TFLite——从模型训练到部署,实现Android图像分类功能
由此我们实现了TFLite——从训练一个超轻量化模型开始,到部署到Android中,实现了一个图像分类功能,作为TFLite的入门学习,这有助于加深Android开发者使用TFLite在移动端实现AI功能的理解。作者:练泽宇TFLite——从模型训练到部署,实现Android图像分类功能。
TFLite——从模型训练到部署,实现Android图像分类功能
背景
TFLite(TensorFlow Lite)是谷歌专为端侧设计的轻量化推理框架,在Android的学习过程中,TFLite可以在Android设备普遍存在配置受限(如内存、存储等)的情况下,让深度学习模型部署并运行。可以实现移动端APP的视觉识别类功能等,如图像识别和图像分类功能,运用到实际中就是可以实现例如扫描图片中的文字实现笔记内容快速导入,通过识别图片得知商品类型等。本文旨在以一个Android初学者的视角,通过从训练模型到部署,最终实现一个Android图像分类功能,从而对TFLite的使用有更加深入的了解。
模型准备
受限于笔记本性能,这次训练的模型是基于CIFAR-10数据集中六种动物(鸟、猫、鹿、狗、青蛙、马,各6000张共36000张32 * 32大小的样本构成),以CNN(卷积神经网络)为深度学习的核心模型,辅以几种模型优化方法训练出的一个超轻量化图像分类模型。
导入训练模型所需的库
采用的是TF 2.x + Keras组合,Keras是一个高级神经网络API,已经作为tf.keras成为TF 2.x的原生核心组件,与其深度融合。TF从1.x到2.x,计算方式从静态计算图升级到了动态计算图,对TFLite的兼容性更好,开发效率更高。
导入训练集

CIFAR-10可以直接通过官方导入,虽然下载比较慢,但是清华镜像不知道为什么不让访问,腾讯、阿里云等镜像也找不到,同时网络上的其它数据集哈希码不对文件大小也不对,就只能官方下了(在运行模型的时候会检测本地/ASUS/.keras/datasets中是否有对应数据集,没有的话会自动下载)。
