UnSola:为智能助手安装语音功能,包括porcupine自定义唤醒词,faster-whisper语音识别,piper-tts语音合成,pyaudio语音播放
procupine自定义唤醒词教程,语音唤醒,语音识别,语音合成以及语音播放结合使用的一个组合类,为大语言模型实现基础的语音控制功能。
·
前言
一款电脑智能助手肯定是需要语音对话来实现控制的,没有语音控制,实用性下降很多,有这打字的功夫跟你助手说,我都能自己点点鼠标完成了。所以我在原有基础上,完善了这部分的基础实现。
问题总结
- 语音播放避雷这个sounddevice库,存在bug,会直接弹窗报错,我后面就改成使用pyaudio,虽然目前局限于在windows上使用,但是智能助手这个项目本身在liunx等系统作用也小很多,所以我暂时不考虑。
- 回复词会被识别的问题,本来我觉得这个问题很简单,加一个固定的忽略就可以,但是却发现,明明忽略之后的提示音是在回复词之后的,但是还是会识别到回复词,逻辑上也一直没找到根本问题,所以在识别之后加了个过滤,把回复词过滤掉。
- 回复词之后一段时间的声音会被吞,这个跟上一个问题是结合在一起的,我怀疑可能是一个问题导致的,我暂时是加了一个提示音,在听到“滴”的一声之后的声音是不会被吞掉的。
环境版本
pvporcupine>=4.0.1
ctranslate2>=4.6.3
faster-whisper>=1.2.1
piper-tts>=1.3.0
onnxruntime-gpu>=1.23.2
soundfile>=0.13.1
pyaudio>=0.2.14
porcupine 自定义唤醒词
官方提供了一些可选的唤醒词,同时也提供了自定义的方法
1.点击官网,进入需要一点魔法。找到下图创建提示词按钮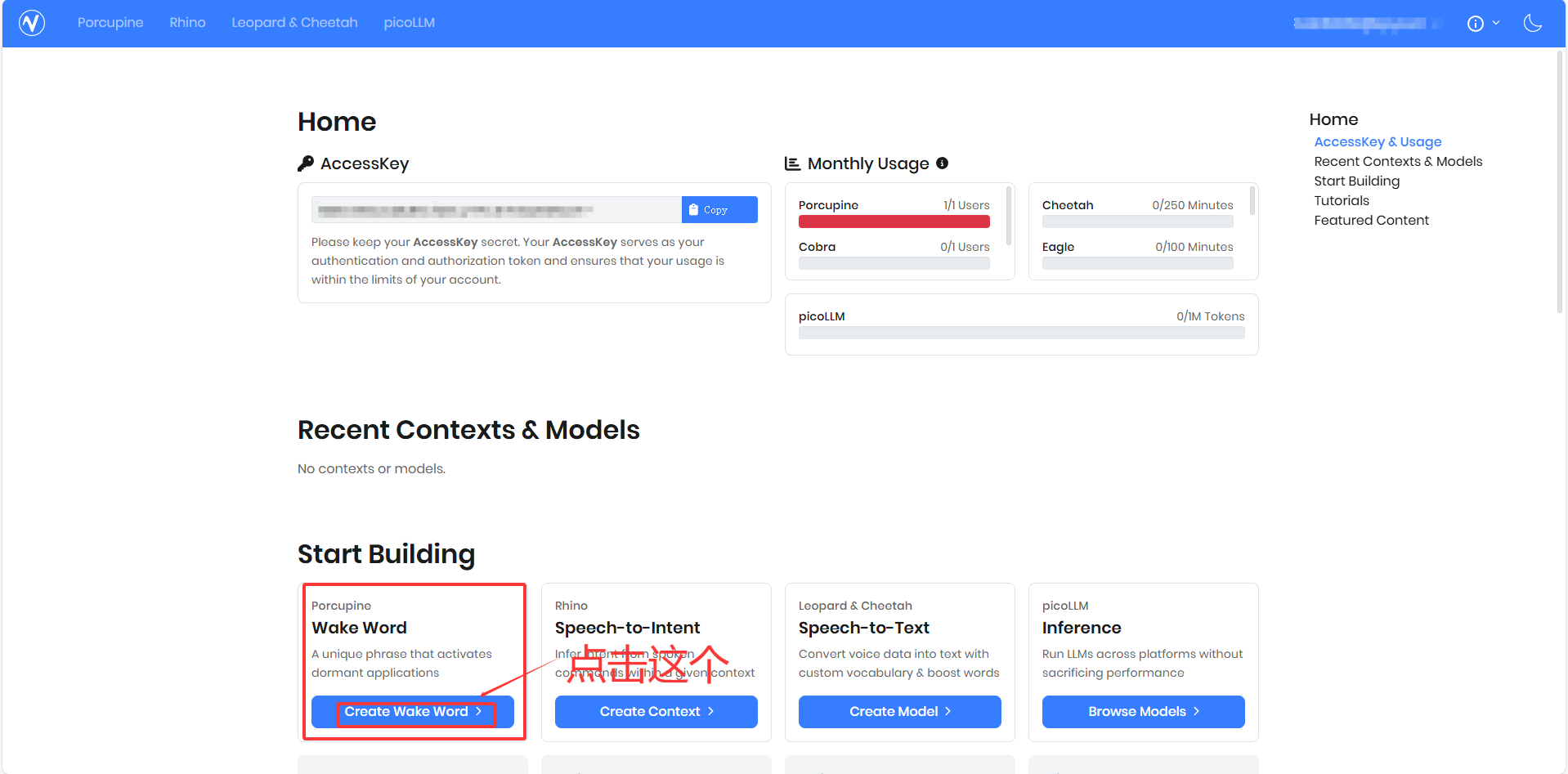
2.选择语言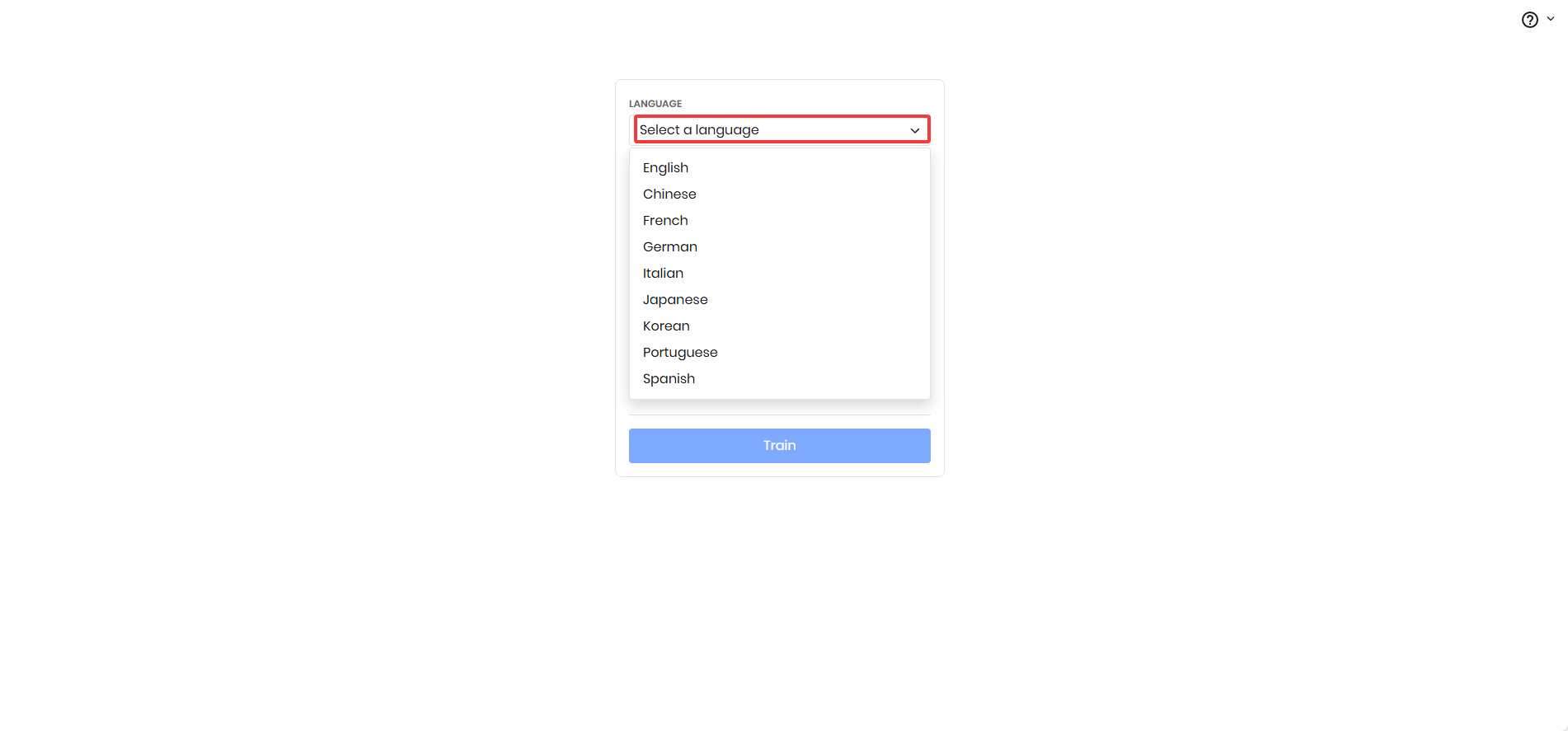
3.输入提示词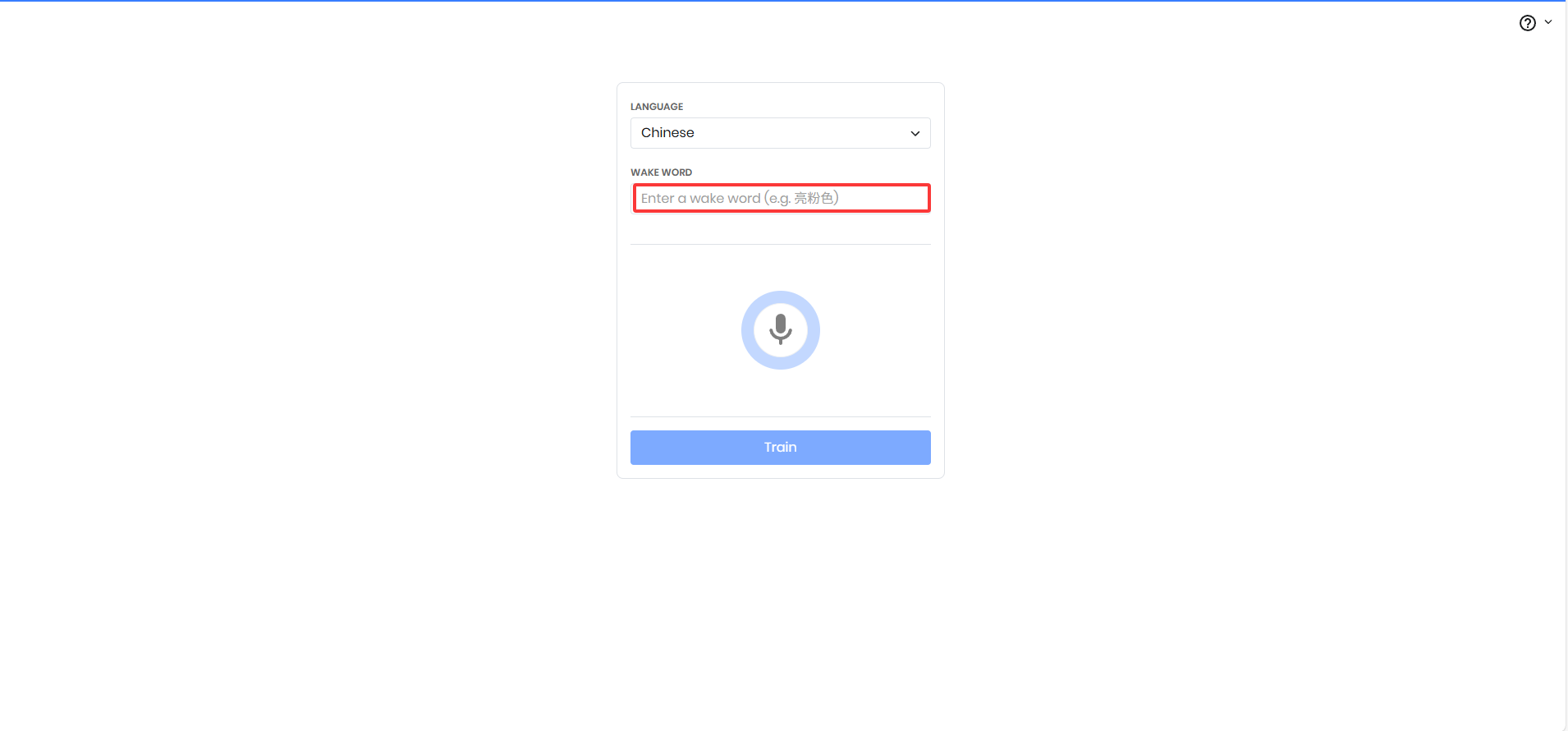
4.录制提示词声音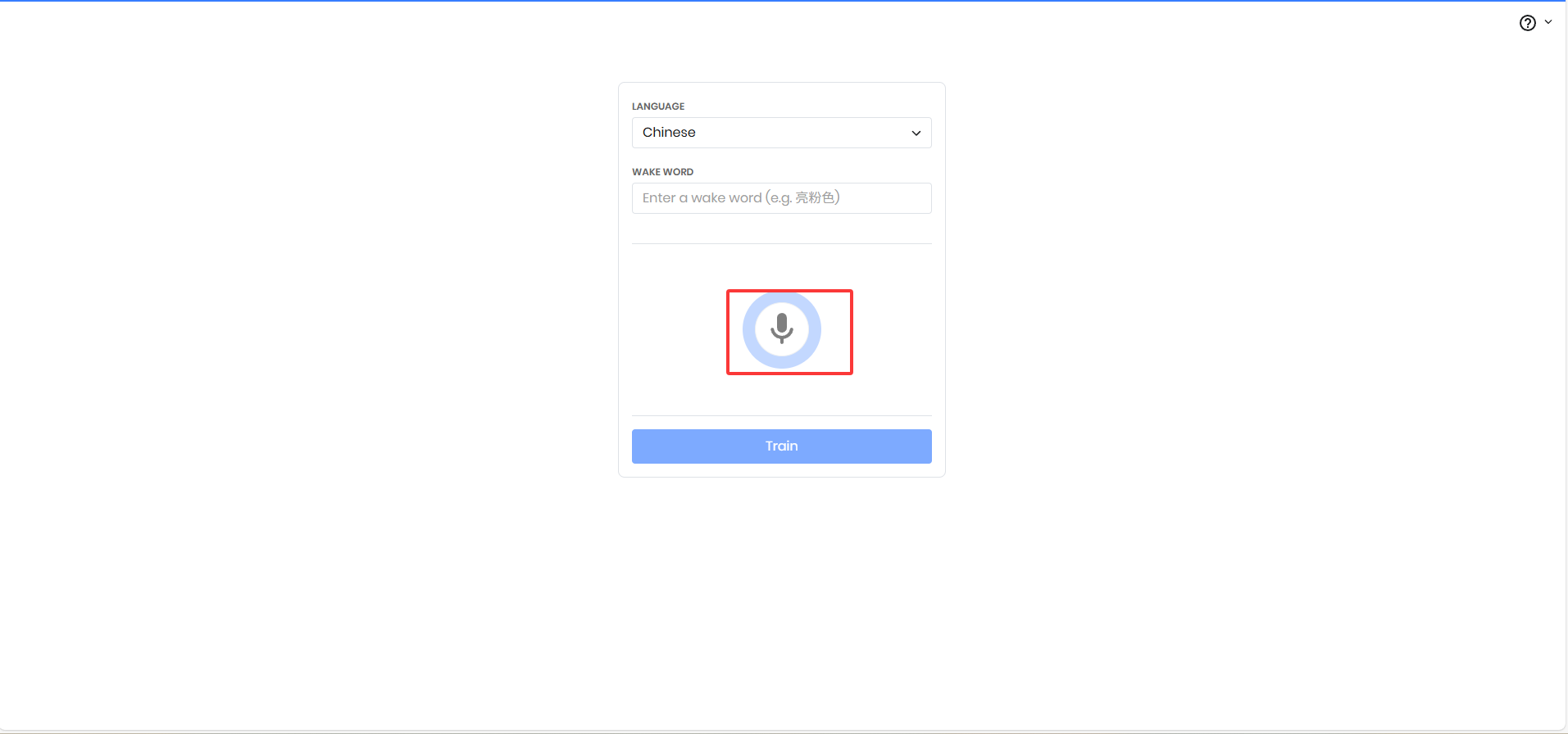
5.点击训练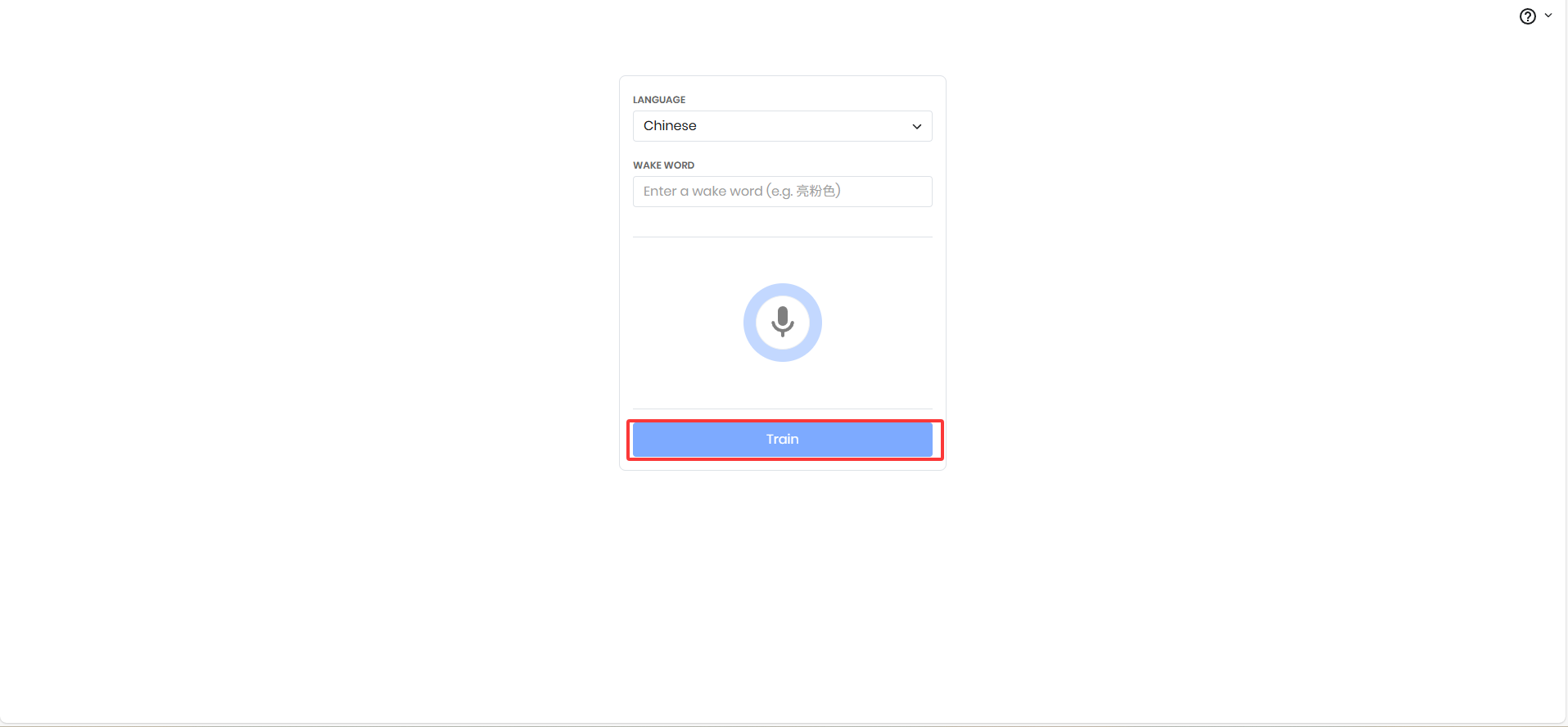
然后回得到一个ppn和pv,在yaml配置文件里面填写相应位置就可以了
