【学习笔记】一文搞懂监督学习和非监督学习
本文介绍了机器学习的两种主要类型:监督学习和无监督学习。监督学习通过输入x和输出标签y的映射关系进行训练,可用于回归和分类问题。无监督学习则从无标签数据中发现结构模式,主要包括聚类算法、异常检测和降维技术。
监督学习与非监督学习
视频学习来源:(超爽中英!) 2025公认最好的【吴恩达机器学习】教程!附课件代码 Machine Learning Specialization哔哩哔哩bilibili
Arthur Samuel将机器学习定义为让计算机在没有明确编程的情况下学习的研究领域 他写了一个跳棋播放程序,这个项目的惊人之处在于他本人不是一个很好的跳棋选手 他所做的是给一台电脑编了程序,让它可以和自己玩成千上万个游戏,通过观察哪些会导致胜利,哪些会导致失败,跳棋随着时间推移学习的播放程序,什么是好的或坏的或立场,通过试图获得好的和避免坏的立场,他的程序越来越擅长下跳棋 因为电脑有耐心和自己玩几万场游戏,能够获得这么多跳棋的经验,最终成为了一个更好的跳棋玩家
学习算法的机会越多,它就会表现得越好
机器学习的两种主要类型是监督学习和无监督学习 监督学习时实际使用最多的机器学习类型
强化学习是另一种机器学习算法
监督学习
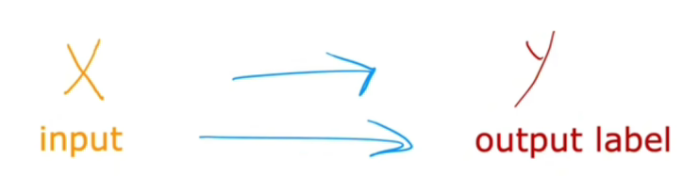
监督学习是指学习x到y或输入到输出映射的算法,监督学习的关键特征是提供学习算法示例以供学习,这包括正确答案 给定输入x的正确标签y,通过查看输入x和所需输出标签y的正确对,学习算法最终学会只接受输入而无需输出标签,并给出输出的合理准确的预测或猜测
例子:
如果输入x是一封电子邮件,输出y是这封电子邮件,无论是垃圾邮件还是非垃圾邮件,都会提供垃圾邮件过滤器 或者,如果输入是音频剪辑,算法的工作是输出文本转录本,那么这就是语音识别 或者,如果输入是英文,输出相应的西班牙文、中文、日文等,那么这就是机器翻译 现今最有利可图的监督学习形式是用于在线广告,几乎所有大型在线广告平台都有一个学习算法,可以输入一些关于广告的信息和用户的信息,然后试图弄清楚你是否会点击那个广告,因为通过向用户展示广告,他们点击的可能性会稍高一些 学习算法将一些图像和来自其他传感器的一些信息作为输入,然后输出其他汽车的位置,然后自动驾驶就可以安全地绕过其他汽车 将制造产品的图片作为输入,例如刚刚下线的手机,并让学习算法输出产品中是否存在划痕、凹痕或其他缺陷,这称为目视检查

在所有这些应用程序中,首先输入示例x和正确答案(标签y)来训练模型,在模型从这些输入和输出或xy对中学习之后,它们可以采用一个全新的输入x,并尝试产生适当的相应输出y
回归算法
另一个具体的例子:
假设想根据房子的大小来预测房价,收集了一些数据,并绘制了数据,如图,横轴是房子的面积,以平方英尺为单位,纵轴是房子的价格 有了这些数据,假设想知道750平方英尺的房子的价格是多少,学习算法如何做?
