自动驾驶---基于强化学习的CarPlanner
本文介绍了浙江大学与菜鸟无人车团队提出的自动驾驶轨迹规划方法CarPlanner,该工作被CVPR2025录用。针对传统模仿学习和强化学习在轨迹规划中存在分布漂移、因果混淆等问题,提出基于一致性自回归建模的强化学习框架。核心创新包括:1)引入一致性模式信息解决时间不一致性;2)采用"生成-选择"框架实现多模态轨迹规划;3)设计非反应式转移模型降低计算复杂度。实验表明,在nuPl
1 前言
对于有资源的研究机构或者企业,通过车端的数据进行训练,基本围绕深度学习的端到端网络或者VLA/VLM模型进行自动驾驶任务开发。但看到对于很多高校的学生来说,不利于论文的发表,因此更多的学生开始投入到基于强化学习的轨迹生成器。
轨迹规划是自动驾驶的核心模块,需在复杂交通环境中生成安全、高效的车辆运动轨迹。传统方法依赖规则或模仿学习(IL),但存在分布漂移(实际场景与训练数据偏差)和因果混淆(无法捕捉动态交互的因果关系)问题。强化学习(RL)虽能通过奖励函数提供更灵活的监督,但其在大规模真实驾驶场景中面临两大挑战:
- 训练效率低:高维轨迹空间直接优化导致探索成本剧增;
- 时间不一致:自回归采样的随机性行为易引发跨时间步的轨迹冲突(如突然变向)。
本篇博客介绍CVPR 2025 录用的一篇论文,浙江大学 × 菜鸟无人车联合发表。首次证明:在具有挑战性的大规模 nuPlan 数据集上,基于强化学习(RL)的规划器性能优于当前最先进(SOTA)的模仿学习(IL)规划器与基于规则的规划器。
2 CarPlanner
CarPlanner的目标:设计一种高效、稳定的 RL 轨迹规划器,突破传统方法的性能瓶颈。
2.1 基础知识
(1)MDP
马尔可夫决策过程(MDP)用于建模序贯决策问题,其形式化定义为一个元组,各组件含义如下:
- S:状态空间(state space),包含所有可能的系统状态。
- A:动作空间(action space),包含智能体可执行的所有动作。
- P:状态转移概率(state transition probability),定义为映射 P:
,表示在状态 s下执行动作 a 后,转移到下一状态 s' 的概率分布(∆(S) 表示 S 上的概率分布集合)。
- R:奖励函数(reward function),定义为映射 R:
,用于量化在状态 s 下执行动作 a 后获得的即时奖励,且奖励值有界。
:初始状态分布(initial state distribution),
,表示智能体初始时刻所处状态的概率分布。
- T:时间步长(time horizon),即序贯决策过程的总步数。
:未来奖励折扣因子(discount factor for future rewards),通常取值范围为 [0,1],用于权衡即时奖励与未来奖励的重要性(
越接近 1,越重视未来奖励)。
状态 - 动作序列定义为,其中
、
分别表示第 t 时间步的状态与动作。强化学习(RL)的目标是最大化期望回报(expected return)。
(2)向量化状态表示
状态 包含以向量化形式表示的地图信息与智能体信息,具体构成如下:
-
地图信息:涵盖道路网络、交通信号灯等元素,采用折线(polylines)与多边形(polygons)进行表示。例如,道路边界可用折线描述其连续的坐标序列,十字路口的可行驶区域可用多边形标记其封闭范围,交通信号灯则可通过多边形定位其空间位置并附加状态标签(如 “红灯”“绿灯”)。
-
智能体信息:包含自车(ego vehicle)与其他交通智能体(如社会车辆、行人)的当前及历史位姿,均通过折线形式表示。其中,自车的索引固定为 0,其他交通智能体的索引从 1 到N(N为场景中除自车外的交通智能体总数)。对于每个智能体i(
),其历史信息记为
,这里H代表历史时间跨度,即该状态包含智能体从\(t-H\)时刻到t时刻的连续位姿序列(例如
时,
包含智能体近 5 个时间步的位姿,用于反映其运动趋势)。
2.2 问题建模
将轨迹规划任务建模为序贯决策过程,并将自回归模型解耦为策略模型(policy model)与转移模型(transition model)。连接轨迹规划与自回归模型的核心在于:将 “动作” 定义为自车的下一个位姿(pose),即(其中
为第t步动作,
为自车第
步的目标位姿)。
因此,自回归模型前向传播后,解码得到的位姿会被收集,形成自车的规划轨迹。具体而言,在该定义与向量化表示下,可将 “状态 - 动作序列” 简化为 “状态序列”,