数据预处理
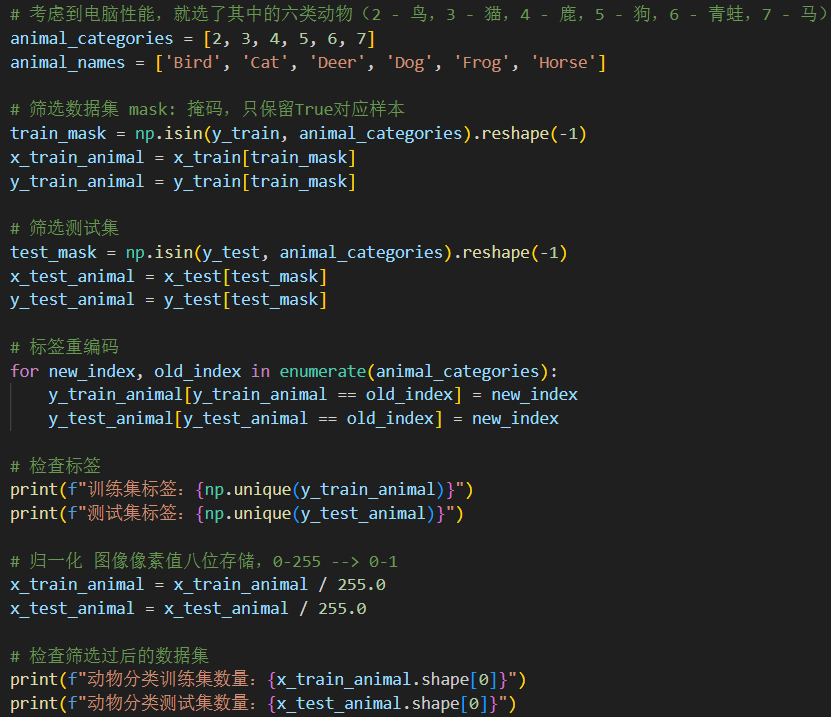
因为本次训练模型只选用六类,但CIFAR-10数据集原本是十类共60000张图片,所以在数据预处理的时候要进行筛选,筛选之后对原本的标签进行重编码,最后将数据集作归一化处理。下面是输出检验:
模型优化
数据增强
数据增强通过对原始数据集进行一系列变换,从而减少模型过拟合现象,提升模型泛化能力。常见的参数有随机翻转(水平/垂直),随机旋转(顺时针/逆时针,建议幅度在10°左右),随机缩放(放大/缩小,建议幅度在10%左右)等,这里考虑到动物比较少出现倒立的情况,同时32 * 32的图片大小再进行缩放或旋转可能会产生奇怪的干扰(尝试过加这些参数,但是准确率直接从未优化模型的68%左右的准确率掉到了50%),所以仅添加了随机水平翻转。
回调函数
回调函数在多个训练轮次的时候可以保存最优一轮的模型,在模型准确率没有继续提升的时候及时停止训练以减少训练预期时间(因为不知道大概几轮会获得最优模型,设置少了可能不够用,设置多了一次训练时间太长)。这里使用了两个回调函数,一个是早停法回调函数: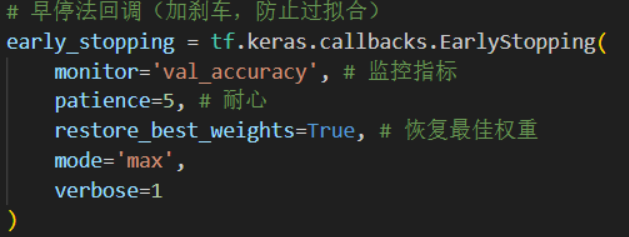
早停法回调函数相当于给模型上了一个刹车,核心是patience(耐心)参数,控制在监控指标经过了patience轮仍未提高时,中止模型训练并把模型恢复到最佳权重的轮次,可以有效防止模型的过拟合。
另一个是模型检查点回调函数: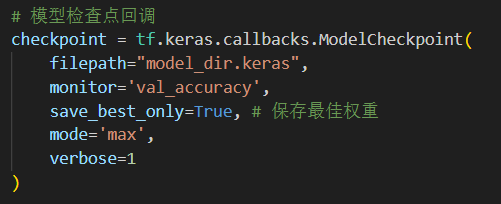
模型检查点回调函数在训练轮次全部结束的时候会回到最佳权重的轮次,相当于给模型上了一个保底,也能有效防止模型的过拟合。但是由于有早停法回调函数,后面训练模型的时候设置轮次成了一百轮,耐心为5的情况下一般不会触发模型检查点回调函数,所以基本上只控制模型输出后的保存路径,这里设置输出为.keras模型。