配置文件yaml
voice:
# 基础设置
enabled: true # 是否启用语音控制
max_history: 10
device: "cpu" # 设备: cpu, cuda, auto
# 音频设置
sample_rate: 16000 # 采样率
chunk_size: 512 # 音频块大小
channels: 1 # 音频通道数
# 唤醒词设置
enable_wake_word: true # 启用唤醒词检测
porcupine_access_key: "" # Picovoice访问密钥(必填)
wake_words: [ "" ] # 默认唤醒词列表
keyword_paths: [ ".ppn" ] # 自定义唤醒词文件路径
model_path: "porcupine_params_zh.pv"
# 语音识别 (STT)
enable_stt: true # 启用语音识别
whisper_model: "medium" # 模型大小: tiny, base, small, medium, large-v2
compute_type: "int8" # 计算类型: int8, int8_float16
# 语音合成 (TTS)
enable_tts: true # 启用语音合成
tts_model: "zh_CN-huayan-medium" # TTS语音模型
use_cuda: false # TTS是否使用CUDA
下载语音合成模型
这个代码运行会从huggingface下载模型,下载失败大概率网络问题
"""
语音模型下载脚本
"""
import os
import sys
from pathlib import Path
import requests
import zipfile
import tarfile
from tqdm import tqdm
import platform
def download_file(url: str, save_path: Path):
"""下载文件并显示进度条"""
try:
response = requests.get(url, stream=True)
total_size = int(response.headers.get('content-length', 0))