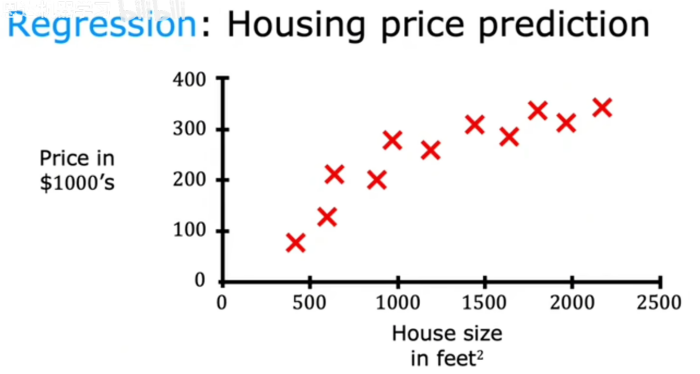
学习算法可以绘制数据的直线,并从直线上读取,看起来750平方英尺的房子大约会以150000美元的价格出售
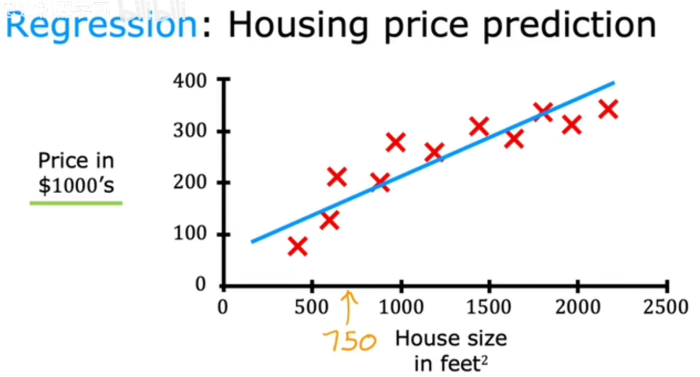
但拟合直线并不是可以使用的唯一学习算法,还有其他可以更好地用于此应用程序的方法 例如拟合直线时,可能拟合曲线更好,如果这样做并预测,看起来750平方英尺的房子可能会以200000美元的价格出售 如何让算法系统地选择最合适的直线、曲线或其他适合该数据的东西
这是一个监督学习的例子,因为给算法提供了一个数据集,在其中有所谓的正确答案,也就是标签 学习算法的作用是产生更多这样的正确答案,例如预测750平方英寸房子的可能价格是多少
这种房价预测是一种特殊类型的监督学习,成为回归 回归是指试图从无数可能的数字中预测一个数字,例如这个例子中的房价,可能是150000美元、70000、183000或介于两者之间的任何其他数字
分类算法
还有第二种主要类型的监督学习问题,成为分类
以乳腺癌检测作为一个分类问题的例子,假设你在做一个机器学习系统,让医生有一个诊断工具来检测乳腺癌,利用病人的医疗记录,你的机器学习系统试图弄清楚一个肿块的肿瘤是否是恶性的 所以你的数据集里有各种大小的肿瘤,这些肿瘤被标记为良性,将用0来表示这个例子,恶性的在这个例子中被称为1,然后可以把数据绘制在图表上,横轴代表肿瘤的大小,纵轴只代表两个值,0和1
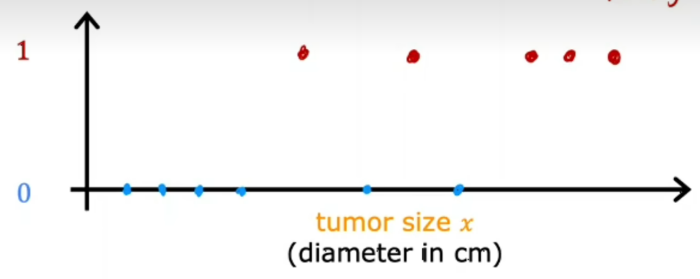
这与回归不同的一个原因是,我们只试图预测一小部分可能的输出或类别,这种情况下,两种可能的产出,0或1 回归试图预测无限多个可能的数字中的任意一个,分类只有有限个可能的输出,这就是为什么叫做分类
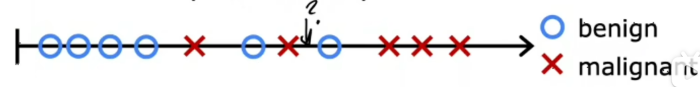
在这个例子中,只有两种可能的输出或两种可能的类别,还可以将这个数据集绘制在像这样的一条线上,用两个不同的符号,一个圆圈表示良性,x表示恶性的例子 如果一个新的病人来做诊断,他们有一个肿块,就是这个尺寸(图中问号),那么问题是,系统会把这个肿瘤分为良性还是恶性