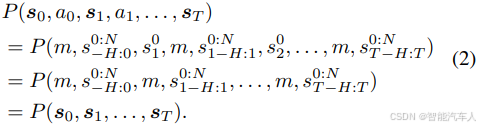
状态序列可进一步以自回归形式构建,并分解为策略模型与转移模型两部分:

由公式(3)可知,典型自回归方法的固有问题可明确识别:由于策略分布依赖于从动作分布中进行随机采样,导致不同时间步之间出现行为不一致的现象。
为解决上述问题,作者在自回归形式中引入了跨时间步保持不变的 “一致性模式信息”c,具体方式如下:

由于聚焦于自车轨迹规划,因此一致性模式c不会对转移模型产生影响。
公式(4)中定义的这种一致性自回归形式,体现了一种 “生成 - 选择” 框架:其中模式选择器基于初始状态 为每个模式打分,而轨迹生成器则通过从 “模式条件化策略”(mode-conditioned policy)中采样,生成多模态轨迹(即对应不同模式的多条候选轨迹)。
非反应式转移模型(Non-reactive Transition Model)
公式(4)中构建的转移模型需要在每个时间步都调用 —— 因为它需基于当前状态 生成
时间步交通智能体(索引 1 到 N)的位姿。但在实际应用中,该过程耗时较高,且发现使用该转移模型并未带来性能提升。因此,采用轨迹预测器
作为非反应式转移模型:给定初始状态
,该模型可 “一次性”(one shot)生成所有交通智能体在未来所有时间步(从 1 到 T)的位姿。
2.3 CarPlanner架构
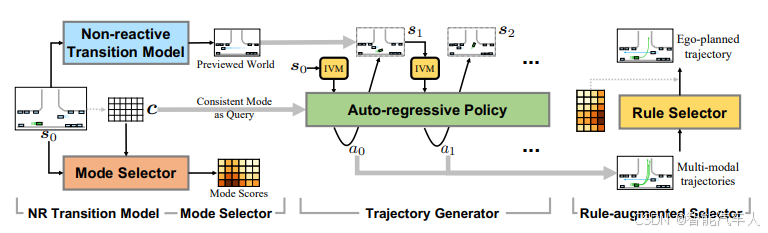
CarPlanner 框架如图所示,包含四个关键组件:1)非反应式转移模型,2)模式选择器,3)轨迹生成器,4)规则增强型选择器。该规划器基于 “生成 - 选择” 框架运作:
给定初始状态 与所有可能的
种模式,轨迹选择器会对每种模式进行评估并分配分数;随后,轨迹生成器会生成与这些模式一一对应的
条轨迹。
在轨迹生成器部分,初始状态 s₀会被复制 次,每一次复制都与
种模式中的一种相关联,从而构建出
个 “平行世界”。策略会在这些模拟环境中执行:在策略展开(policy rollout)过程中,轨迹预测器会作为状态转移模型,在所有时间范围内生成交通智能体(如其他车辆、行人)的未来位置。
(1)核心模块
- 非反应式转换模型:以初始状态 s₀为输入,一次性预测所有交通智体的未来轨迹(无需逐帧交互);
- 模式选择器:基于初始状态 s₀与预设模式集合 {c},输出各模式的匹配分数(如 “直行”“左转” 的概率);
- 轨迹生成器:采用自回归结构,以一致性模式为条件,生成与模式对齐的多模态轨迹(确保同一模式下的轨迹长期连贯);
- 规则增强选择器:通过安全性(碰撞风险)、舒适性(加减速平滑度)、进度性(任务完成度)等指标,对模式分数进行后验补偿,筛选最终轨迹。
(2)核心创新
CarPlanner 的核心思想是将 “一致性模式” 嵌入自回归模型,解决时间不一致性,并通过结构化设计降低 RL 训练复杂度。具体架构包含四大模块:
- 一致性自回归模型:时间因果的稳定表达
- 问题:传统自回归模型通过逐步随机采样生成轨迹,易导致未来动作与初始意图脱节(如 “先计划直行,后突然右转”)。
- 创新:引入全局一致的模式信息(Mode-aware),在初始状态确定后,所有时间步的策略均基于该模式生成,确保轨迹的长期一致性。
- 数学建模:将轨迹生成视为马尔可夫决策过程(MDP),动作定义为自车下一时刻的姿态
,并通过一致性模式 c 约束策略分布
,使跨时间步的决策保持意图一致。
-
生成 - 选择框架:多模态轨迹的高效筛选
- 模式选择器:基于初始状态
评估所有可能模式(如 “直行”“左转”“变道”),输出模式分数
。
- 轨迹生成器:为每个模式独立生成轨迹,通过并行模拟(“平行世界”)实现多模态输出。例如,给定 3 种模式,生成 3 条差异化轨迹。
- 规则 - 增强选择器:融合交通规则(如车道保持、限速)筛选最终轨迹,避免 RL 策略的 “违规” 行为,提升安全性。
- 模式选择器:基于初始状态
- 非反应式转换模型:简化动态环境建模
- 挑战:传统 RL 需实时预测其他交通参与者的轨迹(反应式转换),计算成本高且精度有限。
- 创新:采用一次性轨迹预测器,仅根据初始状态
-
专家指导奖励函数:加速 RL 训练
- 设计包含安全性(碰撞避免)、舒适性(加速度平滑)、合规性(车道中心线偏差)的多目标奖励函数,并通过专家轨迹蒸馏(Behavioral Cloning)初始化策略,减少探索噪声,加速收敛。
| 模块 | 技术方案 | 作用 |
|---|---|---|