with open(save_path, 'wb') as f:
with tqdm(total=total_size, unit='B', unit_scale=True, desc=f"下载 {save_path.name}") as pbar:
for data in response.iter_content(chunk_size=1024):
f.write(data)
pbar.update(len(data))
return True
except Exception as e:
print(f"下载失败: {e}")
return False
def download_piper_tts_models():
"""下载 Piper TTS 语音模型"""
print("=" * 50)
print("下载 Piper TTS 语音模型")
print("=" * 50)
# 语音模型列表
voices = {
"zh_CN-huayan-medium": {
"model": "https://huggingface.co/rhasspy/piper-voices/resolve/main/zh/zh_CN/huayan/medium/zh_CN-huayan-medium.onnx",
"config": "https://huggingface.co/rhasspy/piper-voices/resolve/main/zh/zh_CN/huayan/medium/zh_CN-huayan-medium.onnx.json"
},
"zh_CN-huayan-low": {
"model": "https://huggingface.co/rhasspy/piper-voices/resolve/main/zh/zh_CN/huayan/low/zh_CN-huayan-low.onnx",
"config": "https://huggingface.co/rhasspy/piper-voices/resolve/main/zh/zh_CN/huayan/low/zh_CN-huayan-low.onnx.json"
},
"en_US-lessac-medium": {
"model": "https://huggingface.co/rhasspy/piper-voices/resolve/main/en/en_US/lessac/medium/en_US-lessac-medium.onnx",
"config": "https://huggingface.co/rhasspy/piper-voices/resolve/main/en/en_US/lessac/medium/en_US-lessac-medium.onnx.json"
}
}
# 选择语音
print("可用语音:")
for i, voice_name in enumerate(voices.keys(), 1):
print(f" {i}. {voice_name}")
choice = input("\n请选择要下载的语音编号 (默认 1 中文): ").strip()
if choice == "":
choice = "1"
voice_names = list(voices.keys())
try:
selected_idx = int(choice) - 1
if 0 <= selected_idx < len(voice_names):
voice_name = voice_names[selected_idx]
else:
voice_name = "zh_CN-huayan-medium"
except:
voice_name = "zh_CN-huayan-medium"
print(f"将下载语音: {voice_name}")
project_root = Path(__file__).parent.parent.parent
# 创建目录
voice_dir = project_root/"assets"/ "voices"
voice_dir.mkdir(parents=True, exist_ok=True)
# 下载模型和配置
model_url = voices[voice_name]["model"]
config_url = voices[voice_name]["config"]
model_file = voice_dir / f"{voice_name}.onnx"
config_file = voice_dir / f"{voice_name}.json"
success = True
# 下载模型文件
if not model_file.exists():
print(f"正在下载模型文件...")