在分类问题中,还可以有两个以上可能的输出类别,如果是恶性的,也许你的学习算法可以输出多种类型的癌症诊断,所以让我们把两种不同类型的癌症,类型1和类型2,在这种情况下,该算法将有三种可能的输出类别
顺便说一下,输出类和输出类别经常互换使用,意思是一样的
在我们一直研究的监督学习的例子中,只有一个输入值,但是也可以使用多个输入值来预测输出
另一个例子:
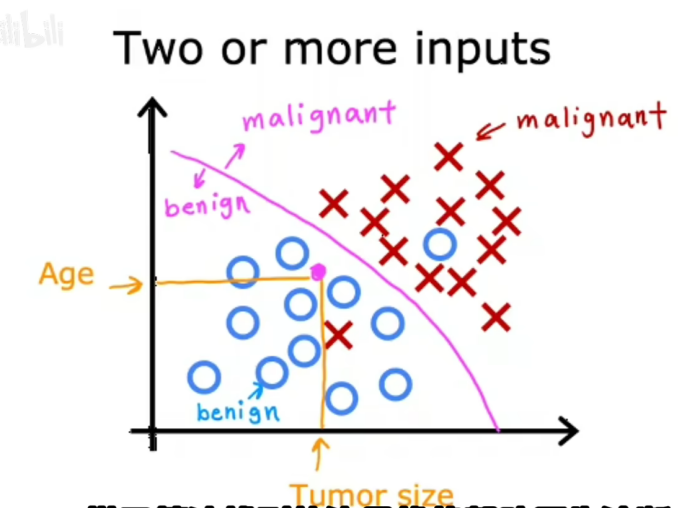
不止知道肿瘤的大小,假设也有每个病人的年龄,新数据集现在有两个输入,绘制这个新的数据集,用圆圈向病人展示他们的肿瘤是良性的,以及叉来显示病人的肿瘤是恶性的 所以当一个新病人进来的时候,医生可以测量患者肿瘤大小,同时记录下病人的年龄,我们如何预测这个病人的肿瘤是良性还是恶性的
基于这样的数据集,学习算法可能要做的就是找到一些边界来区分恶性肿瘤和良性肿瘤,因此学习算法必须决定如何将边界线拟合到这些数据上
无监督学习
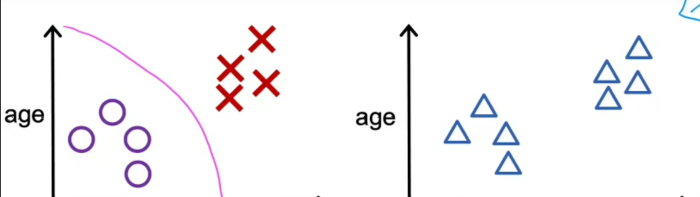
监督学习在分类问题的情况下是这样的,每个示例都有一个输出标签y相关联,例如良性或恶性,在无监督学习中用两极和十字表示给定的数据与任何输出标签y无关,比如给定了有关患者及其肿瘤大小和患者年龄的数据,不论肿瘤是良性的还是恶性的,数据集在右边看起来像这样 我们没有被要求诊断肿瘤是良性还是恶性,因为没有给我们任何标签,相反,如果我们的工作是找到一些结构、模式或者只是在数据中找到一些有趣的东西,这是无监督学习
为了对每个输入给出一些引用正确的答案,我们要求我们的房间自己弄清楚什么是有趣的,或者对于这个特定的数据集,这个数据中可能有什么模式或结构
聚类算法
无监督学习算法会决定将数据分配给两个不同的组或集群,所以它可能会决定,这里有一个集群或组,这里有另一个集群或组,这是一种特殊类型的无监督学习,成为聚类算法
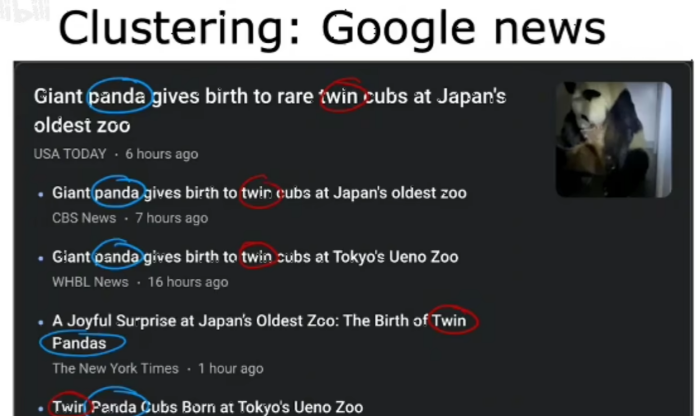
聚类算法将未标记的数据放入不同的集群中,这被用于许多应用程序,例如Google news用的就是聚类,它做的就是查看互联网上数十万篇新闻文章,并将相关故事组合在一起 例如:这里有一个来自谷歌新闻的样本,其中顶部文章的标题是大熊猫在日本最古老的动物园生下一对双胞胎幼崽,下面是其他相关文章