| 智体 - 地图编码器 | PointNet 提取车道、路口等地图特征,结合智体历史轨迹(位置、速度、类别) | 融合静态道路结构与动态交通参与者状态 |
| 非反应式预测器 | Transformer 编码器 + 解码器,输出所有智体未来 T 步轨迹 | 替代实时交互,降低计算量,支持大规模场景模拟 |
| 模式条件策略 | 自回归 Transformer,输入当前状态 + 模式标签,输出下一姿态分布 | 确保同一模式下的轨迹一致性 |
| 训练策略 | PPO 算法 + 对比学习(模式分数最大化)+ 规则约束(硬惩罚违规) | 平衡探索 - 利用,提升样本效率 |
2.4 训练
首先,作者训练非反应式转移模型,并在模式选择器与轨迹生成器的训练过程中冻结其权重。并未将所有模式输入生成器,而是采用 “赢家通吃”(winner-takes-all)策略:根据自车真值轨迹确定一个 “正模式”(positive mode),并将该模式作为轨迹生成器的输入条件。
(1)模式分配(Mode Assignment)
- 横向正模式(positive lateral mode)由真值轨迹的终点位置决定。
- 将自车起始位置到该终点的纵向距离划分为
个区间,纵向正模式则对应于真值轨迹终点所在的距离区间。
(2)损失函数(Loss Function)
- 模式选择器:采用交叉熵损失(cross-entropy loss),计算正模式的负对数似然;同时设置一个辅助任务(side task),对自车真值轨迹进行回归。
- 轨迹生成器:采用 PPO(Proximal Policy Optimization,近端策略优化)损失,该损失包含三部分:策略改进(policy improvement)、价值估计(value estimation)和熵(entropy)。完整细节可参见补充材料。
(3)奖励函数(Reward Function)
为适配多样化场景,将自车未来位姿与真值位姿之间的负位移误差(negative displacement error, DE)作为通用奖励。同时,引入额外项以提升轨迹质量:
- 碰撞率(collision rate):若未来位姿发生碰撞,奖励设为 - 1;否则为 0。
- 可行驶区域合规性(drivable area compliance):若未来位姿超出可行驶区域,奖励设为 - 1;否则为 0。
(4)模式丢弃(Mode Dropout)
由于 Transformer 的残差连接可能导致模型过度依赖模式或路径信息,在训练阶段引入模式丢弃模块:通过随机屏蔽(mask)路径信息,缓解这一过度依赖问题。
2.5 实验
- 数据集:nuPlan(大规模真实驾驶数据集,含 1000 + 小时高速 / 城市场景)。
- 对比方案:基于规则的规划器(如 Lattice Planner)、模仿学习(IL,如 Behavioral Cloning)、传统 RL(如 Gen-Drive)。
- 核心结果:
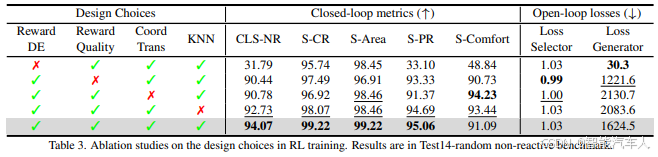
- 性能超越:CarPlanner 在碰撞率(↓27%)、车道合规性(↑32%)、舒适性( jerk↓41%)均优于 IL 和规则方案,首次证明 RL 规划器的实际落地潜力。
- 效率提升:通过一致性模式减少无效探索,训练速度较传统 RL 快 4 倍,支持大规模场景(如 1000 + 交通智体)。
- 真实部署:菜鸟 L4 级无人车已搭载该规划器,在 30 + 区县实现复杂路口(如无保护左转、交叉路口)的稳定通行。
3 总结
CarPlanner 通过一致性自回归建模和结构化 RL 框架,突破了自动驾驶轨迹规划的效率与性能瓶颈,为大规模强化学习在真实场景的落地提供了标杆方案。本文所介绍的CarPlanner和量产中强化学习的对象有些区别,本文中介绍的CarPlanner未来的研究方向还包括:
- 动态模式扩展:支持实时模式切换(如紧急避障);
- 多车协同:纳入 V2X 通信,优化复杂路口的交互规划;
- 轻量化部署:适配边缘计算设备,降低无人车硬件成本。
参考论文:《CarPlanner: Consistent Auto-regressive Trajectory Planning for Large-scale Reinforcement Learning in Autonomous Driving》

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)