if not download_file(model_url, model_file):
success = False
# 下载配置文件
if not config_file.exists():
print(f"正在下载配置文件...")
if not download_file(config_url, config_file):
success = False
if success:
print(f"✅ 语音模型下载完成:")
print(f" 模型: {model_file}")
print(f" 配置: {config_file}")
return str(voice_dir)
else:
print("❌ 语音模型下载失败")
return None
def main():
"""主函数"""
print("Unsola 语音模型下载工具")
print("=" * 50)
print("下载 Piper TTS 语音合成模型")
download_piper_tts_models()
if __name__ == "__main__":
main()
使用需要改一下下载到本地的voice_dir目录路径,而语音识别模型会在使用前检查下没下载,没有下载就会自动下载。
核心代码
我代码分为控制类和助手类,助手类是对控制类的再封装
控制类
"""
语音控制模块
集成唤醒词检测、语音识别、语音合成功能
不使用 sounddevice 库
"""
import threading
import queue
import time
from pathlib import Path
from typing import Optional, Callable, Dict, Any
import numpy as np
import wave
import pvporcupine
import pyaudio
from faster_whisper import WhisperModel
from piper import PiperVoice
from src.utils.config_manager import ConfigManager
from src.utils.logger import LogManager
logger = LogManager().setup_logger("voice_control")
class VoiceControl:
"""语音控制核心类"""
def __init__(self, config_manager: ConfigManager):
"""
初始化语音控制
Args:
config_manager: 配置管理器
"""
self.config = config_manager
self.voice_config=self.config.get('voice', {})
self.is_running = False
self.is_listening = False
self.audio_queue = queue.Queue()
self.wake_word_detected = threading.Event()
# 语音组件
self.porcupine = None # 唤醒词检测
self.whisper_model = None # 语音识别
self.tts_engine = None # 语音合成
# 音频流
self.audio_stream = None
self.pyaudio_instance = None
# 回调函数
self.on_wake_word_callback = None
self.on_transcription_callback = None
self.on_error_callback = None
# 音频参数
self.sample_rate = self.voice_config.get('sample_rate', 16000)
self.channels = self.voice_config.get('channels', 1)
self.chunk_size = self.voice_config.get('chunk_size', 512)
# 线程
self.audio_thread = None
self.processing_thread = None
self.project_root = Path(__file__).parent.parent.parent
# 初始化语音组件
self._initialize_components()
def _initialize_components(self):
"""初始化语音组件"""
try:
# 初始化唤醒词检测
if pvporcupine and self.voice_config.get('enable_wake_word', True):
self._init_wake_word_detector()
# 初始化语音识别
if WhisperModel and self.voice_config.get('enable_stt', True):
self._init_speech_recognition()
# 初始化语音合成
if PiperVoice and self.voice_config.get('enable_tts', True):
self._init_text_to_speech()
# 初始化音频采集
self.pyaudio_instance = pyaudio.PyAudio()
logger.info("语音组件初始化完成")
except Exception as e:
logger.error(f"初始化语音组件失败: {e}")
def _init_wake_word_detector(self):
"""初始化唤醒词检测"""
try:
access_key = self.voice_config.get('porcupine_access_key', '')
if not access_key:
logger.warning("未配置Porcupine Access Key,跳过唤醒词检测")
return
# 获取唤醒词配置
wake_words = self.voice_config.get('wake_words', ['porcupine'])
keyword_paths = self.voice_config.get('keyword_paths', [])
model_path = self.voice_config.get('model_path', '')
# 创建Porcupine实例
if keyword_paths:
self.porcupine = pvporcupine.create(
access_key=access_key,
keyword_paths=keyword_paths,
model_path=model_path
)
else:
self.porcupine = pvporcupine.create(
access_key=access_key,
keywords=wake_words
)
self.sample_rate = self.porcupine.sample_rate
self.chunk_size = self.porcupine.frame_length
logger.info(f"唤醒词检测初始化完成,采样率: {self.sample_rate}Hz, 帧长: {self.chunk_size}")
except Exception as e:
logger.error(f"初始化唤醒词检测失败: {e}")
self.porcupine = None
def _init_speech_recognition(self):
"""初始化语音识别"""
try:
model_size = self.voice_config.get('whisper_model', 'small')
device = self.voice_config.get('device', 'cpu')
compute_type = self.voice_config.get('compute_type', 'int8')
self.whisper_model = WhisperModel(
model_size,
device=device,
compute_type=compute_type,
num_workers=2,
download_root=str(self.project_root/"assets"/ "models")
)
logger.info(f"语音识别初始化完成,模型: {model_size}")
