感知的有效性
- 然而,作者提出的ForceVLA架构成功率显著提高至80%
通过在VLM核心编码之后引入力特征,并利用FVLMoE模块实现自适应融合,ForceVLA能够实现专门化的路由和更深层次的多模态交互
这些结果验证了两个核心设计理念:
一是力特征应在VLM之后引入,以保留预训练的表示;
二是通过FVLMoE实现的复杂融合对于充分发挥力特征在引导机器人丰富接触行为中的作用至关重要
1.3.5 可视化与案例研究
图7展示了ForceVLA在复杂操作任务中根据接触反馈自适应运动的能力

- 在USB插入任务中,当初次尝试因未对齐而失败时,ForceVLA会重新调整或重新抓取U盘,从而实现成功插入——而基线模型则重复失败动作或施加过大力
- 在“插座不稳定”场景(图7c)中,随着插座移动,ForceVLA持续保持顺应性控制,动态调整插头姿态以完成插入,而基线方法则丢失了跟踪并操作失败
这些案例强调了一个关键观点:仅仅加入力输入并不能保证闭环自适应。ForceVLA的FVLMoE模块实现了力、视觉和语言的深度融合,从而支持精确、具备上下文感知的控制,并在动态物理环境下展现出强大的泛化能力
1.4 结论与局限性
1.4.1 结论
总之,他们提出了 ForceVLA 框架,旨在弥合高级模态(视觉/语言)与低级物理感知(力觉)在接触丰富操作任务中的鸿沟
- ForceVLA 的核心是引入了 FVLMoE——一种专家混合(Mixture-of-Experts)模块,能够动态融合视觉、语言和力觉模态,实现细粒度、具备上下文感知能力的控制
且在五项具有挑战性的任务中进行的实验表明,ForceVLA 相较于强大的 π0 基线有显著提升,平均成功率提高了 23.2%,在个别任务中成功率最高可达80%
消融实验进一步验证了后期力觉融合与专家路由机制的优势 - 且作者还贡献了ForceVLA-Data,这是一个面向多模态接触丰富操作的新数据集
1.4.2 局限性
- 首先,ForceVLA 目前采用的是估算的外部力矩值。虽然这种方法已被证明行之有效,但在某些对触觉灵敏度要求极高的场景下,这些估算值可能无法完全达到高精度直接测量所能提供的精确度
潜在的改进方向包括探索集成更高性能的传感器或采用先进的校准技术,以进一步完善细粒度控制能力的技术 - 其次,ForceVLA 的实验验证主要在集成了高成本力-扭矩传感器的机器人(非夕机器人集成了力传感)平台上进行,这在一定程度上限制了其更广泛的可用性
为了促进更广泛的实际部署,并推动力感知操作研究的普及,作者正在积极评估ForceVLA 在配备外部或改装力传感器的更常见、低成本平台上的适应性和性能

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 12
12 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)