所以聚类算法正在寻找当天互联网上所有数十万篇新闻文章,找到提到相似词的文章,并将它们分组到集群中 这种聚类算法会自动计算出哪些词暗示某些文章属于同一组
接下来看一下应用于聚类遗传或DNA数据的无监督学习的例子:
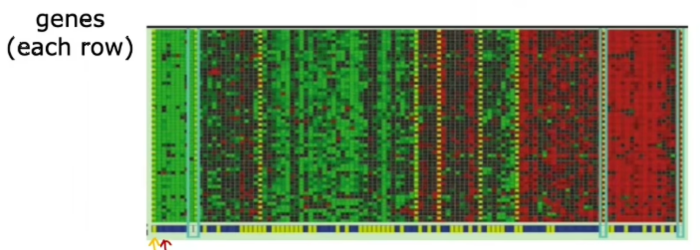
此图像显示了DNA微列阵数据的图片,这些看起来像电子表格的微小网格,每个小柱子代表一个人的遗传或DNA活动,例如,这里的整个柱子都来自一个人的DNA,另一列是另一个人的,每一行代表一个特定的基因,举个例子,这里代表一个影响眼睛颜色的基因,或者这里是一个影响身高的基因 这个想法是为了测量每个人表达了多少特定基因,红色、绿色、灰色等这些颜色显示了不同个体具有或不具有特定基因活性的程度
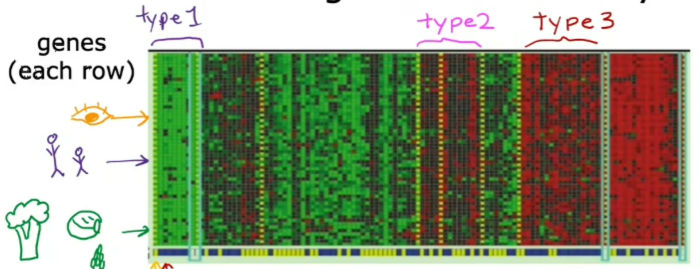
然后可以运行聚类算法,将个体分组到不同的类别中,或者不同类型的人可能像这样聚集在一起的人,我们称这种为类型1,这些人被归为第二类,这些人被归为第三类 这是无监督学习,因为我们没有提前告诉有些人具有某些特征,或具有某些特征的第二类人,而不是我们所说的这是一堆数据
因为我们没有提前为算法提供示例的正确答案,不知道不同类型的人是什么,但你能自动找到数据的结构,并自动找出个人的主要类型
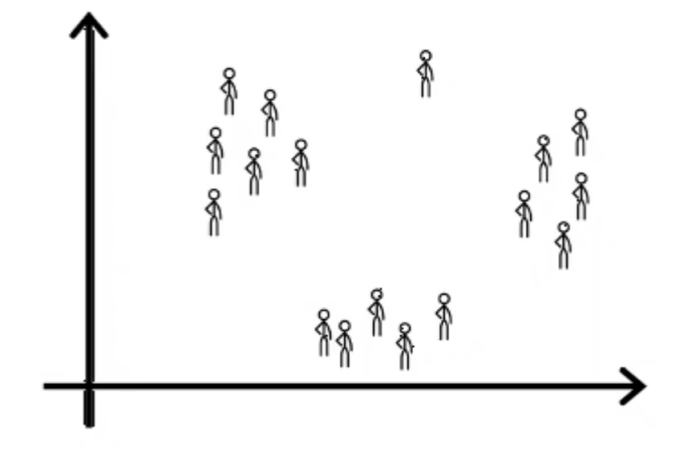
这是无监督学习,第三个例子,很多公司拥有庞大的客户信息数据库,是否能自动将客户分组到不同的细分市场,以便更有效地为客户服务
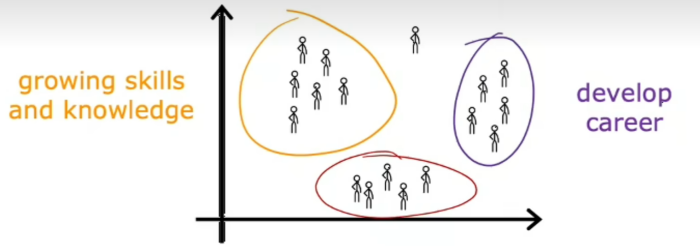
市场细分发现了几个不同的个人群体,一个群体的主要动机是寻求知识以提高他们的技能,第二组的主要动机是寻找发展他们职业的方法,还有一群人想随时了解AI如何影响他们的工作领域
如果图中单独的人是你,你想要与其他三个类别完全不同的东西 这就是无监督学习算法,获取没有标签的数据并尝试自动将他们分组到集群中
聚类将相似的数据点结合在一起,除了聚类以外,还有其他的无监督学习算法:
异常检测
一种称为异常检测,用于检测异常事件,用于金融系统中的欺诈检测
降维
另一种是降维,是指将一个大数据集神奇地压缩成一个小得多的数据集,同时丢失尽可能少的信息

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)