except Exception as e:
logger.error(f"初始化语音识别失败: {e}")
self.whisper_model = None
def _init_text_to_speech(self):
"""初始化语音合成"""
try:
voice_model_name = self.voice_config.get('tts_model', 'zh_CN-huayan-medium')
use_cuda = self.voice_config.get('use_cuda', False)
# 创建模型目录
model_dir = self.project_root/"assets"/"voices"
model_dir.mkdir(parents=True, exist_ok=True)
# 定义完整的模型和配置文件路径
model_file = model_dir / f"{voice_model_name}.onnx"
config_file = model_dir / f"{voice_model_name}.json"
# 检查文件是否存在
if not model_file.exists():
print(f"错误: 找不到模型文件: {model_file}")
print("请下载模型文件:")
print(f"1. https://huggingface.co/rhasspy/piper-voices/tree/main/zh/{voice_model_name}")
print(f"2. 需要下载: {voice_model_name}.onnx 和 {voice_model_name}.json")
return False
# 使用完整路径加载
self.tts_engine = PiperVoice.load(
model_path=str(model_file),
config_path=str(config_file),
use_cuda=use_cuda
)
logger.info(f"语音合成初始化完成,语音模型: {voice_model_name}")
except Exception as e:
logger.error(f"初始化语音合成失败: {e}")
self.tts_engine = None
def start(self):
"""启动语音控制"""
if self.is_running:
logger.warning("语音控制已经在运行")
return
self.is_running = True
# 启动音频采集线程
self.audio_thread = threading.Thread(target=self._audio_capture_loop, daemon=True)
self.audio_thread.start()
# 启动处理线程
self.processing_thread = threading.Thread(target=self._processing_loop, daemon=True)
self.processing_thread.start()
logger.info("语音控制已启动")
def stop(self):
"""停止语音控制"""
self.is_running = False
# 停止音频流
if self.audio_stream:
try:
self.audio_stream.stop_stream()
self.audio_stream.close()
except:
pass
self.audio_stream = None
# 关闭 PyAudio
if self.pyaudio_instance:
try:
self.pyaudio_instance.terminate()
except:
pass
# 等待线程结束
if self.audio_thread:
self.audio_thread.join(timeout=2)
if self.processing_thread:
self.processing_thread.join(timeout=2)
# 释放资源
if self.porcupine:
self.porcupine.delete()
logger.info("语音控制已停止")
def _audio_capture_loop(self):
"""音频采集循环 - 使用 PyAudio"""
try:
# 创建队列
self.audio_queue = queue.Queue(maxsize=50)
# 打开音频流
self.audio_stream = self.pyaudio_instance.open(
format=pyaudio.paFloat32,
channels=self.channels,
rate=self.sample_rate,
input=True,
frames_per_buffer=self.chunk_size,
stream_callback=self._audio_callback
)
logger.info(f"音频采集已启动,采样率: {self.sample_rate}Hz, 块大小: {self.chunk_size}")
# 保持流运行
self.audio_stream.start_stream()
# 等待直到停止
while self.is_running and self.audio_stream.is_active():
time.sleep(0.1)
except Exception as e:
logger.error(f"音频采集错误: {e}")
if self.on_error_callback:
self.on_error_callback(f"音频采集错误: {e}")
def _audio_callback(self, in_data, frame_count, time_info, status):
"""PyAudio 音频回调函数"""
try:
if status:
if status == pyaudio.paInputOverflowed:
logger.warning("音频输入溢出,请降低输入音量")
else:
logger.warning(f"音频状态: {status}")
# 将数据转换为 numpy 数组
audio_data = np.frombuffer(in_data, dtype=np.float32).reshape(-1, self.channels)
# 放入队列
try:
self.audio_queue.put_nowait(audio_data)
except queue.Full:
# 队列满了,丢弃一些旧数据
logger.debug("音频队列已满,丢弃数据")
except Exception as e:
logger.error(f"音频回调错误: {e}")
return in_data, pyaudio.paContinue
def _processing_loop(self):
"""处理循环"""
audio_buffer = []
is_recording = False
silence_frames = 0
max_silence_frames = int(self.sample_rate / self.chunk_size * 2) # 2秒静默
ignore_frames = 0 # 添加忽略帧计数器
ignore_frames_threshold = 10
is_start=True
while self.is_running:
try:
# 从队列获取音频数据
audio_data = self.audio_queue.get(timeout=0.1)
# 检查音频数据长度
if len(audio_data) != self.chunk_size:
logger.warning(f"音频数据长度不匹配: 期望 {self.chunk_size}, 实际 {len(audio_data)}")
continue
# 唤醒词检测
if self.porcupine and not is_recording:
# 转换为 16 位 PCM
pcm_data = (audio_data.flatten() * 32767).astype(np.int16)
# 确保长度正确
if len(pcm_data) == self.porcupine.frame_length:
keyword_index = self.porcupine.process(pcm_data)
if keyword_index >= 0:
logger.info("检测到唤醒词!")