模型创建、编译、训练和评估
模型创建
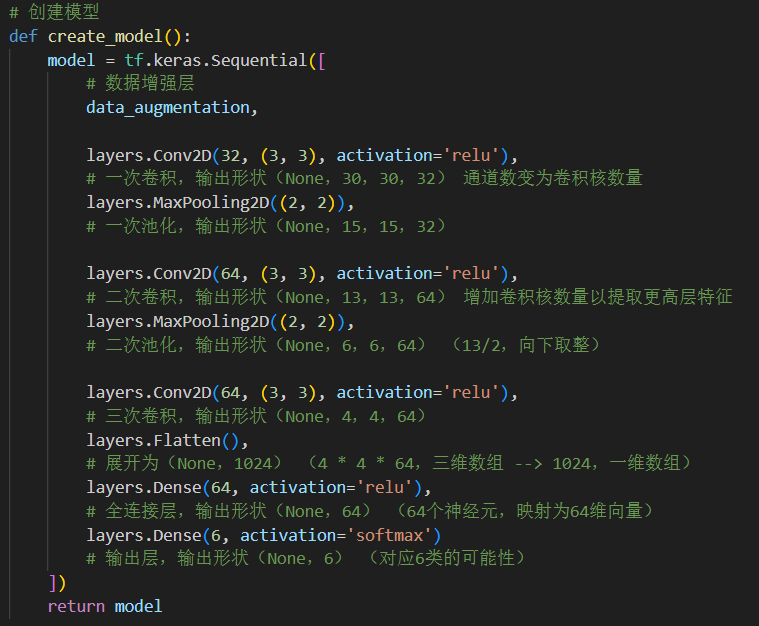
模型以CNN为深度学习的核心,运用了数据增强层(这个不属于CNN)、卷积层(三次卷积)、池化层(两次池化)、全连接层和输出层来提取数据的特征,选用ReLU作为激活函数。以下是对模型经过每一层之后的输出结构验证(对应注解):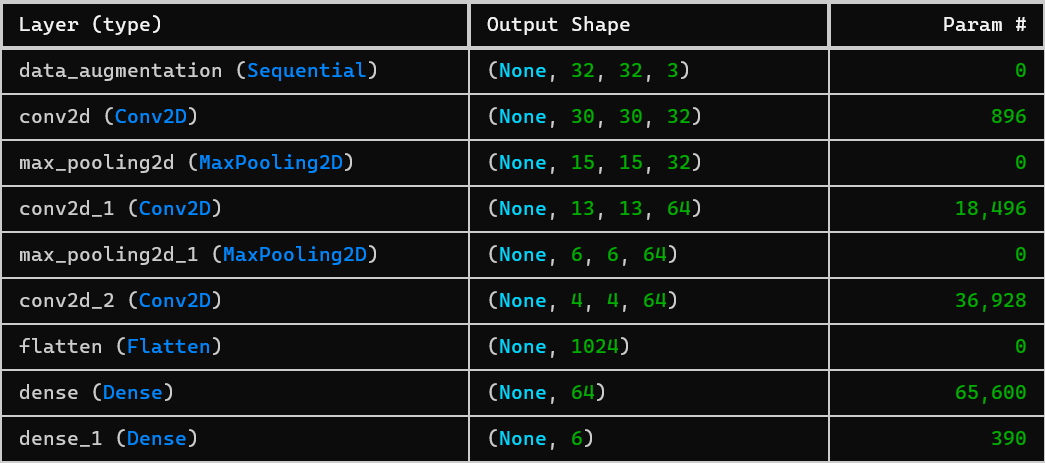
模型编译

Adam:最常用的优化器之一,适合超轻量化模型的训练
整形损失函数:适用于多分类任务
以准确率为评估指标
模型训练

导入筛选后的数据集、回调函数
epochs:模型训练轮数,因为有早停法所以可以设置比较多轮次
batch_size:一轮训练的数据量,为训练集/batch_size
validation_split:验证集,从数据集中提取一定比例的数据作为验证集,不参与模型训练,如果验证集的准确率和测试集的准确率差太多,说明可能是过拟合
模型评估

test_loss:模型在测试集上的损失值(预测与真实标签的差异)
test_acc:模型在测试集上的准确率
模型转换
因为要把深度学习模型部署到Android上,需要把模型转换成.tflite格式,TF 2.x由于和Keras深度融合,自带.keras模型转.tflite模型的转换器,这使得获取.tflite模型变得非常轻松,这也是为什么选择用TF 2.x + Keras的组合来在Android部署模型。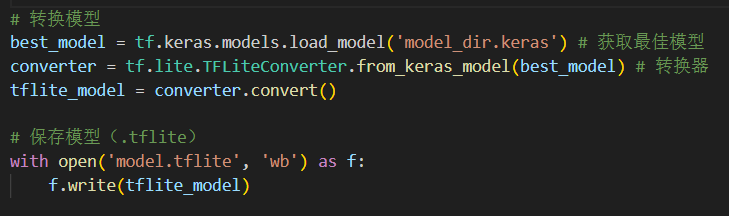
部署准备
要应用TFLite在Android中部署模型,首先需要做好模型的导入和依赖导入工作:
创建一个新的Android项目(独角鲸版本最低支持的API为24,高于最低需求API 21),在构建项目完成后,于src/main下建立一个assets目录,将.tflite格式的模型和测试图片放进去。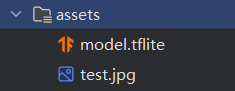
