mysql over函数_窗口函数_解决SQL累加问题
业务场景1:求出每月数量(amount)的累计值这个需求在Excel里面是非常好实现的,一个求和公式直接搞定,但Excel处理的数据量毕竟有限,这个需求在SQL里,怎么来实现呢?——窗口函数。select *,sum(amount) over(order by month) from tablegroup by month;窗口函数1、累计求和基础结构:sum(...) over(...)复杂结.
业务场景1:求出每月数量(amount)的累计值
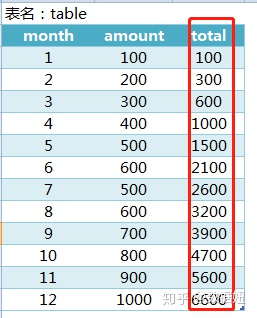
这个需求在Excel里面是非常好实现的,一个求和公式直接搞定,但Excel处理的数据量毕竟有限,这个需求在SQL里,怎么来实现呢?——窗口函数。
select *,sum(amount) over(order by month) from table
group by month;窗口函数
1、累计求和
基础结构:sum(...) over(...)
复杂结构:sum(...) over(partition by ... order by ... rows between ... and ...)
上面省略号(...)位置所替代的信息:
- sum(需要求和的列名);
- partition by 需要分组的列名;
- order by 需要排序的列名:默认升序(asc),降序为desc;
- rows between 参与计算的行起始位置 and 参与计算的行终止位置;over括号中的那些,注:over括号中那些,如果没有相应需求,可以省略;
$包括本行和前3行:rows between 6 preceding and current row (如季度求和)
$包括本行和后3行:rows between current row and 3 following
$包括本行和之前所有的行:rows between unbounded preceding and current row
$包括本行和之后所有的行:rows between current row and unbounded following
$从前5行到下1行(总共包含7行数据):rows between 5 preceding and 1 following
例:对2019年和2020年的数量总额按月累计,按年汇总
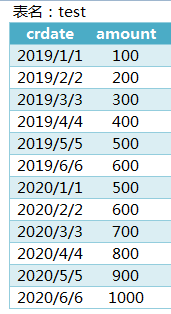
select year(crdate) 年,month(crdate) 月,sum(amount) 每月总量,
sum(sum(amount)) over(partition by year(crdate) order by month(crdate)) 累计 from test
where year(crdate) in (2019,2020)
group by year(crdate),month(crdate);2、其他聚合类的窗口函数
平均:avg(...) over(partition by ... order by ... rows between ... and ...)(如股票中的7日移动平均)
计数:count(...) over(partition by ... order by ... rows between ... and ...)
最大:max(...) over(partition by ... order by ... rows between ... and ...)
最小:min(...) over(partition by ... order by ... rows between ... and ...)
3、排序类的窗口函数
为查出来的每一行生成一个序号
- row_number() over( partition by ... order by ...):序号连续不重复
- dense_rank() over(partition by ... order by ...):序号连续,如有两个第一时,紧接着还是第二:
- rank() over(partition by ... order by ...):序号跳跃的,如有两个第一,接着就是第三
注:省略号同上,row_number()这个括号里不需要添加字段名,其他两个同样;
mysql中没有现成的位移函数,可以借助添加序号辅助列,求上下两行的差值
业务场景2:请求出2020年每月总的新增量(下表中2019-12-31,表示从开始(时间未知)到2019-12-31的累计值)
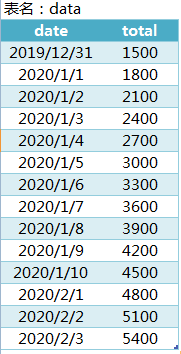
select year(t2.date) year,month(t2.date) month,sum(t2.total-t1.total) from
(select date,total,row_number() over(order by date) rank1 from data) t1
join
(select date,total,row_number() over(order by date) rank2 from data) t2
on t2.rank2 = t1.rank1+1
group by year(t2.date),month(t2.date)4、平均分组(切片类的)窗口函数
ntile(n) over(partition by ...order by ...):
返回每行数据当前所在的切片值(即按指定顺序,被分到第几组)
n:表示把数据分成几组,数据不能均分时,前面组的数据多
业务场景3:求充值排名前25%的用户(假设user_name唯一)
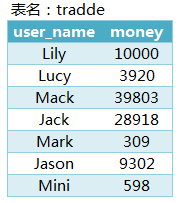
思路:前25%,就是平均分成4份,取第一份
select t.user_name,t.money from
(select username,money,ntile(4) over(order by money desc) tile from tradde group by user_name) t
where t.tile = 15、位移函数(mysql不支持)
取出同一字段前/后n行的数据,作为单独的列
- 前N行:lag(str,N,default) over(partition by ...order by ...)
- 后N行:lead(str,N,default) over(partition by ...order by ...)
str:表示字段名,要取哪一列的数据;
N:表示偏移量,取前/后第几行的数据,默认为1;
default:当取值时,前/后N行已经超出表的范围,或者是没有,这种情况下的默认返回值,不指定的话,返回null;
像前面的业务场景2中,需要计算上下两行数据的差值,就可以用这种位移函数;

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)