is_recording = True
is_start = True
audio_buffer = []
silence_frames = 0
ignore_frames = 0
if self.on_wake_word_callback:
self.on_wake_word_callback()
continue
# 语音识别
if is_recording:
# 如果还在忽略期,跳过当前音频帧
if ignore_frames < ignore_frames_threshold:
ignore_frames += 1
continue
if is_start:
self.play_notification_sound()
is_start = False
audio_buffer.append(audio_data)
# 检测静默(VAD)
energy = np.mean(np.abs(audio_data))
if energy < 0.01: # 静默阈值
silence_frames += 1
else:
silence_frames = 0
# 如果静默时间过长,结束录音
if silence_frames > max_silence_frames:
logger.info("检测到静默,结束录音")
is_recording = False
if audio_buffer:
self._process_audio(audio_buffer)
audio_buffer = []
silence_frames = 0
ignore_frames = 0
except queue.Empty:
continue
except Exception as e:
logger.error(f"处理音频数据错误: {e}")
import traceback
traceback.print_exc()
def _process_audio(self, audio_buffer):
"""处理音频数据"""
try:
# 合并音频数据
audio_np = np.concatenate(audio_buffer, axis=0)
# 保存临时文件
temp_file = self.project_root/"assets" / "temp_audio.wav"
self._save_audio_to_wav(audio_np, temp_file)
# 语音识别
if self.whisper_model:
segments, info = self.whisper_model.transcribe(
str(temp_file),
language=self.voice_config.get('language', 'zh'),
beam_size=5,
vad_filter=True
)
text = " ".join([segment.text for segment in segments])
if text.strip():
# 过滤掉可能的回复词
filter_words = ["我在听", "请说"]
filtered_text = text.strip()
for word in filter_words:
filtered_text = filtered_text.replace(word, "")
# 去除多余的空格
filtered_text = " ".join(filtered_text.split())
logger.info(f"原始识别结果: {text}")
logger.info(f"过滤后结果: {filtered_text}")
if self.on_transcription_callback:
self.on_transcription_callback(filtered_text)
# 删除临时文件
temp_file.unlink(missing_ok=True)
except Exception as e:
logger.error(f"处理音频错误: {e}")
def _save_audio_to_wav(self, audio_data, filepath):
"""保存音频到WAV文件"""
try:
# 转换为16位整数
audio_int16 = (audio_data * 32767).astype(np.int16)
with wave.open(str(filepath), 'wb') as wf:
wf.setnchannels(self.channels)
wf.setsampwidth(2) # 16位 = 2字节
wf.setframerate(self.sample_rate)
wf.writeframes(audio_int16.tobytes())
except Exception as e:
logger.error(f"保存音频文件错误: {e}")
def synthesize_speech(self, text: str) -> Optional[bytes]:
"""
语音合成(文本转语音)
"""
if not self.tts_engine:
logger.warning("语音合成未初始化")
return None
try:
logger.info(f"语音合成: {text[:50]}...")
import io
# 创建内存中的缓冲区
buffer = io.BytesIO()
# 打开一个 wave 写入对象,写入到内存缓冲区
with wave.open(buffer, 'wb') as wav_file:
self.tts_engine.synthesize_wav(text, wav_file)
# 获取完整的 WAV 数据
wav_data = buffer.getvalue()
if wav_data and len(wav_data) > 0:
logger.info(f"语音合成成功: {len(wav_data)} bytes")
# 验证是有效的 WAV 文件
if wav_data.startswith(b'RIFF'):
logger.debug("确认是有效的 WAV 格式")
return wav_data
else:
logger.error("语音合成返回空数据")
return None
except Exception as e:
logger.error(f"语音合成失败: {e}")
import traceback
traceback.print_exc()
return None
def speak(self, text: str) -> bool:
"""
语音合成并播放
"""
try:
# 获取音频数据
audio_data = self.synthesize_speech(text)
if not audio_data:
logger.error("语音合成失败,无音频数据")
return False
# 播放音频
if self._play_audio_with_pyaudio(audio_data):
logger.info(f"语音播放成功: {text[:30]}...")
return True
else:
logger.error("语音播放失败")
return False
except Exception as e:
logger.error(f"语音合成/播放失败: {e}")
import traceback
traceback.print_exc()
return False
def _play_audio_with_pyaudio(self, audio_data: bytes) -> bool:
"""
使用 PyAudio 播放音频
"""
try:
import io
import wave
# 检查是否是有效的 WAV 数据
if not audio_data.startswith(b'RIFF'):
logger.error("无效的音频数据格式")
return False
# 从字节数据创建 wave 文件对象
buffer = io.BytesIO(audio_data)
with wave.open(buffer, 'rb') as wf:
# 获取音频参数
channels = wf.getnchannels()
sample_width = wf.getsampwidth()
sample_rate = wf.getframerate()
n_frames = wf.getnframes()
audio_format = None
# 根据采样宽度设置格式
if sample_width == 1:
audio_format = pyaudio.paInt8
elif sample_width == 2:
audio_format = pyaudio.paInt16
elif sample_width == 4:
audio_format = pyaudio.paInt32
else:
logger.error(f"不支持的采样宽度: {sample_width}")
return False
# 读取所有音频数据
audio_data_bytes = wf.readframes(n_frames)
# 创建 PyAudio 实例(如果不存在)
if not self.pyaudio_instance:
self.pyaudio_instance = pyaudio.PyAudio()
# 打开输出流
output_stream = self.pyaudio_instance.open(
format=audio_format,
channels=channels,
rate=sample_rate,
output=True
)
# 播放音频
output_stream.write(audio_data_bytes)
# 等待播放完成
time.sleep(n_frames / sample_rate + 0.1)
# 关闭流
output_stream.stop_stream()
output_stream.close()
return True
except Exception as e:
logger.error(f"PyAudio 播放失败: {e}")
return False
def play_notification_sound(self):
"""播放通知音"""
try:
# 生成一个简单的提示音
duration = 0.1
frequency = 1000
t = np.linspace(0, duration, int(self.sample_rate * duration), False)
tone = 0.3 * np.sin(2 * np.pi * frequency * t)
# 转换为字节
tone_bytes = (tone * 32767).astype(np.int16).tobytes()
# 播放提示音
stream = self.pyaudio_instance.open(
format=pyaudio.paInt16,
channels=1,
rate=self.sample_rate,
output=True
)
stream.write(tone_bytes)
stream.stop_stream()
stream.close()
except Exception as e:
logger.error(f"播放提示音失败: {e}")
def set_callbacks(self,
on_wake_word: Optional[Callable] = None,
on_transcription: Optional[Callable] = None,
on_error: Optional[Callable] = None):
"""
设置回调函数
Args:
on_wake_word: 唤醒词检测回调
on_transcription: 语音识别回调
on_error: 错误回调
"""