在build.gradle.kts中导入相关依赖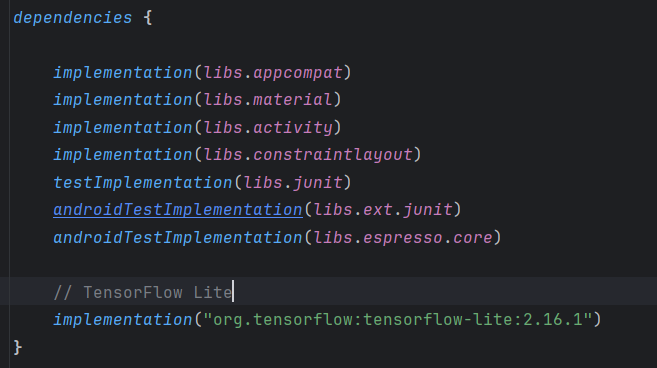
模型部署
加载模型文件
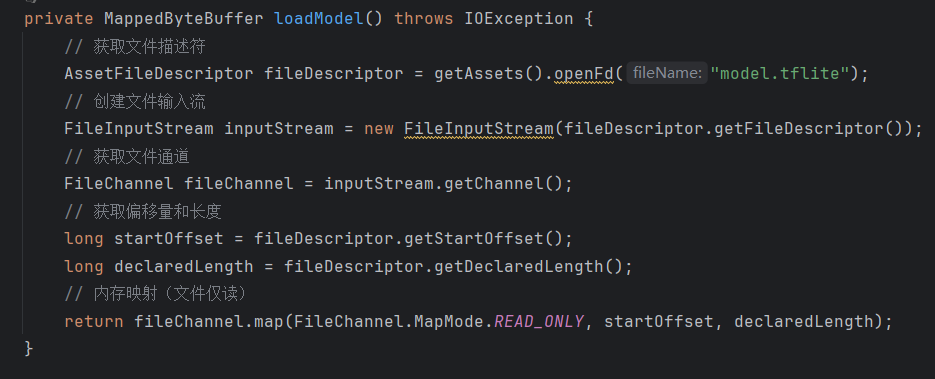
从assets文件夹中读取出模型文件
初始化编译器

使用TFLite在Android部署模型,最关键的是模型编译器Interpreter,它统筹了加载模型、管理输入输出数据以及模型的推理。
规范输入
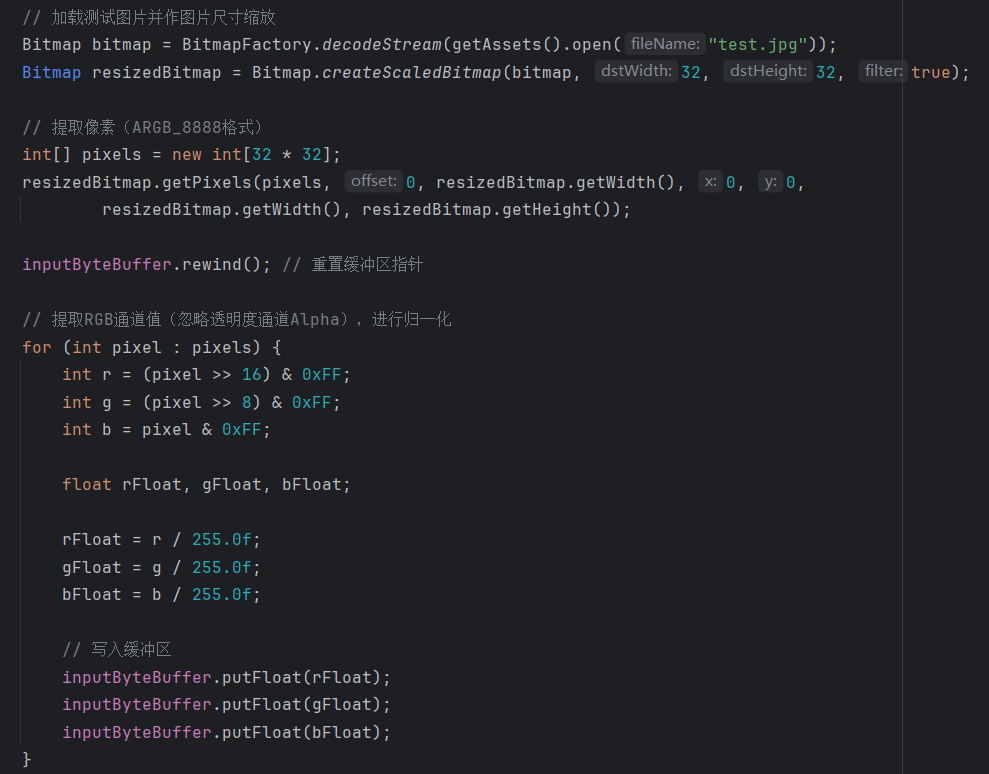
由于网络上找的动物朋友们大多是像素很高的,但是模型又限制了32 * 32的输入,所以要对图片进行缩放(这里选择的动物图片最好是完整展示动物形体的,因为试了一下跪姿鹿的图片,模型跑出来认为是青蛙,本来以为大失败,但是自己在网站上把图片缩放成32 * 32后,我只觉得今天天塌下来这玩意也得是青蛙)
然后要提取出像素,对RGB进行归一化(同模型训练时的归一化的形式),作为规范的输入。
模型运行
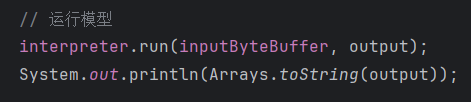
选好图片(test.jpg)之后,就可以运行模型了,Logcat里面找结果太难了,所以把分类和各个种类的概率绑定到了界面的TextView中,方便查看。这里选择的图片是一头看起来眉清目秀的鹿:
可见被预测为鹿的分类置信度达到了85%+,太好了,没有指鹿为马。
总结
由此我们实现了TFLite——从训练一个超轻量化模型开始,到部署到Android中,实现了一个图像分类功能,作为TFLite的入门学习,这有助于加深Android开发者使用TFLite在移动端实现AI功能的理解。
作者:练泽宇
原文链接:TFLite——从模型训练到部署,实现Android图像分类功能

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)