self.on_wake_word_callback = on_wake_word
self.on_transcription_callback = on_transcription
self.on_error_callback = on_error
def get_status(self) -> Dict[str, Any]:
"""获取语音控制状态"""
return {
'running': self.is_running,
'listening': self.is_listening,
'wake_word_ready': self.porcupine,
'stt_ready': self.whisper_model,
'tts_ready': self.tts_engine,
'sample_rate': self.sample_rate
}
助手类
"""
语音助手集成类
将语音控制集成到主助手中
"""
from typing import Optional, Dict, Any
from src.utils.config_manager import ConfigManager
from src.features.voice_control import VoiceControl
from src.utils.logger import LogManager
logger = LogManager().setup_logger("voice_assistant")
class VoiceAssistant:
"""语音助手"""
def __init__(self, assistant, config_manager: ConfigManager):
"""
初始化语音助手
Args:
assistant: 主助手实例
config_manager: 配置管理器
"""
self.assistant = assistant
self.config = config_manager
self.voice_config=self.config.get('voice', {})
self.voice_control = None
self.is_enabled = self.voice_config.get('enabled', False)
# 对话历史
self.conversation_history = []
self.max_history = self.voice_config.get('max_history', 10)
# 初始化语音控制
self._initialize_voice_control()
def _initialize_voice_control(self):
"""初始化语音控制"""
try:
self.voice_control = VoiceControl(self.config)
# 设置回调函数
self.voice_control.set_callbacks(
on_wake_word=self._on_wake_word_detected,
on_transcription=self._on_voice_command,
on_error=self._on_voice_error
)
logger.info("语音助手初始化完成")
except Exception as e:
logger.error(f"初始化语音助手失败: {e}")
self.is_enabled = False
def _on_wake_word_detected(self):
"""唤醒词检测回调"""
logger.info("唤醒词检测到")
# 播放提示音
self.speak("我在听,请说")
def _on_voice_command(self, text: str):
"""语音命令处理回调"""
logger.info(f"收到语音命令: {text}")
# 添加到历史
self._add_to_history(f"用户: {text}")
# 处理命令
response = self._process_voice_command(text)
# 语音回复
if response:
self._add_to_history(f"助手: {response}")
self.speak(response)
def _on_voice_error(self, error: str):
"""语音错误回调"""
logger.error(f"语音错误: {error}")
def _process_voice_command(self, text: str) -> Optional[str]:
"""
处理语音命令
Args:
text: 语音命令文本
Returns:
回复文本
"""
try:
# 检查是否为特殊命令
if self._is_special_command(text):
return self._handle_special_command(text)
# 交给主助手处理
if hasattr(self.assistant, 'chat'):
return self.assistant.chat(text)
# 默认回复
return f"收到命令: {text}"
except Exception as e:
logger.error(f"处理语音命令失败: {e}")
return "抱歉,处理命令时出错"
def _is_special_command(self, text: str) -> bool:
"""检查是否为特殊命令"""
special_commands = ['退出', '停止', '关闭语音', '开启语音', '静音', '取消']
text_lower = text.lower()
for cmd in special_commands:
if cmd in text_lower:
return True
return False
def _handle_special_command(self, text: str) -> Optional[str]:
"""处理特殊命令"""
text_lower = text.lower()
if '退出' in text_lower or '停止' in text_lower:
self.stop()
return "语音助手已停止"
elif '关闭语音' in text_lower:
self.set_enabled(False)
return "语音功能已关闭"
elif '开启语音' in text_lower:
self.set_enabled(True)
return "语音功能已开启"
elif '静音' in text_lower:
self.set_muted(True)
return "已静音"
elif '取消' in text_lower:
return "好的,已取消"
return None
def _add_to_history(self, text: str):
"""添加到历史记录"""
self.conversation_history.append(text)
# 保持历史记录长度
if len(self.conversation_history) > self.max_history:
self.conversation_history = self.conversation_history[-self.max_history:]
def speak(self, text: str):
"""语音合成"""
if not self.is_enabled or not self.voice_control:
return
try:
# 语音合成
success = self.voice_control.speak(text)
if not success:
logger.warning("语音合成失败")
except Exception as e:
logger.error(f"语音合成错误: {e}")
def start(self):
"""启动语音助手,返回是否成功"""
if not self.is_enabled:
logger.warning("语音助手未启用")
return False # 明确返回 False
if not self.voice_control:
logger.warning("语音控制未初始化")
return False # 明确返回 False
try:
self.voice_control.start()
logger.info("语音助手已启动")
return True # 成功时返回 True
except Exception as e:
logger.error(f"启动语音助手失败: {e}")
return False # 失败时返回 False
def stop(self):
"""停止语音助手"""
if self.voice_control:
self.voice_control.stop()
logger.info("语音助手已停止")
def set_enabled(self, enabled: bool):
"""启用/禁用语音助手"""
self.is_enabled = enabled
if enabled and not self.voice_control:
self._initialize_voice_control()
if enabled and self.voice_control:
self.start()
elif self.voice_control:
self.stop()
# 保存配置
self.voice_config.set('enabled', enabled)
self.voice_config.save()
def set_muted(self, muted: bool):
"""设置静音"""
# 这里可以扩展静音功能
pass
def get_status(self) -> Dict[str, Any]:
"""获取状态"""
status = {
'enabled': self.is_enabled,
'history_count': len(self.conversation_history)
}
if self.voice_control:
status.update(self.voice_control.get_status())
return status
def get_conversation_history(self) -> list:
"""获取对话历史"""
return self.conversation_history.copy()
def clear_history(self):
"""清空历史记录"""
self.conversation_history.clear()
对外使用只需要初始化一下,start一下就可以保持在后台运行。
if self.voice_enabled:
try:
self.voice_assistant = VoiceAssistant(self, config)
# 立即启动语音助手(后台运行)
if self.voice_assistant.start():
logger.info("语音助手已在后台启动")
print("🎤 语音助手已启动(后台运行)")
else:
logger.warning("语音助手启动失败")
print("⚠️ 语音助手启动失败")
logger.info("语音助手初始化完成")
except Exception as e:
logger.error(f"初始化语音助手失败: {e}")
print(f"❌ 语音助手初始化失败: {e}")
self.voice_enabled = False
总结
目前算是能实现唤醒,识别,合成和播放,但是一次唤醒只能对话一次,我觉得这点后续还可以改进。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)